大学院-筆記試験練習:线性代数和数据结构(19)
- 1-前言
- 2-线性代数-题目
- 3-线性代数-参考答案
- 4-数据结构-题目
- 5-数据结构-参考答案
- 【問題1】二分探索木と探索順【解答】
- 【問題2】グラフ表現と探索の性質【解答】
- 【問題3】スタックと再帰処理【解答】
- 【問題4】計算量とデータ構造の選択【解答】
- 6-总结
1-前言
为了升到自己目标的大学院,所作的努力和学习,这里是线性代数和数据结构部分。
2-线性代数-题目




3-线性代数-参考答案
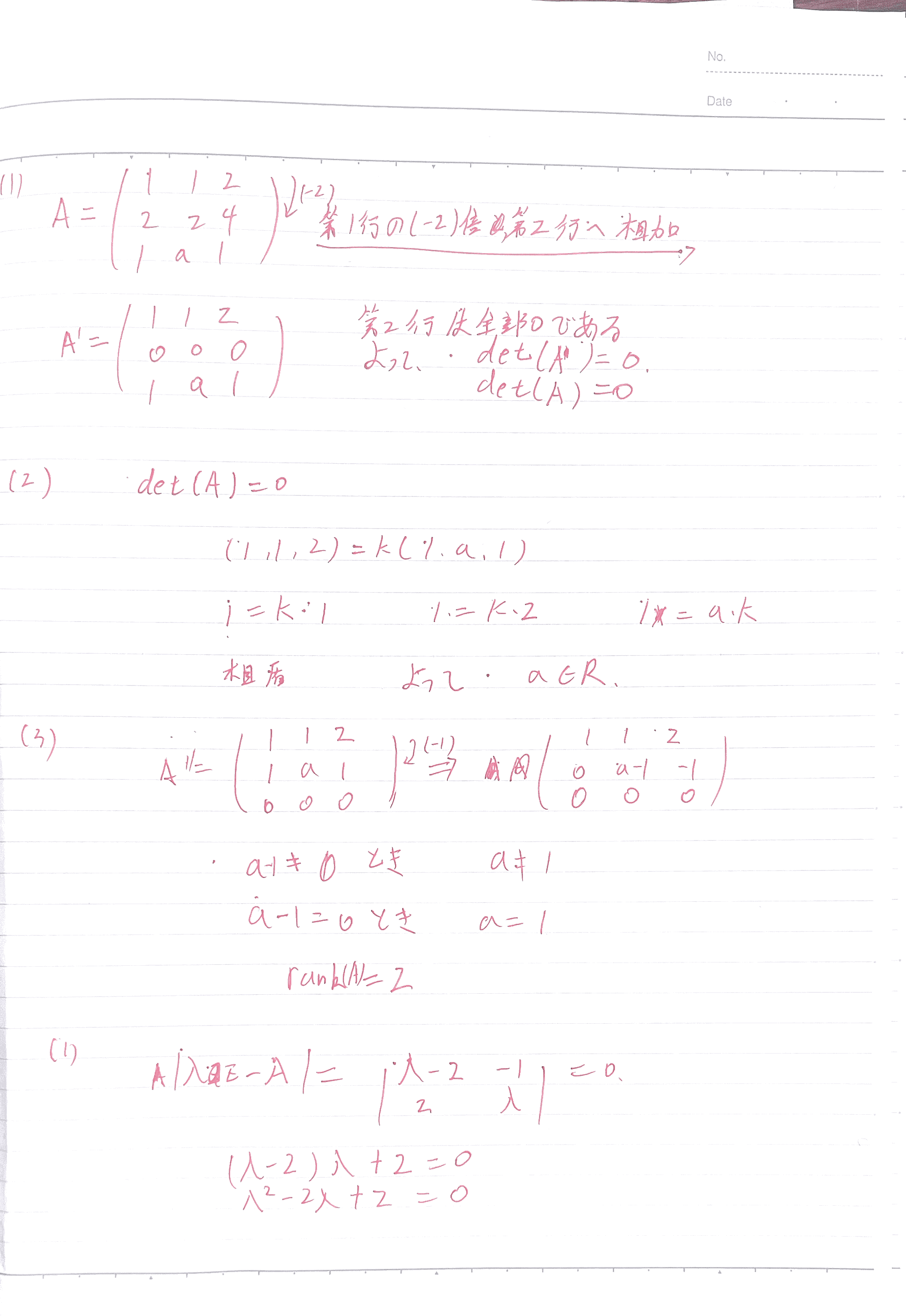
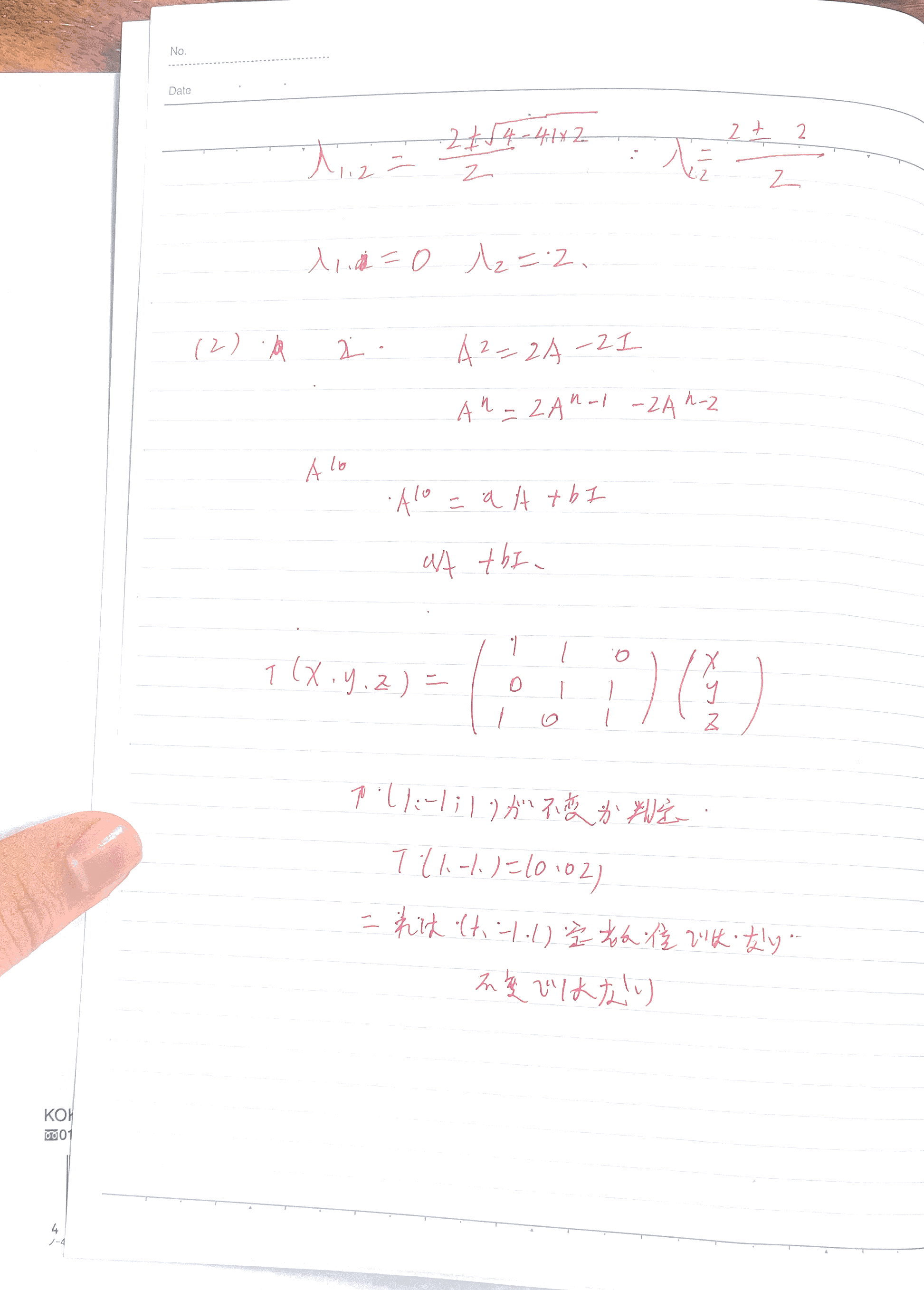
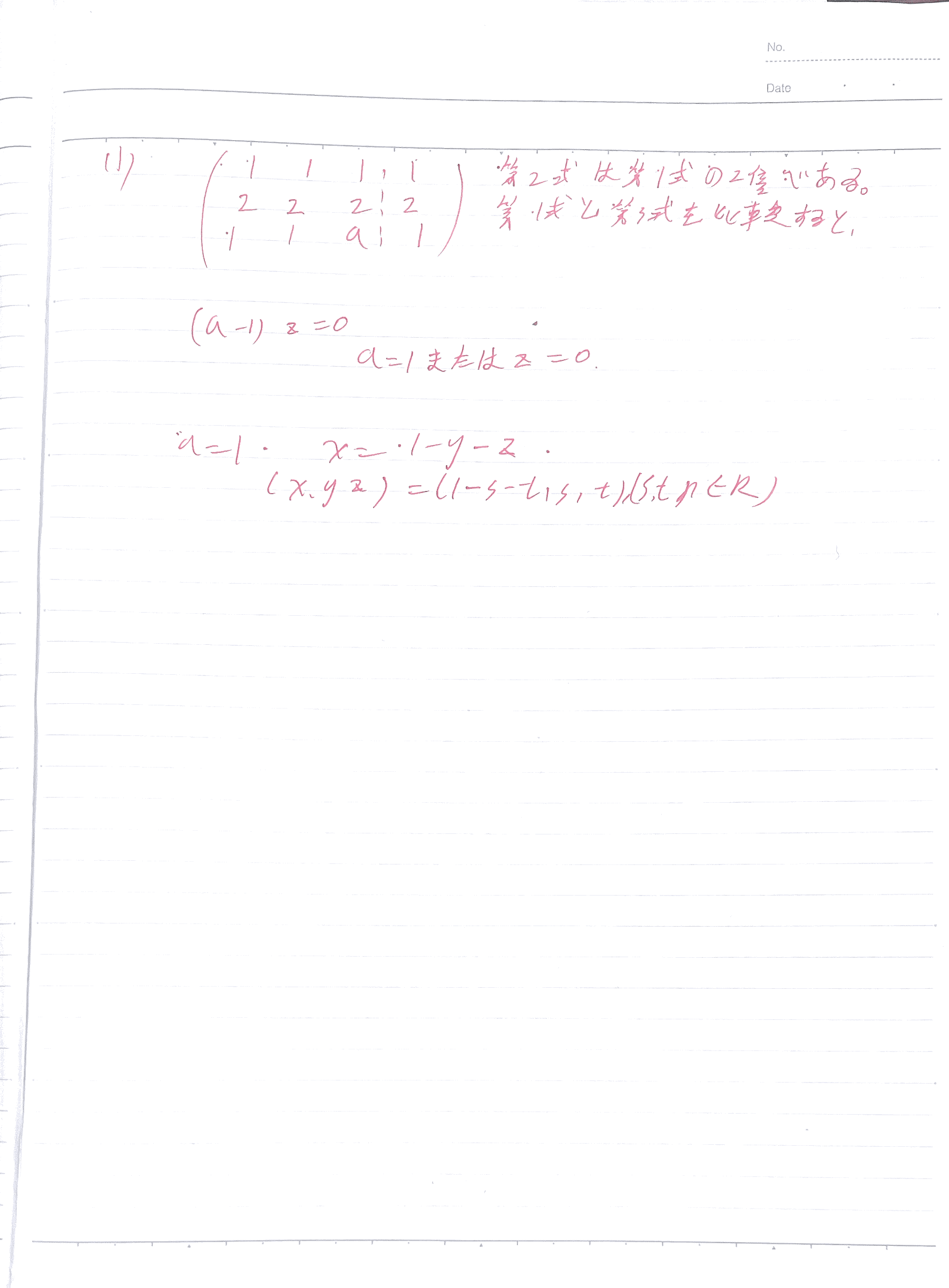
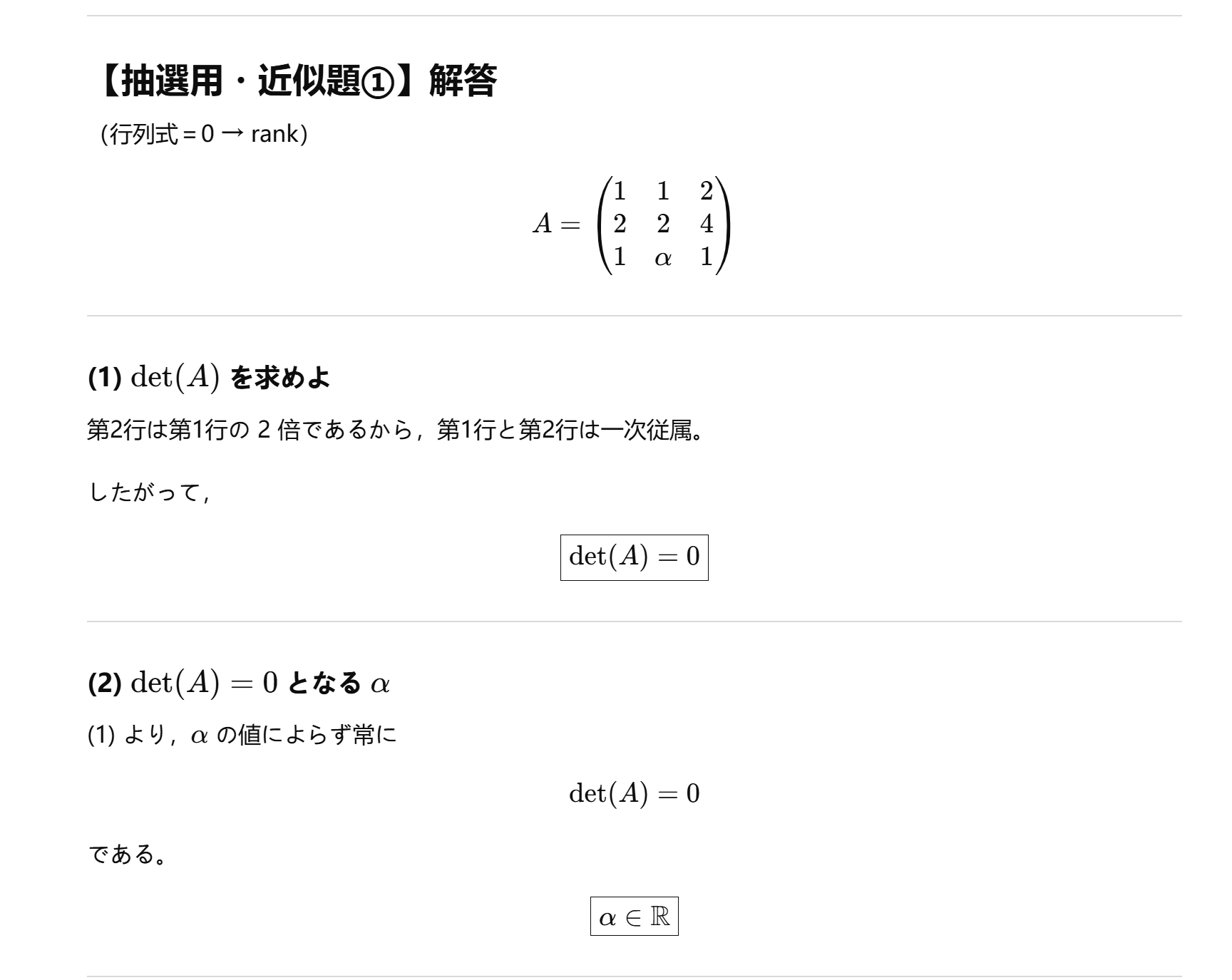




4-数据结构-题目
【問題1】二分探索木と探索順(模拟)
整数値を格納する二分探索木を考える。
