在学习了 Pod 的原理和一些基本使用后,发现在实际使用的时候并不会直接使用 Pod,而是会使用各种控制器来满足我们的需求,Kubernetes 中运行了一系列控制器来确保集群的当前状态与期望状态保持一致,它们就是 Kubernetes 的大脑。
例如,ReplicaSet 控制器负责维护集群中运行的 Pod 数量;Node 控制器负责监控节点的状态,并在节点出现故障时及时做出响应。总而言之,在 Kubernetes 中,每个控制器只负责某种类型的特定资源。
目录
[ReplicaSet 的核心工作机制](#ReplicaSet 的核心工作机制)
[1. 创建ReplicaSet](#1. 创建ReplicaSet)
[2. 弹性扩缩容](#2. 弹性扩缩容)
[3. 删除ReplicaSet](#3. 删除ReplicaSet)
[核心关系:Deployment → ReplicaSet → Pod](#核心关系:Deployment → ReplicaSet → Pod)
[StatefulSet 控制器](#StatefulSet 控制器)
[StatefulSet 的核心:为有状态应用提供身份和存储](#StatefulSet 的核心:为有状态应用提供身份和存储)
[理解有状态 vs. 无状态](#理解有状态 vs. 无状态)
[两个关键设计:Headless Service 与稳定存储](#两个关键设计:Headless Service 与稳定存储)
[什么时候该用 StatefulSet?](#什么时候该用 StatefulSet?)
[DaemonSet 控制器](#DaemonSet 控制器)
[DaemonSet 的核心思想:一节点,一守护](#DaemonSet 的核心思想:一节点,一守护)
ReplicaSet控制器
理解ReplicaSet控制器是掌握Kubernetes自动化运维的关键一步。理解其"自动修复"和"扩缩容"的能力。
ReplicaSet 的核心工作机制
ReplicaSet(RS)的核心目标非常简单:确保与其标签选择器匹配的、正在运行的Pod副本数量,始终等于用户声明的期望数量 。这个过程就是Kubernetes中经典的控制循环 (Control Loop)或调谐循环(Reconcile Loop)。
它通过三个核心部分来实现这一目标:
|---------------------|--------------------------------------|-----------------------------------|---------------------------------------|
| 核心部分 | 作用 | 类比 | YAML |
| 副本数 Replicas | 定义期望的Pod副本数量,即"需要运行多少个完全一样的实例"。 | 餐厅经理计划今晚需要3名服务员上岗 | spec.replicas: 3 |
| 标签选择器Label Selector | 用于识别哪些Pod归自己管理。它会持续扫描集群中带有特定标签的Pod | 经理通过"岗位=服务员"这个标准来识别员工 | spec.selector.matchLabels: app: nginx |
| Pod模板 Pod Template | 当需要创建新的Pod时,就用这个模板来"生成"。它定义了Pod的完整规格 | 经理的"服务员岗位说明书",规定了服务员的制服、工作内容等 | spec.template下的完整Pod定义 |
如何操作ReplicaSet?
