目录
[模块 1:环境配置与可视化基础设置](#模块 1:环境配置与可视化基础设置)
[模块 2:数据加载与预处理(核心数据准备)](#模块 2:数据加载与预处理(核心数据准备))
[模块 3:电商数据特征可视化(多维度探索性分析)](#模块 3:电商数据特征可视化(多维度探索性分析))
[模块 4:数据预处理与拆分(模型输入准备)](#模块 4:数据预处理与拆分(模型输入准备))
[模块 5:辅助函数(模型评估与调参)](#模块 5:辅助函数(模型评估与调参))
[模块 6:截断 SVD 模型训练与调参(基础矩阵分解)](#模块 6:截断 SVD 模型训练与调参(基础矩阵分解))
[模块 7:带偏置的 FunkSVD 实现(进阶矩阵分解)](#模块 7:带偏置的 FunkSVD 实现(进阶矩阵分解))
[模块 8:FunkSVD 模型评估](#模块 8:FunkSVD 模型评估)
[模块 9:模型效果可视化(核心对比分析)](#模块 9:模型效果可视化(核心对比分析))
[模块 10:隐向量 TSNE 可视化(深度特征分析)](#模块 10:隐向量 TSNE 可视化(深度特征分析))
[模块 11:单个客户预测可视化(个性化分析)](#模块 11:单个客户预测可视化(个性化分析))
[模块 12:模型对比总结(最终结论)](#模块 12:模型对比总结(最终结论))
一、引言
本文介绍的内容是电商销售额预测实战,基于矩阵分解(截断 SVD、带偏置 FunkSVD)实现客户 - 产品销售额预测,涵盖数据清洗、特征可视化、模型训练、调参、评估、结果可视化全流程,核心目标是通过用户 - 产品交互数据预测客户对产品的销售额,对比不同矩阵分解模型的效果。以下是按模块拆解进行讲解以及Python代码完整实现。
本文的电子商务数据集CSV文件和电商销售额预测实战代码位于同一目录中。
电子商务数据集下载地址:https://tianchi.aliyun.com/dataset/201220
二、整体架构总览
本文的实战内容分为 11 个核心模块,形成 "数据处理→可视化探索→模型训练→效果评估→深度分析" 的完整闭环,核心逻辑是:原始数据清洗 → 多维度特征可视化 → 构建用户-产品矩阵 → 截断SVD调参训练 → 自定义FunkSVD(带偏置)训练 → 模型效果对比 → 隐向量/单客户预测可视化
三、分模块详细功能说明
模块 1:环境配置与可视化基础设置
| 核心目标 | 解决中文显示乱码问题,统一绘图样式,保证可视化效果一致性 |
|---|---|
| 实现细节 | 1. 设置SimHei(黑体)为默认字体,解决 matplotlib/seaborn 中文显示问题; 2. 关闭负号显示异常; 3. 统一默认绘图尺寸(12,8)、字体大小(10); 4. 设置 seaborn 的whitegrid风格,让图表更美观; |
| 输出结果 | 无显性输出,为后续所有可视化图表奠定样式基础,避免中文乱码 / 负号缺失。 |
模块 2:数据加载与预处理(核心数据准备)
| 核心目标 | 加载原始电商数据,清洗销售额列,归一化,聚合数据,统计数据基础特征 |
|---|---|
| 实现细节 | 2.1 数据加载- 读取E_commerce.csv(GBK 编码),规避低内存警告; 2.2 销售额列清洗- 定义clean_sales_column函数: 将 Sales 列转为字符串,填充空值为 0; 移除 $ 符号、空格,提取纯数字部分; 转为浮点型,异常值填充为 0; 2.3 销售额归一化- 用MinMaxScaler将销售额缩放到 0,1 区间(避免数值过大导致模型训练溢出);2.4 数据聚合- 按「客户 ID + 产品 + 产品类别」聚合,求和销售额(原始 + 归一化后),避免重复交易记录; 2.5 基础信息统计- 计算总客户数、总产品数、总交易数、客户 - 产品矩阵稀疏度(稀疏度 = 1 - 交易数 /(客户数 × 产品数)); |
| 输出结果 | 打印数据基础信息(如总客户数: XXX 稀疏度: 0.XXXX),生成清洗 / 聚合后的核心数据框df_core。 |
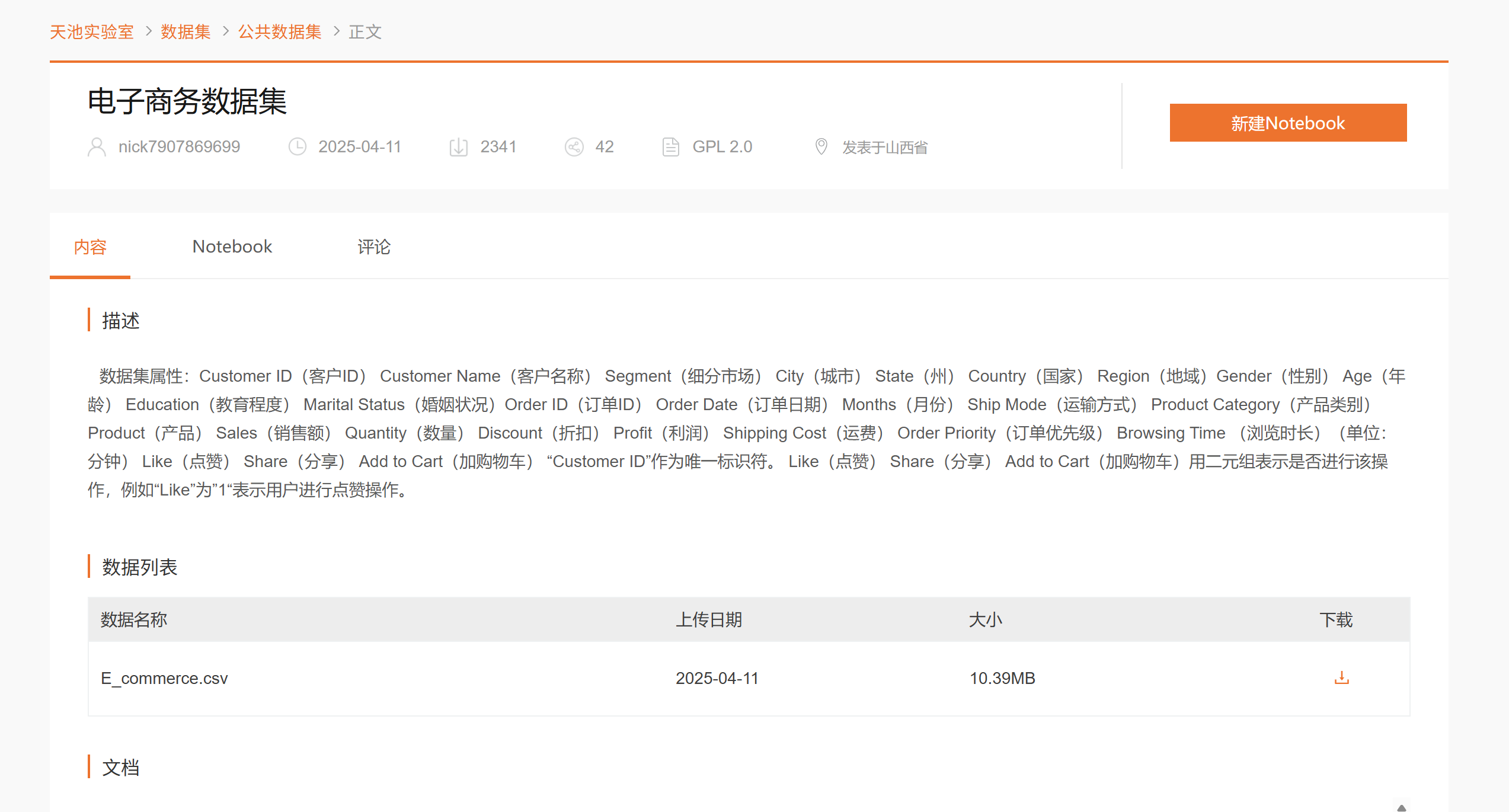
模块 3:电商数据特征可视化(多维度探索性分析)
| 核心目标 | 从 6 个维度可视化数据特征,直观理解数据分布、高价值客户 / 产品、类别特征等 |
|---|---|
| 实现细节 | 定义plot_ecommerce_features函数,生成 2 行 3 列的子图布局,包含 6 类图表: 1. 销售额分布直方图:展示销售额的整体分布,带核密度曲线(KDE); 2. Top N 高消费客户柱状图:选取最多 50 个高消费客户,展示其总购买金额(避免图表过于拥挤); 3. Top N 热销产品柱状图:选取最多 50 个热销产品,前 10 个显示产品名称(超长名称截断),其余显示索引; 4. 客户 - 产品矩阵稀疏性热力图:采样最多 100 个客户,展示交易记录的稀疏性(白色 = 无交易,黑色 = 有交易); 5. 产品类别销售额占比饼图:展示不同类别销售额的占比(百分比); 6. Top N 类别平均销售额柱状图:选取最多 10 个类别,展示其平均销售额; |
| 输出结果 | 生成电商数据特征可视化.png(300DPI,自适应布局),直观呈现数据的核心特征(如哪些类别销售额最高、客户消费分布是否集中等)。 |
模块 4:数据预处理与拆分(模型输入准备)
| 核心目标 | 构建用户 - 产品销售额矩阵,拆分训练 / 测试集,对齐测试集维度 |
|---|---|
| 实现细节 | 1. 按 8:2 拆分训练集train_df和测试集test_df(随机种子 42 保证可复现); 2. 构建训练集的用户 - 产品矩阵train_matrix(行 = 客户 ID,列 = 产品,值 = 销售额,空值填充 0); 3. 对齐测试集:仅保留训练集中存在的客户和产品(避免冷启动问题); |
| 输出结果 | 生成训练矩阵train_matrix、对齐后的测试集test_df,为模型训练提供输入。 |
模块 5:辅助函数(模型评估与调参)
| 核心目标 | 定义评估指标(RMSE)和 k 值调参函数,为模型训练和优化服务 |
|---|---|
| 实现细节 | 5.1 RMSE 计算函数evaluate_rmse 遍历测试集每条记录,匹配预测矩阵中的销售额; 计算真实值与预测值的均方根误差(RMSE),确保预测值非负(销售额不能为负); 5.2 k 值调参函数tune_k_value 过滤超出矩阵维度的 k 值(k 不能大于用户数 / 产品数); 遍历指定 k 值列表,训练截断 SVD 模型,计算每个 k 值的 RMSE; 输出每个 k 值的 RMSE,返回有效 k 值列表和对应 RMSE; |
| 输出结果 | 打印每个 k 值的 RMSE(如k=5 时 RMSE: X.XXXX),为后续选最优 k 值提供依据。 |
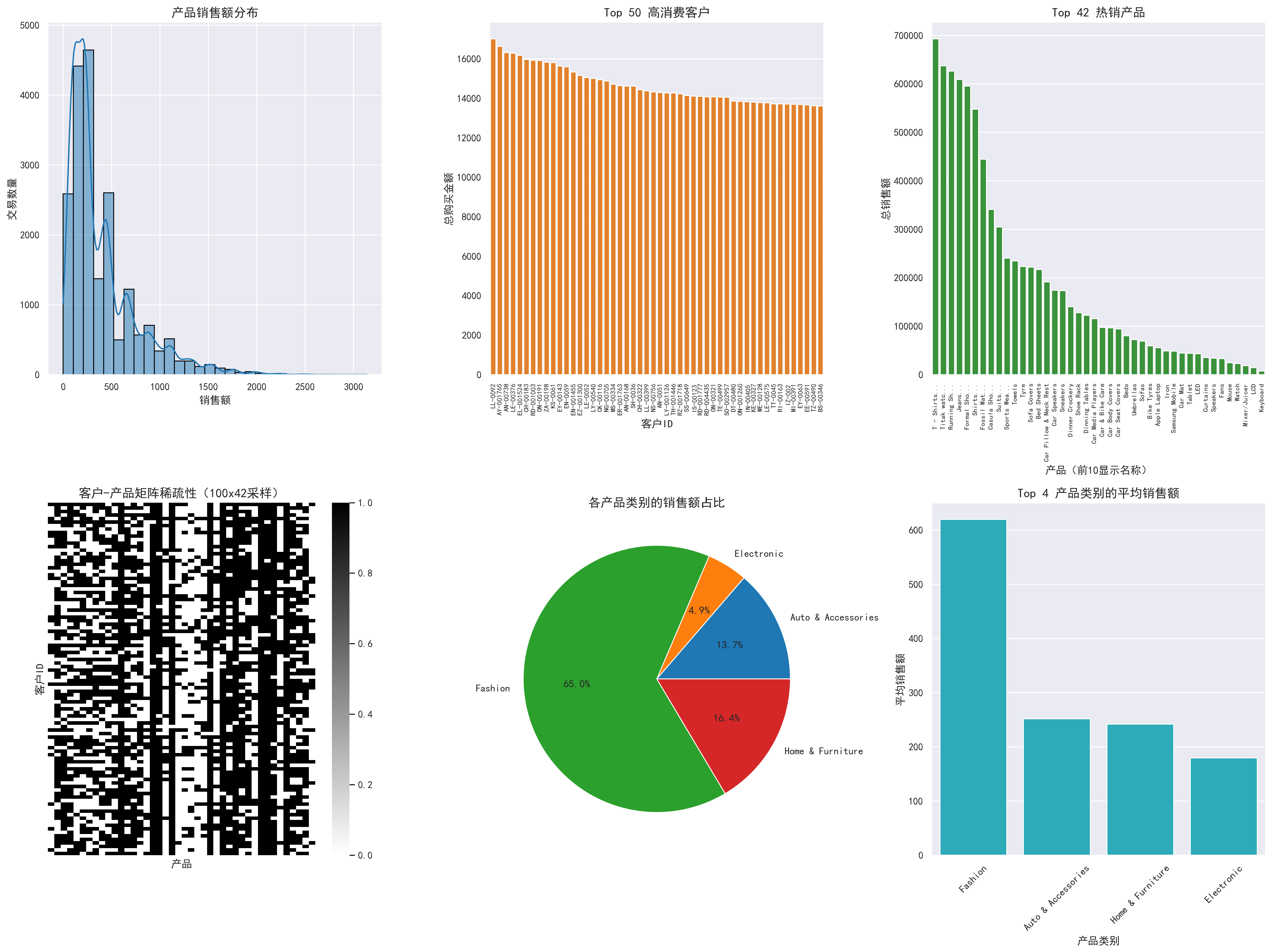
模块 6:截断 SVD 模型训练与调参(基础矩阵分解)
