实战精讲:从零构建 RFM 会员价值模型(进阶挑战版)
前言
在你通往 AI 大模型开发的道路上,除了掌握复杂的神经网络算法,扎实的数据处理能力才是地基。大模型的训练本质上是海量数据的清洗、特征工程与价值挖掘。
今天我们要做的这个RFM 会员价值打分项目 ,虽然不涉及深度学习,但它完整演练了数据分析的核心流程:数据加载 -> 清洗 -> 特征提取 -> 量化评分 -> 可视化决策。这是每一位 AI 工程师在处理业务数据时必须具备的"基本功"。
本文将继续拆解每一步操作。在原先基础流程上我们将直接解决三个进阶难题:
- 如何抛弃死板的固定分值,使用动态百分位进行更科学的分层?
- 如何不只看总分,而是通过R/F/M 组合自动识别 8 类细分人群并制定策略?
- 如何生成一份专业的 HTML 分析报告,直接发给业务部门?
让我们开始吧!
🛠️ 第一步:环境准备与工具导入
我们需要 pandas 处理数据,matplotlib 绘图,以及新增的 jinja2 (用于生成 HTML 报告,通常随 jupyter 或 nbconvert 安装,若单独使用需 pip install jinja2)。这里建议另起一个文件进行编写,不与原先基础流程的内容合在一起。
python
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import os
from datetime import datetime
# 【关键设置】解决中文乱码
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
# 检查依赖
try:
from jinja2 import Template
except ImportError:
print("提示:生成 HTML 报告需要安装 jinja2,请运行:pip install jinja2")📂 第二步:智能加载与清洗数据
这一步我们保持稳健,确保路径兼容性和数据洁净度。
python
# 1. 获取当前脚本所在的绝对目录
script_dir = os.path.dirname(os.path.abspath(__file__))
data_path = os.path.join(script_dir, "../Data/sales_test.xlsx")
# 2. 读取数据,设 USERID 为索引
df = pd.read_excel(data_path, index_col='USERID')
# 3. 数据清洗:删除全空行
sale_data = df.dropna(how='all')
print(f"✅ 数据加载完成。有效用户数:{sale_data.index.nunique()},订单记录数:{len(sale_data)}")输出结果:

🧠 第三步:核心指标计算 (R, F, M)
逻辑不变:按用户分组,分别计算最近消费时间、消费频次、消费总额。
python
# 1. F (Frequency): 订单计数
F_data = sale_data.groupby(sale_data.index)['ORDERID'].count()
# 2. M (Monetary): 金额求和
M_data = sale_data.groupby(sale_data.index)['AMOUNTINFO'].sum()
# 3. R (Recency): 最近购买日期
R_data = sale_data.groupby(sale_data.index)['ORDERDATE'].max()
# 4. 转换 R 为天数差 (以数据集中最大日期为基准,代表"距今"天数)
base_date = R_data.max()
R_days = (base_date - R_data).dt.days
# 注意:这里我们计算的是"距离最近一次购买过去了多少天"。
# 天数越小 -> 越活跃 -> 分数应该越高。🚀 第四步:进阶优化一 ------ 动态百分位打分
痛点解决 :之前的 pd.cut(..., 5) 是等距分箱。如果数据分布不均匀(例如大部分用户分数都很低,只有几个极高),等距分箱会导致大部分人都在低分段,无法区分。
解决方案 :使用 pd.qcut (Quantile Cut)。它根据排名切分,保证每个分数段的人数大致相等(各占 20%)。
4.1 代码实操
python
# 使用 qcut 进行五分位切分 (Labels 1-5)
# duplicates='drop' 用于处理数据量过少导致分位点重复的情况
F_score = pd.qcut(F_data.rank(method='first'), q=5, labels=[1, 2, 3, 4, 5], duplicates='drop')
M_score = pd.qcut(M_data.rank(method='first'), q=5, labels=[1, 2, 3, 4, 5], duplicates='drop')
