内卷时代的"逆行者"
近年来,目标检测模型的发展似乎陷入了一种"堆料"的趋势。为了在公开数据集上刷取更高的mAP,模型架构变得愈发复杂,例如 YOLOv12 引入了注意力机制,YOLOv13 引入了超图结构 。下图是YOLO各代的优化:
| 模型 (年份) | 核心架构创新与贡献 | 任务 | 框架 |
|---|---|---|---|
| YOLOv1 (2015) | 首个统一的单阶段目标检测器(将边界框与类别概率集成在单一网络中)。 | 目标检测、分类 | Darknet |
| YOLOv2 (2016) | 引入多尺度训练;通过 Anchor Box 维度聚类优化先验框(YOLO9000 支持联合检测/分类)。 | 目标检测、分类 | Darknet |
| YOLOv3 (2018) | 更深的 Darknet-53主干网络并引入残差连接;添加 SPP 模块和多尺度特征融合以提升小目标检测性能。 | 目标检测、多尺度检测 | Darknet |
| YOLOv4 (2020) | 采用 Mish 激活函数;引入 CSPDarknet-53 主干网络(跨阶段局部网络)以增强特征重用。 | 目标检测、目标跟踪 | Darknet |
| YOLOv5 (2020) | Ultralytics 推出的 PyTorch 实现版本;提供无锚点(Anchor-free)检测头选项;使用 SiLU (Swish) 激活函数和 PANet 颈部网络进行特征聚合。 | 目标检测、实例分割(有限) | PyTorch (Ultralytics) |
| YOLOv6 (2022) | 采用嵌入自注意力的 EfficientRep 主干网络;引入无锚点检测模式以提升效率。 | 目标检测、实例分割 | PyTorch |
| YOLOv7 (2022) | 扩展的 ELAN (E-ELAN) 主干网络及模型重参数化;集成了基于 Transformer 的模块以支持更广泛的任务(如跟踪)。 | 目标检测、目标跟踪、实例分割 | PyTorch |
| YOLOv8 (2023) | Ultralytics 次世代模型;采用全新的 C2f 主干网络和解耦头;融入生成式技术(基于 GAN 的增强)及完全无锚点设计。 | 目标检测、实例分割、全景分割、关键点检测 | PyTorch (Ultralytics) |
| YOLOv9 (2024) | 引入可编程梯度信息 (PGI) 以进行选择性学习;提出 G-ELAN(增强型 ELAN 架构)以改进特征提取。 | 目标检测、实例分割 | PyTorch |
| YOLOv10 (2024) | 通过一致的双分配训练策略实现了端到端无 NMS(非极大值抑制)检测(移除后处理步骤)。 | 目标检测 | PyTorch |
| YOLOv11 (2024) | 在整个主干/颈部网络中添加了 C3k2 CSP 瓶颈结构(更小内核的 CSP 块)以提升效率;保留了 SPPF 并引入 C2PSA(带有空间注意力的 CSP)模块以聚焦重要区域。 | 目标检测、实例分割、姿态估计、旋转目标检测 | PyTorch (Ultralytics) |
| YOLOv12 (2025) | 以注意力为核心的架构:引入了高效区域注意力模块(低复杂度的全局自注意力)和残差 ELAN (R-ELAN) 块以优化特征聚合,在 YOLO 速度下达到 Transformer 级的精度。 | 目标检测 | PyTorch |
