就在刚刚,DeepSeek 发布了 OCR 2。
依然是熟悉的味道------开源、硬核、直奔 SOTA。

项目地址:https://github.com/deepseek-ai/DeepSeek-OCR-2
模型地址:
https://huggingface.co/deepseek-ai/DeepSeek-OCR-2
论文地址:https://github.com/deepseek-ai/DeepSeek-OCR-2/blob/main/DeepSeek_OCR2_paper.pdf
如果说第一代 DeepSeek-OCR 像一个高效的文件扫描仪,能把图像压缩得极小,还原得尽可能准。
那第二代 OCR2,做了一件更「人」的事:像人眼一样有选择、有顺序地看图。
看完一块再决定看哪一块,甚至能判断哪个先看、哪个后看。
这种能力,过去只有人类才有。现在,DeepSeek 让 AI 模型也有了这种「阅读顺序感」。
而它之所以能做到这件事,核心秘密在于一个大胆的结构性改变:
它把原本由视觉模型(比如 CLIP)承担的视觉理解部分,替换成了一个语言模型架构。对,你没看错,OCR2 把"看图"这件事,从"用眼看"变成了"用语言理解"。
直观来看图,区别就很明显了:
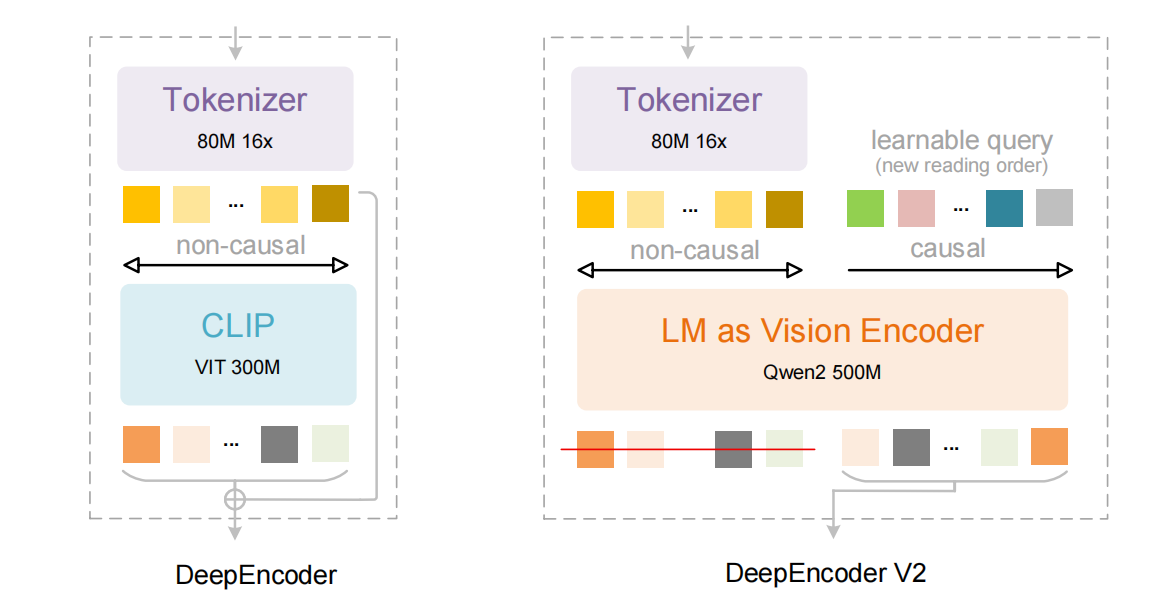
左图为 OCR1 的架构,右图为 OCR2 的架构
为什么要这么干?
因为过去的视觉模型在处理图片时,看图顺序是死的。
比如一张 1024×1024 的图像,会被切成 4096 个 16×16 的 patch,然后按顺序喂给 Transformer 。从左到右、从上到下、无差别硬扫。不管是标题还是表格,不管你想先看哪个,它都一视同仁。
就好比让你读一张报纸,却要求你从第一行像素一直读到最后一行像素,中间无论是标题、广告还是脚注,统统平等对待。
这不傻吗?