# R 的特殊逻辑:
# R_days 越小越好。
# qcut 默认从小到大分箱 (第1箱是最小的天数)。
# 所以最小的天数 (最活跃) 落入第1箱,我们需要给它标为 5 分。
# 标签顺序反转:[5, 4, 3, 2, 1]
R_score = pd.qcut(R_days.rank(method='first'), q=5, labels=[5, 4, 3, 2, 1], duplicates='drop')
# 合并数据
rfm_df = pd.DataFrame({
'r_score': R_score.astype(int),
'f_score': F_score.astype(int),
'm_score': M_score.astype(int),
'R_days': R_days,
'F_count': F_data,
'M_sum': M_data
}, index=R_data.index)
# 计算加权总分 (权重可根据业务调整)
rfm_df['total_score'] = rfm_df['r_score']*0.2 + rfm_df['f_score']*0.2 + rfm_df['m_score']*0.6
print("✅ 动态百分位打分完成。前 5 名用户:")
print(rfm_df.sort_values('total_score', ascending=False).head())📝 操作要点:
- 前5名用户:
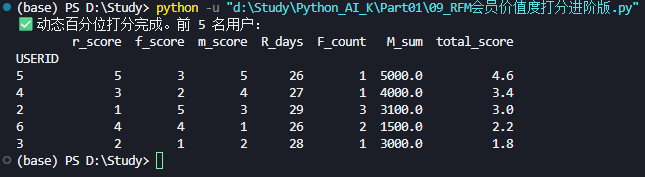
rank(method='first'):防止完全相同的数值在分位时被强行拆分报错。qcutvscut:cut切的是数值范围 (如 0-100, 100-200),qcut切的是人数比例 (前 20%, 次 20%...)。在用户分层中,qcut通常更能反映相对价值。
🎯 第五步:进阶优化二 ------ 8 类细分人群自动识别
痛点解决:总分相同的人,可能结构完全不同。
- 用户 A (5,1,1):刚买过一次大额商品的新客 (R高, F低, M高)。
- 用户 B (3,3,3):表现平平的普通用户。
- 策略必须不同!我们将根据 R/F/M 的高低(以 3 分为界),将用户划分为 8 类。
5.1 定义规则与自动打标
python
def get_customer_segment(row):
r = row['r_score']
f = row['f_score']
m = row['m_score']
# 定义高低阈值 (>=3 为高,<3 为低)
r_level = '高' if r >= 3 else '低'
f_level = '高' if f >= 3 else '低'
m_level = '高' if m >= 3 else '低'
# 8 种组合逻辑与营销建议
if r_level == '高' and f_level == '高' and m_level == '高':
return "重要价值客户", "维持 VIP 待遇,提供专属客服,推荐新品,防止流失。"
elif r_level == '低' and f_level == '高' and m_level == '高':
return "重要挽留客户", "高危流失!老土豪很久没来了。立即发送大额召回券,电话回访。"
elif r_level == '高' and f_level == '低' and m_level == '高':
return "重要发展客户", "新的大额客户。引导办理会员,增加复购频次,建立信任。"
elif r_level == '高' and f_level == '高' and m_level == '低':
return "一般价值客户", "高频低价(可能是羊毛党)。尝试交叉销售高毛利产品,提升客单价。"
elif r_level == '低' and f_level == '低' and m_level == '高':
return "重要唤醒客户", "曾经买过大单但很久没来且不再回购。调查原因,推送强力促销。"
elif r_level == '低' and f_level == '高' and m_level == '低':
return "一般挽留客户", "以前常买便宜货,现在不来了。发送小额无门槛券试探。"
elif r_level == '高' and f_level == '低' and m_level == '低':
return "新客户/潜力客户", "刚买了一次便宜货。通过新人礼包引导第二次购买。"
else: # 低 低 低
return "低价值客户", "非目标群体。减少营销投入,仅在大型活动时群发通知。"
# 应用函数
rfm_df[['客户类型', '营销策略']] = rfm_df.apply(get_customer_segment, axis=1, result_type='expand')
