Vlaser 是一款基于 InternVL3 构建的视觉-语言-行动(VLA)模型,核心亮点是集成协同具身推理与端到端机器人控制能力。
提供VLM多模态数据集,覆盖具身定位、具身问答、空间推理、规划推理、仿真交互等。
论文地址 :VLASER: VISION-LANGUAGE-ACTION MODEL WITH SYNERGISTIC EMBODIED REASONING
开源地址 :https://github.com/OpenGVLab/Vlaser
- 核心痛点:现有VLM 模型的具身推理能力与下游 VLA 策略学习存在领域差距,互联网预训练数据与机器人具身任务适配性不足
- 研究目标:
- 系统分析 VLM 初始化对 VLA 微调的影响,明确关键数据类型
- 缩小互联网预训练,与机器人具身任务的领域迁移鸿沟
- 构建兼具高水平具身推理,与控制能力的基础 VLA 模型(Vlaser)
目录
[阶段 1:多模态预训练 图 (a)](#阶段 1:多模态预训练 图 (a))
[阶段 2:VLA 微调 图 (b)](#阶段 2:VLA 微调 图 (b))
[3、VLM + VLA 双组件结构](#3、VLM + VLA 双组件结构)
[(1)VLM 骨干:具身推理基础](#(1)VLM 骨干:具身推理基础)
[4、Vlaser 数据引擎:6M多模态数据支撑](#4、Vlaser 数据引擎:6M多模态数据支撑)
[(1)阶段一:VLM 预训练(具身推理强化)](#(1)阶段一:VLM 预训练(具身推理强化))
[(2)阶段二:VLA 微调(控制能力)](#(2)阶段二:VLA 微调(控制能力))
[1. 第一步:原始空间推理数据的结构化整理](#1. 第一步:原始空间推理数据的结构化整理)
[2. 第二步:文本标准化(适配 tokenizer 编码)](#2. 第二步:文本标准化(适配 tokenizer 编码))
[3. 第三步:tokenizer 编码(核心转化环节)](#3. 第三步:tokenizer 编码(核心转化环节))
[4. 第四步:拆分 "前文 token" 与 "目标 token"(适配自回归损失)](#4. 第四步:拆分 “前文 token” 与 “目标 token”(适配自回归损失))
