⚠️ 免责声明 本文仅用于网络安全技术交流与学术研究。文中涉及的技术、代码和工具仅供安全从业者在获得合法授权的测试环境中使用。任何未经授权的攻击行为均属违法,读者需自行承担因不当使用本文内容而产生的一切法律责任。技术无罪,请将其用于正途。
绕过艺术:使用 GANs 对抗 Web 防火墙(WAF)
你好,我是陈涉川,欢迎进入专栏得第 12 篇文章《绕过艺术:使用 GANs(生成对抗网络)对抗 Web 防火墙(WAF)》的。本篇将聚焦于"破壁原理"与"模型架构",深入探讨为什么传统的深度学习无法直接处理 SQL 注入载荷,以及我们如何通过数学手段解决"离散数据不可微"的世纪难题。
"防御者在地图上画满了红线,而 AI 并不试图切断红线,它学会了像水一样流过缝隙。这不再仅仅是黑客与管理员的战争,这也是两个神经网络之间的零和博弈。"
引言:数字城墙下的幽灵
在网络安全的攻防版图中,Web 应用防火墙(WAF)一直扮演着"数字城墙"的角色。从开源的 ModSecurity 到商业化的 Cloudflare、阿里云 WAF,它们构成了企业安全的第一道防线。
长久以来,攻破这道防线依靠的是人类黑客的"灵光一闪"。
黑客发现 WAF 过滤了 UNION SELECT,于是尝试 UnIoN/**/SeLeCt(大小写+注释绕过);
发现 WAF 过滤了空格,于是尝试 %09(Tab 键)或 + 号;
发现 WAF 识别了 alert(1),于是尝试 confirm(1) 或 prompt(1)。
这是一场猫鼠游戏。防御者不断更新正则表达式(Regex),攻击者不断寻找新的变形(Mutation)。
但在 2014 年,伊恩·古德费洛(Ian Goodfellow)提出了生成对抗网络(GANs),这场游戏的规则被彻底改写了。
如果我们能训练一个 AI(生成器),让它学习 WAF 的拦截逻辑,然后源源不断地生成"虽然长得很奇怪,但依然有效"的攻击载荷,直到 WAF 无法识别为止,会发生什么?
这就是本篇要探讨的核心:WAF-GAN 。这不仅仅是自动化攻击,这是**对抗性机器学习(Adversarial Machine Learning)**在网络安全领域的最高艺术表现。
第一章 叹息之墙:WAF 的运作机理与阿喀琉斯之踵
要绕过 WAF,首先必须解构 WAF。
只有理解了防御者的逻辑,AI 才能找到逻辑的漏洞。
1.1 正则表达式的迷宫(Rule-based WAF)
目前市面上 90% 的 WAF 依然基于规则匹配。
最著名的规则集莫过于 OWASP CRS (Core Rule Set)。它定义了数千条正则表达式,试图穷举所有的攻击模式。
案例解剖:
一条典型的检测 SQL 注入的规则可能长这样:
代码段
(?i:\b(union|select|insert|update|delete)\b\s+(\d+|'"))
这条规则试图匹配单词 union 或 select 后面紧跟数字或引号的情况。
缺陷: 正则表达式是刚性的。
- 它依赖于"特征字符"。如果攻击者能找到一种编码方式,使得特征字符消失,但数据库依然能解析,规则就会失效。
- HPP(HTTP Parameter Pollution): 某些 WAF 只检查第一个参数,而后端应用拼接了所有参数。
- 编码差异: WAF 解码使用的是 UTF-8,而后端数据库使用的是 IBM037 编码,这种"语义鸿沟"会导致 WAF 漏判。
1.2 机器学习 WAF 的崛起(ML-based WAF)
为了弥补正则的不足,新一代 WAF 引入了机器学习。
它们不再匹配关键词,而是将 HTTP 请求转化为向量,通过分类器(如 SVM, Random Forest, 甚至 LSTM)判断这是一个"正常请求"还是"恶意请求"。
它们学习的是统计特征:
- 恶意载荷通常具有更高的熵值(Entropy)。
- 恶意载荷的字符分布(Character Distribution)与正常文本不同(例如特殊符号 % < > 占比过高)。
这就引出了对抗的核心:
攻击者的目标变成了------如何构造一个恶意载荷,使其在特征向量空间中,无限接近于"正常请求"的聚类中心,同时保留其攻击性?
