文件系统概念
Linux文件系统是操作系统用于管理存储设备(如硬盘、SSD、U盘等)上数据存储和组织的核心组件,它定义了文件的命名、存储、检索、更新以及权限控制等规则。
理解文件系统
当我们使用ls -l会看到
ls -l
我们会看到每行包含七列:模式;软硬链接数;文件所有者;组;大小;文件最后修改时间;文件名
认识磁盘
磁盘是电脑上唯一一个机械设备,也是一个外设。
磁盘的组成
磁盘主要由盘片,磁道,扇区,读写头,磁头臂和主轴这些部分组成。它们的作用分别是:
盘片:数据存储的物理介质
读写头:数据的读取和写入
磁头臂:定位磁头到指定磁道
主轴:驱动盘片高速旋转
磁道:数据存储的基本环形单元
扇区:最小的可寻址存储单元
磁盘访问的最基本单元是扇区,通常为512字节或4kb。
磁盘寻址方式
我们可以把磁盘看做由无数个扇区构成的存储介质。要把数据存储到磁盘中,首先要定位到扇区,哪一面,哪一个磁头->哪一个磁道->哪一个扇区。磁头在磁盘高速旋转时左右摆动本质是定位磁道和扇区的过程。
CHS寻址方式
CHS是传统的磁盘物理寻址方式,它通过三维坐标来精确定位磁盘上的每一个扇区。
三维寻址结构
CHS 坐标:(柱面号, 磁头号, 扇区号)
↓
磁盘物理位置寻址过程
主机请求:CHS = (120, 2, 5)
↓
1. 磁头臂移动到第120柱面(寻道)
2. 选择第2号磁头(激活对应盘面的磁头)
3. 等待盘片旋转到第5扇区
4. 读取/写入数据每个磁盘都有固定的CHS参数如:最大柱面数(C)的典型值1024,最大磁头数(H)的典型值255(受限于8位),最大扇区数(S)的典型值63
寄存器
类别
寄存器按功能可分为四大核心类别:控制寄存器、数据寄存器、地址寄存器、状态寄存器。每类寄存器都有特定的功能和用途,共同协作完成CPU的各种任务。
控制寄存器:用于存储控制信息,控制CPU的操作模式和功能。例如,程序状态字(PSW)中的标志位、中断允许位、工作模式位等都属于控制寄存器。
数据寄存器:用于暂存参与运算的数据,是CPU与内存之间数据交换的缓冲器。在运算过程中,数据从内存读取到数据寄存器,经过ALU运算后结果再写回数据寄存器。
地址寄存器:用于存放内存地址,指示CPU要访问的内存单元位置。如程序计数器(PC)存放下一条指令地址,基址寄存器、变址寄存器等用于形成有效地址。
状态寄存器:用于记录CPU执行指令后的状态信息,如进位标志(CF)、零标志(ZF)、溢出标志(OF)等。这些标志位会影响后续的条件转移指令执行。
CPU通过寄存器与磁盘(I/O设备)进行数据和控制交互
核心机制:CPU并非直接操作磁盘数据,而是通过读写磁盘控制器上的一组寄存器来下达命令、传递参数并获取状态。
寄存器功能分工:
控制寄存器:CPU通过向其中写入命令(如r/w,即读/写)来控制磁盘启动某项操作。
地址寄存器:CPU向其中写入要访问的数据位置。
数据寄存器:作为数据传输的缓冲区。写操作时,CPU将待写入的数据放入此寄存器;读操作时,CPU从此寄存器读取磁盘准备好的数据。
状态寄存器:磁盘将操作结果和当前状态(如是否忙、是否出错)写入此寄存器,供CPU读取判断。
文件系统的基本功能
数据组织:将存储设备划分为固定大小的块(如4KB),并通过元数据(如inode)记录文件属性(权限、大小、位置等)。
命名空间:提供树形目录结构(以/为根),支持文件/目录的层次化命名。
访问控制:通过权限位(rwx)、ACL(访问控制列表)限制用户对文件的访问。
数据持久化:确保文件在系统重启后仍可访问,并通过日志等机制保证崩溃一致性。
inode
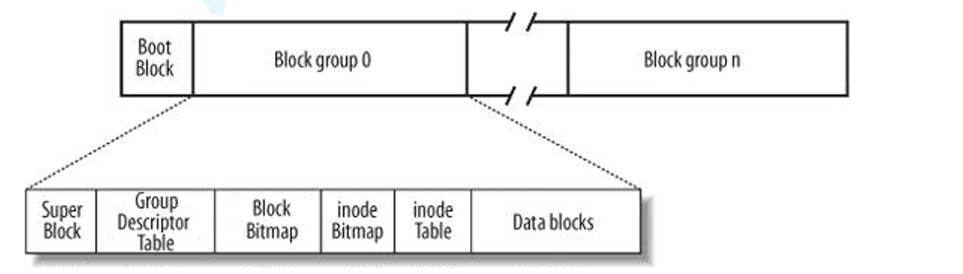
上图为磁盘文件系统图
boot block:(管理操作系统启动的相关信息)在每个分区的头部,将剩下的部分划分成n个block group。
Block Group:ext2文件系统会根据分区的大小划分为数个Block Group。而每个Block Group都有着相 同的结构组成。政府管理各区的例子
超级块(Super Block):存放文件系统本身的结构信息。记录的信息主要有:bolck 和 inode的总量, 未使用的block和inode的数量,一个block和inode的大小,最近一次挂载的时间,最近一次写入数据的 时间,最近一次检验磁盘的时间等其他文件系统的相关信息。Super Block的信息被破坏,可以说整个 文件系统结构就被破坏了
GDT,Group Descriptor Table:块组描述符,描述块组属性信息(它是这个块组的"详细目录"。它记录了本块组内其他各个部分(位图、inode表、数据块区域)的起始块和状态信息。操作系统通过它快速定位到本块组的管理数据。)
块位图(Block Bitmap):Block Bitmap中记录着Data Block中哪个数据块已经被占用,哪个数据块没 有被占用(它本质上是一个巨大的二进制(0/1)地图,每一位(bit)对应本块组内的一个数据块。0表示这个数据块是空闲的。1表示这个数据块已被占用。)
inode位图(inode Bitmap):每个bit表示一个inode是否空闲可用。
i节点表:存放文件属性 如 文件大小,所有者,最近修改时间等
数据区:存放文件内容
核心定义:inode 是文件系统中用于存储文件元数据的数据结构。它不包含文件的内容,而是包含文件的属性。
inode存储的关键信息:

#define NUM 15:这是一个宏定义,表明后续的 blocks数组大小为 15。这里的数字 15 是一个简化的例子。在实际的经典文件系统(如 ext2)设计中,inode 中用于存储数据块指针的数组通常有 12 个直接指针、1 个一级间接指针、1 个二级间接指针和 1 个三级间接指针,总共 15 个"槽位"。这能支持从几 KB 到 TB 级别的文件大小。
inode number:这个字段存储 inode 的编号。它是 inode 在文件系统中的唯一标识,类似于身份证号。内核通过这个编号在磁盘的 inode 表中定位具体的 inode。
文件类型:用于标识这个 inode 代表的是普通文件、目录、符号链接、设备文件(字符/块设备)、管道还是套接字等。
权限:存储经典的 Unix 文件权限位,即 rwxrwxrwx(所有者、组用户、其他用户的读、写、执行权限)。
引用计数:这是一个极其关键的字段。它记录了这个 inode 当前被多少个目录项(即硬链接)引用。只有当引用计数降为 0 时,系统才会真正释放这个 inode 及其占用的数据块。这正是硬链接的工作原理。
拥有者与 所属组:通常存储用户的 UID 和组的 GID,用于进行文件访问权限的归属判断。
ACM时间:这是三个时间戳的合称,通常包括:A-time (Access Time): 最后一次访问文件内容的时间(如 cat, less)。C-time (Change Time): 最后一次更改文件inode元数据的时间(如修改权限、重命名)。M-time (Modify Time): 最后一次修改文件内容的时间。
int blocksNUM:这是 inode 的核心数据。这个数组存储了文件内容所在的物理磁盘块号。
其工作方式是一个多级索引结构(以经典的 ext2 为例,这也是为什么 NUM=15 的常见原因):
blocks0到 blocks11:直接指针。它们直接指向文件的前 12 个数据块。对于小文件(如 ≤ 48KB,假设块大小为 4KB),这就足够了。
blocks12:一级间接指针。它指向一个数据块,但这个数据块不存文件数据,而是存满了更多指向数据块的指针。这可以寻址更多的数据块。
blocks13:二级间接指针。它指向一个块,这个块里存的指针,每个又指向一个块,那些块里存的才是最终的数据块指针。这形成了两级索引。
blocks14:三级间接指针。原理同上,形成三级索引,可以支持非常大的文件。
文件系统的工作流
创建文件:
(1)系统先在 inode 位图 中找一个空闲位,标记为占用。
(2)在对应的 inode 表 位置初始化一个 inode 结构,填写权限、所有者等信息。
(3)根据文件大小,在 块位图 中找若干个空闲数据块,标记为占用。
(4)将找到的数据块编号(指针)填入 inode 的"数据块指针"字段。
(5)最后,在父目录的"目录文件"(它本身也占用数据块)中,添加一条记录:文件名 -> inode编号。
读取文件:
(1)从根目录 /的 inode 开始,找到其数据块,在里面找到 home的 inode 编号。
(2)进入 home目录的数据块,找到 user的 inode 编号。
(3)进入 user目录的数据块,找到 hello.txt的 inode 编号(假设是 12345)。
(4)关键步骤:根据编号 12345,定位到它所在的块组和 inode 表 中的具体位置。
(5)从该 inode 中读取权限信息(检查你是否能读)和数据块指针。
(6)根据指针,去 Data blocks 区域找到对应的数据块,将内容读取出来。
dentry缓存:
dentry 缓存 是 Linux 内核维护的一个内存中的数据结构,用于缓存最近使用过的 dentry 对象。
当我们需要查找文件时,直接在缓存中查找,避免读盘。
软硬链接
硬链接
硬链接 本质上是在同一个文件系统内,为同一个 inode 创建多个不同的文件名。换句话说,硬链接是指向同一个 inode 的目录条目。
创建命令
ln 源文件 硬链接文件名
例:
ln original.txt hardlink.txt工作原理
当你创建硬链接时,系统并没有创建新的文件内容,也没有创建新的 inode。它只是在另一个目录(或同一目录)下,创建了一个新的目录条目,这个新条目中的 inode 编号 和源文件完全相同。inode 结构体中有一个字段叫 "链接计数"。创建硬链接后,这个计数会 +1。
关键特性
(1)无法区分:所有硬链接都是平等的。你无法区分哪个是"原始文件",哪个是"链接"。它们共享同一个 inode,访问任何一个效果都一样。
(2)同步更新:修改任何一个硬链接的内容,其他所有硬链接的内容都会同步改变,因为它们指向的是同一份数据。
(3)删除机制:删除一个硬链接,只是删除了一个指向该 inode 的目录条目,inode 的"链接计数"会 -1。只有当链接计数减到 0 时,inode 和其占用的数据块才会被真正释放。这是硬链接最核心的特性。
(4)限制:
不能跨文件系统:因为 inode 编号只在同一个文件系统内是唯一的。你不能为一个在 /dev/sda1上的文件,在 /dev/sda2上创建硬链接。
不能对目录创建硬链接:这是为了防止目录树中出现循环,导致文件系统工具(如 find, tar)陷入无限循环。只有超级用户可以创建目录的硬链接。
软链接
软链接,也叫符号链接,是一个独立的文件,它有自己的 inode 和数据块。软链接文件的内容很特殊:它只存储了目标文件的路径字符串。
创建命令
ln -s 目标文件 软链接文件名
例:
ln -s original.txt softlink.txt工作原理
(1)当你创建软链接时,系统会创建一个新的文件,分配一个新的 inode 和新的数据块。
(2)这个新文件的内容不是你的文档或代码,而是目标文件的路径(例如 original.txt)。
(3)当你访问软链接时,系统会读取这个路径,然后去查找真正的目标文件。
关键特性
(1)依赖目标文件:软链接只是一个"快捷方式"。如果删除或移动了目标文件,软链接就会"断链",变成一个"悬空链接"。访问它会报错 "No such file or directory"。
(2)独立文件:软链接有自己的 inode、权限和时间戳。它的文件大小就是它存储的路径字符串的长度。
(3)权限特殊:软链接实际访问权限由目标文件决定。
(4)灵活性强:可以跨文件系统:因为它只存路径,所以可以链接到另一个硬盘或网络存储上的文件。可以链接到目录:这是软链接的一个巨大优势,常用于目录的快捷方式。
核心区别
|-------|-----------------|---------------|
| 特性 | 硬链接 | 软链接 |
| 本质 | 同一个 inode 的多个别名 | 一个存储了路径的特殊文件 |
| inode | 相同 | 不同 |
| 跨文件系统 | 不可以 | 可以 |
| 链接目录 | 一般不允许 | 允许 |
| 文件大小 | 与原文件相同 | 等于路径字符串长度 |
| 删除源文件 | 只是链接数减1,数据仍在 | 链接断链,无法访问 |
| 关系 | 如一个人的多个名字 | 如windows的快捷方式 |
页框(页帧)
核心背景
分页机制:
现代操作系统都使用虚拟内存技术。其核心思想是:每个进程都拥有一个独立的、连续的、巨大的虚拟地址空间(例如,32位系统是4GB,64位系统则巨大无比)。然而,物理内存(RAM)是有限的,并且可能不连续。分页机制 将虚拟地址空间和物理内存都划分成固定大小的块。虚拟内存中的块称为页,物理内存中的块称为页框。操作系统通过页表 来维护虚拟地址空间中的"页"到物理内存中"页框"的映射关系。
页
定义:页是虚拟内存的基本管理单位。它是进程视角下的内存单元。
特点:(1)存在于虚拟地址空间中。
(2)大小固定,通常为 4KB(在 x86-64 架构下)。现代系统也支持更大的页,如 2MB 或 1GB(称为大页,Huge Pages)。
(3)一个进程的代码、数据、堆、栈等,都被分割成一个个页。
(4)页是逻辑上连续的,但在物理内存中,它们所映射的页框可能是不连续的。
页框(页帧)
定义:页框是物理内存的基本管理单位。它是物理内存被划分成的固定大小的块。
特点:(1)存在于物理内存(RAM) 中。
(2)大小与页完全相同(如 4KB),以便一一对应。
(3)页框是物理上连续的内存块。
(4)操作系统内核维护着所有页框的状态(空闲、已分配、脏页等)。
页、页框和页表的关系
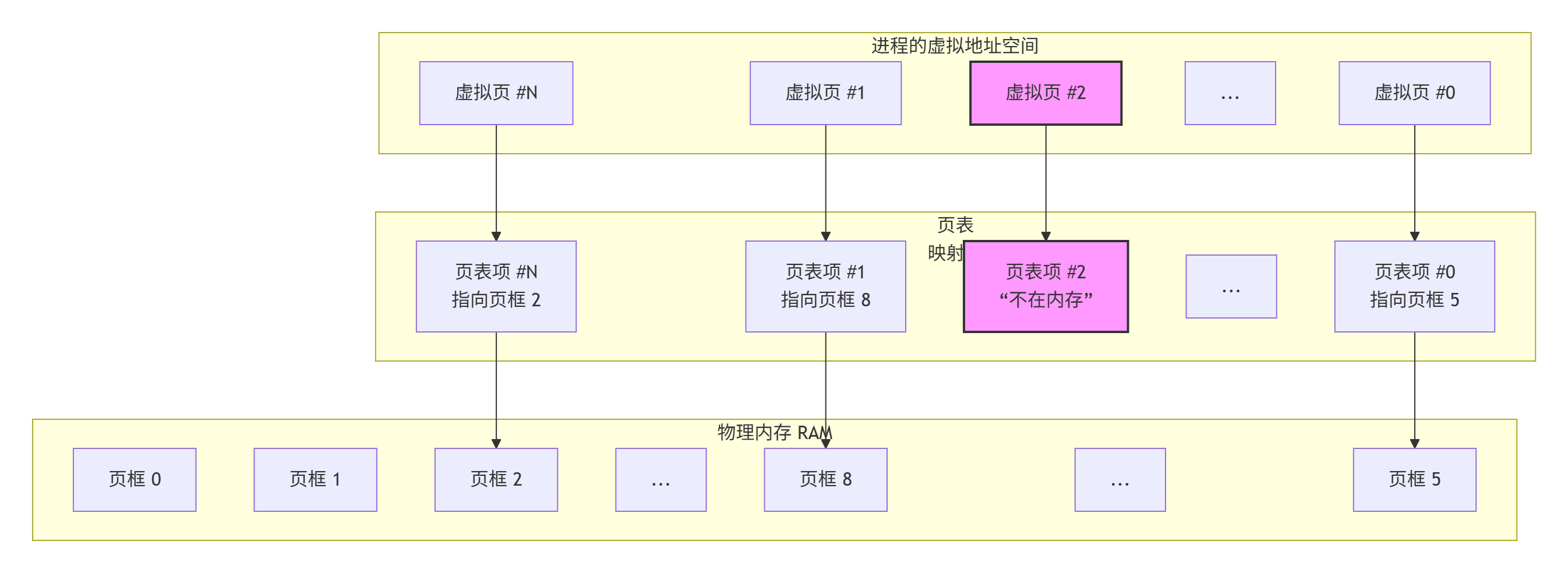
工作流程
映射:当进程访问一个虚拟地址(例如,在虚拟页 #1 中)时,CPU 的内存管理单元会查阅该进程的页表。
查找:在页表中找到对应的页表项。页表项中包含了该虚拟页映射到了哪个物理页框(例如页框 8),以及一些控制位(如是否存在、是否可写)。
转换:如果该页的"存在位"为 1,表示它已被加载到物理内存中。MMU 将虚拟地址转换为物理地址:物理地址 = 页框基址 + 页内偏移。
访问内存:CPU 使用这个物理地址去访问物理内存(RAM)中的相应页框。
缺页异常:如果页表项中的"存在位"为 0(如图中的虚拟页 #2),表示该页不在物理内存中。这会触发一个缺页异常。
处理缺页:操作系统接管控制权:从磁盘(交换分区或文件)中加载所需的数据。在物理内存中找到一个空闲的页框。将数据从磁盘读入这个页框。更新页表项,使其指向这个新的页框,并将"存在位"置 1。然后,重新执行之前失败的指令,这次就能成功访问了。
操作系统管理内存
现代操作系统几乎都采用基于分页的虚拟内存机制。这是内存管理的基石。