1、模型简介
核心能力:协同具身推理 + 端到端机器人控制
架构组成:
| 组件 | 核心构成 | 功能定位 |
|---|---|---|
| VLM 骨干 | InternVL3(2B/8B 参数) InternViT 视觉编码器 + Qwen2.5 LLM | 提供感知、语言理解与具身推理能力 |
| 行动专家 | 流匹配(Flow Matching)+ MoE 架构 | 处理低级别机器人控制,预测动作序列 |
Vlaser-6M数据集:
- 具身定位数据:1.8M(边界框+中心点标注)
- 具身QA+空间推理:1.7M(含1.2M RoboVQA+500k空间数据)
- 规划数据:0.4M(多模态任务+轨迹数据)
- 仿真域内数据:2M(SimplerEnv/RoboTwin机器人交互数据)
2、模型框架
Vlaser的模型框架,如下图所示。
两阶段核心流程:VLM多模态预训练 → VLA 微调,实现 "感知推理→机器人控制"。
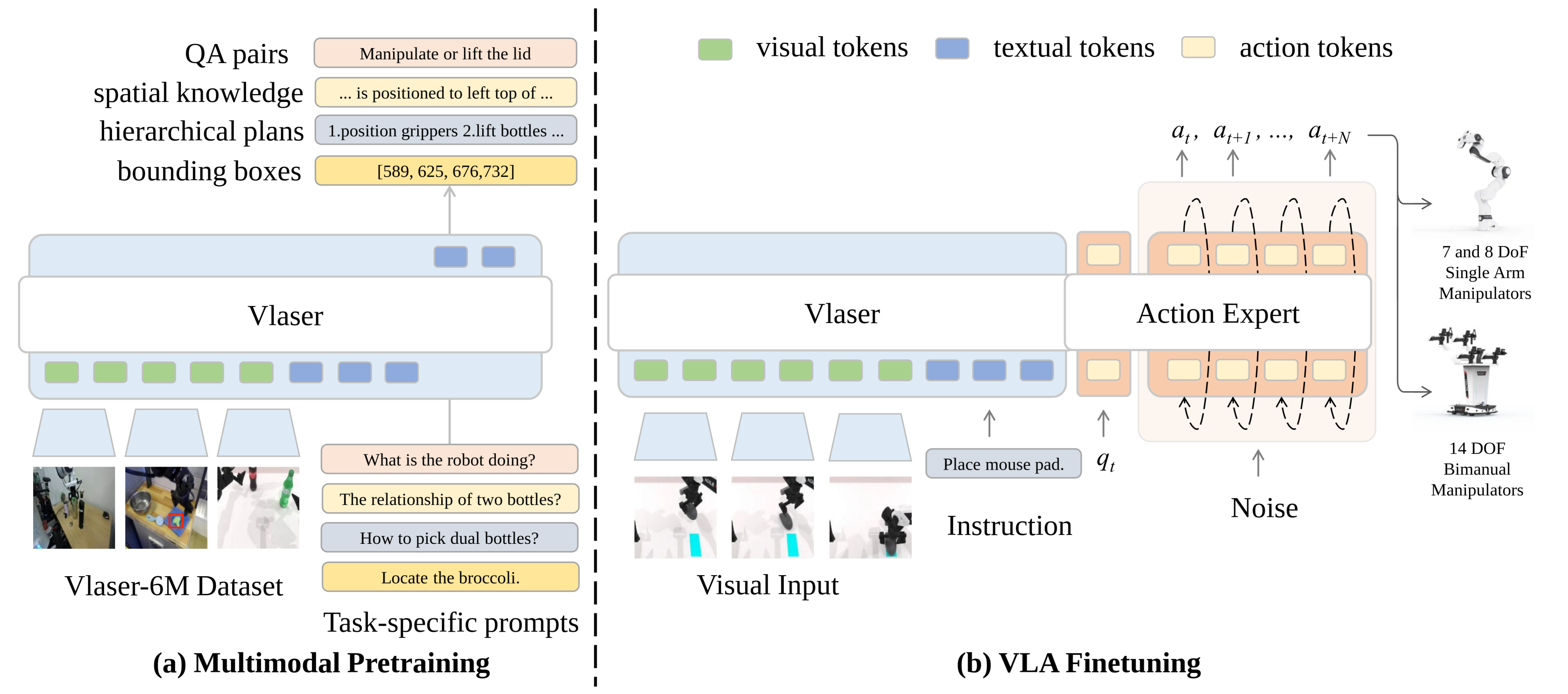
阶段 1:多模态预训练 图 (a)
输入
- 视觉输入:机器人场景的图像数据(来自 Vlaser-6M 数据集);
- 任务特定提示:针对具身任务的指令 / 问题(如 "What is the robot doing?""Locate the broccoli.")。
处理模块:Vlaser 模型(集成视觉、文本编码能力)。
输出(对应具身推理能力),生成多类型具身任务结果,包括:
- 具身QA 对(机器人具身问答任务);
- 空间知识(物体位置关系,如 "...is positioned to left top of...");
- 分层规划(任务步骤,如 "1.position grippers 2.lift bottles...");
- 边界框(目标定位坐标,如
[589,625,676,732])。
阶段 2:VLA 微调 图 (b)
输入
- 视觉输入:机器人场景的图像数据;
- 任务指令:具体操作需求(如 "Place mouse pad");
- 辅助输入:噪声(用于 Action Expert 的动作生成)。
处理模块
