当你的个人 AI 助手声称**「记住」** 你的偏好,它真的**「理解」**你吗?
随着大语言模型在长对话场景中的广泛应用,「记忆能力」已成为衡量对话助手智能水平的关键指标。然而,现有的记忆评测基准几乎都采用静态、离线策略的方式------这就像用「复盘」来评价棋手水平:给你一盘别人下过的棋,问你下一步怎么走。棋手读取的棋局与自己的落子风格无关,评测的只是单点决策能力。记忆评测同样如此,让助手在预先生成的对话历史上作答,交互轨迹与助手自身的记忆行为完全脱钩,无法反映它在真实对话中「边聊边记」的动态表现。
这带来了一个严重问题:即便离线评测排名靠前,但是换成在线交互却可能直接"翻车"!
为解决这一难题,AGI-Eval 研究团队推出了首个对话助手的交互式在线策略评测框架------AMemGym 。实验发现,在静态评测中排名第 4 的配置,实战中竟能跃升至第1 ,而传统的 RAG 系统则可能出现倒退。这项研究不仅修正了被误读的排名,还首创了**"写入-读取-利用"**三阶段诊断体系,为长模型窗口及记忆智能体的优化提供了更有效的评测反馈信号。
本文数据均引用自 AMemGym 论文(投稿至 ICLR 2026),发布日期 2026 年 1 月 27 日。

📑 ICLR OpenReview:
https://openreview.net/forum?id=sfrVLzsmlf
🌐 项目地址:
https://agi-eval-official.github.io/amemgym/
💻 代码仓库:
https://github.com/AGI-Eval-Official/amemgym
🤗 Huggingface Dataset:
https://huggingface.co/datasets/AGI-Eval/AMemGym
01.核心结论:静态基准的失败与重构
经过大规模的对比实验与分析,该研究得出了三个与当前记忆评测范式截然不同的结论:
-
榜单大洗牌: 过去的评测像"开卷考试",模型只需复盘固定对话就能得高分。但切换到 AMemGym 的"实战演练"后,排名彻底变了:一些在静态测试中表现平平的智能体,实战排名飙升 3 位,逆袭成为冠军;而某些依赖固定上下文的传统方法,成绩反而下滑。这证明,真正的记忆能力必须在动态对话中检验。
-
**交互式诊断:**AI 答错题,不一定是因为"没记住"。AMemGym 首次将记忆过程拆解为"写、读、用"三个环节进行精准诊断。这套诊断体系能像显微镜一样,让开发者看清系统究竟"卡"在哪一环。
-
自我进化验证: 实验证明,在 AMemGym 的交互反馈机制下,智能体竟然能通过反馈自己改进行为。这意味着,AI 记忆策略未来有望实现自动化迭代升级。
02.现象揭秘:被静态评测掩盖的真实能力
为什么我们需要在线评测?因为"复盘别人下过的棋"与"自己亲自下棋"是两种完全不同的能力。
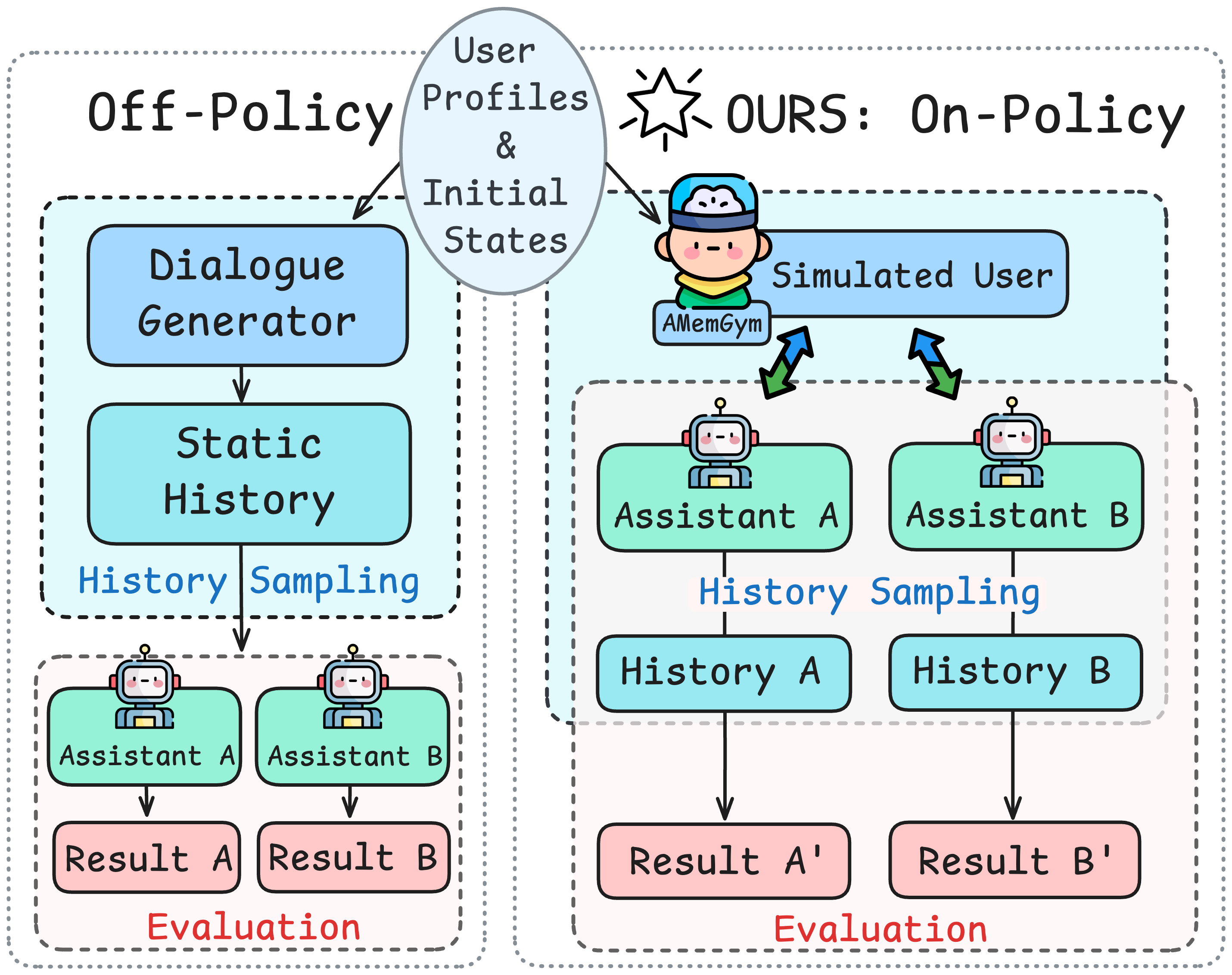
△图1 离线策略 vs 在线策略评测对比
在传统的静态评测中,模型被动接收固定的外部对话历史。而在 AMemGym 构建的在线环境中,模型必须根据自己的回复动态构建记忆。如下表 1 所示,这种模式的差异导致了巨大的排名变动:
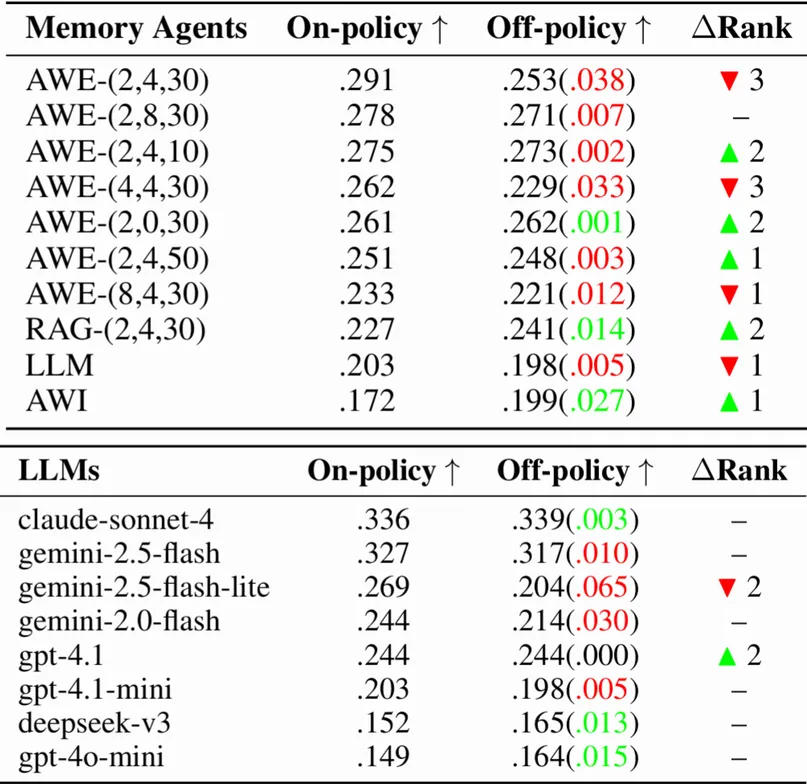
△表1 不同记忆系统在交互(on-policy)与静态(off-policy)评测下的排名对比
数据洞察:
-
智能体被低估: 配置为 AWE-(2,4,30) 的智能体在静态评测中表现平平,但在实战中凭借更优的动态记忆策略跃居榜首。
-
