文章目录
- [0. 个人感悟](#0. 个人感悟)
- [1. 概念](#1. 概念)
- [2. 适配场景](#2. 适配场景)
-
- [2.1 适合的场景](#2.1 适合的场景)
- [2.2 常见场景举例](#2.2 常见场景举例)
- [3. 实现方法](#3. 实现方法)
-
- [3.1 概念理解](#3.1 概念理解)
-
- [3.1.1 文法](#3.1.1 文法)
- [3.3.2 终结符和非终结符](#3.3.2 终结符和非终结符)
- [3.3.3 句子](#3.3.3 句子)
- 3.3.4语法树
- [3.2 实现思路](#3.2 实现思路)
- [3.3 UML类图](#3.3 UML类图)
- [3.4 代码示例](#3.4 代码示例)
- [4. 优缺点](#4. 优缺点)
-
- [4.1 优点](#4.1 优点)
- [4.2 缺点](#4.2 缺点)
0. 个人感悟
- 解释器模式旨在定义语法规则,并对符合语法规则的句子进行解释
- 解释器模式使用场景专业且有限,实际工作中场景很少,可以帮助简单理解编译器原理
- 模式涉及很多编译原理的概念,看了一些文章,还是一直半解,这里把自己理解的内容记录下来,先不纠结了
- 关于四则运行的示例,找了一个比较泛用、易懂的代码,有兴趣可以看看,核心在使用stack构建解释器
- 对于基础的数据表达式分析计算,已有很多成熟的开源底代码,大家实际工作中遇到可以了解下,比如Expression4J、MESP(Math Expression String Parser) 、Jep等
1. 概念
英文定义 (《设计模式:可复用面向对象软件的基础》)
Given a language, define a represention for its grammar along with an interpreter that uses the representation to interpret sentences in the language.
中文翻译
给定一个语言,定义它的文法的一种表示,并定义一个解释器,该解释器使用该表示来解释语言中的句子。
理解
- 语言导向的设计模式:专门为解释和执行特定领域语言而设计
- 文法与解释分离:将文法规则抽象为类结构,解释逻辑分布在各个表达式类中
- 组合模式的应用:通常使用组合模式构建抽象语法树来表示语言结构
- 关注点分离:文法定义、语法解析、解释执行各司其职
2. 适配场景
2.1 适合的场景
- 简单文法规则:当语言的文法相对简单,规则数量有限时
- 执行效率非关键:对解释执行效率要求不高的场景
- 频繁修改文法:当文法需要经常扩展或修改时
- 领域特定语言(DSL):需要为特定领域创建专用解释器
- 避免重复解析:需要多次执行相同或类似表达式
2.2 常见场景举例
- 正则表达式引擎:解释并执行正则表达式匹配规则
- SQL查询解释器:解释简单的SQL查询语句
- 业务规则引擎:解释执行业务规则,如优惠券规则、风控规则
- 数学公式计算器:解释数学表达式并计算结果
- 配置文件解析:解释特定格式的配置文件
- 机器人指令系统:解释机器人控制指令序列
- 简单脚本语言:实现简单的脚本语言解释器
3. 实现方法
3.1 概念理解
定义里提到了很多编译原理中的概念,首先了解下各个概念含义,有利于理解模式
以逆波兰表示法(项在前 运算符在后)的四则运算的四则运算为例
3.1.1 文法
定义
形式语言的规则系统,定义了语言中合法句子的结构规则。通常使用产生式规则描述。
理解*
-
文法是定义语法规则的,比如我们的汉语、正则表达式、sql、甚至代码,都有语法,符合规则才能正确解析。所以解释器一般都有很强的专业性。
-
对于文法的表示,通常用BNF(巴科斯-诺尔范式),有兴趣可以了解下
例子:四则运行::=
|
|::=
|
|::= [0-9]+
::= [a-zA-Z_][a-zA-Z0-9_]*
::= "+" | "-" | "*" | "/"
规则解释
规则1: 表达式 → 项 项 运算符
规则2: 表达式 → 表达式 项 运算符
规则3: 项 → 数字 | 变量 | (表达式)
规则4: 数字 → 一个或多个数字字符
规则5: 变量 → 字母或下划线开头,后跟字母、数字或下划线
规则6: 运算符 → + | - | * | /3.3.2 终结符和非终结符
定义
终结符 :文法中的基本符号,不能再被推导,对应语言的最小单位(如数字、变量、运算符)。
非终结符:可以由终结符和/或其他非终结符组成,表示语言的结构单元(如表达式、项、因子)。
理解*
- 看完语法树的概念再回过头看这个会好理解点
3.3.3 句子
定义
符合文法规则的完整输入字符串,是解释器要处理的具体实例
理解*
- 规则的实例。我们经常说句子通不通顺,实际上是汉语实例是否符合汉语语法。
例子
表达式1: "3 4 +" // 符合:项 项 运算符
表达式2: "3 4 5 * +" // 符合:表达式 项 运算符
表达式3: "3 4 + 5 *" // 符合:表达式 项 运算符
表达式4: "+ 3 4" // 无效:运算符在前
表达式5: "3 4" // 无效:缺少运算符
表达式6: "(3 + 4)" // 无效:有括号3.3.4语法树
定义
