程翠、孙挺、梁素银、高庭荃、张泽伦、刘嘉轩、王雪晴、周常达、刘鸿恩、林曼慧、张越、张玉波、刘毅、余殿海、马艳军
PaddlePaddle 团队,百度公司
官方网站:https://www.paddleocr.com
源代码:https://github.com/PaddlePaddle/PaddleOCR
模型:https://huggingface.co/PaddlePaddle
摘要
我们推出了PaddleOCR-VL-1.5,该升级模型在OmniDocBench v1.5上达到了94.5%的最新最高水平(SOTA)准确率。为了严格评估模型对真实世界物理畸变(包括扫描、倾斜、弯曲、屏幕翻拍和光照变化)的鲁棒性,我们提出了Real5-OmniDocBench基准测试。实验结果表明,该增强模型在新构建的基准测试上获得了SOTA性能。此外,我们通过融入印章识别和文本定位任务扩展了模型的能力,同时保持了0.9B参数的超紧凑VLM架构与高效率。
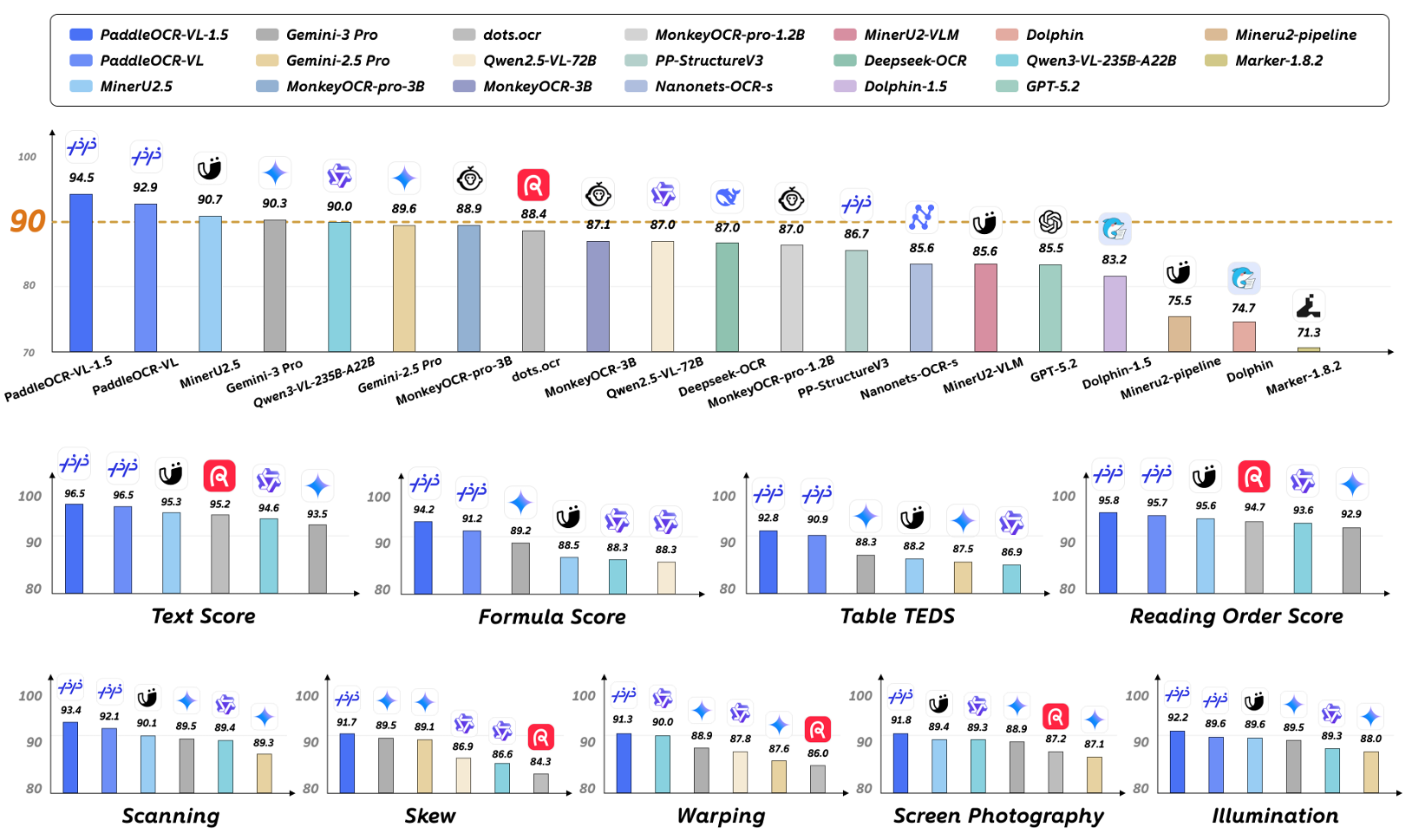
图 1 | PaddleOCR-VL-1.5在OmniDocBench v1.5和Real5-OmniDocBench上的性能。
目录
1 引言 3
2 PaddleOCR-VL-1.5 4
2.1 架构 4
2.2 训练方案 6
3 数据集 9
3.1 版面分析 9
3.2 PaddleOCR-VL-1.5-0.9B 9
4 评估 11
4.1 文档解析 11
4.2 新能力 14
4.3 推理性能 14
5 结论 15
A PaddleOCR-VL-1.5与1.0版本模型的比较 19
B Real5-OmniDocBench基准测试细节 20
C 支持的语言 23
D 不同硬件配置下的推理性能 24
E 真实场景样本 25
E.1 真实场景文档解析 26
E.2 版面分析 31
E.3 文本识别 36
E.4 表格识别 39
E.5 公式识别 42
E.6 印章识别 43
E.7 文本定位 46
1. 引言
作为人类知识的主要载体,文档在数量和复杂性上呈指数级增长,这使得文档解析技术成为人工智能时代的关键技术。文档解析的终极目标 1 , 2 , 3 , 4 1, 2, 3, 4 1,2,3,4超越了单纯的文本识别;它旨在重建文档的深层结构和语义版面。通过精确区分文本块、解码复杂的公式和表格,并推断逻辑阅读顺序,高级解析为大型语言模型(LLMs) 5 , 6 , 7 5, 6, 7 5,6,7奠定了基础。至关重要的是,这种能力使检索增强生成(RAG)系统 8 8 8能够获取高保真知识,从而增强其在下游应用中的可靠性。
自2025年10月以来,该领域创新激增,涌现了多个重要的文档解析解决方案,推动了文档智能的边界。值得注意的是,PaddleOCR-VL 9 9 9建立了一个高性能基线,仅用9亿参数就超越了同时代的SOTA指标,并展示了强大的多场景泛化能力。同时,DeepSeek-OCR 10 10 10利用光学2D映射方法实现了高比例视觉到文本的压缩,提供了强大的端到端解析能力。MonkeyOCR v1.5 11 11 11进一步增强了三阶段解析框架,而HunyuanOCR 12 12 12通过支持翻译和提取的统一架构扩展了专业OCR能力。
尽管取得了这些进展,一个关键差距仍然存在:大多数现有模型主要针对"数字原生"或干净扫描的文档进行优化。涉及极端物理畸变的真实场景------例如严重的倾斜、页面的非刚性弯曲、屏幕捕捉的摩尔纹以及不稳定的光照------仍然是重大障碍,即使是SOTA解决方案也尚未完全克服。
为了弥补这一差距,我们推出了PaddleOCR-VL-1.5,这是一个高性能、资源高效的文档解析解决方案,显著提升了通用精度和真实世界的鲁棒性。基于经过验证的0.9B超紧凑架构,PaddleOCR-VL-1.5引入了几个关键的改进:
-
首先,我们将版面引擎升级到PP-DocLayoutV3。与之前的版面分析方法(例如Dolphin 3, MinerU2.5 2,甚至PP-DocLayoutV2 13)不同,PP-DocLayoutV3专门为处理非平面文档图像设计。它可以直接预测版面元素的多点边界框(而非标准的两点框),并在单次前向传播中确定倾斜和弯曲表面上的逻辑阅读顺序,显著减少了级联错误。
-
其次,我们扩展了模型的核心能力。在保持高效的NaViT风格动态分辨率编码器和ERNIE-4.5-0.3B 5 5 5语言主干的同时,我们整合了包括印章识别和文本定位在内的新任务。在文本、表格和公式识别方面的系统优化进一步推动了模型达到了新的性能里程碑。
-
第三,我们构建了Real5-OmniDocBench来评估真实场景下的鲁棒性。认识到缺乏针对物理畸变的基准测试,我们基于OmniDocBench v1.5 14 14 14精心策划了该数据集。它包含五种不同的场景:扫描、弯曲、屏幕翻拍、光照和倾斜。通过保持与原标注的一一对应关系,Real5-OmniDocBench成为了评估模型在实际应用中韧性的严格基准。
全面的基准测试证实,PaddleOCR-VL-1.5建立了新的SOTA标准。在OmniDocBench v1.5基准测试中,我们的模型实现了94.5%的突破性准确率,保持了其官方排名第一的解决方案地位。更重要的是,在新构建的Real5-OmniDocBench上,该模型以92.05%的整体准确率创造了新记录。尽管其紧凑的0.9B规模,它在文档解析任务上显著优于大型通用VLM,如Qwen3-VL-235B 6 6 6和Gemini-3 Pro 15 15 15,突显了其卓越的参数效率。此外,我们的模型将其能力扩展到文本定位和印章识别,在多样化和具有挑战性的基准测试中取得了领先性能。这些结果共同验证了其在复杂、真实场景中的卓越鲁棒性和泛化能力。附录A详细说明了PaddleOCR-VL-1.5与其前代版本相比的具体升级和变化。
2. PaddleOCR-VL-1.5
2.1. 架构
PaddleOCR-VL-1.5引入了一个增强的框架,能够同时处理文档解析和文本定位任务,如图2所示。
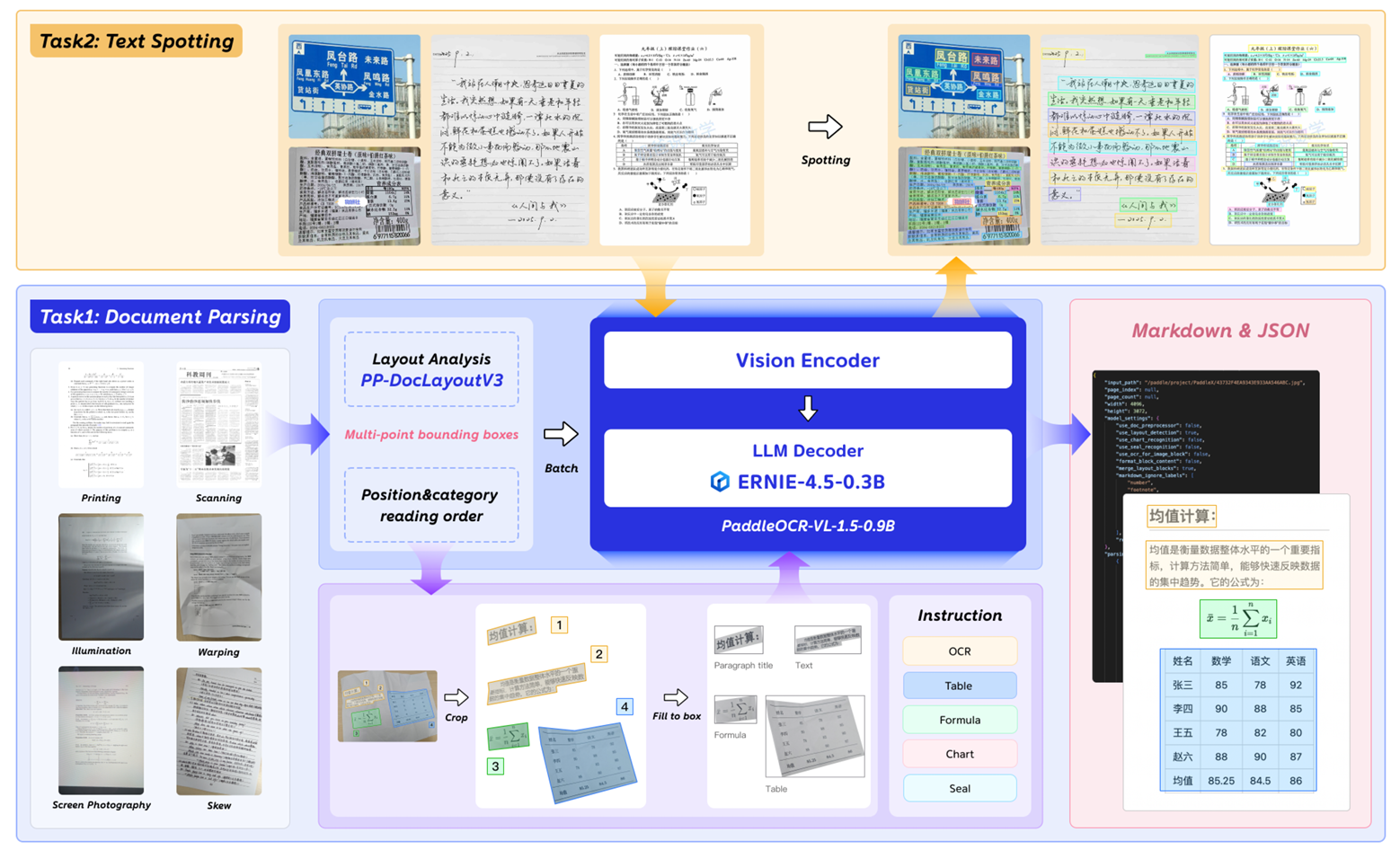
图 2 | PaddleOCR-VL-1.5概述。
对于文档解析任务,PaddleOCR-VL-1.5采用了鲁棒的两阶段框架。在初始阶段,PP-DocLayoutV3执行复杂的版面分析。除了标准的轴对齐检测外,它通过采用多点定位(例如四边形或多边形)专门针对真实世界的复杂性进行了优化。这允许即使在严重的透视倾斜或物理弯曲下,也能精确锚定语义区域的边界,同时建立逻辑阅读顺序。在第二阶段,PaddleOCR-VL-1.5-0.9B模型将这些经过几何校正或局部化的区域作为输入,对多样化的模态(包括文本、复杂表格、数学公式、图表和印章)执行高保真识别。最后,一个轻量级的后处理引擎将这些输出编排成Markdown和JSON等结构化格式,同时提供跨页表格合并和标题层次细化等高级能力。
对于文本定位任务,该框架简化了其工作流程,直接利用PaddleOCR-VL-1.5-0.9B模型进行端到端的文本检测与识别。这种方法支持跨广泛领域的端到端文本检测与识别------从标准文档、身份证件、古籍到无约束的场景,如广告海报、对话截图、标牌和多语种文本。
2.1.1. PP-DocLayoutV3:统一版面分析
为了解决复杂物理畸变(包括倾斜、弯曲和光照变化)的挑战,并克服自回归视觉语言模型(VLMs)固有的高延迟,我们推出了PP-DocLayoutV3。该版本代表了其前代在架构上的显著演进,从标准矩形检测过渡到鲁棒的实例分割框架,同时将阅读顺序预测整合到一个统一的、端到端的Transformer架构中。
基于高效率的RT-DETR目标检测器 16 16 16,PP-DocLayoutV3采用了基于掩码的检测头。这使得模型能够预测版面元素的精确、像素级的掩码,而不是简单的边界框。这种能力对于在非理想场景(如倾斜或弯曲页面)中分离文档组件至关重要,因为传统的轴对齐框经常重叠或捕获过多的背景噪声。
与PP-DocLayoutV2 9 9 9中使用的解耦指针网络不同,PP-DocLayoutV3将阅读顺序预测直接集成到Transformer解码器层中。通过将检测、分割和排序合并到一个单一的以视觉为中心的模型中,PP-DocLayoutV3消除了冗余的后处理和分离特征提取步骤的需求。
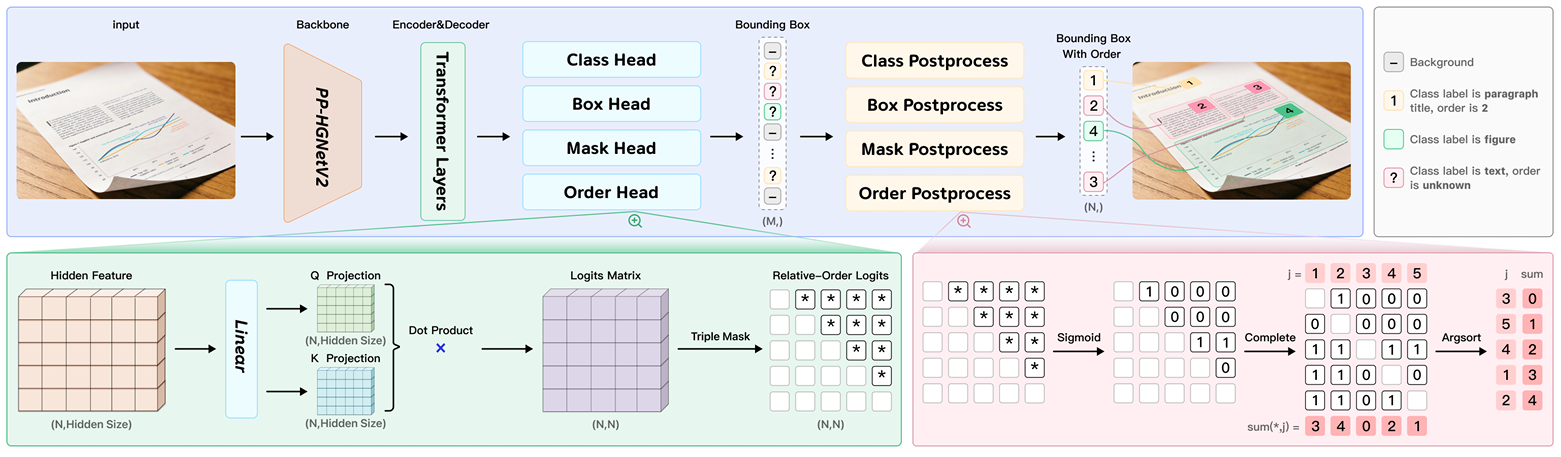
图 3 | PP-DocLayoutV3的统一架构,具有用于实例分割和关系阅读顺序预测的并行头部。
PP-DocLayoutV3的核心架构创新是将阅读顺序预测直接集成到Transformer解码器中。具体来说,我们的模型扩展了RT-DETR框架,以同时优化几何定位和逻辑排序。遵循基于查询的范式,解码器迭代地细化N个对象查询 Q = { q i } i = 1 N ∈ R N × d Q = \{q_{i}\}_{i=1}^{N} \in R^{N \times d} Q={qi}i=1N∈RN×d。然后,阅读顺序通过一个全局指针机制从最终解码器层的细化查询嵌入中推导出来。
我们将细化查询投影到一个共享的关系空间中,以计算成对的前后顺序得分 S i , j S_{i,j} Si,j:
S i , j = f ( q i , q j ) − f ( q j , q i ) d h , w h e r e f ( q i , q j ) = ( W q q i ) ⊤ ( W k q j ) S_{i,j}=\frac{f(q_{i},q_{j})-f(q_{j},q_{i})}{\sqrt{d_{h}}},\quad\mathrm{w h e r e}f(q_{i},q_{j})=(W_{q}q_{i})^{\top}(W_{k}q_{j}) Si,j=dh f(qi,qj)−f(qj,qi),wheref(qi,qj)=(Wqqi)⊤(Wkqj)
