前言
在高并发架构设计中,我们早已习惯将 Redis 当作"加速工具"------作为 MySQL 的缓存层,缓解磁盘 IO 压力、降低接口延迟。但随着业务峰值越来越极端(比如电商大促、直播秒杀),传统 Cache-Aside 模式的一致性痛点、MySQL 磁盘读写的性能瓶颈,逐渐成为架构升级的绊脚石。
今天,我们聊一个反常规但可落地的创新思路:Redis-First 架构------将 Redis 从"缓存/加速层"升级为"主存储/首选读写层",在特定场景下直接替代 MySQL,实现吞吐与延迟的量级提升。
核心结论先给到位:在明确场景边界(高并发、数据模型适配、可接受的持久化策略)下,该方案完全可行。通过主从复制+分级持久化+热冷分层等工程手段,既能把数据安全性、存储成本控制在可接受范围,还能简化缓存一致性带来的大量工程开销,尤其适配核心高并发链路。
一、为什么要"反常规"?Redis 替代 MySQL 的核心动因
不是为了"炫技",而是高并发场景下的必然选择------传统架构的痛点,只有打破"Redis 只做缓存"的固有认知,才能高效解决。
1. 性能差距:量级级的延迟碾压
高并发场景对 IO 延迟极度敏感,而 Redis 与 MySQL 的读写性能,本质上是"内存 vs 磁盘"的差距:Redis 的内存读取是 O(1) 操作,而 MySQL 的磁盘/索引查找是 O(logN) 甚至更高复杂度,两者在吞吐、延迟上能差数十倍到上百倍。
比如会话存储、商品售罄标识、排行榜这类场景,用 Redis 直接承接读写,能轻松扛住 MySQL 难以承受的峰值压力,这也是我们优先考虑迁移的核心场景。
2. 一致性简化:告别缓存层的"一地鸡毛"
传统 Cache-Aside 模式(读走缓存、写更数据库+删缓存),需要额外做大量工程优化来规避缓存穿透、雪崩、双删不一致等问题,复杂度随业务迭代不断上升。
而 Redis-First 架构,直接将 Redis 当作主库,把一致性问题简化到数据库层------通过 Redis 自身的复制、持久化机制保障数据可靠,无需再为"缓存与数据库同步"头疼,大幅降低工程维护成本。
3. 生态成熟:Redis 早已具备"主存储"能力
很多架构师的顾虑是"Redis 太轻,撑不起主存储",但实际上 Redis 生态早已完成迭代:Redis Enterprise、Redis-on-Flash、RediSearch 等组件,已经在多个大厂的核心链路中,被用于"主数据存储"或高并发场景优化,验证了 Redis 作为主存储的可行性。
二、可行性论证:三大核心顾虑,逐一破解
将 Redis 作为主存储,架构师最关心的三个问题:数据安全、复杂查询能力、内存成本。这三点都有成熟解决方案,无需过度担心。
1. 数据安全:持久化+复制,兜底可靠性
Redis 并非"内存易失",其提供 AOF、RDB 两种持久化方式,搭配多种 appendfsync 策略,可根据业务 SLA 灵活选择:
-
everysec:每秒执行一次 fsync,通常仅丢失最多 1s 数据,兼顾性能与可靠性,适合大多数非核心业务;
-
always:每次写操作都执行 fsync,数据安全性最高,但会显著影响性能,适合支付、记账等强一致场景。
推荐实操做法:主库(负责写入)开启 AOF 持久化,根据业务分级选择策略;同时配置多副本与自动主从切换,确保主库故障时秒级切换,搭配 AOF 延迟、复制滞后监控,进一步降低数据丢失风险------这一套组合拳,已经过大量工程案例验证,可靠性不输 MySQL。
2. 复杂查询:RediSearch 补位,不盲目替代
Redis 作为 KV 存储,天生不擅长复杂关联查询,但这并不意味着无法承接复杂读场景:Redis Stack / RediSearch 提供倒排索引、聚合、全文检索能力,对于商品搜索、标签检索、计数聚合等常见场景,完全可以替代 MySQL 或外部搜索系统,且延迟更有优势。