句子结构的树形表示,根节点是起始符号,内部节点是非终结符,叶子节点是终结符,反映了句子的层次结构。
例子
3+4 * 5
*
/ \
+ 5
/ \
3 43.2 实现思路
- 定义文法规则:分析要解释的语言,用形式文法描述其结构
- 设计抽象语法树节点:为每个文法规则创建对应的表达式类
- 实现终结符表达式:创建表示基本元素的类(如数字、变量)
- 实现非终结符表达式:创建表示组合结构的类(如运算表达式)
- 定义上下文环境:创建包含解释器所需全局信息的上下文类
- 构建解释器接口:定义统一的解释方法接口
- 实现解释逻辑:在每个表达式类中实现具体的解释操作
- 添加构建器或解析器:可选,用于将输入字符串转换为抽象语法树
3.3 UML类图
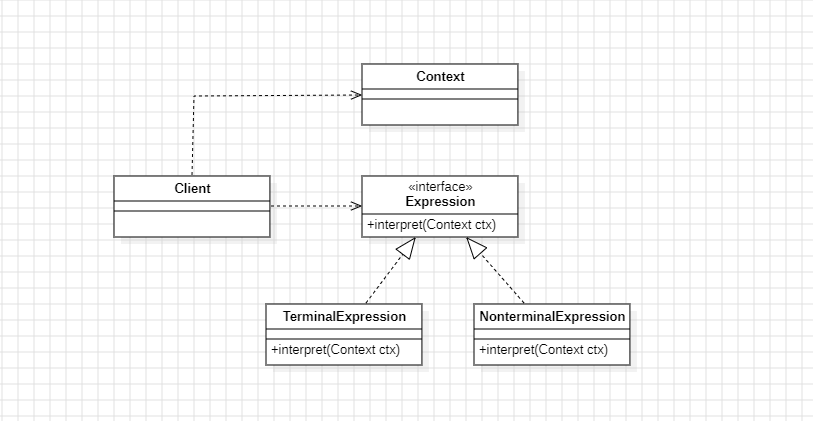
!\[解释器模式_UML.png]
角色说明:
- AbstractExpression:抽象表达式,声明解释操作的接口
- TerminalExpression:终结符表达式,实现与文法终结符相关的解释操作
- NonterminalExpression:非终结符表达式,实现与文法非终结符相关的解释操作
- Context:上下文,包含解释器之外的全局信息
- Client:构建抽象语法树并调用解释操作
3.4 代码示例
背景
- 逆波兰表示法(项在前 运算符在后)的四则运算的四则运算
- 核心是stack构建解释器逻辑
表达式接口
java
public interface Expression {
int interpret(Context context);
}上下文
java
public class Context {
private Map<String, Integer> variables = new HashMap<>();
public void assign(String variable, int value) {
variables.put(variable, value);
}
public int getValue(String variable) {
Integer value = variables.get(variable);
if (value == null) {
throw new IllegalArgumentException("Variable not found: " + variable);
}
return value;
}
}终结符表达式
java
// 变量
public class VariableExpression implements Expression {
private String name;
public VariableExpression(String name) {
this.name = name;
}
@Override
public int interpret(Context context) {
return context.getValue(name);
}
}
// 数字
public class NumberExpression implements Expression {
private int number;
public NumberExpression(int number) {
this.number = number;
}
@Override
public int interpret(Context context) {
return number;
}
}非终结符表达式
java
// 加
public class AddExpression implements Expression {
private Expression left;
private Expression right;
public AddExpression(Expression left, Expression right) {
this.left = left;
this.right = right;
}
@Override
public int interpret(Context context) {
return left.interpret(context) + right.interpret(context);
}
}
// 减
public class SubtractExpression implements Expression {
private Expression left;
private Expression right;
public SubtractExpression(Expression left, Expression right) {
this.left = left;
this.right = right;
}
@Override
public int interpret(Context context) {
return left.interpret(context) - right.interpret(context);
}
}
// 乘
public class MultiplyExpression implements Expression {
private Expression left;
private Expression right;