其中 W q , W k ∈ R d × d h W_{q}, W_{k} \in R^{d \times d_{h}} Wq,Wk∈Rd×dh是可学习的投影矩阵, d h d_{h} dh表示隐藏维度。生成的关系矩阵 S ∈ R N × N S \in R^{N \times N} S∈RN×N被约束为反对称的,使得 S i , j = − S j , i S_{i,j} = -S_{j,i} Si,j=−Sj,i,其中 S i , j > 0 S_{i,j} > 0 Si,j>0意味着元素i在元素j之前。
在推理过程中,为了从这些成对关系中推导出全局一致的序列,我们实现了一种基于投票的排序策略。我们首先对关系矩阵S应用sigmoid函数 σ ( ⋅ ) \sigma(\cdot) σ(⋅)并掩蔽对角线元素。每个元素j的绝对优先票数 V j V_{j} Vj通过聚合其他元素在其之前的概率来计算:
V j = ∑ i = 1 , i ≠ j N σ ( S i , j ) . V_{j}=\sum_{i=1,i\neq j}^{N}\sigma(S_{i,j}). Vj=i=1,i=j∑Nσ(Si,j).
最终的阅读顺序通过按元素的总票数 V j V_{j} Vj升序排序来确定。这种联合优化确保了逻辑序列对细化后的对象特征高度敏感,从而在复杂、多列和非标准文档版面上实现卓越性能。
通过将检测、分割和排序合并到一个单一的以视觉为中心的模型中,PP-DocLayoutV3消除了冗余的后处理和分离特征提取步骤。该模型在一次前向传播中生成完整的文档结构,其中多头系统同时输出分类标签、边界框坐标、像素级分割掩码和逻辑阅读序列。
2.1.2. PaddleOCR-VL-1.5-0.9B:元素级识别与文本定位
PaddleOCR-VL-1.5-0.9B继承了PaddleOCR-VL-0.9B 9 9 9的轻量级架构,集成了原生分辨率视觉编码器 17 17 17、自适应MLP连接器和轻量级ERNIE-4.5-0.3B语言模型 5 5 5。在此次更新中,模型的能力已扩展至包括印章识别和文本定位。因此,该模型现在支持六个核心任务的全面集合:OCR、公式识别、表格识别、图表识别、印章识别和文本定位。
与其前代相比,PaddleOCR-VL-1.5-0.9B在复杂表格和数学公式的识别准确性上表现出显著提升。此外,该模型针对罕见字符、古汉语文本、多语言表格以及文本装饰(如下划线和强调标记)融入了更细粒度的优化。
2.2. 训练方案
以下部分介绍了这两个模块的训练细节:用于版面分析的PP-DocLayoutV3和用于元素识别与文本定位的PaddleOCR-VL-1.5-0.9B。
2.2.1. 版面分析
PP-DocLayoutV3的训练从PP-DocLayoutV2 9 9 9中使用的两阶段解耦过程演变为更复杂的端到端联合优化策略。这种方法允许检测、实例分割和阅读顺序模块共享统一的特征表示,从而实现空间定位和逻辑排序之间更好的对齐。
该模型使用PP-DocLayout_plus-L 13 13 13的预训练权重进行初始化。我们将训练语料库扩展到超过38,000个高质量文档样本。每个样本都经过了严格的人工标注以提供真实值,包括每个版面元素的坐标、类别标签和绝对阅读顺序。
为了实现环境鲁棒性,我们设计了一个专门的畸变感知数据增强流水线。与标准增强不同,该流水线专门模拟移动摄影中发现的复杂物理变形。
我们使用AdamW优化器,权重衰减为0.0001。学习率设置为常数 2 × 10 − 4 2 \times 10^{-4} 2×10−4,以确保集成的全局指针和掩码头的稳定收敛。模型以总批次大小32训练150个周期。
与前一个版本相比,所有组件------包括RT-DETR主干和集成的阅读顺序Transformer------都是同时训练的。这种端到端的监督确保了Transformer解码器中学到的查询能够捕获文档元素的几何边界和拓扑关系。
2.2.2. 元素级识别与文本定位
基于第2.1.2节描述的架构,PaddleOCR-VL-1.5-0.9B引入了使用PaddleFormers 18 18 18的渐进式训练范式,PaddleFormers是基于PaddlePaddle框架 19 19 19构建的高性能LLM和VLM训练工具包。虽然我们保留了先前版本中有效的后适应策略和初始化设置,但训练方法已显著升级,以增强数据规模、任务多样性和模型鲁棒性。这三个阶段的概述如表1所示。
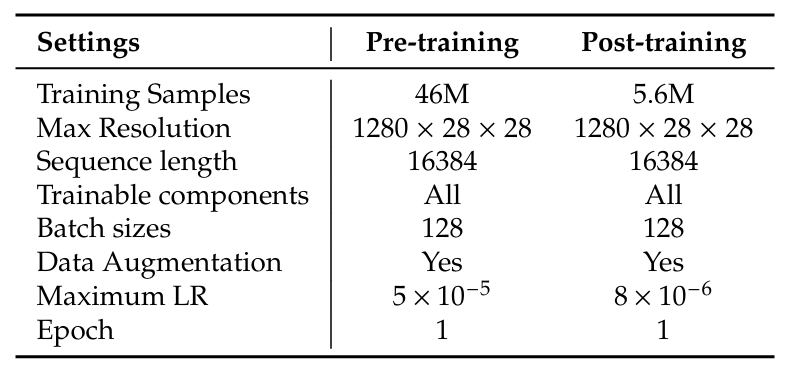
表 1 | PaddleOCR-VL-1.5-0.9B的训练设置。
预训练:增强的视觉-语言对齐。尽管基本目标仍然是使视觉特征与文本语义对齐,但与PaddleOCR-VL-0.9B 9 9 9相比,此阶段的数据量经历了实质性升级,预训练数据集从2900万扩大到4600万图像-文本对。这种扩展代表了数据分布质的飞跃,而非仅仅是量的增加。具体来说,为了增强视觉主干的泛化能力并支持新引入的能力,我们纳入了更广泛的多语言文档和复杂真实场景。此外,我们有意在此对齐阶段注入了与印章识别和文本定位相关的大规模预训练数据。具体而言,定位任务的最大分辨率增加到 2048 × 28 × 28 2048 \times 28 \times 28 2048×28×28像素,使模型能够实现更精确的文本定位和识别。通过在训练流水线早期引入这些任务特定的先验知识,模型建立了一个鲁棒的基础,能够捕获复杂的视觉模式,并有效地支持后续阶段所需的细粒度定位和识别任务。
后训练:具有新能力的指令微调。在此阶段,我们继承了PaddleOCR-VL-0.9B的四个基本指令任务------OCR、表格、公式和图表识别------确保了向后兼容性和在标准文档元素上的高性能。PaddleOCR-VL-1.5-0.9B的关键创新在于增加了两个专门任务:
- 印章识别:我们引入了一个特定的指令来处理官方印章和戳记,应对弯曲文本、模糊图像和背景干扰等挑战。
- 文本定位(带位置的OCR):与仅输出文本内容的标准OCR不同,文本定位任务要求模型在预测文本内容的同时,按照自然阅读顺序预测其精确的空间位置。为了适应真实场景中的复杂布局(例如,旋转文本、常见场景或密集表格),我们采用4点四边形表示而非传统的2点边界框。4点格式使用四个顶点定义一个文本区域:左上(TL)、右上(TR)、右下(BR)和左下(BL)。这种表述在定位倾斜和不规则文本形状时提供了更高的灵活性,这是标准的轴对齐矩形无法紧密包围的。
形式上,对于一个给定的文本实例,目标序列是通过将八个位置标记附加到文本标记来构建的:
Y = T e x t ⊕ < L O C _ x T L > < L O C _ y T L > ... < L O C _ y B L > Y=\mathrm{T e x t}\oplus<\mathrm{L O C\{x}{T L}}><\mathrm{L O C\{y}{T L}}>\ldots<\mathrm{L O C\{y}{B L}}> Y=Text⊕<LOC_xTL><LOC_yTL>...<LOC_yBL>
这里,我们向模型的词汇表中引入一组标记KaTeX parse error: Undefined control sequence: \langleLOC at position 3: \{\̲l̲a̲n̲g̲l̲e̲L̲O̲C̲\_0\rangle,\ldo...来表示归一化的坐标。与将坐标视为纯数字文本不同,这些专用的特殊标记允许模型学习空间信息的特定嵌入,并防止分词碎片化。
例如,识别出的单词"DREAM"实例表示为:
DREAM <LOC_253> <LOC_286> <LOC_346> <LOC_298> <LOC_345> <LOC_339> <LOC_252> <LOC_330>
这种统一的表示使得模型能够在单次生成过程中执行端到端的识别和细粒度定位。
为了增强泛化能力并统一不同的标签风格,我们引入了一个利用组相对策略优化(GRPO) 20 ^{20} 20的强化学习阶段。通过执行并行推演并在每个组内计算相对优势,GRPO促进了稳健的策略更新并缓解了风格不一致性。这个过程得到了一个动态数据筛选协议的支持,该协议优先考虑具有高奖励潜力和熵不确定性的挑战性样本,确保模型专注于非平凡的、高价值的学习案例。
3. 数据集
3.1. 版面分析
为了确保模型在不同真实世界文档场景下的鲁棒性能,我们策划了一个内部版面分析数据集。数据源涵盖38k张跨多个领域的文档图像,包括学术论文、教科书、市场分析、财务报告、幻灯片、报纸、补充教材、试卷以及各种发票和收据。该数据集对25个不同的组件类别进行了细致的人工标注:段落标题、图像、文本、数字、摘要、内容、图标题、显示公式、表格、参考文献、文档标题、脚注、页眉、算法、页眉、印章、图表、公式编号、旁注文本、参考文献内容、页眉图像、页眉图像、行内公式、垂直文本和视觉脚注。所有文档都经过人工标注,包含元素级边界及其对应的阅读顺序,从而为版面元素检测和阅读顺序恢复提供有效的训练和评估。这种高质量的真实标注确保了模型能够准确地重建复杂文档的空间结构和逻辑流程。