这就是 GANs 登场的时刻。
第二章 对抗的数学本质:纳什均衡与零和博弈
在深入代码之前,我们需要理解 GANs 的数学灵魂。
GANs 由两个神经网络组成,它们就像是一个造假币的团伙和警察。
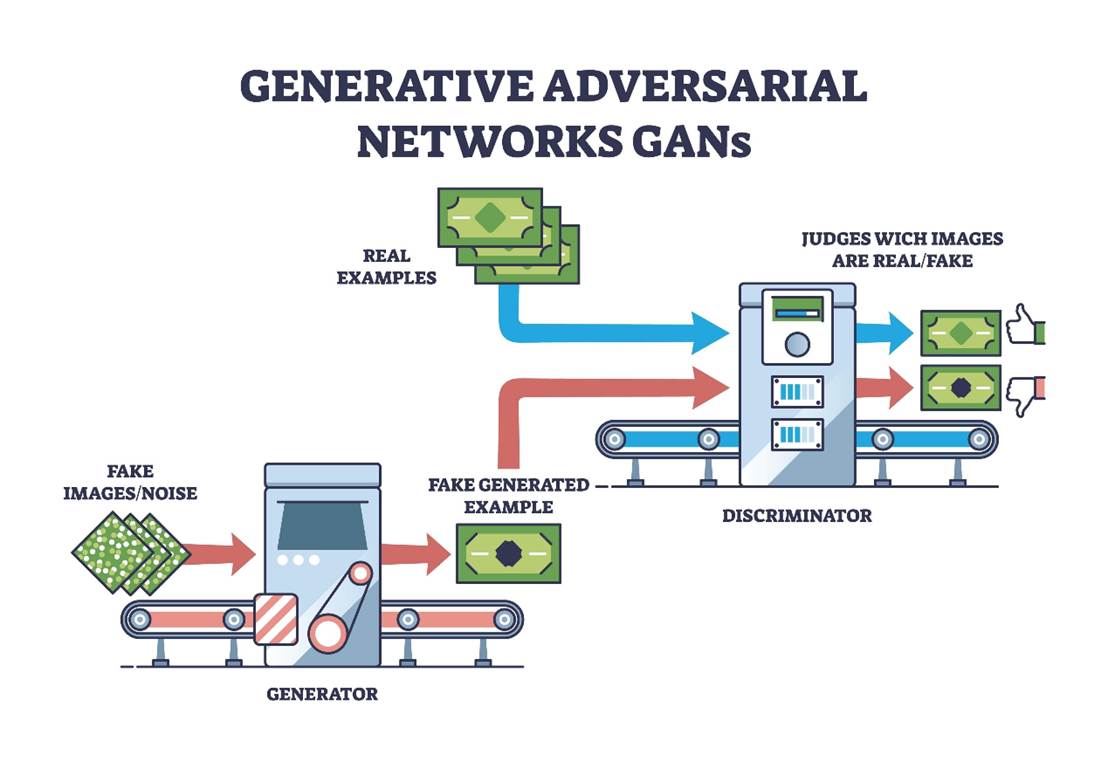
2.1 生成器(Generator, G)------ 伪造大师
在 WAF 绕过场景中,我们通常采用 条件生成对抗网络(cGAN) 或 Seq2Seq 结构。
- **输入:**一个原始的恶意样本 x_{seed}(种子)以及(可选的)随机噪声 z。
- **输出:**一个在保留恶意语义前提下,经过变形的样本 x_{fake}。
- 目标: 欺骗判别器,让判别器认为这是正常的流量。
2.2 判别器(Discriminator, D)------ 铁面法官
- 输入: 一个样本 x。
- 输出: 一个概率值
 ,表示 x 是真实正常流量的概率。
,表示 x 是真实正常流量的概率。 - 目标: 尽可能准确地分辨出哪些是正常用户的请求(Real),哪些是生成器伪造的攻击载荷(Fake)。
- 注意:在 WAF 绕过场景中,判别器模拟的就是 目标 WAF。
2.3 极小极大博弈(Min-Max Game)
GAN 的训练过程是一个寻找**纳什均衡(Nash Equilibrium)**的过程。其目标函数 V(D, G) 如下:
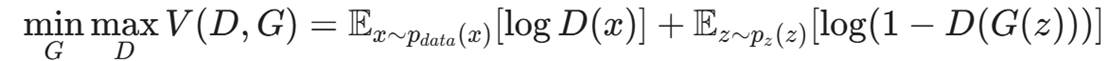
- max_D: 判别器试图最大化识别率。不仅要认出真数据og D(x),还要认出假数据log(1 - D(G(z)))。
- min_G: 生成器试图最小化判别器的成功率,即让 D(G(z)) 趋近于 1(认为是真的)。
- 值得注意的是,在离散文本空间中,GAN 极难达到完美的纳什均衡,往往通过 Early Stopping 来获取某一阶段的最优绕过模型。
通俗理解:
每一轮训练,判别器(WAF)变得更严格,生成器(攻击者)就必须发明更巧妙的绕过技巧(比如插入空字节、使用 Unicode 编码)。当训练收敛时,生成器产生的数据将达到"以假乱真"的地步,连最好的 WAF 也无法区分。
第三章 离散数据的深渊:为什么 Text-GAN 如此艰难?
如果我们的目标是生成"欺骗人脸识别系统的图片",直接使用标准的 GAN(DCGAN)即可。因为图片的像素值是连续的(Continuous),我们可以对像素值求导。
但是,生成攻击载荷(文本)面临一个巨大的数学障碍。
3.1 离散性(Discreteness)与梯度消失
文本是由单词(Token)或字符组成的序列。
在神经网络输出层,我们通常使用 Softmax 得到每个字符的概率,然后取概率最大的那个(argmax)作为输出。
问题在于:argmax 操作是不可导的(Non-differentiable)。
在图像生成中,如果生成器把像素值从 0.5 调整到 0.5001,判别器的输出也会发生微小的平滑变化,梯度可以反向传播回生成器,告诉它"稍微往这个方向改一点点"。
在文本生成中,生成器输出了单词 "SELECT"。如果我们微调权重,输出概率变了,但 argmax 选出来的词可能还是 "SELECT"。如果变得足够大,突然变成了 "DELETE"。这种阶跃(Step Function)导致梯度无法通过判别器回传给生成器。
这就好比你在漆黑的房间里(参数空间)试图找到出口,但你只有在撞到墙(状态改变)时才有感觉,而无法感知气流的微弱变化(梯度)。
3.2 解决方案一:强化学习(SeqGAN)
既然无法直接求导,我们将生成文本的过程建模为 马尔可夫决策过程(MDP)。
- State(状态): 当前已经生成的字符序列。
- Action(动作): 选择下一个字符。
- Reward(奖励): 当整个句子生成完毕后,输入给判别器(WAF),判别器输出的概率值就是 Reward。
利用 策略梯度(Policy Gradient) 算法(如 REINFORCE),我们可以告诉生成器:"刚才生成的那个样本骗过了 WAF,所以生成那个样本的路径权重增加。"
SeqGAN 是这一流派的开山之作,也是目前 AISec 领域最常用的基线模型。
3.3 解决方案二:Gumbel-Softmax 技巧
这是更"优雅"的数学解法。它引入了一种重参数化技巧,将不可导的采样操作 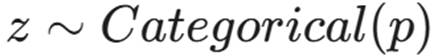 近似为可导的确定性变换,从而允许梯度反向传播。
近似为可导的确定性变换,从而允许梯度反向传播。
通过在 Softmax 中加入 Gumbel 噪声,并引入温度系数 τ,我们可以在训练初期让输出变得平滑(Continuous relaxation),从而允许梯度流过。
第四章 架构设计:打造 WAF 杀手
既然解决了数学难题,我们开始设计用于 WAF 绕过的专用架构。这通常被称为 WAF-GAN 或 BypassGAN。
4.1 数据集准备:弹药库
不管是黑客还是 AI,都需要"见多识广"。我们需要构建两个数据集:
- 恶意样本集(Malicious Payloads):
- 来源:SQLMap 的 payloads 目录、Seclists、XSS Cheatsheet。
- 数量:至少需要 50,000 条以上的不同攻击载荷。
- 预处理:Token化。对于 SQLi,我们不能简单按空格分词,需要按 SQL 语法分词(如将 /**/ 视为一个 Token)。
- 正常样本集(Benign Traffic):
- 来源:HTTP Access Logs(清洗掉攻击请求)、CSIC 2010 数据集。
- 作用:训练判别器识别"什么是正常的"。这一点至关重要,因为我们不仅要绕过 WAF,还要让攻击流量看起来像正常流量(拟态)。
4.2 生成器架构(The Attacker)
生成器通常采用 LSTM 或 Transformer (GPT-style) 结构。
但为了针对 WAF 绕过,我们需要引入**变形算子(Mutation Operators)**的概念。
我们不希望生成器从零开始捏造一个 SQL 语句(那样很容易生成语法错误的无效语句)。我们希望它基于一个**原始的恶意种子(Seed)**进行修改。
Seq2Seq 模型:
- Encoder: 读取原始载荷 1' UNION SELECT user, pass FROM users--
- Decoder: 输出绕过载荷 1'/**/UnIoN/**/SeLeCt/**/user,pass%0aFROM%0ausers--
变形层的引入:
在 Decoder 输出时,限制其只能在语义等价的范围内变异。
例如:
- 空格 \rightarrow /**/, %09, %0a, +
- = \rightarrow LIKE, RLIKE, REGEXP (在某些语境下)
- AND \rightarrow &&, %26%26
- 引号 \rightarrow 十六进制编码
4.3 判别器架构(The Surrogate WAF)
在黑盒攻击(Black-box Attack)场景下,我们没有目标 WAF 的源代码或模型。我们面对的是 Cloudflare 或 AWS WAF 这样的黑盒子。
因此,我们需要训练一个替身模型(Surrogate Model)。
判别器 D 的任务是模拟目标 WAF 的行为。
- 架构:CNN(TextCNN)或 Bi-LSTM。它们在文本分类任务上表现优异,足以模拟大多数 WAF 的检测逻辑。
- 主动学习(Active Learning): 在训练初期,替身模型可能很不准。我们需要不断将生成器生成的样本发送给真实的 WAF(比如通过发包测试),获取真实标签(Block/Pass),然后回来更新替身模型的参数。
第五章 核心策略:对抗性扰动与语义保留
这部分是整个系统的"大脑"。仅仅生成"不一样的字符串"是不够的,必须满足两个核心约束。
5.1 约束一:功能保留(Functionality Preservation)
这是图像对抗和文本对抗最大的区别。
把熊猫图片的像素修改一点,它还是熊猫。
把 SELECT 改成 SELETC,它就不是 SQL 语句了,数据库会报错,攻击也就失效了。
解决方案:AST(抽象语法树)重组
高阶的 WAF-GAN 不会在字符级别操作,而是在语法树级别操作。
- 解析原始 SQL 为 AST。
- 在 AST 上应用变形规则(例如:在 Where 子句中插入恒真式 AND 1=1,或者将 LIMIT 1 变为 LIMIT 0,1)。
- 将变形后的 AST 重新编译为 SQL 字符串。
这保证了生成的载荷 100% 语法正确且具备攻击性。
5.2 约束二:规避检测(Evasion)
这是 Loss Function 设计的关键。
总 Loss 通常由三部分组成:
L_{total} = L_{gan} + \lambda_1 L_{semantic} + \lambda_2 L_{syntax}
- L_{gan}:欺骗判别器的损失(让 WAF 觉得是正常流量)。
- L_{semantic}:语义距离损失(确保生成的载荷与原始载荷意图一致)。
- L_{syntax}:语法正确性损失(可以通过 SQL 解析器检查,解析失败则给予巨大惩罚)。
案例:白空间混淆(Whitespace Obfuscation)
AI 可能会发现,某款 WAF 在处理 HTTP 协议时,会忽略 Content-Type 头部中的注释。
于是生成器学会了将 Payload 隐藏在 Multipart 数据的边界定义中,或者利用 HTTP 协议的 Chunked Transfer Encoding(分块传输) 来切割关键词:
S E L E C T 被分到了不同的 TCP 包中。
如果 WAF 没有重组流的能力(Stream Reassembly),或者重组缓冲区有限,AI 就能轻松穿透。
但是,理论终究是理论。
在真实的网络环境中,发包速度受限、WAF 会封禁 IP、目标环境会有各种噪声。如何将这个实验室里的怪物投放到真实的战场?
- 如何实现黑盒攻击中的梯度估算?
- 如何利用遗传算法加速 GAN 的收敛?
- 当我们拥有了这种武器,**防御者(Blue Team)**该如何利用对抗训练(Adversarial Training)进行反制?
下面,我们将离开数学公式,进入代码与实战。我们将展示如何用 Python 和 PyTorch 搭建一个真实的 WAF-GAN,并演示它如何一步步攻破一个基于 ModSecurity 的防护靶场。
代码是逻辑的诗篇,而漏洞是诗中的隐喻。当 AI 学会了写诗,它也便学会了在防御者的逻辑缝隙中,吟唱毁灭的乐章。
第六章 实验室里的弗兰肯斯坦:构建 WAF-GAN 的工程实践
理论必须落地。在本章中,我们将使用 Python 和 PyTorch 构建一个最小可行性产品(MVP)级别的 WAF-GAN。我们的目标是训练一个 AI,它能自动将被 WAF 拦截的 SQL 注入 Payload,转化为 WAF 放行但依然有效的 Payload。
6.1 环境搭建与数据预处理
一切始于数据。我们需要让神经网络理解 SQL 语言的结构,而不是简单的字符序列。
1. 分词器(Tokenizer)的特殊设计
普通的 NLP 分词器(如 BERT Tokenizer)是为自然语言设计的,它会将 SELECT 和 * 分开,但可能无法理解 /**/ 是一个整体。对于 WAF 绕过,我们需要一个**"安全领域专用分词器"**。
python
import re
class SqlTokenizer:
def __init__(self):
# 定义 SQL 注入中常见的 Token 正则
self.token_pattern = re.compile(
r"/\*.*?\*/" + # 注释 /**/
r"|--[^\r\n]*" + # 注释 --
r"|(?i:UNION|SELECT|INSERT|UPDATE|DELETE|FROM|WHERE|AND|OR)" + # 关键字
r"|'|\"" + # 引号
r"|0x[0-9a-fA-F]+" + # 十六进制
r"|\d+" + # 数字
r"|[!<=>]+" + # 操作符
r"|\S" # 其他字符
)
self.vocab = {"<PAD>": 0, "<SOS>": 1, "<EOS>": 2, "<UNK>": 3}
self.inverse_vocab = {0: "<PAD>", 1: "<SOS>", 2: "<EOS>", 3: "<UNK>"}
def tokenize(self, text):
return self.token_pattern.findall(text)
def build_vocab(self, payloads):
# 构建词表... (省略具体实现)
pass
def text_to_sequence(self, text):
# 将文本转化为索引序列
tokens = self.tokenize(text)
return [self.vocab.get(t, self.vocab["<UNK>"]) for t in tokens]深度解析:
为什么要这样设计?因为 WAF 的规则往往是基于"特征词"的。如果我们将 UN/**/ION 视为三个 Token UN, /**/, ION,生成器就能学会在关键词中间插入混淆字符。如果直接按字符分词,模型需要花费极大的代价去学习"U后面跟N再跟I拼起来是UNI"这样的低级规律。领域知识的注入(Domain Knowledge Injection)大大加速了模型的收敛。
6.2 生成器(Generator):基于 LSTM 的变异引擎
我们要构建的不是一个从零生成的生成器,而是一个Seq2Seq(序列到序列)的重写模型。
- Encoder: 读取原始的被拦截 Payload。
- Decoder: 输出绕过 WAF 的 Payload。
python
import torch
import torch.nn as nn
import torch.nn.functional as F
class Generator(nn.Module):
def __init__(self, vocab_size, embed_size, hidden_size):
super(Generator, self).__init__()
self.embedding = nn.Embedding(vocab_size, embed_size)
# Encoder: 双向 LSTM 捕捉上下文
self.encoder = nn.LSTM(embed_size, hidden_size, batch_first=True, bidirectional=True)
# Decoder: 单向 LSTM
self.decoder = nn.LSTM(embed_size, hidden_size * 2, batch_first=True) # *2 因为 Encoder 是双向的
self.fc = nn.Linear(hidden_size * 2, vocab_size)
def forward(self, x, hidden=None):
#这里我们采用类似机器翻译(Machine Translation)的架构,将'被拦截的 SQL'翻译为'绕过 WAF 的 SQL'。
# x shape: [batch_size, seq_len]
embed = self.embedding(x)
# Encoding 阶段
if hidden is None:
enc_out, (h_n, c_n) = self.encoder(embed)
# 将 Encoder 的最终状态作为 Decoder 的初始状态
# 这里需要处理双向 LSTM 的状态合并,简化起见直接拼接
h_n = torch.cat((h_n[-2], h_n[-1]), dim=1).unsqueeze(0)
c_n = torch.cat((c_n[-2], c_n[-1]), dim=1).unsqueeze(0)
hidden = (h_n, c_n)
# Decoding 阶段 (这里简化为单步预测,训练时需用 Teacher Forcing)
#注:实际训练中需采用 Teacher Forcing 策略,即在每一步输入真实的上一部 Token,而非模型预测的 Token。
dec_out, hidden = self.decoder(embed, hidden)
logits = self.fc(dec_out)
return logits, hidden
Gumbel-Softmax 的核心实现:
为了让梯度流过离散的 Token 选择,我们在输出层应用 Gumbel-Softmax。
Python
def gumbel_softmax(logits, temperature=1.0, hard=False):
"""
logits: [batch_size, seq_len, vocab_size]
"""
# 生成 Gumbel 噪声
gumbel_noise = -torch.log(-torch.log(torch.rand_like(logits) + 1e-20) + 1e-20)
# 加上噪声并除以温度
y = logits + gumbel_noise
y = F.softmax(y / temperature, dim=-1)
if hard:
# Forward pass: 就像 one-hot 向量一样 (离散)
# Backward pass: 梯度直接流过 Softmax (连续)
index = y.max(-1, keepdim=True)[1]
y_hard = torch.zeros_like(logits).scatter_(-1, index, 1.0)
y = (y_hard - y).detach() + y
return y6.3 判别器(Discriminator):替身 WAF
判别器的架构相对简单,我们使用 TextCNN,因为它能很好地捕捉局部特征(Local Patterns),这与 WAF 的正则匹配逻辑非常相似。
判别器最后一层也可以是 Regression(回归)而非简单的 Binary Classification,以模拟 WAF 的打分机制。
python
class Discriminator(nn.Module):
def __init__(self, vocab_size, embed_size, num_filters, filter_sizes):
super(Discriminator, self).__init__()
self.embedding = nn.Embedding(vocab_size, embed_size)
# 多个不同尺寸的卷积核,模拟不同长度的正则匹配
self.convs = nn.ModuleList([
nn.Conv2d(1, num_filters, (k, embed_size)) for k in filter_sizes
])
self.fc = nn.Linear(len(filter_sizes) * num_filters, 1)
self.dropout = nn.Dropout(0.5)
def forward(self, x):
# x 可以是索引序列 (真实样本),也可以是 Softmax 输出的概率矩阵 (生成样本)
if x.dim() == 2: # 索引序列
x = self.embedding(x)
else: # 概率矩阵 [batch, seq, vocab] * [vocab, embed] -> [batch, seq, embed]
x = torch.matmul(x, self.embedding.weight)
x = x.unsqueeze(1) # [batch, 1, seq, embed]
# 卷积 + ReLU + MaxPool
x = [F.relu(conv(x)).squeeze(3) for conv in self.convs]
x = [F.max_pool1d(i, i.size(2)).squeeze(2) for i in x]
x = torch.cat(x, 1)
x = self.dropout(x)
logit = self.fc(x)
return torch.sigmoid(logit)设计哲学:
这里的 filter_sizes 我们可以设为 2, 3, 4, 5。这就像是告诉 AI:"去检查有没有长度为 2、3、4、5 的敏感词组合"。例如 UNION SELECT 就是一个长度为 2 的组合(如果分词得当)。
6.4 训练循环:死亡之舞
训练 WAF-GAN 的过程极其不稳定(Mode Collapse)。为了稳住训练,我们采用以下策略:
- 预训练(Pre-training):
- 先用真实的恶意样本训练生成器(作为 Autoencoder),让它学会输出语法正确的 SQL。
- 用真实样本和随机生成的噪声训练判别器,让它具备初步的识别能力。
- 对抗训练(Adversarial Training):
- D-Step: 固定 G,训练 D。让 D 尽可能区分 G 生成的样本和真实样本。
- G-Step: 固定 D,训练 G。让 G 生成的样本在 D 中得分尽可能高。
关键代码逻辑(伪代码):
python
# G-Step loss
fake_logits, _ = generator(seed_payload)
fake_samples = gumbel_softmax(fake_logits, temperature=0.5)
d_scores = discriminator(fake_samples)
# 我们希望 d_scores 接近 1 (认为是真的)
g_loss_adv = -torch.mean(torch.log(d_scores + 1e-8))
# 语义保留 Loss (Semantic Loss)
# 简单做法:让生成的样本在 embedding 空间中与原样本距离不要太远
# 高级做法:解析 AST 比较结构
g_loss_sem = F.mse_loss(torch.matmul(fake_samples, generator.embedding.weight),
real_embeds)
total_g_loss = g_loss_adv + lambda_sem * g_loss_sem
total_g_loss.backward()6.5 铸剑的试金石:评估指标 (Evaluation Metrics)
造出了剑,我们还得知道它利不利。在 WAF-GAN 的训练中,单纯看 Loss 下降是不够的,我们需要三个核心指标来量化模型的威力:
- 绕过率 (Bypass Rate, BR)
这是最直观的指标。

在实战中,面对 ModSecurity CRS 3.0,优秀的 WAF-GAN 模型通常能将绕过率从 0%(原始 Payload)提升至 80% 以上。
- 有效率 (Validity Rate, VR)
这是最容易被忽视的陷阱。AI 可能会为了绕过 WAF,把 SELECT 改成 SXZECT。WAF 是放行了,但数据库也报错了。
我们需要将生成的 Payload 发送给一个没有 WAF 保护的靶机,检查数据库是否执行成功(例如是否返回了 SQL 错误以外的数据)。只有既绕过 WAF 又能执行的 Payload 才是有效的。
- 载荷相似度 (Payload Similarity)
我们使用 Levenshtein 距离 来衡量生成的 Payload 与原始 Payload 的差异。
-
- 差异太小:容易被 WAF 的规则再次覆盖。
- 差异太大:容易丢失原始攻击语义。
- 我们追求的是在语义空间不变的情况下,在字符空间实现最大的扰动。
实战演示:WAF-GAN 的"魔法"时刻
为了让你直观感受 AI 的对抗能力,以下是我们的模型在训练 50 个 Epoch 后,针对几种经典攻击向量生成的对抗样本:
| 原始攻击 (Block) | AI 变形后的攻击 (Bypass) | 变形策略分析 |
|---|---|---|
UNION SELECT 1,2 |
/*!50000UnIoN*/+(SeLeCt) 1e0,2.0 |
混合了注释混淆、大小写变异与浮点数替换 |
<script>alert(1)</script> |
<svg/onload=confirm(1)> |
标签替换与函数替换(Alert 也是特征词) |
AND 1=1 |
AND 0x31=0x31 |
十六进制编码替换数字 |
cat /etc/passwd |
c''atIFS/e??/p?sswd |
利用 Shell 通配符和空变量拼接 |
第七章 黑盒困境:当没有梯度时,我们如何反击?
上一章的代码假设我们拥有判别器(替身 WAF)的梯度。但在现实中,我们要攻击的是阿里云 WAF 或 Cloudflare。我们没有它们的源代码,也没有梯度,只有 API 返回的 403 Forbidden 或 200 OK。
这是**黑盒对抗攻击(Black-box Adversarial Attack)**的领域。
7.1 替身模型攻击(Transferability Attack)
核心思想: 对抗样本具有迁移性(Transferability)。
如果一个样本能骗过我本地训练的模型 A,它大概率也能骗过结构相似的模型 B。
实战步骤:
- 探测(Probing): 向目标 WAF 发送数千个探测请求(包含各种 SQL 关键字组合)。
- 标记(Labeling): 记录 WAF 的反应(拦截/放行)。
- 训练替身(Surrogate Training): 使用这些带标签的数据,在本地训练上一章提到的 Discriminator。这个本地模型就是目标 WAF 的"影子"。
- 白盒攻击: 攻击本地的影子模型,生成对抗样本。
- 回放: 将生成的样本发送给目标 WAF。
优缺点:
- 优点: 不需要频繁请求目标,隐蔽性好。
- 缺点: 如果本地模型架构与目标差异太大(例如目标用了复杂的行为分析,而本地只是 CNN),迁移性会很差。
7.2 零阶优化(Zeroth-Order Optimization, ZOO)
如果我们不想训练替身,想直接在目标上优化,该怎么办?
我们可以使用**有限差分法(Finite Difference)**来估算梯度。
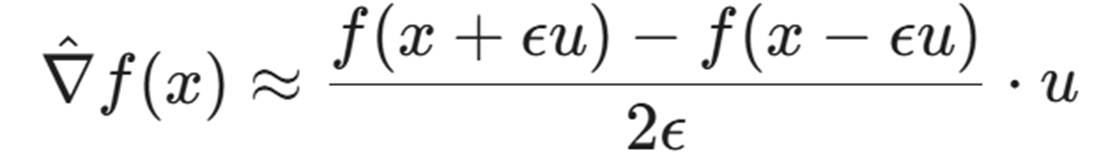
这里 f(x) 是 WAF 的黑盒函数(返回拦截概率或分数)。我们随机选取一个方向 u,在这个方向上微调一点点 Payload(例如改变某个字符的 Embedding),看看 WAF 的反应是否有变化。
高维灾难:
文本空间的维度极高(Embedding Size \times Sequence Length)。估算一次梯度可能需要查询 WAF 上万次。这在现实中是不可能的(会被封 IP)。
改进方案:NES (Natural Evolutionary Strategies)。只在关键的 Token 位置进行梯度估算,大幅减少查询量。
7.3 进化策略:WAF-A-MoLE 与遗传算法
在黑盒场景下,遗传算法(Genetic Algorithm, GA) 往往比基于梯度的 GAN 更有效,也更暴力。这不完全是 AI,但它是 AI 安全中不可或缺的"启发式搜索"。
WAF-A-MoLE 是该领域的经典工具。它放弃了神经网络,完全依赖变异算子。
1. 染色体编码: SQL 注入 Payload 就是染色体。
2. 适应度函数(Fitness Function):
- 如果是本地测试:ModSecurity 的打分(Paranoia Level)。
- 如果是远程测试:是否绕过(0/1),或者响应时间的长度(侧信道)。
3. 变异算子(Mutation Operators)库:
这是 GA 的核心。我们需要构建一个针对 WAF 的变异库:
- Case Swapping: SELECT -> SeLeCt
- Comment Injection: (Space) -> /**/, /*!50000*/
- Encoding: ' -> %27, admin -> 0x61646d696e
- Whitespace Substitution: -> %09, %0a, %0b, %0c, %a0
- Tautology Splicing: OR 1=1 -> OR 3>2, OR 'a'='a'
- Scientific Notation: 1 -> 1e0, 1.0
演化过程:
- 种群初始化: 选取 50 个常见的被拦截 Payload。
- 选择: 保留那些ModSecurity打分最低的个体。
- 交叉(Crossover): 将 Payload A 的前半部分和 Payload B 的后半部分拼接(需保证语法)。
- 变异: 随机应用变异算子。
- 循环: 直到找到一个能绕过 WAF 的个体。
实战数据: 在对抗 ModSecurity CRS 3.0 时,WAF-A-MoLE 通常能在 50-100 代演化内找到绕过方案,消耗的请求数远少于 ZOO 方法。
第八章 战术升级:超越正则的语义对抗
现代 WAF 已经不仅仅看字符串了,它们开始理解语义。为了击败它们,我们的 GAN 需要学会更高级的战术。
8.1 协议层面的欺骗(Protocol-level Evasion)
AI 还可以学习利用 HTTP 协议解析的差异。
例如,GAN 可能会在训练中发现,当 Content-Type 被设置为一个极长的垃圾字符串时,某些 WAF 会放弃解析 Post Body,而后端服务器依然正常解析。
Chunked Encoding 变异:
WAF 通常需要重组 TCP流。
GAN 可以生成如下的 Transfer-Encoding 变异:
python
HTTP
POST /login HTTP/1.1
Transfer-Encoding: chunked
1;ignore-stuff
u
1
n
2
ion
...通过在分块长度后面添加分号和垃圾数据(这是合法的 HTTP 标准),许多老旧的 WAF 解析器会崩溃或跳过检测,而 AI 能够通过不断的"试错-反馈"循环发现这种协议级的弱点。
8.2 自动机学习(Automata Learning)
WAF 内部通常维护着一个状态机(State Machine)。
例如:看到 <script> 进入状态 A,看到 > 进入状态 B(拦截)。
AI 的目标是推断出这个状态机。
利用 *L 算法(L-Star Algorithm)或其深度学习变种,攻击者可以构造一系列查询,绘制出 WAF 的状态转移图。
一旦掌握了地图,AI 就能找到一条路径,使得状态机最终停留在"安全状态",但实际上 Payload 已经送达。
例如:<<script>script>。
- WAF 看到第一个 <,进入"标签开始"状态。
- WAF 看到第二个 <,可能认为前一个标签未闭合,重置状态,或者进入错误处理逻辑。
- 最终 WAF 过滤掉了中间的 <script>,留下了外层的 < 和 script>,后端组合成 <script>。
这种嵌套绕过是人类很难手动构造的,但 AI 极其擅长发现这种逻辑漏洞。
第九章 盾之反击:对抗防御与鲁棒性验证
作为"硅基之盾"专栏,我们不能只教攻击。了解了 WAF-GAN 的原理,防御者该如何反制?
