第一次"建库成功",通常是向量数据库最危险的时刻
几乎所有第一次用向量数据库的团队,都会经历一个非常相似的阶段。
那一天,你终于看到:
- embedding 正常生成
- 向量成功写入
- search 接口返回结果
- demo 能跑通
然后你会下意识地松一口气:
"向量数据库这块,应该算是解决了。"
但如果你回头去看真实工程事故,会发现一个残酷事实:
向量数据库的第一次翻车,几乎从来不是发生在"建库失败",
而是发生在"你以为已经没问题了"的那一刻。
真正的坑,往往在后面。
一个先说清楚的前提:向量数据库实战,不等于"把数据存进去"
很多教程,会把向量数据库实战讲成三步:
- 文档 → embedding
- embedding → 向量库
- query → search
但在真实系统里,这三步只解决了一件事:
"系统具备了做相似性检索的可能性。"
而不是:
"系统已经能稳定给出有用结果。"
向量数据库真正的难点,从来不是"能不能查到",
而是:查到的东西能不能被模型用来做正确决策。
第一阶段:选型与建库------一切看起来都很顺利
我们先从"还没翻车之前"说起。
大多数项目在建库阶段,会经历下面这些决策:
- 选一个向量数据库(本地 / 云 / 开源)
- 选一个 embedding 模型
- 确定 chunk 大小
- 把现有文档一次性全量入库
这一阶段的共同特征是:
- 数据量相对可控
- 文档比较"干净"
- 使用者都是内部同事
所以你会看到非常好的效果:
- 搜索结果看起来"都挺相关"
- 模型回答大多数问题都还说得过去
于是团队会形成一个隐含共识:
"向量数据库这块,算是 OK 了。"
第一次隐患:你在建库时,其实已经"赌"了很多前提
虽然你当时未必意识到,但在建库阶段,你其实已经默认了很多假设。
比如:
- 所有文档的重要性是相似的
- 所有 chunk 都是"等价证据"
- embedding 能正确表达业务语义
- TopK=3 或 TopK=5 足够
在 demo 阶段,这些假设往往不会出问题。
但它们会在真实用户进来之后,被逐个击穿。
第二阶段:数据规模上来,一切开始变"玄学"
向量数据库第一次翻车,最常见的触发条件只有一个:
数据规模和数据类型发生变化。
比如:
- 文档从几十篇,变成几千篇
- 文档类型从"说明文档",变成"制度 + FAQ + 工单记录"
- 新文档开始不断追加,而不是一次性入库
这时,你会开始发现一些非常熟悉的症状。
翻车症状一:TopK 明明命中了,但结果"用不上"
这是最经典的。
你去看检索结果,会发现:
- embedding 相似度很高
- 关键词也对
- 看起来"挺相关"
但你仔细读,会发现:
- 只有背景,没有结论
- 只有规则,没有适用条件
- 只有步骤的一半
模型拿到这样的 chunk,只能开始"脑补"。
这时,很多团队会第一反应是:
"是不是模型不行?"