数据策划过程结合了特定的数据挖掘策略,旨在扩展数据集多样性并识别困难案例以提高模型鲁棒性。此工作流程始于对广泛内部数据池应用基于聚类的采样,利用视觉特征确保代表性分布并最小化冗余。随后,使用PP-DocLayoutV2 9 9 9执行困难案例挖掘流水线进行双阈值推理。在高置信度阈值和低置信度阈值之间检测密度存在显著差异的样本被归类为不稳定案例。这种方法有助于系统性地发现非常规布局结构------包括漫画、CAD图纸和高宽比截图------这些结构与标准文档格式不同。这些实例通过人机交互流程进一步细化。将这些多样化的场景整合到数据集中,拓宽了模型的特征表征范围,并增强了其在复杂真实世界文档领域中的适应能力。
3.2. PaddleOCR-VL-1.5-0.9B
PaddleOCR-VL-1.5-0.9B的数据构建策略由两个核心目标驱动:增强模型在挑战性样本上的鲁棒性和扩展支持能力的广度。因此,我们的数据准备流程分为两个不同的部分:(1)困难样本挖掘(第3.2.1节),专注于识别和加权高不确定性样本以细化模型的决策边界;(2)新能力数据构建(第3.2.2节),涉及策划专门的数据集以解锁新技能,如文本定位、印章识别和高级多语言支持。
3.2.1. 数据选择策略:不确定性感知的聚类采样
为了最大化指令微调阶段(阶段2)的效率,我们提出了一种旨在平衡视觉多样性和样本难度的数据策划策略。我们采用不确定性感知聚类采样(UACS)机制,而非均匀随机采样。这种方法确保了训练数据覆盖广泛的视觉场景,同时将更多的训练预算分配给模型表现出高度不确定性的"困难"案例。
-
视觉特征聚类。首先,为了保证六个任务(OCR、表格、公式、图表、印章和定位)之间视觉布局的多样性,我们利用CLIP 21 21 21视觉编码器为所有候选图像提取高维语义嵌入。对于每个任务,我们应用K-Means聚类将数据集D划分为K个不同的视觉簇 { C 1 , C 2 , ... , C K } \{C_{1}, C_{2}, \ldots, C_{K}\} {C1,C2,...,CK}。此步骤将具有相似视觉结构(例如,实线表格与无线表格)的样本分组在一起。
-
不确定性估计。对于每个簇 C i C_{i} Ci,我们通过测量模型的预测不确定性来估计其难度。具体来说,我们从 C i C_{i} Ci中随机抽取一个图像子集,并使用来自阶段1的预训练模型通过随机解码进行多次推理。我们基于生成输出的分歧来计算一个不确定性分数 S i S_{i} Si。较高的 S i S_{i} Si表示模型对于该簇中的样本存在不一致或缺乏信心。
-
加权采样计划。基于不确定性分数,我们制定一个采样计划来确定要从每个簇 C i C_{i} Ci中抽取的样本数量 N i N_{i} Ni。受困难样本挖掘原则的启发,我们采用多项式加权方案来放大对更困难簇的关注。具体来说,簇 C i C_{i} Ci分配的样本数 N i N_{i} Ni由下式决定:
N i = min ( ⌊ ( S i + α ) β ∑ j = 1 K ( S j + α ) β × N t o t a l ⌋ , ∣ C i ∣ ) N_{i}=\min\left(\left\lfloor\frac{(S_{i}+\alpha)^{\beta}}{\sum_{j=1}^{K}(S_{j}+\alpha)^{\beta}}\times N_{total}\right\rfloor,\left|C_{i}\right|\right) Ni=min(⌊∑j=1K(Sj+α)β(Si+α)β×Ntotal⌋,∣Ci∣)
其中 S i S_{i} Si是簇 C i C_{i} Ci的平均不确定性分数, ∣ C i ∣ |C_{i}| ∣Ci∣表示该簇中可用样本的总数。参数 α \alpha α和 β \beta β分别是平滑因子和幂因子(根据经验观察设置为 α = 1.0 , β = 2.0 \alpha = 1.0, \beta = 2.0 α=1.0,β=2.0)。 N t o t a l N_{total} Ntotal代表总采样预算。这种策略允许我们动态上采样复杂场景(例如,变形的印章、密集表格),同时为简单案例保持代表性基线。
如前一节所述,我们采用不确定性感知聚类采样(UACS)策略,基于视觉聚类和推理方差来选择最有效的训练样本。
3.2.2. 新能力的数据构建
除了数据质量控制外,我们还通过整合涵盖更广泛任务、语言和文档类型的数据来扩展VLM的能力。此扩展聚焦于以下关键维度:定位、专用文本(印章)、OCR增强以及复杂表格、公式和图表。
定位:我们收集了一个大规模且多样化的图像集合,覆盖了广泛的真实场景,例如金融研究报告、表格文档、手写材料、古典文本以及其他复杂文档和自然场景图像。在标注过程中,我们联合使用PP-OCRv5 22 ^{22} 22生成初始识别结果,然后采用基于IoU的交叉过滤策略剔除低质量和不一致的样本,同时对一部分标签模糊或不准确的样本,进一步利用包括PaddleOCR-VL 9 ^{9} 9和Qwen3-VL 6 ^{6} 6在内的多模态模型进行标签精炼,从而大幅提高了数据集的整体标注质量和鲁棒性。
印章:我们结合了合同、发票和纪念印章的合成图像和真实世界图像,构建了一个高质量的数据集。标签使用Qwen3-VL 6 6 6生成,并通过基于微调的重新标注过程进行精炼。具有挑战性的案例经过人工校正,以确保最终的标注准确性和鲁棒性。
OCR:我们通过提升数据集的精度和扩展功能范围,显著增强了模型的能力。这包括系统地修正公式表示和换行逻辑,同时扩展对教育专用标记(如强调点和下划线)的支持以捕获教学语义。此外,孟加拉语和中国藏文的整合拓宽了模型的语言多样性,确保其在不同的书写系统和教育环境中具有鲁棒的性能。
公式:公式数据集整合了模拟的CV伪影,例如高斯光照和谐波摩尔纹,以模拟物理条件,如扫描、弯曲、屏幕捕捉和几何倾斜。这些样本涵盖了广泛的环境变量,包括真实场景中遇到的光线波动和复杂的文档畸变。
表格:表格数据已扩展至覆盖广泛的场景,包括财务报告、学术论文和复杂的工业表格。整合了多种结构,例如登记表和目录表。重点放在密集表格环境中精确识别单元格级公式和多语言内容。这些进步确保了即使处理复杂的单元格结构和专业符号,也能高保真地转换为结构化格式。
4. 评估
为了全面评估PaddleOCR-VL-1.5的有效性,我们在文档解析基准OmniDocBench v1.5及其衍生的真实世界数据集Real5OmniDocBench上进行了评估。此外,我们通过纳入文本定位和印章识别任务扩展了评估范围,以更全面地分析模型在实际和复杂场景中的性能。
4.1. 文档解析
本节详细介绍了使用以下两个基准测试对端到端文档解析能力进行的评估,旨在衡量其在真实世界文档场景中的整体性能。
OmniDocBench v1.5 为了全面评估文档解析能力,我们在OmniDocBench v1.5 2 2 2基准测试上进行了广泛的实验。它是版本v1.0的扩展,新增了374份文档,总计1,355页文档。它的中英文数据分布更加平衡,并更丰富地包含了公式和其他元素。与版本v1.0相比,评估方法已更新。虽然文本和阅读顺序仍使用编辑距离进行评估,表格使用基于树编辑距离的相似度(TEDS)进行评估,但公式现在使用字符检测匹配(CDM) 23 23 23方法进行评估。该指标为预测公式的正确性提供了更客观和鲁棒的评估。整体指标是文本、公式和表格指标的加权组合。
表2表明,PaddleOCR-VL-1.5在所有关键指标上都实现了SOTA性能,持续优于现有的流水线工具、通用VLM和专门的文档解析模型。值得注意的是,与PaddleOCR-VL相比,PaddleOCR-VL-1.5表现出显著的性能飞跃,将整体得分从92.86%提高到顶级排名94.50%。具体而言,它在CDM分数、表格TEDS和阅读顺序分数上分别实现了2.99%、1.87%和0.1%的提升。此外,我们的模型在所有子任务中都建立了新的SOTA结果,包括更低的文本编辑距离(0.035),改进的公式CDM分数(94.21%),以及在表格TEDS(92.76%)和表格TEDS-S(95.79%)上的领先分数。这些改进,特别是在保持0.042的高阅读排序分数方面,强调了模型在文本识别、公式提取和复杂表格结构分析方面增强的精度。
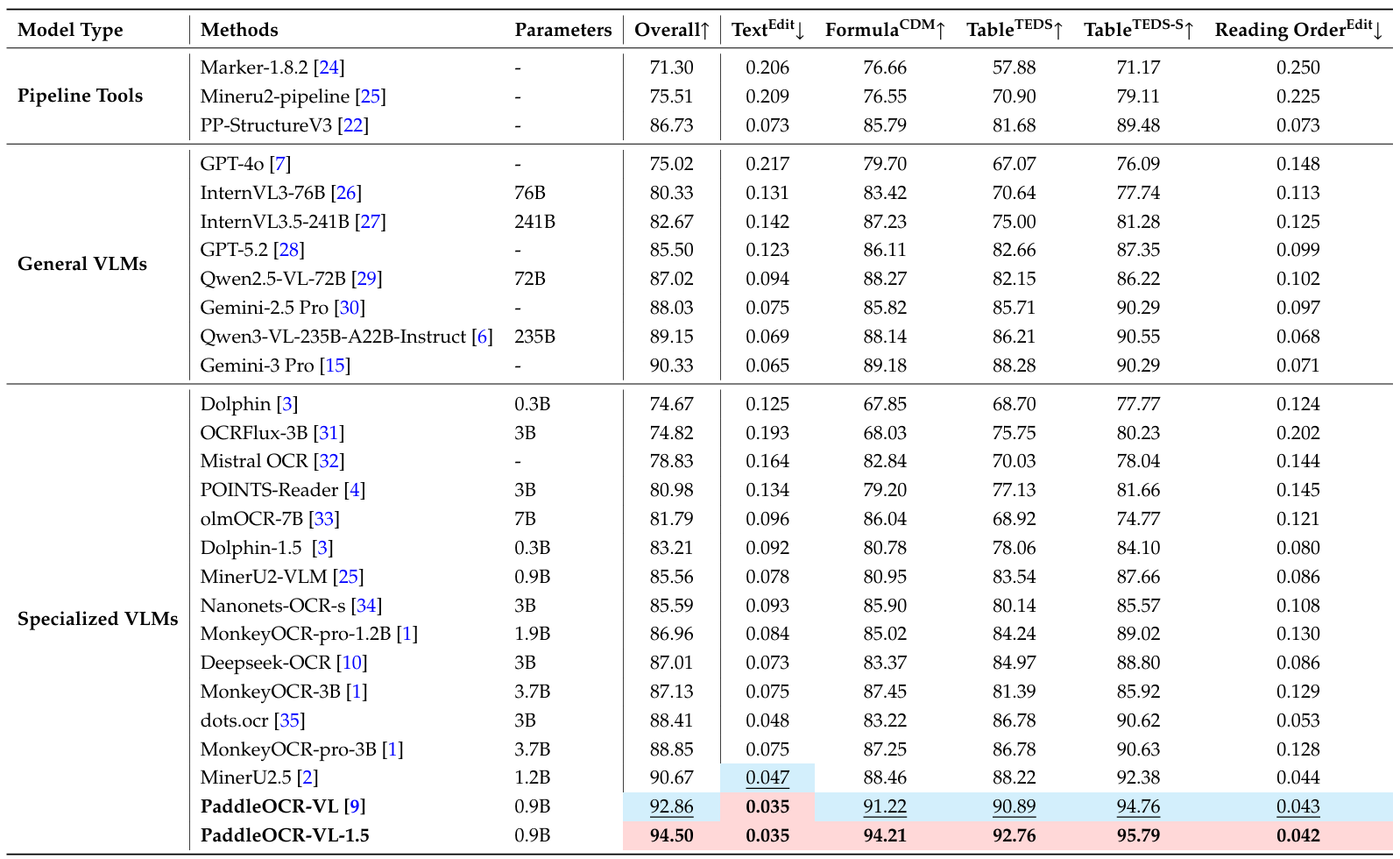
表 2 | OmniDocBench v1.5上的综合评估。性能指标引自官方排行榜 14,除了Gemini-3 Pro、GPT-5.2、Qwen3-VL-235B-A22B-Instruct和我们模型的指标是我们独立评估的。
Real5-OmniDocBench Real5-OmniDocBench 1 ^{1} 1是一个面向真实场景的全新基准测试,我们基于OmniDocBench v1.5数据集构建。该数据集包含五个不同的场景:扫描、弯曲、屏幕翻拍、光照和倾斜。除了扫描类别外,所有图像都是通过手持移动设备手动获取的,以密切模拟真实世界条件。每个子集与原始OmniDocBench保持一一对应关系,严格遵循其真实标注和评估协议。鉴于其经验和真实性,该数据集是评估文档解析模型在实际应用中鲁棒性的严格基准。图4展示了所提出数据集中代表性样本的可视化结果。
如表3所示,PaddleOCR-VL-1.5在所有评估场景中都表现出一致的优越性,以92.05%的整体准确率创下了新的SOTA记录。尽管其参数规模仅为0.9B,但该模型在文档解析任务上显著优于Qwen3-VL-235B和Gemini-3 Pro等大型通用VLM,突显了其在文档中心任务中卓越的参数效率。值得注意的是,在极具挑战性的倾斜类别中,PaddleOCR-VL-1.5达到了91.66%的准确率,相比其前代版本有14.19%的绝对提升。这一显著的性能飞跃突显了其对抗极端几何畸变的卓越鲁棒性,并验证了其在无约束环境中进行复杂文档解析的可靠性。关于文本、公式、表格和阅读顺序等子项的详细比较可在附录B中找到。