print("\n✅ 8 类人群划分完成。各类型人数统计:")
print(rfm_df['客户类型'].value_counts())📝 技术要点:
- 客户类型:

- 这段代码将冰冷的数字转化为了可执行的业务指令。
apply(..., axis=1)是 Pandas 中逐行处理复杂逻辑的标准写法。- 现在,运营人员拿到表格,直接看"营销策略"列就知道该给谁发什么券了。
📊 第六步:可视化与 HTML 报告生成
我们不仅要画图,还要生成一个包含图表、数据表和策略建议的 HTML 文件,方便直接邮件发送。
6.1 绘制核心图表
python
# 设置画布
fig, axes = plt.subplots(1, 2, figsize=(16, 6))
# 图 1: 8 类人群分布
type_counts = rfm_df['客户类型'].value_counts()
colors = plt.cm.Set3(np.linspace(0, 1, len(type_counts)))
axes[0].barh(type_counts.index, type_counts.values, color=colors)
axes[0].set_title('RFM 8 类客户人群分布', fontsize=14, weight='bold')
axes[0].set_xlabel('人数')
for i, v in enumerate(type_counts.values):
axes[0].text(v + 0.1, i, str(v), va='center')
# 图 2: 各类型平均贡献金额
avg_m = rfm_df.groupby('客户类型')['M_sum'].mean().sort_values(ascending=True)
axes[1].barh(avg_m.index, avg_m.values, color='#4ECDC4')
axes[1].set_title('各类客户平均消费金额 (Monetary)', fontsize=14, weight='bold')
axes[1].set_xlabel('平均金额')
plt.tight_layout()
# 保存图片供 HTML 引用
img_path = os.path.join(script_dir, "../Data/rfm_analysis.png")
plt.savefig(img_path, dpi=300, bbox_inches='tight')
print(f"✅ 图表已保存至: {img_path}")
plt.show()由于数据集并不多,看得不算太明显:
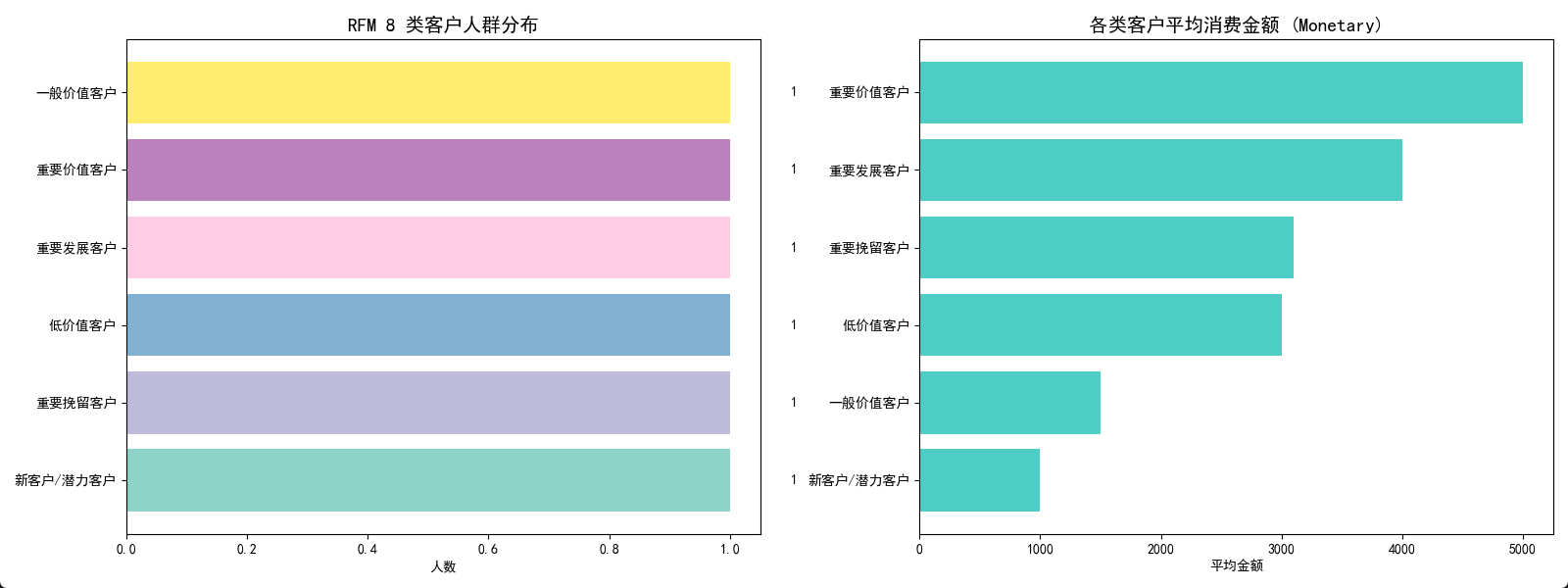
6.2 生成 HTML 报告
python
# 准备数据摘要
summary_stats = {
'total_users': len(rfm_df),
'high_value_count': len(rfm_df[rfm_df['客户类型'].str.contains('重要')]),
'top_segment': rfm_df['客户类型'].value_counts().idxmax(),
'report_time': datetime.now().strftime("%Y-%m-%d %H:%M")
}
# HTML 模板 (使用 Jinja2 语法)
html_template = """
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<title>RFM 会员价值分析报告</title>
<style>
body { font-family: 'Microsoft YaHei', sans-serif; padding: 20px; background-color: #f4f4f9; }
.container { max-width: 1000px; margin: 0 auto; background: white; padding: 30px; box-shadow: 0 0 10px rgba(0,0,0,0.1); }
h1 { color: #2c3e50; text-align: center; }
.summary { display: flex; justify-content: space-around; margin-bottom: 30px; background: #ecf0f1; padding: 20px; border-radius: 8px; }
.stat-box { text-align: center; }
.stat-num { font-size: 24px; font-weight: bold; color: #e74c3c; }
table { width: 100%; border-collapse: collapse; margin-top: 20px; }