| 核心目标 | 测试不同隐因子 k 值的效果,选最优 k 训练截断 SVD,评估预测效果 |
|---|---|
| 实现细节 | 1. 测试 k 值列表[5,10,20,30,40,50,60],调用tune_k_value函数; 2. 绘制 k 值与 RMSE 的关系曲线,标记最优 k 值(RMSE 最小的 k); 3. 用最优 k 值训练TruncatedSVD模型: 生成用户隐向量user_emb_svd(用户数 ×k); 生成产品隐向量item_emb_svd(k× 产品数); 矩阵相乘得到预测销售额矩阵pred_matrix_svd; 4. 计算最优 k 值下的测试集 RMSE; |
| 输出结果 | 1. 生成k值调参曲线.png(展示 k 值与 RMSE 的关系,标注最优 k); 2. 打印最优 k 值的 RMSE(如截断SVD (k=20) 测试集RMSE: X.XXXX); |
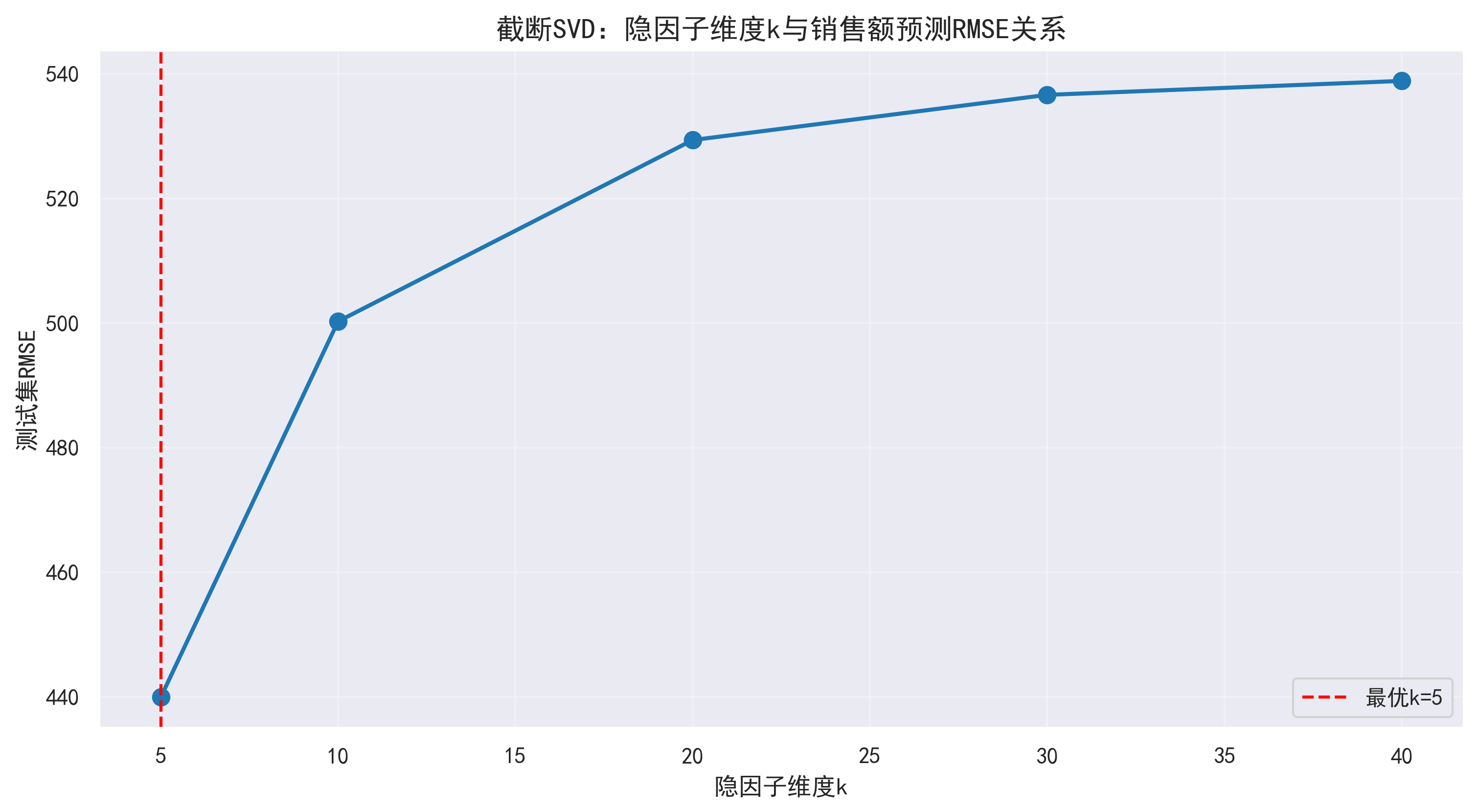
模块 7:带偏置的 FunkSVD 实现(进阶矩阵分解)
| 核心目标 | 自定义带客户 / 产品偏置项的 FunkSVD 类,适配归一化后的销售额预测,提升精度 |
|---|---|
| 实现细节 | 定义BiasFunkSVD类,核心逻辑: 7.1 初始化参数- k:隐因子维度(默认 50); lr:学习率(0.0001,缩小学习率避免更新幅度过大); reg:正则化系数(0.05,增大正则化稳定训练); epochs:迭代轮数(50); 其他:全局均值、用户 / 产品偏置、用户 / 产品隐向量、ID 到索引的映射、损失历史; 7.2 训练方法fit 计算归一化销售额的全局均值; 构建用户 / 产品 ID 到索引的映射(方便矩阵操作); 初始化偏置项(全 0)和隐向量(正态分布,方差 0.01,避免初始值过大); 迭代训练: 1. 每轮打乱训练数据,避免顺序影响; 2. 遍历每条记录,计算预测值(全局均值 + 用户偏置 + 产品偏置 + 隐向量内积); 3. 计算损失(平方误差 + 正则化项); 4. 梯度下降更新偏置项和隐向量; 5. 每 10 轮打印总损失; 7.3 预测方法predict 冷启动处理:未知客户 / 产品返回全局均值(反归一化后); 计算归一化销售额的预测值,确保非负; 反归一化(通过scaler.inverse_transform)得到原始尺度的销售额; |
| 输出结果 | 1. 训练过程中打印每 10 轮的总损失(如 `Epoch 10/50总损失: X.XXXX`); 2. 生成训练损失曲线(后续可视化); |
模块 8:FunkSVD 模型评估
| 核心目标 | 计算 FunkSVD 的测试集 RMSE,为后续对比提供指标 |
|---|---|
| 实现细节 | 定义evaluate_funksvd函数: 1. 遍历测试集,调用predict方法得到每个客户 - 产品的销售额预测值; 2. 计算真实值与预测值的 RMSE; 3. 返回 RMSE、真实值列表、预测值列表; |
| 输出结果 | 打印 FunkSVD 的 RMSE(如带偏置FunkSVD 测试集RMSE: X.XXXX); |
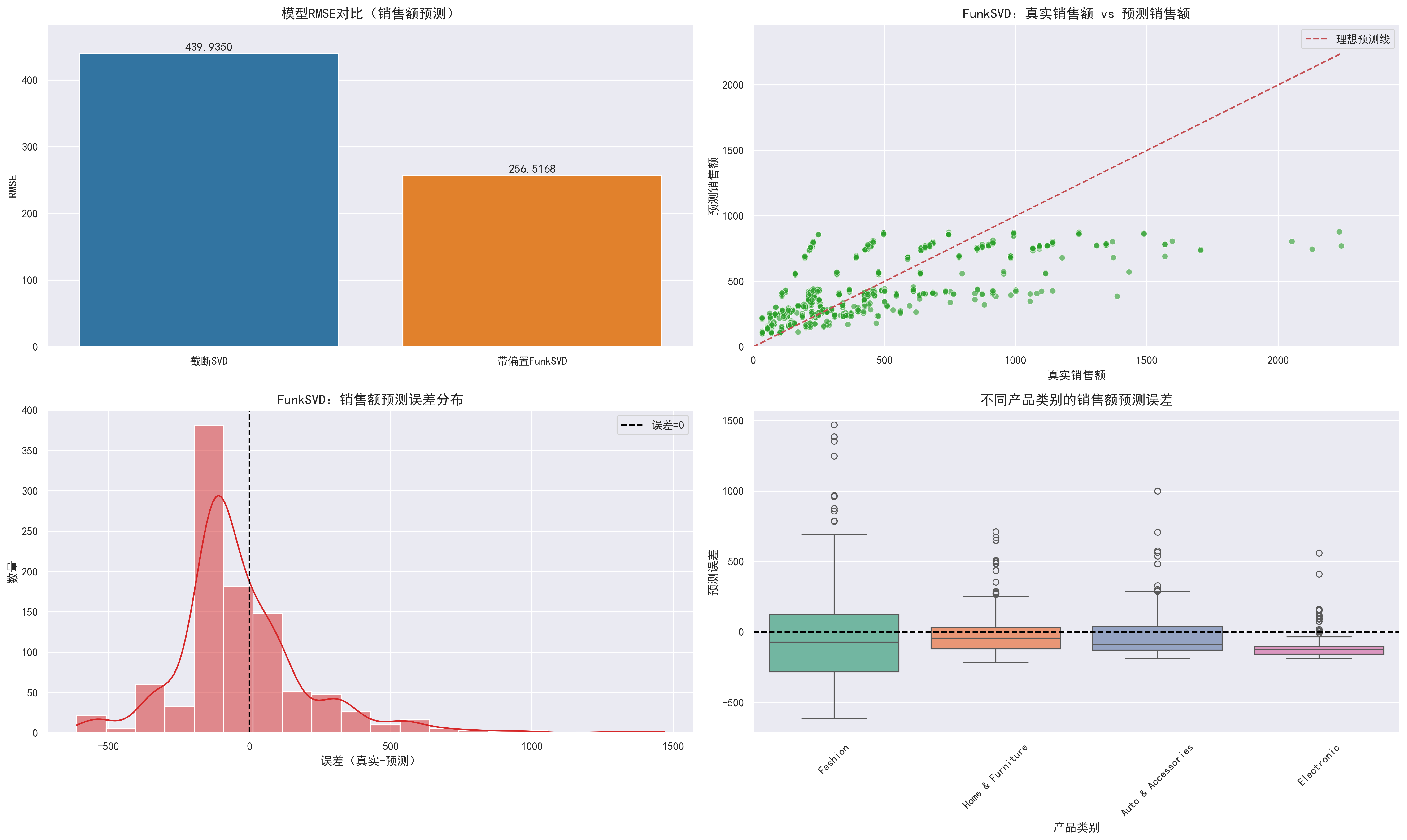
模块 9:模型效果可视化(核心对比分析)
| 核心目标 | 从 4 个维度对比截断 SVD 和 FunkSVD 的效果,分析预测误差特征 |
|---|---|
| 实现细节 | 定义plot_model_performance函数,生成 2 行 2 列的子图: 1. 模型 RMSE 对比柱状图:对比截断 SVD 和 FunkSVD 的 RMSE,标注具体数值; 2. 真实 vs 预测销售额散点图:采样 1000 条记录,绘制真实值与预测值的散点,添加理想预测线(y=x); 3. 预测误差分布直方图:展示误差(真实 - 预测)的分布,标注误差 = 0 的线; 4. 不同类别误差箱线图:展示各产品类别的预测误差分布,标注误差 = 0 的线; |
| 输出结果 | 生成模型效果可视化.png,直观展示 FunkSVD 相比截断 SVD 的优势(如 RMSE 更低、误差更集中在 0 附近)。 |
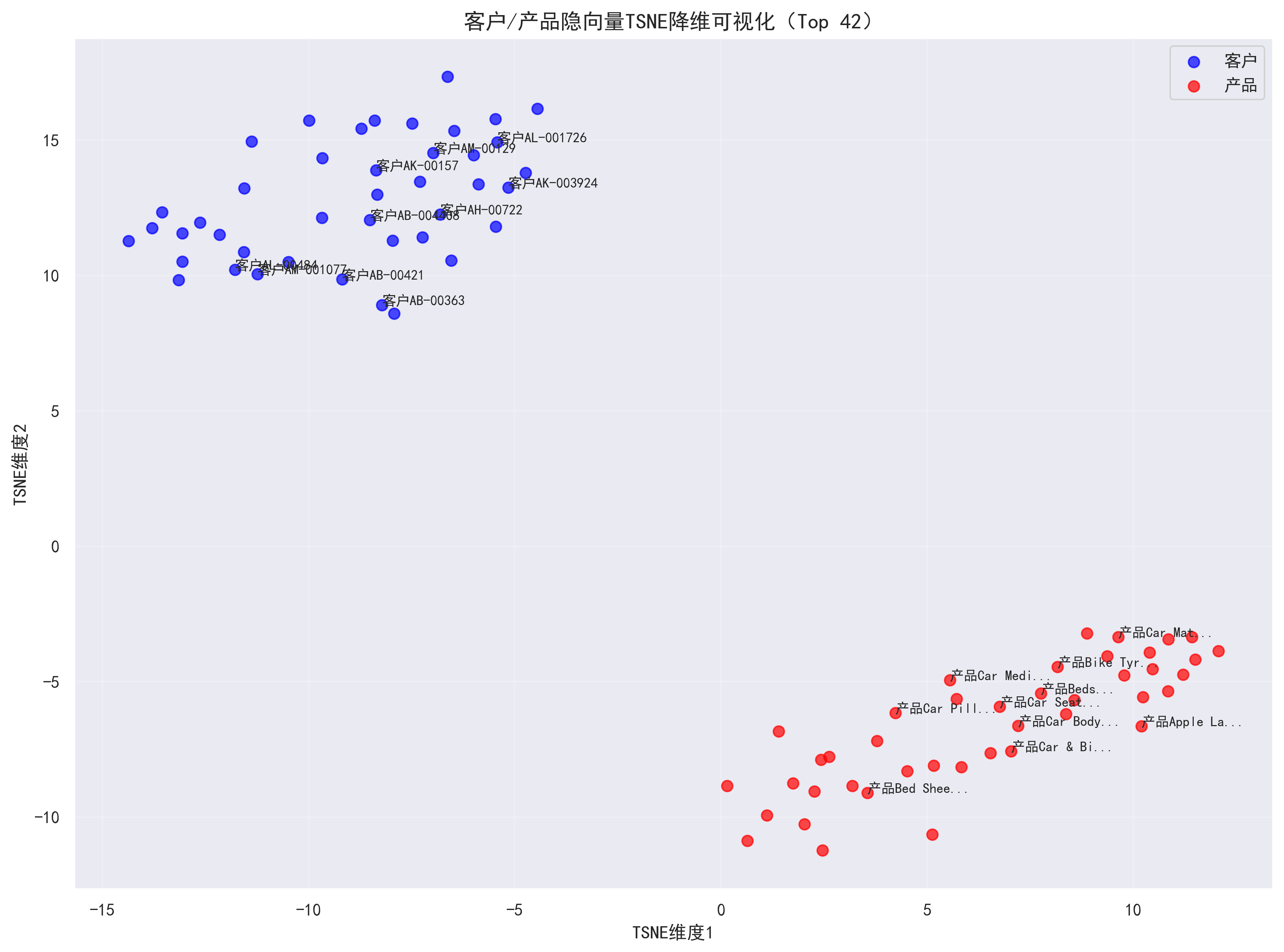
模块 10:隐向量 TSNE 可视化(深度特征分析)
| 核心目标 | 将高维的用户 / 产品隐向量降维到 2 维,展示客户与产品的聚类特征 |
|---|---|
| 实现细节 | 定义plot_embedding_tsne函数: 1. 采样 Top 50 的用户 / 产品隐向量(避免计算量过大); 2. 设置 TSNE 的 perplexity(最小 15,避免样本不足报错); 3. 用 TSNE 将用户 + 产品隐向量降维到 2 维; 4. 绘制散点图(客户 = 蓝色,产品 = 红色),标注前 10 个客户 / 产品的名称(产品名截断); |
| 输出结果 | 生成隐向量TSNE可视化.png,可观察到 "相似客户 / 产品聚在一起" 的特征(如高消费客户与高价值产品靠近)。 |
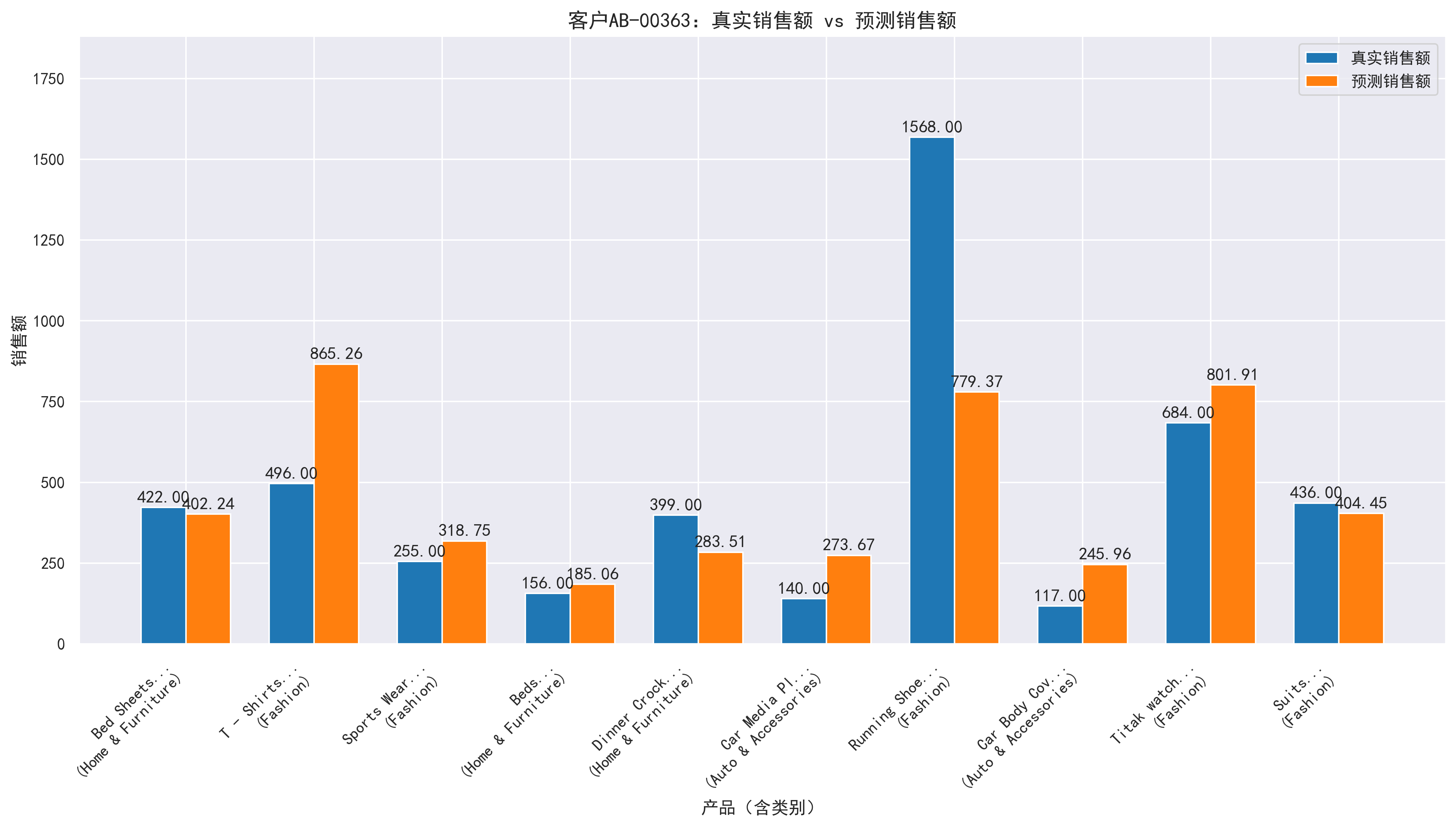
模块 11:单个客户预测可视化(个性化分析)
| 核心目标 | 聚焦单个客户,展示其购买产品的真实销售额与预测销售额对比 |
|---|---|
| 实现细节 | 定义plot_user_prediction函数: 1. 选取第一个客户(无交易则跳过); 2. 随机选 10 个该客户购买过的产品; 3. 提取每个产品的真实销售额、FunkSVD 预测销售额、产品类别; 4. 绘制分组柱状图(真实 = 蓝色,预测 = 橙色),标注具体数值,产品名截断并显示类别; |
| 输出结果 | 生成客户XXX销售额预测对比.png,直观展示单个客户的预测效果(如哪些产品预测更准确)。 |
模块 12:模型对比总结(最终结论)
| 核心目标 | 输出两种模型的 RMSE 对比,量化 FunkSVD 的提升效果 |
|---|---|
| 实现细节 | 打印截断 SVD 和 FunkSVD 的 RMSE,计算 FunkSVD 相比截断 SVD 的 RMSE 下降值; |
| 输出结果 | 打印最终对比结论(如FunkSVD 相比截断SVD 提升: 0.XXXX)。 |
四、电商销售额预测实战的Python代码完整实现
python
import os
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.decomposition import TruncatedSVD
from sklearn.metrics import mean_squared_error
from sklearn.manifold import TSNE
from sklearn.preprocessing import MinMaxScaler # 新增:销售额归一化工具
from math import sqrt