图 4 | Real5-OmniDocBench样本示例。
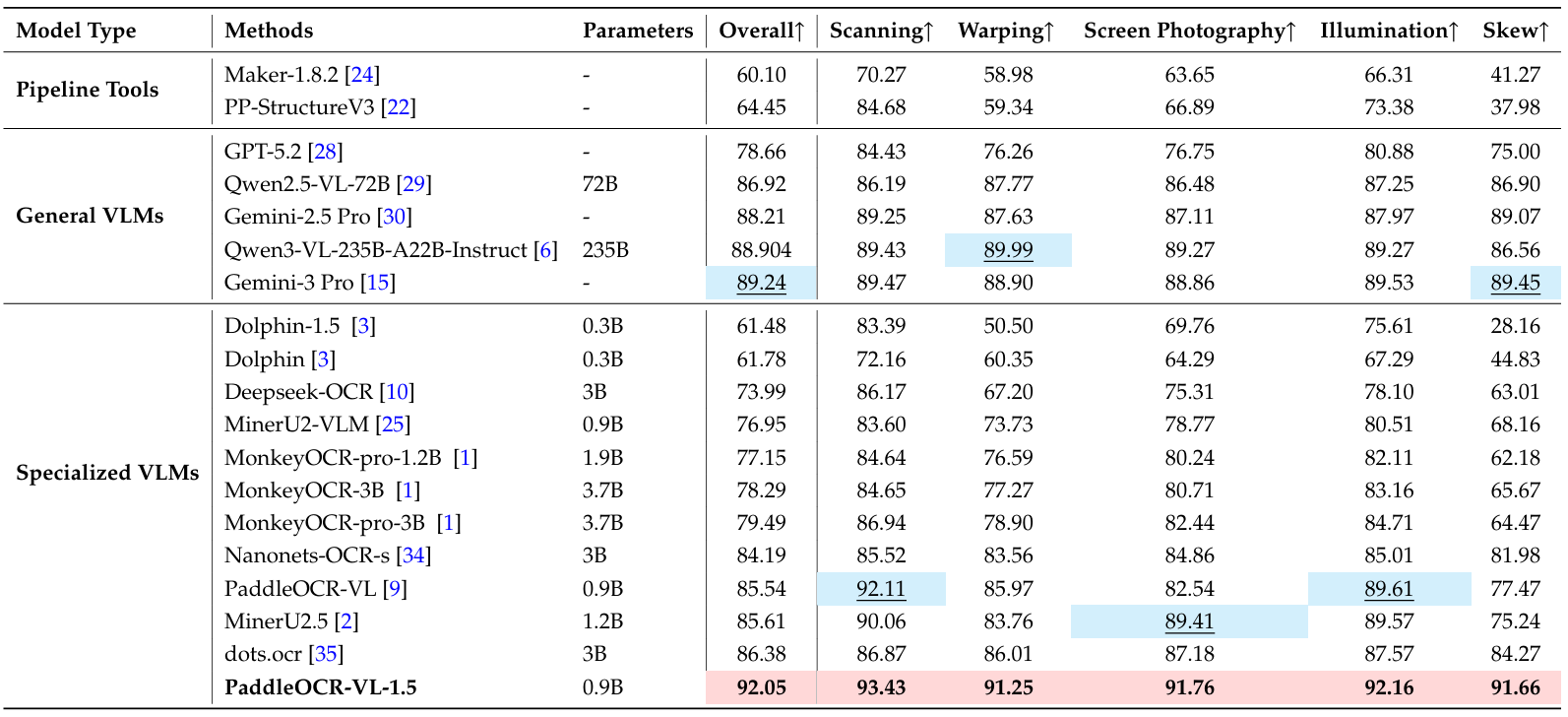
表 3 | Real5-OmniDocBench上文档解析的综合评估,附录B提供了该基准测试更详细的指标。
4.2. 新能力
4.2.1. 文本定位
为了全面评估模型的端到端文本定位能力(检测+识别),我们建立了一个涵盖10个关键维度的综合性OCR基准测试。除了标准设置(如普通场景和日语多语言识别)外,该基准测试旨在通过有意采样更具挑战性的案例来反映实际部署中的困难,包括退化或低质量图像(模糊)、中英文高度变化的手写体(Handwrite_ch/en)、结构化且对布局敏感的表格内容(Table),以及具有文化意义的历史材料(如古籍和繁体中文(Ancient))。如表4总结,我们的模型在所有9个维度上都实现了最高的定位准确率,持续优于强基线,并在多样化的视觉条件和文本风格下展现出强大的泛化能力。这些结果表明,所提出的方法不仅在常规文档场景中保持可靠,而且在需要精确定位和忠实转录的、具有挑战性的真实场景中同样可靠。