OCR2 要解决的,就是这种「机械顺序」的问题。
所以它干脆把视觉处理模块也改造成了一个语言模型,引入了「因果流查询(Causal Flow Query)」机制,让模型拥有"选择顺序"的能力。
整体流程是这样的:
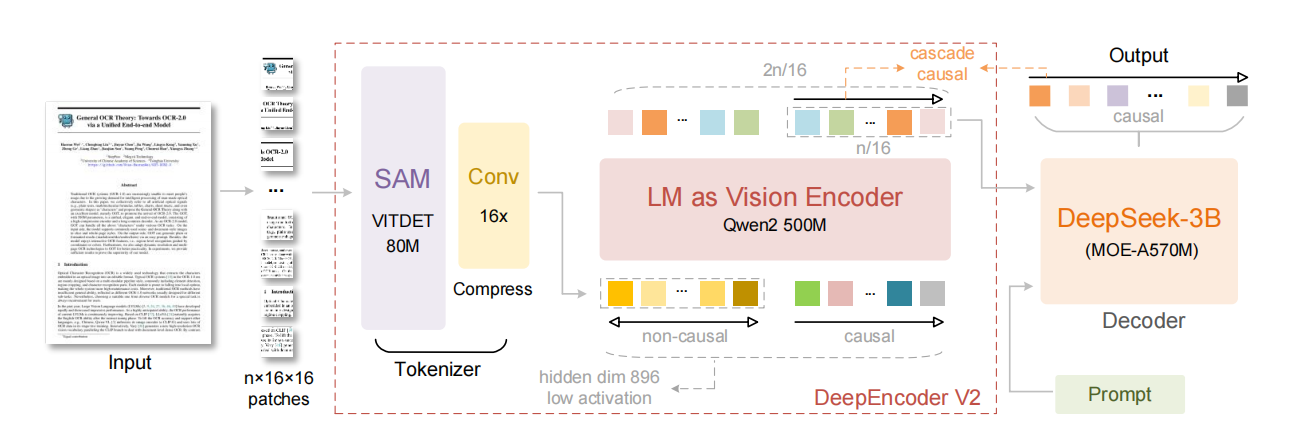
OCR2 首先把图像切成 patch,接着用 ViTDet 做初步感知,然后有一整套专门为大模型设计的 Token 压缩流程,把几千个视觉 token,压缩成几百个核心信息。
这一点非常关键。
一张分辨率正常的图(1280×1280),一拆就是 6400 个小块(16×16 patch),对模型来说简直是灾难性的计算负担。
而 OCR2 的解决方案是:动态 Token 压缩。
-
用 ViTDet 编码整张图,提取出完整的视觉 token map;
-
加入一个 Token Merging 模块,通过 CNN + Channel Mixer,把 token 数压缩到原来的 1/16;
-
加上 Positional Embedding 和 LayerNorm,形成紧凑、保留关键信息的 token 序列。
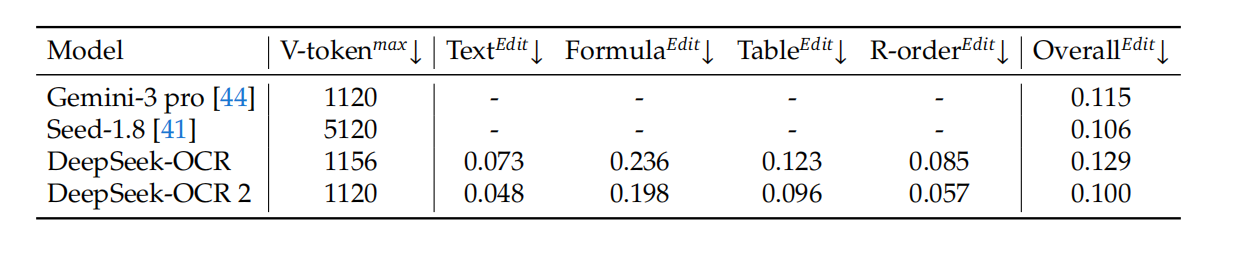