但实际上,这往往是切分 + 召回策略的问题。
翻车症状二:同一个问题,有时答得好,有时答得很怪
这是第二个常见翻车点。
你会发现:
- 同一个问题
- 不同时间问
- 或者稍微换个说法
模型的回答差异非常大。
排查后你会发现:
- TopK 里的候选块经常在变
- 不同 chunk 被送进模型
- 模型只能基于"当次上下文"发挥
这意味着:
系统已经进入了"轻微抖动就换证据"的状态。
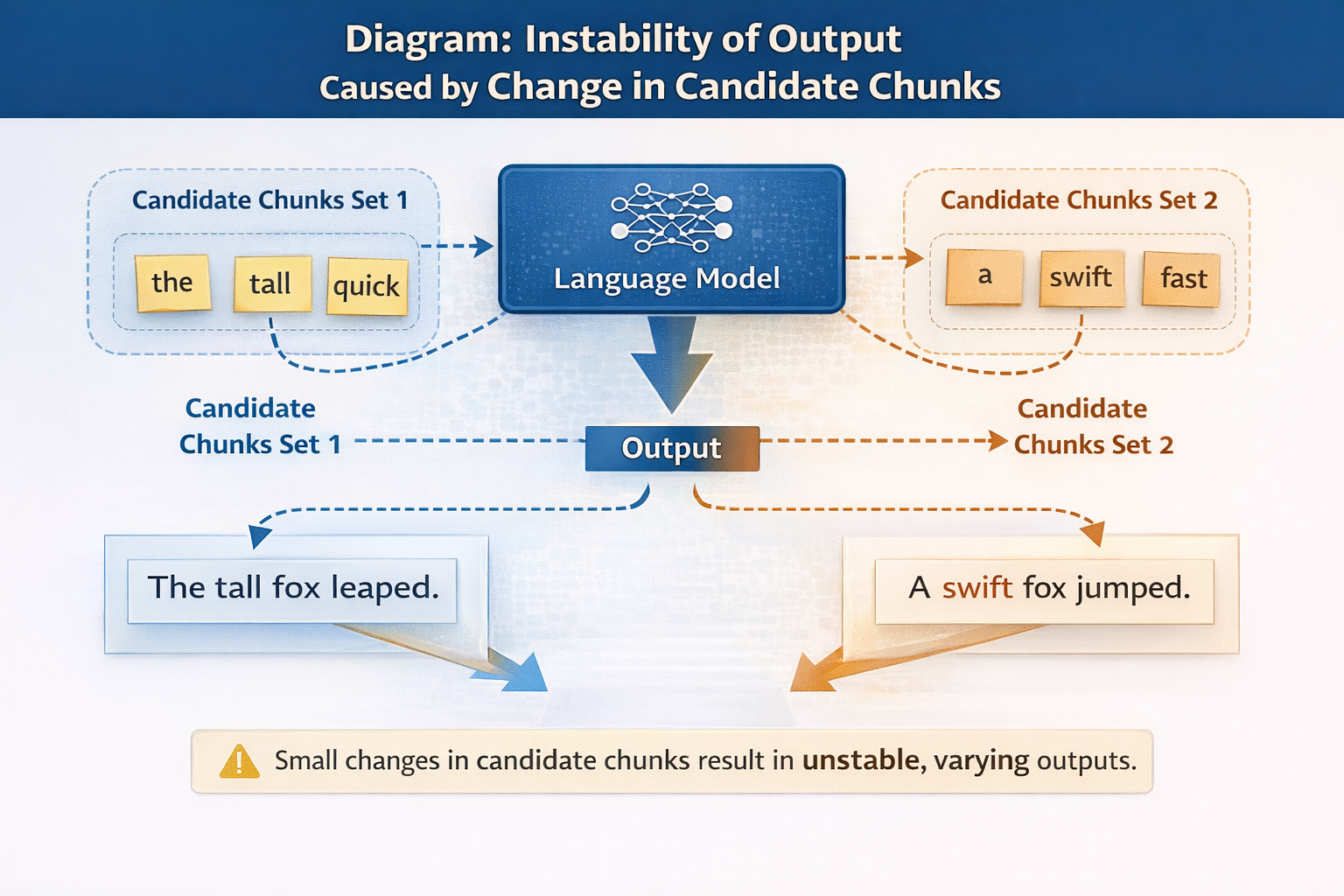
候选 chunk 变化导致输出不稳定示意图
翻车症状三:你开始不断调大 TopK
这是一个非常危险、但非常常见的"自救动作"。
当你发现:
- Top3 不稳定
- Top5 有时不够
你会很自然地做一件事:
"那我 Top10、Top20 吧,总能把正确的放进去。"
短期内,这确实能缓解问题。
但你很快会遇到新的麻烦:
- 上下文变长
- 噪声更多
- 模型开始抓错重点
你会发现:
TopK 不是"越大越保险",而是"越大越考验后处理能力"。
一个被严重低估的问题:向量数据库并不理解"重要性"
这是很多第一次翻车的根因。
向量数据库只理解一件事:
"相似度"
它并不知道:
- 哪个 chunk 更权威
- 哪个 chunk 是例外说明
- 哪个 chunk 只是背景介绍
如果你在建库时,把所有 chunk 当成"等价知识",
那在真实检索中,它们就会被等价对待。
这在小规模时不明显,但在规模上来后,非常致命。
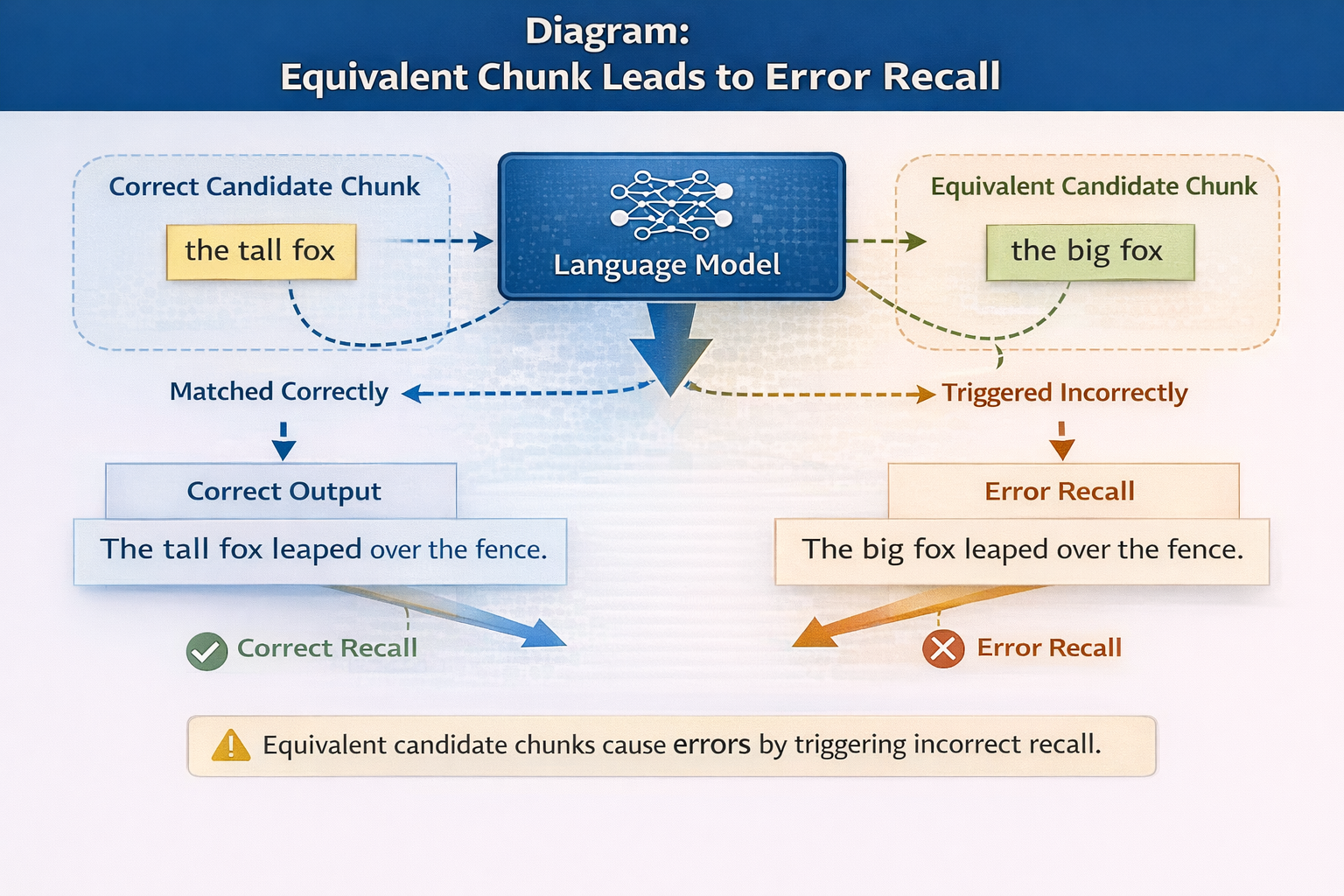
等价 chunk 导致错误召回示意图
第一次翻车,往往发生在"边界问题"上
一个非常真实的现象是:
- 常规问题,一直都答得不错
- 真正翻车的,往往是边界问题
比如:
- "这种情况算不算例外?"
