1.区分 序列式容器 与 关联式容器
前面学习了很多容器:string,vector,list,stack,queue,array等,这些统称为序列式容器:因为逻辑结构为线性序列的数据结构,两个位置存储的值一般没有紧密的关联关系,交换一下,依旧是序列式容器。顺序容器中的元素是按照他们在容器的存储位置顺序保存和访问的。
今天要学习的may和set是关联式容器:关联式容器逻辑结构通常是非线性结构,两个位置有紧密关联关系(key、value),交换一下,存储结构就破坏了。顺序容器中是按照关键字(key)保存和访问的 。后续的unordered_map系列 / unordered_set系列也是关联式容器。
本章的map,set底层是红黑树,红黑树是一颗平衡二叉搜索树。set是key结构,map是key/value结构
2.set系列的使用
2.1set的简介
如图,set系列作为C++stl的高级容器之一,头文件是 set ,包含两个set类:set,multiset,还支持迭代器遍历。 下面是set的声明:
1.set默认支持less仿函数比较(less仿函数是升序,greater仿函数降序,同样可自己写)
2.set底层存储数据的内存默认是从空间配置器申请的,允许自己写一个内存池,传给第三个参数
3.一般情况下我们不需要传第二,三个参数(比较逻辑和内存池,不怎么需要修改)
4.set底层是红黑树实现,增删查效率是
,迭代器遍历是中序(同二叉搜索树),输出结果有序
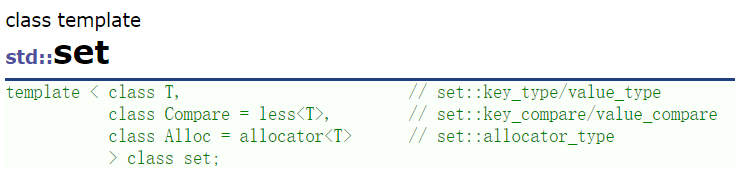
2.2set的 构造函数 和迭代器
构造函数就看几个常用的:无参默认构造,迭代器区间构造,拷贝构造,Initializer_list构造
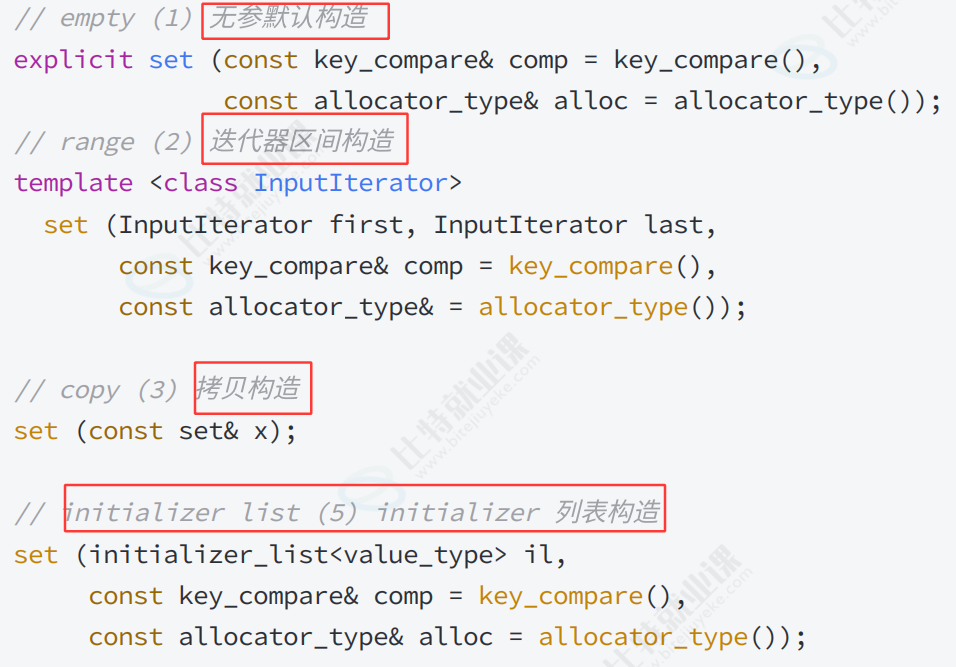
迭代器也是一样的。