- Vlaser:处理视觉 token、文本 token,提供感知与推理基础;
- Action Expert:接收 Vlaser 的输出(视觉 / 文本 token)+ 噪声,生成动作序列。
输出(对应机器人控制)
生成动作序列 (a_t, a_{t+1}, ..., a_{t+N}),驱动不同自由度的机械臂执行任务:
- 单臂机械臂(7/8 DoF);
- 双臂机械臂(14 DoF)。
小结:
先通过多模态预训练,让 Vlaser 掌握具身场景下的 "感知、推理、规划、定位" 能力;
再通过VLA 微调,结合 Action Expert 模块,将预训练获得的推理能力转化为可执行的机器人动作,实现 "从认知到操作" 的具身智能。
3、VLM + VLA 双组件结构
Vlaser 的架构核心是 "VLM 骨干(感知推理层)+ 行动专家(控制执行层) ",二者共享注意力机制,实现高级推理与低级控制的无缝衔接。
(1)VLM 骨干:具身推理基础
- 基础框架:基于 InternVL3 构建,聚焦 2B/8B 参数规模(适配机器人计算资源约束)。
- 核心构成:
- 视觉编码器:采用 InternViT,负责提取机器人场景图像的视觉特征。
- 语言模型:搭配 Qwen2.5-1.5B(2B 模型)/ Qwen2.5-7B(8B 模型),处理文本指令、任务提示与推理逻辑。
- 核心目标:强化具身常识推理(如物体空间关系、任务逻辑拆解),而非通用多模态任务。
(2)行动专家:端到端控制模块
- 设计理念:在 VLM 基础上扩展低级别机器人控制能力,验证不同数据流对 VLA 微调的有效性。
- 技术核心:
- 架构参考:混合专家(MoE)设计,分离通用模态(图像 / 文本)与机器人特定模态(动作 / 状态)的权重。
- 动作预测:采用 流匹配(Flow Matching) 算法,基于单帧观测生成未来动作序列。
- 输入编码:将机器人状态编码为 "状态 token",噪声动作编码为 "动作 token",与视觉 / 文本 token 共同输入。
- 注意力机制:VLA 流采用非因果注意力,适配动作序列的生成逻辑。
- 推理过程:结合图像观测、语言指令与当前机器人状态,对噪声动作进行去噪,输出可执行动作。
