目录
Redis支持的数据结构
查看官网,Redis 支持以下数据结构,
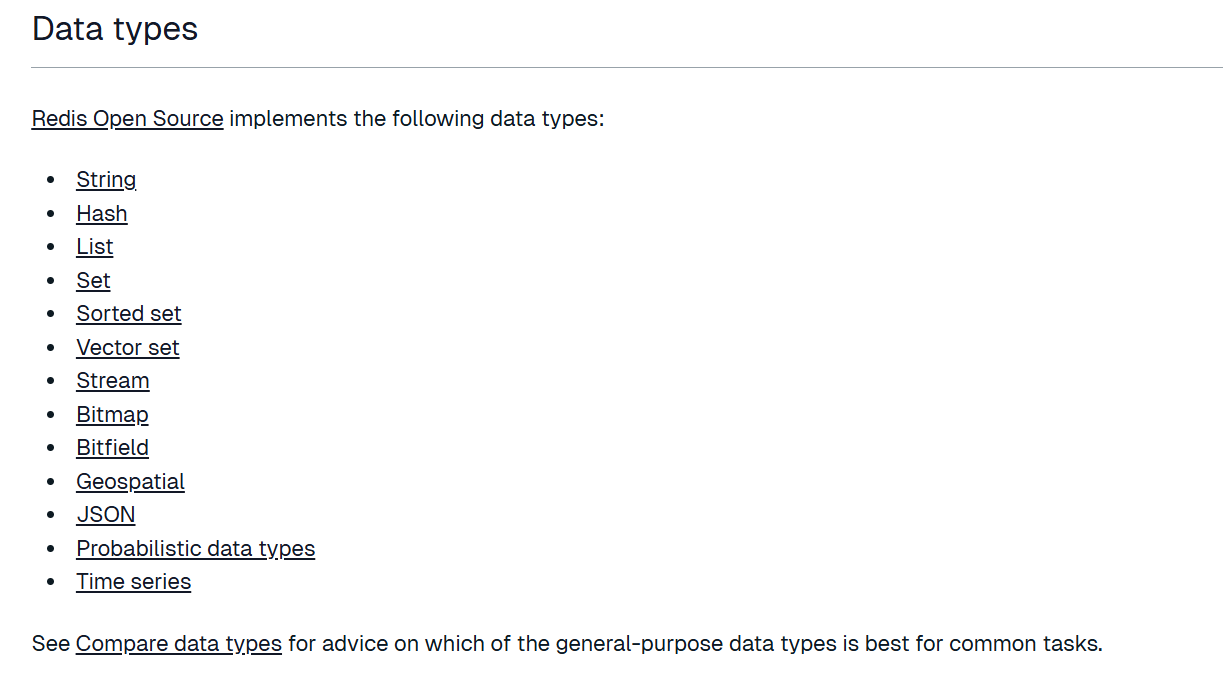
其中string(字符串)、list(列表)、hash(哈希)、set(集合)、zset(有序集合)最为常用。
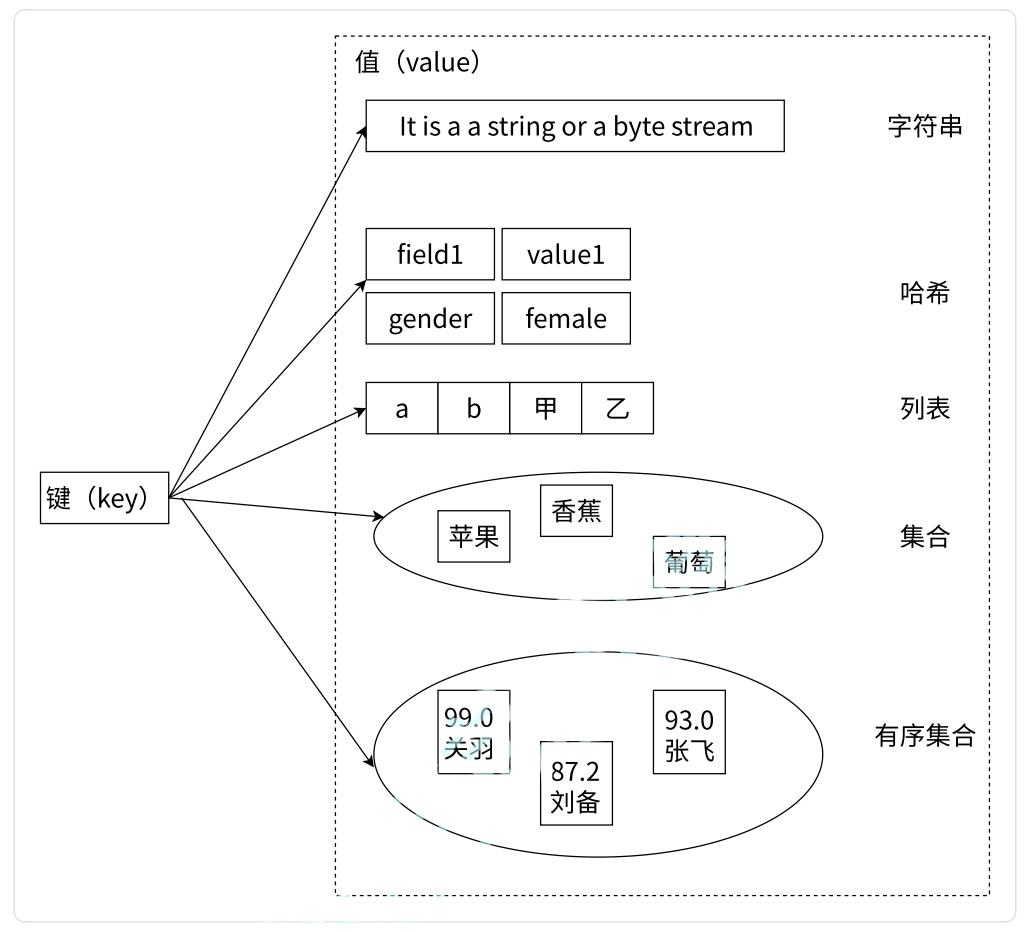
string 类似 C++ 中的 std::string ,哈希类似 std::unordered_map ,列表类似 std::deque ,集合类似 std::unordered_set ,有序集合,就是一个每个成员都有权值的 set ,然后 set 会根据这个权值进行排序。当然这只是粗略介绍,之后会详细讲解。
上面的数据结构,我们用起来就是这个用法,但是这些数据结构在源码层面,会进行特定的优化,同样的数据结构也会根据情况有一定的变数,来达到节省时间 / 空间的作用。
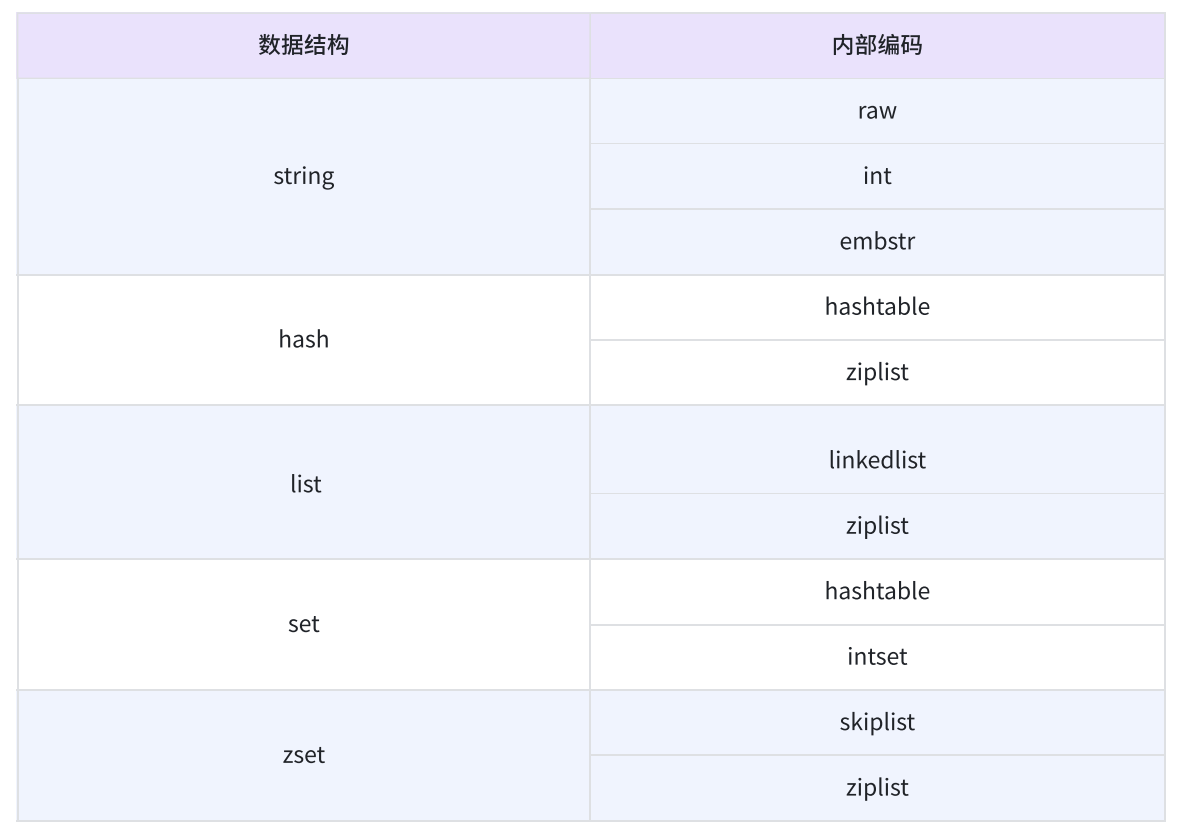
可以看到,即使是同样的数据结构,也会有不同的实现方式,我们程序员在使用时一般感知不到。
我们看 string, raw 编码可以认为是最基本的字符串。 C++ 角度来看就是 char 数组。而 int 就是 redis 通常用来实现一些计数等的功能,当 redis 的 string 存的是整数时,就是拿 int 来存,底层是8字节的,在 C++ 看来是 long long。 embstr 就是对短字符串的特殊优化。