1. 创建ReplicaSet
使用你的YAML文件示例,通过命令即可创建:
kubectl apply -f nginx-rs.yaml
创建后,可以查看RS和Pod的状态:
kubectl get rs
kubectl get pods -l app=nginx # -l 用于按标签筛选Pod
2. 弹性扩缩容
调整副本数有两种常用方式:
-
修改YAML文件 :将
spec.replicas的值改为2,然后重新执行kubectl apply -f nginx-rs.yaml。 -
使用scale命令(更快捷):
kubectl scale rs nginx-rs --replicas=2
3. 删除ReplicaSet
- 默认删除:会删除RS对象及其管理的所有Pod。
kubectl delete rs nginx-rs
- 只删除控制器(保留Pod):使用此命令后,Pod将变成无人管理的"自主式Pod"。
kubectl delete rs nginx-rs --cascade=orphan
Deployment控制器
Deployment 是 Kubernetes 中用于管理应用部署的核心控制器,它通过管理 ReplicaSet 来实现强大的滚动更新 和版本控制功能,确保应用更新过程平滑、可控。
核心关系:Deployment → ReplicaSet → Pod
Deployment 并不直接创建和管理 Pod。它的工作模式是:
-
Deployment 根据你定义的 Pod 模板创建并管理 ReplicaSet。
-
ReplicaSet 负责确保指定数量的 Pod 副本正常运行。
-
当你更新 Pod 模板(如镜像版本)时,Deployment 会创建一个新的 ReplicaSet,并逐步将 Pod 从旧的 ReplicaSet 迁移到新的 ReplicaSet,直至所有 Pod 都符合新模板。
这种层级关系使得 Deployment 能够实现 ReplicaSet 不具备的复杂部署策略。
滚动更新详解
滚动更新是 Deployment 的核心价值所在,它通过精细的控制策略实现服务不中断的更新。
1.关键控制参数:
-
maxSurge:允许超出期望副本数的最大 Pod 数量,用于在更新过程中启动新版本 Pod(例如,设置为 1 意味着最多可以有一个额外的 Pod)。 -
maxUnavailable:更新过程中允许不可用 Pod 的最大数量,用于控制旧版本 Pod 的下线速度(例如,设置为 1 意味着最多可以有一个 Pod 暂时无法服务)。
更新过程通常表现为:启动一个新版本 Pod → 终止一个旧版本 Pod → 循环此过程,直到所有 Pod 都替换为新版本。
你可以使用 kubectl rollout status deployment/
2.更新管控与版本回滚
Deployment 提供了强大的流程控制功能:
-
暂停与继续 :你可以使用 kubectl rollout pause deployment/
暂停滚动更新,以便在部分 Pod 更新后进行验证。确认无误后,使用 kubectl rollout resume deployment/ 继续更新过程。 -
版本记录与回滚 :每次对 Deployment 的修改都会创建一个新的 修订版本 。你可以使用 kubectl rollout history deployment/
查看所有修订记录。如果更新后发现问题,可以迅速回滚到上一个版本 kubectl rollout undo deployment/ ,或回滚到特定版本 kubectl rollout undo deployment/ --to-revision= 。Kubernetes 正是通过保留旧 ReplicaSet的对象来实现回滚的。
3.进阶概念:更智能的部署策略
虽然原生 Deployment 的滚动更新已经很强大,但对于需要更精细控制流量或验证新版本稳定性的场景,还有更高级的策略:
-
蓝绿部署:同时部署新版本和旧版本,测试通过后,一次性将流量从旧版本切换到新版本。
-
金丝雀发布:仅将一小部分流量引导至新版本,观察一段时间确认稳定后,再逐步扩大新版本的流量比例。
这些策略通常需要借助 Argo Rollouts 或 Flagger 等工具来实现,它们提供了基于指标的自动验证和更灵活的流量管理能力。
StatefulSet 控制器
StatefulSet 的核心:为有状态应用提供身份和存储
