接触新东西,最好有一个完整的学习路径图,网上文章往往比较零散,官网吧说实话人家介绍东西思维方式跟我们还是有差别的,还是不能快速初窥门径。AI可以极快加速这个过程。我按照豆包提供的路径做了如下事情:
1、docker本地(Mac)部署ES和Kibina;
2、使用kibana的图形化开发工具,熟悉基本的CURD。
文章目录
一、docker部署ES和Kibina
docker-compose.yml文件如下【亲测可用!】:
yaml
version: '3.8'
# 自定义网络:ES和Kibana互通
networks:
es-network:
driver: bridge
# 数据卷:持久化ES数据/插件、Kibana数据(Mac下避免权限问题)数据卷:持久化 ES 数据,Mac 下 Docker 会自动管理数据卷存储路径
volumes:
es-data:
es-plugins:
kibana-data:
services:
# Elasticsearch节点(适配Mac Docker内存限制)
elasticsearch:
image: elasticsearch:7.17.9
container_name: es7-mac
restart: always
networks:
- es-network
ports:
- "9200:9200" # REST API端口
- "9300:9300" # 集群通信端口
volumes:
- es-data:/usr/share/elasticsearch/data # 数据持久化
- es-plugins:/usr/share/elasticsearch/plugins # 插件目录
#- ./ik-analyzer:/usr/share/elasticsearch/plugins/ik #ik分词器插件
environment:
# JVM堆内存:Mac Docker默认内存2G,设1G足够(避免内存不足)
- "ES_JAVA_OPTS=-Xms1g -Xmx1g"
- "discovery.type=single-node" # 单节点模式(Mac测试首选)
- "cluster.name=es-cluster-mac"
- "node.name=es-node-1"
- "bootstrap.memory_lock=true" # 锁定内存(Mac下需Docker开启内存限制)
- "xpack.security.enabled=false" # 禁用安全(测试环境)
- "xpack.monitoring.enabled=false"
- "http.cors.enabled=true" # 允许跨域(Kibana访问)
- "http.cors.allow-origin=*"
- "TAKE_FILE_OWNERSHIP=true" # Mac下解决数据目录权限问题
ulimits:
memlock:
soft: -1
hard: -1
nofile:
soft: 65535 # 最大打开文件数
hard: 65535
# Mac下限制容器资源(避免占满系统内存)
deploy:
resources:
limits:
cpus: '2'
memory: 2G
# Kibana(汉化+适配Mac)
kibana:
image: kibana:7.17.9
container_name: kibana7-mac
restart: always
networks:
- es-network
ports:
- "5601:5601"
volumes:
- kibana-data:/usr/share/kibana/data
environment:
- "ELASTICSEARCH_HOSTS=http://elasticsearch:9200" # 容器名互通
- "I18N_LOCALE=zh-CN" # 汉化
- "SERVER_HOST=0.0.0.0" # 允许外部访问(Mac下必要)
depends_on:
- elasticsearch # 先启动ES
deploy:
resources:
limits:
cpus: '1'
memory: 1G在mac下目录结构如下:
我开始还在这里建立了elasticsearch目录,里面还建了data和plugins目录。原本目的是在docker-compose里指定宿主机的卷,后来发现Mac下是不用指定的,Docker Desktop会自动创建卷,你只用给个名字就可以了(就类似Mac下安装应用你是不用也没法指定安装位置的一样),所以这里的真正起作用的就是docker-compose.yml。如果指定会报语法错误的。
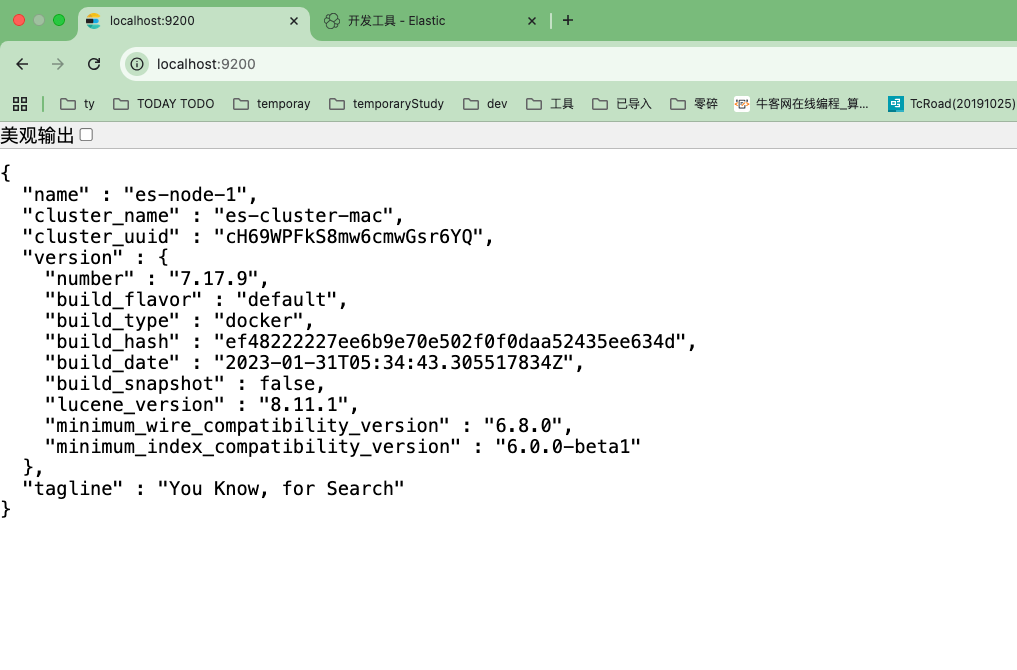
Kibana理解成类似Navicate的工具就可以了。
二、Kibana的工具界面操作CURD
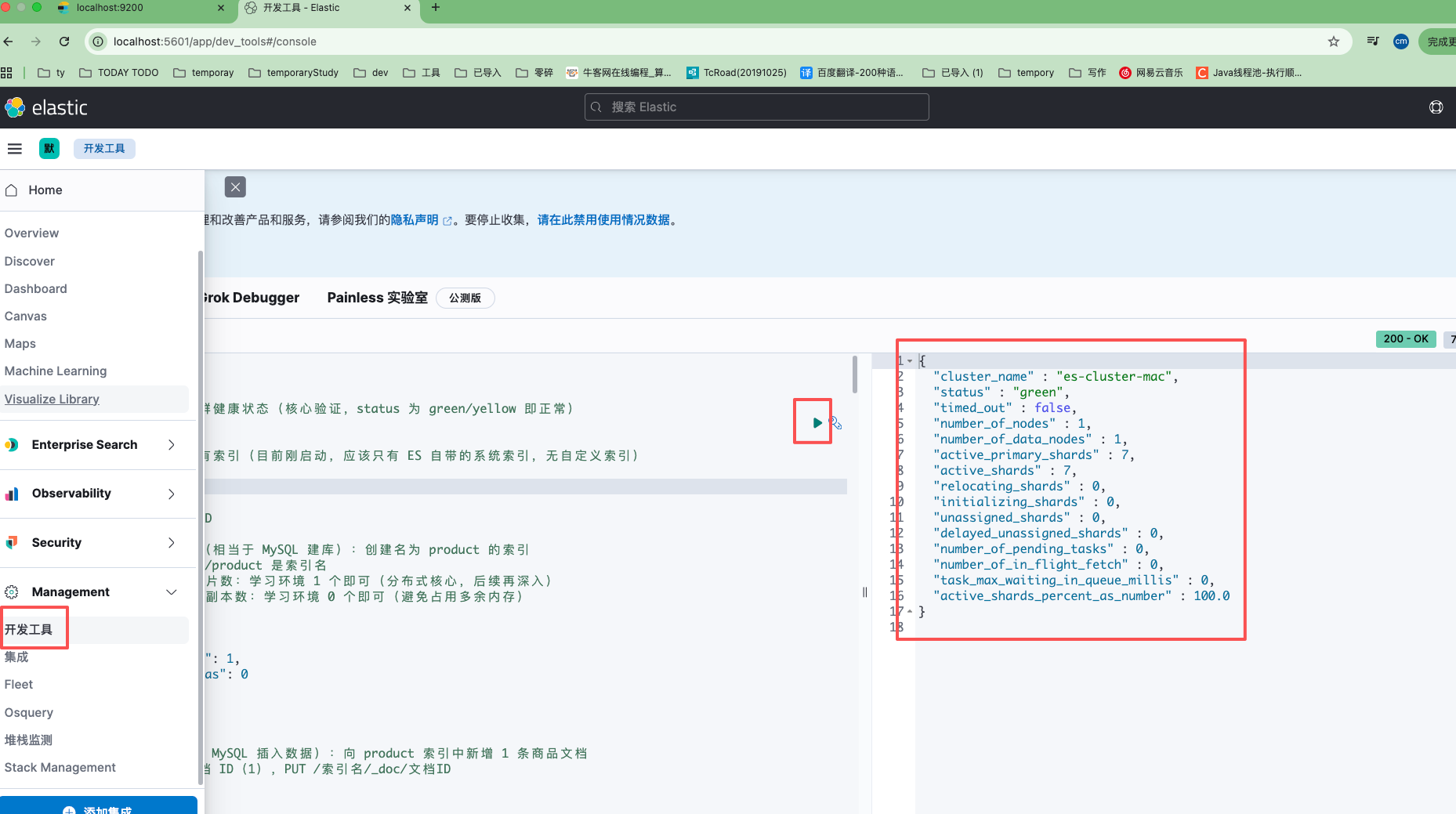
按照豆包给的步骤,把以下每个命令单个执行,观察并思考结果。
步骤一 熟悉kibina
步骤二:熟悉ES的CURD
步骤三 自定义Mapping映射,避免ES自动推断数据类型导致和预期不符。
步骤四------入门查询 DSL ------ 实现基础检索(ES 核心价值)
sql
# 步骤一 熟悉kibina
# 命令 1:查看 ES 集群健康状态(核心验证,status 为 green/yellow 即正常)
GET /_cluster/health
# 命令 2:查看 ES 所有索引(目前刚启动,应该只有 ES 自带的系统索引,无自定义索引)
GET /_cat/indices?v