# --------------------------
# 可视化基础设置(彻底解决中文显示+样式优化)
# --------------------------
plt.rcParams['font.family'] = ['SimHei'] # 指定默认字体为黑体
plt.rcParams['font.sans-serif'] = ['SimHei'] # 中文支持
plt.rcParams['axes.unicode_minus'] = False # 负号显示
plt.rcParams['figure.figsize'] = (12, 8) # 默认图大小
plt.rcParams['font.size'] = 10 # 默认字体大小
sns.set_style("whitegrid") # 绘图风格
sns.set(font='SimHei') # 强制seaborn使用指定字体
# --------------------------
# 1. 加载电子商务数据集
# --------------------------
print("=== 加载电子商务数据集 ===")
df = pd.read_csv('E_commerce.csv', encoding='gbk', low_memory=False)
# --------------------------
# 清洗Sales列,转为纯数值
# --------------------------
def clean_sales_column(series):
"""清洗Sales列:移除$、空格、重复字符,转为float"""
series = series.astype(str).fillna('0')
series = series.str.replace(r'\$', '', regex=True)
series = series.str.replace(r'\s+', '', regex=True)
series = series.str.extract(r'(\d+\.?\d*)')[0]
series = pd.to_numeric(series, errors='coerce').fillna(0.0)
return series
# 应用清洗函数到Sales列
df['Sales'] = clean_sales_column(df['Sales'])
# --------------------------
# 销售额归一化(避免数值过大导致训练溢出)
# --------------------------
core_cols = ['Customer ID', 'Product', 'Product Category', 'Sales']
df_core = df[core_cols].copy()
# 销售额缩放到[0,1]区间(稳定训练数值)
scaler = MinMaxScaler(feature_range=(0, 1))
df_core['Sales_scaled'] = scaler.fit_transform(df_core[['Sales']])
# 聚合同一客户-产品的销售额(保留原始+缩放后的值)
df_core = df_core.groupby(
['Customer ID', 'Product', 'Product Category'],
as_index=False
).agg(
Sales=('Sales', 'sum'),
Sales_scaled=('Sales_scaled', 'sum')
)
# 加载产品信息(用于可视化)
products_df = df_core[['Product', 'Product Category']].drop_duplicates().reset_index(drop=True)
# 基础数据信息
print("\n=== 📊 电商数据基本信息 ===")
user_num = df_core['Customer ID'].nunique()
item_num = df_core['Product'].nunique()
interact_num = df_core.shape[0]
sparsity = 1 - interact_num / (user_num * item_num)
print(f"总客户数: {user_num}")
print(f"总产品数: {item_num}")
print(f"总交易记录数: {interact_num}")
print(f"客户-产品矩阵稀疏度: {sparsity:.4f}")
# --------------------------
# 2. 电商数据特征可视化(全量动态适配)
# --------------------------
def plot_ecommerce_features(df_core, products_df):
fig = plt.figure(figsize=(20, 15))
# 子图1:销售额分布直方图
ax1 = plt.subplot(2, 3, 1)
sns.histplot(df_core['Sales'], bins=30, kde=True, color='#1f77b4', edgecolor='black')
plt.title('产品销售额分布', fontsize=14, fontweight='bold')
plt.xlabel('销售额')
plt.ylabel('交易数量')
# 子图2:Top N高消费客户
ax2 = plt.subplot(2, 3, 2)
top_n_user = min(50, df_core['Customer ID'].nunique())
user_sales = df_core.groupby('Customer ID')['Sales'].sum().sort_values(ascending=False)[:top_n_user]
sns.barplot(x=user_sales.index.astype(str).tolist(), y=user_sales.values, color='#ff7f0e')
plt.title(f'Top {top_n_user} 高消费客户', fontsize=14, fontweight='bold')
plt.xlabel('客户ID')
plt.ylabel('总购买金额')
plt.xticks(rotation=90, fontsize=8)
# 子图3:Top N热销产品
ax3 = plt.subplot(2, 3, 3)
top_n_product = min(50, df_core['Product'].nunique())
product_sales = df_core.groupby('Product')['Sales'].sum().sort_values(ascending=False)[:top_n_product]
product_labels = []
show_name_num = min(10, len(product_sales))
