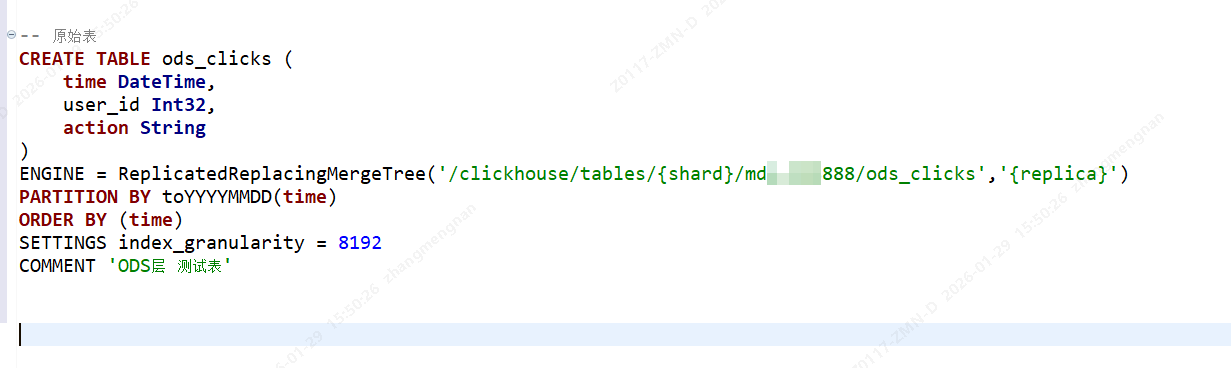
分片副本表结构
PARTITION BY toYYYYMM(time) 按日期分区,每月一个分区
排序键设计完整:覆盖了主要查询维度
ReplacingMergeTree 避免重复统计
- 核心组件比喻
节点(Node)
相当于一个仓库,可以存储货物(数据),并且能自己处理打包、查询任务。
比如你在全国有 10 个仓库,每个仓库就是一个节点。
分片(Shard) - 假设你的订单数据量太大,一个仓库放不下,于是你把数据按规则拆分。
- 例如:按客户所在省份分片,北京的数据放在分片1,上海的数据放在分片2。
- 每个分片可能由一个或多个仓库(节点)负责。
副本(Replica)
- 为了防止某个仓库着火或宕机导致数据丢失,你在另一个地方建立备份仓库,存一模一样的数据。
- 比如北京分片的数据,除了仓库A存一份,还在仓库B存一份完全相同的。
- A 是主副本,B 是副本,它们互为副本。
ClickHouse 就是: - 把大数据分片存储(并行处理查询更快)
- 每个分片有副本(高可用、可负载均衡)
- 所有节点组成一个集群,对外像一个整体数据库。
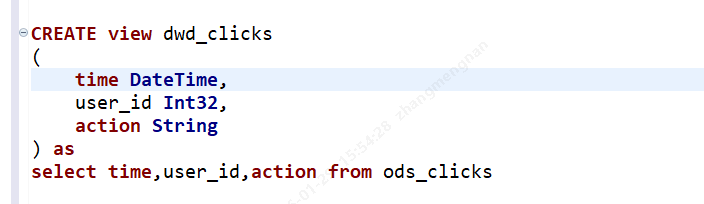
视图
引用 clicks 的数据
SETTINGS index_granularity = 8192 详解
8192 = 2¹³ 每个颗粒大小 ≈ 8192行 × 平均行大小
什么是 Granularity(粒度)? - 在 ClickHouse 中,数据在磁盘上按颗粒(granule)存储
- 每个颗粒是物理上连续存储的一组行
- index_granularity = 8192 表示:每个索引颗粒包含 8192 行数据
