大家好,今天我想和大家聊聊一个既有趣又实用的编程技能------Python网络爬虫。无论你是想做数据分析、竞品调研,还是只是单纯好奇如何从网上获取信息,这篇文章都能给你一个清晰的起点。
🤔 为什么要学网络爬虫?
在这个信息爆炸的时代,网络上的数据量呈指数级增长。无论是做数据分析、竞品调研,还是学术研究,我们都需要从海量信息中提取有价值的数据。
• 数据分析的基础:爬虫可以帮我们获取原始数据,为后续的清洗、分析和可视化打下基础
• 自动化的利器:代替人工完成重复的信息收集工作,大大提高效率
• 编程能力的试炼场:涉及HTTP协议、HTML解析、数据存储等多个知识点,能全面提升你的编程水平
📜 爬虫的"交通规则":Robots协议
在结束今天的分享前,我想再次强调遵守robots.txt的重要性。这不仅是技术问题,更是伦理问题。
• 查看目标网站的Robots协议:访问https://www.example.com/robots.txt
• 尊重网站的爬取规则:避免访问被禁止的路径
• 控制爬取频率:给服务器留有余地
🚀 Requests库:爬虫的"瑞士军刀"
作为Python爬虫的基石,requests库的强大远超你的想象。它不仅能发送简单的GET请求,还能处理各种复杂场景。
- requests库的安装
pip install requests -i https://pypi.tuna.tsinghua.edu.cn/simple

- GET请求的高级玩法
除了基础的URL访问,GET请求还可以通过params参数传递查询条件:
python
import requests
r = requests.get("https://www.ryjiaoyu.com")
print(r.text)
这种方式让我们能灵活地构造搜索请求,模拟用户在网站上的搜索行为。
• get()搜索信息
python
import requests
r = requests.get('https://www.ryjiaoyu.com//search?keyword=python')
print(r.text)
• get()添加信息
python
import requests
info = {'keyword':'excel'}
r = requests.get('https://www.bilibili.com/sarch',params = info)
print(r.url)
print(r.text)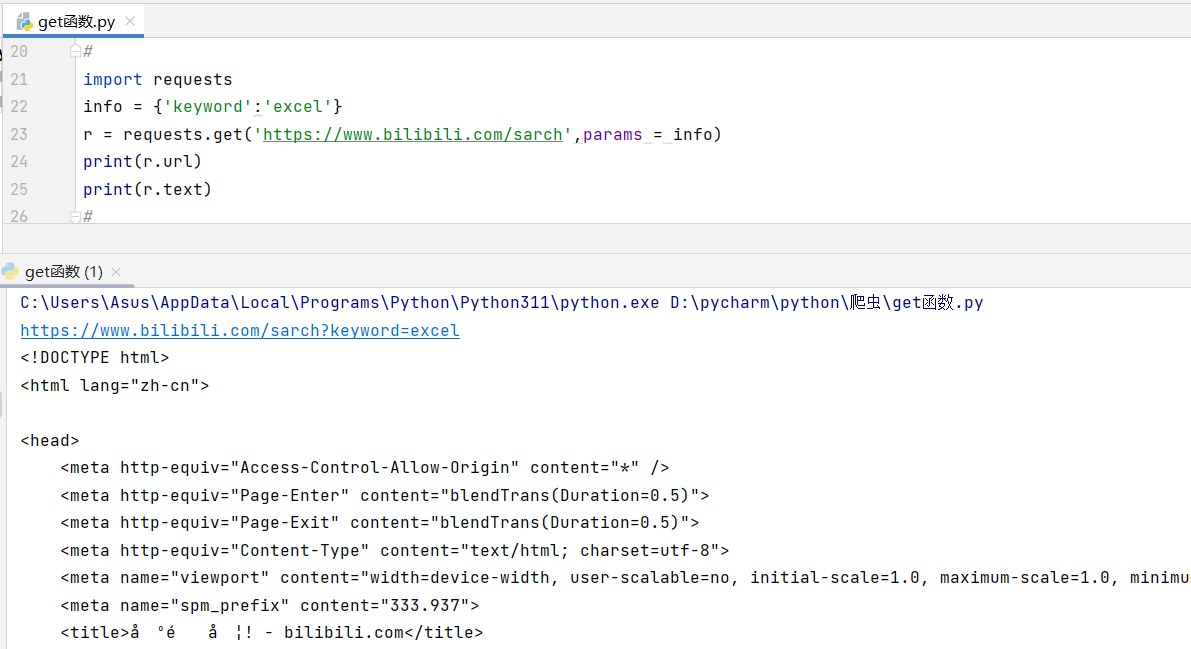
- 返回Response对象
• Response 的属性
Response包含的属性有status_code、headers、url、encoding、cookies等。
status.code(状态码):当获取一个HTML网页时,网页所在的服务器会返回一个状态码,表明本次获取网页的状态。
python
import requests
r = requests.get("https://www.baidu.com")
print(r.status_code)
print(r.headers)
print(r.url)
print(r.encoding)
print(r.cookies)
if r.status_code==200:
print(r.text)
else:
print('本次访问失败')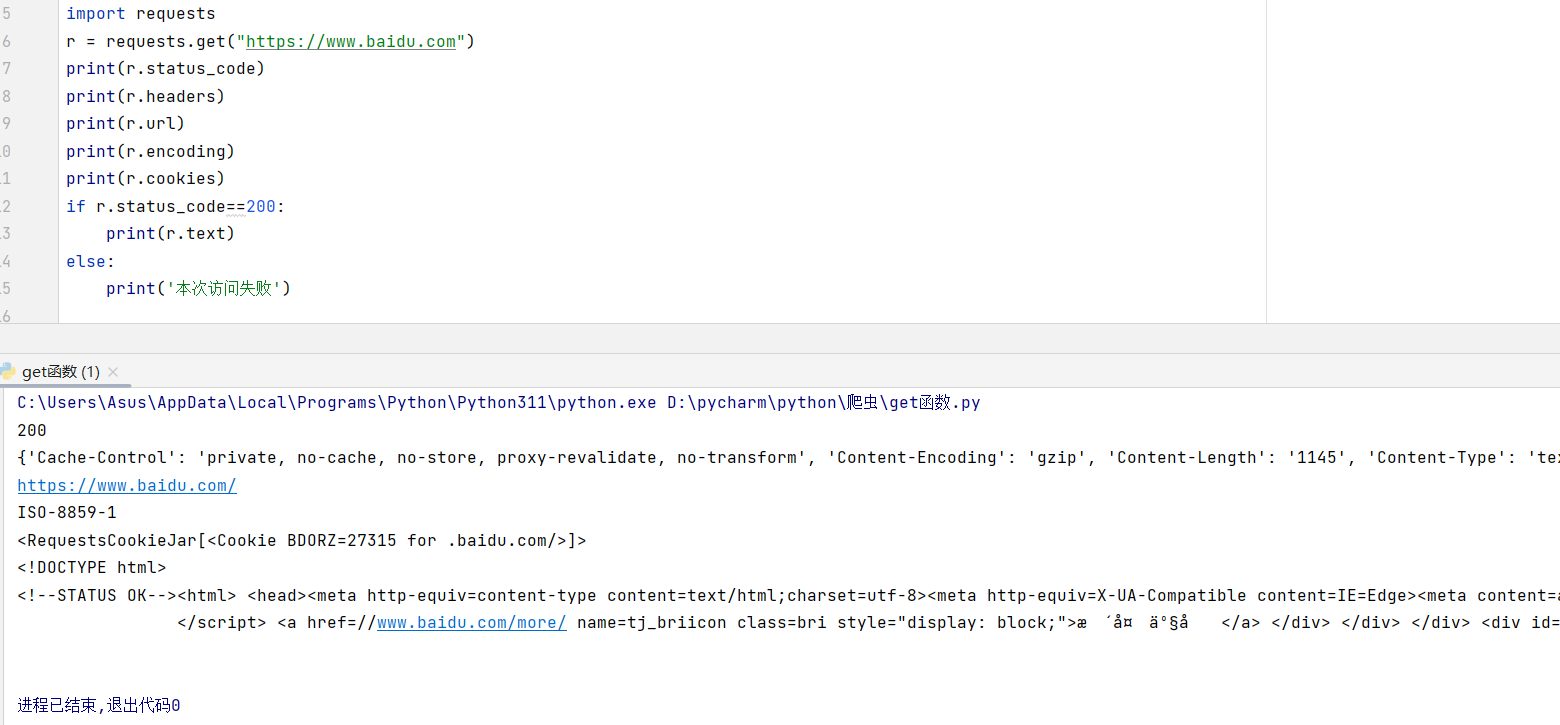
• 设置编码
python
import requests
url = "https://www.baidu.com/"
head = {"Uesr-Agent":"Mozilla/5.0(Windows NT 10.0; Win4; x64) ADpLeeBkit/537.36 (KHTML, Like Geck0) Chrome/142. 0.0.0 Safari/537.36 E/142.0.0.0"}
r = requests.get(url,headers=head)
r.encoding = r.apparent_encoding
print(r.text)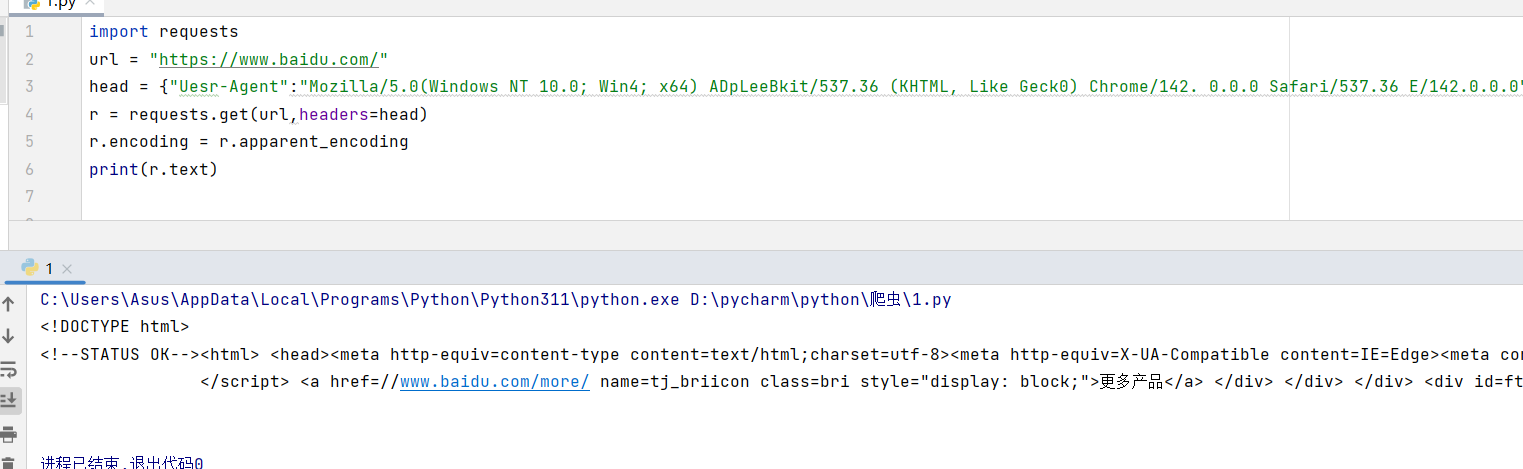
• 返回网页内容
esponse对象中返回网页内容有两种方法,分别是text()方法和content()方法,其中text()方法在前面的内容中有介绍,它是以字符串的形式返回网页内容。而content()方法是以二进制的形式返回网页内容,常用于直接保存网页中的媒体文件。
python
import requests
r = requests.get('https://cdn.ptpress.cn/uploadimg/Material/978-7-115-68312-0/72jpg/68312_s300.jpg')
f2= open('b.jpg','wb')#w表示创建写模式,b表示二进制模型
f2.write(r.content)
f2.close()
f1 = open('a.txt','w',encoding='utf-8')
f1.write('人工智能')
f1.close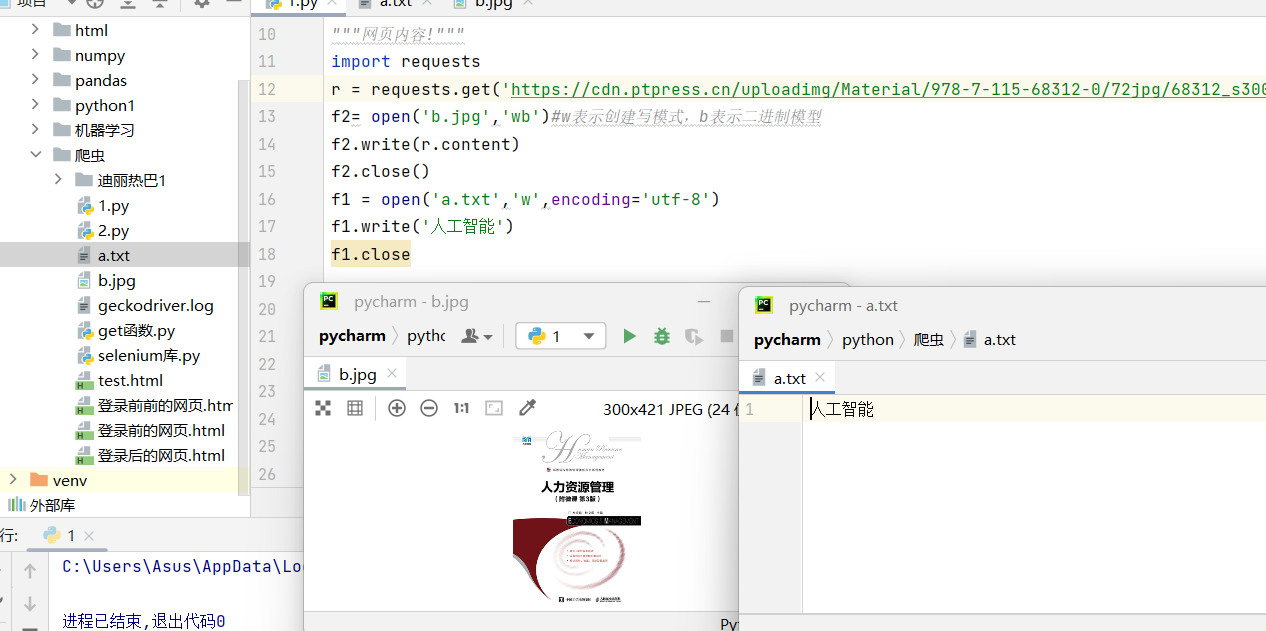
- 小项目案例:实现处理获取的网页信息
使用get()函数获取HTML网页源代码的目的在于让获取的信息为用户所用。例如获取某购物网站新上架的商品信息,由于该网站每天都可能会上架新商品,因此工作人员每天都需要进入网站观察并统计新商品信息。这些工作完全可以使用代码来完成,即通过requests库爬取网站信息,并自动识别网页中的所有新商品信息,从而实现自动化处理信息。
python
import requests
import re
r = requests.get('https://www.ryjiaoyu.com/tag/details/7')
print(r.text)
result = re.findall(r'title="(.+)">(.+)</a></h4>',r.text)
for i in range(len(result)):
print('第',i+1,'本书:',result[i][1])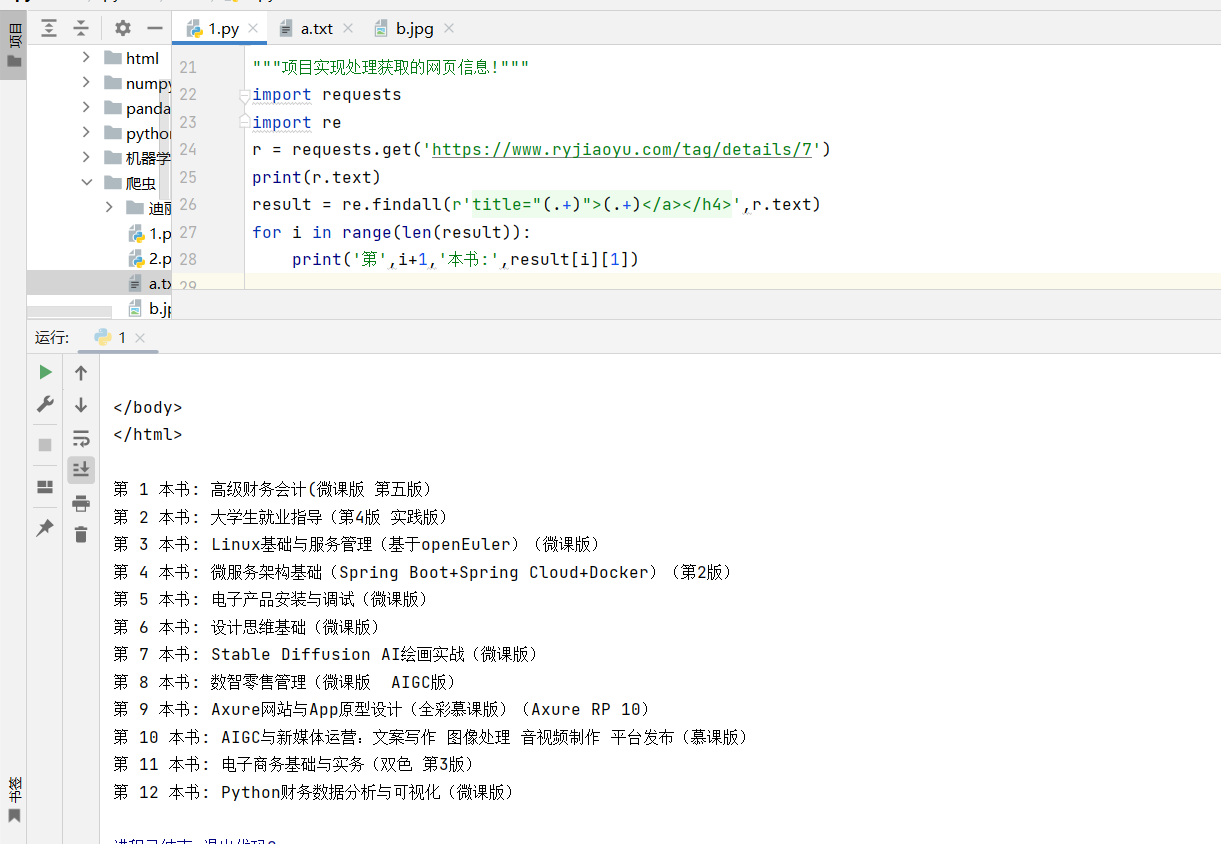
⚠️ 爬虫的伦理与法律
最后,我想强调一下爬虫的伦理和法律问题:
-
遵守Robots协议:这是最基本的礼貌
-
控制爬取频率:不要给目标网站带来过大压力
-
尊重版权:不要爬取和传播受版权保护的内容
-
注意数据隐私:避免爬取个人敏感信息
记住,技术本身是中立的,关键在于我们如何使用它。一个负责任的爬虫开发者,应该始终保持敬畏之心。