| YOLOv13 (2025) | 基于超图的自适应相关性增强 (HyperACE) 模块,捕捉全局高阶特征交互;采用全流水线聚合分发 (FullPAD) 方案增强网络特征流;利用深度可分离卷积降低复杂度。 | 目标检测 | PyTorch |
| YOLOv26 (2025) | Ultralytics 边缘优化模型:通过原生端到端预测器消除 NMS;移除 DFL(分布FOCAL损失)以实现更简易、更快速的推理;引入MuSGD 优化器(SGD+Muon 混合)实现稳定快速收敛;显著提升小目标精度,CPU 推理速度提升高达43%。 | 目标检测、实例分割、姿态估计、旋转目标检测、分类 | PyTorch (Ultralytics) |
然而,在实际的工业落地中,复杂的架构往往意味着在边缘设备(如移动端、无人机、嵌入式平台)上面临严重的推理延迟和模型导出瓶颈 。在这一背景下,2025 年 9 月发布的 YOLO26 选择了一条不同的演进路线:回归部署导向的实用主义 。来看效率对比:
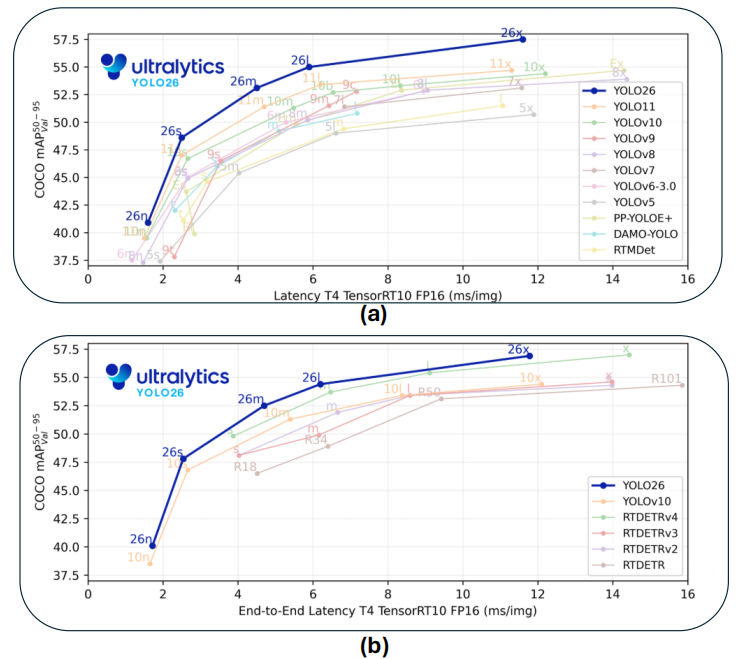
本文将拆解 YOLO26 的四个核心架构变动,探讨其如何在砍掉复杂模块的同时,利用训练策略和新型优化器维持高精度。
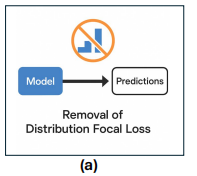
一、 移除 DFL(分布焦点损失):简化边界框回归
在 YOLOv8 等前代模型中,DFL(Distribution Focal Loss)被广泛使用 。
1. 为什么要用 DFL,又为什么要移除它?
在目标检测中,AI 需要画一个"边界框"(Bounding Box)来框住物体。以往的 YOLO 模型(如 YOLOv8)为了追求极高的框选精度,引入了 DFL,将其转化为一个离散的概率分布预测。你可以把它想象成"猜身高":传统的做法是直接猜"这个人 175 厘米";而 DFL 的做法是输出一个概率分布:"这个人有 10% 的可能 174 厘米,80% 的可能 175 厘米,10% 的可能 176 厘米" 。虽然 DFL 的"概率猜测法"很准,但它需要进行大量的复杂数学运算(计算概率分布)。在推理时,需要通过计算期望(积分或加权求和)来还原坐标。
DFL假设真实的坐标 yyy 落在两个相邻的离散网格点 yiy_iyi 和 yi+1y_{i+1}yi+1 之间。模型会输出这两个点的概率 SiS_iSi 和 Si+1S_{i+1}Si+1,DFL 的核心公式通常计算这两个相邻点的交叉熵:
DFL(Si,Si+1)=−((yi+1−y)log(Si)+(y−yi)log(Si+1))\text{DFL}(S_i, S_{i+1}) = -((y_{i+1} - y)\log(S_i) + (y - y_i)\log(S_{i+1}))DFL(Si,Si+1)=−((yi+1−y)log(Si)+(y−yi)log(Si+1))
在推理时,模型需要通过积分(离散情况下的加权求和,即 Softmax 配合期望计算)来还原最终坐标:
y^=∑jP(yj)⋅yj\hat{y} = \sum_{j} P(y_j) \cdot y_jy^=∑jP(yj)⋅yj
这种概率分布计算引入了不可忽视的算力开销,并且在将其导出为 TensorRT、CoreML 或 TFLite 等端侧格式时,常常遇到算子不支持或执行效率低下的问题 。YOLO26 为了追求极致的部署友好性,直接移除了 DFL 模块 。回归头恢复为最直接的线性映射,仅输出确切的坐标。这极大简化了计算图,使得模型在 INT8 或 FP16 量化下也能保持稳定的精度表现 。
