展示了人脸控制的基本流程:首先,从"目标"图片或视频中提取出表情和动作特征,然后将这些特征应用到"源"图片中,从而生成具有相同表情和动作的图片或视频。

人脸控制伪造视频的示意图。图片来源:Zakharov 2019.
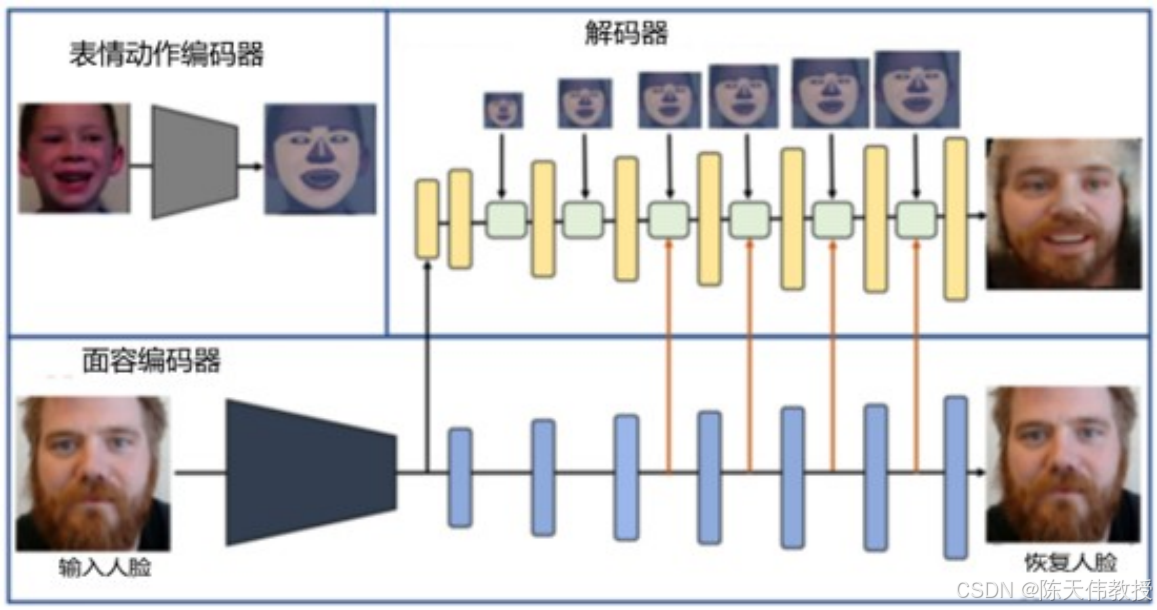
展示了一个人脸控制模型的结构。左上的"表情动作编码器"负责提取表情和动作特征,左下的"面容编码器"负责提取面部的外观特征。最后,右上的解码器将这两部分信息结合,生成带有表情和动作的合成图片或视频。
人脸控制模型结构图。图片来源:Zhang et al., 2019
展示了人脸控制的基本流程:首先,从"目标"图片或视频中提取出表情和动作特征,然后将这些特征应用到"源"图片中,从而生成具有相同表情和动作的图片或视频。
人脸控制伪造视频的示意图。图片来源:Zakharov 2019.
展示了一个人脸控制模型的结构。左上的"表情动作编码器"负责提取表情和动作特征,左下的"面容编码器"负责提取面部的外观特征。最后,右上的解码器将这两部分信息结合,生成带有表情和动作的合成图片或视频。
人脸控制模型结构图。图片来源:Zhang et al., 2019