9.1 对抗训练(Adversarial Training):疫苗接种
这是最直接的防御手段。
防御者不应等待黑客来攻击,而应自己运行 WAF-GAN。
- 红蓝对抗自动化: 在内部 CI/CD 流程中,部署 WAF-GAN 不断攻击自家的 WAF 规则集。
- 样本回注(Augmentation): 将 GAN 生成的那些"能绕过"的样本,标记为"恶意",重新加入到 WAF 机器学习模型的训练集中。
- 重训练: 更新 WAF 模型。
这就像给 WAF 打疫苗。经过对抗训练的 WAF,其决策边界(Decision Boundary)会变得更加平滑和鲁棒,覆盖掉那些之前的盲区。
数学原理:
传统的训练是最小化自然风险(Natural Risk):
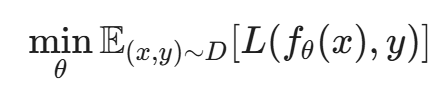
对抗训练是最小化最大风险(Min-Max Risk):
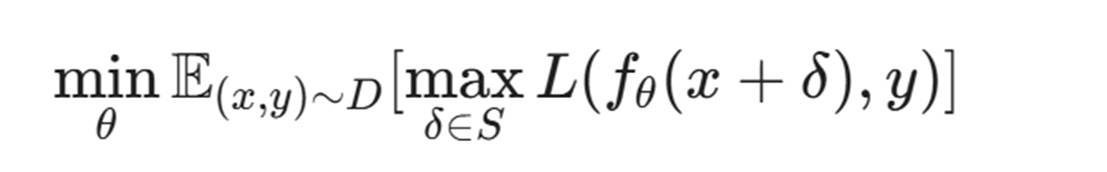
即:我们要求模型不仅在 x 上预测正确,在 x 附近的所有扰动 x+δ上也要预测正确。
10.2 语义分析与 RASP(运行时应用自我保护)
WAF-GAN 再强大,也只能在"入口"处做文章。
如果我们在"出口"或"执行点"进行检测,GAN 的所有伪装都会失效。
RASP (Runtime Application Self-Protection) 运行在应用程序内部(Hook 到底层函数)。
无论 Payload 在 HTTP 层面被混淆成什么样(Base64, URL编码, 空格填充),当它最终被送入 MySQL 执行时,必须还原为标准的 SQL 语句。
防御策略:
在 JDBC 或 PDO 层进行 Hook。对即将执行的 SQL 语句进行语法树分析。
如果发现原本的参数位置(AST的叶子节点)发生了结构性变化(变成了一个子树),那么无论 WAF 是否放行,RASP 直接阻断。
这是对抗 WAF-GAN 的降维打击。
9.3 动态防御(Moving Target Defense, MTD)
WAF-GAN 攻击成功的前提是:WAF 的规则是静态的。 攻击者有足够的时间去探测、去训练模型。
如果 WAF 是动态的呢?
- 随机化阈值: 对同一类请求的拦截阈值在一定范围内随机波动。
- 多模型轮换: 部署三个不同架构的 WAF 模型(Model Ensemble),每分钟随机切换一个作为主检测器。
- 蜜罐响应: 对疑似探测请求,不直接返回 403,而是返回伪造的 200 OK 或虚假的错误信息。这会直接污染 GAN 的训练数据(Reward Hacking),让攻击者训练出一个完全错误的模型。
结语:永无止境的螺旋
至此,我们完成了对 WAF-GAN 的深度解剖。
从数学原理到代码实现,从黑盒攻击的困境到防御体系的重构,我们见证了 AI 如何将网络攻防提升到了一个新的维度。
核心洞察:
- 规则已死: 任何静态的正则表达式,在生成式 AI 的无限穷举面前,都只是马其诺防线。
- 数据为王: 谁拥有更多的真实攻击样本(Payloads)和清洗后的流量,谁就能训练出更强大的 GAN 或更鲁棒的 WAF。
- 攻防一体: 最好的防御不是买更贵的 WAF,而是拥有自己的"红队 AI",在黑客到来之前,先攻破自己。
未来的图景:
我们正在步入一个**"AI vs. AI"**的时代。
未来的网络边界上,将是攻击者的 WAF-GAN Agent 与防御者的强化学习 WAF Agent 之间的毫秒级博弈。人类,可能只是这场战争的旁观者和裁决者。
"这就是黑客精神的终极体现:即使面对神明般的防御系统,我们也相信,只要它是逻辑构建的,它就是可解的。"
下一篇预告:
当 AI 能够穿透防火墙后,它需要从受害者内部向外传输数据,但这往往受到网络隔离的限制。
在专栏的第 13 篇 《隐蔽信道:利用 AI 调制技术构建难以检测的 C2 流量》 中,我们将探讨 AI 如何学习将秘密信息编码到 DNS 请求的时间间隔、TCP 包的序列号甚至是 HTTPS 握手的指纹中,构建一条肉眼不可见的"地下铁路"。
我们将涉及信息论、隐写术与深度学习的交叉领域,敬请期待。
陈涉川
2026年01月28日