想象一下夏日的花丛中,成群的蜜蜂围绕着花朵忙碌地飞舞。每只蜜蜂都是一个独立的数据点,它们既保持群体聚集的形态,又不会完全重叠在一起。
这就是蜂群图 (Swarm Plot)的核心理念------在有限的空间内展示所有数据点,让每个点都能被清晰看见。
蜂群图是一种特殊的数据可视化图表,它将分类数据与数值数据结合起来,展示数据的分布情况。
与传统的条形图或箱线图不同,蜂群图不进行任何数据聚合,而是展示每一个原始数据点,避免了信息丢失。
1. 蜂群图核心特点
蜂群图最巧妙的地方在于它的布局算法。
当多个数据点具有相似数值时,它们不会简单地重叠在一起,而是像有"排斥力"一样,在垂直方向(或水平方向)上轻微偏移,形成一个类似蜂群的分布。
比如,下面是同一组数据 在散点图 和蜂群图中展示的效果。
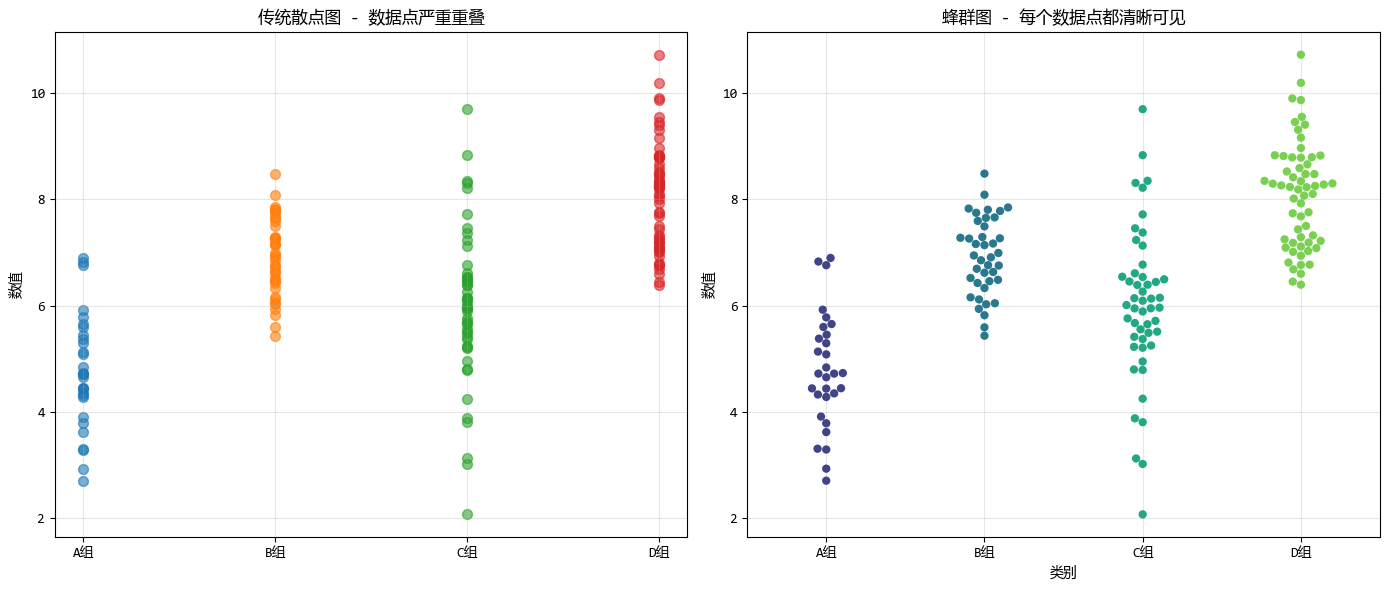
从中可以看出蜂群图的核心特点有:
- 绝不重叠: 它通过算法检测数据点的重叠情况,一旦发现两个点数值相近,就会自动把它们向水平方向推开。
- 保留分布形态: 散开后的形状,天然形成了一种类似"小提琴"或"山峰"的轮廓,直观地展示了数据的密度。
- 参数调整: 我们可以调整点的大小(marker size)和排列的紧密程度。点越大,视觉冲击力越强,但需要的水平空间也越多。
2. 蜂群图 vs. 条形图:从摘要到细节
条形图就像是一份数据摘要报告,它告诉我们每个类别的平均值或总计值,但隐藏了数据内部的分布细节。
而蜂群图则像是一次数据点的全员大会,每个数据点都有发言的机会。
下面针对同一组数据,我们分别绘制了条形图 、箱线图 和蜂群图,一起来感受一下它们之间不同的展示效果。
python
# 生成示例数据
np.random.seed(123)
categories = ["产品A", "产品B", "产品C", "产品D"]
data_comparison = []
for category in categories:
n_points = 40
if category == "产品A":
values = np.random.normal(75, 8, n_points)
elif category == "产品B":
values = np.random.normal(82, 12, n_points)
elif category == "产品C":
values = np.random.normal(65, 5, n_points)
else: # 产品D
# 创建一个双峰分布
values1 = np.random.normal(55, 6, n_points // 2)
values2 = np.random.normal(85, 7, n_points // 2)
values = np.concatenate([values1, values2])
for value in values:
data_comparison.append({"产品": category, "用户评分": value})
# 1. 条形图(平均值)
means = []
for category in categories:
cat_data = [d["用户评分"] for d in data_comparison if d["产品"] == category]
means.append(np.mean(cat_data))
bars = axes[0].bar(
categories, means, color=["#1f77b4", "#ff7f0e", "#2ca02c", "#d62728"]
)
# 在条形上标注平均值
# 省略...
# 2. 箱线图
box_data = []
for category in categories:
cat_data = [d["用户评分"] for d in data_comparison if d["产品"] == category]
box_data.append(cat_data)
boxplot = axes[1].boxplot(
box_data, tick_labels=categories, patch_artist=True, boxprops=dict(facecolor="lightblue")
)
# 省略...
# 3. 蜂群图
data_df = pd.DataFrame(data_comparison)
sns.swarmplot(
x="产品",
y="用户评分",
hue="产品",
data=data_df,
ax=axes[2],
size=5,
palette="Set2",
edgecolor="black",
linewidth=0.5,
)
# 省略...
plt.tight_layout()
plt.show()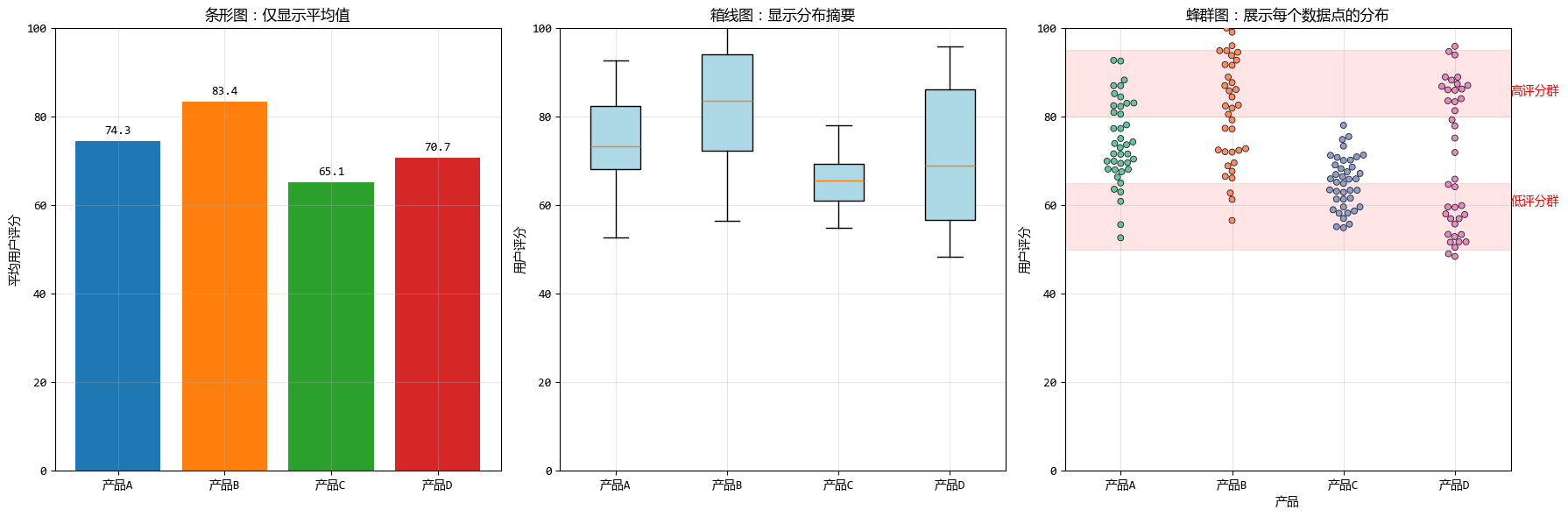
绘制蜂群图可以用seaborn这个库中的swarmplot函数。
从上面的对比可以看出:
- 条形图告诉我们产品D的平均分约为70分
- 箱线图提示产品D的数据分布范围很广
- 但只有蜂群图清晰地揭示了产品D实际上有两个明显的用户群体:一个低评分群体和一个高评分群体
3. 蜂群图 vs. 散点图:从混乱到有序
传统散点图在处理分类数据时,常常导致数据点大量重叠,形成"黑团",我们无法看清数据点的真实分布。
蜂群图通过智能布局算法解决了这个问题。
下面构造一个不同密度的数据,看看蜂群图和散点图的展示效果。
python
# 比较散点图与蜂群图的视觉效果
fig, axes = plt.subplots(1, 2, figsize=(14, 6))
# 生成具有不同密度的数据
np.random.seed(42)
density_data = []
categories = ["低密度", "中等密度", "高密度"]
for i, category in enumerate(categories):
n_points = 20 + i * 30 # 不同密度
if category == "低密度":
values = np.random.normal(50, 15, n_points)
elif category == "中等密度":
values = np.random.normal(50, 8, n_points)
else: # 高密度
values = np.random.normal(50, 4, n_points)
for value in values:
density_data.append({"类别": category, "数值": value})
# 左侧:传统散点图
for i, category in enumerate(categories):
cat_data = [d["数值"] for d in density_data if d["类别"] == category]
x_positions = np.full(len(cat_data), i)
axes[0].scatter(x_positions, cat_data, alpha=0.6, s=60, label=category)
#省略...
# 右侧:蜂群图
density_data_df = pd.DataFrame(density_data)
sns.swarmplot(
x="类别",
y="数值",
hue="类别",
data=density_data_df,
ax=axes[1],
size=6,
palette="coolwarm",
edgecolor="black",
linewidth=0.5,
)
#省略...
plt.tight_layout()
plt.show()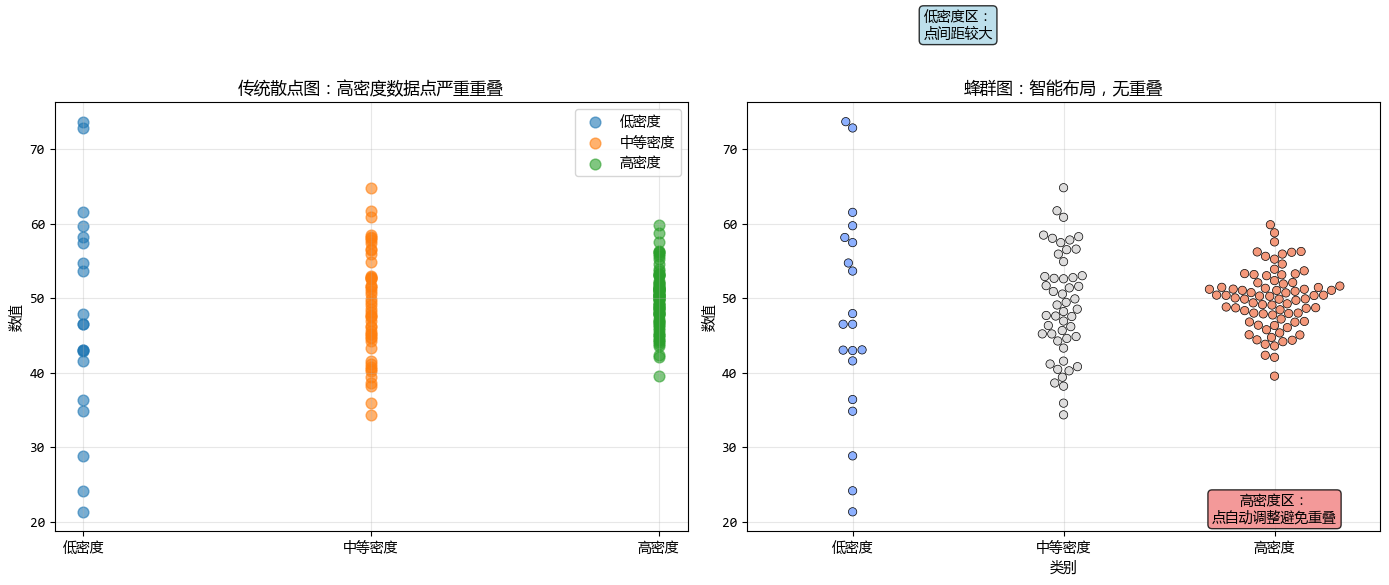
蜂群图 解决了 "重叠(Overplotting)" 的问题。在数据量适中(几百到几千个点)时,它是展示分布密度的最佳选择。
4. 蜂群图的适用场景
蜂群图 并不是为了取代条形图 或散点图,它有自己的适用场景和局限性。
适合使用蜂群图的场景:
- 样本量适中(通常少于几百个点)时,展示完整数据分布
- 需要同时看到整体趋势和个体数据点
- 数据有多个分类变量,需要比较不同类别分布
- 希望发现异常值或特殊模式(如双峰分布)
蜂群图 的局限性主要有:
- 大数据集可能导致图表过于拥挤
- 对于非常大规模数据,箱线图或小提琴图可能更合适
- 精确的数值比较不如条形图直观
5. 总结
蜂群图就像数据可视化领域的"显微镜",它让我们既能观察到数据的整体分布形态,又能看到每一个数据点的具体位置。
与只能显示摘要信息的条形图 和容易产生重叠的散点图 相比,蜂群图在显示中小型数据集的完整分布信息方面具有独特优势。
在数据可视化实践中,选择正确的图表类型就像选择正确的工具一样重要。
当下一次你需要展示分类数据的分布时,不妨尝试一下蜂群图,它可能会揭示出你从未注意到的数据秘密。
文中的完整代码共享在:蜂群图.ipynb (访问密码: 6872)