2.3set的增删查
注意删除会导致迭代器失效。其余的都是和之前一样。
Insert:注意第一个,返回的是pair类型,意思是:
插入成功,返回<插入key位置的迭代器,true>
插入失败,返回<已存在key的迭代器,false>
count:用于记数,统计value,不过set都是1(value统计个数,但是set不支持数据冗余),这是为了配合multiset(支持数据冗余),保证接口一致性,降低不必要的学习成本。这里的作用是:判断是否存在

2.3.1插入,迭代器 使用示例
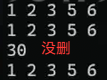
输出结果有序:
不是严格升序,而是:去重+排序
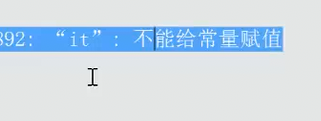
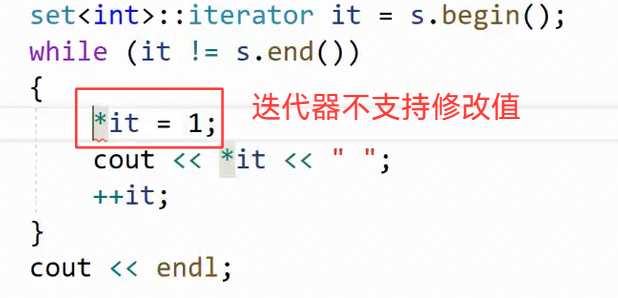
迭代器不允许修改,没有重载 * 运算符

2.3.2 删除,查找使用示例
erase删除,在就删,不在,就不删:


2.4lower_bound 和 upper_bound
lower_bound:获取 " >= x " 的起始位置的迭代器
upper_bound:获取 " < x " 的起始位置的迭代器
可以用于删除一段闭区间的值

2.5multiset的简介
multiset也包含于 set 头文件。它是支持数据冗余的set,函数接口可以说一模一样,没什么好说的。具体区别下面列举:
2.5.1multiset的增删查...等其他接口
排序区别
multiset可以插入同样的值,它的真正的升序:不是set的去重+排序

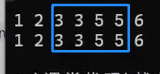
find ,find查找重复值
对于重复的值x,find查找的是中序的第一个x,这点可以验证:


为什么是中序遍历第一个x呢?这和旋转有关。旋转是AVL树的知识,AVL树通过旋转结点,控制树的高度差不超过1。后面会讲到,了解
可以看出:set系列的迭代器封装了二叉树的中序遍历
count和erase
count记3的个数,打印了4,erase把所有3都删了


equal_range
这个函数,会把输入的值x(全部重复的值)的左闭右开区间 [ x,...),返回给pair类型
pair.first 指向第一个x的迭代器(>= x),pair.second 指向比x大的第一个迭代器(> x)
可以用auto,自动推导pair类型:
set也有这个函数,没讲,因为意义不大:只会返回3,没有重复值。