4、Vlaser 数据引擎:6M多模态数据支撑
数据引擎是 Vlaser 具身推理能力的核心保障,通过 "curated 公开数据 + 合成标注 + 领域内数据" 构建,覆盖具身任务全链条。
(1)数据构成与特点
| 数据类型 | 规模 | 核心内容 | 格式 / 来源 | 核心作用 |
|---|---|---|---|---|
| 具身定位数据 | 1.8M | 目标定位任务(开放词汇描述→边界框 / 中心点) | 边界框 / 中心点(归一化至 0,1000),来源包括 RoboPoint、SA-1B(合成标注) | 强化机器人 "定位目标" 的基础能力 |
| 通用 & 空间推理数据 | 1.7M | 1.2M RoboVQA(机器人状态、场景问答)+ 500k 空间推理(物体计数、相对位置) | 问答对,来源包括 RoboVQA、SPAR、3D 场景手动标注(ScanNet 等) | 提升场景认知与 3D 空间理解能力 |
| 规划数据 | 0.4M | 多步任务分解、轨迹数据 | 语言规划步骤 + 动作轨迹,来源包括 Alpaca-15k、Habitat 模拟器生成轨迹 | 赋能复杂任务的分步执行能力 |
| 仿真域内数据 | 2M | 机器人交互场景专属数据 | 问答对(状态查询、定位、空间推理),来源包括 SimplerEnv(Google Robot/WidowX)、RoboTwin(双臂机器人) | 缩小互联网数据与机器人任务的领域差距 |
(2)数据质量保障
- 合成数据优化:对 SA-1B 的分割掩码进行转换(边界框 / 中心点),并通过 BLIP-2+Qwen2.5-VL 进行 caption 过滤,确保标注准确性。
- 人工标注增强:针对空间推理任务,基于 3D 场景手动生成 100k 样本,强化关键空间能力。

5、训练流程:两阶段优化策略
Vlaser 采用 "预训练(强化推理)→ 微调(落地控制) " 的两阶段训练,确保每阶段目标明确、能力聚焦。
(1)阶段一:VLM 预训练(具身推理强化)
- 训练目标:在 InternVL3 基础上,通过监督微调(SFT)注入具身推理能力。
- 训练数据:Vlaser-6M 中的通用具身数据(定位、具身QA、空间推理、规划)。
