在实际生产生活中,为了保证模型的训练正确率足够大,其中一个重要条件就是拥有足够的数据集,但当数据集过大,或者模型在实际生活中部署时,我们不可能花费大量的时间去现场训练模型,此时我们便需要保存模型并且在之后调用它
模型的保存:
python
import os
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
from torchvision import datasets, transforms, models
from torchvision.models import resnet18, ResNet18_Weights
import matplotlib.pyplot as plt
from PIL import Image
import warnings
warnings.filterwarnings('ignore')
# ====================== 1. 配置参数(可根据需求修改) ======================
DATA_ROOT = r"E:\pycharm\Py_Projects\food_dataset2\food_dataset2"
BATCH_SIZE = 32
EPOCHS = 20
LEARNING_RATE = 0.001
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
IMG_SIZE = (224, 224)
MODEL_SAVE_PATH = "food_classification_model.pth"
# ====================== 2. 数据预处理与加载 ======================
train_transforms = transforms.Compose([
transforms.Resize(IMG_SIZE),
transforms.RandomHorizontalFlip(p=0.5),
transforms.RandomRotation(10),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
test_transforms = transforms.Compose([
transforms.Resize(IMG_SIZE),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
# 修复后的自定义数据集类(遵循ImageFolder接口规范)
class FoodDataset(datasets.ImageFolder):
# 仅返回classes和class_to_idx(符合父类要求)
def find_classes(self, directory):
classes = []
# 遍历文件夹提取纯食物名称
for root, dirs, files in os.walk(directory, topdown=False):
for dir_name in dirs:
food_name = dir_name.split("_")[-1]
if food_name not in classes:
classes.append(food_name)
# 排序保证标签稳定
classes.sort()
class_to_idx = {cls_name: i for i, cls_name in enumerate(classes)}
return classes, class_to_idx
# 重写make_dataset方法,自定义样本路径和标签映射
def make_dataset(self, directory, class_to_idx, extensions=None, is_valid_file=None):
samples = []
directory = os.path.expanduser(directory)
# 支持的图片格式
valid_extensions = ('.png', '.jpg', '.jpeg') if extensions is None else extensions
for root, dirs, files in os.walk(directory):
for file in files:
# 过滤有效图片文件
if file.lower().endswith(valid_extensions):
# 提取食物名称作为标签
dir_name = os.path.basename(root)
food_name = dir_name.split("_")[-1]
if food_name in class_to_idx:
path = os.path.join(root, file)
item = (path, class_to_idx[food_name])
samples.append(item)
return samples
# 加载训练集和测试集
print("【阶段1:加载数据集】开始解析数据集...")
train_dataset = FoodDataset(root=os.path.join(DATA_ROOT, "train"), transform=train_transforms)
test_dataset = FoodDataset(root=os.path.join(DATA_ROOT, "test"), transform=test_transforms)
# 创建数据加载器
train_loader = DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True, num_workers=0)
test_loader = DataLoader(test_dataset, batch_size=BATCH_SIZE, shuffle=False, num_workers=0)
# 输出数据集信息
num_classes = len(train_dataset.classes)
print(f"✅ 数据集加载完成!")
print(f" - 训练集样本数:{len(train_dataset)}")
print(f" - 测试集样本数:{len(test_dataset)}")
print(f" - 食物类别数:{num_classes}")
print(f" - 类别列表:{train_dataset.classes}")
print(f" - 使用设备:{DEVICE}")
# ====================== 后续代码(3-8阶段)完全不变 ======================
# 3. 构建CNN模型
print("\n【阶段2:构建模型】初始化ResNet18模型...")