3.set的简单OJ题
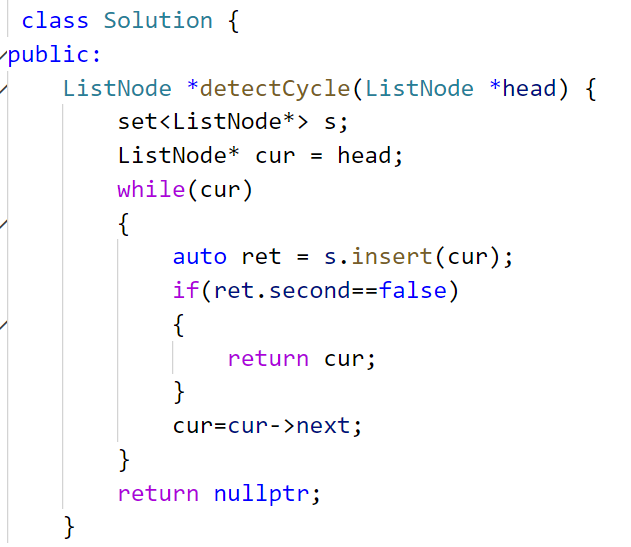
3.1环形链表II
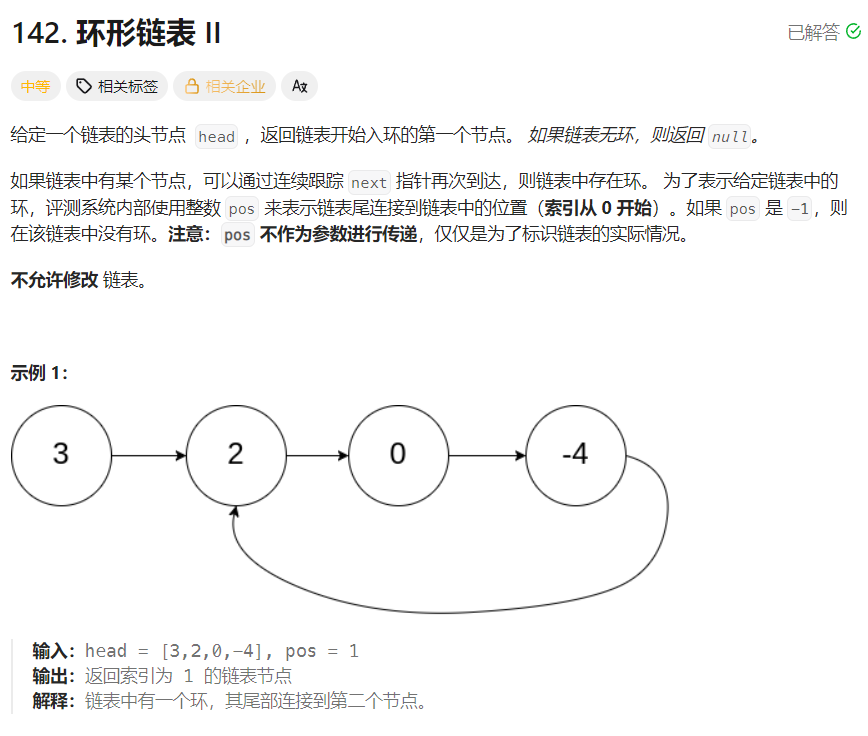
C语言数据结构阶段写过环形链表的题,思路是快慢指针,总会相遇在交叉结点。但是代码写起来比较复杂 。今天学的set可以秒杀 :核心思路在于:set的元素唯一性
思路讲解:把链表节点依次插入进set,第一个插入失败就是环形入口。利用set"不允许相同值插入"的规则 ,一旦出现第一个插入失败(Insert返回pair<iterator , bool>),说明已经插入过,说明此节点是交叉节点,就是环形链表的入口。
也可以利用count的返回值判断是否插入成功,存在(count记数,0未插入,1已经插入)
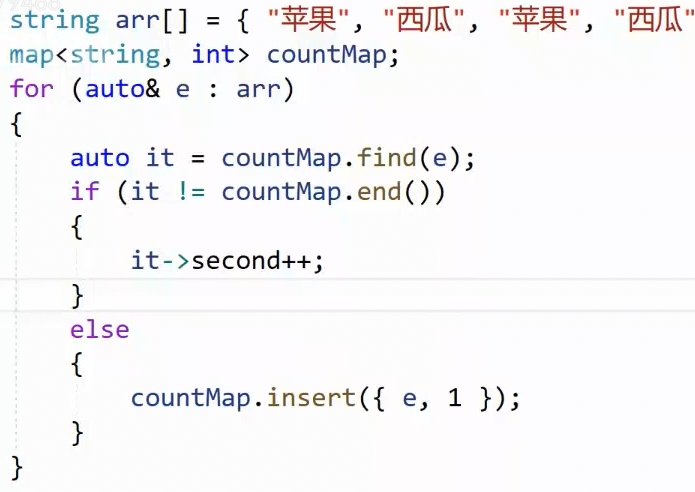
3.2两个数组的交集
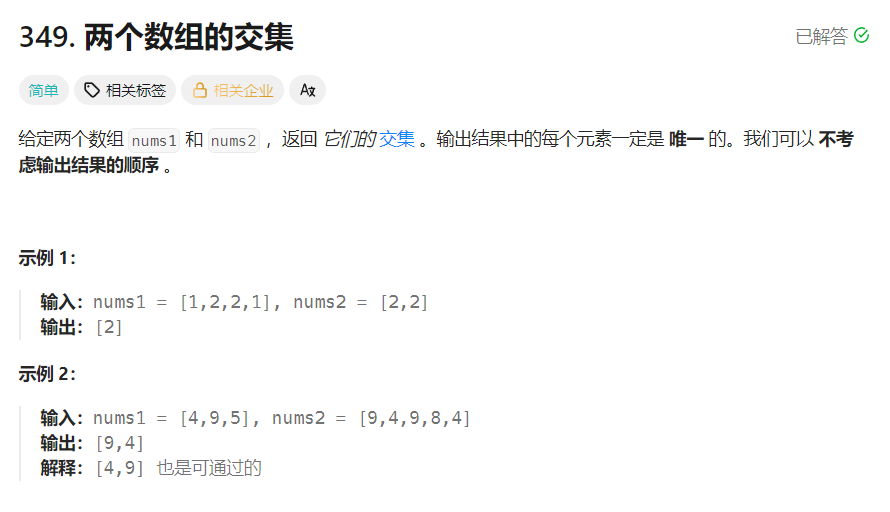
有两个思路:第一个简单粗暴:一个是A存值,B遍历比较查找,在就插入,不在就比较下一个值。可查找完后去重,也可以查找前去重,因为只要求返回一个重复的。缺点是时间复杂度高。
第二个:去重+排序后,两个指针指向A,B起始位置,指向内容小的++,大的不变。相同就插入。思想和归并排序类似,这个方法效率更高。
扩展:
代码如下:
class Solution {
public:
vector<int> intersection(vector<int>& nums1, vector<int>& nums2) {
set<int> s1(nums1.begin(),nums1.end());
set<int> s2(nums2.begin(),nums2.end());
vector<int> ret;
auto it1 = s1.begin();
auto it2 = s2.begin();
while(it1!=s1.end() && it2!=s2.end())
{
if(*it1<*it2)
{
*it1++;
}
else if(*it1>*it2)
{
*it2++;
}
else
{
ret.push_back(*it1);
*it1++;*it2++;
}
}
return ret;
}
};4.map系列的使用
map,地图,也有映射 的意思。前面说了,set的底层存储数据是key,而map是key/value(键值对)。下面介绍一下它的使用:
4.1map系列的简单介绍,声明和pair类型
map系列也有map和multimap,头文件是<map. 先了解map。map系列的底层是红黑树。
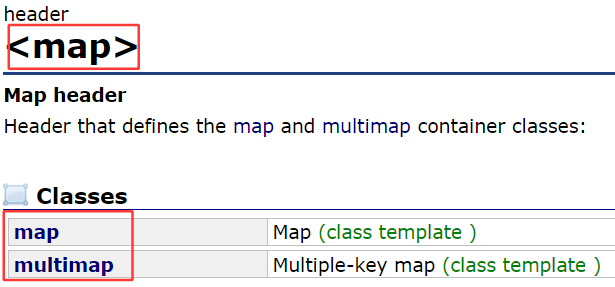
4.1.1map声明
这是map的声明,参数Key就是底层map的关键字类型,T是map底层value类型。同样,map后面两个参数也基本不需要传。由于底层是红黑树实现,增删查改的效率就是O(log N).
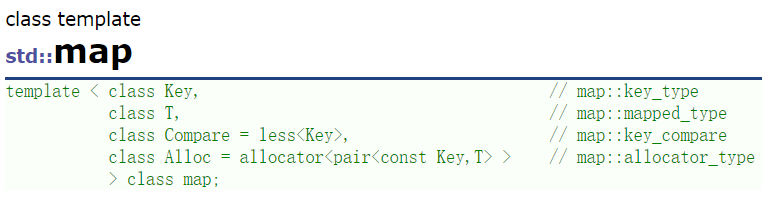
4.1.2map的底层数据存储结构:pair类型
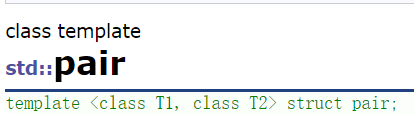
pair是一个标准库提供的:结构体模板,里面存储两个数据。红黑树底层也是用pair<Key,Value>存储键值对数据。下面是它的常用构造:

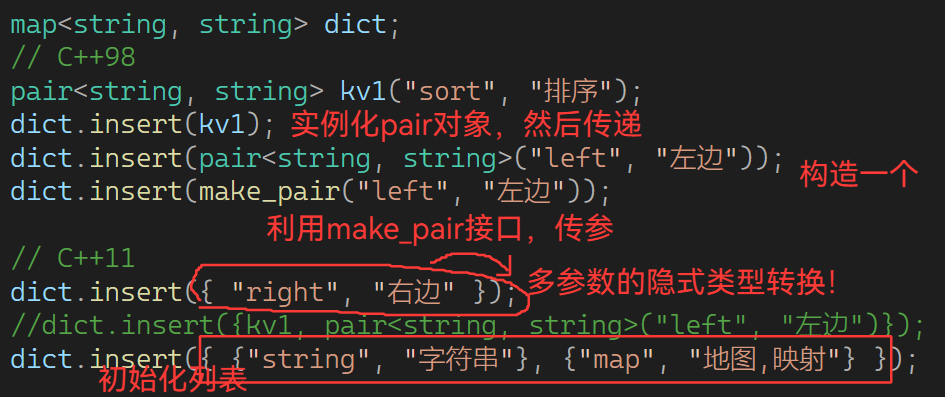
标准库还提供了一个接口,方面传pair对象:

4.1.3pair类型使用,如图
4.2map的构造和迭代器及其遍历方式
构造
无参默认构造,迭代器区间构造,拷贝构造,initializer_list构造:


迭代器
迭代器支持正向反向。

迭代器遍历
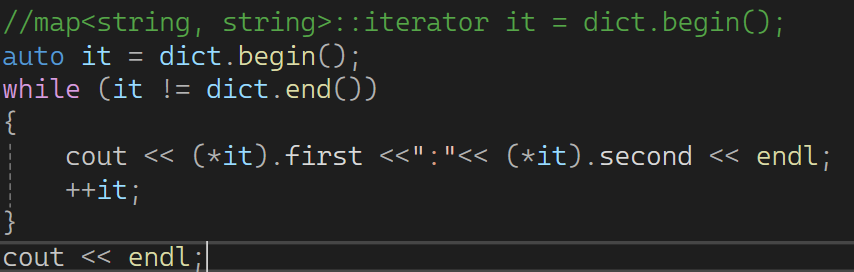
**一般不建议这样遍历(上面)。因为迭代器重载了箭头->:**实际上是这样的:两个 -> ,优化为一个 -> ,这部分之前的容器中也有说明。迭代器的箭头重载,在map中尤其用得多。

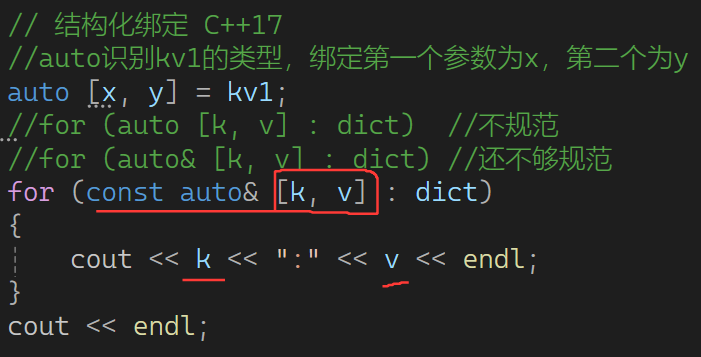
范围for遍历 与 C++17新增:结构化绑定
范围for其实就是利用迭代器,e接收了 *it,所以可以直接用e.first,e.second方式调用获取pair键值对。下面:

C++17新增了一个新语法,让map遍历键值对更方便快捷 :结构化绑定
4.3map的增删查
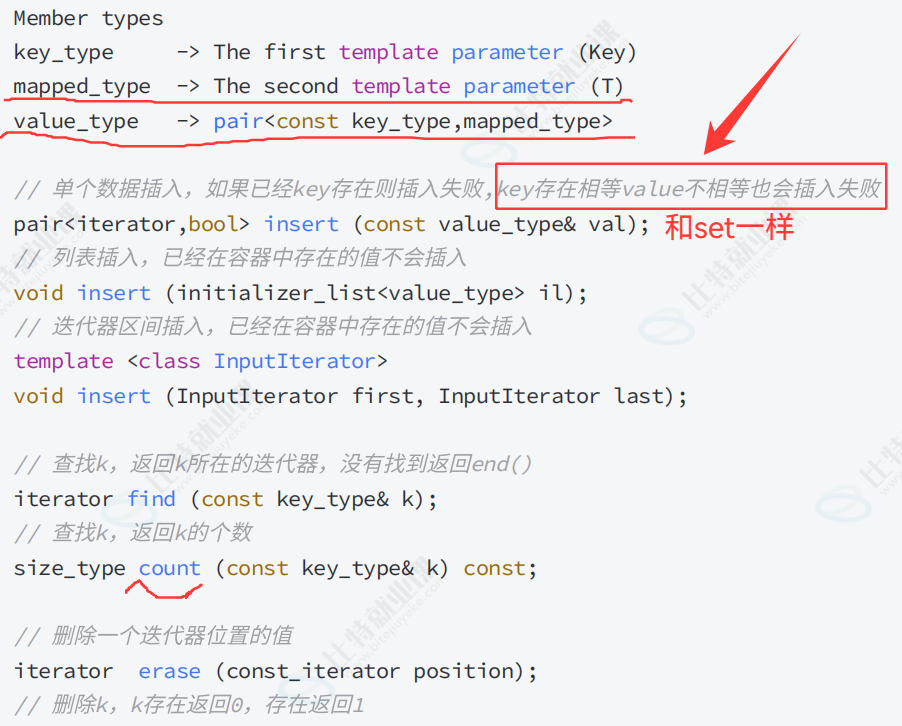


insert
借用上图。insert 使用没区别,就是注意pair的传对象方式 :
注意这个:

find 和 erase,count
这几个用法还是和之前一样。
find:找到返回迭代器位置,失败返回end().
count:map中是查找是否存在,multimap允许数据冗余,可用于统计个数。
erase:删除迭代器位置,返回删除的下一个迭代器位置,避免迭代器失效。
删除k元素,返回0或1,。 删除一段区间的值,传迭代器区间
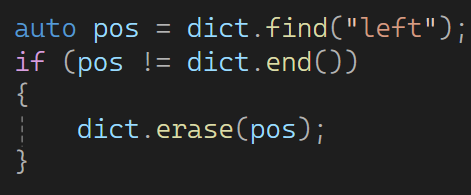
4.4 operator ------修改value
我们可以通过查找+遍历+value充当count 来实现统计个数 。这样比较麻烦。下面介绍一下operator
这个方括号的玩法,与我们之前所熟悉的完全不同。这里传的是Key,返回的是Value
这说明什么?我们可以直接修改它的返回值,来修改Value:
看吧,很方便。
但它远不止于此**:map 的 operator 不仅支持修改Value,还支持插入数据,查找数据。所以它是一个多功能复合接口**。
所以如果水果第一次出现,operator 还能新插入一个数据。
为什么会这样?我们来看看它的底层:
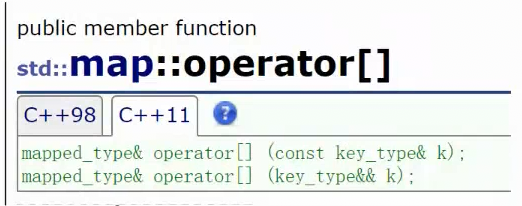
operator 的底层
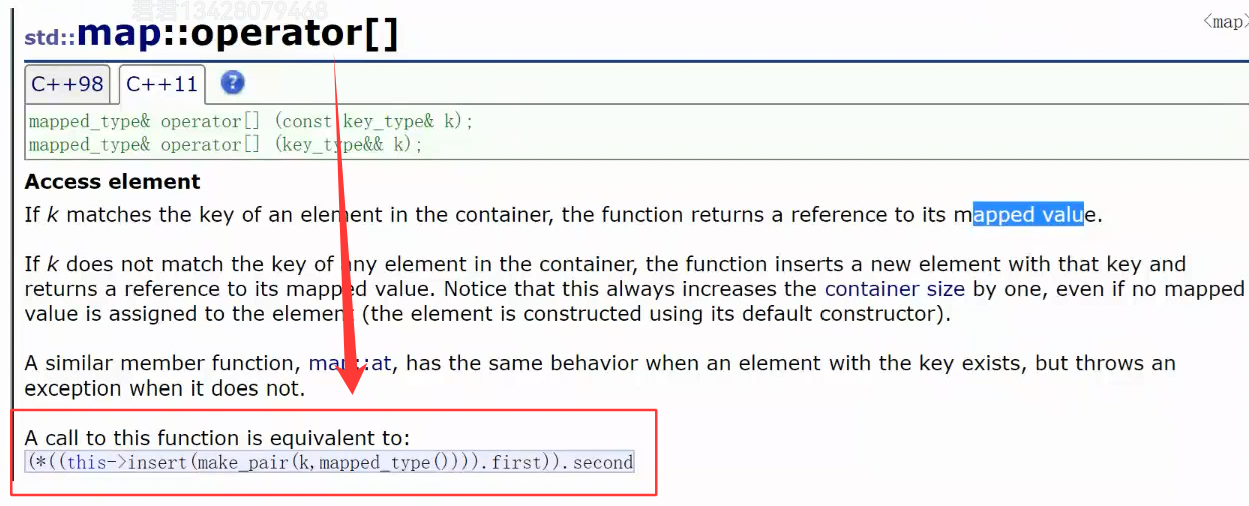