而其他的数据结构中的 ziplist 是压缩列表,是 Redis 为了节省内存而设计的一种紧凑的、序列化的双向链表结构。它不像普通链表那样用指针连接节点,而是把所有元素连续地存放在一块内存里,通过记录每个元素的长度来定位下一个元素。在元素比较少时会使用这种编码,拿哈希来说,即使其查要求 O(1) ,但是因为元素少,所以即使暴力遍历也不会很慢,所以这里就省空间了。
对于list来说,虽然有两种编码方式,但是在 redis3.2 开始,引入了 quicklist,它兼具了 linkedlis t和 ziplist 的优点,每个元素又都是 ziplist ,所以说有点像 deque 。
intset 则是 set 在元素少且全是整数时的优化。
skiplist 则是跳表。
虽然讲了那么多编码方式,但是其实还是该怎么用怎么用,前面也说了,底层它优化就优化,用法不会产生改变,我们也不用过多在意,甚至特意去记什么大小改变编码,那都没有意义。
string
Redis 中的字符串直接按照二进制的方式存储的(不会做任何编码转换),像 MySQL ,就有很多编码格式,编码格式出错就会报错、乱码, Redis 就不会出这种问题,乱码问题概率更小。Redis 这种直接存二进制的方式使得存储无限制,适配所有数据类型,整数、字符串、JSON、xml、二进制数据(图片视频音频,不过 Redis 的 string 类型限制了大小 512M,因为单线程模型希望操作速度快)。相应的, Redis 自身也无法解析各类二进制数据。
set
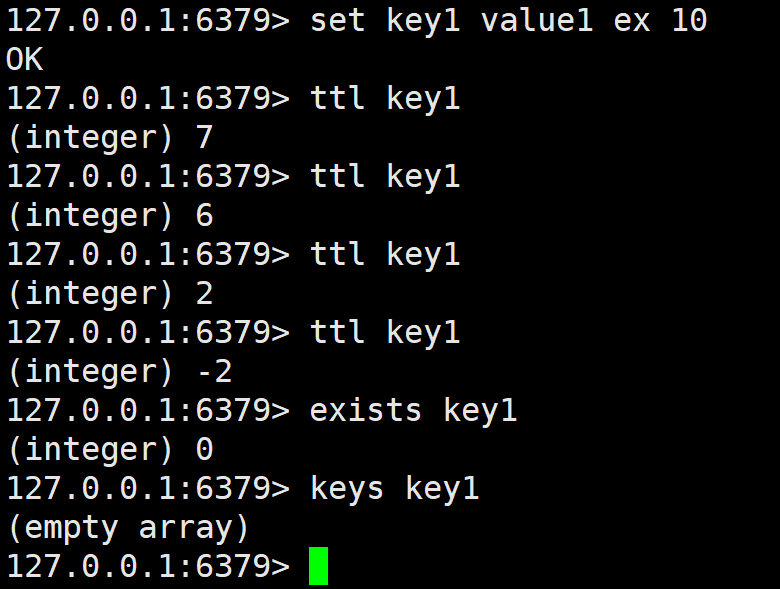
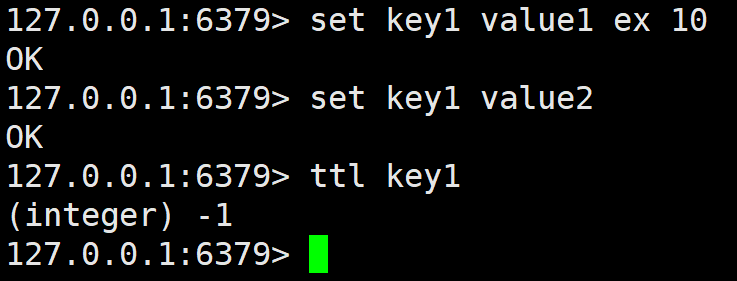