for idx, product in enumerate(product_sales.index):
product_labels.append(product[:10] + '...' if idx < show_name_num else str(product))
sns.barplot(x=range(len(product_sales)), y=product_sales.values, color='#2ca02c')
plt.title(f'Top {top_n_product} 热销产品', fontsize=14, fontweight='bold')
plt.xlabel(f'产品(前{show_name_num}显示名称)')
plt.ylabel('总销售额')
plt.xticks(range(len(product_labels)), product_labels, rotation=90, fontsize=8)
# 子图4:客户-产品矩阵稀疏性热力图
ax4 = plt.subplot(2, 3, 4)
sample_user_num = min(100, df_core['Customer ID'].nunique())
sample_product_num = df_core['Product'].nunique()
if sample_user_num > 0 and sample_product_num > 0:
sample_users = np.random.choice(df_core['Customer ID'].unique(), sample_user_num, replace=False)
sample_products = np.random.choice(df_core['Product'].unique(), sample_product_num, replace=False)
sample_df = df_core[(df_core['Customer ID'].isin(sample_users)) & (df_core['Product'].isin(sample_products))]
sample_matrix = sample_df.pivot_table(index='Customer ID', columns='Product', values='Sales', fill_value=0)
sparse_matrix = (sample_matrix > 0).astype(int)
sns.heatmap(sparse_matrix, cmap='binary', cbar=True, ax=ax4, xticklabels=False, yticklabels=False)
plt.title(f'客户-产品矩阵稀疏性({sample_user_num}x{sample_product_num}采样)', fontsize=14, fontweight='bold')
plt.xlabel('产品')
plt.ylabel('客户ID')
# 子图5:产品类别的销售额占比饼图
ax5 = plt.subplot(2, 3, 5)
category_sales = df_core.groupby('Product Category')['Sales'].sum()
plt.pie(category_sales.values, labels=category_sales.index, autopct='%1.1f%%',
colors=sns.color_palette('tab10', len(category_sales)))
plt.title('各产品类别的销售额占比', fontsize=14, fontweight='bold')
# 子图6:Top N产品类别的平均销售额
ax6 = plt.subplot(2, 3, 6)
top_n_category = min(10, df_core['Product Category'].nunique())
category_mean_sales = df_core.groupby('Product Category')['Sales'].mean().sort_values(ascending=False)[
:top_n_category]
sns.barplot(x=category_mean_sales.index.tolist(), y=category_mean_sales.values, color='#17becf')
plt.title(f'Top {top_n_category} 产品类别的平均销售额', fontsize=14, fontweight='bold')
plt.xlabel('产品类别')
plt.ylabel('平均销售额')
plt.xticks(rotation=45)
plt.tight_layout()
plt.savefig('电商数据特征可视化.png', dpi=300, bbox_inches='tight')
plt.show()
# 绘制电商数据特征图
print("\n=== 🎨 绘制电商数据特征可视化图 ===")
plot_ecommerce_features(df_core, products_df)
# --------------------------
# 3. 数据预处理与拆分(构建用户-产品矩阵)
# --------------------------
train_df, test_df = train_test_split(df_core, test_size=0.2, random_state=42)
train_matrix = train_df.pivot_table(index='Customer ID', columns='Product', values='Sales', fill_value=0)
# 对齐测试集
test_df = test_df[
(test_df['Customer ID'].isin(train_matrix.index)) &
(test_df['Product'].isin(train_matrix.columns))
]
# --------------------------
# 4. 辅助函数:RMSE计算 + 不同k值调参
# --------------------------
def evaluate_rmse(test_df, pred_df):
actual = []
pred = []
for _, row in test_df.iterrows():
user = row['Customer ID']
item = row['Product']
actual.append(row['Sales'])
pred.append(max(0, pred_df.loc[user, item])) # 销售额非负
return sqrt(mean_squared_error(actual, pred))
