2012 年,Alex Krizhevsky等人的AlexNet模型在ILSVRC(ImageNet Large Scale Visual Recognition Challenge)中取得了骄人的成绩,这一成果使得CNN成为了当时最先进的图像识别模型。2014年,VGGNet凭借着更深更宽的网络结构取得ILSVRC竞赛定位任务第一名。同年,GoogLeNet采用了能更高效利用计算资源的Inception模块,在ILSVRC的分类任务上击败VGGNet夺得冠军。2015年,Kaiming He等人提出的ResNet引入残差模块来解决深度神经网络训练时的网络退化问题,横扫当年的ILSVRC和COCO挑战赛。2017年,DenseNet模型发布,采用了密集连接结构,使得模型更加紧凑并且有更好的鲁棒性,斩获CVPR 2017的最佳论文奖。它们都是卷积神经网络发展史上的重要里程碑。
1. AlexNet
AlexNet基本思想
模型的设计是受到LeNet的启发的,但是它比LeNet要大得多,有5个卷积层和3个全连接层。它也引入了新的技术,例如使用ReLU激活函数代替Sigmoid激活函数,使用Dropout正则化以防止过拟合等。 AlexNet还是第一个在大型数据集上训练的卷积神经网络模型,它在ImageNet数据集上取得了很好的结果,并且在计算机视觉领域中引起了很大的关注。
AlexNet结构
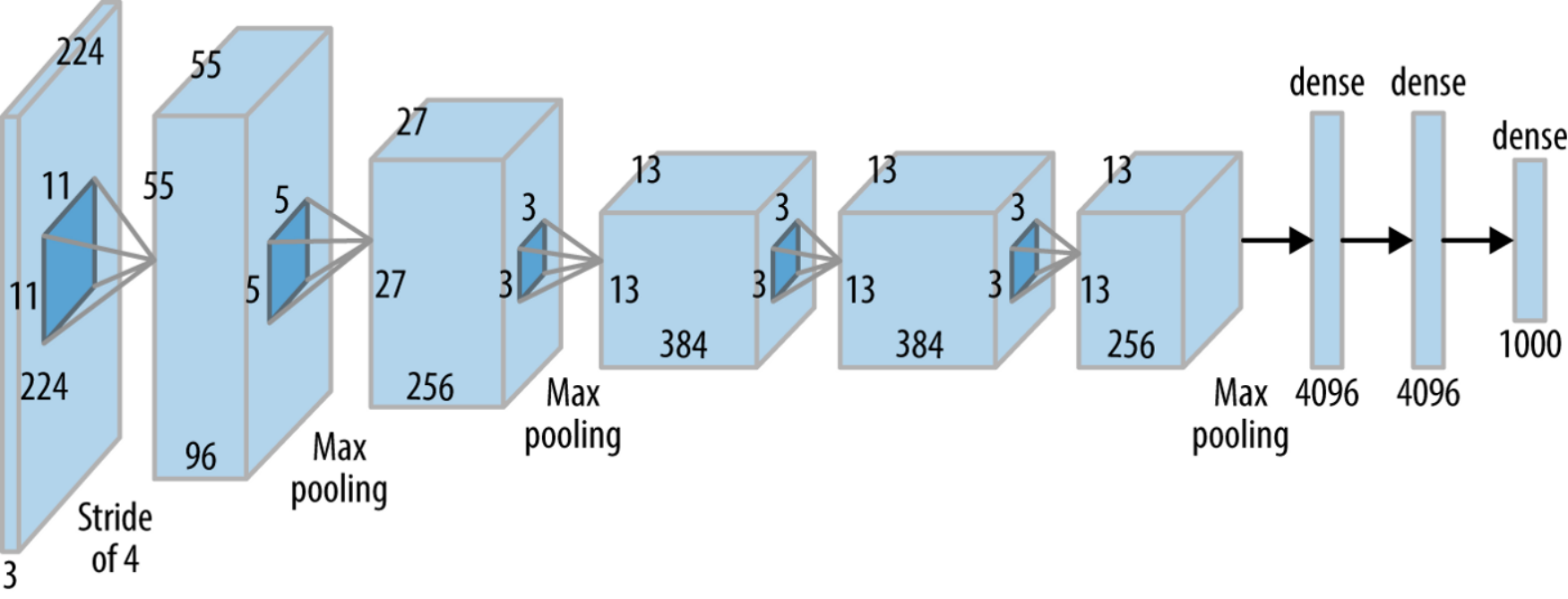
AlexNet是一个8层的卷积神经网络,其中包括5个卷积层和3个全连接层。
-
第一层是卷积层,用于提取图像的特征。它包括96个11x11步长为4的卷积核,并使用最大池化。
-
第二层是卷积层,包括256个5x5的卷积核,并使用最大池化。
-
第三、四、五层也是卷积层,分别包括384个3x3的卷积核,384个3x3的卷积核,和256个3x3的卷积核。这三层后面使用最大池化。
-
第六层是全连接层,包括4096个神经元。
-
第七层是全连接层,包括4096个神经元。
-
第八层是输出层,包括1000个神经元,用于预测图像属于ImageNet数据集中的哪一类。
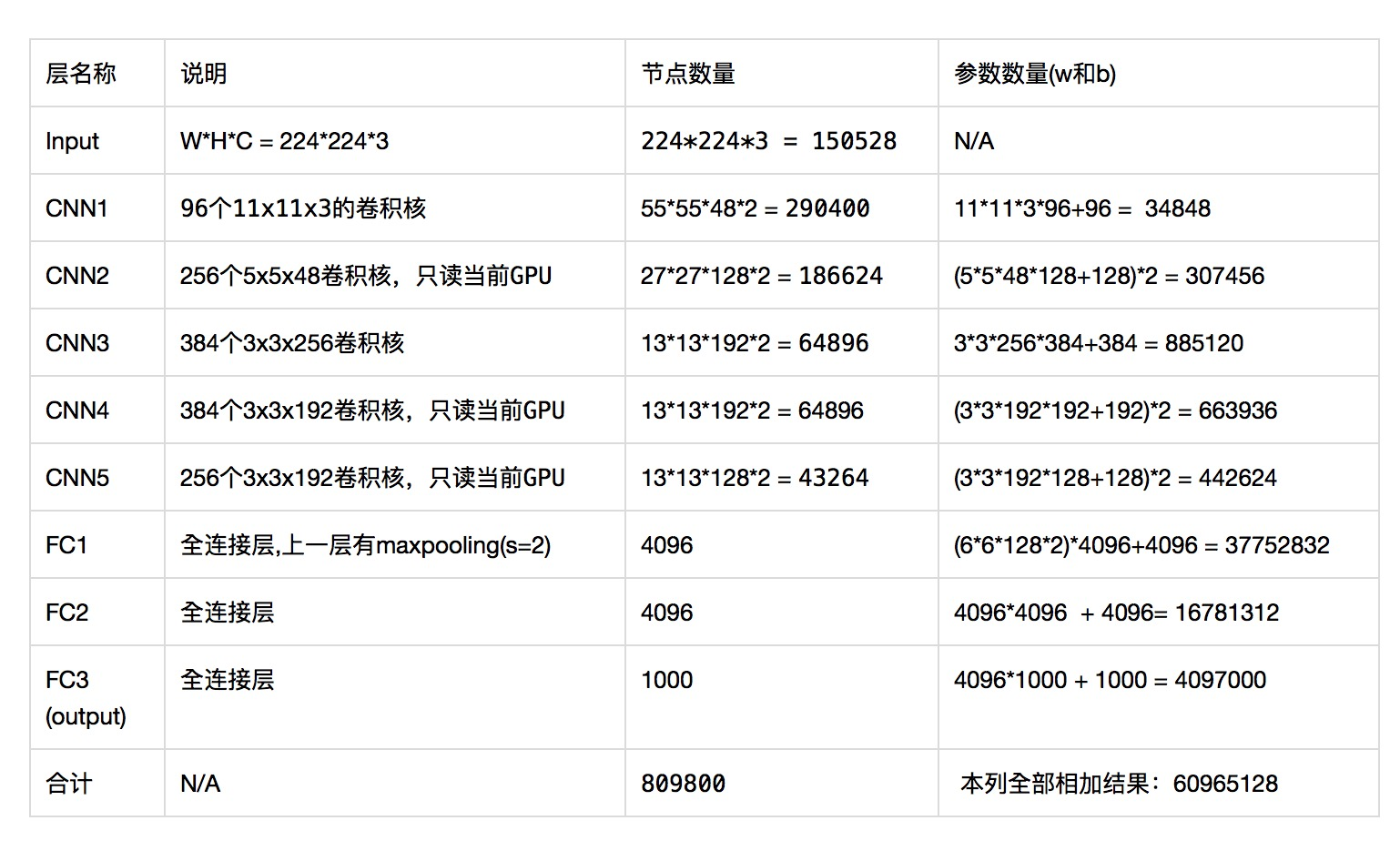
AlexNet参数量计算参考下图:
AlexNet代码实现
python
# 导入必要的库
import torch
import torch.nn as nn
# 定义AlexNet的网络结构
class AlexNet(nn.Module):
def __init__(self, num_classes=1000, dropout=0.5):
super().__init__()