二、端到端无 NMS 推理:二分图匹配的工程实践
目标检测流水线中,NMS(非极大值抑制)长期以来是一个难以优化的后处理瓶颈 。
1. 传统"一对多"分配的痛点 在传统的训练机制中,只要多个预测框与真实目标(Ground Truth, GT)的交并比(IoU)达到一定阈值,它们都会被视为"正样本"。这种"一对多"的分配导致模型在推理时会针对同一个物体输出大量重叠的候选框。因此,必须依赖 NMS 步骤,通过人工设定的 IoU 阈值来剔除冗余框 。这不仅增加了 CPU 的串行计算延迟,还使得模型在密集场景下容易发生误删 。
2. YOLO26 的"一对一"二分图匹配 YOLO26 重构了预测头,实现了原生的端到端无 NMS 推理 。其核心在于训练阶段采用了基于**匈牙利算法(Hungarian Algorithm)**的一对一匹配策略,这种古老的算法曾在基于Transformer的目标检测器DETR中被使用。
系统会计算所有预测框与所有 GT 之间的"匹配代价矩阵"(Cost Matrix),该代价通常由三部分组成:
Ci,j=λclsLcls+λiouLiou+λL1LL1C_{i,j} = \lambda_{cls} \mathcal{L}{cls} + \lambda{iou} \mathcal{L}{iou} + \lambda{L1} \mathcal{L}_{L1}Ci,j=λclsLcls+λiouLiou+λL1LL1
- Lcls(pi,cj)\mathcal{L}_{cls}(p_i, c_j)Lcls(pi,cj):分类代价 。pip_ipi 是预测为目标类别 cjc_jcj 的概率。通常使用 Focal Loss。如果预测类别完全不对,这项代价会极高。
- Liou(bi,b^j)\mathcal{L}_{iou}(b_i, \hat{b}_j)Liou(bi,b^j):IoU 代价 。通常使用 GIoU 或 CIoU。预测框 bib_ibi 和真实框 b^j\hat{b}_jb^j 重叠越少,代价越高。
- ∥bi−b^j∥1\| b_i - \hat{b}_j \|_1∥bi−b^j∥1:L1 距离代价。预测框与真实框中心点坐标的绝对距离。
- λ\lambdaλ:各项的权重系数。
计算完所有 iii 和 jjj 的组合后,我们就得到了一个 N×MN \times MN×M 的代价矩阵。
匈牙利算法会在全局范围内,为每一个 GT 寻找唯一一个综合代价最低的预测框作为正样本,其余预测框全部强制作为负样本(背景)。这迫使模型在训练阶段就内化了"抑制冗余"的能力。反映在性能上,这一改动使得 YOLO26 的 CPU 推理时间相比前代缩短了最高达 43% 。
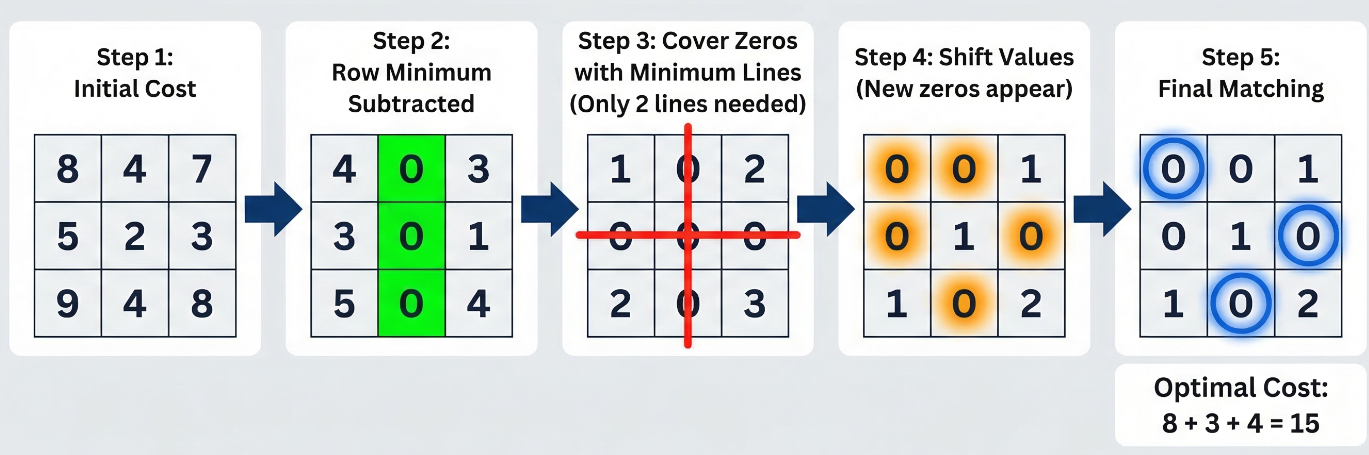
对于不熟悉匈牙利算法的同学,这里我举一个例子,方便直观感受。下面用一个"公司给 3 个候选人分配 3 个岗位"的实战例子,手把手推演一遍匈牙利算法。假设系统输出了3个预测框(候选人),画面里有3个真实目标(岗位)。我们计算出了它们之间的"不匹配代价"(Cost)。数值越低,说明匹配度越高。始代价矩阵如下(比如候选人 1 去岗位 2 的代价是 4):
847523948\begin{bmatrix} 8 & 4 & 7 \\ 5 & 2 & 3 \\ 9 & 4 & 8 \end{bmatrix} 859424738