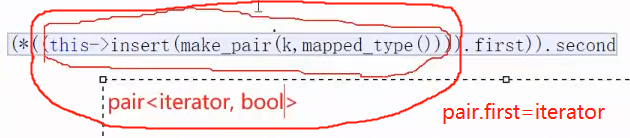
operator ,等价于这行代码,我们仔细分析一下这个:
它最里面一层是这样的:this指针调用insert,insert通过make_pair构造了一个k为key,value为:mapped_type()匿名对象的pair。mapped_type就 value,value的类型是int,所以这里的匿名对象值就是0. this调用insert插入这个键值对
然后返回pair<iterator,bool>:
插入成功:iterator就是新插入位置,bool为1.
插入失败:iterator就是已存在位置,bool为0.
再外一层,就是利用返回值的pair,调用first,获取迭代器位置
再外一层,就是调用这个迭代器。
最后一层:(*iterator).second ,获取插入成功或失败Key位置的Value值。




operator 的使用
既然了解了这个多功能复合接口,那该怎么使用?下面给出样例:

operator 相似的接口:at

5.multimap
multimap允许数据冗余,遍历和find是查找中序的第一个。

5.1multimap没有operator
有多个Key重复,无法确定要哪个value
5.2multimap,map的OJ题
5.2.1随机链表的复制
这题之前学链表也做过,难度很高。
深拷贝一个链表,很简单。难的是随机指针(无法直接遍历,因为链表值可以重复,很麻烦)下面回顾一下之前的思路
我们回顾一下之前的思路:间隔插入 。将深拷贝的结点间隔插入在每个节点之间:
现在学习一下map的思路:map可以让两个值关联,存储起来,并且进行查找修改。那就很好办了,把 原节点和复制节点关联起来。先深拷贝原链表,然后利用map的关联关系,获取原结点random的指向,然后修改copy链表的指向。
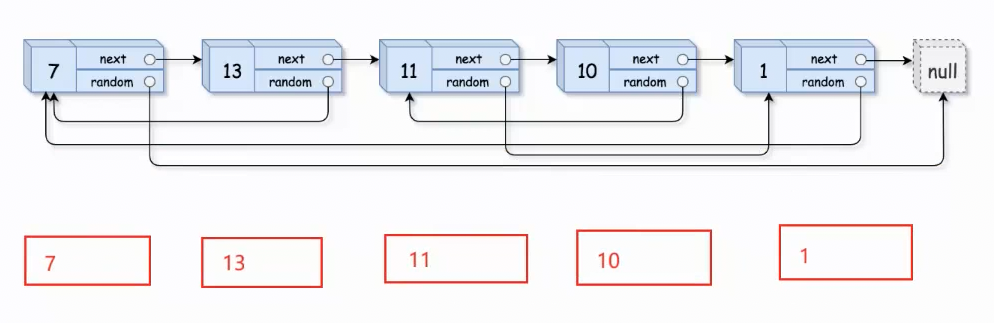