public MultiplyExpression(Expression left, Expression right) {
this.left = left;
this.right = right;
}
@Override
public int interpret(Context context) {
return left.interpret(context) * right.interpret(context);
}
}
// 除
public class DivideExpression implements Expression {
private Expression left;
private Expression right;
public DivideExpression(Expression left, Expression right) {
this.left = left;
this.right = right;
}
@Override
public int interpret(Context context) {
int divisor = right.interpret(context);
if (divisor == 0) {
throw new ArithmeticException("Division by zero");
}
return left.interpret(context) / divisor;
}
}表达式构建构器
java
public class ExpressionBuilder {
public static Expression build(String expression) {
Stack<Expression> stack = new Stack<>();
String[] tokens = expression.split("\\s+");
for (String token : tokens) {
switch (token) {
case "+":
Expression right = stack.pop();
Expression left = stack.pop();
stack.push(new AddExpression(left, right));
break;
case "-":
right = stack.pop();
left = stack.pop();
stack.push(new SubtractExpression(left, right));
break;
case "*":
right = stack.pop();
left = stack.pop();
stack.push(new MultiplyExpression(left, right));
break;
case "/":
right = stack.pop();
left = stack.pop();
stack.push(new DivideExpression(left, right));
break;
default:
// 尝试解析为数字,否则视为变量
try {
int number = Integer.parseInt(token);
stack.push(new NumberExpression(number));
} catch (NumberFormatException e) {
stack.push(new VariableExpression(token));
}
break;
}
}
return stack.pop();
}
}测试
java
public class Client {
static void main() {
// 创建上下文
Context context = new Context();
context.assign("a", 10);
context.assign("b", 5);
context.assign("c", 2);
Expression expression1 = ExpressionBuilder.build("a b c * +");
int result1 = expression1.interpret(context);
System.out.println("a + b * c = " + result1); // 输出: a + b * c = 20
}
}结果
a + b * c = 204. 优缺点
4.1 优点
- 高内聚:每个表达式类只关注自己的解释逻辑,职责单一
- 易于扩展语法:添加新的表达式类即可扩展语言功能,符合开闭原则
- 可复用性高:表达式类可以在不同的解释器中复用
- 可维护性好:文法规则与解释逻辑分离,修改文法不影响解释器结构
- 灵活性:可以通过组合不同的表达式创建复杂的语言结构
- 良好的可读性:语法树直观反映了语言结构,便于理解和调试
4.2 缺点
- 效率较低:复杂语法树需要递归解释,性能可能不佳
- 类数量爆炸:文法复杂时,需要创建大量的表达式类
- 可维护性挑战:对于复杂文法,类层次结构会变得复杂,难以维护
- 不适合复杂文法:文法过于复杂时,解释器模式不是最佳选择
- 稳定性受影响:文法频繁变化时,需要大量修改代码
- 违反单一职责原则:文法规则和解释逻辑混合在表达式类中
参考: