导言 :您是否出现这样的情况?急需上周各渠道的投入产出分析来调整本周预算,却被告知"数据还在跑,最快下午能出";想实时查看不同地区新产品的销量排行,看到的却是前一天下班前的静态数字。
给您推荐一个好帮手:AllData数据中台集成的开源项目Kylin作为数仓建模平台。上手体验后被数仓建模平台Kylin能力惊艳到。
原本以为 "处理 PB 级数据"、"秒级出分析结果" 是只有技术专家才能玩转的复杂操作,没想到亲测后发现,哪怕像我这样对代码一知半解的非技术人员,也能轻松用起来。

数仓建模平台(Kylin)是企业处理海量数据的"智能加速器"。简单来说,数仓建模平台是一个分布式的分析引擎,能在Hadoop/Spark等大数据生态之上,提供亚秒级的多维分析(OLAP)查询能力。
核心创新在于采用了"空间换时间"的策略。AllData数据中台把开源项目Kylin集成进来,相当于给企业搭了个 "智能图书馆",不用自己请 "整理员"(不用技术团队从零开发),直接用现成的工具,就能快速处理海量数据,还能对接金融、制造、电商等各种业务场景。
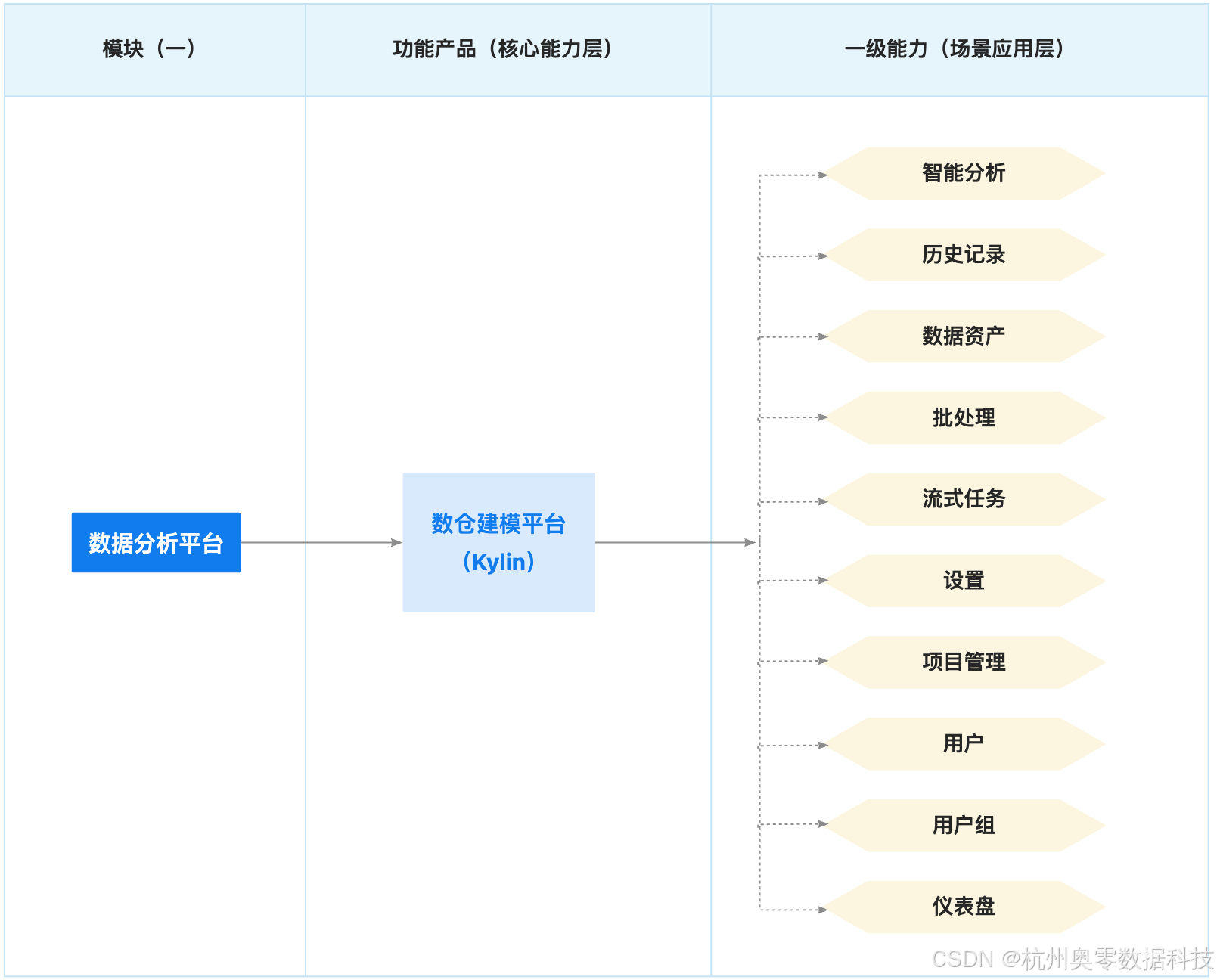
一、【数仓建模平台】功能架构
数仓建模平台(Kylin)的功能架构核心是 "离线预计算 + 在线秒级查询",以 "空间换时间" 实现海量数据高效分析,整体结构简洁清晰。
1、数据源层:
支持hive和kafka两种数据源,支持接入事实表、维度表等结构化数据,且仅需遵循星形模型即可适配,兼容性强。
2、离线构建层:
根据定义的维(度如时间、地区)和度量(如销量、销售额),通过MapReduce/Spark引擎预计算所有维度组合,生成Cube(含多种 Cuboid 物化视图),提前存储计算结果。
3、存储层:
将预计算好的Cube结果存入HBase,通过物化视图形式留存,为后续查询快速调取数据奠定基础。
4、查询服务层:
提供RESTful API、JDBC/ODBC等接口,接收用户查询请求后,解析并匹配对应的Cube结果,无需实时计算即可返回答案。
二、【核心能力演示】这位 "智能图书馆" 有什么惊喜?
数仓建模平台(Kylin)是AllData数据中台核心功能,下面结合实际场景,给大家演示。
🔹项目地址:https://kylin.apache.org/zh-Hans/docs/overview
1、快速建 "分析模型":像搭积木一样简单
支持通过界面化流程快速搭建分析模型,只需三步即可完成:
✅ 第一步在界面选择并对接目标数据源,无需手动导入数据;
✅ 第二步勾选需要分析的维度;
✅ 第三步设定核心统计指标。
全程采用下拉菜单和勾选操作,操作简单高效,短时间内即可完成模型搭建。
测试时:要分析 "不同地区、不同品类的双 11 销量",首先得建个 "分析模型",只要在数仓建模平台(Kylin) 界面里,只要 3 步操作,全程都是下拉菜单和勾选操作,不到 5 分钟就建好了模型,比想象中简单太多。
2、预计算 "Cube":让大数据分析 "秒出结果"
✅模型搭建完成后,通过界面点击即可启动Cube构建任务;
✅系统会自动预计算所有维度组合的结果并存储为Cube;
✅基于预计算结果,后续的各类数据查询无需实时计算;
✅可实现海量数据的秒级响应,大幅提升查询效率。
测试时:上传了 2024 年全年的电商订单数据(大概 500G,相当于 200 多部高清电影),点【构建】后,系统自动跑任务,完成后查任何组合的销量:比如 "11 月 11 日 - 华南地区 - 手机品类 - 销量 TOP3",原本用传统工具要等 5 分钟,现在 1 秒不到就出结果,刷新页面时还以为点错了,反复试了 3 次都是秒出。
3、灵活查数据:便捷操作 "查询"
内置可视化查询界面,无需编写 SQL 语句。用户可直接在界面设置查询条件,完成数据筛选与分组操作,系统自动返回查询结果,同时支持将结果一键生成各类可视化图表,无需额外导出数据进行二次处理。
数仓建模平台(Kylin)的 "查询界面",像用Excel筛选一样简单:比如想查 "双 11 期间,客单价超过 500 元的订单分布",直接在界面输 "客单价 > 500",再选 "按地区分组",点 "查询" 就出结果;还能直接生成柱状图、折线图,非常清晰。
4、实时更数据:数据变了不用重新算
支持Cube增量更新功能,当数据源产生新数据时,系统无需重新计算全量 Cube,仅针对新增数据部分进行计算并合并到已有Cube中。
测试时:模拟了 "每小时新增 5000 单",系统全程自动更新,查 "实时销量" 时,数据和后台订单系统完全同步,没出现过延迟。
5、能监控会预警:不怕操作出错
配备完善的任务监控功能,在 Cube 构建等关键流程中,系统会实时监控任务状态。当遇到资源不足导致任务排队时,会给出预计等待时间;当数据源配置错误或缺失关键字段时,会即时标红提示问题所在,帮助用户快速定位并解决操作失误。
数仓建模平台(Kylin)的 "任务监控" 功能特别贴心:比如构建Cube时,要是资源不够,界面会弹出 "当前任务排队中,预计 10 分钟后开始" 的提示;要是选的数据源有问题,会直接标红 "某表缺少'销量'字段",不用自己瞎猜哪里错了。
三、【数仓建模平台】功能能力演示
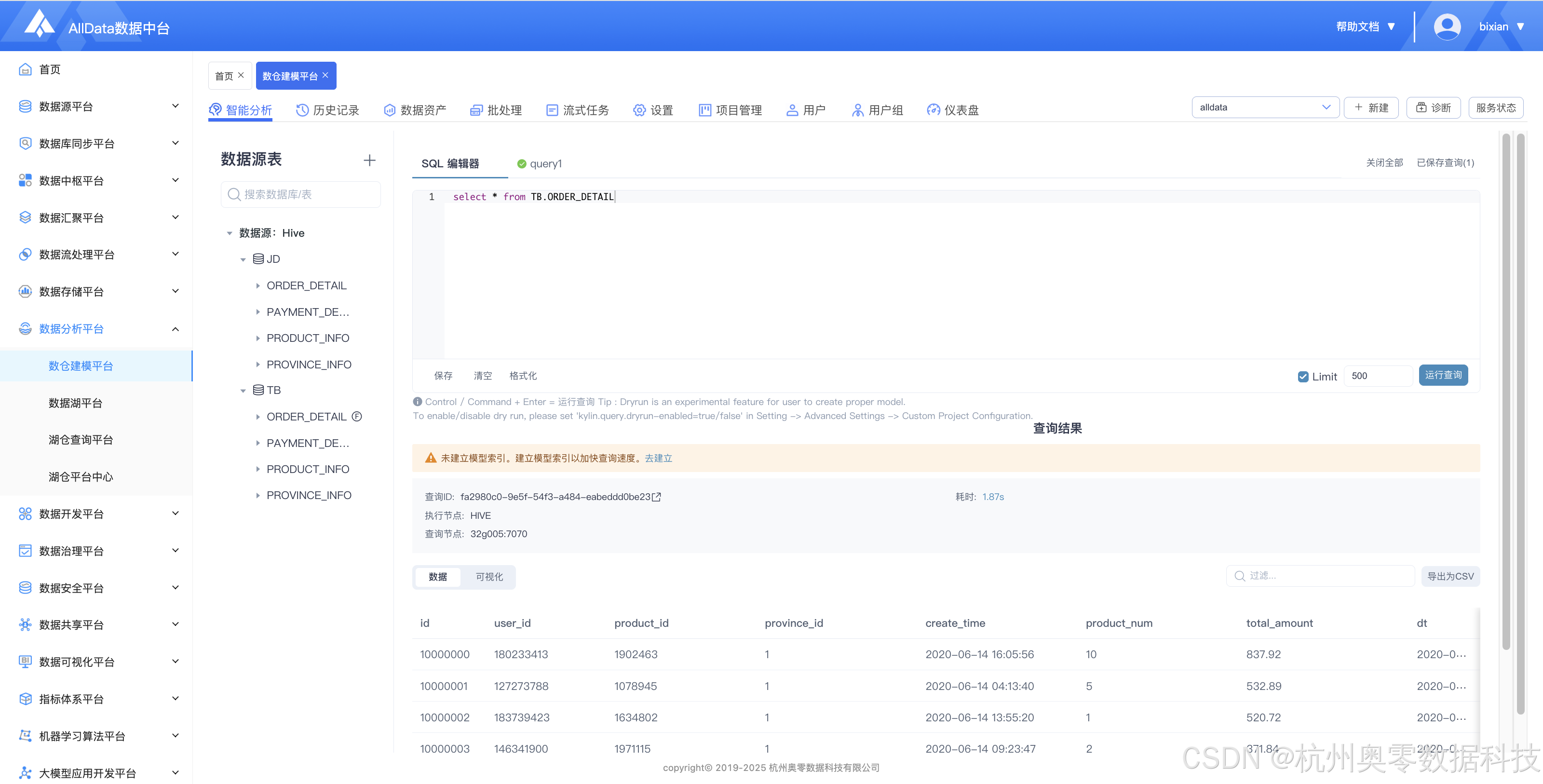
1、智能分析 (自动挖掘数据价值,提供可视化洞察与精准决策支持)
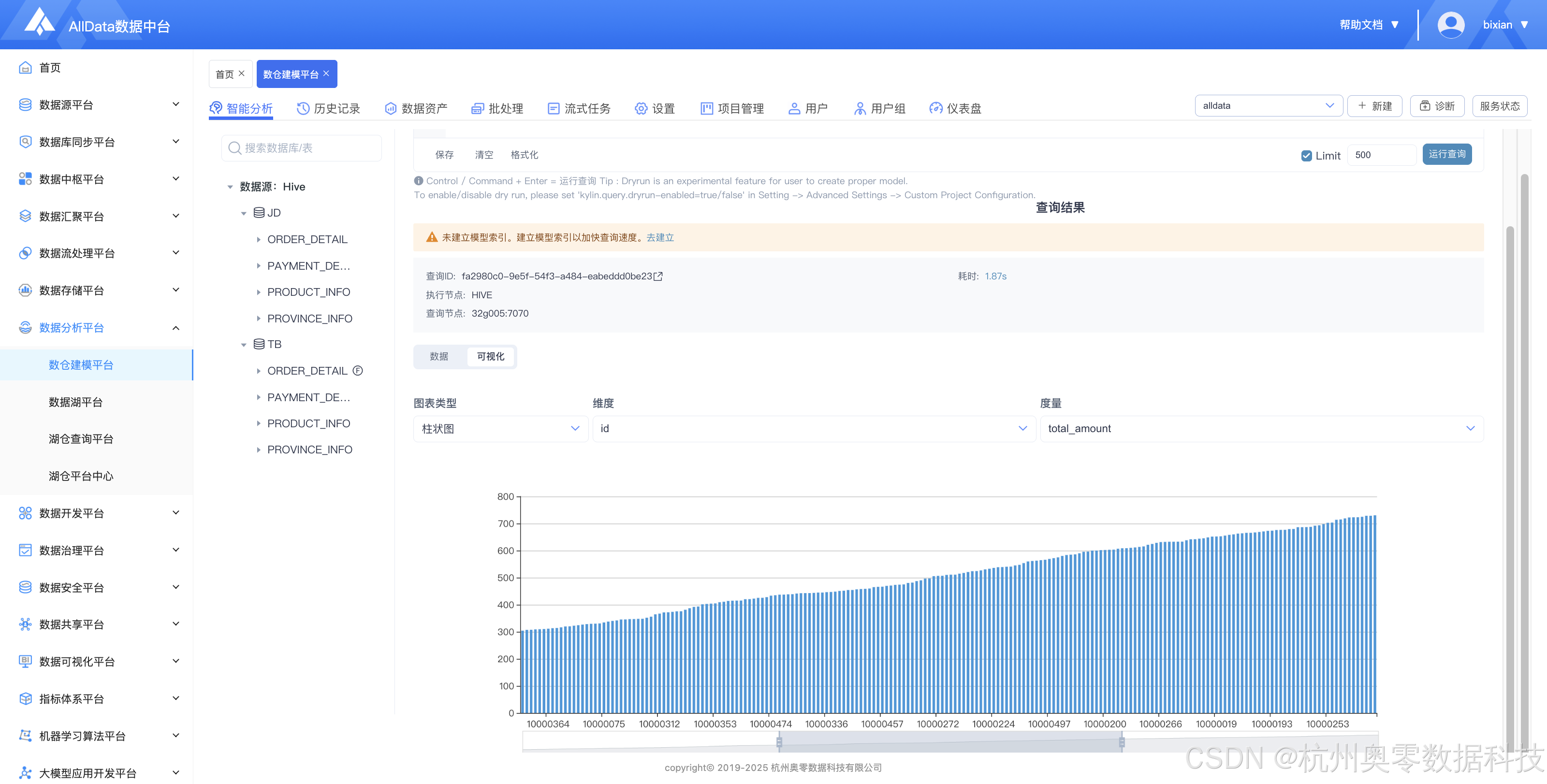
2、查询切换可视化图表查看
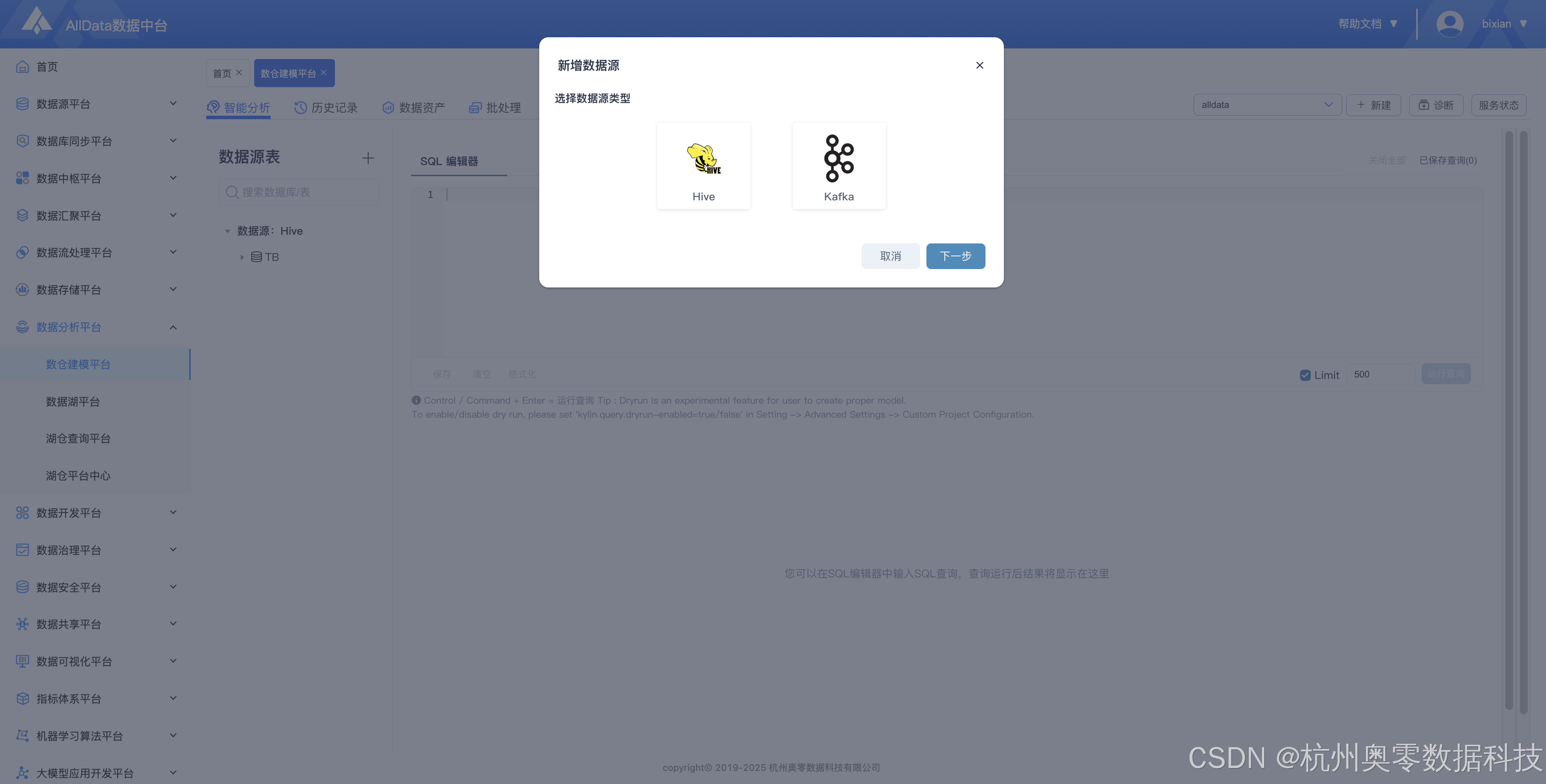
3、新建数据源 (智能分析模块支持便捷新增数据源,可快速接入数据源,拓展分析维度与数据覆盖范围。支持hive和kafka两种数据源)
4、新建项目 (支持一键新建项目,可自定义配置数据模型与指标,快速搭建个性化数据分析环境)
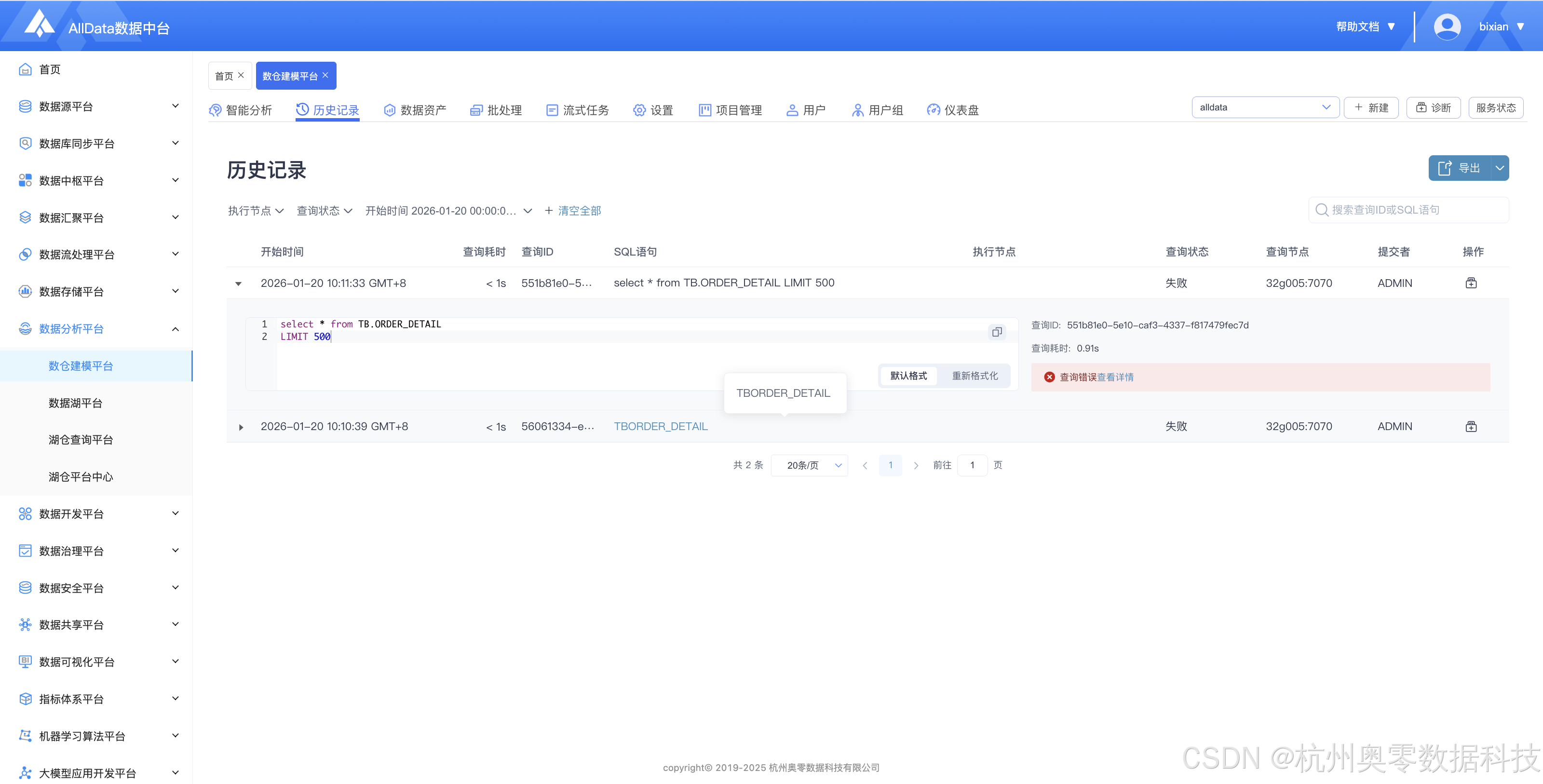
5、历史任务 (自动记录操作历史,支持按时间、类型筛选查看,便于追溯修改轨迹与审计复盘)
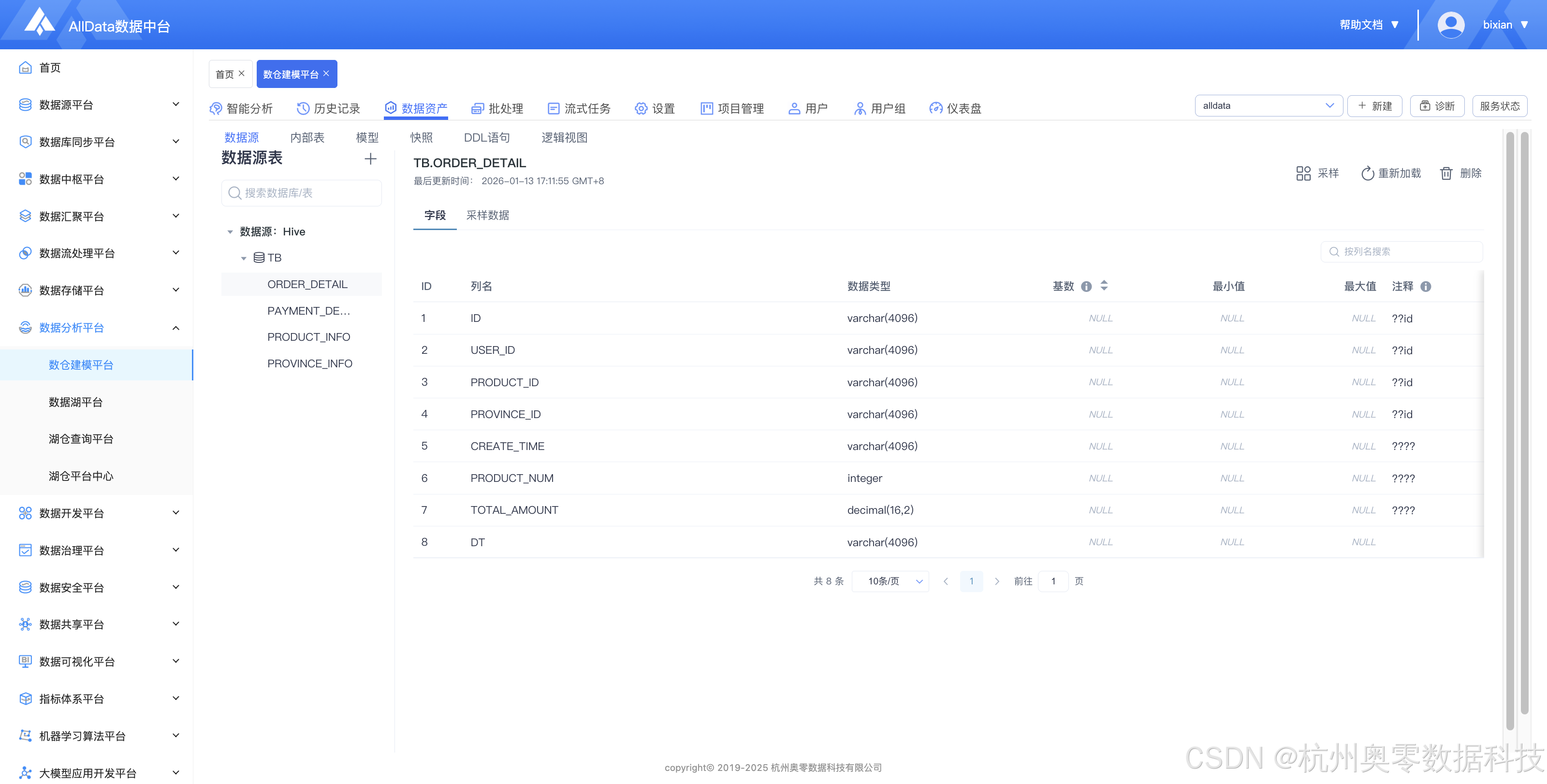
6、数据资产-数据源 (数据资产模块可集中管理数据源,支持多类型接入、元数据查看及权限灵活配置)
7、模型-新建模型 (可自定义维度指标,快速构建适配业务场景的数据分析模型)
8、快照-新建快照 (支持在数据资产快照模块新建快照,可定时刻录数据状态,保障数据安全与历史版本回溯)
9、DDL语句
10、逻辑视图
11、批处理 (数仓建模平台依托Kylin,支持大规模批处理,可高效处理海量数据,实现批量分析与计算任务)
12、流式任务 (支持实时流式任务处理,可高效捕获、分析动态数据流并即时响应)
13、设置-基础设置 (可配置系统参数、权限及数据连接,灵活适配多样化业务场景需求)
14、设置-高级设置 (支持Kylin引擎调优、资源分配定制及复杂计算规则配置,满足精细化管控需求)
15、设置-内部表设置 (可自定义表结构、索引及存储策略,优化Kylin底层数据组织与查询效率)
16、设置-模型设置 (支持定义维度、指标及聚合方式,灵活适配Kylin模型,优化数据分析性能)
17、项目管理 (支持多项目创建、权限分配与资源隔离,助力团队高效协作与数据资产管控)
18、用户 (提供用户管理功能,支持角色分配、权限细控,保障不同用户安全访问Kylin相关数据资源)
19、用户-新建用户
20、用户组 (支持用户组管理,可批量分配权限、资源,实现用户分类管控,提升Kylin数据操作协作效率)
21、用户组-新建用户组
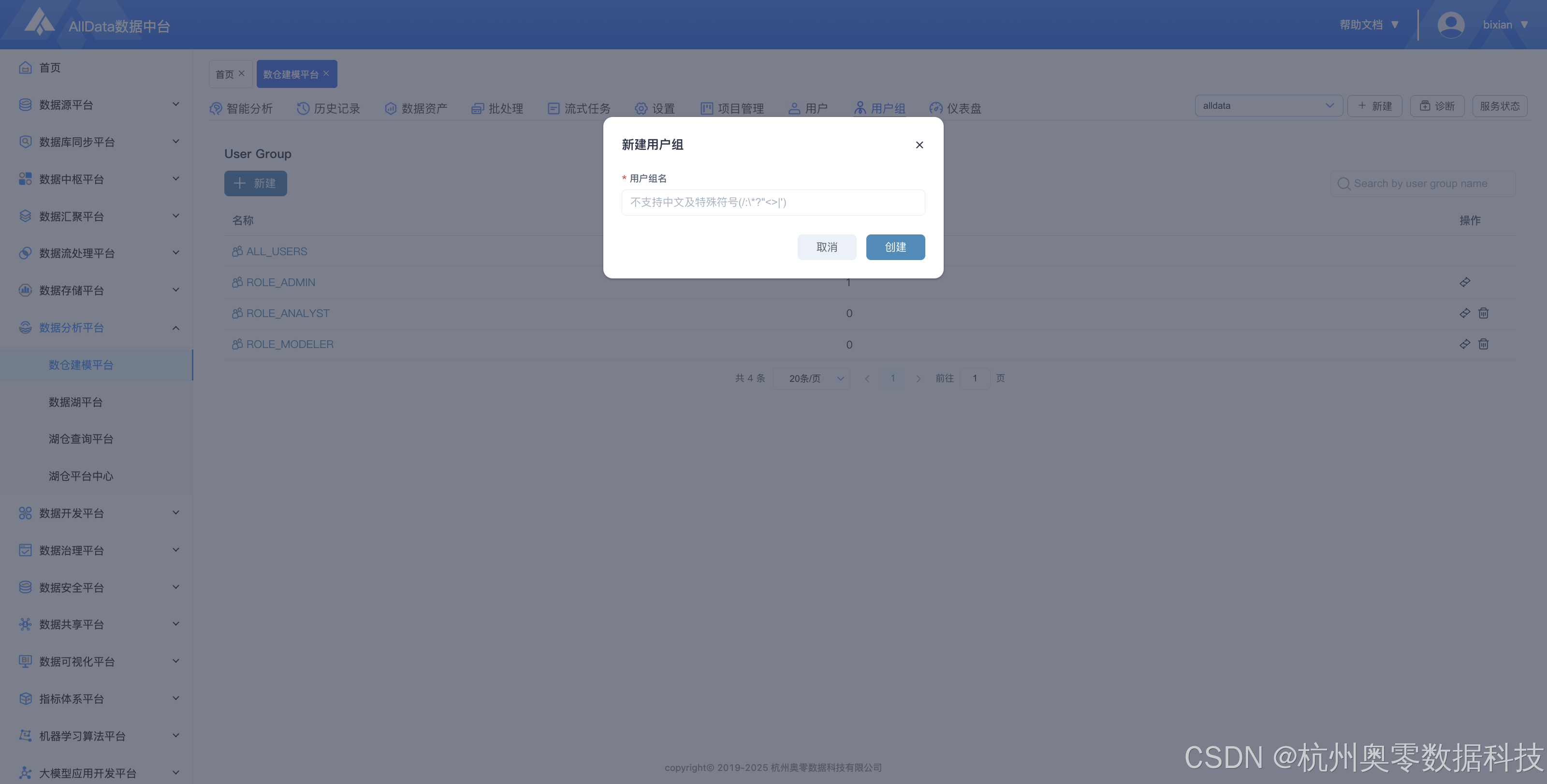
22、用户组详情查看
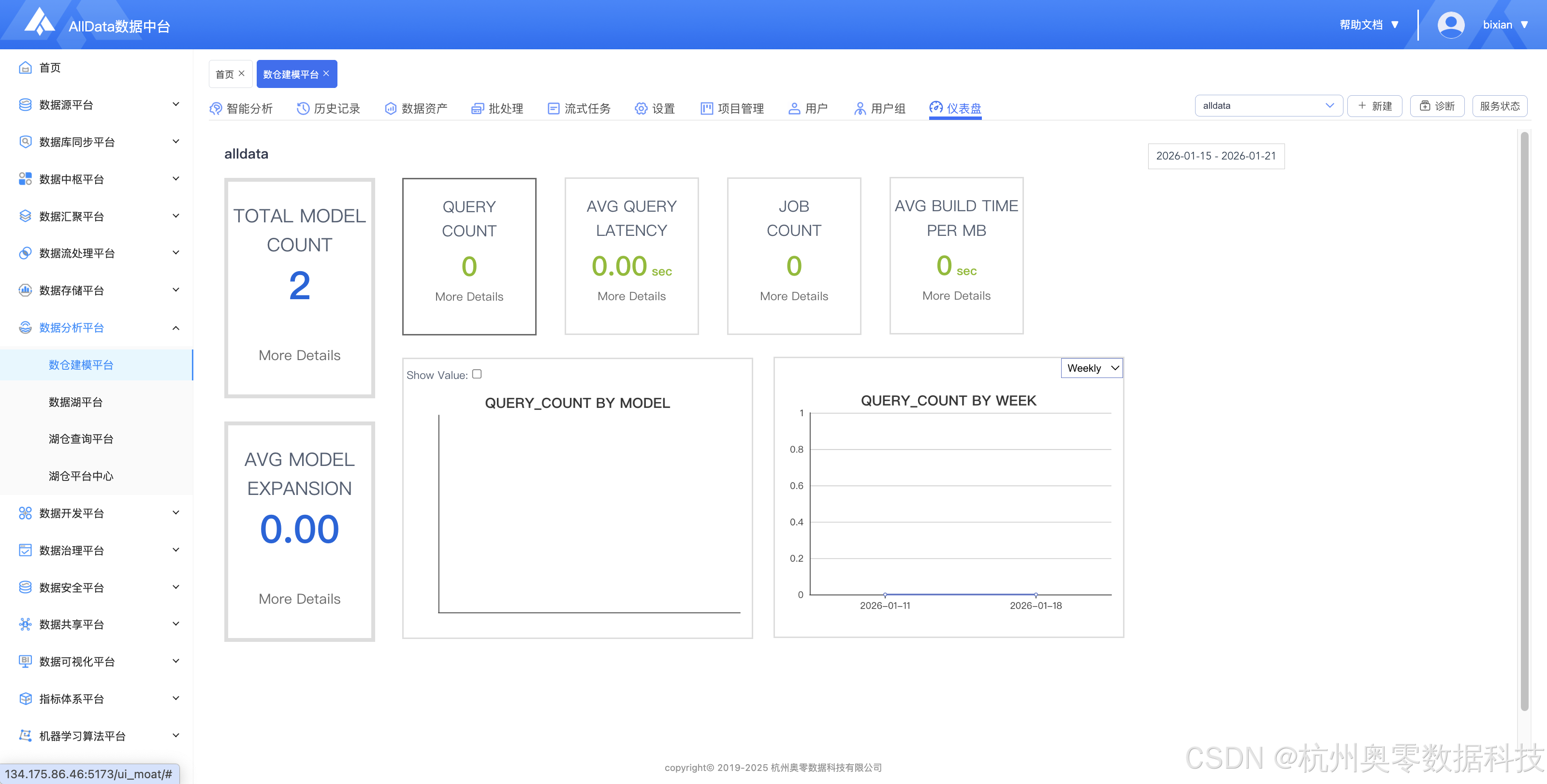
23、仪表盘
四、【实操演示】从零构建销售分析模型
下面我们通过4个核心步骤完成一个销售数据分析模型的搭建,需编码背景,您将学会如何将原始销售数据转化为可视化分析报表快速走通流程:

全过程,无需写代码、不用懂专业技术,通过 "接入数据源→建项目→搭模型→出报表" 四步,就能完成从数据到决策的全流程分析。平台内置的可视化操作、自动建模等功能,让非技术人员也能轻松玩转大数据分析,高效支撑工作决策。
作为非技术人员,以前总觉得 "大数据分析" 是技术岗的专属,直到用了数仓建模平台(Kylin)才发现,数据分析其实可以很简单。
就像一个 "翻译官",把复杂的大数据变成普通人能看懂、能使用的信息,不用依赖别人,自己就能快速拿到数据洞察。如果你也经常被数据分析困扰,真心推荐试试这个平台 ------ 亲测好用,省时又省心,让数据真正为你的工作赋能!
五、【相关资源】
AllData开源项目:https://github.com/alldatacenter/alldata
AllData官方手册:https://www.yuque.com/aolingdata/product
杭州奥零数据科技官网:http://www.aolingdata.com