def tune_k_value(train_matrix, test_df, k_list):
max_possible_k = min(train_matrix.shape[0], train_matrix.shape[1])
k_list = [k for k in k_list if k <= max_possible_k]
if not k_list:
k_list = [max_possible_k] if max_possible_k > 0 else [1]
rmse_list = []
for k in k_list:
svd = TruncatedSVD(n_components=k, random_state=42)
user_emb = svd.fit_transform(train_matrix)
item_emb = svd.components_
pred_matrix = np.dot(user_emb, item_emb)
pred_df = pd.DataFrame(pred_matrix, index=train_matrix.index, columns=train_matrix.columns)
rmse = evaluate_rmse(test_df, pred_df)
rmse_list.append(rmse)
print(f"k={k} 时 RMSE: {rmse:.4f}")
return k_list, rmse_list
# --------------------------
# 5. 模型训练可视化(截断SVD)
# --------------------------
print("\n=== 🔍 测试不同隐因子k值对截断SVD的影响 ===")
k_list = [5, 10, 20, 30, 40, 50, 60]
k_vals, rmse_vals = tune_k_value(train_matrix, test_df, k_list)
# 绘制k值与RMSE关系图
plt.figure(figsize=(12, 6))
plt.plot(k_vals, rmse_vals, marker='o', linewidth=2, markersize=8, color='#1f77b4')
best_k = k_vals[np.argmin(rmse_vals)]
plt.axvline(x=best_k, color='red', linestyle='--', label=f'最优k={best_k}')
plt.title('截断SVD:隐因子维度k与销售额预测RMSE关系', fontsize=14, fontweight='bold')
plt.xlabel('隐因子维度k')
plt.ylabel('测试集RMSE')
plt.grid(True, alpha=0.3)
plt.legend()
plt.savefig('k值调参曲线.png', dpi=300, bbox_inches='tight')
plt.show()
# 训练最终的截断SVD模型
print(f"\n=== 🚀 训练最终截断SVD模型(k={best_k}) ===")
svd = TruncatedSVD(n_components=best_k, random_state=42)
user_emb_svd = svd.fit_transform(train_matrix)
item_emb_svd = svd.components_
pred_matrix_svd = np.dot(user_emb_svd, item_emb_svd)
pred_df_svd = pd.DataFrame(pred_matrix_svd, index=train_matrix.index, columns=train_matrix.columns)
rmse_svd = evaluate_rmse(test_df, pred_df_svd)
print(f"截断SVD (k={best_k}) 测试集RMSE: {rmse_svd:.4f}")
# --------------------------
# 6. 带偏置的FunkSVD(适配电商销售额预测)
# --------------------------
class BiasFunkSVD:
"""带客户/产品偏置项的FunkSVD(适配归一化后的销售额)"""
def __init__(self, k=50, lr=0.0001, reg=0.05, epochs=50):
self.k = k
self.lr = lr # 缩小学习率(避免更新幅度过大)
self.reg = reg # 增大正则化(稳定训练)
self.epochs = epochs
self.global_mean = 0 # 归一化后的全局平均
self.user_bias = None
self.item_bias = None
self.user_vec = None
self.item_vec = None
self.user_id2idx = None
self.item_id2idx = None
self.loss_history = []
def fit(self, train_df):
self.global_mean = train_df['Sales_scaled'].mean() # 使用归一化后的销售额
users = sorted(train_df['Customer ID'].unique())
items = sorted(train_df['Product'].unique())
self.user_id2idx = {uid: i for i, uid in enumerate(users)}
self.item_id2idx = {iid: i for i, iid in enumerate(items)}
n_users = len(users)
n_items = len(items)
self.k = min(self.k, min(n_users, n_items))
# 缩小初始参数方差(避免初始值过大)
self.user_bias = np.zeros(n_users)
self.item_bias = np.zeros(n_items)
self.user_vec = np.random.normal(0, 0.01, (n_users, self.k))
self.item_vec = np.random.normal(0, 0.01, (n_items, self.k))
print("\n=== 🚀 训练带偏置的FunkSVD模型 ===")
for epoch in range(self.epochs):
total_loss = 0
train_df_shuffled = train_df.sample(frac=1, random_state=epoch)
for _, row in train_df_shuffled.iterrows():