第一步:行减极小值(保证每个人都有最想去的岗位)。找到每一行的最小值(分别是 4、2、4),然后这一行的所有数字都减去这个最小值。出现了 0,代表候选人当前的最优解。但你发现,三个人都在第 2 列出现了 0(都抢着要去岗位 2),这叫冲突。
8−44−47−45−22−23−29−44−48−4→403301504\begin{bmatrix} 8-4 & 4-4 & 7-4 \\ 5-2 & 2-2 & 3-2 \\ 9-4 & 4-4 & 8-4 \end{bmatrix} \rightarrow \begin{bmatrix} 4 & 0 & 3 \\ 3 & 0 & 1 \\ 5 & 0 & 4 \end{bmatrix} 8−45−29−44−42−24−47−43−28−4 → 435000314
第二步:列减极小值(保证每个岗位都有最合适的人)。在上一步的矩阵中,找每一列的最小值(分别是 3、0、1),然后该列所有数字减去最小值。
4−30−03−13−30−01−15−30−04−1→102000203\begin{bmatrix} 4-3 & 0-0 & 3-1 \\ 3-3 & 0-0 & 1-1 \\ 5-3 & 0-0 & 4-1 \end{bmatrix} \rightarrow \begin{bmatrix} 1 & 0 & 2 \\ 0 & 0 & 0 \\ 2 & 0 & 3 \end{bmatrix} 4−33−35−30−00−00−03−11−14−1 → 102000203
第三步:画线覆盖(测试是否能完美分配)规则是:用最少的直线(横线或竖线)把矩阵里所有的0给划掉。 你看上面的矩阵,所有的0集中在第2列和第 2 行。所以我们只需要画 2 条线(划掉第 2 列、划掉第 2 行)就能覆盖所有0。因为矩阵是 3x3,但我们只用了2条线,线数(2)< 维度(3),说明目前的 0 还不够多,还没法达成完美的一对一分配。
第四步:矩阵调整(强行挤出新的 0)
第一步,找到没被线划到的数字:是左上、左下、右上、右下的 {1,2,2,3}\{1, 2, 2, 3\}{1,2,2,3}。
第二步,找出这些数字里的最小值:是 111。
第三步,让所有没划到的数字减去 111;让线条交叉点的数字(第 2 行第 2 列那个 0)加上 111;只被一条线覆盖的数字不变。
1−102−100+102−103−1→001010102\begin{bmatrix} 1-1 & 0 & 2-1 \\ 0 & 0+1 & 0 \\ 2-1 & 0 & 3-1 \end{bmatrix} \rightarrow \begin{bmatrix} 0 & 0 & 1 \\ 0 & 1 & 0 \\ 1 & 0 & 2 \end{bmatrix} 1−102−100+102−103−1 → 001010102
第五步:完成最终匹配
现在再尝试画线,发现必须画 3 条线才能覆盖所有的 0了(线数 = 维度 3)。说明完美匹配已诞生!我们挑出互不冲突的 0 的位置:
候选人 1 -> 岗位 1 (矩阵1,1 = 0,原来代价是8)
候选人 2 -> 岗位 3 (矩阵2,3 = 0,原来代价是3)
候选人 3 -> 岗位 2 (矩阵3,2 = 0,原来代价是4)
总代价 = 8 + 3 + 4 = 15。这就是这9种组合里代价最低、最完美的一对一分配方案!