表 4 | 内部基准测试上的文本定位性能对比。总体表示所有9个评估维度的平均准确率。
4.2.2. 印章识别
为了评估我们模型在复杂印章识别任务中的有效性,我们构建了一个包含300张高质量图像的专业基准测试。该评估集涵盖了多样化的印章形状(例如圆形、椭圆形、矩形)和具有挑战性的真实场景,例如重叠文本、低对比度印记和扭曲背景。我们采用归一化编辑距离(NED)作为主要评估指标,以在字符级别评估识别准确性。
如表5所示,PaddleOCR-VL-1.5在印章识别方面展现出明显优势。尽管其规模紧凑(0.9B参数),它实现了0.138的NED,以较大优势超过了235B参数的Qwen3-VL(0.382)。这突显了模型在处理专业文档元素方面的有效性。
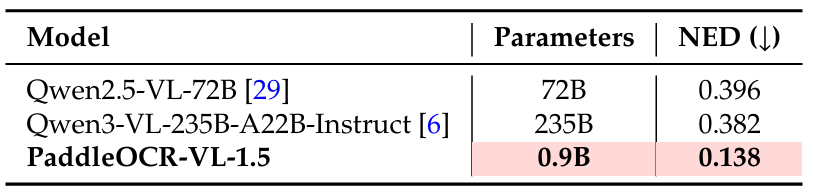
表 5 | 内部印章基准测试上的印章识别性能对比。
4.3. 推理性能
为了加速推理,我们通过引入异步、多线程设计来优化PaddleOCR-VL-1.5的执行工作流,遵循与PaddleOCR-VL相同的策略。整个工作流被分解为三个连续的阶段:输入准备(主要是将PDF页面转换为图像)、版面分析和VLM推理。每个阶段在其专用线程中运行,中间结果通过基于队列的缓冲区在相邻阶段之间交换。这种流水线架构实现了跨阶段的并发执行,从而提高了并行度并提升了整体吞吐量。特别是对于VLM推理阶段,动态地形成小批量:当队列大小达到预设容量或最旧的排队项等待时间超过指定时间限制时,会启动一个批次。这种批处理策略使得将多个页面的内容块分组到单个推理调用中成为可能,这大大提高了并行效率,尤其是在处理大型文档集合时。此外,我们将PaddleOCR-VL-1.5-0.9B部署在高性能推理和服务框架上,即FastDeploy 37 37 37、vLLM 38 38 38和SGLang 39 39 39。关键的运行时参数,包括最大批处理令牌数和GPU内存利用率,都经过精心调整,以在最大化推理吞吐量和控制GPU内存使用之间取得平衡。
表6总结了在OmniDocBench v1.5数据集上不同OCR方法在不同部署后端下的端到端推理效率。PaddleOCR-VL-1.5在所有指标上均实现了最佳整体性能。使用FastDeploy后端,它在单个NVIDIA A100 GPU上达到了1.4335页/秒和2016.6令牌/秒,分别超过了其前身PaddleOCR-VL 16.9%和18.6%。这些结果证实了PaddleOCR-VL-1.5提供了SOTA的推理速度和吞吐量,使其非常适合大规模、真实世界的文档理解应用。
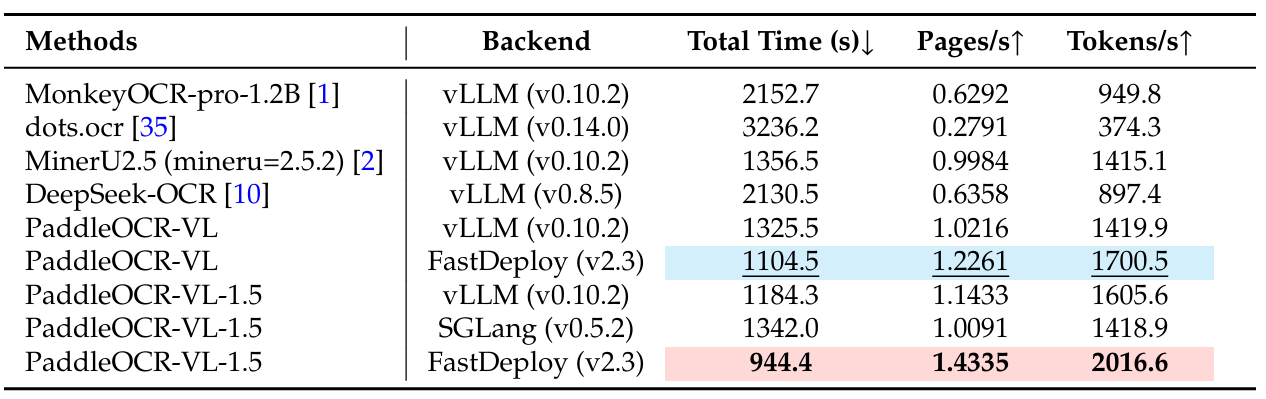
表 6 | OmniDocBench v1.5上的端到端推理性能对比。PDF文档在单个NVIDIA A100 GPU上以512的批量处理。报告的端到端运行时间包括PDF渲染和Markdown生成。所有方法都依赖
其内置的PDF解析模块和默认的DPI设置以反映开箱即用的性能。分词和特殊处理细节遵循 9 9 9中引入的协议。
5. 结论
这项工作推出了PaddleOCR-VL-1.5,在OmniDocBench v1.5上实现了创纪录的94.5% SOTA准确率,并在文档解析方面展示了卓越的通用精度。此版本的一个关键进步是其对无约束真实环境的卓越鲁棒性。该模型有效地克服了诸如严重倾斜、页面的非刚性弯曲和不稳定照明等关键障碍------在这些场景中,传统解决方案经常失败。此外,它还通过整合印章识别和文本定位扩展了其功能多样性。通过提供高保真的数据基础,PaddleOCR-VL-1.5将显著增强下游RAG系统和大型语言模型应用在复杂、真实部署中的可靠性和性能。
参考文献
1 Zhang Li, Yuliang Liu, Qiang Liu, Zhiyin Ma, Ziyang Zhang, Shuo Zhang, Zidun Guo, Jiarui Zhang, Xinyu Wang, and Xiang Bai. Monkeyocr: Document parsing with a structure-recognition-relation triplet paradigm. arXiv preprint arXiv:2506.05218, 2025.
2 Junbo Niu, Zheng Liu, Zhuangcheng Gu, Bin Wang, Linke Ouyang, Zhiyuan Zhao, Tao Chu, Tianyao He, Fan Wu, Qintong Zhang, et al. Mineru2. 5: A decoupled vision-language model for efficient high-resolution document parsing. arXiv preprint arXiv:2509.22186, 2025.
3 Hao Feng, Shu Wei, Xiang Fei, Wei Shi, Yingdong Han, Lei Liao, Jinghui Lu, Binghong Wu, Qi Liu, Chunhui Lin, et al. Dolphin: Document image parsing via heterogeneous anchor prompting. arXiv preprint arXiv:2505.14059, 2025.
4 Yuan Liu, Zhongyin Zhao, Le Tian, Haicheng Wang, Xubing Ye, Yangxiu You, Zilin Yu, Chuhan Wu, Xiao Zhou, Yang Yu, et al. Points-reader: Distillation-free adaptation of vision-language models for document conversion. arXiv preprint arXiv:2509.01215, 2025.
5 Baidu-ERNIE-Team. Ernie 4.5 technical report, 2025.
6 An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report. arXiv preprint arXiv:2505.09388, 2025.
7 Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report. arXiv preprint arXiv:2303.08774, 2023.
8 Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, et al. Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in neural information processing systems, 33:9459--9474, 2020.
9 Cheng Cui, Ting Sun, Suyin Liang, Tingquan Gao, Zelun Zhang, Jiaxuan Liu, Xueqing Wang, Changda Zhou, Hongen Liu, Manhui Lin, et al. Paddleocr-vl: Boosting multilingual document parsing via a 0.9 b ultra-compact vision-language model. arXiv preprint arXiv:2510.14528, 2025.
10 Haoran Wei, Yaofeng Sun, and Yukun Li. Deepseek-ocr: Contexts optical compression. arXiv preprint arXiv:2510.18234, 2025.
11 Jiarui Zhang, Yuliang Liu, Zijun Wu, Guosheng Pang, Zhili Ye, Yupei Zhong, Junteng Ma, Tao Wei, Haiyang Xu, Weikai Chen, et al. Monkeyocr v1.5 technical report: Unlocking robust document parsing for complex patterns. arXiv preprint arXiv:2511.10390, 2025.
12 Hunyuan Vision Team, Pengyuan Lyu, Xingyu Wan, Gengluo Li, Shangpin Peng, Weinong Wang, Liang Wu, Huawen Shen, Yu Zhou, Canhui Tang, et al. Hunyuanocr technical report. arXiv preprint arXiv:2511.19575, 2025.