model = resnet18(weights=ResNet18_Weights.IMAGENET1K_V1)
model.fc = nn.Linear(model.fc.in_features, num_classes)
model = model.to(DEVICE)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=LEARNING_RATE)
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=5, gamma=0.8)
# 4. 训练与验证函数
def train_one_epoch(model, loader, criterion, optimizer, epoch):
model.train()
total_loss = 0.0
correct = 0
total = 0
for batch_idx, (images, labels) in enumerate(loader):
images, labels = images.to(DEVICE), labels.to(DEVICE)
outputs = model(images)
loss = criterion(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item()
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
if batch_idx % 10 == 0:
batch_acc = 100 * correct / total
batch_loss = total_loss / (batch_idx + 1)
print(
f" 训练轮次[{epoch + 1}/{EPOCHS}] | 批次[{batch_idx}/{len(loader)}] | 批次损失:{batch_loss:.4f} | 批次准确率:{batch_acc:.2f}%")
epoch_loss = total_loss / len(loader)
epoch_acc = 100 * correct / total
return epoch_loss, epoch_acc
def validate(model, loader, criterion):
model.eval()
total_loss = 0.0
correct = 0
total = 0
with torch.no_grad():
for images, labels in loader:
images, labels = images.to(DEVICE), labels.to(DEVICE)
outputs = model(images)
loss = criterion(outputs, labels)
total_loss += loss.item()
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
val_loss = total_loss / len(loader)
val_acc = 100 * correct / total
return val_loss, val_acc
# 5. 开始训练
print("\n【阶段3:开始训练】")
train_loss_history = []
train_acc_history = []
val_loss_history = []
val_acc_history = []