set可以将 string 类型的 value 设置到 key 中。默认无选项时如果 key 之前存在,则覆盖,无论原来的数据类型是什么。之前关于此 key 的 TTL 也全部失效。

set有许多选项,其中:
EX seconds------使用秒作为单位设置 key 的过期时间。
PX milliseconds------使用毫秒作为单位设置 key 的过期时间。
NX ------只在 key 不存在时才进行设置,即如果 key 之前已经存在,设置不执行。
XX ------只在 key 存在时才进行设置,即如果 key 之前不存在,设置不执行。
redis文档给出的语法格式说明,\[\] 相当于一个独立的单元,表示可选项(可有可无的),其中 | 表示"或者"的意思,多个只能出现一个。其中 \[\] 和 \[\] 之间是可以同时存在的。
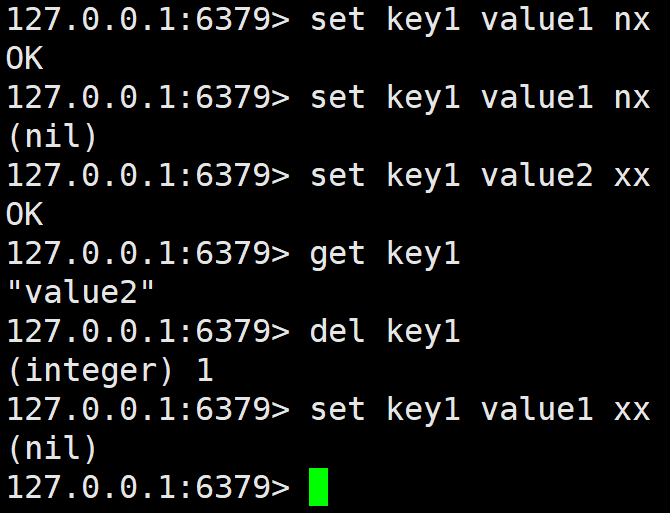
除此之外,set 还有 setnx、setex、psetex 等的接口,就是 set 自动加上选项 nx、ex、px。注意由于带选项的 set 命令可以被 setnx、 setex、 psetex 等命令代替,所以之后的版本中,Redis 可能进行合并,也就是setnx、setex、psetex 可能就无了。
像set使用选项比如ex,其实也保证了原子性,即设置键和设置超时时间是同时完成的,中间不会有其它操作,此外也提升了指令执行效率,因为前面也说过,网络IO才是占用时间的大头,我们应该尽量在少的网络IO次数中完成想要的操作。
get
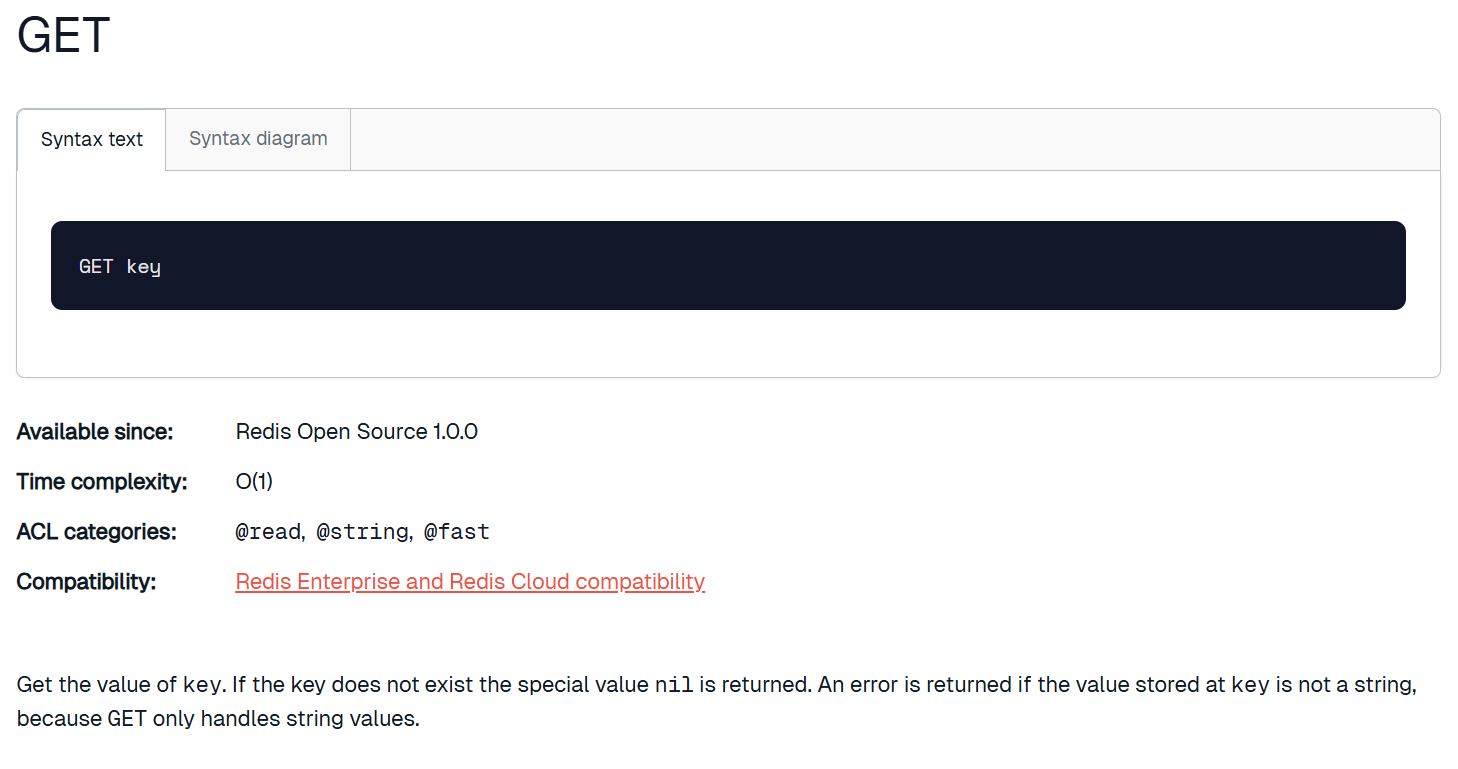
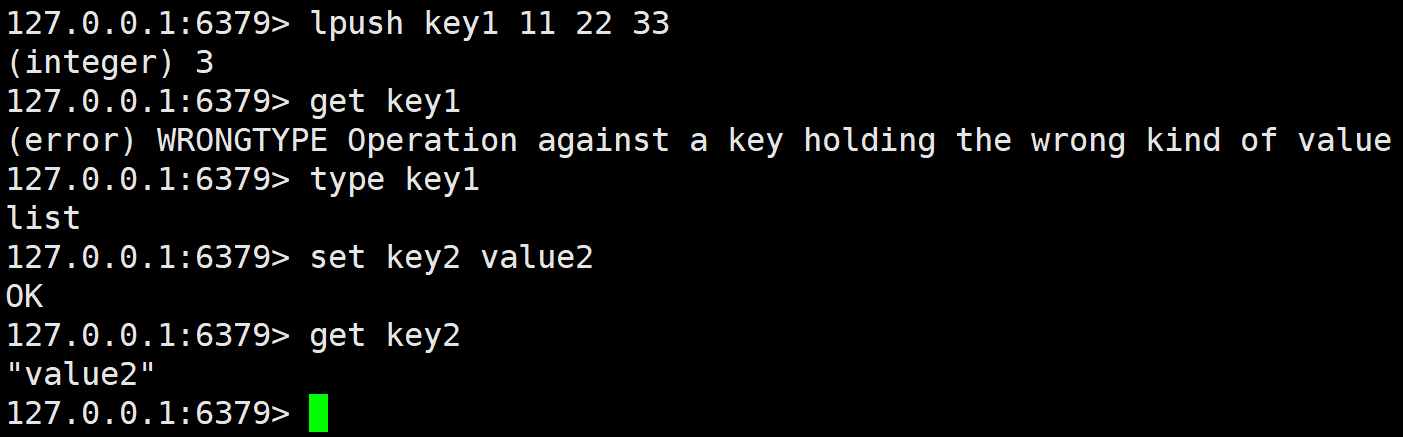