- 损失函数:**语言建模损失(Llm)**核心逻辑:给定图像x与文本提示y,最小化下一个 token 的预测误差。
- 训练配置:动态分辨率、448px 补丁大小、bfloat16 精度,全局批次 128。
语言建模 损失函数为:
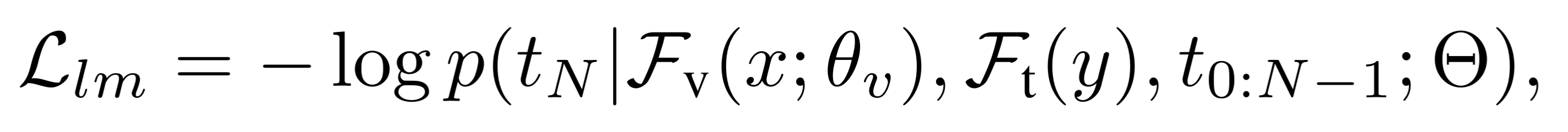
这里其实是一个"自回归 语言建模损失",
- 核心目标:让模型学习 "给定图像x和文本提示y的前文 token(t0:N−1),准确预测下一个 token(tN)"
- 公式关键参数对应:
- p:模型预测的下一个 token 的概率分布(维度为词汇表大小m)
- Fv(x;θv):图像x通过 ViT 视觉编码器 + MLP 提取的视觉特征(θv为视觉模块参数)
- Ft(y):文本提示y通过文本 tokenizer 转换后的文本特征
- Θ:LLM(语言模型)的核心参数
- tN:待预测的 "下一个 token"(真实标签)
(2)阶段二:VLA 微调(控制能力)
- 训练目标:优化行动专家模块,将具身推理能力转化为机器人可执行动作。
- 训练数据:Vlaser-6M 中的领域内数据(机器人交互场景专属数据)。
- 核心定义:
- 动作块At:当前时刻t开始的H个连续动作(At=at,at+1,...,at+H−1),H=4。
- 观测值ot:多视角图像It、语言指令lt、机器人状态qt的融合编码。
- 损失函数:**流匹配损失(Lvla)**核心逻辑:训练网络学习 "噪声动作→真实动作" 的去噪向量场。
- 推理配置:积分步长δ=0.1(10 次去噪迭代),平衡推理效率与动作精度。
流匹配 损失函数为:
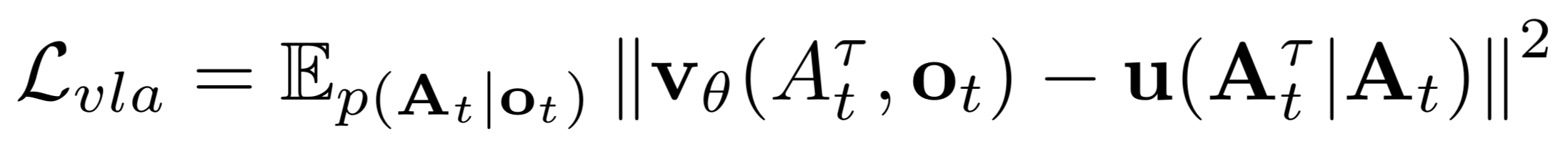
其中At τ为噪声动作(τ为流匹配时序),u为目标去噪向量场。
- 该损失函数是 流匹配损失(Flow Matching Loss),本质是基于 "去噪向量场匹配" 的均方误差(MSE)损失期望形式;
- 核心目标是让模型学会从噪声动作中恢复真实机器人动作,确保预测的去噪方向与理论目标方向一致;
- 所有关键参数均对应机器人动作生成的核心要素(真实动作、噪声、观测、模型预测),适配 VLA 微调阶段的端到端控制需求。