# 步骤二:熟悉ES的CURD
## 1. 创建自定义索引(相当于 MySQL 建库):创建名为 product 的索引
# PUT 表示创建/更新,/product 是索引名
# number_of_shards 分片数:学习环境 1 个即可(分布式核心,后续再深入)
# number_of_replicas 副本数:学习环境 0 个即可(避免占用多余内存)
PUT /product
{
"settings": {
"number_of_shards": 1,
"number_of_replicas": 0
}
}
# 2. 新增文档(相当于 MySQL 插入数据):向 product 索引中新增 1 条商品文档
# 方式 1:手动指定文档 ID(1),PUT /索引名/_doc/文档ID
PUT /product/_doc/1
{
"id": 1,
"name": "华为 Mate 60 Pro",
"price": 6999.0,
"category": "智能手机",
"create_time": "2024-01-01"
}
# 方式 2:自动生成文档 ID,POST /索引名/_doc(无需指定 ID)
POST /product/_doc
{
"id": 2,
"name": "苹果 iPhone 15",
"price": 5999.0,
"category": "智能手机",
"create_time": "2024-02-01"
}
# 用于删除 (生成的id是:oFsCCZwBaeiVDLwkuPWm)
POST /product/_doc
{
"id": 3,
"name": "红米 K70",
"price": 1500.0,
"category": "智能手机",
"create_time": "2026-01-29"
}
# 3. 查询文档(相当于 MySQL 查询单条数据)
# 方式 1:根据文档 ID 查询(精确查询单条)
GET /product/_doc/1
GET /product/_doc/n1v1CJwBaeiVDLwkBvXE
GET /product/_doc/oFsCCZwBaeiVDLwkuPWm
# 方式 2:查询 product 索引下所有文档(相当于 SELECT * FROM product)
# match_all:匹配所有文档
GET /product/_search
{
"query": {
"match_all": {}
}
}
# 4. 更新文档(相当于 MySQL UPDATE)
# 方式 1:局部更新(推荐,只更新指定字段),POST /索引名/_update/文档ID
# 只更新价格字段 # stock为新增字段(无模式特性,直接添加即可)
POST /product/_update/1
{
"doc": {
"price": 6799.0,
"stock": 100
}
}
# 方式 2:全量替换(不推荐,需传入完整文档,未传入字段会丢失)
PUT /product/_doc/1
{