get可以获取 key 对应的 value。如果 key 不存在,返回 nil。如果 value 的数据类型不是 string,会报错。
mset和mget
mset一次性设置多个 key 的值。megt一次性获取多个 key 的值。如果对应的 key 不存在或者对应的数据类型不是 string,返回 nil。
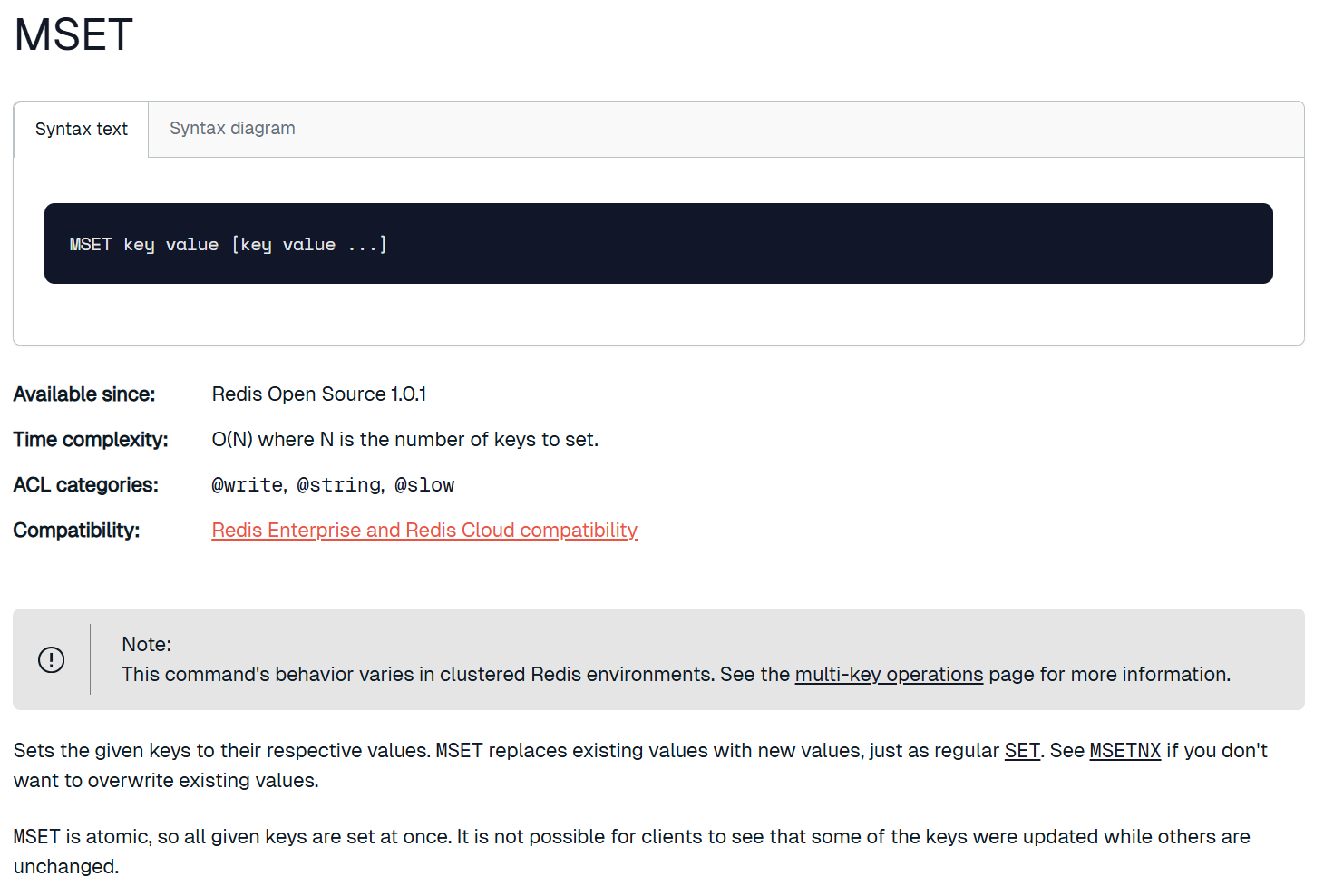
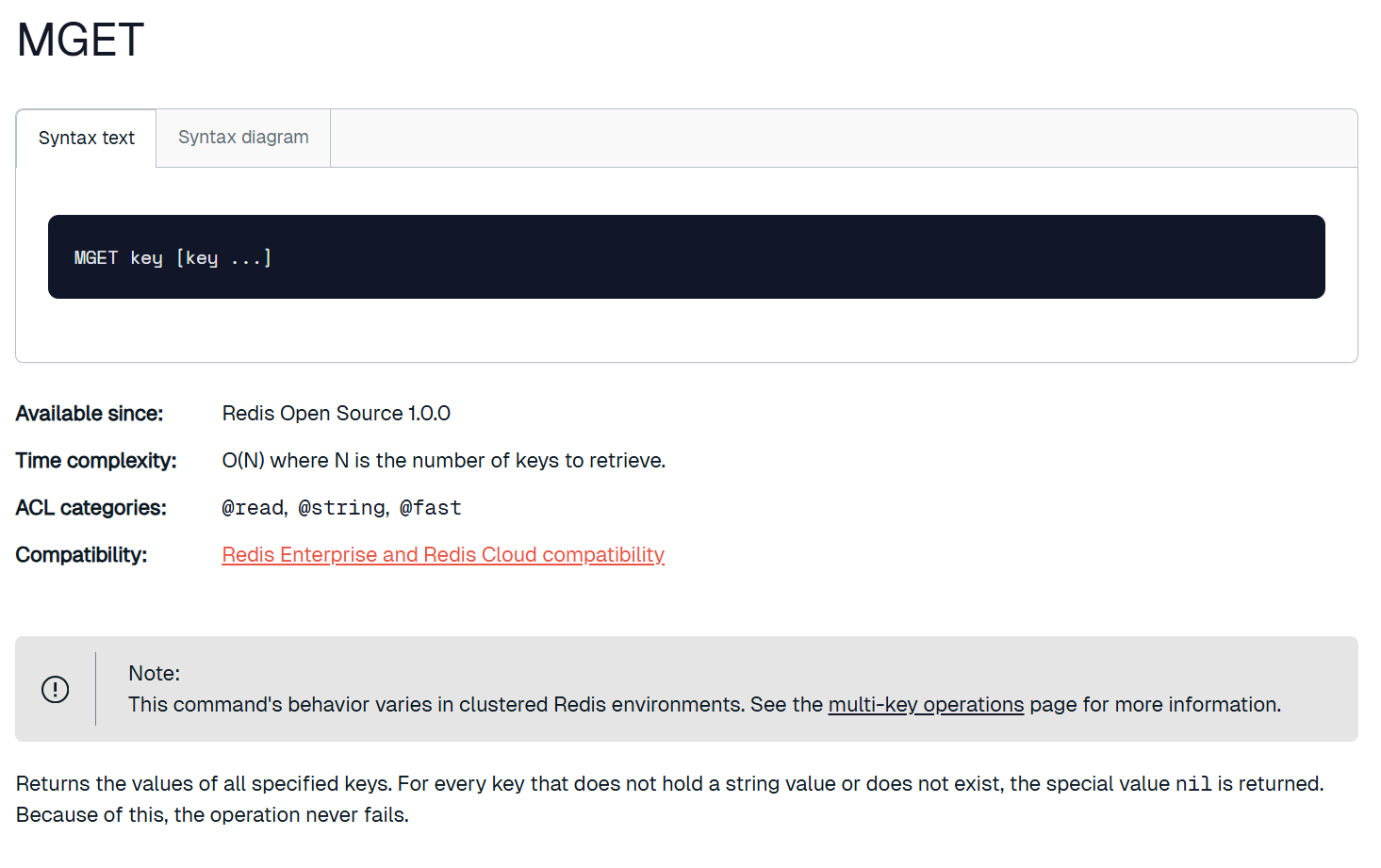
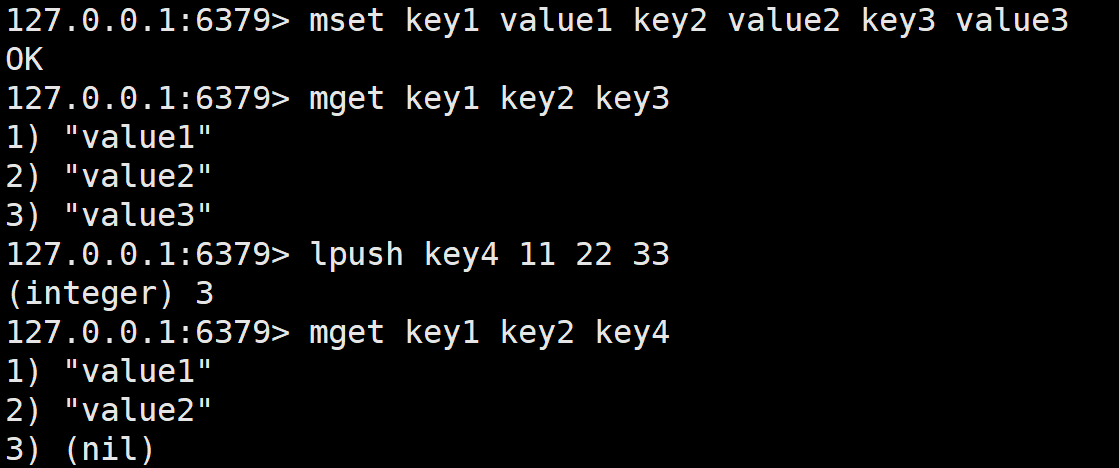
这里的时间复杂度 O(N) 是指设置的键值对数量是 N,实际设置的少和 O(1) 差不多,我们也不建议设置太多,因为 Redis 是单线程模型,设置太多可能会阻塞单线程。
数字相关
incr
针对 value 进行加1,注意这里 key 对应的 value 得是整数,这个整数是64位也就是8字节的有符号整数,对应到C++就是 long long 。
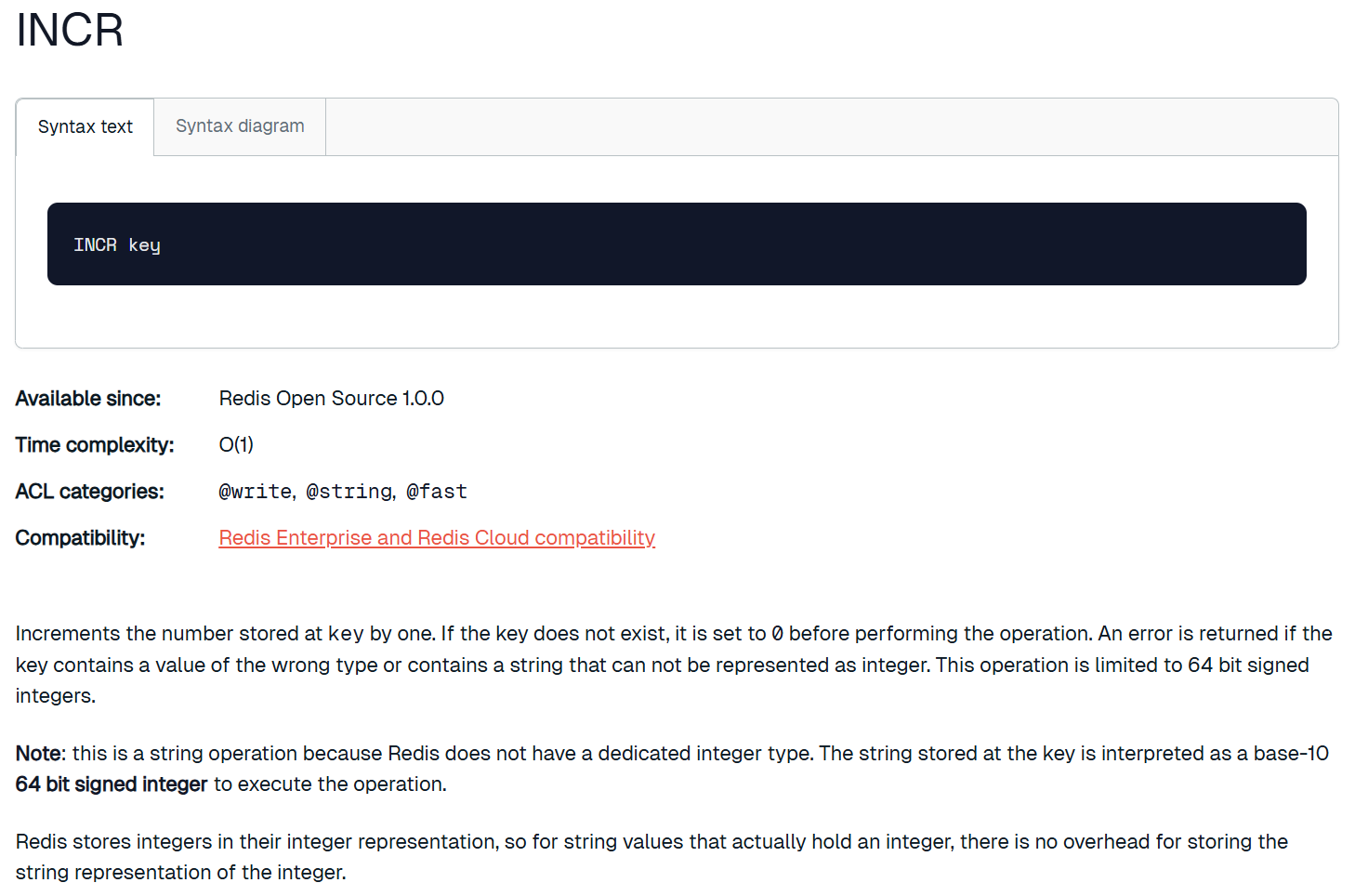
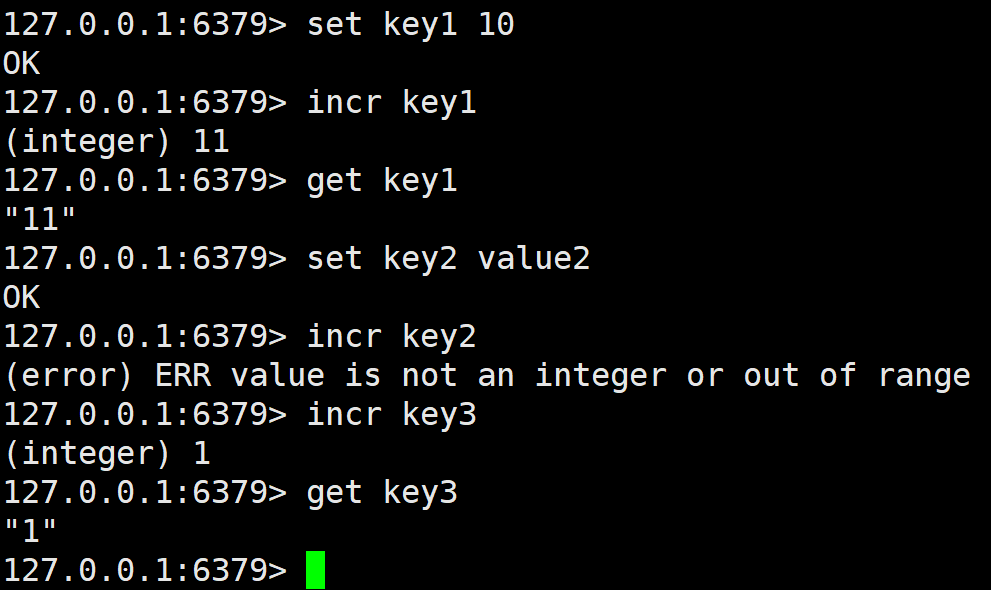
注意 incr 返回的值是 +1 之后的值,也就是前置加加。另外,如果 incr 的 key 是不存在的,那么就会将这个key创建,value 当成0来使用。
incrby
将 key 对应的 string 表示的数字加上对应的值。如果 key 不存在,则视为 key 对应的 value 是 0。如果 key 对应的 string 不是一个整型或者范围超过了 64 位有符号整型,则报错。
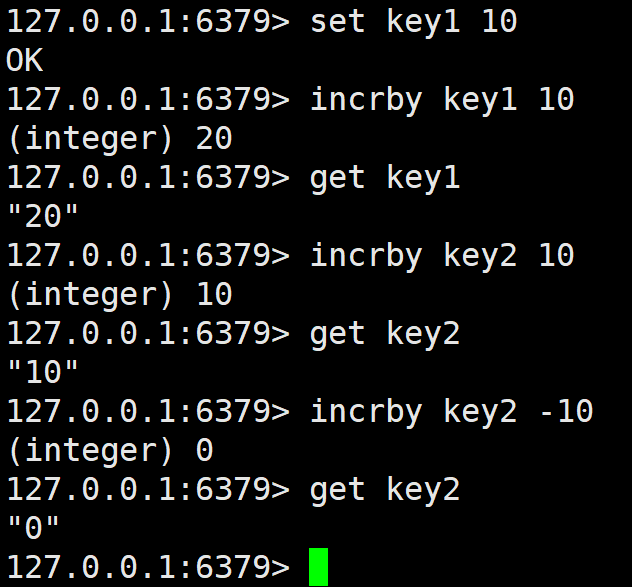
注意这里可以通过加负数来达到减法的效果。
decr
将 key 对应的 string 表示的数字减一。如果 key 不存在,则视为 key 对应的 value 是 0。如果 key 对应的 string 不是一个整型或者范围超过了 64 位有符号整型,则报错。
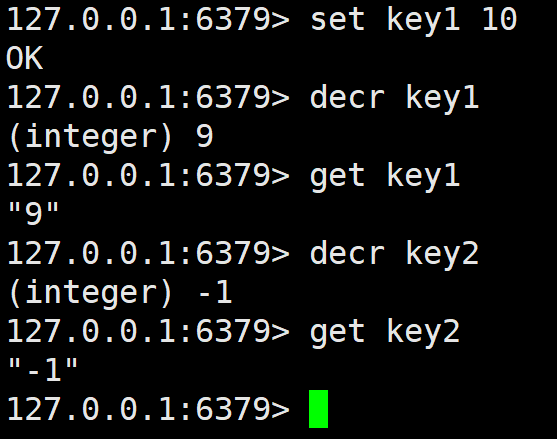
同样返回 -1 之后的结果。
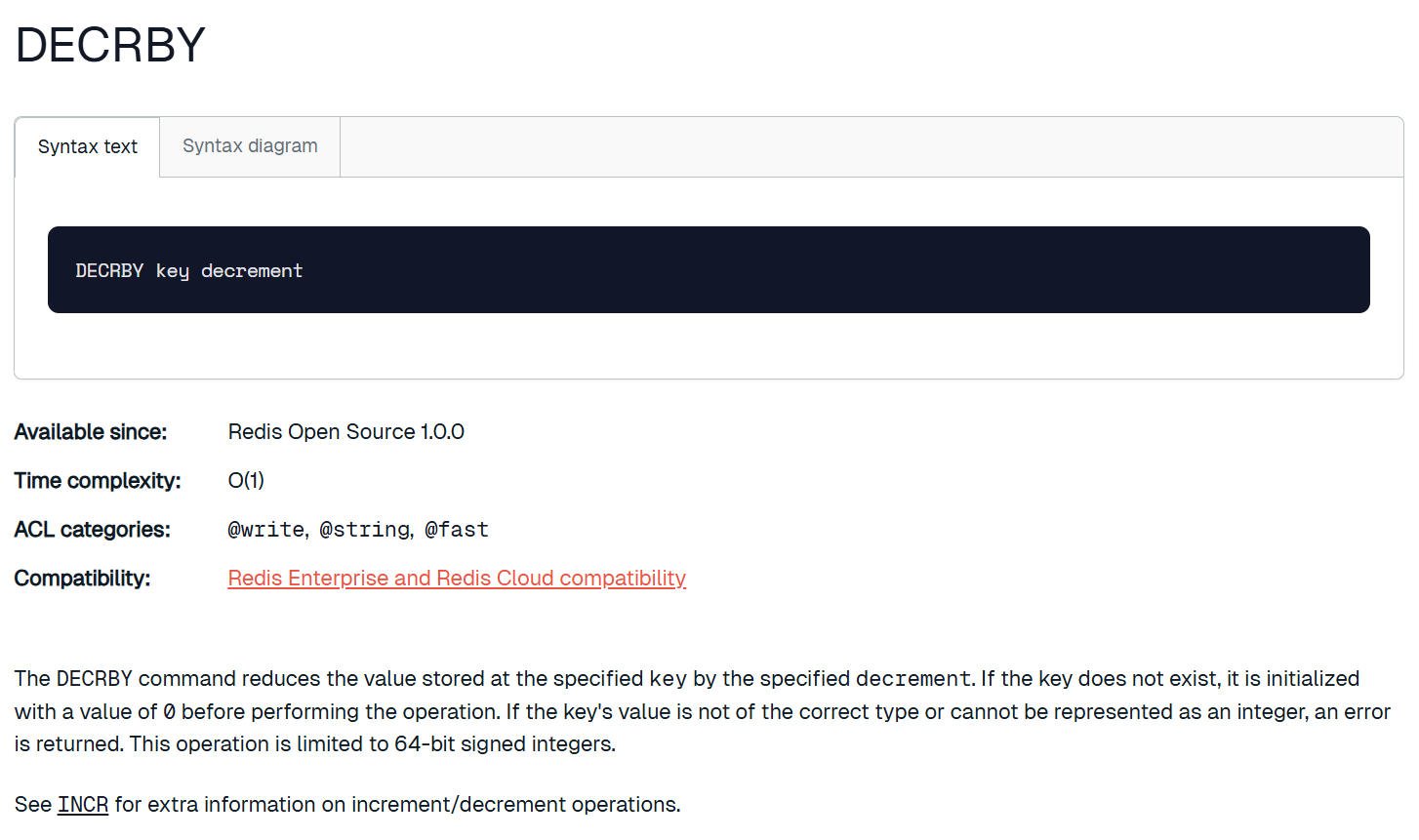
decrby
将 key 对应的 string 表示的数字减去对应的值。如果 key 不存在,则视为 key 对应的 value 是 0。如果 key 对应的 string 不是一个整型或者范围超过了 64 位有符号整型,则报错。
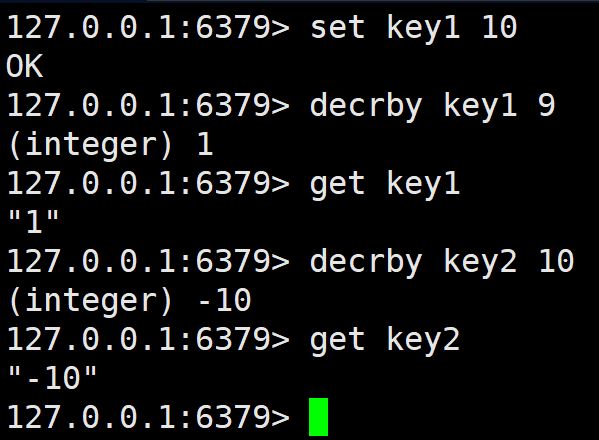
incrbyfloat
将 key 对应的 string 表示的浮点数加上对应的值。如果对应的值是负数,则视为减去对应的值。如果key 不存在,则视为 key 对应的 value 是 0。如果 key 对应的不是 string,或者不是一个浮点数,则报错。允许采用科学计数法表示浮点数。
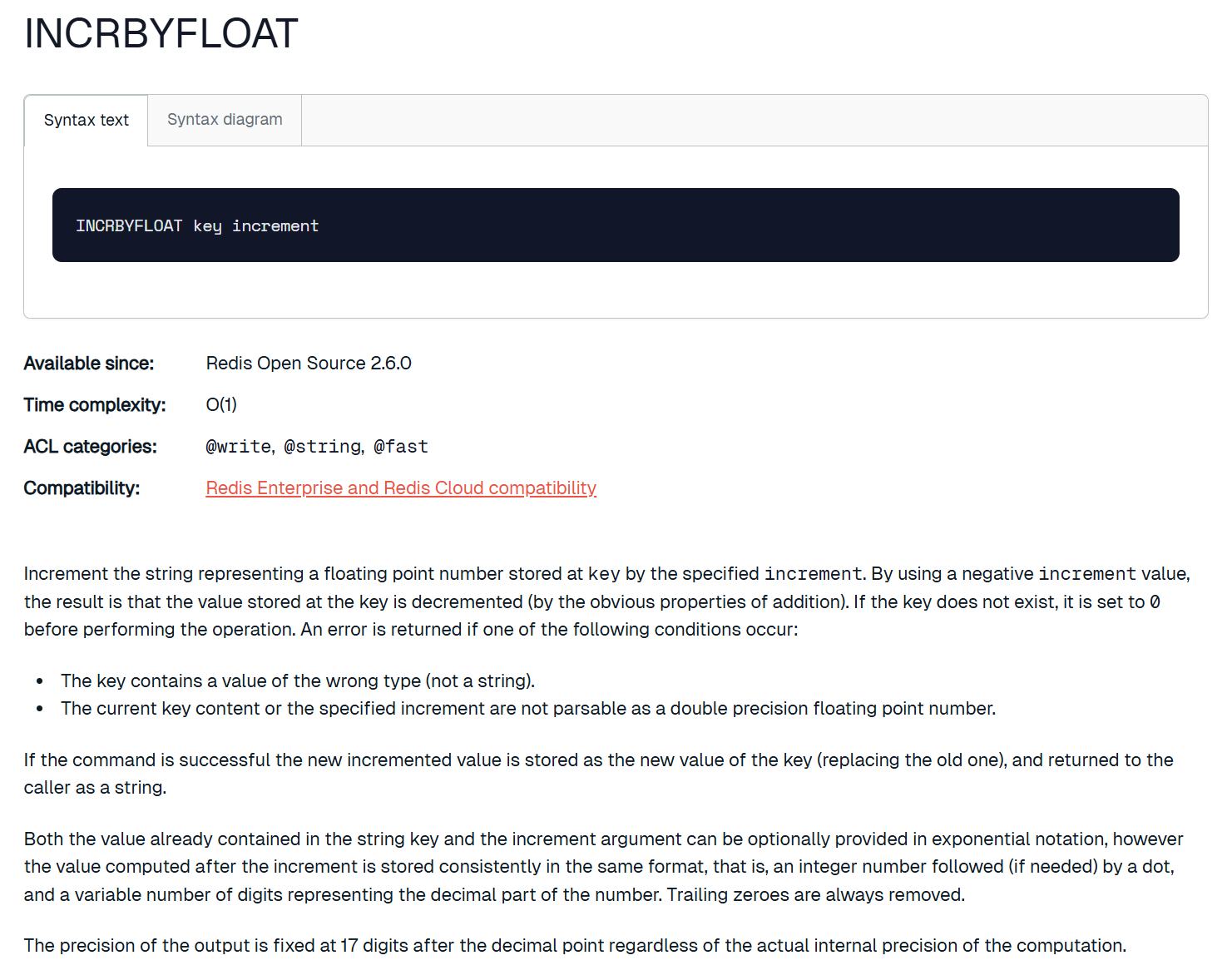
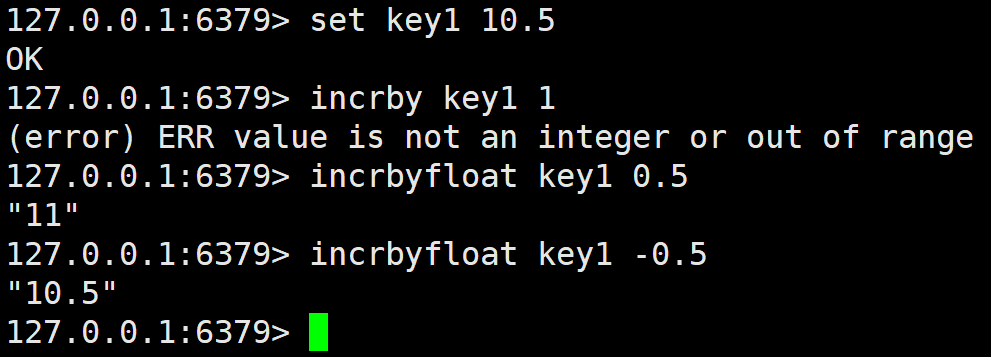