核心原则:不追求"一刀切"替代。将复杂且对相关性要求极高的搜索(比如多字段复杂排序、精准相关性评分),留给 Elasticsearch/Opensearch 这类专门搜索引擎;而延迟敏感、查询模式可索引化的场景,直接迁移到 RediSearch,实现"各司其职、性能最优"。
3. 内存成本:热冷分层,把钱花在"刀刃上"
最大的顾虑之一,就是"全量数据放内存成本太高"。但目前已有两类成熟解决方案,能将内存成本压低到可接受范围,甚至接近 MySQL 存储成本:
-
热冷分离 + Redis on Flash / Auto-Tiering:将键和索引保留在内存(保障查询速度),冷数据自动沉降到 SSD,访问时再拉回内存。比如 Redis Enterprise 的 Flash 技术,已在多个大厂落地,能显著降低内存开销;华为云发布的 Redis 混合存储版,更是能将同等容量成本降低 2/3,读写性能可达纯内存的 85%。
-
兼容协议的 KV 引擎:比如 Kvrocks、RocksDB 后端,在成本敏感、延迟要求可放宽的场景,用这类持久化 KV 存储替代纯内存 Redis,兼顾成本与性能。
推荐实操做法:只将**工作集(hot set,高频访问数据)**放在内存,冷数据自动沉降至 SSD;同时根据 SLA 调整访问后的升温策略(异步预热、队列化),既控制成本,又不影响热点数据的访问性能。
三、风险与缓解:工程落地的关键避坑点
没有完美的架构,Redis 替代 MySQL 也存在一定风险,但只要做好分级管控和兜底策略,就能将风险降到最低。
1. 数据丢失/一致性风险(最核心)
风险点:AOF everysec 仍可能丢失 ≤1s 数据;always 策略会大幅影响写入性能。
缓解方案:按业务分级管控------支付、记账等强一致业务,采用 AOF always 策略,或二级同步到关系库做兜底;非关键业务(如排行榜、会话),采用 everysec 策略,同时同步写入下游审计日志或消息队列,作为二次数据保障。
2. 复杂查询能力不足
风险点:部分复杂跨表 join、OLAP 查询,不适合 Redis 的 KV 风格。
缓解方案:不强行迁移------复杂 OLAP、多表 join 保留到专门系统(如 MySQL、ClickHouse);能用 RediSearch 实现的倒排、聚合查询,优先迁移;无法迁移的复杂读请求,通过后端服务统一处理,实现"写走 Redis、复杂读走后端"的混合模式。
3. 运维复杂度上升
风险点:Redis 主从复制、热冷分层、持久化等机制,会增加监控、运维的复杂度,容易出现复制滞后、热冷抖动等问题。
缓解方案:构建完善的监控体系,重点监控复制延迟、AOF 落盘延迟、主从健康、内存命中率、SSD 命中率;设置自动降级策略(本地从库不可用 → 读主库或回退到后端服务);借助成熟运维工具链(Redis Sentinel / Redis Cluster / Redis Enterprise),降低运维成本。
4. 热备份/灾备
实操做法:跨 AZ/Region 部署只读副本,定期将快照导出到冷存储;对于重要表、关键业务,采用"双写"或"异步落库"方式,同时写入关系型 DB 做审计,实现"Redis 做主存储、MySQL 做灾备审计"的双重保障。
四、直接可落地:Redis-First 架构实现例子
架构
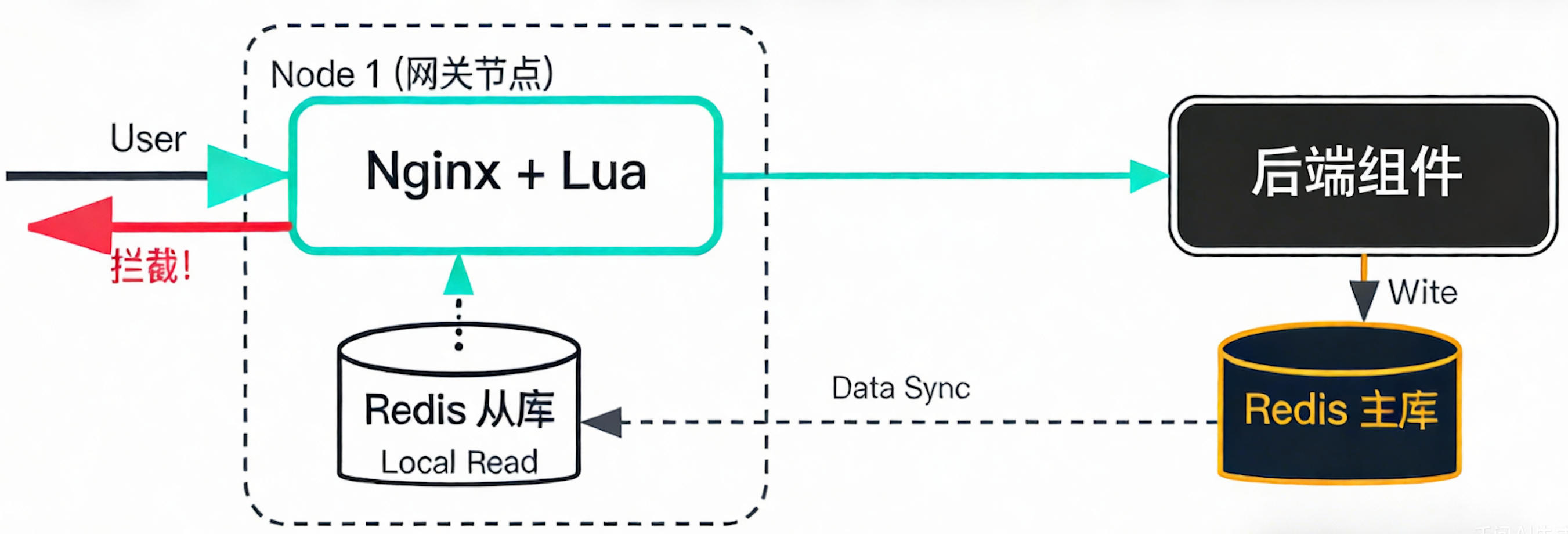
不用复杂重构,按以下 5 步推进,即可快速落地 Redis-First 架构,适合大多数高并发业务场景。
1. 网关层:边缘读优先,极致降低延迟
每个网关节点部署 Nginx + Lua,同时在网关本地部署 Redis 只读从库(仅承接读请求);Lua 脚本拦截读请求,简单 key 查询直接从本地从库返回,写请求、复杂查询透传至后端 Java 服务。