th, td { border: 1px solid #ddd; padding: 12px; text-align: left; }
th { background-color: #34495e; color: white; }
tr:nth-child(even) { background-color: #f2f2f2; }
.img-container { text-align: center; margin: 20px 0; }
img { max-width: 100%; height: auto; }
.strategy-tip { background: #fff3cd; border-left: 5px solid #ffc107; padding: 15px; margin-top: 20px; }
</style>
</head>
<body>
<div class="container">
<h1>📊 RFM 会员价值深度分析报告</h1>
<p style="text-align: center; color: #7f8c8d;">生成时间:{{ time }}</p>
<div class="summary">
<div class="stat-box"><div>总用户数</div><div class="stat-num">{{ total }}</div></div>
<div class="stat-box"><div>重要客户数</div><div class="stat-num">{{ high_val }}</div></div>
<div class="stat-box"><div>人数最多群体</div><div class="stat-num">{{ top_seg }}</div></div>
</div>
<div class="img-container">
<img src="rfm_analysis.png" alt="RFM Analysis Charts">
</div>
<h2>🎯 重点人群营销策略预览 (前 10 条)</h2>
<table>
<thead>
<tr>
<th>用户 ID</th>
<th>客户类型</th>
<th>R/F/M 得分</th>
<th>建议策略</th>
</tr>
</thead>
<tbody>
{{ table_rows }}
</tbody>
</table>
<div class="strategy-tip">
<strong>💡 分析师建议:</strong> 请重点关注"重要挽留客户",这部分用户历史贡献大但近期流失风险高,建议优先安排专人回访。
</div>
</div>
</body>
</html>
"""
# 构建表格行 HTML
table_rows_html = ""
# 选取几个典型的不同类型的用户展示
sample_df = rfm_df.sort_values('M_sum', ascending=False).head(10)
for idx, row in sample_df.iterrows():
rfm_str = f"R:{row['r_score']} F:{row['f_score']} M:{row['m_score']}"
table_rows_html += f"""
<tr>
<td>{idx}</td>
<td><strong>{row['客户类型']}</strong></td>
<td>{rfm_str}</td>
<td>{row['营销策略']}</td>
</tr>
"""
# 渲染模板
template = Template(html_template)
html_content = template.render(
time=summary_stats['report_time'],
total=summary_stats['total_users'],
high_val=summary_stats['high_value_count'],
top_seg=summary_stats['top_segment'],
table_rows=table_rows_html
)
# 保存 HTML
html_path = os.path.join(script_dir, "../Data/rfm_report.html")
with open(html_path, 'w', encoding='utf-8') as f:
f.write(html_content)
print(f"✅ HTML 分析报告已生成:{html_path}")
print("🎉 项目全部完成!请打开 HTML 文件查看最终成果。")最后的HTML文件为:
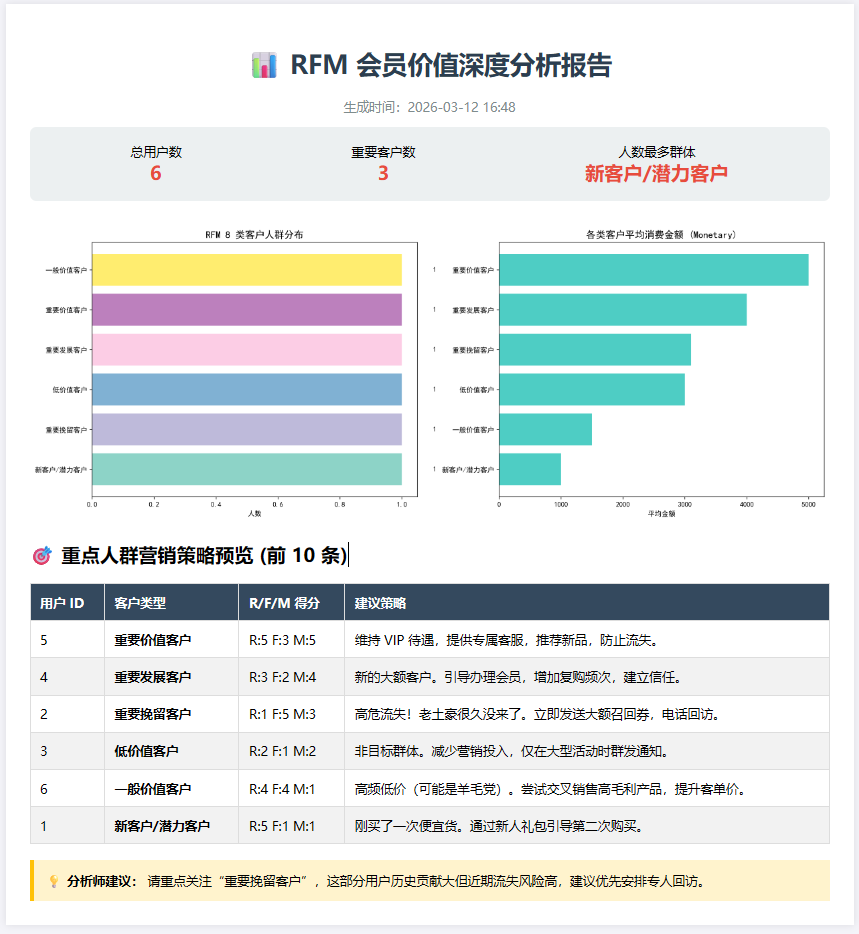
💡 总结:从代码到商业价值
通过这个进阶版项目,我们完成了三个重要的跨越:
- 从"死板"到"灵活" :利用