之前的那些指令都不能对浮点数进行操作,这个指令可以。但是这个指令没有配套的 decrbyfloat,如果我们想要减的话可以通过加上负数来实现。浮点数的加减在Redis中也并不常见,多是整数。
append
如果 key 已经存在并且是一个 string,命令会将 value 追加到原有 string 的后边。如果 key 不存在,则效果等同于 SET 命令。
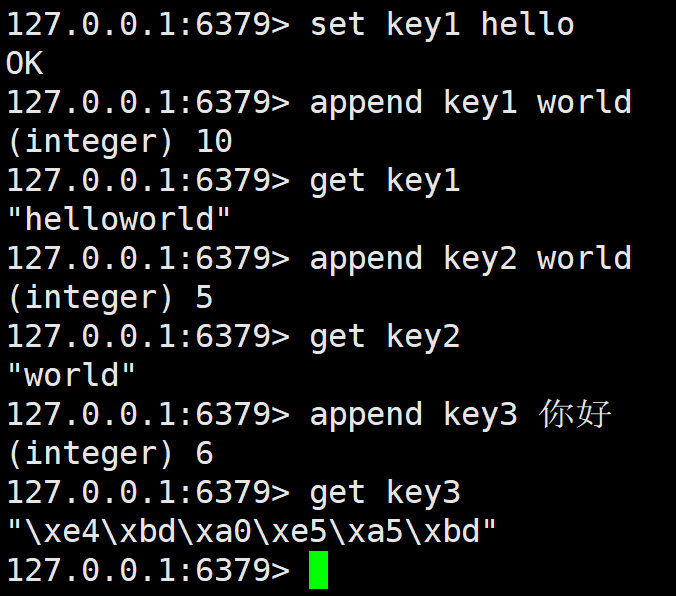
指令返回追加后的字符串的长度,如果 key 不存在则创建一个视为空追加,等价于 set。值得注意的是,如果追加汉字,则返回字符数乘3的增加数,因为这里的 Xshell 是 utf8 编码,一个汉字3个字节存,所以这里返回的是以字节为单位的长度。查看 value,发现和utf编码一样。
这里的\x表示这是十六进制,可以无视。
如果我们就是想要看到原本设置的结果,那么我们可以在启动redis客户端时在后面加上选项--raw,这表示让 Redis 客户端以原始字符串格式返回结果,而不进行任何转义或格式化,也就是不自动转义成类似 \n、\x00 的形式,这样Xshell自己又用 utf8 解码回来,就又能看到了。
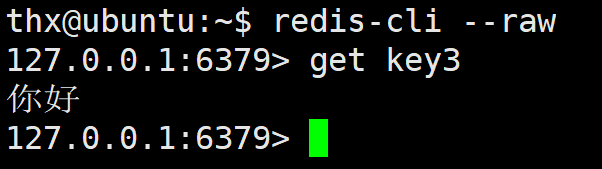
getrange
返回 key 对应的 string 的子串,由 start 和 end 确定(左闭右闭)。可以使用负数表示倒数。-1 代表倒数第一个字符,-2 代表倒数第二个,其他的与此类似。超过范围的偏移量会根据 string 的长度调整成正确的值。
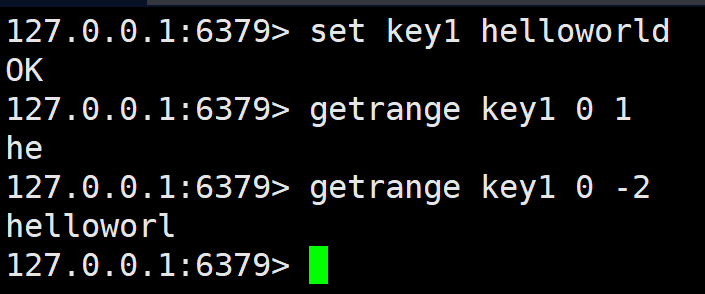
该指令效果类似 substr,但是是左闭右闭。使用时还可以用负数,表示倒数第几个的意思。