核心优势:读请求零跳转后端,大幅降低网络开销和后端压力;本地从库通过主从复制保持数据近实时,延迟可控制在毫秒级------这一思路与"本地缓存+Redis 二级缓存"的高性能架构异曲同工,能进一步放大 Redis 的性能优势。
2. 后端写入层:统一入口,保障持久化
Java 服务集群作为统一写入入口,所有写操作优先落到 Redis 主库(开启 AOF + RDB 备份策略),并同步到各只读从库(包括网关本地从库);对于关键写事务,额外写入消息队列或审计库,作为二次持久化保障,避免数据丢失。
3. Redis 主从与复制:高可用兜底
主库专注于写入,按业务分级配置 AOF 策略;从库(含网关本地从库)以异步复制为主,重点监控复制滞后情况,一旦超过阈值,立即触发降级(如直接读主库、回退到后端服务),避免脏读。
4. 热冷分层:成本优化核心
启用 Redis Enterprise Flash / Auto-Tier 或 Kvrocks/RocksDB 后端,实现热数据(工作集)存内存、冷数据沉降 SSD;根据业务热点,调整数据升温策略,确保冷数据访问时的延迟可控。
5. 监控与兜底:保障稳定运行
实时监控核心指标:复制延迟、从库存活、AOF fsync 延迟、内存命中率、SSD 命中率;设置兜底策略,确保任何环节故障时,系统能自动降级,不影响业务可用性。
五、适用场景与实施路线(优先级明确)
Redis 替代 MySQL 不是"全量替代",而是"精准迁移",按以下优先级推进,收益最高、风险最低。
优先迁移场景(高收益、低改造)
售罄标识、库存预占(需做好幂等保障)、会话与用户态快速读写、排行榜、限流计数器、短期缓存型实体------这类场景数据模型简单、高并发、延迟敏感,迁移成本低,能快速享受到性能提升。
谨慎迁移场景(需多验证)
复杂跨表 join 报表、强事务一致账务、对全文检索相关性要求极高的搜索------这类场景不适合直接迁移,可采用"混合模式",或先通过 RediSearch 做验证,再逐步迁移。
分阶段实施路线(可直接照搬)
-
PoC 阶段(2--6 周):选择 1--2 个非关键但高并发的业务(如商品列表热读、售罄标识),实现 Redis-First 网关+本地只读从库架构,跑完整压测,验证 AOF 策略、复制滞后等核心指标。
-
平台封装阶段(2--4 月):将读拦截、降级、监控、热冷自动分层等能力,封装成共享组件(如 Nginx+Lua 模板、复制策略、运维脚本),降低后续迁移成本。
-
分阶段迁移+灾备演练(持续):先迁移"可最终一致"类业务,再评估强一致业务的迁移可行性;同时定期开展灾备演练,确保数据安全,逐步实现核心链路的 Redis-First 架构落地。
六、总结:Redis 替代 MySQL,核心是"取舍与适配"
Redis 替代 MySQL 做主存储,不是否定 MySQL,而是在高并发场景下,选择更合适的工具做"更擅长的事"------Redis 承接高并发读写、保障低延迟,MySQL (或其他专用系统)承接复杂查询、做灾备审计,形成互补。
其核心可行性,在于三点:一是 Redis 生态的成熟,解决了数据安全、复杂查询、成本控制等核心痛点;二是 Redis-First 架构简化了缓存一致性工程,降低了维护成本;三是热冷分层等技术,打破了内存成本的制约。
对于架构师而言,无需固守"Redis 只做缓存"的固有认知,只要明确场景边界、做好风险管控、按阶段落地,就能用 Redis-First 架构,轻松破解高并发场景的性能瓶颈,实现架构的高效升级。
我的博客:https://itart.cn/blogs/2026/explore/redis-first-replace-mysql.html