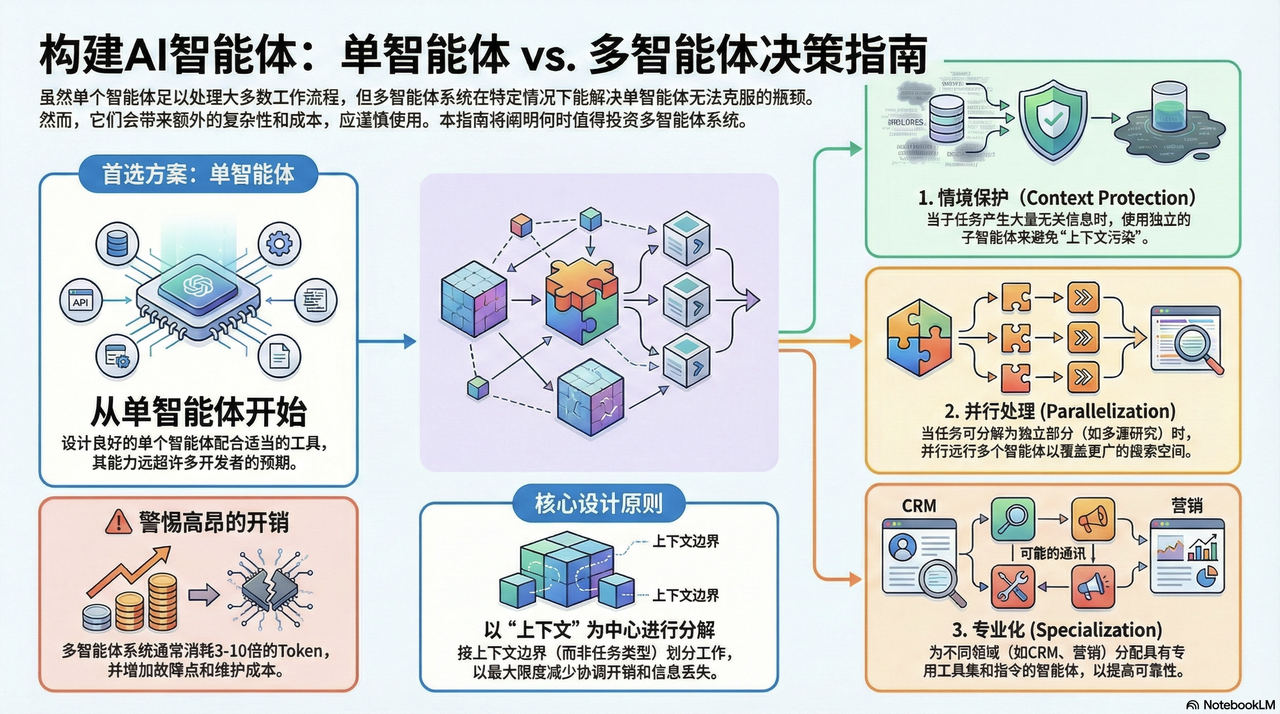
多智能体系统是为特定问题而生的特定解决方案,而非通用升级。Anthropic在官网介绍了多agent的构建经验 并总结出三种它们始终优于单agent的场景:防止上下文污染、通过并行提升全面性,以及通过专门化提升可靠性。
本文将提供一个战略框架,帮助你判断何时应该"升级"。我们会探讨这三种场景,解释成功的核心设计原则,并指出那些可能浪费数月开发时间的常见陷阱。
-
你精心设计的多智能体系统,可能只是提示词没写好
在架构复杂系统之前,开发者应当始终先从单一智能体开始。多智能体系统会引入显著的额外开销,包括更多潜在故障点、更多需要维护的提示词,以及大幅更高的 token 成本。很多时候,看似需要多个智能体,实际上是在暗示单一智能体的提示词尚未优化到位。
在 Anthropic,我们见过一些团队花了数月时间构建复杂的多智能体架构,最终却发现:只要改进单一智能体的提示词,就能达到同样的效果。
这一原则至关重要,因为它能为开发者节省大量时间和资源。先掌握构建一个强大单一智能体的基本功,团队就能避免不必要的复杂性,从一开始就打造更稳健、高效且具成本效益的解决方案。
-
上下文保护:防止性能退化
使用多智能体系统的第一个、也是最重要的原因,是防止上下文污染。当一个智能体的上下文窗口被某个子任务的大量信息填满,而这些信息对下一个任务并不相关时,它的性能就会下降。子智能体通过"隔离"解决了这一问题,让每个智能体都在干净、专注于自身任务的上下文中运行。
例如,一个客服智能体既要查询订单历史,又要诊断技术问题。如果查询订单时把成千上万的 token(购买记录、物流信息等)加入上下文,那么它在推理技术问题时的能力就会被稀释。
多智能体方案可以将上下文隔离开来:专门启动一个订单查询智能体,负责检索并处理完整历史,然后只返回一个 50--100 token 的精简摘要。主智能体只接收关键信息,从而保持上下文简洁,专注解决用户的技术问题。
-
并行化:以成本换取全面性
当任务可以拆分为相互独立的部分(例如研究问题的不同侧面)时,并行运行多个智能体,可以覆盖远超单一智能体的信息空间。这种模式在搜索和研究类任务中尤其有价值,因为全面覆盖至关重要。
但这种全面性是有代价的。对于同等任务,多智能体系统通常会消耗单一智能体 3 到 10 倍的 token。开销主要来自:
- 为每个智能体复制上下文;
- 智能体之间的协调通信;
- 结果交接时的总结。
这也澄清了一个常见误解:并行化并不等于更快。这里的主要收益是"更全面",而不是缩短总执行时间。由于总体计算量大幅增加,整个流程往往比单一智能体更慢。取舍很明确:更高的 token 消耗和更长的运行时间,换取更全面的结果。
-
专门化:用聚焦提升可靠性
当一个智能体被赋予越来越多的工具和职责时,其可靠性往往会下降。专门化指的是创建多个智能体,各自拥有聚焦的工具集、系统提示词或领域知识,以提升特定任务的表现。这在三种场景下尤为有效:
- 工具集专门化:当一个智能体拥有过多工具(常见 20 个以上)时,容易选错工具。将其拆分为工具更少、领域明确的智能体(例如只负责 CRM 的智能体、只负责营销的智能体)可以减少选择错误。
- 系统提示词专门化:有些任务需要彼此冲突的角色设定。客服需要共情,而代码审查需要严谨和挑剔。将它们分离为拥有不同系统提示词的专门智能体,能带来更一致、可靠的行为。
- 领域专长专门化:需要深度领域知识的任务(如法律分析、医学研究),适合由加载了高度聚焦上下文的智能体来完成,否则这些信息会压垮通用型智能体。
专门化的主要挑战在于路由复杂度增加。调度智能体必须正确分配任务,一旦分配错误,结果就会变差。
按"上下文"而不是"岗位"来拆分工作
构建多智能体系统时,最重要的设计决策是如何拆分工作。一个常见错误是"以问题或角色为中心"的拆分方式,模仿人类团队分工(如规划智能体、编码智能体、测试智能体)。这种方式几乎总会失败,形成"传话游戏",在每次交接中丢失关键上下文。
更有效的替代方案是"以上下文为中心"。只有当各个任务所需的上下文能够真正隔离时,才应该拆分工作。一个负责编写功能的智能体,也应该同时编写测试,因为它已经拥有全部必要上下文;强行拆分只会增加协调成本和失败点。
实用指南如下:
适合的拆分边界包括:
- 相互独立的研究路径,例如分别研究亚洲与欧洲市场趋势;
- 接口清晰的独立组件,例如通过明确 API 分隔的前后端;
- 黑盒验证,只需要针对输出运行测试的验证任务。
不适合的拆分边界包括:
- 同一工作的顺序阶段,如规划、实现、测试同一个功能;
- 强耦合组件,需要频繁来回沟通;
- 需要共享状态的工作,智能体必须不断同步理解。
唯一被反复验证有效的模式:验证智能体
有一种多智能体模式被证明始终有效:验证子智能体。它是一个专门用于测试或验证主智能体工作的独立智能体。
这一模式之所以成功,是因为它完美契合"以上下文为中心"的拆分原则。验证智能体不需要了解完整的开发历史,只需根据清晰标准对最终输出进行"黑盒测试",从而完全避免上下文丢失的问题。值得注意的是,更强的调度模型(如 Claude Opus 4.5)已越来越能够直接评估子智能体的工作,但这种模式在强制执行明确验证节点方面仍然非常有价值。
该模式最常见的失败点是"过早胜利问题":智能体在未进行充分测试前就宣布任务成功。为避免这一问题,需要明确的缓解策略:
- 提供具体标准(如"运行完整测试套件并报告所有失败项");
- 要求负向测试,确认本应失败的输入确实失败;
- 使用明确指令,例如:"在标记为通过之前,你必须运行完整测试套件。"
结论:只有在必须时才增加复杂性
多智能体系统很强大,但应只在单一智能体无法克服真实约束时使用。在构建"AI 群体"之前,确认你确实需要上下文保护、深度并行或任务专门化。默认选择永远应是"能工作的最简单方案"。