各節点は 1 つの整数値を保持し,左部分木にはその値より小さい要素,右部分木には大きい要素のみを格納するものとする。
同じ値は挿入されない。
(1)
数列
S={15, 6, 23, 4, 7, 71, 5}
を先頭から順に挿入したときに得られる二分探索木を図示せよ。
(2)
(1) で得られた木に対して,
「節点 → 左部分木 → 右部分木」の順で訪問する操作を行ったとき,
出力される値を順に示せ。
(3)
挿入される数列が昇順に与えられる場合,
この二分探索木への挿入処理全体の最悪時間計算量を,
要素数 (n) を用いてオーダー表記で答えよ。
【問題2】グラフ表現と探索の性質(模拟)
連結な有向グラフ (G=(V,E)) を考える。
頂点数を (n),辺数を (m) とする。
(1)
グラフを隣接行列で表現した場合,
ある 1 つの頂点に隣接するすべての頂点を列挙するために要する時間計算量を答えよ。
(2)
同じグラフを隣接リストで表現した場合の空間計算量を,
(n,m) を用いてオーダー表記で答えよ。
(3)
幅優先探索(BFS)と深さ優先探索(DFS)に共通して,
必ず成り立つ性質を 1 つ挙げ,簡潔に説明せよ。
【問題3】スタックと再帰処理(预测)
次のような再帰関数を考える。
func(n):
if n <= 0:
return
func(n-1)
出力 n(1)
この関数を func(3) として呼び出したとき,
出力される値の順序を示せ。
(2)
この処理を再帰を用いずに実現するためには,
どのようなデータ構造を用いればよいか答えよ。
(3)
(2) で用いるデータ構造が必要となる理由を,
関数呼び出しの性質に着目して説明せよ。
【問題4】計算量とデータ構造の選択(预测)
要素数 (n) のデータ集合に対して,
次の操作を頻繁に行う必要がある。
- 要素の追加
- 最小要素の取り出し
(1)
これらの操作を効率よく行うために適したデータ構造を 1 つ挙げよ。
(2)
(1) で挙げたデータ構造を用いた場合,
各操作の時間計算量をオーダー表記で答えよ。
(3)
配列を用いた単純な実装と比較した場合の利点を,
計算量の観点から簡潔に述べよ。
5-数据结构-参考答案


【問題1】二分探索木と探索順【解答】