best_val_acc = 0.0
for epoch in range(EPOCHS):
train_loss, train_acc = train_one_epoch(model, train_loader, criterion, optimizer, epoch)
val_loss, val_acc = validate(model, test_loader, criterion)
scheduler.step()
train_loss_history.append(train_loss)
train_acc_history.append(train_acc)
val_loss_history.append(val_loss)
val_acc_history.append(val_acc)
print(f"\n✅ 训练轮次[{epoch + 1}/{EPOCHS}] 完成!")
print(f" - 训练损失:{train_loss:.4f} | 训练准确率:{train_acc:.2f}%")
print(f" - 验证损失:{val_loss:.4f} | 验证准确率:{val_acc:.2f}%")
print(f" - 当前学习率:{scheduler.get_last_lr()[0]:.6f}")
if val_acc > best_val_acc:
best_val_acc = val_acc
torch.save({
'epoch': epoch,
'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'best_val_acc': best_val_acc,
'class_to_idx': train_dataset.class_to_idx,
'classes': train_dataset.classes
}, MODEL_SAVE_PATH)
print(f" 🎉 最优模型已保存!当前最高验证准确率:{best_val_acc:.2f}%")
print("-" * 80)
# 6. 可视化结果
print("\n【阶段4:训练完成】开始可视化训练结果...")
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(train_loss_history, label='训练损失', color='blue')
plt.plot(val_loss_history, label='验证损失', color='red')
plt.title('训练/验证损失变化')
plt.xlabel('轮次')
plt.ylabel('损失值')
plt.legend()
plt.grid(True)
plt.subplot(1, 2, 2)
plt.plot(train_acc_history, label='训练准确率', color='blue')
plt.plot(val_acc_history, label='验证准确率', color='red')
plt.title('训练/验证准确率变化')
plt.xlabel('轮次')
plt.ylabel('准确率(%)')
plt.legend()
plt.grid(True)
plt.tight_layout()
plt.savefig("training_result.png")
plt.show()
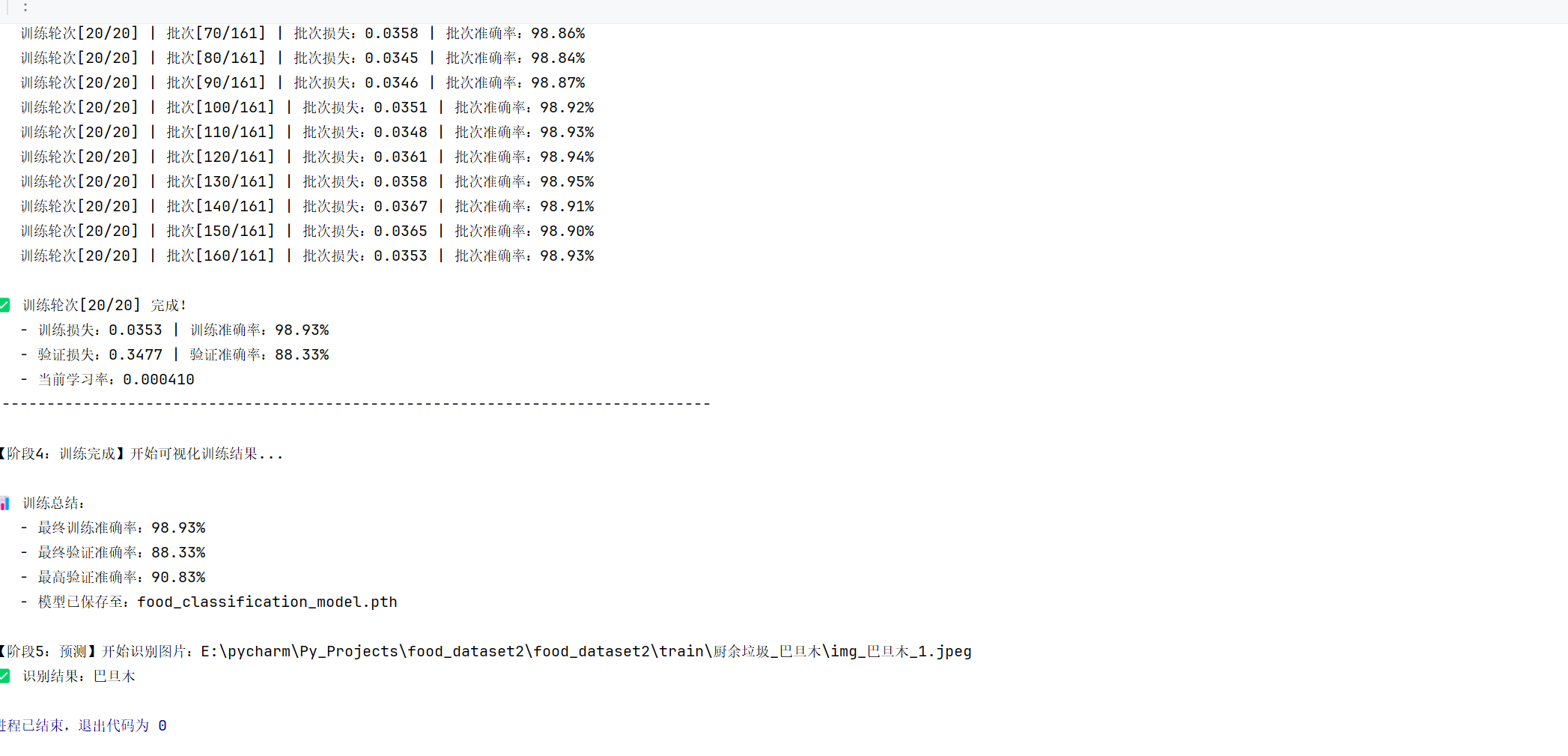
print(f"\n📊 训练总结:")