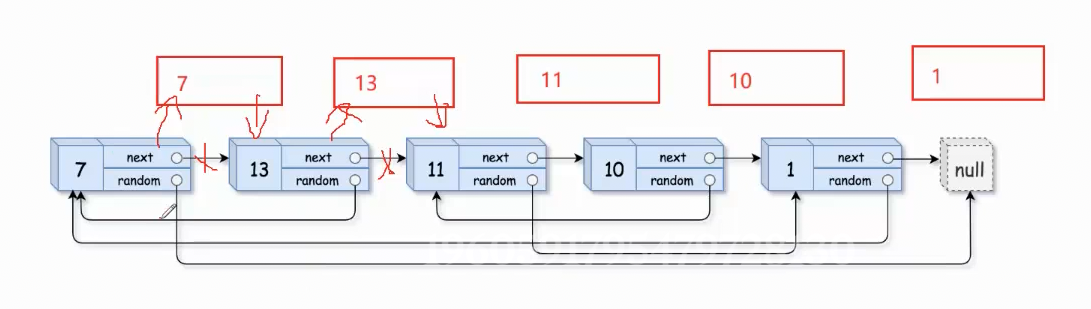
class Solution {
public:
Node* copyRandomList(Node* head) {
map<Node*,Node*> NodeMap;
Node* copyhead = nullptr,*copytail = nullptr;
Node* cur = head;
//深拷贝原结点
while(cur)
{
Node* copy = new Node(cur->val);
if(copytail==nullptr)
{
copyhead = copytail = copy;
}
else
{
copytail->next=copy;
copytail=copy; //更新尾结点
} //插入原节点与复制节点
NodeMap.insert({cur,copy});
cur=cur->next; //更新cur
}
cur = head;
Node* copy = copyhead;
while(cur)
{
if(cur->random==nullptr)
{
copy->random=nullptr;
}
else
{
copy->random=NodeMap[cur->random];
}
cur=cur->next;
copy=copy->next;
}
return copyhead;
}
};5.2.2前K个高频单词

思路:可以用大堆,控制比较逻辑降序,不断取栈顶出栈顶,K次。
还可以用map,统计次数,控制比较逻辑降序,然后取前K个。
1.map
class Solution {
public:
struct KV
{
//仿函数,控制比较逻辑
bool operator()(const pair<string,int>& kv1,const pair<string,int>& kv2)
{
return kv1.second > kv2.second;
}
};
vector<string> topKFrequent(vector<string>& words, int k)
{
//思路:map存储起来,然后用稳定排序降序,获取前K个。
map<string,int> CountMap;
for(const auto& s : words)
{
CountMap[s]++;
}
vector<pair<string,int>> v(CountMap.begin(),CountMap.end());
//稳定排序,保证字典序大小排序也正确,用sort会出错:方法2是:
仿函数内添加控制字典序大小排序。(当次数相等时)
stable_sort(v.begin(),v.end(),KV());
vector<string> ret;
for(int i=0;i<k;i++)
{
ret.push_back(v[i].first);
}
return ret;
}
};2.大堆 priority_queue
class Solution {
public:
struct KV
{
bool operator()(const pair<string,int>& kv1,const pair<string,int>& kv2)
{ //仿函数自己控制逻辑:小于是大于逻辑,所以全部符号都得反过来
return kv1.second<kv2.second||(kv1.second==kv2.second)&&kv1.first>kv2.first;
}
};
vector<string> topKFrequent(vector<string>& words, int k) {
map<string,int> CountMap;
for(const auto& e : words)
{
CountMap[e]++;
}
//建堆,控制比较逻辑
priority_queue<pair<string,int>,vector<pair<string,int>>,KV> pq(CountMap.begin(),CountMap.end());
vector<string> ret;
for(int i=0;i<k;i++)
{
ret.push_back(pq.top().first);
pq.pop();
}
return ret;
}
};set和map的解析就到这了,感谢大家阅读