三、 弥补精度损失的训练策略:ProgLoss 与 STAL
简化架构势必会带来精度波动的风险,YOLO26 采用 ProgLoss 和 STAL 两种策略在训练端进行补偿 。
1. ProgLoss(渐进式损失平衡) 在训练后期,模型往往会被大量容易分类的简单样本主导。ProgLoss 通过动态调整分类损失和回归损失的权重,防止模型过拟合于简单目标,确保优化过程的平稳 。你可以把它想象成一位"因材施教的老师"。模型在训练后期,容易在简单的大物体上"刷分"而忽略难题。ProgLoss 会动态调整权重的天平,防止简单样本主导训练,稳住大局 。
在目标检测中,总损失通常是分类损失 LclsL_{cls}Lcls 和回归损失 LregL_{reg}Lreg 的加权和。ProgLoss 引入了随训练周期(Epoch)ttt 动态变化的权重系数 α(t)\alpha(t)α(t) 和 β(t)\beta(t)β(t):
Ltotal=α(t)Lcls+β(t)LregL_{total} = \alpha(t) L_{cls} + \beta(t) L_{reg}Ltotal=α(t)Lcls+β(t)Lreg
在训练后期,模型往往会被大量容易分类的简单样本(Easy Examples)主导。ProgLoss 自适应地调整这些权重,防止简单样本产生的微小梯度累积淹没困难样本的梯度,从而保证后期的训练稳定性 。
2. STAL(小目标感知标签分配)
传统的匹配规则看的是"重叠面积比例"(IoU)。对于一个占据半个屏幕的大卡车,预测框就算稍微偏了几十个像素,重叠率依然很高,能轻松被判定为正样本。 但是,如果目标是一架远处的无人机(面积只有 10×1010 \times 1010×10 像素),预测框只要稍微抖动偏移 2 个像素,重叠率就会断崖式下跌,瞬间跌破及格线,被系统判定为"负样本"。这样的后果是模型在训练时,几乎拿不到小目标的正样本,它会以为"这些小黑点都是背景",导致实战中根本检测不到小目标(召回率极低)。
STAL 就像是一个懂得"扶弱济贫"的考官。它在训练时会先检查真实目标的面积(AGTA_{GT}AGT)。如果发现这是一个小目标,STAL 就会主动降低匹配代价的门槛(Threshold) 。"既然你这么小、这么难预测,那我就对你宽容一点。只要你的预测框离小目标足够近,哪怕重合度没有达到标准,我也破例算你是正样本!"模型被强制分配了更多关于小目标的学习资料。因为学习的次数多了,模型在无人机视角或拥挤遮挡的环境下,把真实目标找出来的能力(召回率)就大幅提升了 。
虽然论文没有公开 STAL 具体的专有函数公式,但根据论文描述其"明确优先考虑小目标的标签分配" ,我们可以还原这类尺度感知分配算法的数学原理。在传统的标签分配中,通常会设定一个固定的匹配阈值(比如 IoU>0.5\text{IoU} > 0.5IoU>0.5 才能算正样本)。对于面积 AGTA_{GT}AGT 很小的目标,轻微的像素偏移就会导致 IoU 暴跌,无法跨越阈值。STAL 的核心在于引入尺度惩罚/补偿项,让阈值 τ\tauτ 成为关于目标面积 AGTA_{GT}AGT 的动态函数。
一种典型的数学建模方式是:τSTAL=τbase×(AGTAnorm)γ\tau_{STAL} = \tau_{base} \times \left( \frac{A_{GT}}{A_{norm}} \right)^\gammaτSTAL=τbase×(AnormAGT)γ
- τbase\tau_{base}τbase:基础门槛(例如 0.5)。
- AGTA_{GT}AGT:当前真实目标的像素面积(宽 ×\times× 高)。
- AnormA_{norm}Anorm:设定的标准尺度归一化常数。
- γ\gammaγ:调节灵敏度的超参数(通常为正数)。
当 AGTA_{GT}AGT 非常小(比如远处的无人机),比例 AGTAnorm\frac{A_{GT}}{A_{norm}}AnormAGT 就会是一个远小于 1 的数。经过 γ\gammaγ 次方后,算出的动态门槛 τSTAL\tau_{STAL}τSTAL 可能会降低到 0.2 或更低。这样,原本因为微小偏差被淘汰的预测框,就能跨过这个"降低后的门槛",被强制指定为小目标的正样本进行学习。