print(f" - 最终训练准确率:{train_acc:.2f}%")
print(f" - 最终验证准确率:{val_acc:.2f}%")
print(f" - 最高验证准确率:{best_val_acc:.2f}%")
print(f" - 模型已保存至:{MODEL_SAVE_PATH}")
# 7. 预测函数
def predict_food(image_path, model_path=MODEL_SAVE_PATH):
print(f"\n【阶段5:预测】开始识别图片:{image_path}")
checkpoint = torch.load(model_path, map_location=DEVICE)
model.load_state_dict(checkpoint['model_state_dict'])
classes = checkpoint['classes']
model.eval()
try:
image = Image.open(image_path).convert('RGB')
transform = test_transforms
image = transform(image).unsqueeze(0)
image = image.to(DEVICE)
with torch.no_grad():
outputs = model(image)
_, predicted_idx = torch.max(outputs, 1)
predicted_class = classes[predicted_idx.item()]
print(f"✅ 识别结果:{predicted_class}")
return predicted_class
except Exception as e:
print(f"❌ 预测失败!错误信息:{e}")
return None
# 8. 测试预测功能
if __name__ == "__main__":
test_image_path = r"E:\pycharm\Py_Projects\food_dataset2\food_dataset2\train\厨余垃圾_巴旦木\img_巴旦木_1.jpeg"
predict_food(test_image_path)运行结果(20轮):
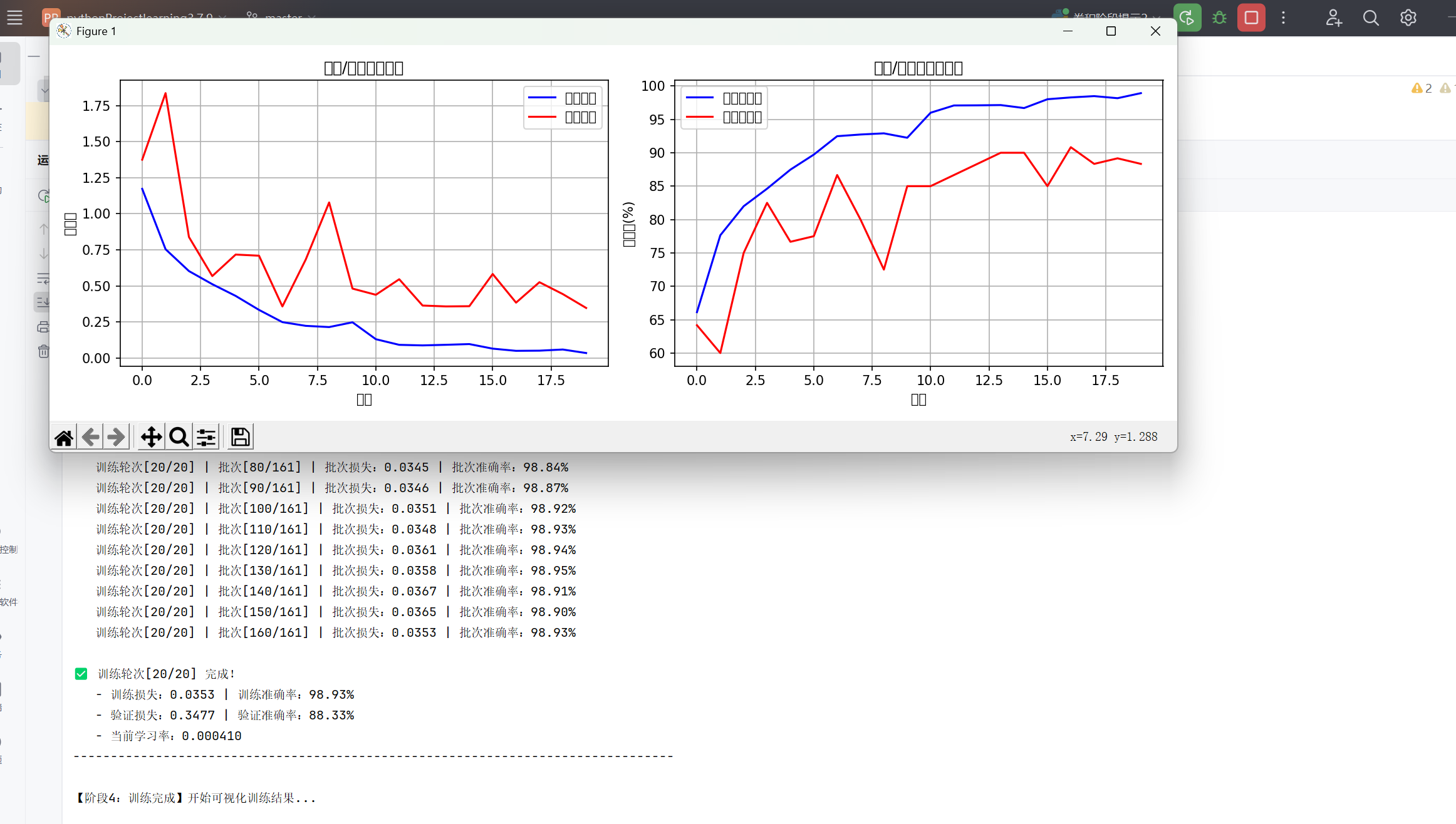
如图所示,准确率很可观:
首先,在配置参数时定义保存模型的名称:
python
MODEL_SAVE_PATH = "food_classification_model.pth"在训练与验证函数时:
python
for epoch in range(EPOCHS):
train_loss, train_acc = train_one_epoch(model, train_loader, criterion, optimizer, epoch)
val_loss, val_acc = validate(model, test_loader, criterion)
scheduler.step()
train_loss_history.append(train_loss)
train_acc_history.append(train_acc)
val_loss_history.append(val_loss)
val_acc_history.append(val_acc)
print(f"\n✅ 训练轮次[{epoch + 1}/{EPOCHS}] 完成!")