"id": 1,
"name": "华为 Mate 60 Pro",
"price": 6199.0,
"category": "智能手机",
"create_time": "2026-01-29"
}
# 5. 删除操作
# 方式 1:删除指定文档(相当于 MySQL DELETE)
DELETE /product/_doc/oFsCCZwBaeiVDLwkuPWm
# 方式 2:删除整个索引(谨慎!相当于 DROP DATABASE,删除后数据无法恢复)
# DELETE /product
# 步骤三 自定义Mapping映射,避免ES自动推断数据类型导致和预期不符。
# 1. 先删除之前的 product 索引(方便重新演示,这里不在删除,新建一个即可)
#DELETE /product
# 2. 创建索引 + 自定义 Mapping(核心:在 settings 同级添加 mappings 字段)
# "analyzer": "standard" # 分词器:默认英文分词器(中文后续替换为 IK)
#"type": "keyword" # keyword 类型:不可分词,用于精确匹配(如分类筛选、排序)
#"format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis" # 支持的日期格式
PUT /productv2
{
"settings": {
"number_of_shards": 1,
"number_of_replicas": 0
},
"mappings": {
"properties": {
"id": {
"type": "integer"
},
"name": {
"type": "text",
"analyzer": "standard"
},
"price": {
"type": "double"
},
"category": {
"type": "keyword"
},
"create_time": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"
}
}
}
}
# 3. 查看 Mapping 结构(验证自定义配置是否生效)
GET /product/_mapping
GET /productv2/_mapping
# 4. 插入文档,验证字段类型是否符合预期(插入后无报错即正常)
PUT /productv2/_doc/1
{
"id": 1,
"name": "华为 Mate 60 Pro",
"price": 6999.0,
"category": "智能手机",
"create_time": "2024-01-01"
}
GET /productv2/_doc/1
GET /productv2/_search
{
"query": {
"match_all": {}
}
}
#总结:
#核心知识点
