conda create -n llama_factory python=3.12 -y
conda activate llama_factory
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
pip install -e ".torch,metrics"
llamafactory-cli version
启动Web UIllamafactory-cli webui
http://localhost:7860/
1. 检查点路径(Checkpoint Path)
- 作用:指定训练过程中保存的模型权重文件路径。
- 说明 :
- 如果你之前训练过模型,可以填入该路径来加载预训练的检查点继续训练;
- 如果是第一次训练,留空即可(会从头开始);
- 输出的最终模型也会保存到这个路径。
示例:
./output/Qwen3-8B-LoRA注意:路径必须存在或可创建,否则会报错。
2. 量化方法(Quantization Method)
当前值 :
bnb作用 :在训练时对模型进行量化压缩,以节省显存、加快推理速度。
选项说明 :
值 含义 none不做量化(默认) bnb使用 BitsAndBytes 的 4-bit 量化(推荐用于 GPU 显存不足时) fp16/bf16半精度浮点数(不叫"量化",但也是减少显存的方式) 推荐:如果你用的是消费级显卡(如 RTX 3060/4090),建议选
bnb来支持 4-bit 量化训练。
3. 对话模板(Dialogue Template)
- 当前值 :
default- 作用:定义如何将用户输入和系统提示构造成符合模型格式的 prompt。
- 常见模板 :
default:通用模板,适用于大多数模型;qwen:专为 Qwen 系列设计的模板(如 Qwen3、Qwen2);chatml:类似 OpenAI ChatML 格式;llama-2/vicuna:对应特定模型的对话结构。当前你使用的是 Qwen3-8B-Base ,建议选择
qwen模板以获得最佳效果。
若选错模板可能导致模型无法理解上下文。
4. RoPE 插值方法(RoPE Interpolation Method)
- 当前值 :
none- 作用 :处理模型在长序列生成时的位置编码问题。
- 背景知识 :
- RoPE(Rotary Position Embedding)是 LLaMA 等模型使用的位置编码方式;
- 默认只支持固定长度(如 2048 tokens),超过则需插值;
- 插值方法决定如何扩展位置编码到更长序列。
选项说明:
值 含义 none不做插值,仅支持原生最大长度(如 2048) linear线性插值,简单但可能影响性能 dynamic动态插值,更适合长文本(推荐用于 >4096 tokens) 如果你的数据或推理需要超长上下文(>2048 tokens),建议设为
dynamic;否则none即可。
5. 加速方式(Accelerate Method)
当前值 :
auto作用:选择训练过程中的硬件加速策略。
选项说明 :
值 含义 auto自动检测设备(CPU/GPU/Multi-GPU)并启用最优加速(推荐) cpu仅用 CPU 训练(慢) gpu使用单张 GPU dp/ddp多卡并行训练(DP: 数据并行;DDP: 分布式数据并行) 对于大多数用户,
auto是最安全的选择,它会自动判断是否可用 GPU 并开启相应加速。
建议配置
配置项 推荐值 说明 检查点路径 ./output/Qwen3-8B-LoRA可自定义输出路径 量化方法 bnb节省显存,适合消费级显卡 对话模板 qwen匹配 Qwen3 模型 RoPE 插值方法 none或dynamic若用长文本选 dynamic加速方式 auto自动适配硬件
其中:
1. 量化等级(Quantization Level)
- 当前值 :
4- 作用 :指定使用 QLoRA(Quantized LoRA)时的量化位数。
- 说明 :
QLoRA 是一种在训练时对基础模型进行 低比特量化 的技术,可大幅减少显存占用;
常见选项为
4或8:
值 含义 4使用 4-bit 量化(最常用),显存节省最多,但精度略有下降 8使用 8-bit 量化,比 4-bit 更稳定,适合对精度要求高的场景 推荐:如果你用的是消费级显卡(如 RTX 3060/4090),建议选
4,以支持更小显存下的训练。
2. 量化方法(Quantization Method)
当前值 :
bnb作用:选择实现量化所使用的算法库。
选项说明 :
方法 全称 特点 推荐场景 bnbBitsAndBytes 支持 4-bit 量化,性能好,兼容性强 最常用,推荐首选 hqqHQQ (High Precision Quantization) 精度更高,但依赖特定库 实验性较强,需额外安装 eetqEfficient and Exact Tensor Quantization 轻量级量化,适用于推理 不常用于训练 当前你选择了
bnb,这是目前最成熟、最广泛支持的 4-bit 量化方案。
注意:要使用bnb,必须确保已安装bitsandbytes包:
pip install bitsandbytes
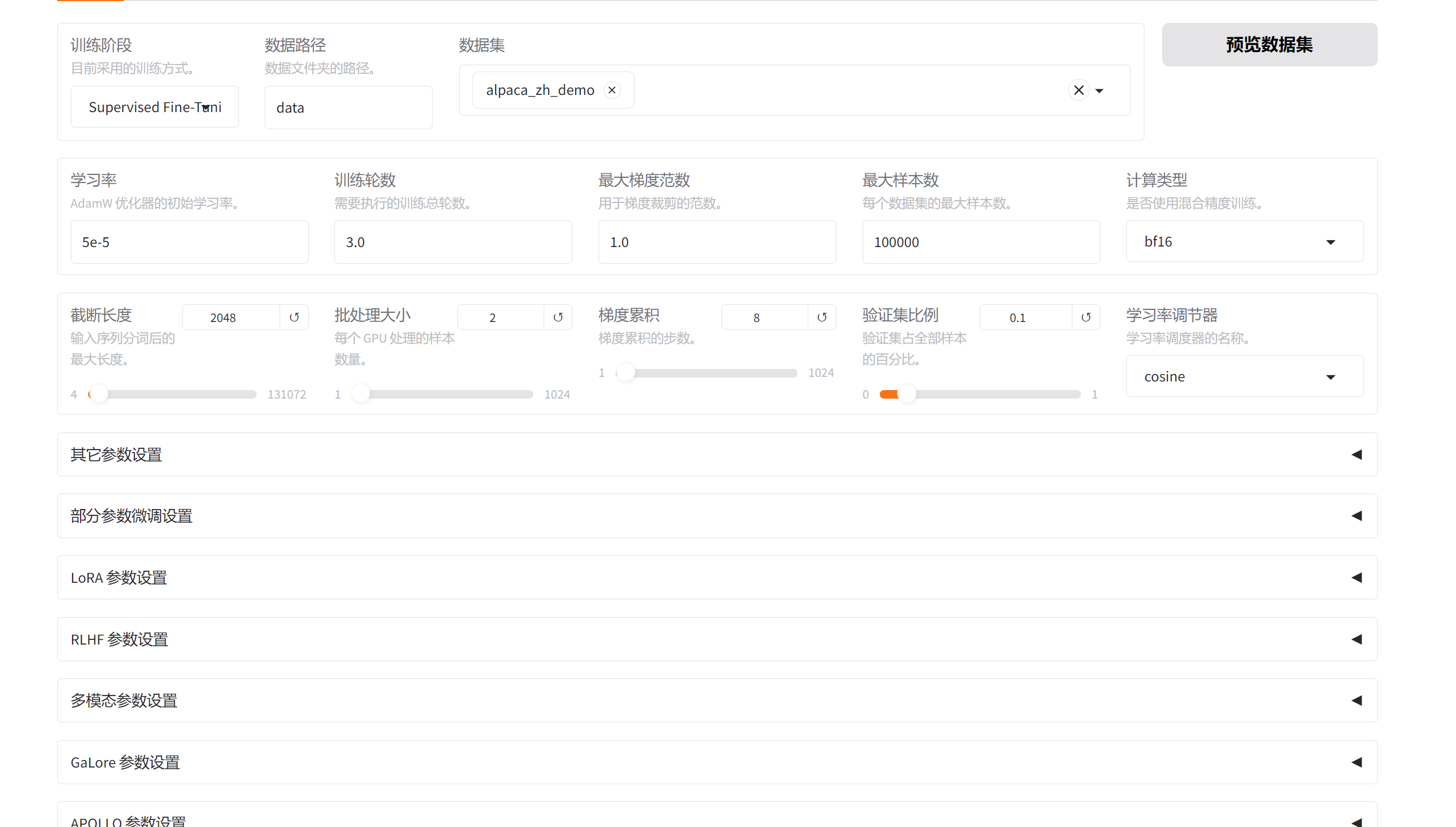
一、训练阶段(Training Stage)
1. 训练阶段(Training Stage)
- 当前值 :
Supervised Fine-Tuning(已选)- 作用:选择微调方法。
- 选项说明:
方法 含义 适用场景 Supervised Fine-Tuning(SFT)监督式微调,使用"输入-输出"对进行训练 最常用,适合指令学习、角色扮演等任务 Reward Modeling奖励建模,用于强化学习(RLHF)的第一步 需要人工标注偏好数据 PPOProximal Policy Optimization,强化学习算法 RLHF 的第二步,优化策略 DPODirect Preference Optimization,直接偏好优化 比 PPO 更简单高效,无需奖励模型 KTOKullback-Leibler Training Objective,KL 散度优化 控制输出与原始模型的一致性 Pre-Training预训练,从头训练模型 极少用,需要海量数据 推荐:大多数用户应选择
Supervised Fine-Tuning,即 SFT。
二、数据相关配置
2. 数据路径(Data Path)
当前值 :
data作用:指定训练数据文件夹的路径。
要求 :
- 文件夹中必须包含一个或多个
.jsonl或.csv格式的训练数据;- 数据格式需符合 LLaMA Factory 要求(见下文);
示例结构:
data/ └── train.jsonl3. 数据集(Dataset)
- 作用:从内置数据集中选择预定义的数据集。
- 说明 :
- 这些是 LLaMA Factory 内置的示例数据集,供用户快速测试;
- 如果你有自己的数据,可以忽略此选项,直接通过"数据路径"上传;
- 常见内置数据集列表:
数据集名 含义 语言 类型 identity每个输入直接返回原样(用于测试) 任意 测试用 alpaca_en_demo英文 Alpaca 示例数据 英文 SFT alpaca_zh_demo中文 Alpaca 示例数据 中文 SFT glaive_toolcall_en_demo英文工具调用示例 英文 Tool Use glaive_toolcall_zh_demo中文工具调用示例 中文 Tool Use mlm_demo掩码语言建模(MLM)示例 任意 MLM mlm_audio_demo/mlm_video_demo多模态 MLM 示例 任意 多模态 alpaca_en/alpaca_zh完整版 Alpaca 数据集 英文/中文 SFT alpaca_gpt4_en/alpaca_gpt4_zhGPT-4 生成的高质量 Alpaca 数据 英文/中文 高质量 SFT 推荐:
- 初学者 → 使用
alpaca_zh_demo快速测试;- 自定义数据 → 不选任何数据集,只填"数据路径"。
4. 预览数据集
- 功能:点击后可查看数据内容,确认格式是否正确。
- 建议:每次训练前都点一下,避免因数据格式错误导致训练失败。
三、训练超参数(Hyperparameters)
5. 学习率(Learning Rate)
- 当前值 :
5e-5- 作用:AdamW 优化器的初始学习率。
- 说明 :
- 学习率决定了每次更新权重的步长;
- 值太大 → 训练不稳定,可能发散;
- 值太小 → 收敛慢;
- 推荐范围:
- Qwen3-8B 等大模型 →
1e-5~5e-5- 小模型(如 Qwen-7B)→ 可稍高(如
1e-4)
6. 训练轮数(Epochs)
- 当前值 :
3.0- 作用:整个数据集被遍历的次数。
- 说明 :
- 通常 1~5 轮足够;
- 太多容易过拟合,太少则欠拟合;
- 推荐:
2.0~3.0(对于小数据集)
7. 截断长度(Truncation Length)
- 当前值 :
2048- 作用:输入序列分词后的最大长度(token 数)。
- 说明 :
- 超出的部分会被截断;
- 与模型的最大上下文窗口一致(Qwen3-8B 支持 32K,但默认限制为 2048);
- 若你的数据较长,可适当增大(如 4096),但需注意显存占用;
- 推荐:
2048(平衡性能与内存)
8. 批处理大小(Batch Size)
- 当前值 :
2- 作用:每个 GPU 在一次迭代中处理的样本数量。
- 说明 :
- 批大小越大,训练越快,但显存需求越高;
- 受限于显存容量(如 RTX 3060 ≈ 12GB,RTX 4090 ≈ 24GB);
- 推荐:
- 单卡 RTX 3060 →
1或2- 单卡 RTX 4090 →
2~4- 多卡 → 可适当增大
9. 最大梯度范数(Max Gradient Norm)
- 当前值 :
1.0- 作用:防止梯度爆炸,控制梯度裁剪阈值。
- 说明 :
- 当梯度范数超过此值时,会自动缩放;
- 设置为
1.0是常见默认值;- 推荐:
1.0(无需修改)
10. 最大样本数(Max Samples)
- 当前值 :
100000- 作用:限制每个数据集中使用的最大样本数量。
- 说明 :
- 如果你的数据量很大(如 >10万),可以设为
None或较大值;- 设为较小值可用于快速测试;
- 推荐:根据实际数据大小调整,例如:
- 小型项目 →
10000- 中型项目 →
100000- 全量训练 →
None
11. 计算类型(Compute Type)
当前值 :
bf16作用:指定混合精度训练使用的数据类型。
选项说明 :
类型 含义 是否推荐 bf16Brain Floating Point 16-bit 推荐,稳定且节省显存 fp16Float 16-bit 速度更快,但可能有数值不稳定问题 fp32Float 32-bit 精度高,但显存占用大,不推荐 推荐:
bf16(现代 GPU 支持良好,如 NVIDIA A100/RTX 4090)
12. 梯度累积(Gradient Accumulation Steps)
- 当前值 :
8- 作用:模拟更大的 batch size,当显存不足时使用。
- 说明 :
- 实际 batch size =
批处理大小 × 梯度累积步数;- 例如:batch=2,accum=8 → 相当于 batch=16;