四、MuSGD 优化器:用低成本运算逼近二阶优化
在模型优化方面,YOLO26 提出了 MuSGD 优化器,它结合了传统 SGD(随机梯度下降)的泛化能力,并吸收了常用于大语言模型(LLM)训练的Muon优化器思想 ,在KIMI2.5训练中就用到了Muon。
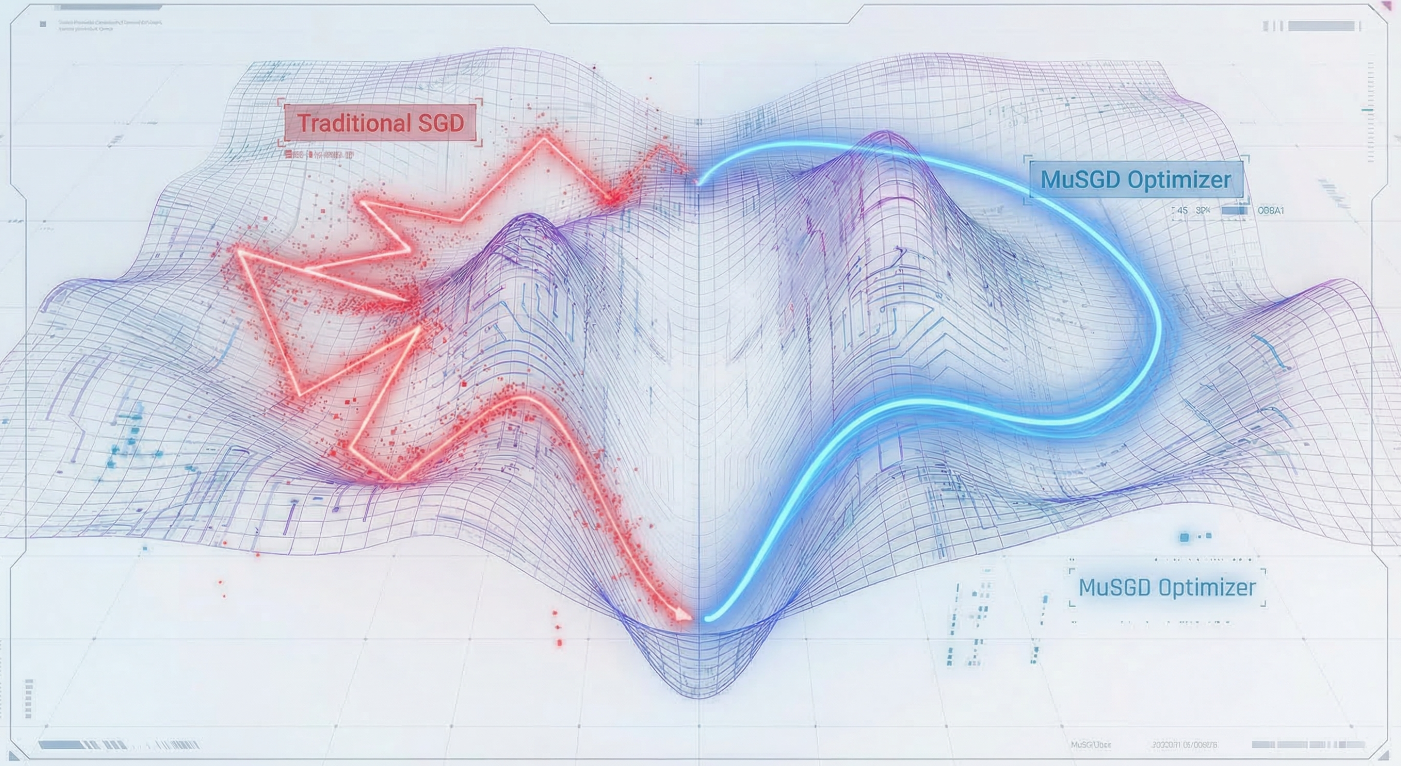
1. 为什要引入 Muon 算法?
传统的SGD仅利用一阶梯度,在复杂的损失曲面中容易震荡且收敛缓慢 。理想的优化需要获取地形的"曲率"(二阶信息,如近似海森矩阵),这就需要对梯度矩阵进行正交化。但若使用奇异值分解(SVD)来计算逆平方根,算力开销巨大。
2. 牛顿-舒尔茨迭代的数学优雅
Muon 算法的核心在于使用牛顿-舒尔茨迭代(Newton-Schulz Iteration)来近似这一过程。通过泰勒展开,可以将复杂的逆平方根运算 (XkTXk)−1/2(X_k^T X_k)^{-1/2}(XkTXk)−1/2 近似转化为多项式:
Xk+1=32Xk−12XkXkTXkX_{k+1} = \frac{3}{2} X_k - \frac{1}{2} X_k X_k^T X_kXk+1=23Xk−21XkXkTXk
这一公式的美妙之处在于,它仅包含矩阵乘法和简单的标量加减。现代 GPU 对矩阵乘法的处理效率极高。MuSGD 利用这一迭代,在几乎不增加额外显存负担的情况下,获取了包含平滑曲率信息的正交化梯度 ,使得 YOLO26 能够以更少的训练轮数(Epochs)稳定收敛 。
对于想了解上式背后数学的同学,我这里提供一个关于牛顿-舒尔茨迭代的简单解释。这个公式的核心目的,是用极其廉价的计算代价,去逼近一个极其昂贵的矩阵运算。我一步步拆开:
首先思考我们在这个问题中的终极目标是什么 ,在优化器(如 MuSGD)中,我们希望把一个普通的梯度矩阵 XkX_kXk 变成一个正交矩阵 。 在数学上,如果一个矩阵是完美的正交矩阵,它必须满足:XTX=IX^T X = IXTX=I
如果要用暴力的、绝对精确的数学方法把 XkX_kXk 强行正交化,标准做法是让它乘上自己转置乘积的逆平方根:
Xperfect=Xk(XkTXk)−1/2X_{perfect} = X_k (X_k^T X_k)^{-1/2}Xperfect=Xk(XkTXk)−1/2
但是!在深度学习里,计算一个大矩阵的"逆平方根" (XkTXk)−1/2(X_k^T X_k)^{-1/2}(XkTXk)−1/2 需要做奇异值分解(SVD),这会把显卡的算力瞬间榨干。所以,牛顿-舒尔茨迭代的任务就是:绕开 SVD,用简单的加减乘除来近似计算 (XkTXk)−1/2(X_k^T X_k)^{-1/2}(XkTXk)−1/2。
第二步:引入"误差矩阵"
假设当前的矩阵 XkX_kXk 已经离正交矩阵"有一点点近"了,我们可以定义一个误差矩阵 EEE,看看它离完美的单位矩阵 III 还差多少,如果 XkX_kXk 已经是完美正交的,那么 XkTXk=IX_k^T X_k = IXkTXk=I,此时误差 E=0E = 0E=0:
E=I−XkTXkE = I - X_k^T X_kE=I−XkTXk
现在,我们把前面那个极其难算的"逆平方根"部分,用误差矩阵 EEE 替换一下:(XkTXk)−1/2=(I−E)−1/2(X_k^T X_k)^{-1/2} = (I - E)^{-1/2}(XkTXk)−1/2=(I−E)−1/2
第三步:见证奇迹的泰勒展开
现在,要用到大学微积分里非常经典的一个公式------二项式泰勒展开。
对于普通的数字 xxx,当 xxx 很小(接近 0)的时候,有这样一个近似公式:
(1−x)−1/2≈1+12x(1 - x)^{-1/2} \approx 1 + \frac{1}{2} x(1−x)−1/2≈1+21x
牛顿-舒尔茨算法的核心胆识,就是把这个微积分公式直接搬到了矩阵上!
因为误差矩阵 EEE 很小(接近 0 矩阵),所以可以对 (I−E)−1/2(I - E)^{-1/2}(I−E)−1/2 进行一阶泰勒展开:
(I−E)−1/2≈I+12E(I - E)^{-1/2} \approx I + \frac{1}{2} E(I−E)−1/2≈I+21E