#常用字段类型:text(全文检索)和keyword(精确匹配)是重中之重,后续查询的核心区别就源于。
#Mapping 一旦创建(字段类型定义完成),大部分字段类型无法修改(只能新增字段),因此创建索引时要谨慎设计字段类型。
# 步骤四------入门查询 DSL ------ 实现基础检索(ES 核心价值)
# 掌握 term(精确查询)和 match(全文检索),理解两者的区别,能实现基础的条件检索。
# 先插入几条测试数据,方便查询演示
PUT /productv2/_doc/2
{
"id": 2,
"name": "苹果 iPhone 15",
"price": 5999.0,
"category": "智能手机",
"create_time": "2024-02-01"
}
PUT /productv2/_doc/3
{
"id": 3,
"name": "华为平板 MatePad 11",
"price": 2499.0,
"category": "平板电脑",
"create_time": "2024-03-01"
}
PUT /productv2/_doc/4
{
"id": 4,
"name": "红米 K70",
"price": 1500.0,
"category": "智能手机",
"create_time": "2026-01-29"
}
#查所有
GET /productv2/_search
{
"query": {
"match_all": {}
}
}
# 1. term 查询:精确匹配(适用于 keyword、integer、double、date 类型字段)
# 需求:查询分类为「智能手机」的所有商品(category 是 keyword 类型)
#"category": { # 要查询的字段
# "value": "智能手机" # 要匹配的值(精确一致,不分词),可以修改成:智能、手机,是查不到的
GET /productv2/_search
{
"query": {
"term": {
"category": {
"value": "智能手机"
}
}
}
}
# 2. match 查询:全文检索(适用于 text 类型字段)
# 需求:查询商品名称中包含「华为」的所有商品(name 是 text 类型)
# 全文检索:会对「华为」进行分词(英文分词器直接匹配,中文后续用 IK 分词)
GET /productv2/_search
{
"query": {
"match": {
"name": "华为手机"
}
}
}
# 3. 简单复合查询:bool(多条件组合,包含 must(必须满足)、filter(过滤,不评分))
# 需求:查询分类为「智能手机」且价格大于 5000 的商品
#"must": [ # 必须满足所有条件(相当于 AND)
#"filter": [ # 过滤条件(不参与评分,性能更好,适用于范围、精确匹配)