u_idx = self.user_id2idx[row['Customer ID']]
i_idx = self.item_id2idx[row['Product']]
actual = row['Sales_scaled'] # 用归一化后的销售额训练
# 预测(归一化后的值)
pred = self.global_mean + self.user_bias[u_idx] + self.item_bias[i_idx]
pred += np.dot(self.user_vec[u_idx], self.item_vec[i_idx].T)
# 计算损失(数值范围稳定)
error = actual - pred
loss = error ** 2 + self.reg * (
self.user_bias[u_idx] ** 2 + self.item_bias[i_idx] ** 2 +
np.sum(self.user_vec[u_idx] ** 2) + np.sum(self.item_vec[i_idx] ** 2)
)
total_loss += loss
# 梯度更新(幅度更小)
self.user_bias[u_idx] += self.lr * (error - self.reg * self.user_bias[u_idx])
self.item_bias[i_idx] += self.lr * (error - self.reg * self.item_bias[i_idx])
self.user_vec[u_idx] += self.lr * (error * self.item_vec[i_idx] - self.reg * self.user_vec[u_idx])
self.item_vec[i_idx] += self.lr * (error * self.user_vec[u_idx] - self.reg * self.item_vec[i_idx])
self.loss_history.append(total_loss)
if (epoch + 1) % 10 == 0:
print(f"Epoch {epoch + 1}/{self.epochs} | 总损失: {total_loss:.4f}")
def predict(self, user_id, item_id):
if user_id not in self.user_id2idx or item_id not in self.item_id2idx:
# 冷启动:返回原始尺度的全局平均
scaled_mean = self.global_mean
return scaler.inverse_transform([[scaled_mean]])[0][0]
u_idx = self.user_id2idx[user_id]
i_idx = self.item_id2idx[item_id]
# 预测归一化后的值
pred_scaled = self.global_mean + self.user_bias[u_idx] + self.item_bias[i_idx]
pred_scaled += np.dot(self.user_vec[u_idx], self.item_vec[i_idx].T)
pred_scaled = max(0, pred_scaled) # 确保非负
# 转换回原始销售额尺度
return scaler.inverse_transform([[pred_scaled]])[0][0]
# 训练FunkSVD并绘制损失曲线
funksvd = BiasFunkSVD(k=best_k, lr=0.0001, reg=0.05, epochs=50)
funksvd.fit(train_df)
# 绘制FunkSVD训练损失曲线
plt.figure(figsize=(12, 6))
plt.plot(range(1, len(funksvd.loss_history) + 1), funksvd.loss_history,
marker='o', linewidth=2, color='#ff7f0e', label='训练损失')
plt.title('FunkSVD 训练损失曲线(归一化销售额)', fontsize=14, fontweight='bold')
plt.xlabel('迭代轮数')
plt.ylabel('总损失')
plt.grid(True, alpha=0.3)
plt.legend()
plt.savefig('FunkSVD损失曲线.png', dpi=300, bbox_inches='tight')
plt.show()
# --------------------------
# 7. 评估FunkSVD
# --------------------------
def evaluate_funksvd(test_df, model):
actual = []
pred = []
for _, row in test_df.iterrows():
actual.append(row['Sales'])
pred.append(model.predict(row['Customer ID'], row['Product']))
return sqrt(mean_squared_error(actual, pred)), actual, pred
rmse_funksvd, actual_sales, pred_sales = evaluate_funksvd(test_df, funksvd)
print(f"\n带偏置FunkSVD 测试集RMSE: {rmse_funksvd:.4f}")
# --------------------------
# 8. 第三部分:模型效果可视化
# --------------------------
def plot_model_performance(rmse_svd, rmse_funksvd, actual_sales, pred_sales):
fig = plt.figure(figsize=(20, 12))
# 子图1:模型RMSE对比柱状图
ax1 = plt.subplot(2, 2, 1)
models = ['截断SVD', '带偏置FunkSVD']
rmse_vals = [rmse_svd, rmse_funksvd]
sns.barplot(x=models, y=rmse_vals, hue=models, palette=['#1f77b4', '#ff7f0e'], legend=False)
plt.title('模型RMSE对比(销售额预测)', fontsize=14, fontweight='bold')
plt.ylabel('RMSE')
plt.ylim(0, max(rmse_vals) + max(rmse_vals) * 0.1)
for i, v in enumerate(rmse_vals):