第四步:代入化简,得出最终公式
现在,把 EEE 替换回它原本的样子(E=I−XkTXkE = I - X_k^T X_kE=I−XkTXk):I+12E=I+12(I−XkTXk)I + \frac{1}{2} E = I + \frac{1}{2} (I - X_k^T X_k)I+21E=I+21(I−XkTXk)
把括号拆开,合并同类项:=I+12I−12XkTXk=32I−12XkTXk= I + \frac{1}{2} I - \frac{1}{2} X_k^T X_k= \frac{3}{2} I - \frac{1}{2} X_k^T X_k=I+21I−21XkTXk=23I−21XkTXk
这就意味着,那个原本算死人的逆平方根,被化简成了这个简单的多项式:(XkTXk)−1/2≈32I−12XkTXk(X_k^T X_k)^{-1/2} \approx \frac{3}{2} I - \frac{1}{2} X_k^T X_k(XkTXk)−1/2≈23I−21XkTXk
第五步:完成迭代计算
最后,把这个化简后的结果,代回到第一步的公式里。为了得到下一步更完美的矩阵 Xk+1X_{k+1}Xk+1,我们用当前的 XkX_kXk 乘以上面这坨近似值:Xk+1=Xk(32I−12XkTXk)X_{k+1} = X_k \left( \frac{3}{2} I - \frac{1}{2} X_k^T X_k \right)Xk+1=Xk(23I−21XkTXk)
把 XkX_kXk 乘进去,展开括号:Xk+1=32Xk−12XkXkTXkX_{k+1} = \frac{3}{2} X_k - \frac{1}{2} X_k X_k^T X_kXk+1=23Xk−21XkXkTXk
仔细看最终的公式,里面只有矩阵乘法(XkXkTXkX_k X_k^T X_kXkXkTXk)和常数加减法(32\frac{3}{2}23、12\frac{1}{2}21)。现代 GPU(比如英伟达的 Tensor Core)天生就是为了做矩阵乘法而造的,算乘法快如闪电;但做求逆、开根号却非常笨拙。通过这个数学推导,Muon 优化器成功地把"GPU 最讨厌的复杂运算"转化成了"GPU 最擅长的傻瓜乘法"。循环迭代个 5 次,就能拿到极其精准的正交化梯度,从而让 YOLO26 的训练又快又稳。
代码浅析
这里从开源代码上看一下上面的四个核心改进,由于ultralytics代码库庞大,本文只是将涉及这四点的内容单独拎出来浅析,后续文章中再专门针对代码进行解读。
官方仓库:https://github.com/ultralytics/ultralytics
1. 极简回归头与 DFL 的移除
论文中提到 YOLO26 为了兼顾端侧部署,移除了复杂的分布焦点损失(DFL)。在代码中,这一点体现得非常直接且精妙:
-
配置文件 (
ultralytics/cfg/models/26/yolo26.yaml):在配置中,明确设置了
reg_max: 1和end2end: True。 -
网络模块 (
ultralytics/nn/modules/head.py):在
Detect类的初始化函数__init__中,有这样一行关键代码:self.dfl = DFL(self.reg_max) if self.reg_max > 1 else nn.Identity()因为 YOLO26 的配置传入了
reg_max=1,所以self.dfl被直接实例化为nn.Identity()(占位符,不进行任何计算)。这意味着网络直接输出确切坐标,跳过了原先极其耗时的积分计算和 Softmax 概率分布转换。这为 TensorRT 和 TFLite 的算子导出扫清了最大障碍。
2. 端到端无 NMS (NMS-Free) 推理的实现
YOLO26 实现提速 43% 的杀手锏是彻底丢弃人工超参数 NMS 后处理。在代码中清楚地看到了**"双头(Dual-Head)架构"与原生 Top-K 提取**:
-
双头结构 (
head.py):在检测头中,当