你可以把 StatefulSet 看作是专门用于管理有状态应用 的 Deployment。它的核心设计目标是确保每个 Pod 都有唯一的、稳定的身份标识和独立的、持久的存储。这与 Deployment 管理的、彼此完全等同的无状态 Pod 形成了鲜明对比。
下面的表格清晰地展示了它与 Deployment 的核心区别:
|------------|--------------------------------------------|----------------------------------------------------------------|
| 特性 | Deployment(无状态) | StatefulSet(有状态) |
| Pod 身份 | 所有 Pod 身份完全一致,名称随机(如 app-7df9cfc97d-xyz) | 每个 Pod 有唯一且稳定的名称,按顺序编号(如 web-0, web-1, web-2) |
| 网络标识 | 共享同一个 Service 的虚拟 IP(VIP),访问会随机转发到某个 Pod | 每个 Pod 有稳定的 DNS 名称:<pod-name>.<service-name>....,可直接访问特定 Pod |
| 存储 | 所有 Pod 共享存储卷(如果定义) | 每个 Pod 拥有独立的持久化存储卷(PV),Pod 重建后仍绑定原数据 |
| 启停顺序 | 并行创建和扩展,无固定顺序 | 顺序操作:按编号升序(0,1,2)创建/扩展,按降序(2,1,0)删除/缩容 |
理解有状态 vs. 无状态
-
无状态服务(Stateless) :实例本身不保存需要持久化的数据,多个实例完全等价且可互换。例如,一个 Web 前端服务,其会话(Session)数据存储在外部的 Redis 中。适合用 Deployment 管理。
-
有状态服务(Stateful) :实例需要在本地磁盘保存持久化数据,且实例间存在依赖关系(如主从、主备)。例如,MySQL 数据库、ZooKeeper、Etcd 等。必须用 StatefulSet 管理,否则 Pod 重启或调度到新节点会导致数据丢失。
两个关键设计:Headless Service 与稳定存储
1. Headless Service(无头服务)
这是 StatefulSet 网络身份稳定的基础。它与普通 Service 的关键区别在于 clusterIP: None,即没有集群虚拟 IP。
-
作用:它不为 Pod 提供负载均衡,而是为每个 Pod 提供一个稳定的 DNS 域名。
-
域名格式 :
<pod-name>.<service-name>.<namespace>.svc.cluster.local- 例如,对于名为
web的 StatefulSet 和名为nginx的 Headless Service,第一个 Pod(web-0)的域名是:web-0.nginx.default.svc.cluster.local。通过此域名可以直接解析到web-0这个 Pod 的 IP 地址。
- 例如,对于名为
2. 稳定的持久化存储
这是 StatefulSet 数据不丢失的保障。通过 volumeClaimTemplates(卷申请模板)实现。
-
工作原理 :当 StatefulSet 创建 Pod 时(如
web-0),会根据模板自动创建一个与之绑定的 PVC(PersistentVolumeClaim,持久化卷申请),命名格式为<volumeClaimTemplateName>-<statefulsetName>-<ordinal>(如www-web-0)。这个 PVC 会绑定到一个 PV(PersistentVolume,持久化卷)。 -
核心优势 :当 Pod
web-0被删除并重建后,新 Pod 仍然会绑定到原来那个 名为www-web-0的 PVC,从而挂载原有的数据卷,实现了数据的持久化。
特性与工作流程
-
有序部署与伸缩:
-
创建 :必须等
web-0进入Running且Ready状态后,才会开始创建web-1。 -
扩容 :扩容到 3 个副本时,会按顺序创建
web-2。 -
缩容:缩容时,则按逆序(2,1,0)终止 Pod。
-
-
更新策略:
-
RollingUpdate:默认策略,逆序(从最大序号开始)滚动更新 Pod。 -