| 参数符号 | 中文含义 | 核心定义 | 作用 |
|---|---|---|---|
| Lvla | VLA 优化损失 | 流匹配损失的最终计算结果,是 VLA 微调阶段的核心优化目标(论文 2.3 节) | 衡量模型动作生成的精准度,指导参数更新 |
| $\mathbb{E}_{p(A_t | o_t)}$ | 条件分布的期望 | 对 "给定观测ot时真实动作块At的概率分布 p (A_to_t)" 求期望确保损失反映所有合理 "观测 - 动作" 配对的平均误差,避免个别样本偏差 |
| At | 真实动作块 | t 时刻开始的连续动作序列,At=at,at+1,...,at+H−1(H=4 为动作 horizon,论文 2.3 节) | 模型需要生成的 "正确动作目标" |
| τ | 流匹配时序参数 | 取值范围 0,1,控制噪声注入强度 | τ=0 时Atτ=ε(全噪声动作),τ=1 时Atτ=At(无噪声真实动作),覆盖从噪声到真实的完整过渡 |
| ϵ | 高斯噪声 | 服从标准正态分布N(0,I)(I 为单位矩阵) | 模拟动作生成中的随机扰动,让模型学习鲁棒的去噪能力 |
| Atτ | 噪声动作块 | 由真实动作块At与噪声ε按 τ 加权混合得到,公式:Atτ=τAt+(1−τ)ϵ | 模型的输入动作样本,用于学习 "去噪→还原真实动作" 的逻辑 |
| ot | 观测值 | t 时刻的多模态观测,ot=It1,...,Itn,lt,qt(含 n 视角图像Iti、语言指令lt、机器人状态qt,论文 2.3 节) | 为动作生成提供场景上下文(如 "看到杯子""收到抓取指令") |
| vθ(Atτ,ot) | 预测去噪向量场 | 模型(参数为 θ)输出的去噪方向向量,输入是噪声动作块Atτ和观测ot | 模型预测的 "如何从噪声动作Atτ恢复到真实动作At" 的校正方向 |
| $u(A_t^{\tau} | A_t)$ | 目标去噪向量场 | 理论上的最优去噪方向,选中内容定义为ϵ−At为模型提供 "正确的去噪参考",是预测向量场的对齐目标 |
| ∣∣⋅∣∣2 | L2 范数的平方 | 计算两个向量场(预测值与目标值)的元素级误差平方和 | 量化预测偏差,是 MSE 损失的核心计算形式 |