- 用于在有限显存下实现更大批量训练;
- 推荐:
- 显存不足 → 使用
8~16- 显存充足 → 可设为
1
13. 验证集比例(Validation Split Ratio)
- 当前值 :
0- 作用:从训练集中划分出多少比例作为验证集。
- 说明 :
- 用于监控训练过程中的性能变化;
- 一般设为
0.1(10%);- 若为
0,则不划分验证集;- 推荐:
0.1(除非你已经有独立的验证集)
14. 学习率调节器(Learning Rate Scheduler)
当前值 :
cosine作用:控制学习率随训练进度的变化方式。
选项说明 :
调节器 含义 推荐场景 cosine余弦退火,先下降后缓慢收敛 最常用,适合大多数任务 linear线性衰减 简单直观 constant固定学习率 不推荐,易发散 推荐:
cosine
推荐配置组合(SFT + Qwen3-8B)
参数 推荐值 说明 训练阶段 Supervised Fine-Tuning 基础微调 数据路径 ./data存放 .jsonl 或 .csv 文件 训练轮数 3.0 一般够用 最大梯度范数 1.0 默认值 最大样本数 100000 根据数据量调整 计算类型 bf16 稳定高效 批处理大小 2 适配主流显卡 梯度累积 8 模拟大 batch 验证集比例 0.1 监控训练效果 学习率调节器 cosine 平滑收敛
四、高级参数设置(可展开)
这些是针对特定微调方法或优化技术的高级选项,通常用于专业用户。
1.其它参数设置
- 包括学习率、权重衰减等,可在展开后配置。
2. 部分参数微调设置
- 用于冻结部分层,只训练特定模块。
3. LoRA 参数设置
- LoRA 微调的关键参数,如:
r:秩(rank),决定 LoRA 的复杂度;lora_alpha:缩放因子;lora_dropout:Dropout 率;- 通常保持默认即可(如 r=8, alpha=16, dropout=0.05)。
4. RLHF 参数设置
- 作用:配置强化学习从人类反馈(Reinforcement Learning from Human Feedback)相关参数。
- 适用场景 :
- 使用
Reward Modeling、PPO、DPO等 RLHF 方法时启用;- 包括奖励模型训练、策略优化等超参数;
- 常见参数:
beta:DPO 中的 KL 散度权重;gamma:PPO 中的折扣因子;kl_coef:KL 惩罚系数;- 注意:普通 SFT 微调无需修改此部分。
5. 多模态参数设置
- 作用:配置支持图像、音频、视频等多模态输入的模型训练参数。
- 适用场景 :
- 使用 Qwen-VL、Qwen-Audio 等多模态模型;
- 需要处理图文混合数据;
- 示例参数:
- 图像分辨率;
- 视频帧率;
- 多模态编码器类型;
- 注意:纯文本模型无需开启。
6. GaLore 参数设置
- 作用:配置 GaLore(Gradient Low-Rank Optimization)算法,一种高效的梯度压缩技术。
- 功能 :
- 在训练中对梯度进行低秩近似,减少显存占用;
- 适用于大模型训练;
- 推荐用途:
- 当显存不足时使用;
- 可显著降低内存需求,但可能轻微影响收敛速度;
- 注意:仅在需要节省显存时启用。
7. APOLLO 参数设置
- 作用:配置 APOLLO(Adaptive Parameter Optimization for Large-scale Language Models)算法。
- 功能 :
- 动态调整学习率和优化器参数;
- 提高训练稳定性;
- 适合场景:
- 复杂任务、长序列训练;
- 对训练稳定性要求高的项目;
- 注意:属于实验性功能,建议先测试。
8. BAdam 参数设置