13 Ting Sun, Cheng Cui, Yuning Du, and Yi Liu. Pp-doclayout: A unified document layout detection model to accelerate large-scale data construction. arXiv preprint arXiv:2503.17213, 2025.
14 Linke Ouyang, Yuan Qu, Hongbin Zhou, Jiawei Zhu, Rui Zhang, Qunshu Lin, Bin Wang, Zhiyuan Zhao, Man Jiang, Xiaomeng Zhao, et al. Omnidocbench: Benchmarking diverse pdf document parsing with comprehensive annotations. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 24838--24848, 2025.
15 Google DeepMind. Gemini 3.0. https://blog.google/products-and-platforms/products/gemini/gemini-3-collection/, 2025.
16 Yian Zhao, Wenyu Lv, Shangliang Xu, Jinman Wei, Guanzhong Wang, Qingqing Dang, Yi Liu, and Jie Chen. Detrs beat yolos on real-time object detection. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 16965--16974, 2024.
17 Mostafa Dehghani, Basil Mustafa, Josip Djolonga, Jonathan Heek, Matthias Minderer, Mathilde Caron, Andreas Steiner, Joan Puigcerver, Robert Geirhos, Ibrahim M Alabdulmohsin, et al. Patch n'pack: Navit, a vision transformer for any aspect ratio and resolution. Advances in Neural Information Processing Systems, 36:2252--2274, 2023.
18 PaddlePaddle Authors. Paddleformers. https://github.com/PaddlePaddle/PaddleFormers, 2025.
19 Yanjun Ma, Dianhai Yu, Tian Wu, and Haifeng Wang. Paddlepaddle: An open-source deep learning platform from industrial practice. Frontiers of Data and Computing, 1(1):105--115, 2019.
20 Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300, 2024.
21 Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. In International conference on machine learning, pages 8748--8763. PMLR, 2021.
22 Cheng Cui, Ting Sun, Manhui Lin, Tingquan Gao, Yubo Zhang, Jiaxuan Liu, Xueqing Wang, Zelun Zhang, Changda Zhou, Hongen Liu, et al. Paddleocr 3.0 technical report. arXiv preprint arXiv:2507.05595, 2025.
23 Bin Wang, Fan Wu, Linke Ouyang, Zhuangcheng Gu, Rui Zhang, Renqiu Xia, Botian Shi, Bo Zhang, and Conghui He. Image over text: Transforming formula recognition evaluation with character detection matching. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 19681--19690, June 2025.
24 Vik Paruchuri. Marker. https://github.com/datalab-to/marker, 2025. Accessed: 2025-09-25.
25 opendatalab. Mineru2.0-2505-0.9b. https://huggingface.co/opendatalab/MinerU2.0-2505-0.9B, 2025.
26 Jinguo Zhu, Weiyun Wang, Zhe Chen, Zhaoyang Liu, Shenglong Ye, Lixin Gu, Hao Tian, Yuchen Duan, Weijie Su, Jie Shao, et al. Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models. arXiv preprint arXiv:2504.10479, 2025.
27 Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, et al. Internvl3.5: Advancing open-source multimodal models in versatility, reasoning, and efficiency. arXiv preprint arXiv:2508.18265, 2025.
28 OpenAI. Gpt-5.2 system card, 2025. URL https://cdn.openai.com/pdf/3a4153c8-c748-4b71-8e31-aecbde944f8d/oai_5_2_system-card.pdf.
29 Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report. arXiv preprint arXiv:2502.13923, 2025.
30 Google DeepMind. Gemini 2.5. https://blog.google/technology/google-deepmind/gemini-model-thinking-updates-march-2025/, 2025.
31 chatdoc.com. Ocrflux. https://github.com/chatdoc-com/OCRFlux, 2025. Accessed:2025-09-25.
32 Mistral AI Team. Mistral-ocr. https://mistral.ai/news/mistral-ocr?utm_source=ai-bot.cn, 2025.
33 Jake Poznanski, Jon Borchardt, Jason Dunkelberger, Regan Huff, Daniel Lin, Aman Rangapur, Christopher Wilhelm, Kyle Lo, and Luca Soldaini. olmocr: Unlocking trillions of tokens in pdfs with vision language models. arXiv preprint arXiv:2502.18443, 2025.
34 Souvik Mandal, Ashish Talewar, Paras Ahuja, and Prathamesh Juvatkar. Nanonets-ocr-s: A model for transforming documents into structured markdown with intelligent content recognition and semantic tagging, 2025.
35 rednote-hilab. dots.ocr: Multilingual document layout parsing in a single vision-language model, 2025.
36 Qing Jiang, Junan Huo, Xingyu Chen, Yuda Xiong, Zhaoyang Zeng, Yihao Chen, Tianhe Ren, Junzhi Yu, and Lei Zhang. Detect anything via next point prediction. arXiv preprint arXiv:2510.12798, 2025.
