Redis最主要三个用途:
1)存储数据(内存数据库)
2)缓存(redis常见场景)
3)消息队列
1.缓存简介
把常用数据放到访问速度更快的地方,这个地方就是缓存;
最常见的是内存作为硬盘的缓存(redis定位);
缓存容量是通常不足,只能放一些热点数据,二八定律;
2.使用场景
通常是使用redis作为数据库的缓存;
如何提高mysql能承担的并发量?
1)开源:引入更多的机器,构成数据库集群;
2)节流:引入缓存,频繁访问的数据放到缓存中,缓存中有了,就不用访问数据库了;

3.缓存更新策略(重点)
1.定期生成
每隔一段时间,更新缓存;
数据哪里来?通过日志统计,然后数据分析而来;
- 优点:实现起来比较简单,过程更可控(缓存有什么是可以确定的);
- 缺点:实时性不足,当遇到一些突发事件,平时不常用的词成热词了,这个热词因为更新不及时,缓存命中不了,从而导致数据库压力过大
2.实时生成
如果在redis查到了,就直接返回;没有查到,从数据库查,查到结果也写入Redis;
但是缓存容量是有上限的,因此需要制定缓存淘汰策略;
1)FIFO,先进先出,队列
2)LRU,最久未使用
3)LFU,最近最少访问次数
4)Random,随机淘汰




4.缓存常见问题
1.缓存预热(Cache preheating)
把定期生成和实时生成结合,先统计处高频key,然后导入,避免mysql压力过大。
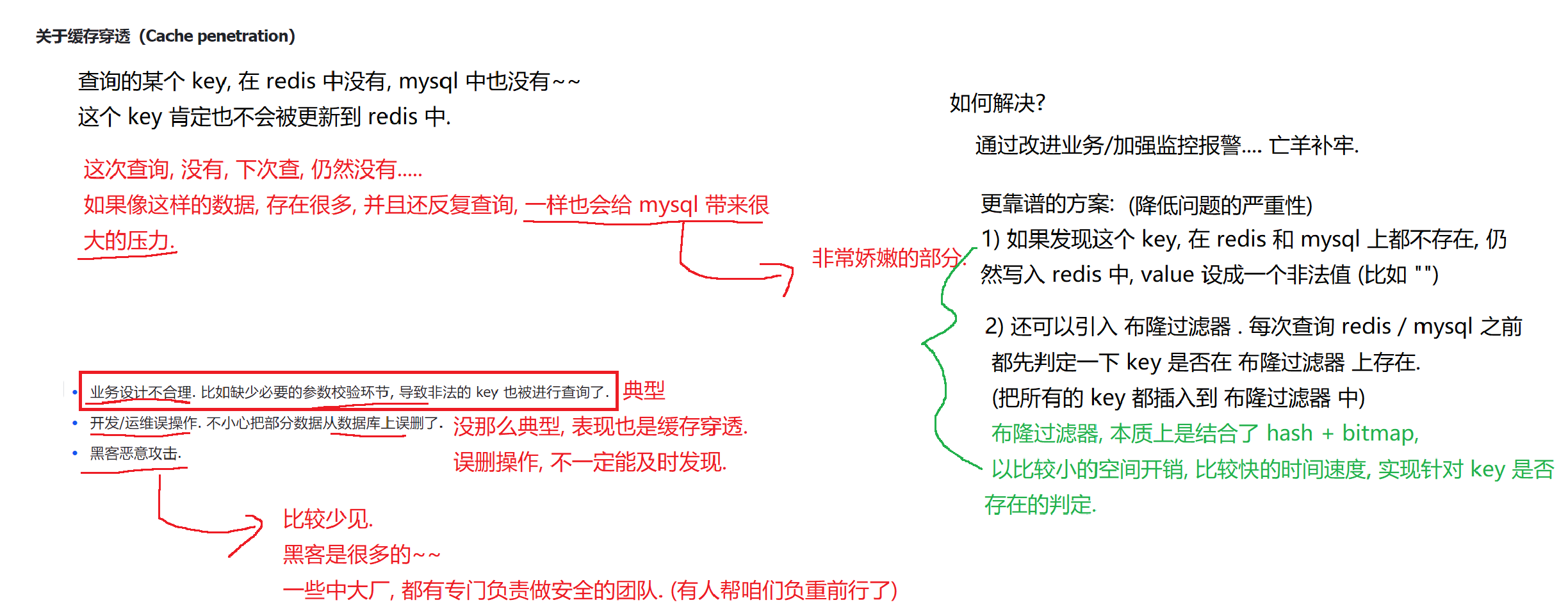
2.缓存穿透(Cache penetration)查询的某个key,在redis中没有,mysql中也没有;这个key不会被更新到redis中;
核心问题:如果说这个key后续还要被反复查询,会给mysql带来很大的压力;
发生场景:
1)业务设计不合理
2)开发/运维误操作,把部分数据从数据库上删除了
3)黑客恶意攻击
如何解决:
1)改进业务/加强监控报警,亡羊补牢
更靠谱的方案:
1)如果发现这个key在redis和mysql都不存在,仍然写入redis中,value设置成非法值;
2)引入布隆过滤器,每次查询redis/mysql之前都先判断一下存在性;**3.缓存雪崩(Cache avalanche)**短时间内,redis上大规模的key失效,导致缓存命中率陡然下降,mysql压力迅速上升,甚至宕机;
发生场景:
1)redis挂了
2)redis正常,但是短时间设置了大量key过期时间相同
解决:
1)加强监控报警,加强redis集群可用性
2)不给key设置过期时间 / 设置的过期时间添加随机因子4.缓存击穿(Cache breakdown)
热点key突然过期,导致大量请求直接访问数据库,甚至引起数据库宕机;
解决:
1)基于统计的方式发现热点key,设置成永不过期;
2)必要时进行服务降级,访问数据库使用分布式锁,限制同时访问数据库的并发数;