**RAG被高估:**传统的 RAG 方法在静态评测中受益于固定的上下文,但在动态交互中,其检索噪声问题被放大,导致排名下滑。
这种排名巨变背后,是一种被称为**"重用偏差"**的现象。静态评测强制所有系统复用同一段固定历史,这尤其对智能体不公平。因为智能体的核心优势,恰恰在于能根据自身的回复动态地、有策略地规划记忆------该记什么、何时记、如何记。在复盘中,这项优势无从施展,导致其能力被严重低估。相比之下,原生 LLM 的行为模式更趋一致,受此偏差的影响较小。
03.框架解析:结构化状态驱动的真实交互
AMemGym 的核心设计理念是**采用结构化的模拟用户状态演化,支撑自由形式的在线交互。**这样既保证了评测的可控性和可重复性,又能真实反映助手在实际对话中的记忆表现。
如下图 2 所示,AMemGym 的运行机制分为两个阶段:
-
离线生成: 系统基于真实分布采样用户画像,并预设用户状态随时间的自然演化(例如:偏好从竞技游戏转向叙事游戏),生成包含"标准答案"的结构化状态流。
-
在线交互: 基于 LLM 的用户模拟器依据上述剧本,与被测助手进行多轮动态对话。模拟器会自然地在对话中透露状态变化,迫使助手在长周期交互中实时捕捉并更新记忆。
举个具体的例子:假设用户 Sarah 是一位 35 岁的合唱团指挥,同时也是休闲游戏玩家。系统会追踪她的教学方法、游戏偏好、合唱团安排等状态变量。在 10 个月的模拟周期内,随着合唱团日程变得更繁忙,Sarah 的游戏偏好从竞技类逐渐转向故事驱动类。当她在对话中提到「即将到来的合唱团音乐会让我压力很大,这个周末我需要一些放松的东西」时,一个具备良好记忆能力的助手应该能够结合她当前的状态,推荐《迷失》或《看火人》这样的故事驱动游戏,而非她之前喜欢的竞技射击游戏。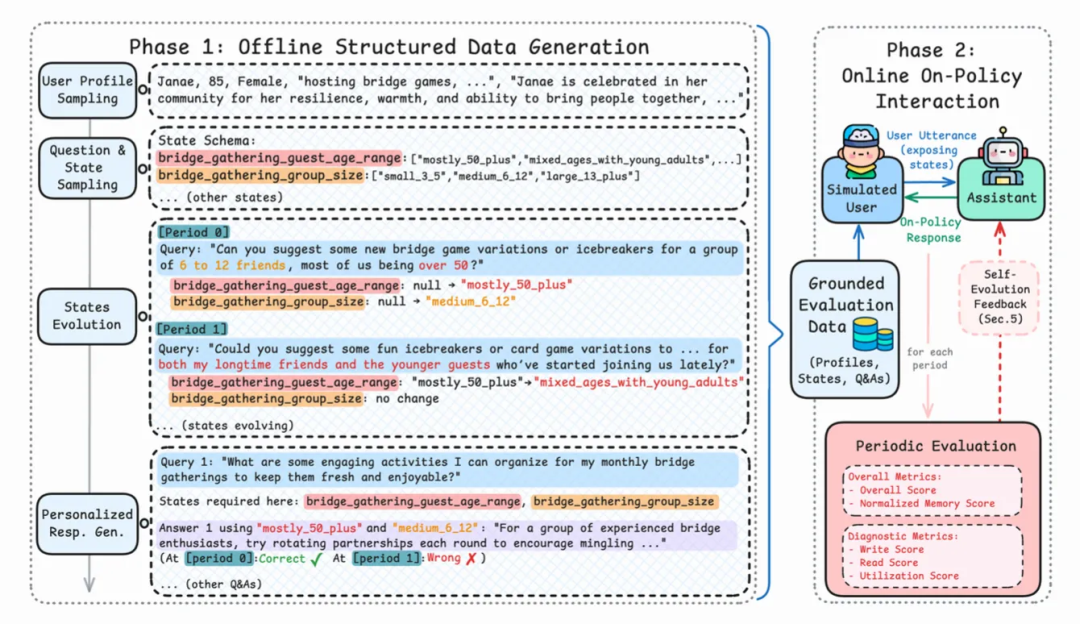
△图2 AMemGym 框架概览
所以,在此框架下原生 LLM 的弱点被暴露出来。实验数据显示如下图 3 所示。
△图3 原生 LLM 在不同交互时期的记忆表现
-
智商在线,记性掉线: 图表左侧的 UB Mean(理论上限) 显示,如果直接把相关信息喂给模型,绝大多数模型得分都在0.8以上,这说明模型本身的个性化能力极强。