37 PaddlePaddle Authors. Fastdeploy. https://github.com/PaddlePaddle/FastDeploy, 2025.
38 Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with paged attention. In Proceedings of the 29th symposium on operating systems principles, pages 611--626, 2023.
39 Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Chuyue Livia Sun, Jeff Huang, Cody Hao Yu, Shiyi Cao, Christos Kozyrakis, Ion Stoica, Joseph E Gonzalez, et al. Sglang: Efficient execution of structured language model programs. Advances in neural information processing systems, 37:62557--62583, 2024.
附录
A. PaddleOCR-VL-1.5与1.0版本模型的比较
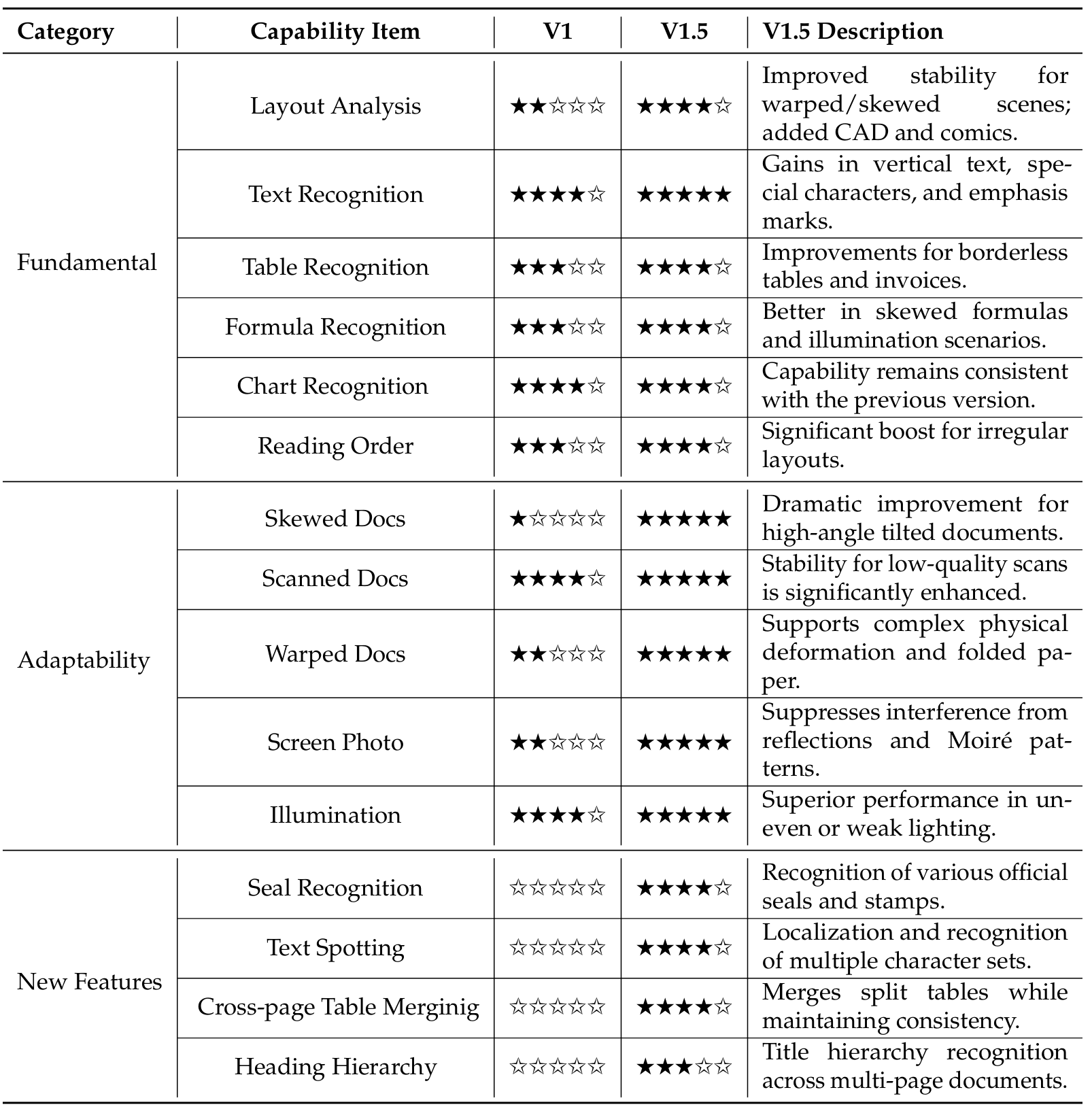
表 A1 | PaddleOCR-VL与PaddleOCR-VL-1.5的全面功能演进和鲁棒性比较。星级评分仅表示两个版本的相对性能,不代表其绝对准确率。
B. Real5-OmniDocBench基准测试详情
Real5-OmniDocBench 2 ^{2} 2是一个面向真实场景的全新基准测试,基于OmniDocBench v1.5 14 14 14数据集构建。PaddleOCR-VL-1.5在Real5-OmniDocBench的所有子场景中均取得了SOTA结果,展现了其对真实世界文档的鲁棒解析能力。本附录提供了PaddleOCR-VL-1.5与该数据集上其他先进文档解析模型在各种指标上的详细对比。
如表A2所示,在扫描场景下,PaddleOCR-VL-1.5在所有关键指标上都实现了SOTA性能,持续优于现有的流水线工具、通用VLM和专门文档解析模型。与其前身PaddleOCR-VL相比,新版本保持了0.9B的紧凑参数量,同时将总体分数从92.11%提升至领先的93.43%。值得注意的是,PaddleOCR-VL-1.5在该场景下的所有子任务中都创下了新纪录,包括93.04%的公式CDM分数和90.97%的表格TEDS分数,这两项都显著超过了Qwen3-VL-235B和Gemini-3 Pro等大型模型。此外,该模型实现了极低的文本编辑距离(0.037)和阅读顺序分数(0.045),进一步证明了其在文本识别、公式提取和复杂表格结构分析方面的高精度。总体而言,PaddleOCR-VL-1.5在Real5-OmniDocBench扫描场景中实现了新的突破。
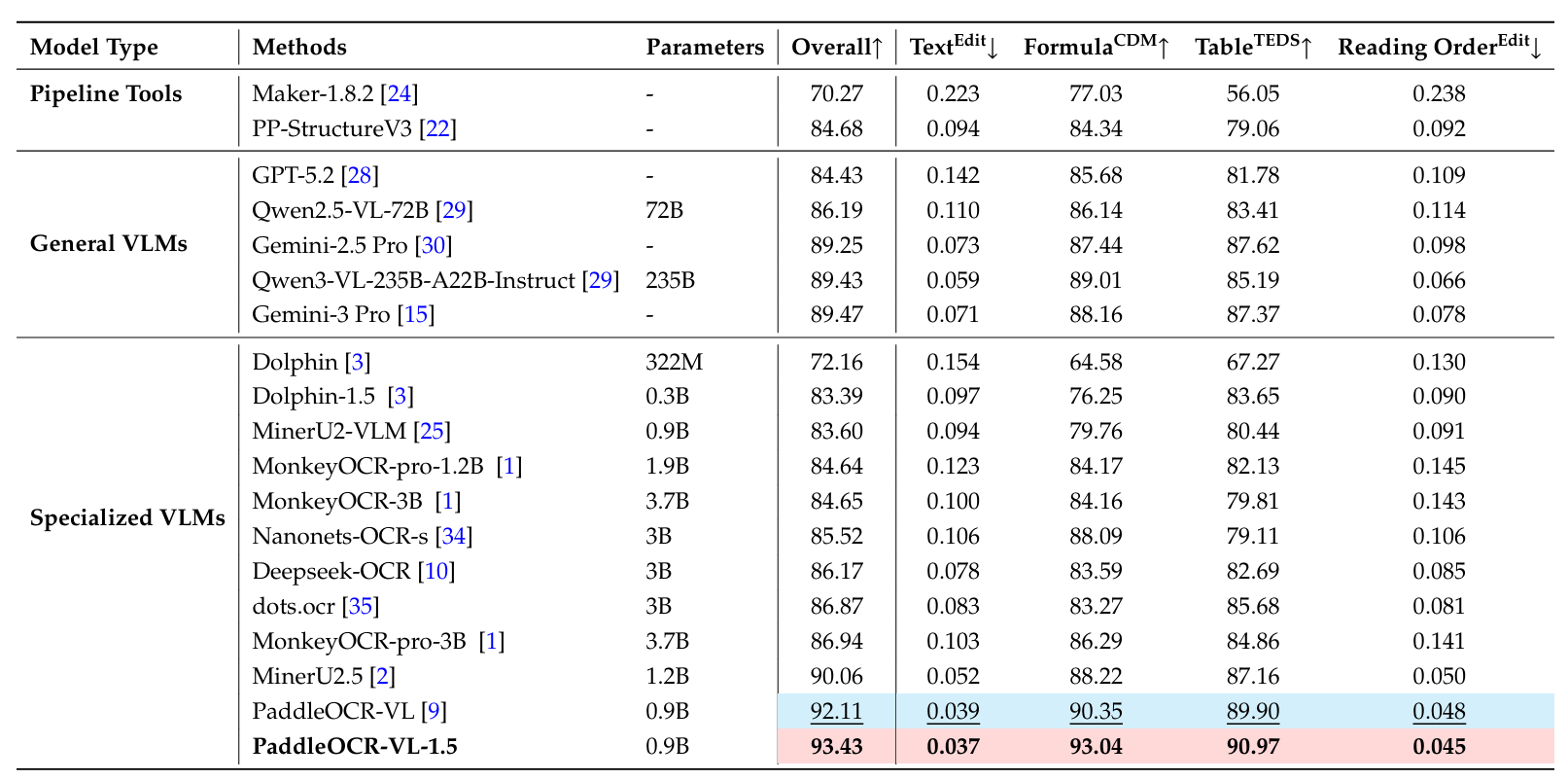
表 A2 | Real5-OmniDocBench扫描场景上的文档解析综合评估
如表A3所示,PaddleOCR-VL-1.5在弯曲场景下表现出显著的鲁棒性,取得了91.25%的总体分数,高于较大的Qwen3-VL-235B模型(89.99%)。其90.94%的公式CDM分数和88.10%的表格TEDS分数表明在显著几何畸变下保持文档结构的能力很强。
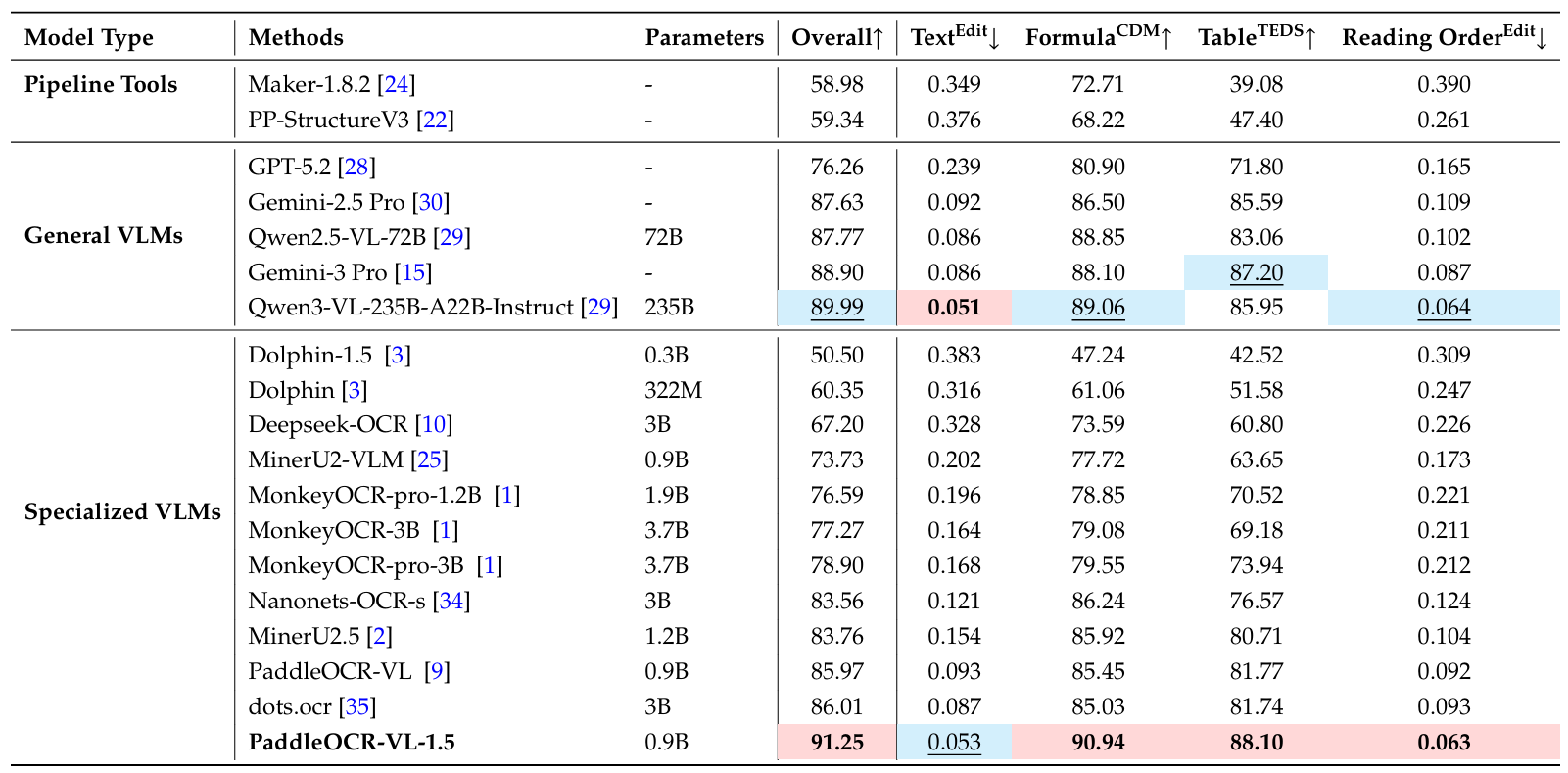
表 A3 | Real5-OmniDocBench弯曲场景上的文档解析综合评估。
在表A4所示的屏幕翻拍场景中,PaddleOCR-VL-1.5获得了91.76%的总体分数,在专用VLM中表现出具有竞争力的性能。该模型取得了90.88%的公式CDM分数,优于MinerU2.5(87.55%)和dots.ocr(85.34%),并显示出对屏幕捕捉文档中典型的摩尔纹和反光的有效处理。
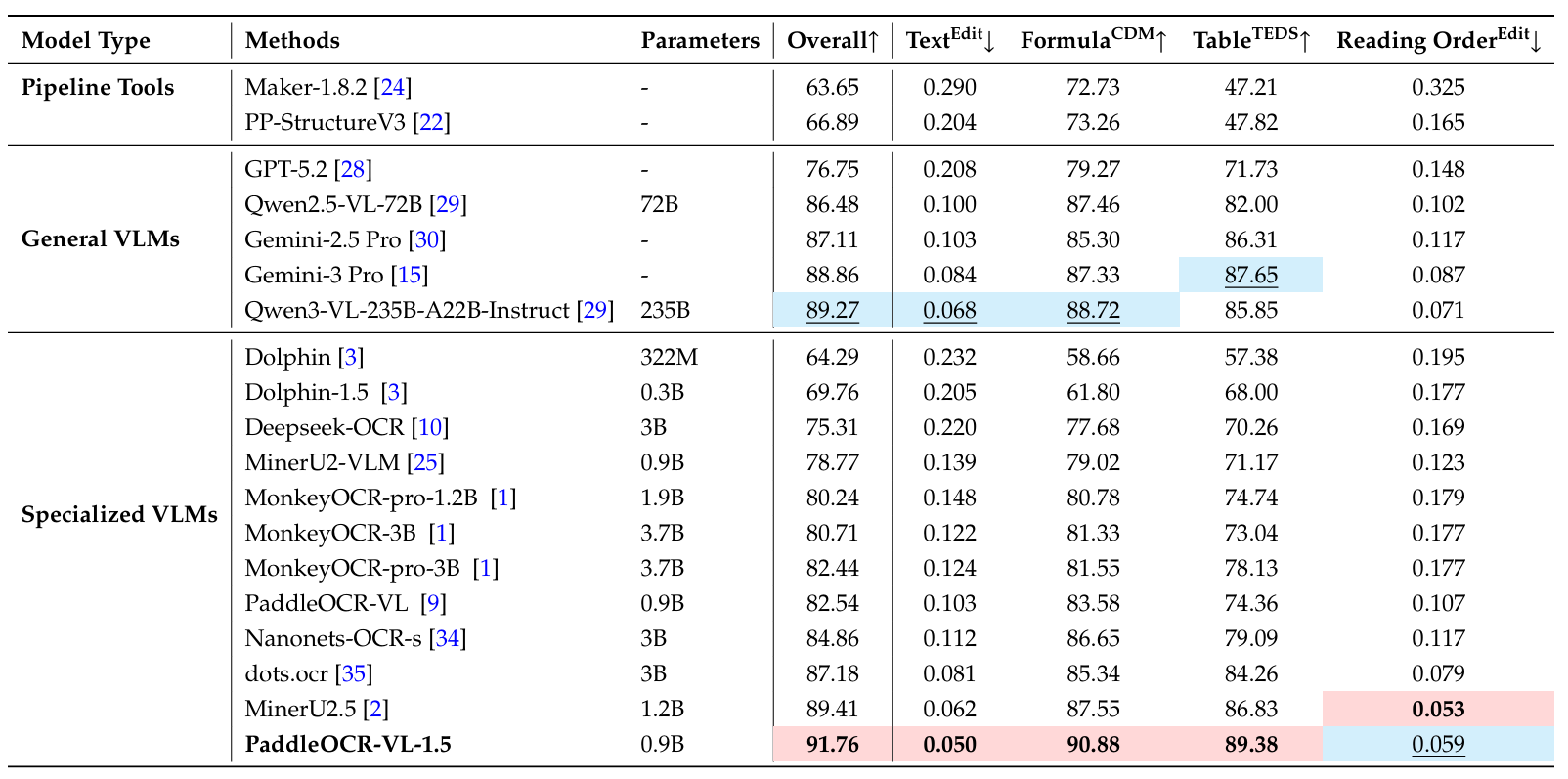
表 A4 | Real5-OmniDocBench屏幕翻拍场景上的文档解析综合评估。
表A5评估了光照变化下的性能,其中PaddleOCR-VL-1.5达到了92.16%的总体分数。这一结果不仅较前代PaddleOCR-VL(89.61%)有显著提升,也超过了Gemini-3 Pro(89.53%)等顶级通用VLM。该模型91.80%的公式CDM分数和89.33%的表格TEDS分数突显了其在低对比度或光照不均匀环境下的高灵敏度和准确性。
其在低对比度或光照不均匀环境下的高灵敏度和准确性。
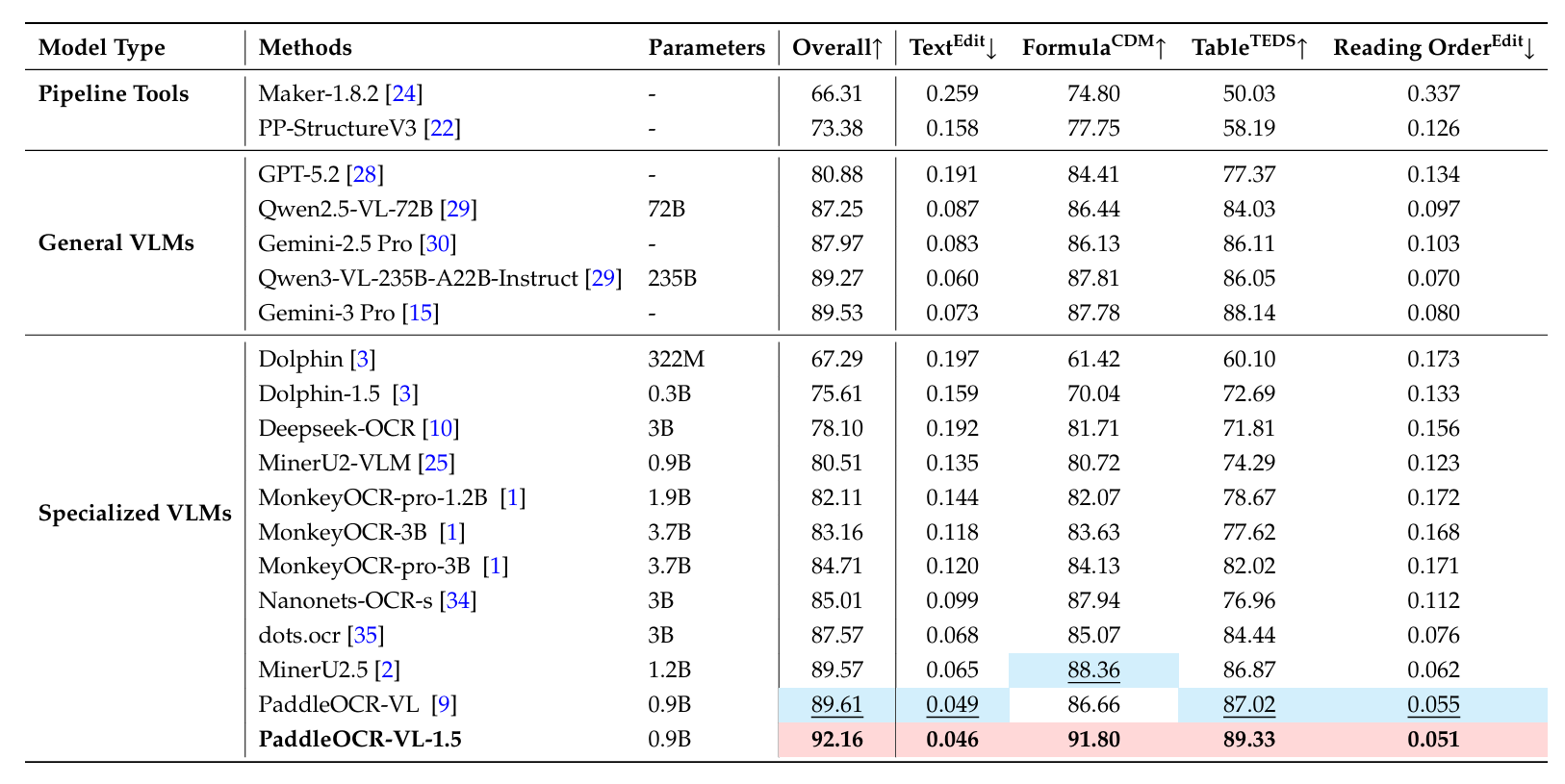
表 A5 | Real5-OmniDocBench光照场景上的文档解析综合评估。
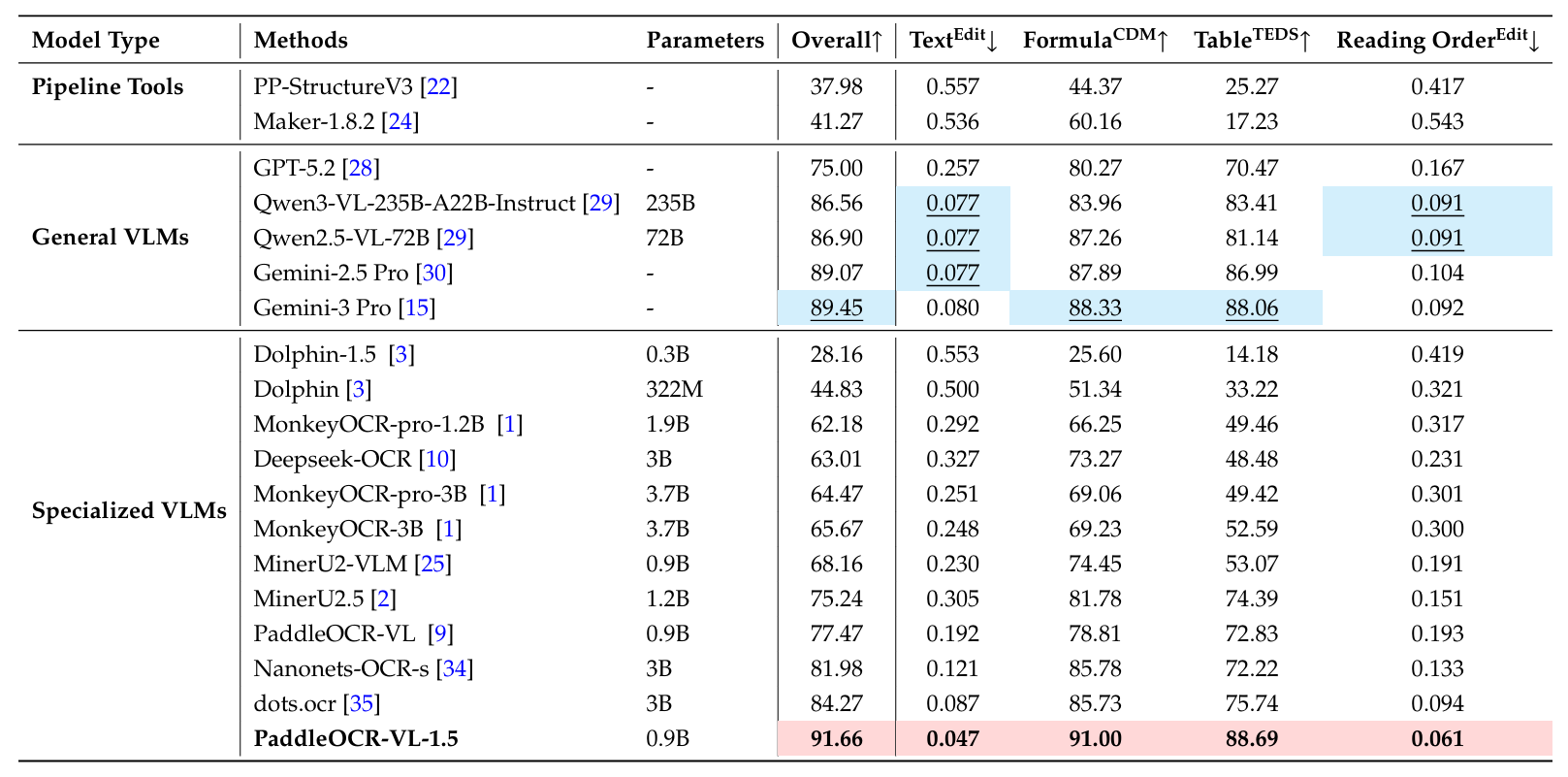
如表A6详细描述的倾斜场景下,PaddleOCR-VL-1.5以91.66%的总体分数保持其主导地位,再次超越了包括Gemini-3 Pro(89.45%)在内的通用VLM。它尤其在复杂结构恢复方面表现出色,表格TEDS分数达到91.00%,文本编辑距离降至0.047,展示了其在校正和解析倾斜文档布局方面的卓越能力。
C. 支持的语言
PaddleOCR-VL-1.5 总计支持 111 种语言。与 PaddleOCR-VL 相比,PaddleOCR-VL-1.5 新增了对中国藏文和孟加拉语的识别能力。表 A7 列出了每种语言类别与具体支持的语言/文字之间的对应关系。
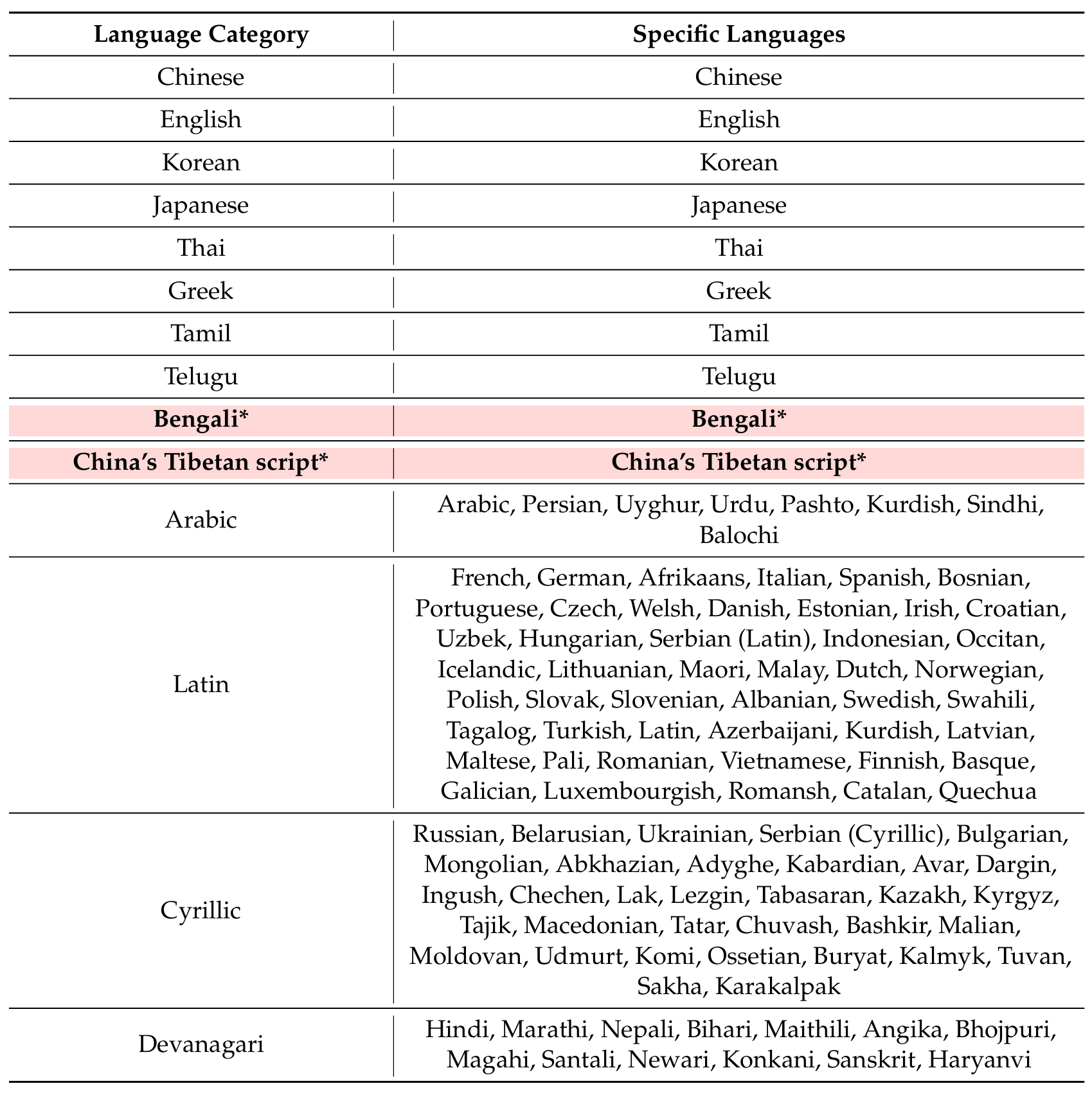
表 A7 | 支持的语言/文字(*表示新增语言/文字)
D. 不同硬件配置上的推理性能
我们在多种硬件配置上评估了 PaddleOCR-VL-1.5 的推理吞吐量和延迟,详细结果见表 A8。在我们的实验中,所有 PDF 页面均以 72 DPI 渲染,这在内存效率和可靠 OCR 所需的视觉保真度之间提供了良好的平衡。我们注意到,在不同硬件平台上的实验未进行广泛的参数调整或系统级优化;因此,报告的性能数据应被视为保守估计,仍有进一步改进的空间。所有模型均使用三个部署后端进行评估,即 FastDeploy v2.3.0、vLLM v0.10.2 和 SGLang v0.5.2。在这些框架中,PaddleOCR-VL-1.5 始终能提供高且稳定的推理效率,证明了其在多样硬件配置和执行引擎上的强大泛化能力,以及对异构计算环境的良好兼容性。
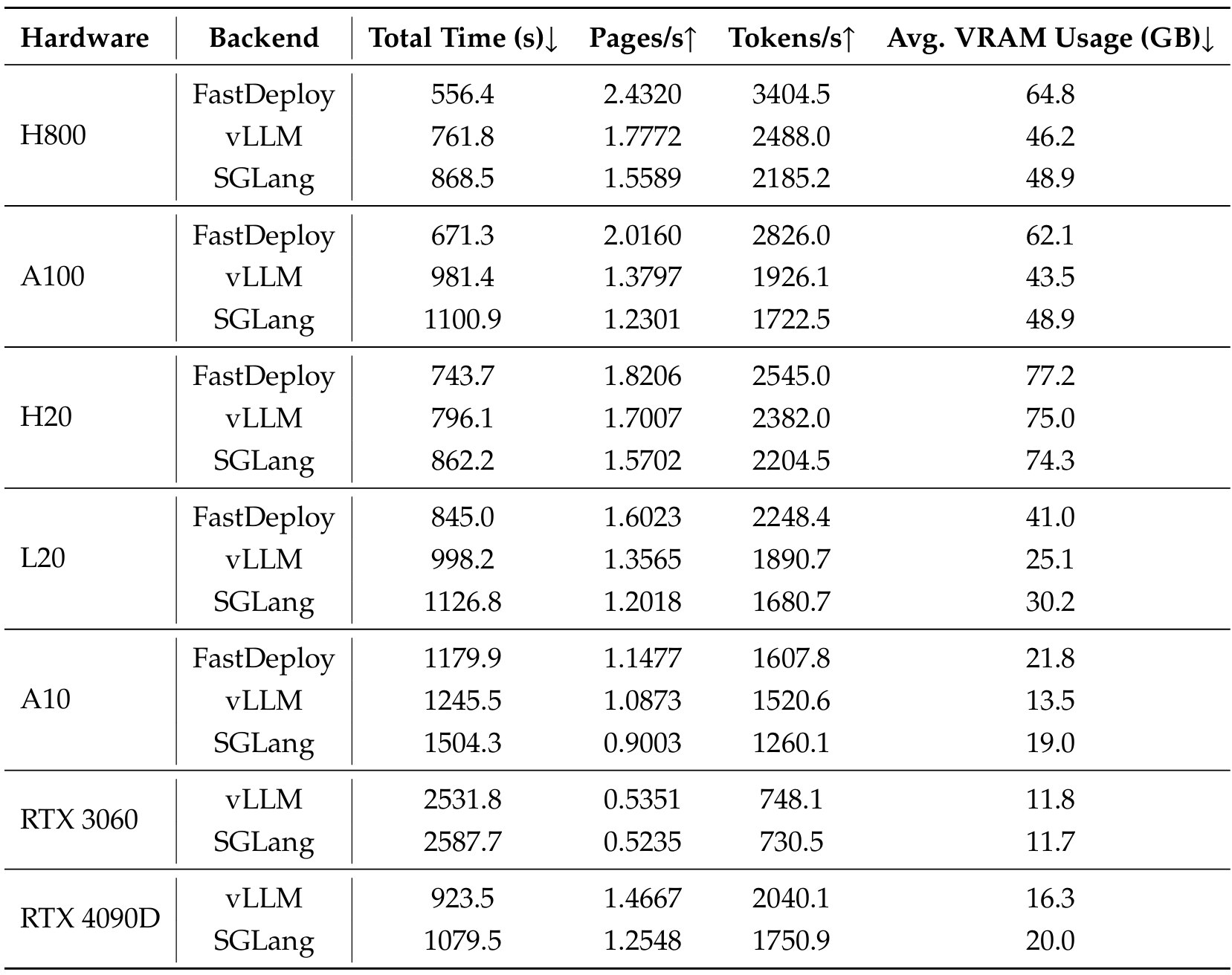
表 A8 | 端到端推理性能
E. 真实世界样本
本附录展示了 PaddleOCR-VL-1.5 在处理多样化、高复杂度真实场景时的鲁棒性和多功能性。
E.1 节 展示了 PaddleOCR-VL-1.5 的真实世界文档解析能力。图 A1--A5 展示了 PaddleOCR-VL-1.5 在多样化条件下(包括不同光照、几何倾斜、屏幕翻拍噪声和弯曲扫描表面)解析真实世界文档的鲁棒性能。
E.2 节 中的图 A6--A9 展示了 PaddleOCR-VL-1.5 在具有挑战性的真实条件下(包括倾斜或弯曲几何形状、屏幕翻拍噪声和光照变化)进行版面分析的鲁棒性。此外,图 A10 突出了其对专业领域(如漫画、CAD 图纸和多印章文档)的扩展泛化能力,这些是早期模型版本面临局限的领域。
E.3 节 评估了 PaddleOCR-VL-1.5 在多种约束下的文本识别性能。如图 A11 所示,该模型对文本装饰(如下划线、强调标记和波浪纹)表现出更高的敏感性,超越了其前代模型。图 A12 和图 A13 展示了在识别特殊字符和长尾用例(如垂直方向和字符级模糊情况)方面增强的鲁棒性。
E.4 节 展示了模型的表格识别能力。图 A14 说明了模型在处理复杂布局(包括来自学术教科书的表格以及包含嵌入式图像或数学公式的表格)时的鲁棒性。图 A15 展示了模型在多语言表格识别方面的熟练程度。此外,图 A16 展示了其跨页表格检测和合并的扩展能力,以解决多页文档解析的挑战。
E.5 节 中的图详细说明了公式识别性能。如图 A17 所示,更新后的模型在数学表达式识别方面表现出优越的性能,特别是在下标/上标准确性、多行公式分割和更低的整体错误率方面。
E.6 节中,印章识别代表了此次模型更新的一项新能力。如图 A18--A20 所示,该模型能准确提取各种类型印章中的内容,即使面临复杂的背景干扰和杂乱环境也表现出高精度。
E.7 节 中的图 A21 突出了模型新集成的文本检测与识别能力,该能力支持同步定位和识别。结果表明,该能力在具有挑战性的布局(从多栏杂志页面和复杂表格到不规则手写内容)中均表现出卓越的鲁棒性。
E.1. 真实世界文档解析