6、数据如何转为token(可选观看)
VLM 预训练时,输出的token,进行计算损失,那么token怎么生成的????
比如,采集了一段机器人空间推理数据,能实现了某个任务,认为是成功的。那这段数据,如何转为真实 token?
- 空间推理的成功任务数据,需先整理为 "图像 + 文本指令 + 正确推理结果" 的结构化配对,
- 再通过文本 tokenizer(Ft(⋅)) 编码为数字 token 序列,
- 最终形成损失计算所需的 "真实 token"(即模型需预测的正确 token 序列)。
1. 第一步:原始空间推理数据的结构化整理
首先将 "成功完成任务的空间推理数据" 拆解为模型可识别的输入 - 输出配对,核心是明确 "文本指令" 和 "正确推理结果"(真实标签):
- 输入部分:
- 图像x:空间推理场景的图像(如 3D 室内场景、机器人工作区画面,对应论文 2.2 节 "3D 场景数据集(ScanNet/ScanNet++)");
- 文本提示y:空间推理相关的问题 / 指令(如 "机器人从窗边出发到白鞋,需先左转还是右转?""物体 A 相对于物体 B 的位置是什么?")。
- 真实输出部分:
- 正确推理结果(真实标签文本):任务成功对应的标准答案(如 "先左转,再左转""物体 A 在物体 B 的左前方 30cm 处"),需确保表述精准、符合任务要求(论文强调数据标注的高质量与准确性)。
2. 第二步:文本标准化(适配 tokenizer 编码)
对 "文本提示y" 和 "真实推理结果" 进行统一格式处理,避免歧义:
- 统一表述风格:比如空间关系用固定术语("左前方""正上方" 而非模糊表述),数字单位统一(如距离用 "cm",角度用 "°");
- 完整序列拼接:将 "文本提示y + 真实推理结果" 拼接为完整文本序列(如 "问题:机器人从窗边出发到白鞋,需先左转还是右转?答案:先左转,再左转"),确保 token 序列的连贯性。
3. 第三步:tokenizer 编码(核心转化环节)
利用论文中定义的Ft(⋅)(文本 tokenizer,如 Qwen2.5 的 tokenizer,对应 2.1 节 "搭配 Qwen2.5-1.5B/7B LLM"),将标准化后的完整文本序列转为数字 token:
- 编码逻辑:tokenizer 会为词汇表(大小m)中的每个词 / 子词分配唯一数字 ID(即 token);
- 具体转化示例:原始文本序列:"问题:机器人从窗边出发到白鞋,需先左转还是右转?答案:先左转,再左转"编码后 token 序列(示例数字):
[101, 3299, 589, ..., 678, 3345, 102](其中 101/102 为特殊标记,中间数字为对应文本的真实 token)。
4. 第四步:拆分 "前文 token" 与 "目标 token"(适配自回归损失)
根据选中内容的损失函数逻辑,将编码后的真实 token 序列拆分为两部分,用于训练:
- 前文 token(t0:N−1):文本提示y + 真实推理结果的前半部分(如 "问题:机器人从窗边出发到白鞋,需先左转还是右转?答案:先左转,")对应的 token 序列;
- 目标 token(tN):前文之后的下一个正确 token(如 "再" 对应的数字 token);
- 完整序列迭代:通过滑动窗口迭代,让模型逐 token 学习 "基于图像特征 + 前文 token,预测下一个正确 token",最终覆盖整个真实推理结果。
7、模型效果
如下表所示,与现有闭源、开源及具身相关视觉语言模型(VLMs)在12个通用具身推理基准测试上的对比,
这些基准测试涵盖具身问答、规划、具身基础定位、空间智能以及闭环仿真评估等多个维度。
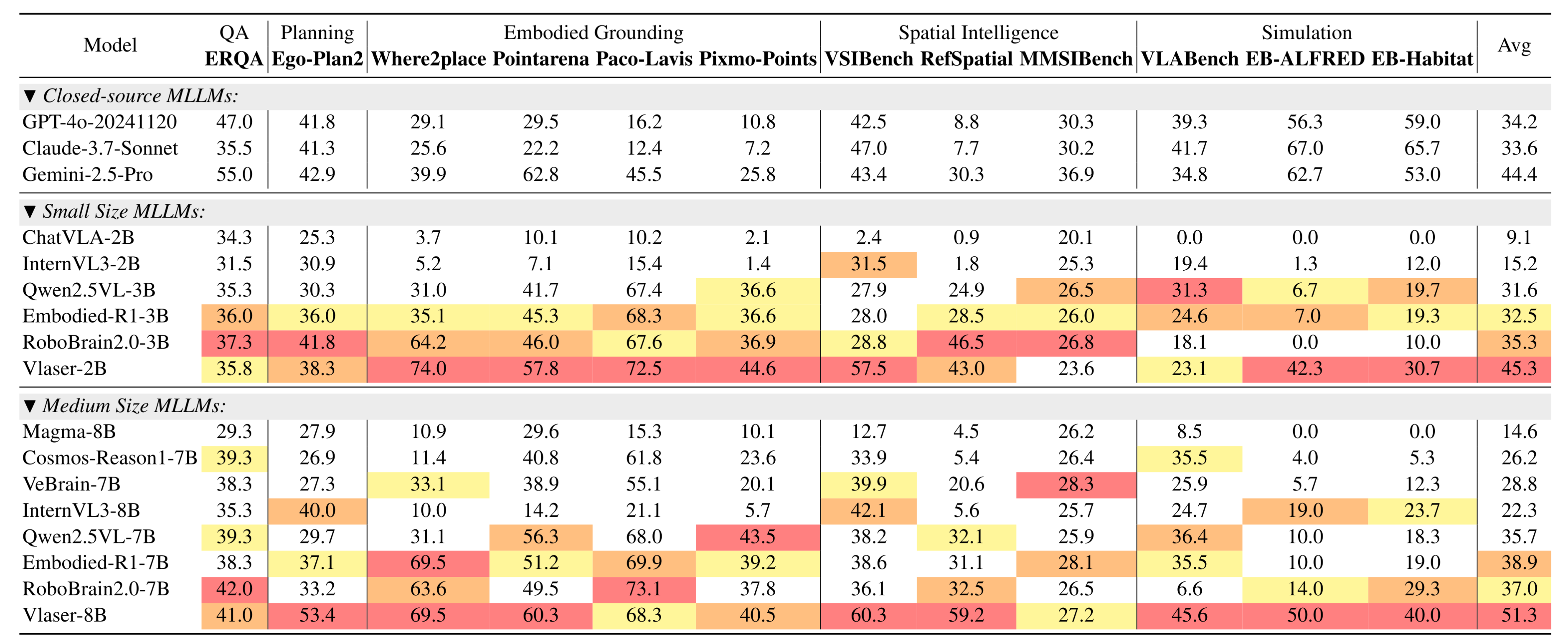
- Avg表示所有基准测试的归一化平均性能。
- 在所有基线模型中,最优、次优和第三优的分数分别用红色、橙色和黄色标注。
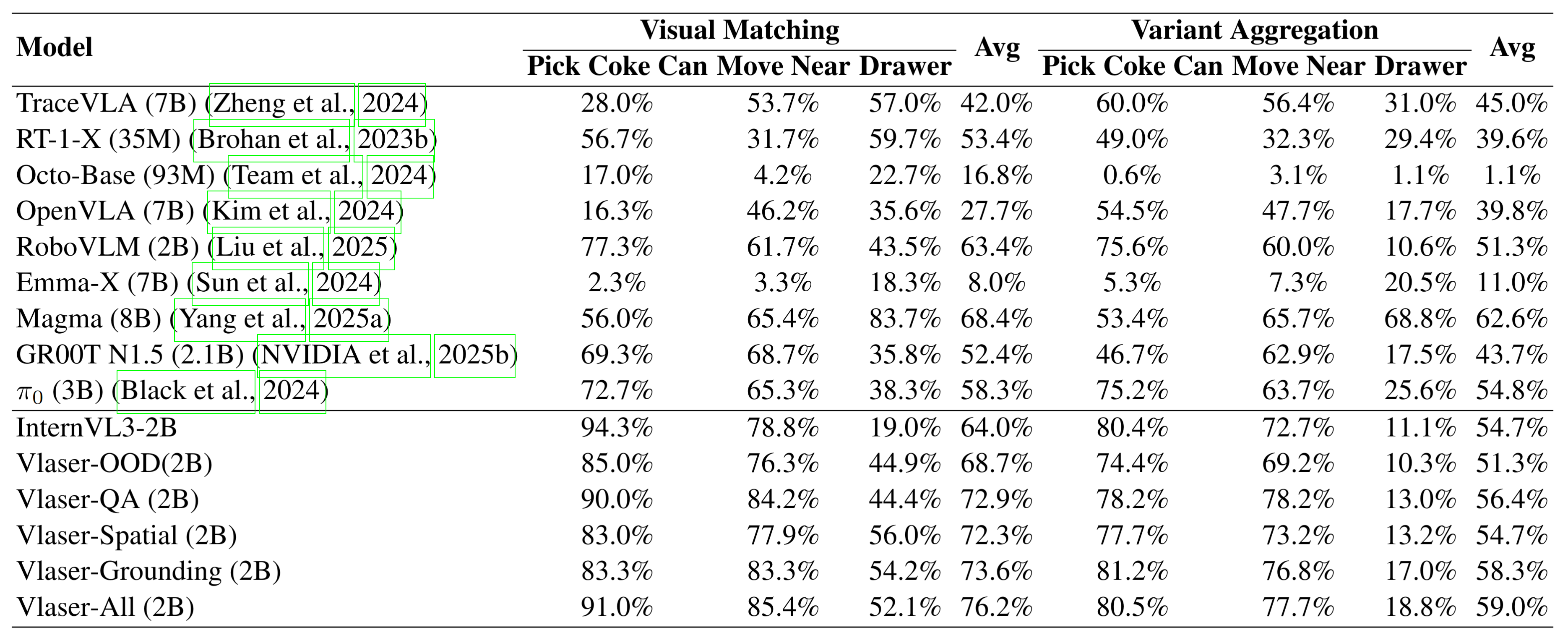
在SimplerEnv中针对Google Robot任务与现有方法的对比,Avg表示三个任务的平均成功率。
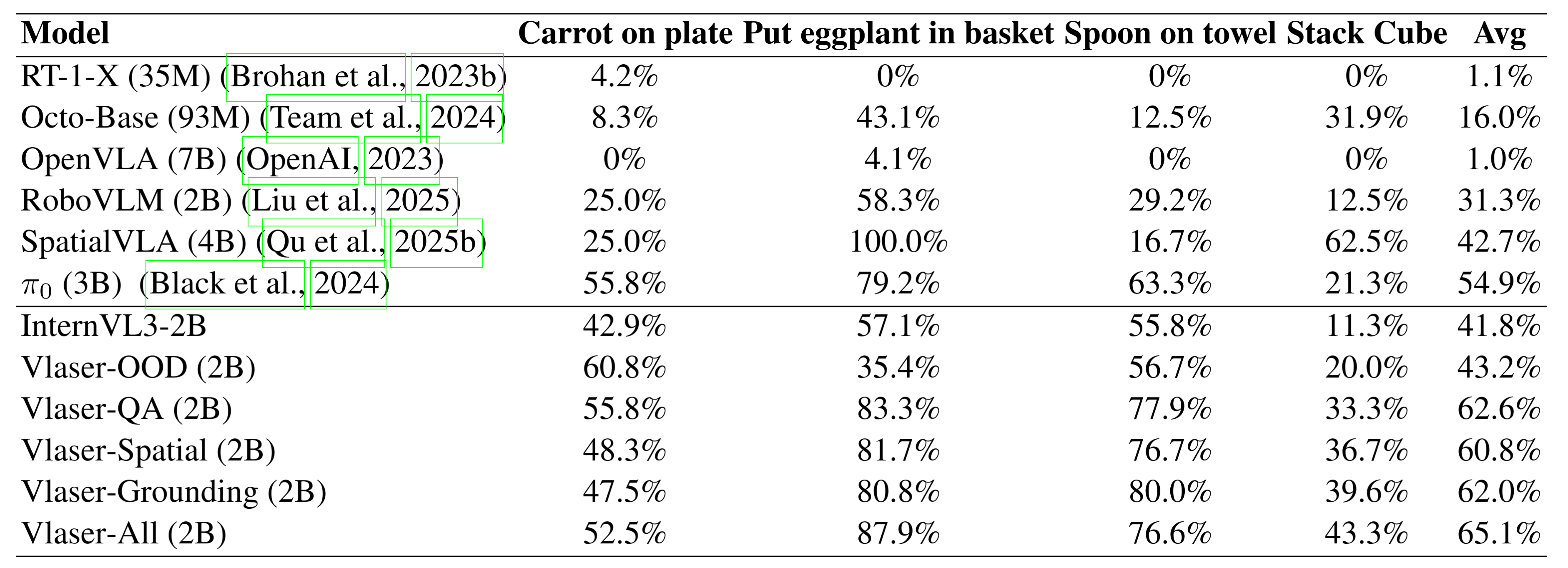
在WidowX机器人任务上的SimplerEnv评估结果, Avg表示四个任务的平均成功率。
具身问答效果1:

具身问答效果2:

具体推理:

分享完成~