这一套操作下来,每张图最多只输出 512 个视觉 token ,相比之前的 OCR1(1156)和 Gemini(1120),不仅更短 ,还更有效。
而且更巧妙的是,这个压缩是自适应的。 模型会判断哪些区域信息密集、哪些不重要,从而动态保留或融合 patch**。**
在这个 token 压缩的基础上,OCR2 再由 Qwen2 模型生成动态阅读 Query,引导模型逐步"看图",再交由 DeepSeek-3B 生成结构化输出。
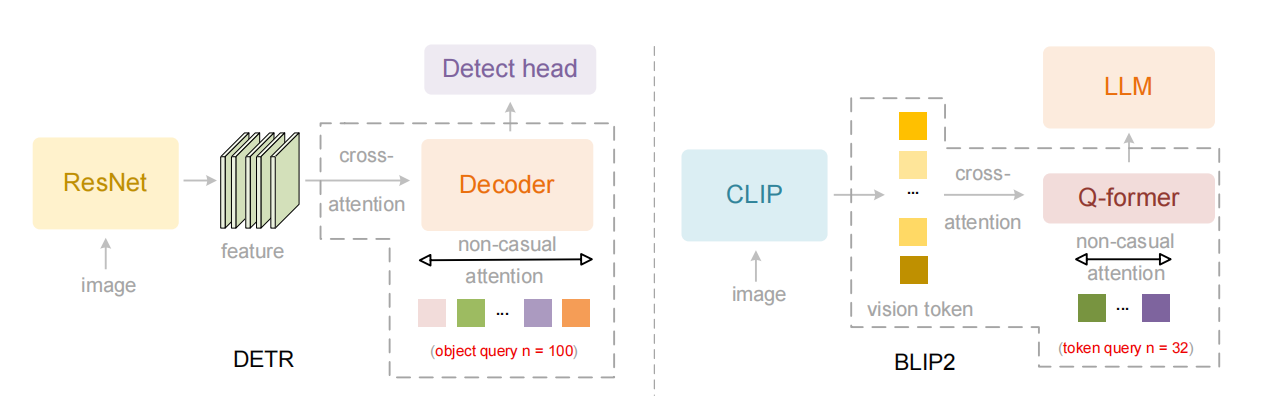
这个「LM as Vision Encoder」的设计,和传统 DETR、BLIP2 架构完全不同:
-
DETR 是靠固定数量的 Query(比如 100 个)"抓取"图中的物体,不关心顺序;
-
BLIP2 是用 Q-former 从图像 token 中找"代表性 token",再喂给语言模型;
OCR2,则是直接让语言模型做"第一性理解"。
那它到底有多强?直接上指标。
在 OmniDocBench v1.5 基准测试中,DeepSeek-OCR 2 是唯一一个在视觉 token 不超过 1120 的前提下,全面超越所有"大 token"模型的选手。
与上一代相比,整体准确率提升了 **3.73%**。
