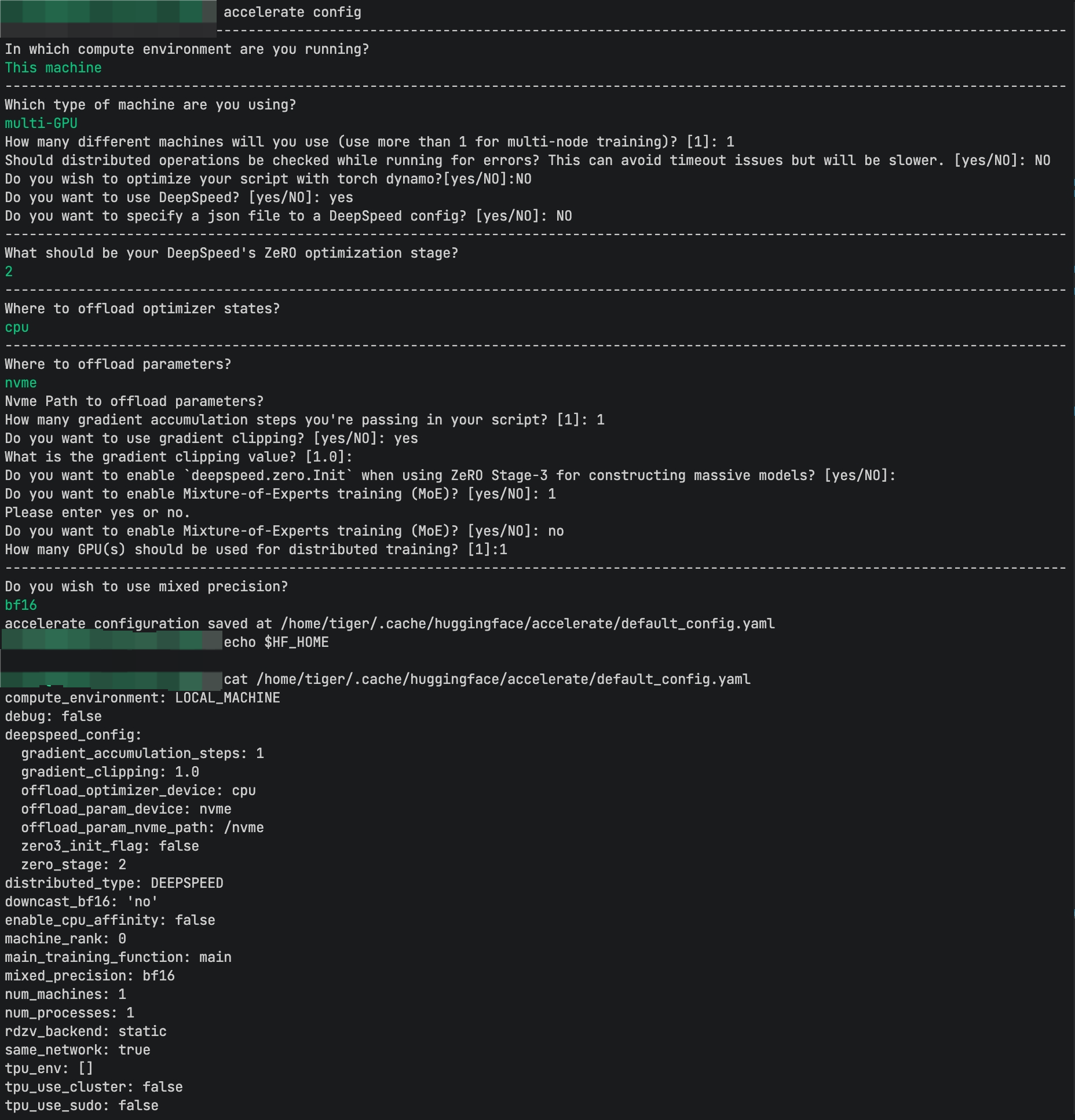
执行完accelerate config会有一个默认的yaml配置文件
python
from accelerate import Accelerator
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
from torchvision import datasets, transforms, models
# 初始化Accelerator
accelerator = Accelerator()
device = accelerator.device
# 数据预处理
transform = transforms.Compose([
transforms.RandomHorizontalFlip(),
transforms.RandomCrop(32, padding=4),
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
])
# 加载数据集
train_dataset = datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
test_dataset = datasets.CIFAR10(root='./data', train=False, download=True, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=2048, shuffle=True, num_workers=4)
test_loader = DataLoader(test_dataset, batch_size=2048, shuffle=False, num_workers=4)
# 定义模型
model = models.resnet18(num_classes=10).to(device)
print(f'initial model device: {next(model.parameters()).device}')
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.1, momentum=0.9, weight_decay=5e-4)
# 使用accelerate包装模型、优化器和数据加载器
model, optimizer, train_loader, test_loader = accelerator.prepare(model, optimizer, train_loader, test_loader)
# 检查分配情况
print(f"Model is on device: {next(model.parameters()).device}")
for batch_idx, (inputs, targets) in enumerate(train_loader):
print(f"batch_{batch_idx} inputs are on device: {inputs.device}")
print(f"batch_{batch_idx} targets are on device: {targets.device}")
# 训练函数
def train(epoch):
model.train()
for batch_idx, (inputs, targets) in enumerate(train_loader):
print(f'{epoch}:{batch_idx}', accelerator.is_main_process, batch_idx, inputs.device, targets.device, model.device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, targets)
accelerator.backward(loss)
optimizer.step()
if batch_idx % 200 == 0:
print(f'{accelerator.is_main_process}, Train Epoch: {epoch} [{batch_idx * len(inputs)}/{len(train_loader.dataset)} ({100. * batch_idx / len(train_loader):.0f}%)]\tLoss: {loss.item():.6f}')
# 测试函数
def test():
model.eval()
test_loss = 0
correct = 0
total = 0
with torch.no_grad():
for inputs, targets in test_loader:
outputs = model(inputs)
loss = criterion(outputs, targets)
test_loss += accelerator.gather(loss).sum().item()
pred = outputs.argmax(dim=1, keepdim=True)
correct += accelerator.gather(pred.eq(targets.view_as(pred)).sum()).sum().item()
total += targets.size(0) * accelerator.num_processes # 这里的总数可以直接累加
test_loss /= total
accuracy = 100. * correct / total
if accelerator.is_main_process:
print(f'Test set: Average loss: {test_loss:.4f}, Accuracy: {correct}/{total} ({accuracy:.0f}%)')
# 主训练循环
for epoch in range(3):
train(epoch)
test()
print("Training completed.")