#"range": { # range:范围查询(适用于数值、日期类型)
# gt:大于;gte:大于等于;lt:小于;lte:小于等于
#"sort": [ # 排序:按价格降序排列
GET /productv2/_search
{
"query": {
"bool": {
"must": [
{
"term": {
"category": "智能手机"
}
}
],
"filter": [
{
"range": {
"price": {
"lt": 2000
}
}
}
]
}
},
"sort": [
{
"price": {
"order": "desc"
}
}
],
"from": 0,
"size": 10
}
#总结:
#1、term 是「精确匹配」,不分词,适合筛选分类、ID 等固定值;match 是「全文检索」,会分词,适合搜索商品名称、文章内容等。
#2、filter 过滤不参与评分,性能优于 must,实战中优先用 filter 做条件筛选。
# 4、默认的分词器
#这里我们重点在研究下没有中文分词器IK的情况下,为啥:华为手机 可以返回"name" : "华为 Mate 60 Pro","name" : "华为平板 MatePad 11",
#按照预期,没有分词器的情况下,name是text,既然不能分词那么效果应该类似term,结果应该是匹配不到。这里为什么会匹配到?
GET /productv2/_search
{
"query": {
"match": {
"name": "华为手机"
}
}
}
#1. 检查字段实际使用的分词器
GET /productv2/_mapping
#发现返回的name的analyzer是:standard 默认标准的分词器
#2. 测试 standard 对中文的切分效果
GET /_analyze
{
"analyzer": "standard",
"text": "华为手机"
}
#预期输出: ["华","为","手","机"](单字切分)
GET /_analyze
{
"analyzer": "standard",
"text": "华为 Mate 60 Pro"
}
#预期输出: ["华","为","mate","60","pro"]
#所以到这里明白了,默认的分词器:standard在起作用,他们单个词之间是or关系,所以name为:"华为 Mate 60 Pro","name" : "华为平板 MatePad 11",都匹配到了。这样有啥问题?IK分词器又有啥作用?
#潜在风险(无中文分词器的隐患)
#| 问题 | 示例 | 影响 |
#|------|------|------|
#| 过度召回 | 搜"华为手机" → 返回"中华""清华""手工"等含单字的文档 | 精确度低,噪声多 |