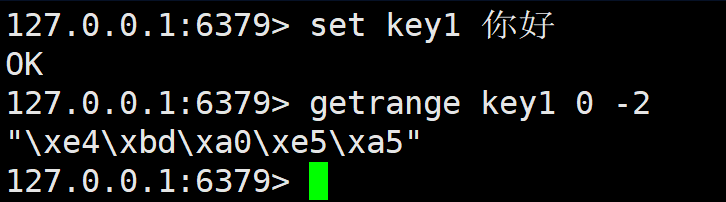
注意对汉字来说还是以字节为单位,不是汉字数。
setrange
覆盖字符串的一部分,从指定的偏移开始。
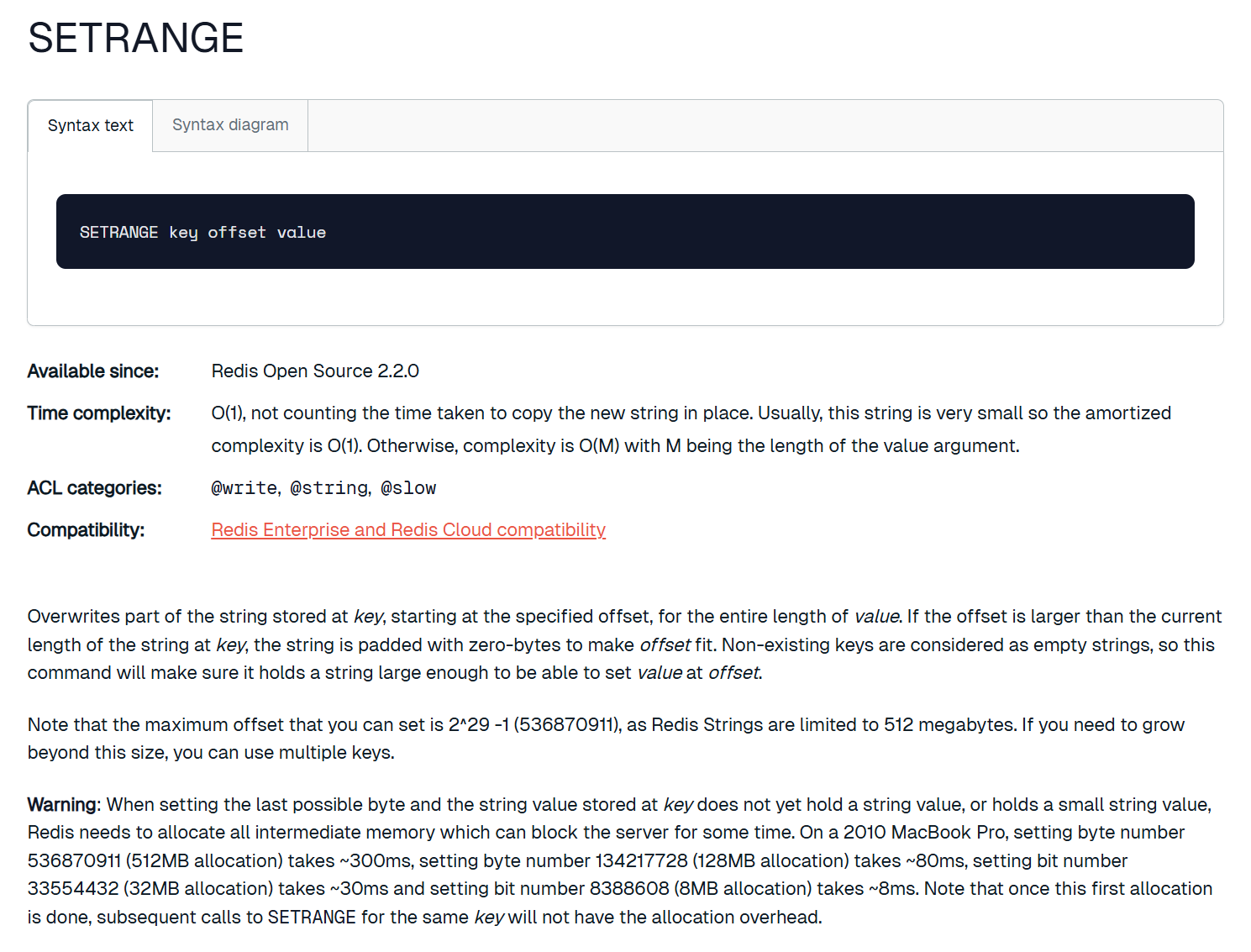
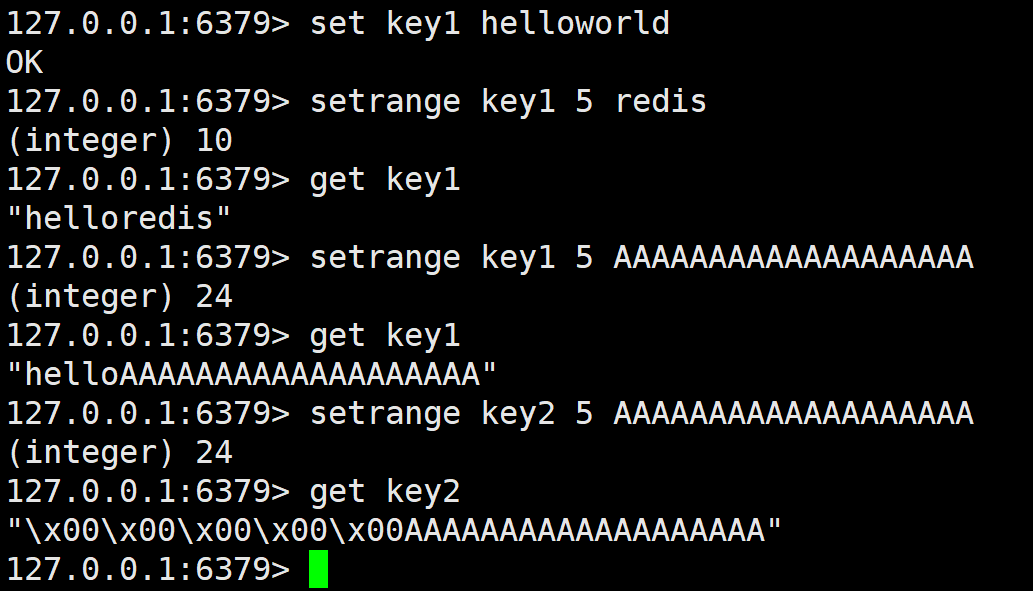
可以看到这里只用指定开始的偏移量,结束位置根据覆盖的字符串的长度决定,提前结束了就还有一部分保留,如果超出了原本字符串那也会正常替换。另外,setrange 也能对不存在的key使用,它会将 offset 之前的字符填充成 \x00。
strlen
获取 key 对应的 string 的长度。当 key 存放的类似不是 string 时,报错。
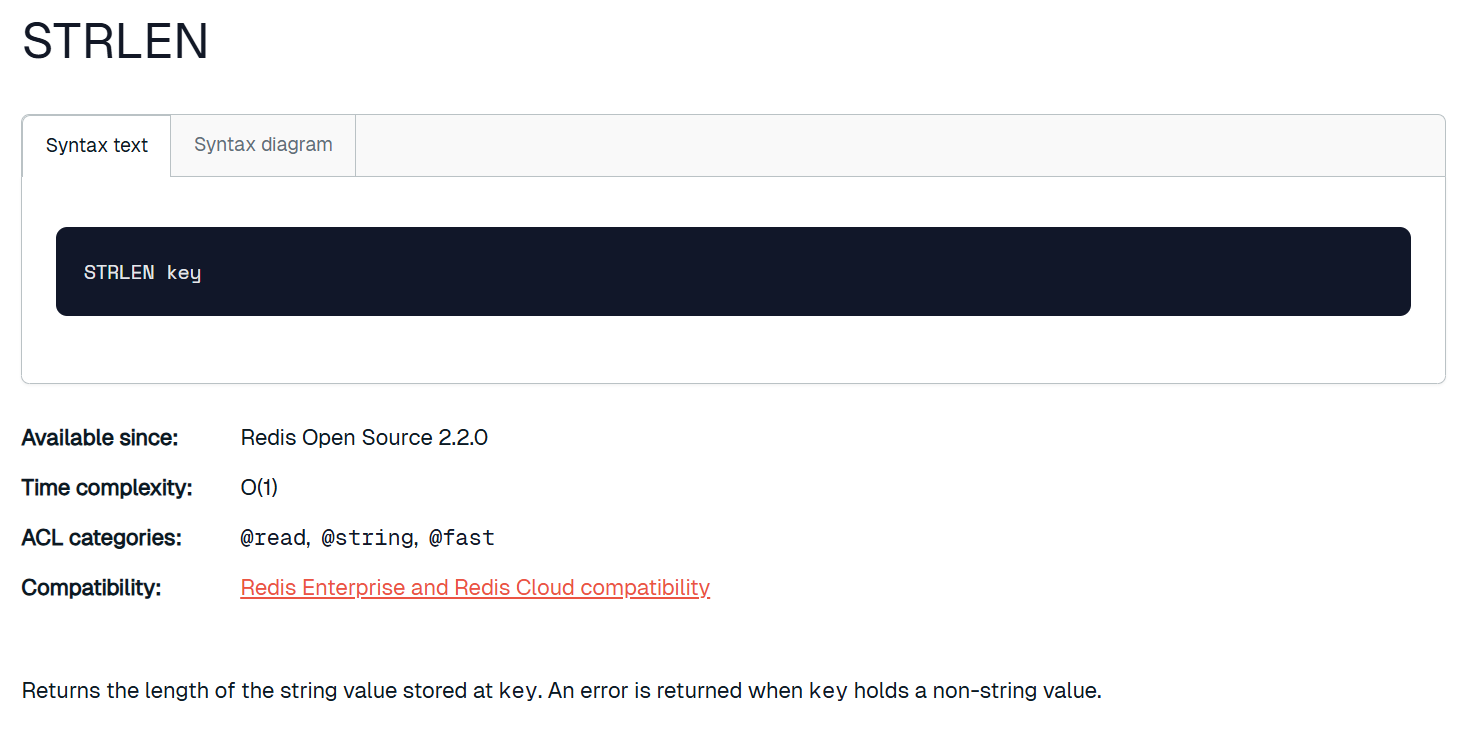
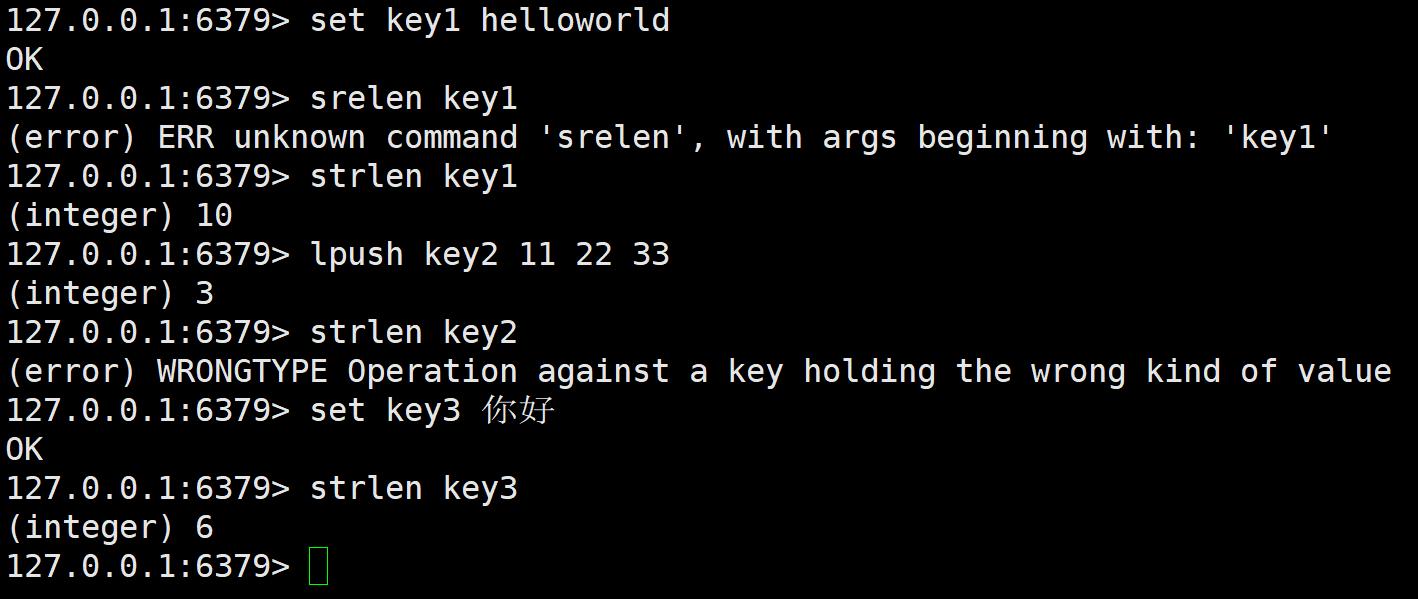
可以看到对于汉字还是乘以3的结果,所以这是以字节为单位的。
object encoding
使用 object encoding 可以查看用于查询指定键对应值的底层存储编码格式,这个不是 string 专属的。我们使用这个指令查看一下 string 的各个编码方式。

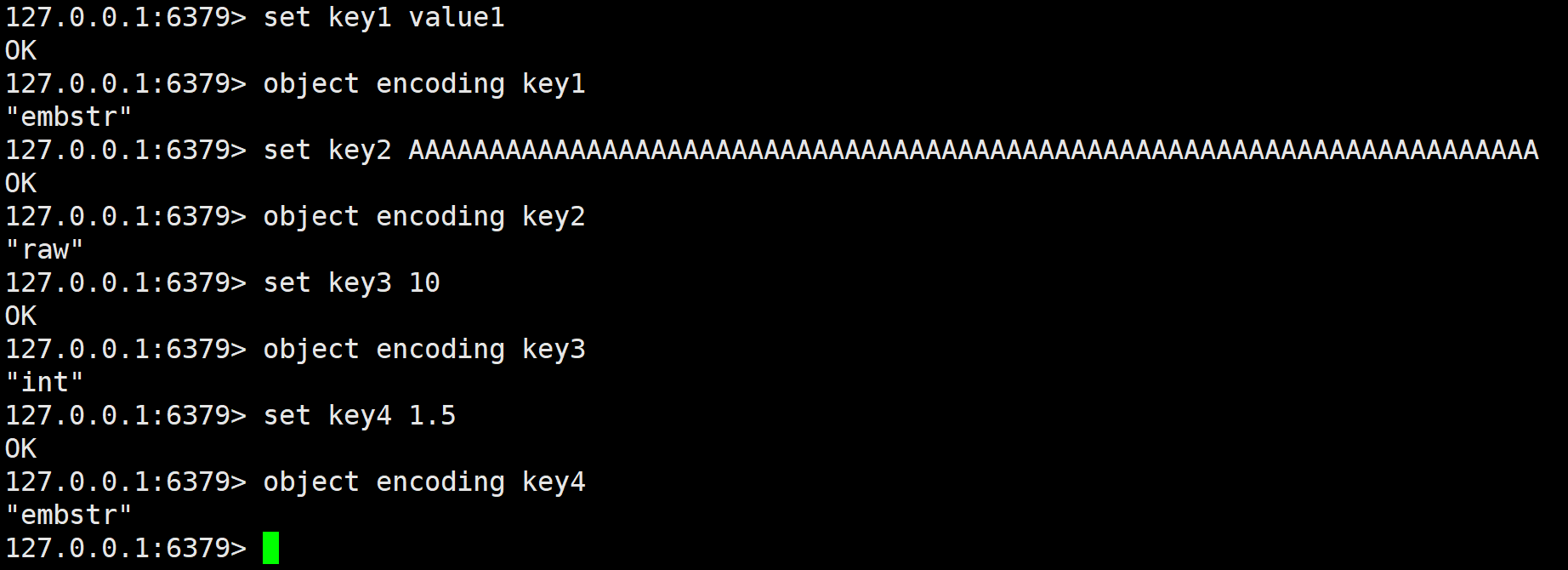
注意看当 string 较短时,编码格式为 embstr,较长时就是 raw,是整数的话则是 int,而小数则还是用字符串来存,所以小数的计算就会有两次转换,会有一定的性能开销,所以我们使用小数的话一定要权衡好利弊。