plt.text(i, v + max(rmse_vals) * 0.01, f'{v:.4f}', ha='center', fontweight='bold')
# 子图2:真实vs预测销售额散点图
ax2 = plt.subplot(2, 2, 2)
sample_size = min(1000, len(actual_sales))
sample_idx = np.random.choice(len(actual_sales), sample_size, replace=False)
actual_sample = [actual_sales[i] for i in sample_idx]
pred_sample = [pred_sales[i] for i in sample_idx]
sns.scatterplot(x=actual_sample, y=pred_sample, alpha=0.6, color='#2ca02c')
max_val = max(max(actual_sample), max(pred_sample))
plt.plot([0, max_val], [0, max_val], 'r--', label='理想预测线')
plt.title('FunkSVD:真实销售额 vs 预测销售额', fontsize=14, fontweight='bold')
plt.xlabel('真实销售额')
plt.ylabel('预测销售额')
plt.xlim(0, max_val * 1.1)
plt.ylim(0, max_val * 1.1)
plt.legend()
# 子图3:预测误差分布
ax3 = plt.subplot(2, 2, 3)
errors = [actual_sales[i] - pred_sales[i] for i in sample_idx]
sns.histplot(errors, bins=20, kde=True, color='#d62728')
plt.axvline(x=0, color='black', linestyle='--', label='误差=0')
plt.title('FunkSVD:销售额预测误差分布', fontsize=14, fontweight='bold')
plt.xlabel('误差(真实-预测)')
plt.ylabel('数量')
plt.legend()
# 子图4:不同类别误差箱线图
ax4 = plt.subplot(2, 2, 4)
error_df = test_df.iloc[sample_idx].copy()
error_df['预测误差'] = [actual_sales[i] - pred_sales[i] for i in sample_idx]
sns.boxplot(x='Product Category', y='预测误差', data=error_df, hue='Product Category', palette='Set2', legend=False)
plt.axhline(y=0, color='black', linestyle='--')
plt.title('不同产品类别的销售额预测误差', fontsize=14, fontweight='bold')
plt.xlabel('产品类别')
plt.ylabel('预测误差')
plt.xticks(rotation=45)
plt.tight_layout()
plt.savefig('模型效果可视化.png', dpi=300, bbox_inches='tight')
plt.show()
print("\n=== 🎨 绘制模型效果可视化图 ===")
plot_model_performance(rmse_svd, rmse_funksvd, actual_sales, pred_sales)
# --------------------------
# 9. 第四部分:隐向量可视化(TSNE降维)
# --------------------------
def plot_embedding_tsne(user_emb, item_emb, user_ids, item_ids, top_n=50):
top_n = min(top_n, len(user_ids), item_emb.shape[1])
if top_n < 2:
print("⚠️ 样本数不足,跳过TSNE可视化")
return
user_emb_sample = user_emb[:top_n]
item_emb_sample = item_emb[:, :top_n].T
perplexity = min(15, top_n - 1)
tsne = TSNE(n_components=2, random_state=42, perplexity=perplexity)
all_emb_tsne = tsne.fit_transform(np.vstack([user_emb_sample, item_emb_sample]))
user_tsne = all_emb_tsne[:top_n]
item_tsne = all_emb_tsne[top_n:]
plt.figure(figsize=(14, 10))
plt.scatter(user_tsne[:, 0], user_tsne[:, 1], c='blue', label='客户', alpha=0.7, s=50)
plt.scatter(item_tsne[:, 0], item_tsne[:, 1], c='red', label='产品', alpha=0.7, s=50)
annotate_num = min(10, top_n)
for i in range(annotate_num):
plt.annotate(f'客户{user_ids[i]}', (user_tsne[i, 0], user_tsne[i, 1]), fontsize=9)
plt.annotate(f'产品{item_ids[i][:8]}...', (item_tsne[i, 0], item_tsne[i, 1]), fontsize=9)
plt.title(f'客户/产品隐向量TSNE降维可视化(Top {top_n})', fontsize=14, fontweight='bold')
plt.xlabel('TSNE维度1')
plt.ylabel('TSNE维度2')
plt.legend()
plt.grid(True, alpha=0.2)
plt.savefig('隐向量TSNE可视化.png', dpi=300, bbox_inches='tight')
plt.show()
print("\n=== 🎨 绘制隐向量TSNE可视化图 ===")
user_ids = train_matrix.index.values
item_ids = train_matrix.columns.values