end2end=True时,代码不仅有传统的cv2/cv3,还深度克隆(deepcopy)出了额外的一对一专属预测头:if end2end: self.one2one_cv2 = copy.deepcopy(self.cv2) self.one2one_cv3 = copy.deepcopy(self.cv3) -
推理无 NMS 化 (
postprocess方法):在
head.py的推理后处理环节,没有调用torchvision.ops.nms。取而代之的是,它调用了get_topk_index方法,单纯依靠张量操作获取得分最高的max_det(如 300)个框:scores, conf, idx = self.get_topk_index(scores, self.max_det) boxes = boxes.gather(dim=1, index=idx.repeat(1, 1, 4))这说明模型在训练时已经学会了"自我抑制",输出的框天然就是不重叠的,极大释放了 CPU 算力。
3. ProgLoss 渐进式损失平衡的训练补偿
为了弥补去掉 DFL 带来的精度风险,YOLO26 引入了 ProgLoss(渐进式损失平衡)。
-
损失函数调度 (
ultralytics/utils/loss.py):在端到端损失计算中,我们看到了动态权重更新的逻辑:
def update(self) -> None: """Update the weights for one-to-many and one-to-one losses based on the decay schedule.""" self.updates += 1 self.o2m = self.decay(self.updates) self.o2o = max(self.total - self.o2m, 0)o2m(one-to-many 损失权重) 随着训练步数 (self.updates) 的增加而逐渐衰减,而o2o(one-to-one 损失权重) 则相应增加。这对应了论文中提到的:前期利用一对多分配来保证充足的梯度和召回率,后期平滑过渡到一对一分配,强化无 NMS 推理的能力。
4. MuSGD 优化器(大模型底层逻辑跨界)
这是代码库中最硬核的数学实现之一,位于 ultralytics/optim/muon.py 中。
牛顿-舒尔茨迭代 (Newton-Schulz Iteration):
上面推导过近似正交化公式 Xk+1=32Xk−12XkXkTXkX_{k+1} = \frac{3}{2} X_k - \frac{1}{2} X_k X_k^T X_kXk+1=23Xk−21XkXkTXk,在代码中被极其工整地用 bfloat16 精度和 5 次循环实现了出来:
def zeropower_via_newtonschulz5(G: torch.Tensor, eps: float = 1e-7) -> torch.Tensor:
# ... [初始化与归一化] ...
for a, b, c in [ (3.4445, -4.7750, 2.0315), ... ]: # 循环5次
A = X @ X.T
B = b * A + c * A @ A
X = a * X + B @ X
return X这里作者使用了一组优化过的系数 (3.4445, -4.7750, 2.0315) 来替代标准的 (1.5, -0.5) 泰勒展开系数,进一步加速了矩阵在零点的收敛斜率(这是对原生 Muon 优化器在视觉任务上的一次微调)。
正是因为全篇只用到了 X @ X.T(矩阵乘法)和简单的加法,现代 GPU 运行这个"获取二阶曲率"的操作几乎是瞬间完成的,从而让 YOLO26 训练得又快又稳。
小结
YOLO26 不仅仅是一个模型版本的更新,它代表了计算机视觉领域的一种觉醒:真正的领先,不是在实验室的顶级显卡上跑出多高的分数,而是能顺畅地部署到工厂的流水线、农田的无人机和人们口袋里的手机中。
无论你是做图像分类、目标检测还是实例分割,YOLO26 这套极其轻量、对部署极度友好的架构(支持 ONNX、TensorRT、CoreML、TFLite),都值得你立刻 git clone 下来跑一跑!后面几期我将从教学视角给出几个YOLO26的实战体验。