string的用途
缓存是 Redis 字符串最典型的用途之一。在这类场景中,Redis 会作为缓冲层,MySQL 作为持久化存储层。绝大部分请求会优先从 Redis 获取数据,只有缓存未命中时才会去 MySQL 查询,再将结果写入 Redis 并设置过期时间。这种方式能极大提升读写速度,降低后端数据库的访问压力,比如根据用户 uid 获取用户信息的场景,理想情况下每个用户的信息一小时内只会查询一次 MySQL。
计数功能也是 Redis 字符串的核心用途。利用INCR等命令可以实现快速计数,比如视频网站的播放次数统计,用户每播放一次视频,就对对应的键执行自增操作。同时计数数据还可以异步同步到其他数据源,支撑高并发场景下的实时计数需求。不过实际开发成熟的计数系统,还需要解决防作弊、多维度计数、避免单点问题等挑战。
集中管理 Session 是分布式 Web 服务中常见的应用。分布式系统中用户请求会被负载均衡到不同服务器,如果 Session 分散存储在各服务器,用户刷新请求时可能需要重新登录。通过 Redis 集中存储 Session 信息,无论用户请求被分配到哪台服务器,都能从 Redis 中统一查询和更新 Session,保证了 Session 的一致性和服务的可用性。
实现手机验证码功能也依赖于 Redis 字符串。为了防止短信接口被频繁调用,会限制用户每分钟获取验证码的次数,比如一分钟最多 5 次。这可以通过 Redis 的SET ... NX和INCR命令实现,同时还会将生成的验证码存入Redis 并设置过期时间(如 5 分钟),在验证时再从 Redis 中取出对比,以此保证验证码的时效性和安全性。