图 A1 | 光照条件下的 Markdown 输出。

图 A2 | 倾斜条件下的 Markdown 输出。

图 A3 | 屏幕翻拍条件下的 Markdown 输出。

图 A4 | 扫描条件下的 Markdown 输出。

图 A5 | 弯曲/变形条件下的 Markdown 输出。
E.2. 版面分析
E.2.1. 真实世界文档的版面分析

图 A6 | 弯曲/变形条件下 PaddleOCR-VL 与 PaddleOCR-VL-1.5 的版面分析结果对比。

图 A7 | 屏幕翻拍条件下 PaddleOCR-VL 与 PaddleOCR-VL-1.5 的版面分析结果对比。

图 A8 | 倾斜条件下 PaddleOCR-VL 与 PaddleOCR-VL-1.5 的版面分析结果对比。

图 A9 | 光照条件下 PaddleOCR-VL 与 PaddleOCR-VL-1.5 的版面分析结果对比。
E.2.2. 新场景的版面分析

图 A10 | 新场景下 PaddleOCR-VL 与 PaddleOCR-VL-1.5 的版面分析结果对比。
E.3. 文本识别
E.3.1. 带文本装饰的文本识别

图 A11 | 带文本装饰的文档上 PaddleOCR-VL 与 PaddleOCR-VL-1.5 的 Markdown 输出对比。
E.3.2. 特殊字符的文本识别

图 A12 | 含特殊字符的文档上 PaddleOCR-VL 与 PaddleOCR-VL-1.5 的 Markdown 输出对比。
E.3.3. 长尾场景的文本识别

图 A13 | 长尾场景文档上 PaddleOCR-VL 与 PaddleOCR-VL-1.5 的 Markdown 输出对比。
E.4. 表格识别
E.4.1. 通用表格识别
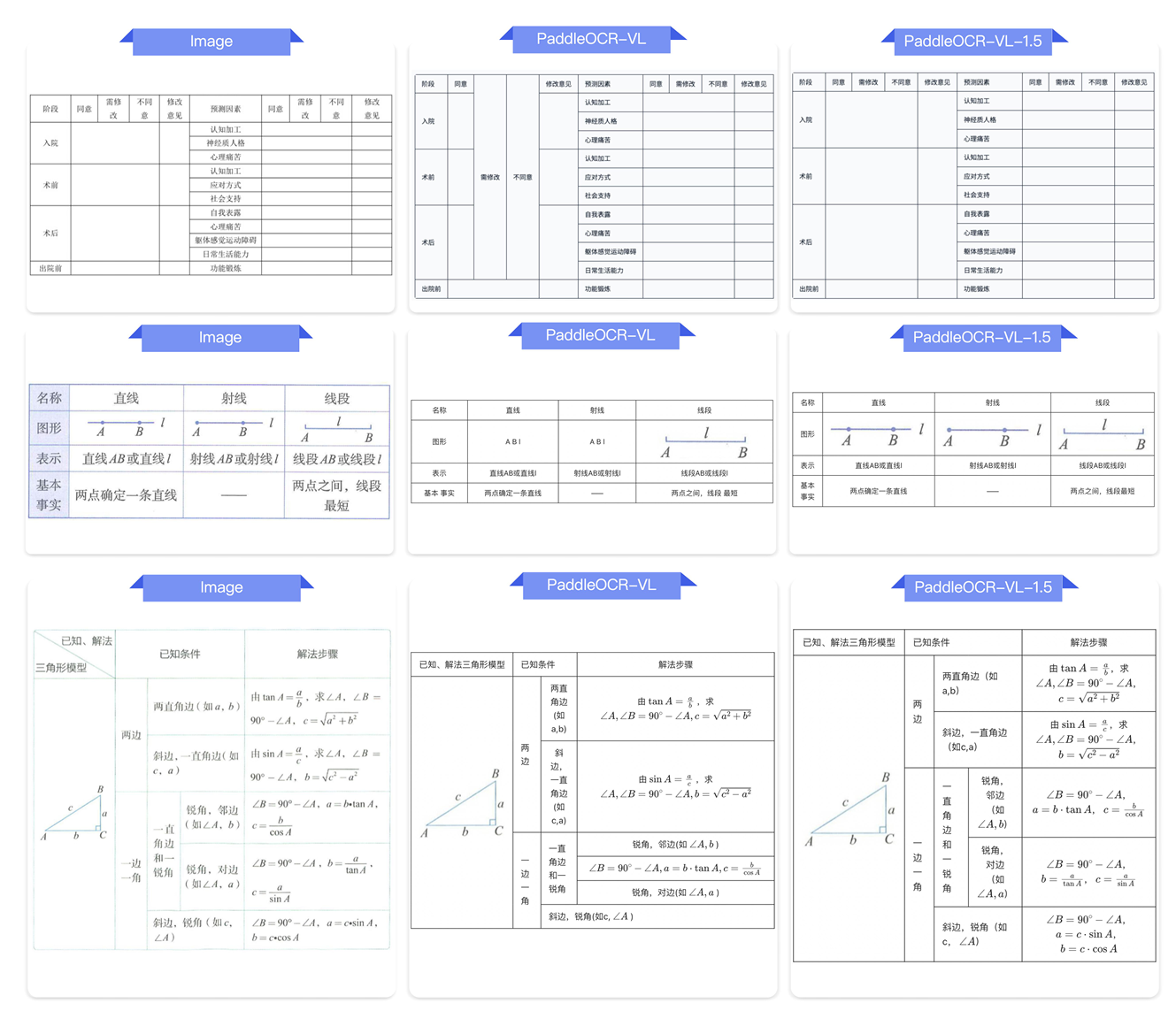
图 A14 | 通用表格上 PaddleOCR-VL 与 PaddleOCR-VL-1.5 的 Markdown 输出对比。
E.4.2. 多语言表格识别

图 A15 | 多语言表格上 PaddleOCR-VL 与 PaddleOCR-VL-1.5 的 Markdown 输出对比。
E.4.3. 跨页表格识别

图 A16 | 跨页表格上 PaddleOCR-VL 与 PaddleOCR-VL-1.5 的 Markdown 输出对比。
E.5. 公式识别

图 A17 | 各类公式上 PaddleOCR-VL 与 PaddleOCR-VL-1.5 的 Markdown 输出对比。
E.6. 印章识别

图 A18 | 各类印章 1 的 Markdown 输出。

图 A19 | 各类印章 2 的 Markdown 输出。
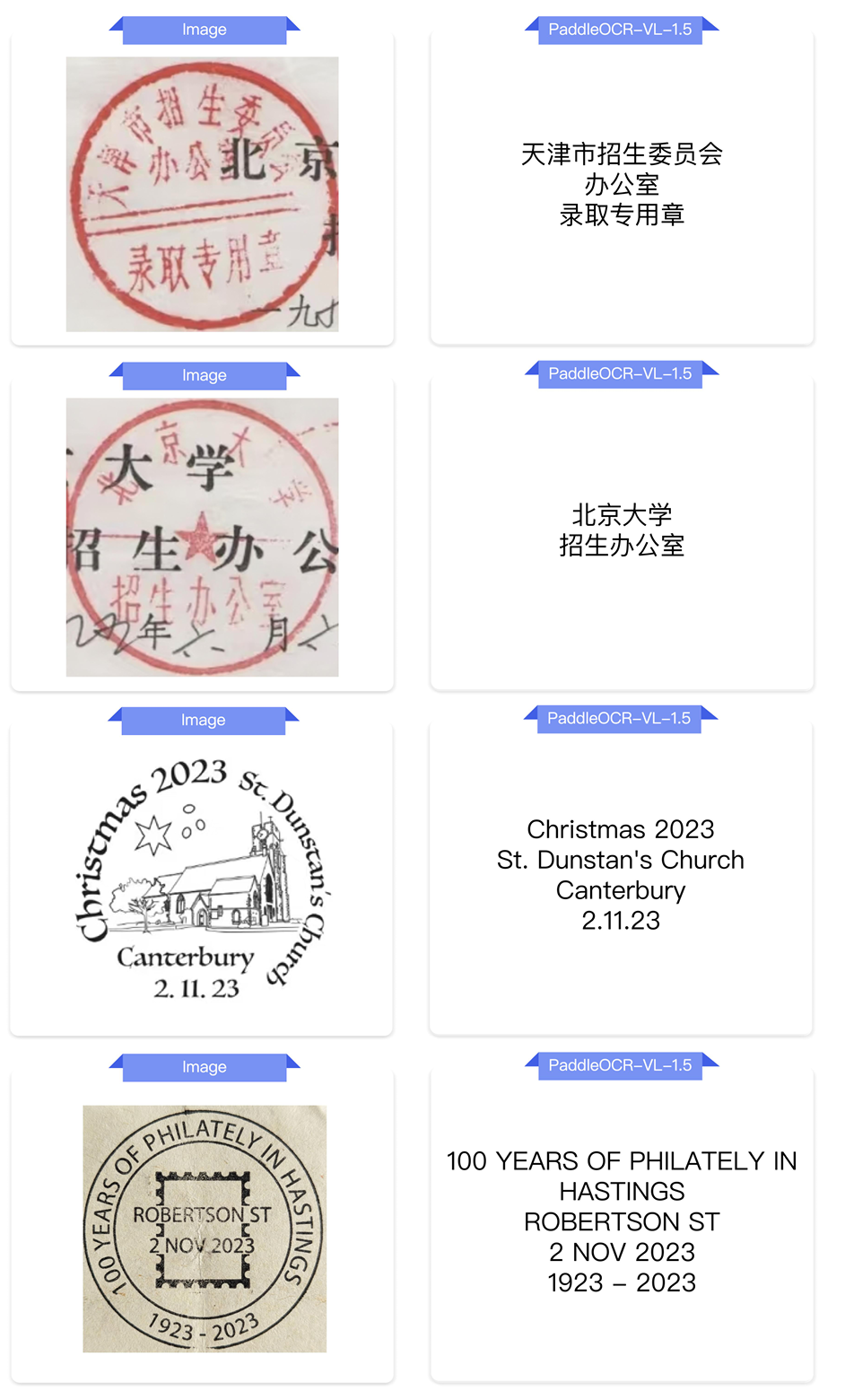
图 A20 | 各类印章 3 的 Markdown 输出。
E.7. 文本检测与识别(文本定位)

图 A21 | 各类文档上的文本检测与识别(文本定位)结果。