- 作用:配置 BAdam(Block-wise Adaptive Momentum)优化器。
- 功能 :
- 将模型参数按块划分,分别应用不同的自适应动量;
- 提升训练效率;
- 优点:
- 更好的参数更新策略;
- 减少震荡;
- 注意:替代标准 AdamW 的高级优化器。
9. SwanLab 参数设置
- 作用:集成 SwanLab(可视化训练监控平台)。
- 功能 :
- 实时上传训练日志、损失曲线、学习率变化等;
- 支持在线查看训练过程;
- 使用方式:
- 需注册 SwanLab 账号;
- 输入 API Key 后即可自动同步;
- 注意:若不使用,可忽略。
二、训练控制按钮
1. 预览命令
功能:点击后显示当前所有参数对应的完整训练命令行。
用途 :
- 便于复制到终端运行;
- 或用于调试、记录配置;
示例输出:
python train.py --model_name Qwen/Qwen3-8B-Base --data_path ./data --learning_rate 5e-5 ...
2. 保存训练参数
- 功能 :将当前配置保存为
.yaml文件。- 用途 :
- 方便后续复用;
- 共享配置给他人;
- 默认路径:
train_YYYY-MM-DD-HH-MM-SS.yaml
3. 载入训练参数
- 功能 :加载之前保存的
.yaml配置文件。- 用途 :
- 快速恢复历史配置;
- 批量训练不同实验;
- 支持格式:
.yaml文件
4. 开始 / 中断
- 开始:启动训练任务;
- 中断:停止正在进行的训练;
- 注意:
- 开始后会弹出终端窗口或后台运行;
- 中断后可选择是否保存中间检查点。
三、输出与设备配置
1. 输出目录(Output Directory)
- 当前值 :
train_2026-01-30-16-00-35- 作用:指定训练结果(如模型权重、日志、检查点)的保存路径。
- 说明 :
- 自动生成时间戳命名;
- 可手动修改为自定义路径;
- 例如:
./output/my_model- 推荐:保持默认,避免冲突。
2. 配置路径(Config Path)
- 当前值 :
2026-01-30-16-00-35.yaml- 作用:保存当前训练配置的 YAML 文件路径。
- 说明 :
- 记录所有参数设置;
- 便于复现实验;
- 推荐:保留原名,方便追溯。
3. 设备数量(Device Count)
- 当前值 :
1- 作用:指定参与训练的 GPU 数量。
- 说明 :
- 单卡 →
1- 多卡 →
2,4,8等;- 若设为大于可用 GPU 数,则报错;
- 推荐:根据实际硬件设置。
4. DeepSpeed stage
当前值 :
none作用:选择 DeepSpeed 分布式训练阶段。
选项说明 :
值 含义 none不使用 DeepSpeed stage-1数据并行(DP),简单易用 stage-2模型并行(MP),适合超大模型 stage-3完整模型并行 + offload,支持超大规模训练 推荐:
- 单卡 →
none- 多卡且模型较大 →
stage-1或stage-2
5. 使用 offload
- 功能:启用 DeepSpeed offload(将部分计算卸载到 CPU)。
- 作用 :
- 缓解显存压力;
- 代价是训练速度变慢;
- 适用场景:
- 显存严重不足时;
- 无法使用
bf16或fp16量化;- 注意:仅当
DeepSpeed stage不为none时生效。
推荐配置组合(SFT + Qwen3-8B)
参数 推荐值 说明 输出目录 train_...自动生成,无需修改 配置路径 ...yaml自动保存配置 设备数量 1单卡训练 DeepSpeed stage none无需分布式训练 使用 offload 关闭 除非显存不足