#| 语义割裂 | "北京大学" → 拆为`["北","京","大","学"]` | 无法匹配完整词组 |
#| 相关性失真 | "手机壳"含"手""机" → 与"华为手机"强相关(实际无关) | 排序不合理 |
#后续知识点: 1、 安装中文分词器 IK 2、深入复合查询与高亮显示 3、Java 客户端整合 4、性能优化入门:了解分片策略、避免深度分页、优化查询语句,解决实战中的性能问题后续步骤分下期博客继续:#后续知识点: 1、 安装中文分词器 IK 2、深入复合查询与高亮显示 3、Java 客户端整合 4、性能优化入门:了解分片策略、避免深度分页、优化查询语句,解决实战中的性能问题
三、遇到的问题
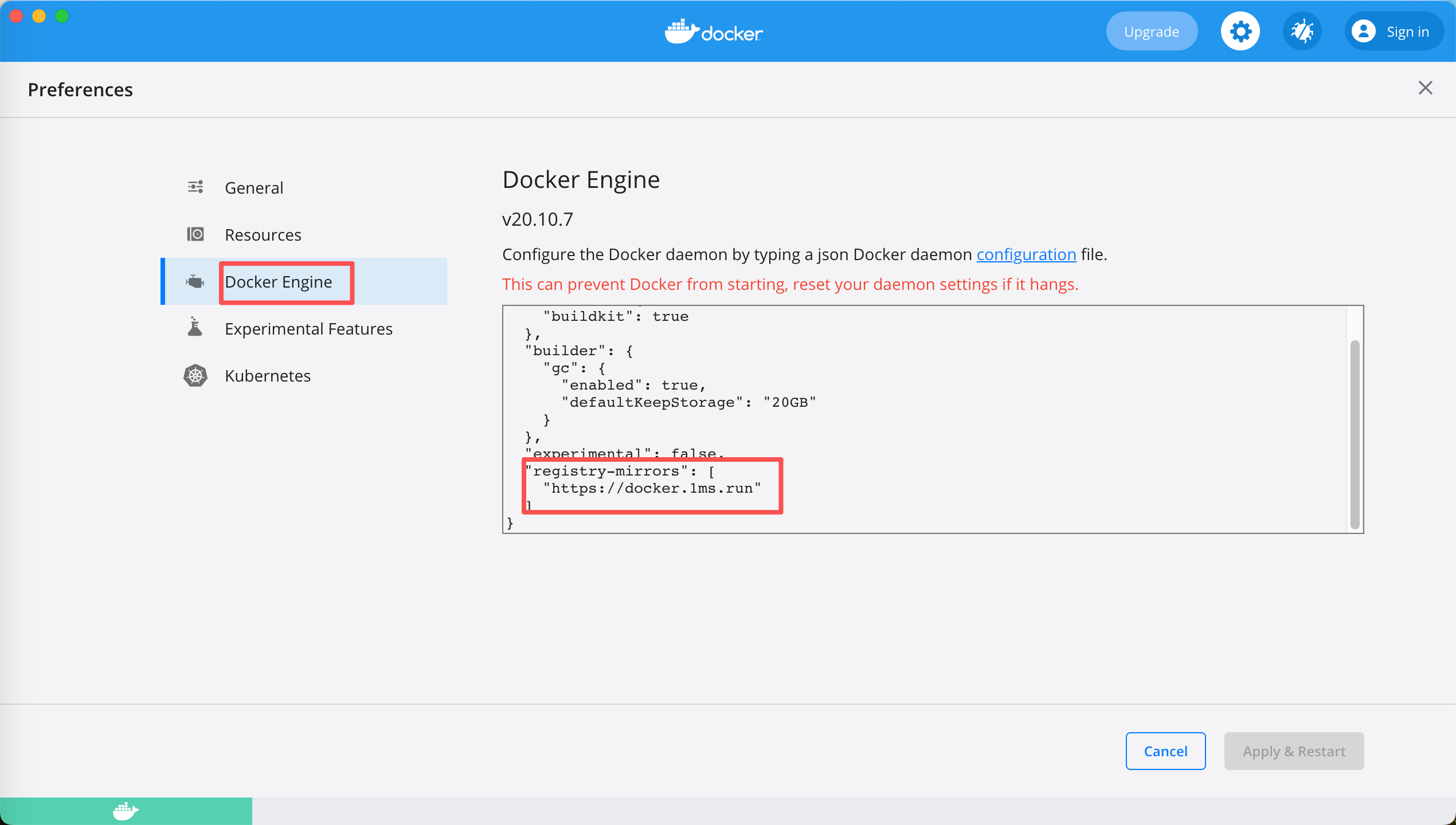
1、Mac下Docker配置国内镜像,加速拉镜像;
核心是增加国内镜像配置:
java
"registry-mirrors": [
"https://docker.1ms.run"
]
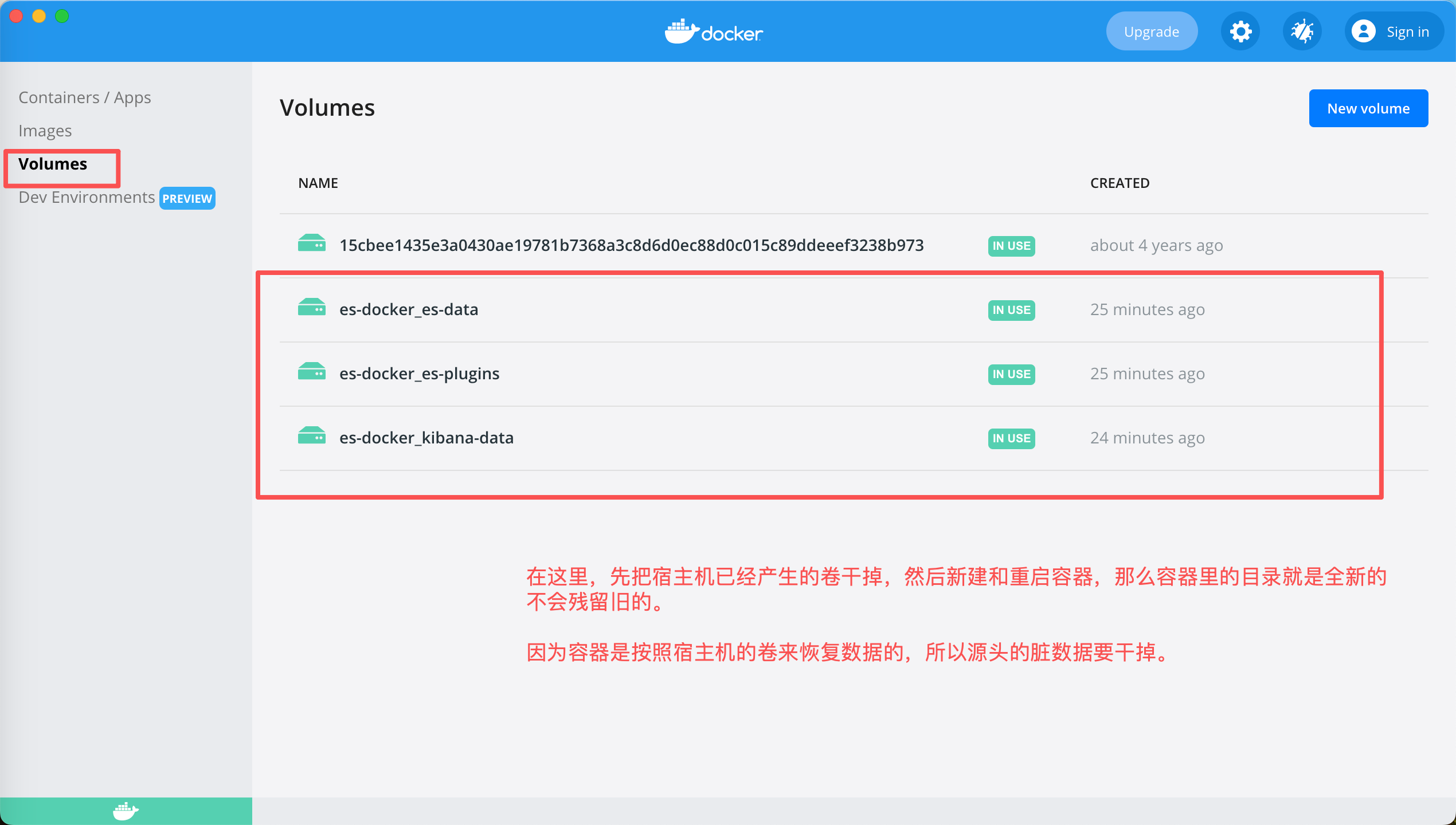
2、由于开始的docker-compose里配置了ik卷,开始启动的容器没问题,后来修改了脚本干掉了ik卷,新的容器就启动报错说找不到ik插件的配置文件
"... 6 more"] }
java.lang.IllegalStateException: Could not load plugin descriptor for plugin directory ik
Likely root cause: java.nio.file.NoSuchFileException: /usr/share/elasticsearch/plugins/ik/plugin-descriptor.properties
at java.base/sun.nio.fs.UnixException.translateToIOException(UnixException.java:92)
at java.base/sun.nio.fs.UnixException.rethrowAsIOException(UnixException.java:106)
at java.base/sun.nio.fs.UnixException.rethrowAsIOException(UnixException.java:111)
at java.base/sun.nio.fs.UnixFileSystemProvider.newByteChannel(UnixFileSystemProvider.java:218)
删掉容器也不行。原因是Docker Desktop挂载的卷在宿主机也就是Mac上已经产生了ik目录,所以docker-compose up -d的时候新建的容器自然也会形成这个目录,有了ik目录容器就去找对应的配置文件,所以报错。解决办法就是先干掉容器宿主机上的卷在重创建容器。