# 定义卷积层
self.features = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=11, stride=4, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(64, 192, kernel_size=5, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(192, 384, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(384, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
)
# 定义全连接层
self.classifier = nn.Sequential(
nn.Dropout(p=dropout),
nn.Linear(256 * 6 * 6, 4096),
nn.ReLU(inplace=True),
nn.Dropout(p=dropout),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Linear(4096, num_classes),
)
def forward(self, x):
x = self.features(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x-
AlexNet是当时第一个在大型数据集上训练的卷积神经网络模型,使得卷积神经网络成为计算机视觉领域中可行的机器学习方法。
-
使用了ReLU激活函数,这使得训练更快且模型性能更好。
-
使用Dropout正则化,有利于防止过拟合。
-
在数据集上做了很多工作,引入数据增强,例如镜像以及随机剪裁等。
-
采用了一种局部响应归一化(Local Response Normalization, LRN)的方法进行处理。
2. VGGNet
VGGNet是Oxford的Visual Geometry Group的团队在ILSVRC 2014上的相关工作。
本文作者Karen Simonyan和Andrew Zisserman当时都是牛津大学工程科学系Visual Geometry Group成员,这也是VGG名字的由来。其中一作Karen后曾在DeepMind担任研究员,现在在一家研究AI人机交互的初创公司Inflection AI担任联合创始人兼首席科学家。二作Andrew Zisserman在牛津大学担任计算机视觉工程教授,同时是英国皇家学会教授。
从论文摘要中就能看出几个关键点的研究方向,论文主要研究卷积网络深度对模型的影响,使用3x3的小卷积,深度提升到11-19层。并且以此在2014年的ImageNet挑战赛在定位和分类问题中分获第一和第二,并且推广到其他数据集上同样取得了SOTA的结果。
同时VGGNet的拓展性很强,迁移到其他图片数据上的泛化性非常好。VGGNet的结构非常简洁,整个网络都使用了小尺寸的卷积核以及相同的池化尺寸(2x2)。到目前为止,VGGNet依然经常被用来提取图像特征,论文引用次数已经超过9万,被广泛应用于视觉领域的各类任务。
VGGNet基本思想
它的主要思想其实是在于解决了以下几个问题:
-
在当时的卷积神经网络模型中,网络深度越深,表现就越好,但同时也会带来较大的计算复杂度和较高的模型大小。VGGNet通过设计一种更深但同时较小的卷积神经网络,解决了这一问题。
-
在训练过程中,卷积神经网络容易出现过拟合的问题,导致泛化能力较差。VGGNet通过设计合理的网络结构和使用较小的卷积核,提高了模型的泛化能力。
-
在计算机视觉任务中,网络的计算效率是一个很重要的问题。VGGNet通过使用小核卷积和简单的网络结构,在保证较高的精度的同时,提高了模型的计算效率。
VGGNet结构
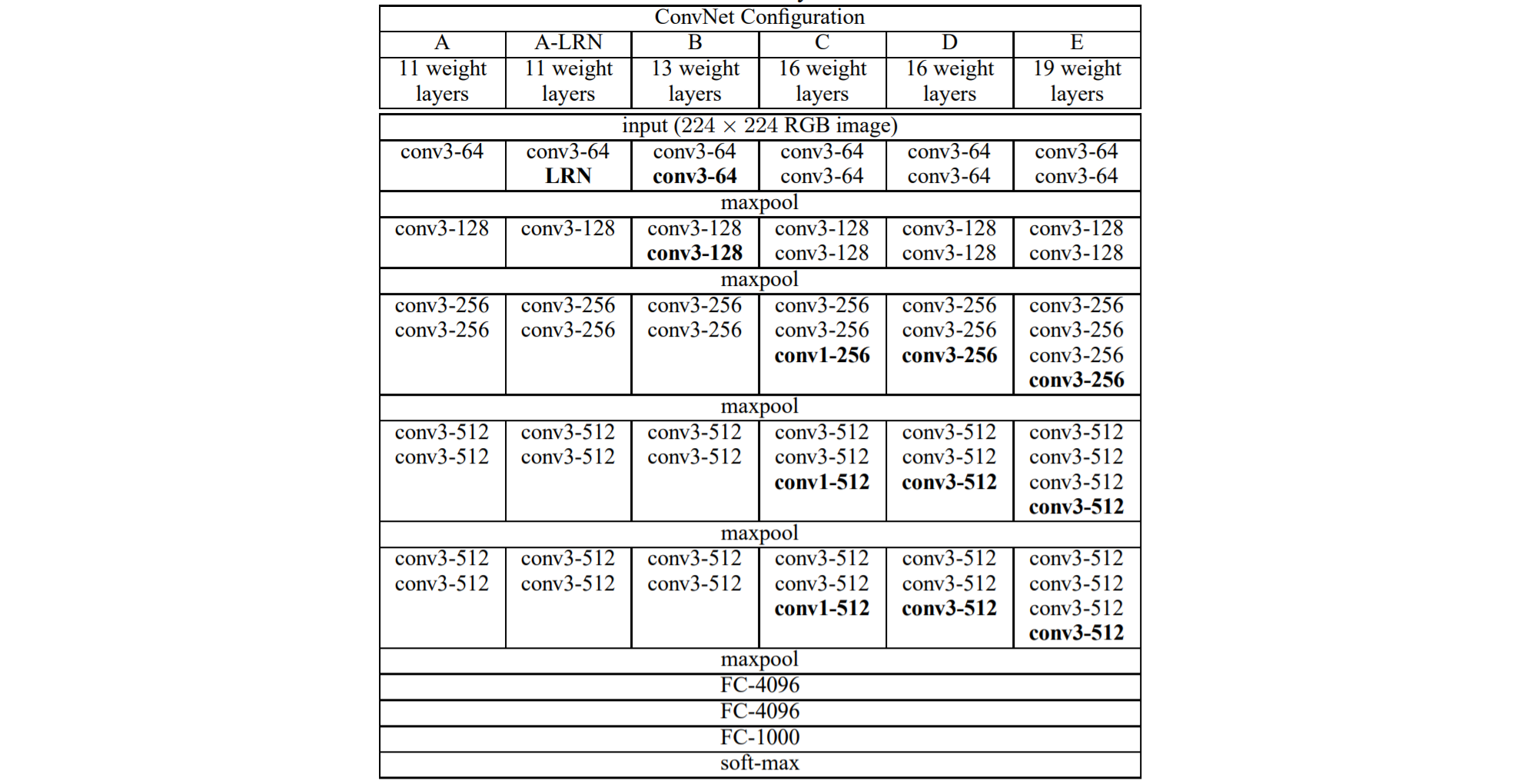
VGGNet是一个典型的卷积神经网络模型,由若干个卷积层和全连接层组成。从上面的结构中我们可以看到,VGGNet包含多个级别的网络,深度从11到19层不等。其网络结构主要可以分为三个部分:
-
卷积层:VGGNet的卷积层卷积核的大小均为3x3,且卷积核的个数相同。
-
池化层:VGGNet在卷积层之后使用了最大池化层来缩小图像的尺寸,并通过池化层的下采样来减少计算复杂度。
-
全连接层:VGGNet的全连接层包括两个4096维的全连接层和一个输出层。输出层的大小取决于任务的类别数。
最后经过一个sofmax得到最终类别上的概率分布。
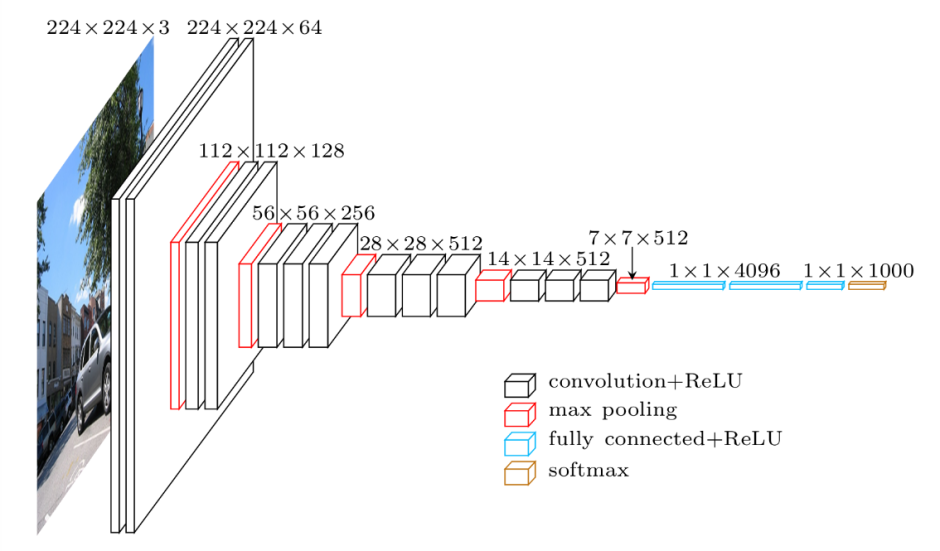
以VGG16为例,其网络结构图经可视化后如下所示:
VGG16参数量计算参考下图:
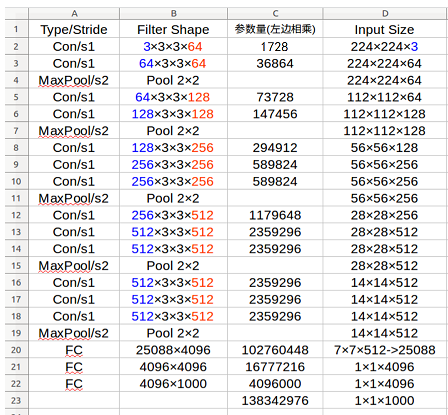
VGGNet代码实现:
python
# 定义VGGNet的网络结构
class VGG(nn.Module):
def __init__(self, features, num_classes=1000):
super(VGG, self).__init__()
self.features = features
self.classifier = nn.Sequential(
nn.Linear(512 * 7 * 7, 4096),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(4096, num_classes),
)
def forward(self, x):
x = self.features(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x- VGGNet的结构非常简洁,整个网络都使用了同样大小的卷积核尺寸和池化层。
- 几个小滤波器(3x3)卷积层的组合比一个大滤波器(5x5或7x7)卷积层好,一方面减少参数,另一方面拥有更多的非线性变换。
- 验证了通过加深网络结构可以提升性能。
- VGGNet不使用局部响应归一化(LRN),这种标准化并不能在ILSVRC数据集上提升性能,却导致更多的内存消耗和计算时间。
- VGGNet最后全连接层的参数量很大,可能会导致训练缓慢。
3. 批量标准化
批量标准化 (Batch Normalization) 是一种在深度学习中很常见的技巧,可以通过对每个输入批次的数据进行标准化来提高神经网络的训练速度和准确性。它通过计算数据的均值和方差,将数据按比例缩放和平移使其落在指定的范围内。这样做可以缓解深层神经网络中的梯度消失和爆炸问题,通常被放置在卷积层或全连接层的输入或输出之间,有助于模型收敛。
批量标准化 (Batch Normalization) 是2015年由两位谷歌工程师合作提出的,作者分别是Sergey Ioffe和Christian Szegedy。截止目前为止,论文引用次数已经超过4万。
批量标准化基本思想
批量标准化是为了解决深度神经网络训练过程中的两个主要问题:
-
梯度消失/爆炸:当神经网络深度很大时,梯度在传播到网络的较深层时会变得非常小或者非常大,导致梯度消失或者爆炸。这可能会导致模型无法收敛。
-
内部协变量偏移 (Internal Covariate Shift):这是指在训练过程中,神经网络的中间层输入分布可能会发生变化。这是因为随着训练的进行,前一层的权重可能会发生变化,导致中间层的输入分布发生变化。这可能会导致模型训练变慢,并且可能会影响模型的准确性。
批量标准化计算
批量标准化 (Batch Normalization) 的计算其实很简单,经简化后,输出数据 y 的每个元素都是通过如下公式计算得到的:
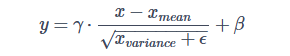
其中,x 是输入数据,xmean 和 xvariance 分别是输入数据的均值和方差,γ 和 β 是批量标准化层的两个可训练参数,ϵ 是一个很小的常数,用于避免方差为 0 的情况。
批量标准化一般还有另外两个参数,移动平均值和移动方差,用于计算整个数据集的均值和方差。
python
class LeNet(nn.Module):
def __init__(self):
super(LeNet, self).__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(1, 6, 5),
nn.BatchNorm2d(6)
)
self.conv2 = nn.Sequential(
nn.Conv2d(6, 16, 5),
nn.BatchNorm2d(16)
)
self.fc1 = nn.Sequential(
nn.Linear(16 * 4 * 4, 120),
nn.BatchNorm1d(120)
)
self.fc2 = nn.Sequential(
nn.Linear(120, 84),
nn.BatchNorm1d(84)
)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = torch.relu(self.conv1(x))
x = nn.functional.max_pool2d(x, 2)
x = torch.relu(self.conv2(x))
x = nn.functional.max_pool2d(x, 2)
x = x.view(-1, 16 * 4 * 4)
x = torch.relu(self.fc1(x))
x = torch.relu(self.fc2(x))
x = self.fc3(x)
return x4. GoogLeNet
GoogLeNet是在2014年ImageNet竞赛中首次提出的,并在竞赛中获得了最高的分类精度,GoogLeNet和之前介绍过的VGGNet分列比赛的第一名和第二名,而两个模型之间的差距也在毫厘之间。其网络设计受到了LeNet和AlexNet的启发,但在模型架构方面有了很大的改进。
GoogLeNet基本思想
GoogLeNet是2014年Christian Szegedy等人提出的一种全新的深度学习结构,在这之前的AlexNet、VGGNet等结构都是通过增大网络的深度来获得更好的训练效果,但层数的增加会带来很多负作用,比如过拟合、梯度消失、梯度爆炸等。GoogLeNet中提出的Inception结构则从另一种角度来提升训练结果:能更高效的利用计算资源,在相同的计算量下同时增加网络的宽度与深度,提取更多的特征,从而提升训练结果。
Inception结构
在讲GoogLeNet之前,先看一下它的重要组成部分Inception的结构。如下图所示:
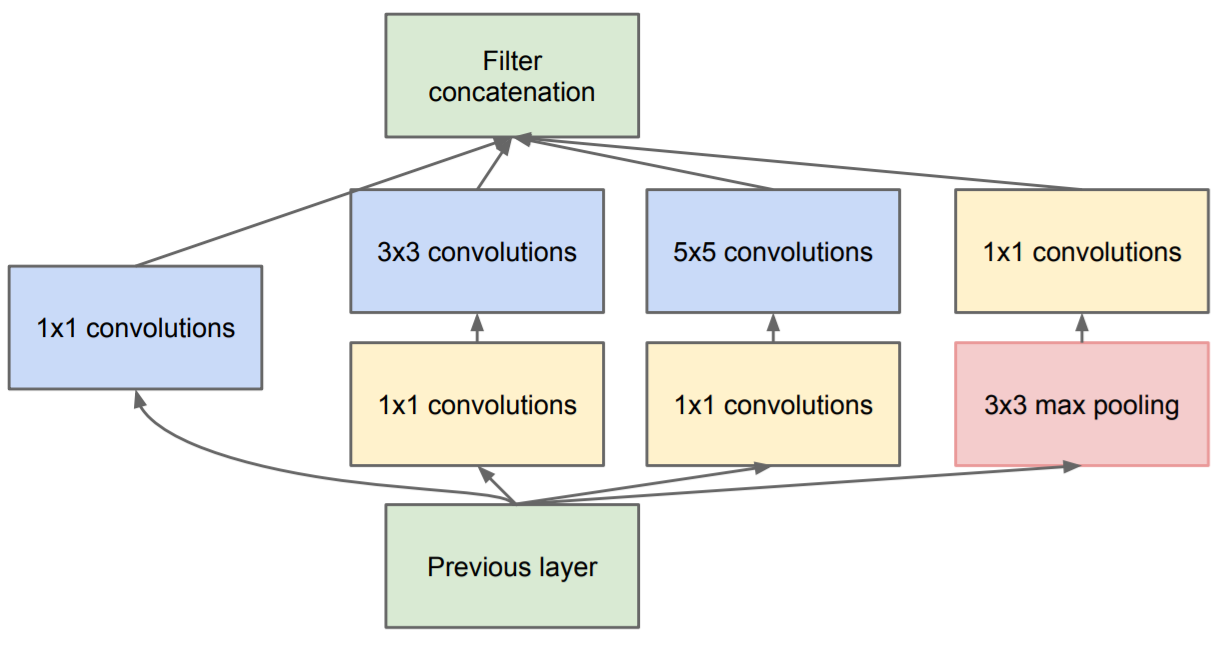
典型深度学习图像分类网络存在收敛速度太慢,训练参数太多、训练时间长,容易发生梯度消失和梯度爆炸问题。为了解决上述问题,GoogLeNet模型基于Inception网络构建而成,融合了不同尺度的特征信息,是一种带有稀疏性和具备高性能的网络结构。它将1x1,3x3,5x5的卷积层和3x3的最大池化层的结果堆叠起来,在3x3,5x5的卷积层之前以及3x3最大池化层之后加上了1x1的卷积层降维。Inception网络增加了网络的宽度,融合了不同小尺度的卷积与池化操作,能够有效地捕捉图像中的不同尺度特征,可以达到更好的识别效果,同时还能够有效地减少模型的参数数量。这使得Inception结构在许多不同的图像处理任务中都表现出色。
其中1x1卷积核是一种特殊的卷积核,通常用于改变输入张量的维度。在Inception模块中使用1x1卷积核的目的是减少输入张量的通道数,从而减少模型的参数数量。例如,如果输入张量是一个256x256x128的张量,而1x1卷积核的个数是64,那么使用1x1卷积核后输出的张量就是一个256x256x64的张量。可以看到,使用1x1卷积核后输出张量的通道数减少了一半,这也就意味着模型的参数数量也减少了一半。
GoogLeNet结构
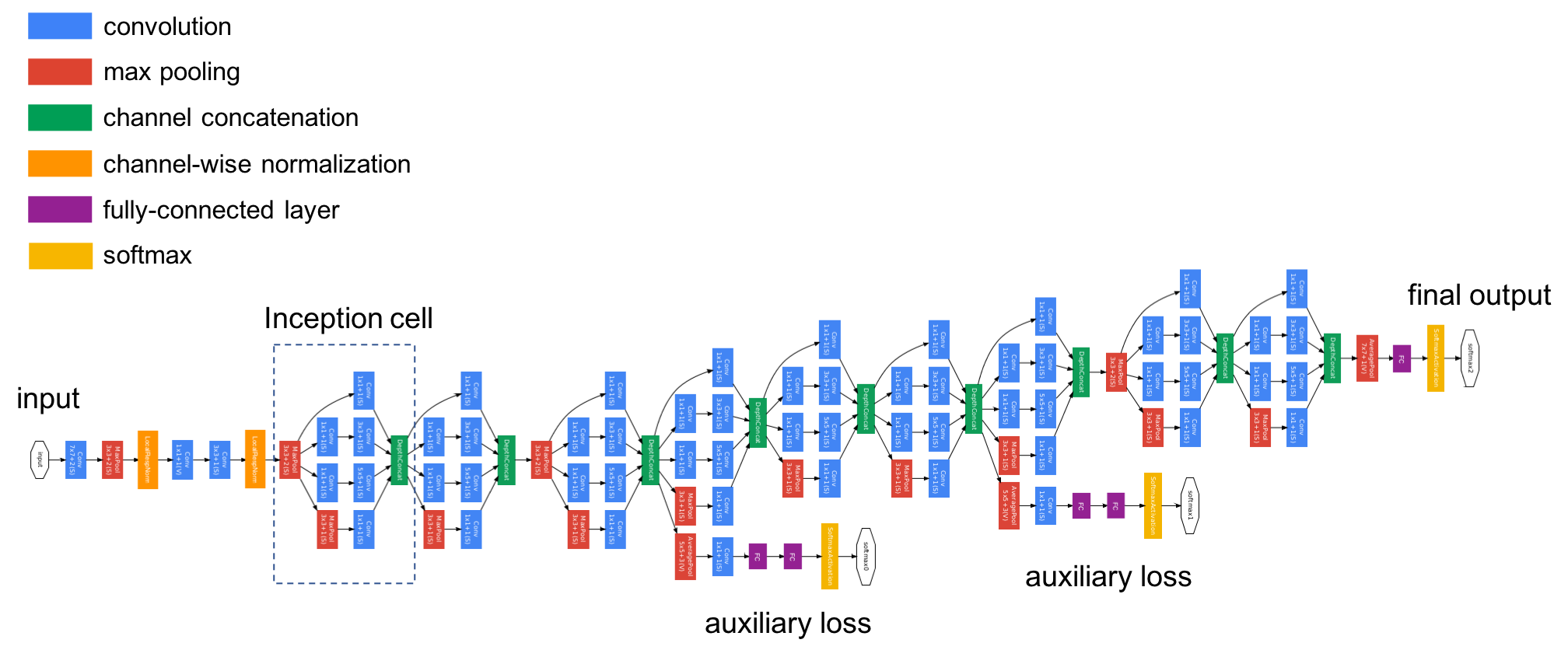
里面很多元素都是相同的Inception结构,下面梳理一下GoogLeNet的网络结构。
- 第一部分是卷积层,包含64个7x7步长为2的卷积核,后接最大池化层。
- 第二部分是卷积层,包含64个1x1的卷积核,然后是192个3x3步长为1的卷积核,后接最大池化层。
- 第三部分是两个Inception层,后接最大池化层。
- 第四部分是五个Inception层,后接最大池化层。
- 第五部分是两个Inception层,后接平均池化层。
- 第六部分是是输出层,包括1000个神经元的全连接,用于预测图像属于哪一类。
这样一梳理其实只有六个部分。
其中为了避免梯度消失,网络额外增加了2个辅助的softmax用于向前传导梯度,也可以理解为辅助分类器。辅助分类器是将中间某一层的输出用作分类,并按一个较小的权重加到最终分类结果中,这样相当于做了模型融合,同时给网络增加了反向传播的梯度信号,也提供了额外的正则化,对于整个网络的训练很有裨益。
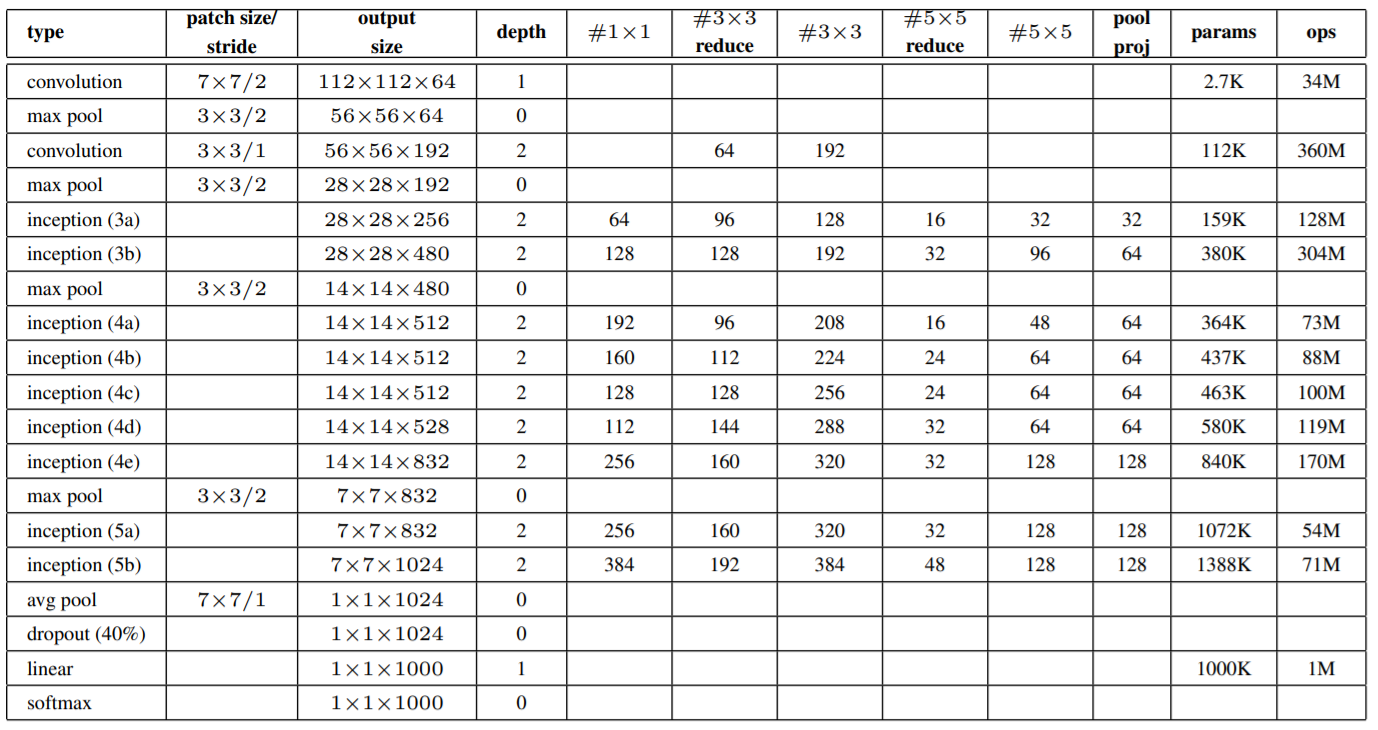
GoogLeNet的具体结构及参数量计算参考下图:
GoogLeNet代码实现
python
# 定义Inception结构
class Inception(nn.Module):
def __init__(self, in_channels, ch1x1, ch3x3red, ch3x3, ch5x5red, ch5x5, pool_proj):
super().__init__()
# 定义四个分支路径
self.branch1 = nn.Conv2d(in_channels, ch1x1, kernel_size=1)
self.branch2 = nn.Sequential(
nn.Conv2d(in_channels, ch3x3red, kernel_size=1),
nn.Conv2d(ch3x3red, ch3x3, kernel_size=3, padding=1)
)
self.branch3 = nn.Sequential(
nn.Conv2d(in_channels, ch5x5red, kernel_size=1),
nn.Conv2d(ch5x5red, ch5x5, kernel_size=3, padding=1)
)
self.branch4 = nn.Sequential(
nn.MaxPool2d(kernel_size=3, stride=1, padding=1),
nn.Conv2d(in_channels, pool_proj, kernel_size=1)
)
def forward(self, x):
branch1 = F.relu(self.branch1(x), inplace=True)
branch2 = F.relu(self.branch2(x), inplace=True)
branch3 = F.relu(self.branch3(x), inplace=True)
branch4 = F.relu(self.branch4(x), inplace=True)
# 连结输出
outputs = [branch1, branch2, branch3, branch4]
return torch.cat(outputs, dim=1)接下来定义GoogLeNet,每个part分别对应前面梳理的网络结构,总共六个部分:
python
# 定义GoogLeNet的网络结构
class GoogLeNet(nn.Module):
def __init__(self, num_classes=1000):
super().__init__()
self.part1 = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3),
nn.ReLU(inplace=True),
nn.MaxPool2d(3, stride=2, padding=1)
)
self.part2 = nn.Sequential(
nn.Conv2d(64, 64, kernel_size=1),
nn.ReLU(inplace=True),
nn.Conv2d(64, 192, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(3, stride=2, padding=1)
)
self.part3 = nn.Sequential(
Inception(192, 64, 96, 128, 16, 32, 32),
Inception(256, 128, 128, 192, 32, 96, 64),
nn.MaxPool2d(3, stride=2, padding=1)
)
self.part4 = nn.Sequential(
Inception(480, 192, 96, 208, 16, 48, 64),
Inception(512, 160, 112, 224, 24, 64, 64),
Inception(512, 128, 128, 256, 24, 64, 64),
Inception(512, 112, 144, 288, 32, 64, 64),
Inception(528, 256, 160, 320, 32, 128, 128),
nn.MaxPool2d(3, stride=2, padding=1)
)
self.part5 = nn.Sequential(
Inception(832, 256, 160, 320, 32, 128, 128),
Inception(832, 384, 192, 384, 48, 128, 128),
nn.AdaptiveAvgPool2d((1, 1))
)
self.part6 = nn.Sequential(
nn.Flatten(),
nn.Dropout(0.4),
nn.Linear(1024, num_classes)
)
def forward(self, x):
x = self.part1(x)
x = self.part2(x)
x = self.part3(x)
x = self.part4(x)
x = self.part5(x)
x = self.part6(x)
return x- GoogLeNet在2014年的ImageNet竞赛中获得了最高的分类精度,证明了它在图像分类任务中的优越性。
- 使用了Inception模块,能够有效地捕捉图像中的不同尺度特征,而且还能够有效地减少模型的参数数量。
- 在Inception模块中使用1x1的卷积核,目的是减少输入张量的通道数,从而减少模型的参数数量。
- 训练时使用了两个辅助分类器,作用是增加反向传播的梯度信号,也提供了额外的正则化,帮助主分类器更好地泛化。
- 论文的主要思路也是想通过构建密集的块结构来近似最优的稀疏结构,从而达到提高性能而又不大量增加计算量的目的。