(1)
数列
S={15, 6, 23, 4, 7, 71, 5}
を先頭から順に挿入すると,得られる二分探索木は次のとおりである。
15
/ \
6 23
/ \ \
4 7 71
\
5(2)
訪問順が「節点 → 左部分木 → 右部分木」であるため,
出力される値の順序は次のとおりである。
15,\\ 6,\\ 4,\\ 5,\\ 7,\\ 23,\\ 71
(3)
挿入される数列が昇順に与えられる場合,
二分探索木は片側にのみ伸び,高さが (n) となる。
よって,挿入処理を (n) 回行うときの最悪時間計算量は
O(n\^2)
である。
【問題2】グラフ表現と探索の性質【解答】
(1)
隣接行列では,ある 1 つの頂点に隣接するすべての頂点を列挙するには,
対応する行(または列)の全要素を調べる必要がある。
したがって時間計算量は
O(n)
である。
(2)
隣接リストでは,頂点数分のリストと,辺数分の要素を保持するため,
空間計算量は
O(n+m)
である。
(3)
幅優先探索および深さ優先探索では,
各頂点は高々 1 回だけ訪問され,
最終的にすべての到達可能な頂点が探索される。
【問題3】スタックと再帰処理【解答】
(1)
func(3) を実行したとき,出力される値の順序は
1,\\ 2,\\ 3
である。
(2)
再帰を用いずに同じ処理を実現するためには,
スタック(LIFO 構造) を用いればよい。
(3)
再帰呼び出しでは,関数の呼び出し順序と戻り順序を管理する必要がある。
この管理はスタック構造によって実現されているため,
再帰処理を明示的に実装する際にもスタックが必要となる。
【問題4】計算量とデータ構造の選択【解答】
(1)
これらの操作を効率よく行うために適したデータ構造として,
ヒープ(優先度付きキュー) が挙げられる。
(2)
ヒープを用いた場合,
- 要素の追加:(O(\log n))
- 最小要素の取り出し:(O(\log n))
である。
(3)
配列を用いた単純な実装では,
最小要素の探索に (O(n)) の時間を要する。
一方,ヒープを用いることで,
これらの操作を対数時間で行うことが可能となり,
計算量の点で優れている。
6-总结
训练成长。!!