plot_embedding_tsne(user_emb_svd, item_emb_svd, user_ids, item_ids, top_n=50)
# --------------------------
# 10. 第五部分:单个客户的销售额预测可视化
# --------------------------
def plot_user_prediction(sample_user, df_core, funksvd, products_df):
user_trans = df_core[df_core['Customer ID'] == sample_user]
if len(user_trans) == 0:
print(f"⚠️ 客户{sample_user}无交易记录,跳过")
return
select_num = min(10, len(user_trans))
user_products = user_trans['Product'].sample(select_num, random_state=42).values
real_sales = []
pred_sales = []
product_info = []
for product in user_products:
real = user_trans[user_trans['Product'] == product]['Sales'].values[0]
pred = funksvd.predict(sample_user, product)
category = products_df[products_df['Product'] == product]['Product Category'].values[0]
product_info.append(f"{product[:12]}...\n({category})")
real_sales.append(real)
pred_sales.append(pred)
plt.figure(figsize=(14, 8))
x = np.arange(len(product_info))
width = 0.35
plt.bar(x - width / 2, real_sales, width, label='真实销售额', color='#1f77b4')
plt.bar(x + width / 2, pred_sales, width, label='预测销售额', color='#ff7f0e')
plt.title(f'客户{sample_user}:真实销售额 vs 预测销售额', fontsize=14, fontweight='bold')
plt.xlabel('产品(含类别)')
plt.ylabel('销售额')
plt.xticks(x, product_info, rotation=45, ha='right')
plt.ylim(0, max(max(real_sales), max(pred_sales)) * 1.2)
plt.legend()
max_val = max(max(real_sales), max(pred_sales))
for i in range(len(x)):
plt.text(x[i] - width / 2, real_sales[i] + max_val * 0.01, f'{real_sales[i]:.2f}', ha='center')
plt.text(x[i] + width / 2, pred_sales[i] + max_val * 0.01, f'{pred_sales[i]:.2f}', ha='center')
plt.tight_layout()
plt.savefig(f'客户{sample_user}销售额预测对比.png', dpi=300, bbox_inches='tight')
plt.show()
print("\n=== 🎨 绘制单个客户销售额预测对比图 ===")
if len(df_core['Customer ID'].unique()) > 0:
sample_user = df_core['Customer ID'].unique()[0]
plot_user_prediction(sample_user, df_core, funksvd, products_df)
else:
print("⚠️ 无客户数据,跳过")
# --------------------------
# 11. 模型对比总结
# --------------------------
print("\n=== 📝 模型效果最终对比 ===")
print(f"截断SVD RMSE: {rmse_svd:.4f}")
print(f"带偏置FunkSVD RMSE: {rmse_funksvd:.4f}")
print(f"FunkSVD 相比截断SVD 提升: {(rmse_svd - rmse_funksvd):.4f}")五、程序运行结果展示
=== 加载电子商务数据集 ===
=== 📊 电商数据基本信息 ===
总客户数: 795
总产品数: 42
总交易记录数: 20425
客户-产品矩阵稀疏度: 0.3883
=== 🎨 绘制电商数据特征可视化图 ===
=== 🔍 测试不同隐因子k值对截断SVD的影响 ===
k=5 时 RMSE: 439.9350
k=10 时 RMSE: 500.2656
k=20 时 RMSE: 529.3775
k=30 时 RMSE: 536.6351
k=40 时 RMSE: 538.8738
=== 🚀 训练最终截断SVD模型(k=5) ===
截断SVD (k=5) 测试集RMSE: 439.9350
=== 🚀 训练带偏置的FunkSVD模型 ===
Epoch 10/50 | 总损失: 23461.2419
Epoch 20/50 | 总损失: 19804.3852
Epoch 30/50 | 总损失: 18474.5425
Epoch 40/50 | 总损失: 17916.4201
Epoch 50/50 | 总损失: 17635.3735
带偏置FunkSVD 测试集RMSE: 256.5168
=== 🎨 绘制模型效果可视化图 ===
=== 🎨 绘制隐向量TSNE可视化图 ===
=== 🎨 绘制单个客户销售额预测对比图 ===
=== 📝 模型效果最终对比 ===
截断SVD RMSE: 439.9350
带偏置FunkSVD RMSE: 256.5168
FunkSVD 相比截断SVD 提升: 183.4181
六、总结
本文基于电商交易数据,通过矩阵分解方法实现客户-产品销售额预测。研究采用截断SVD和带偏置FunkSVD两种模型,构建了完整的数据分析流程:从数据清洗、特征可视化到模型训练评估。实验结果显示,FunkSVD(RMSE=256.52)相比截断SVD(RMSE=439.94)预测精度显著提升183.42。通过多维度可视化分析,验证了FunkSVD在误差分布和类别预测上的优势,为电商销售预测提供了有效的解决方案。