qcut实现了基于排名的动态分层,适应了真实数据的偏态分布。 - 从"单一"到"立体" :通过 R/F/M 组合逻辑,将用户细分为 8 类,并给出了具体的行动指南,让数据真正驱动业务。
- 从"脚本"到"产品":自动生成 HTML 报告,让分析结果可以直接交付给非技术背景的运营团队,体现了工程化的交付思维。
在 AI 大模型时代,这种**"数据清洗 + 特征工程 + 业务逻辑封装 + 自动化报告"**的能力,正是构建 Agent(智能体)和自动化工作流的基础。希望你不仅能跑通代码,更能理解背后的设计思想,将其应用到更复杂的场景中去。
本文的完整代码如下:
python
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import os
from datetime import datetime
# 【关键设置】解决中文乱码
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
# 导入 jinja2 模板引擎
try:
from jinja2 import Template
except ImportError:
print("提示:生成 HTML 报告需要安装 jinja2,请运行:pip install jinja2")
raise
# 1. 获取当前脚本所在的绝对目录
script_dir = os.path.dirname(os.path.abspath(__file__))
data_path = os.path.join(script_dir, "../Data/sales_test.xlsx")
# 2. 读取数据,设 USERID 为索引
df = pd.read_excel(data_path, index_col='USERID')
# 3. 数据清洗:删除全空行
sale_data = df.dropna(how='all')
# print(f"✅ 数据加载完成。有效用户数:{sale_data.index.nunique()},订单记录数:{len(sale_data)}")
# 1. F (Frequency): 订单计数
F_data = sale_data.groupby(sale_data.index)['ORDERID'].count()
# 2. M (Monetary): 金额求和
M_data = sale_data.groupby(sale_data.index)['AMOUNTINFO'].sum()
# 3. R (Recency): 最近购买日期
R_data = sale_data.groupby(sale_data.index)['ORDERDATE'].max()
# 4. 转换 R 为天数差 (以数据集中最大日期为基准,代表"距今"天数)
base_date = R_data.max()
R_days = (base_date - R_data).dt.days #dt.days 是 Pandas 的专用访问器,用于从"时间差"列中直接提取出具体的天数数值(去掉时间单位,只保留整数)。
# 注意:这里我们计算的是"距离最近一次购买过去了多少天"。
# 天数越小 -> 越活跃 -> 分数应该越高。
# 使用 qcut 进行五分位切分 (Labels 1-5)
# duplicates='drop' 用于处理数据量过少导致分位点重复的情况
F_score = pd.qcut(F_data.rank(method='first'), q=5, labels=[1, 2, 3, 4, 5], duplicates='drop')
M_score = pd.qcut(M_data.rank(method='first'), q=5, labels=[1, 2, 3, 4, 5], duplicates='drop')
# R 的特殊逻辑:
# R_days 越小越好。
# qcut 默认从小到大分箱 (第1箱是最小的天数)。
# 所以最小的天数 (最活跃) 落入第1箱,我们需要给它标为 5 分。
# 标签顺序反转:[5, 4, 3, 2, 1]
R_score = pd.qcut(R_days.rank(method='first'), q=5, labels=[5, 4, 3, 2, 1], duplicates='drop')
# 合并数据
rfm_df = pd.DataFrame({
'r_score': R_score.astype(int),
'f_score': F_score.astype(int),
'm_score': M_score.astype(int),
'R_days': R_days,
'F_count': F_data,
'M_sum': M_data
}, index=R_data.index)
# 计算加权总分 (权重可根据业务调整)
rfm_df['total_score'] = rfm_df['r_score']*0.2 + rfm_df['f_score']*0.2 + rfm_df['m_score']*0.6