- "在 XX 条件下还能不能用?"
这些问题,通常依赖:
- 多个条件
- 例外条款
- 注意事项
而这些信息,最容易在切分或召回中被拆散。
模型不是不知道规则,而是没拿到完整证据。
工程复盘:第一次翻车后,你应该优先做的不是"换数据库"
这是一个很重要的认知纠偏。
第一次翻车后,很多团队会考虑:
- 换 embedding
- 换向量数据库
- 加 rerank
- 改 prompt
但真正应该优先做的,是三件事:
- 把真实问题对应的 TopK chunk 全部拉出来
- 人工判断:哪些 chunk 是"可用证据"
- 统计:不可用 chunk 的比例与类型
你会惊讶地发现,问题往往集中在:
- 切分不当
- chunk 信息不完整
- 文档结构被破坏
翻车问题排查路径图
一个非常实用的排查方式:把"向量库"当成黑盒,先只看输出
在第一次翻车时,我非常不建议你马上动系统结构。
更有效的方式是:
- 固定 embedding
- 固定模型
- 固定 prompt
- 只分析"向量检索给了模型什么"
很多问题,在这一层就已经暴露了。
一个简化但非常真实的检索示意代码
python
results = vector_db.search(query, top_k=5)
for r in results:
print("score:", r.score)
print("content:", r.text)
print("-" * 20)如果你把这段结果完整看完,
还觉得"这些 chunk 本身就能支撑答案",
那才值得继续往下排查模型。
翻车之后,向量数据库实战才真正开始
很多团队在第一次翻车后,会产生两种极端反应:
- 要么否定向量数据库
- 要么开始无限加复杂度
但更成熟的做法,往往是:
- 承认:之前低估了工程复杂度
- 接受:向量数据库是长期系统
- 开始系统性地"治理检索质量"
这一步,才是真正的"实战"。
向量数据库实战的几个现实真相(翻车后你一定会懂)
我这里直接说结论型经验:
- 向量数据库不是一次性工程
- embedding 的选择会长期影响系统
- chunk 质量比数据库性能更重要
- rerank 不是锦上添花,而是止损
- 很多问题,本质上不是"检索",而是"知识组织"
在第一次翻车之后,很多团队需要反复对比不同切分、不同 embedding、不同 TopK 策略在同一批问题上的表现。这个阶段如果全靠本地脚本手动切换,很容易陷入"改了很多,但不知道哪一步真的起作用"的状态。用LLaMA-Factory online这类工具先快速搭建可对照的 RAG + 向量检索实验环境,会更容易把问题定位在"切分、召回还是生成",也更容易止损。
总结:向量数据库的第一次翻车,其实是一次必要的"认知校正"
如果要给这篇文章一个真正的总结,我会这样说:
向量数据库不是"装上就能用"的组件,
而是一个会随着数据规模和业务变化,不断暴露问题的系统。
第一次翻车,并不是失败,
而是你终于看清了:
- 你真正依赖的不是数据库
- 而是你对知识的组织方式
当你开始用"工程系统"的眼光,而不是"工具使用者"的眼光看向量数据库时,
它才会慢慢变成资产,而不是负担。