OnDelete:手动删除 Pod 后,才会用新模板创建。 -
Partition:可实现灰度发布,仅更新序号大于等于指定分区值的 Pod。
-
-
管理策略:
-
OrderedReady:默认策略,遵循上述顺序性保证。 -
Parallel:并行启动或终止所有 Pod,不等待,适用于不需要严格顺序的集群。
-
什么时候该用 StatefulSet?
当你需要部署满足以下一个或多个条件的应用时:
-
稳定的、唯一的网络标识。
-
稳定的、持久化的存储。
-
有序的部署、扩缩容和更新。
-
实例间有不平等关系(如主从、主备)。
典型场景:MySQL、PostgreSQL 等数据库集群,ZooKeeper、Etcd、Kafka、Redis Cluster 等中间件集群。
DaemonSet 控制器
Daemon,就是用来部署守护进程的,DaemonSet用于在每个 Kubernetes 节点中将守护进程的副本作为后台进程运行。
DaemonSet 的核心思想:一节点,一守护
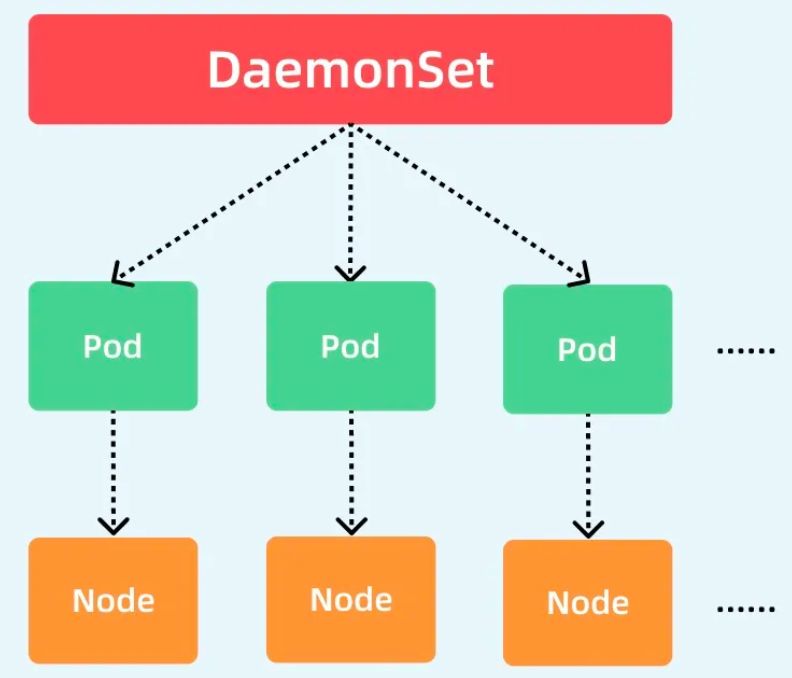
DaemonSet 的核心目标非常简单:确保集群中的每一个(符合条件的)节点上,都运行一个指定的 Pod 副本。就像一个尽职的"守护进程"一样。
你的图片完美诠释了这一点:
-
**最上层的
DaemonSet** 是控制器本身。 -
中间层的
Pod 是它管理的对象,每个节点对应一个 Pod。 -
**底层的
Node** 是这些 Pod 运行的实际位置。
这种"一对一"的绑定关系,使得 DaemonSet 非常适合部署那些需要运行在所有节点上、提供节点级别服务的系统级组件。
四大典型应用场景
以下场景是 DaemonSet 的"主场":
|----------|-----------------------------------|------------------------------------|
| 场景 | 典型应用 | 核心原因 |
| 存储插件 | glusterd, ceph | 每个节点都需要一个代理来提供或接入分布式存储 |
| 节点监控 | node-exporter(Prometheus) | 需要从每个节点收集硬件和操作系统级别的监控指标 |
| 日志收集 | fluentd, logstash, Filebeat | 需要在每个节点上运行一个代理,统一收集该节点上所有容器的日志 |
| 网络插件 | flannel, calico | 需要在每个节点上运行网络代理/守护进程,以管理 Pod 间的网络通信 |
关键特性与工作原理
-
自动绑定节点,绕过调度器:
-
这是 DaemonSet 与 Deployment/ReplicaSet 的根本区别 。DaemonSet 在创建 Pod 时,会直接指定 Pod 运行在哪个节点上(通过
.spec.nodeName),完全不经过 Kubernetes 默认调度器。 -
这意味着:即使节点被标记为
unschedulable(不可调度),DaemonSet 的 Pod 依然可以部署上去。即使集群的调度器(kube-scheduler)还未启动,DaemonSet 的 Pod 也能被创建。
-
-
自动跟随节点生命周期:
-
节点加入集群 -> 自动在该节点上创建一个 Pod。
-
节点从集群移除 -> 自动删除该节点上的 Pod。
-
删除 DaemonSet 对象 -> 删除它创建的所有 Pod。
-
-
如何保证"一节点一 Pod":
-
控制器流程:DaemonSet 控制器持续监听集群中所有节点的变化。
-
获取所有节点列表。
-
根据 Pod 模板和节点的污点/容忍等配置,判断 Pod 是否能运行在该节点上。
-
检查节点上是否已有符合要求的 Pod。
-
没有 -> 创建。
-
有且只有一个 -> 保持。
-
有多个 -> 删除多余的(确保唯一)。
-
-
Pod 损坏时,在原节点上重建。
-
-
-
更新策略:
-
RollingUpdate(默认):滚动更新。更新时,DaemonSet 会按节点顺序(默认随机)逐节点替换 Pod。 -
OnDelete:手动删除 Pod 后,DaemonSet 才会用新模板创建新的 Pod。适用于需要精确控制更新节奏的场景。
-

一句话总结 :当你需要在集群的每个节点上都运行一个相同的、提供节点级服务 的 Pod 时,就使用 DaemonSet。