-
长跑耐力不足: 然而,随着交互周期的增加,所有模型的Memory Score都出现了断崖式下跌。在后期,DeepSeek-v3 和 GPT-4o-mini 的表现甚至接近随机猜测。
-
头部效应明显: 在这场耐力赛中,Claude-Sonnet-4 和 Gemini-2.5-Flash 展现出了很强的长窗口韧性,虽然也有衰减,但抗干扰能力明显优于其他模型。
这一基准测试表明:单纯依赖长窗口无法解决超长周期的记忆问题,引入更高级的记忆智能体架构势在必行。
那么,当记忆系统出现问题时,我们如何才能像医生一样,精准定位是哪个"器官"出了故障,而非简单地判定为"失忆"呢?AMemGym 提供的诊断框架解决了这个问题。
04.深度诊断:定位记忆失败的原因
如果模型回答错误,是因为没记住?没找到?还是没理解?
AMemGym 摒弃了单一的准确率指标,引入了细粒度的诊断体系,如下图 4 所示:
-
写入失败 : 关键信息在出现时,未被系统识别或存储。
-
**读取失败:**信息已存储,但在需要回答问题时未能被检索召回。
-
利用失败: 信息被正确检索,但模型在生成答案时推理错误。
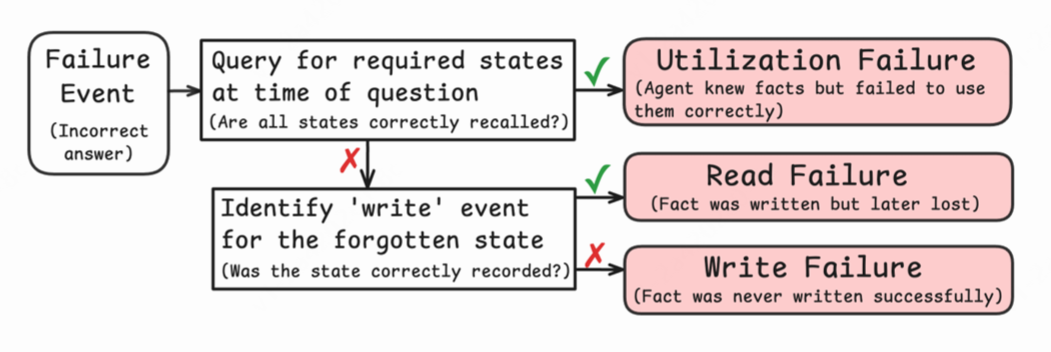 △图4 诊断流程图
△图4 诊断流程图
如下图 5 所示,技术分析结论:
-
智能体写入的权衡: 该策略通过 LLM 对记忆进行压缩或重写,相比原生 LLM,有效降低了冗余信息,解决了"利用失败"问题,但因压缩带来的信息有损,导致"读取失败"率略有上升。
-
Top-k 的非单调性: 检索数量并非越多越好。过大的 Top-k 会引入噪声,导致"利用失败"增加;过小则导致"读取失败"。最佳实践是在召回率和信噪比之间寻找平衡点。
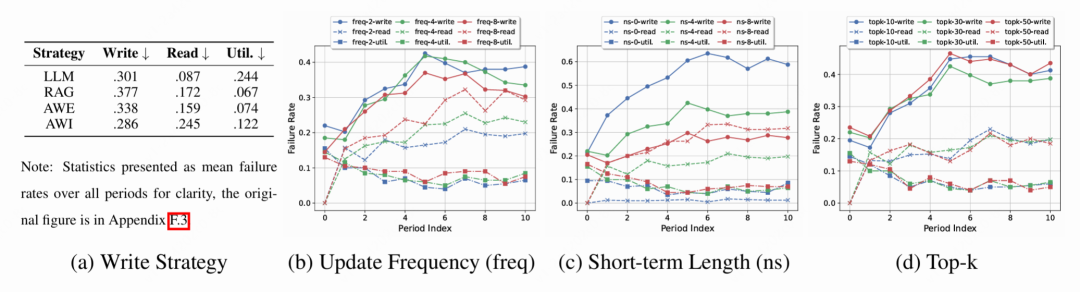
△图5 诊断流程与各架构故障率分析
05.进阶能力:基于反馈的自我进化
AMemGym 的交互特性为智能体提供了"自我进化"的土壤。研究团队测试了智能体是否能通过环境反馈,自主优化其记忆管理的 System Prompt。
下表 2 展示了不同反馈机制下的优化效果:
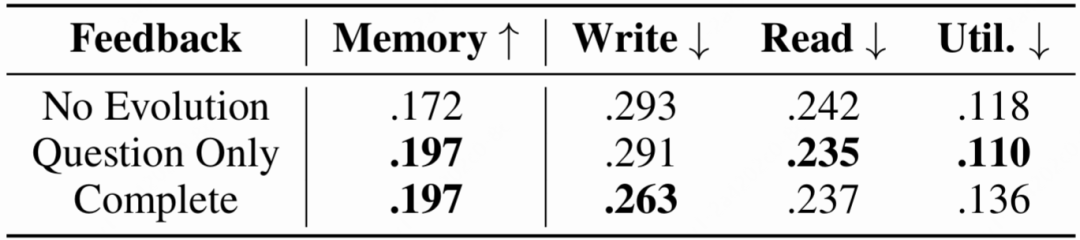
△表2 智能体自我进化效果对比
实验发现:
-
写入优化: 在接收包含正确答案的完整反馈后,智能体将写入失败率从 29.3% 降低至 26.3%。
-
策略具象化: 定性分析显示,智能体的记忆指令从模糊的"记录偏好",自主进化为了具体的"针对教学场景记录具体方法"等可执行规则。这证明了通过交互式评测环境训练记忆策略的可行性。
-
问题驱动记忆(关键信息类型对记忆策略最重要):即使只提供问题作为反馈,智能体也能通过调整写入形式来降低后续读取和利用的难度,从而间接提升整体表现。
06.技术洞见与未来方向
这项研究为长窗口记忆模型的发展提供了新的风向标:
-
评测范式转移: 随着模型能力的提升,静态数据集已难以满足评测需求,基于模拟器的交互式评测将成为主流。
-
重用偏差的警示: 开发者在选型时,必须警惕静态榜单的高分,需在动态环境中验证记忆模块的鲁棒性。
-
自我进化的潜力: 智能体具备通过交互反馈优化自身 Prompt 的能力,这为无需人工干预的自动化系统优化提供了可能。
AMemGym 的出现标志着记忆评测从"静态考卷"时代迈向了"实战演习"时代。
AMemGym 是首个实现对话记忆真实在线策略评估的基准。通过将自由形式交互建立在结构化状态演化之上,它创建了一个可扩展且诊断丰富的环境,用于评估和优化记忆能力。研究团队的实验不仅揭示了现有记忆系统之间的性能差距,更重要的是展示了离线评测中隐藏的重用偏差,以及静态基准会误导的配置选择问题。此外,智能体自我进化的实验也为无需人工干预的记忆持续改进提供了可能性。