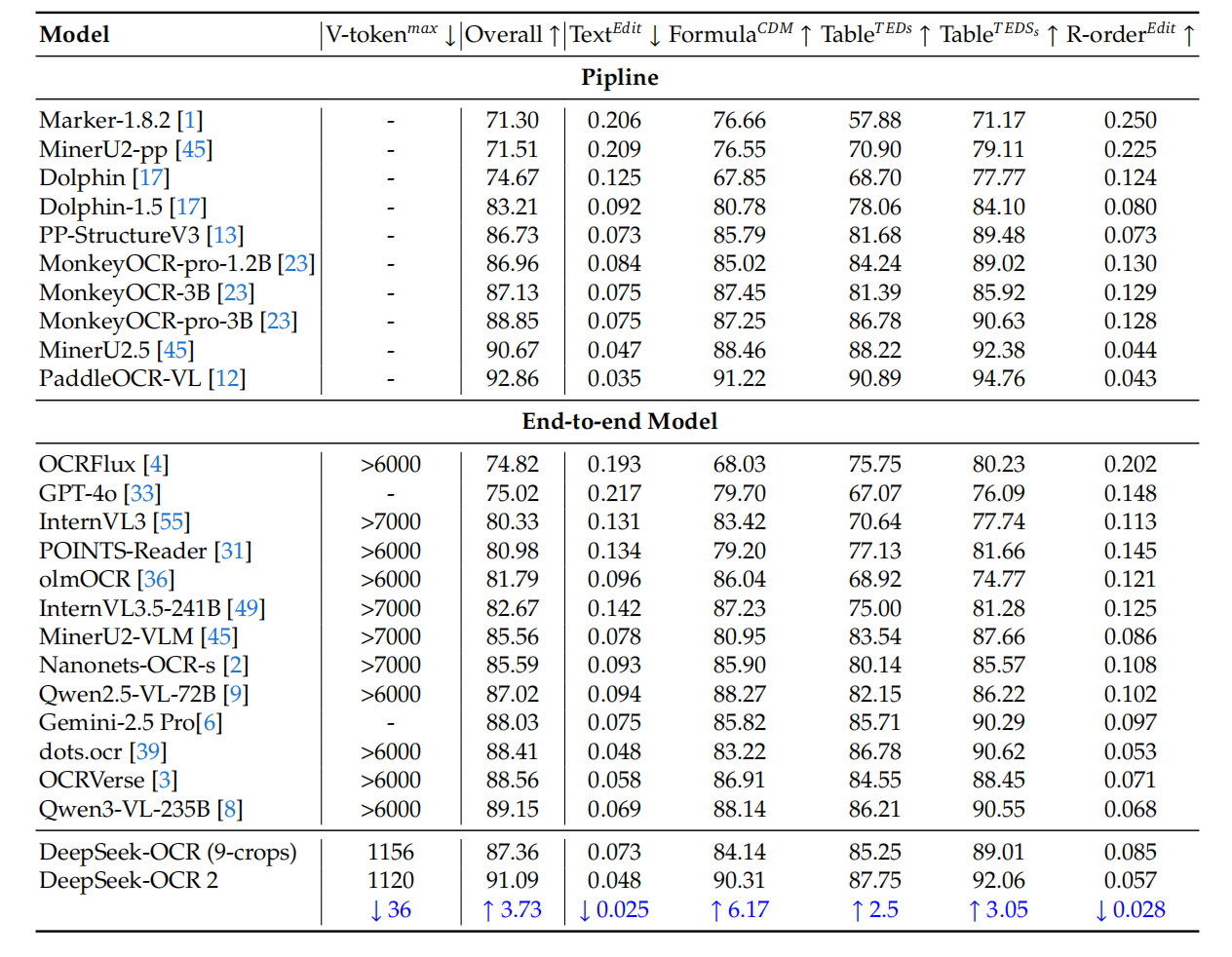
核心升级的阅读顺序识别(R-order Edit),直接从 0.085 → 0.057,误差率下降 33%。
看到这你可能会发现,DeepSeek-OCR 2 做的事,其实已经不太像我们以前理解的「OCR」了。
传统 OCR 的世界观很朴素:图里有字,我把字抠出来。抠得越像越好。它的终点是"把图变成字"。
但你真把 OCR 用在工作里就知道,文档里从来不只是字。它是标题、层级、引用、图注、表格、脚注、双栏、页眉页脚、编号体系......这些东西共同决定了"怎么读"。传统 OCR 往往不管这些。于是你只能得到一串看似完整的文本,自己还得当一次编辑。重新对齐归位。
而 OCR2 开始尝试"把图变成内容"。"字"是你能看见的符号,"内容"是你不用返工否,能直接拿去用的东西。
所以它才要死磕"阅读顺序感"。
因为在真实文档里,最要命的错误往往不是错别字,而是读错了顺序。字错了你一眼能看出来,顺序错了你得整段读完才意识到不对劲,等你发现的时候,下游的检索、抽取、归档、知识库,可能已经跟着一起乱套了。
这才是 OCR2 真正想解决的事。也恰恰是过去很多 OCR 产品一直没解决、但你每天都在被迫解决的事。