print(f" - 训练损失:{train_loss:.4f} | 训练准确率:{train_acc:.2f}%")
print(f" - 验证损失:{val_loss:.4f} | 验证准确率:{val_acc:.2f}%")
print(f" - 当前学习率:{scheduler.get_last_lr()[0]:.6f}")
if val_acc > best_val_acc:
best_val_acc = val_acc
torch.save({
'epoch': epoch,
'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'best_val_acc': best_val_acc,
'class_to_idx': train_dataset.class_to_idx,
'classes': train_dataset.classes
}, MODEL_SAVE_PATH)
print(f" 🎉 最优模型已保存!当前最高验证准确率:{best_val_acc:.2f}%")
print("-" * 80)在
python
if val_acc > best_val_acc:
best_val_acc = val_acc中,如果当前训练验证准确率由于历史最好验证准确率,则用新的模型将其替代。
接下来运行
torch.save({内容},路径/名称)
来保存模型文件。
模型文件字典的内容:
字典中每个键值对都有明确作用,缺一不可:
| 键名 | 含义 & 作用 |
|---|---|
epoch |
保存最优模型时的训练轮次(便于后续复现 / 继续训练,知道模型在第几轮达到最优) |
model_state_dict |
模型的权重参数(模型的核心,决定模型预测能力,model.state_dict()返回所有可学习参数) |
optimizer_state_dict |
优化器的状态参数(如果后续要继续训练,需要恢复优化器的学习率、动量等状态) |
best_val_acc |
该模型对应的最高验证准确率(便于后续查看模型效果,无需重新计算) |
class_to_idx |
类别名称到标签索引的映射(如{"巴旦木":0, "苹果":1},保证预测时标签对应正确) |
classes |
完整的类别列表(如["巴旦木", "苹果", "香蕉"],预测时通过索引反查类别名称) |
随着for循环的反复遍历,比如我训练时使其训练了二十轮,if就会进行反复对比,由于文件名相同,每次运行完后新的pth文件就会替代老的文件,知道best_val_acc得出20次训练后的最优结果。
然后再预测函数中会调用model_state_dict和classes
torch.load():读取.pth文件,恢复保存的字典;model.load_state_dict():将保存的权重加载到模型中,让模型具备预测能力;classes:从保存的字典中恢复类别列表,保证预测时能输出正确的类别名称(而非数字索引)
python
# 7. 预测函数
def predict_food(image_path, model_path=MODEL_SAVE_PATH):
print(f"\n【阶段5:预测】开始识别图片:{image_path}")
checkpoint = torch.load(model_path, map_location=DEVICE)
model.load_state_dict(checkpoint['model_state_dict'])
classes = checkpoint['classes']
model.eval()
try:
image = Image.open(image_path).convert('RGB')
transform = test_transforms
image = transform(image).unsqueeze(0)
image = image.to(DEVICE)
with torch.no_grad():
outputs = model(image)
_, predicted_idx = torch.max(outputs, 1)
predicted_class = classes[predicted_idx.item()]
print(f"✅ 识别结果:{predicted_class}")
return predicted_class
except Exception as e:
print(f"❌ 预测失败!错误信息:{e}")
return None模型的引用
在相同分类(20)的另一个小模型内
python
# ====================== 2. 加载新数据集并验证分类数 ======================
# 修改数据预处理,添加数据增强
transform = transforms.Compose([
transforms.Resize((36, 36)), # 先放大,再随机裁剪
transforms.RandomCrop((32, 32)), # 随机裁剪到训练尺寸
transforms.RandomHorizontalFlip(p=0.5), # 随机水平翻转
transforms.ColorJitter(brightness=0.2, contrast=0.2), # 随机调整亮度/对比度
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
# 新数据集路径
new_data_root = r"E:\pycharm\Py_Projects\pythonProjectlearning3.7.9\.venv\food_dataset"
train_dataset = datasets.ImageFolder(root=new_data_root + "/train", transform=transform)
# 打印数据集核心信息
print("=" * 50)
print("新数据集验证信息:")
print(f"实际分类数:{len(train_dataset.classes)}")
print(f"类别名称 & 标签索引:{train_dataset.class_to_idx}")
class_names = train_dataset.classes # 保存类别名称,用于后续预测标注
print("=" * 50)
# 自动匹配分类数
new_num_classes = len(train_dataset.classes)
train_loader = DataLoader(train_dataset, batch_size=20, shuffle=True)
# ====================== 3. 加载原模型并适配新分类数 ======================
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = SimpleCNN(num_classes=new_num_classes).to(DEVICE)
# 加载原模型权重
checkpoint = torch.load("food_classification_model.pth", map_location=DEVICE)
model_dict = model.state_dict()
pretrained_dict = checkpoint['model_state_dict']
# 优化权重过滤逻辑
pretrained_dict_filtered = {}
for k, v in pretrained_dict.items():
if k in model_dict and model_dict[k].shape == v.shape:
pretrained_dict_filtered[k] = v
else:
print(
f"跳过不匹配的层:{k}(原模型形状:{v.shape},新模型形状:{model_dict[k].shape if k in model_dict else '不存在'})")
model_dict.update(pretrained_dict_filtered)
model.load_state_dict(model_dict, strict=False)先加载数据集,然后调用之前训练好的模型的权重。