# print("✅ 动态百分位打分完成。前 5 名用户:")
# print(rfm_df.sort_values('total_score', ascending=False).head())
def get_customer_segment(row):
r = row['r_score']
f = row['f_score']
m = row['m_score']
# 定义高低阈值 (>=3 为高,<3 为低)
r_level = '高' if r >= 3 else '低'
f_level = '高' if f >= 3 else '低'
m_level = '高' if m >= 3 else '低'
# 8 种组合逻辑与营销建议
if r_level == '高' and f_level == '高' and m_level == '高':
return "重要价值客户", "维持 VIP 待遇,提供专属客服,推荐新品,防止流失。"
elif r_level == '低' and f_level == '高' and m_level == '高':
return "重要挽留客户", "高危流失!老土豪很久没来了。立即发送大额召回券,电话回访。"
elif r_level == '高' and f_level == '低' and m_level == '高':
return "重要发展客户", "新的大额客户。引导办理会员,增加复购频次,建立信任。"
elif r_level == '高' and f_level == '高' and m_level == '低':
return "一般价值客户", "高频低价(可能是羊毛党)。尝试交叉销售高毛利产品,提升客单价。"
elif r_level == '低' and f_level == '低' and m_level == '高':
return "重要唤醒客户", "曾经买过大单但很久没来且不再回购。调查原因,推送强力促销。"
elif r_level == '低' and f_level == '高' and m_level == '低':
return "一般挽留客户", "以前常买便宜货,现在不来了。发送小额无门槛券试探。"
elif r_level == '高' and f_level == '低' and m_level == '低':
return "新客户/潜力客户", "刚买了一次便宜货。通过新人礼包引导第二次购买。"
else: # 低 低 低
return "低价值客户", "非目标群体。减少营销投入,仅在大型活动时群发通知。"
# 应用函数
rfm_df[['客户类型', '营销策略']] = rfm_df.apply(get_customer_segment, axis=1, result_type='expand')
# print("\n✅ 8 类人群划分完成。各类型人数统计:")
# print(rfm_df['客户类型'].value_counts())
# 设置画布
fig, axes = plt.subplots(1, 2, figsize=(16, 6))
# 图 1: 8 类人群分布
type_counts = rfm_df['客户类型'].value_counts()
colors = plt.cm.Set3(np.linspace(0, 1, len(type_counts)))
axes[0].barh(type_counts.index, type_counts.values, color=colors)
axes[0].set_title('RFM 8 类客户人群分布', fontsize=14, weight='bold')
axes[0].set_xlabel('人数')
for i, v in enumerate(type_counts.values):
axes[0].text(v + 0.1, i, str(v), va='center')
# 图 2: 各类型平均贡献金额
avg_m = rfm_df.groupby('客户类型')['M_sum'].mean().sort_values(ascending=True)
axes[1].barh(avg_m.index, avg_m.values, color='#4ECDC4')
axes[1].set_title('各类客户平均消费金额 (Monetary)', fontsize=14, weight='bold')
axes[1].set_xlabel('平均金额')
plt.tight_layout()
# 保存图片供 HTML 引用
img_path = os.path.join(script_dir, "../Data/rfm_analysis.png")
plt.savefig(img_path, dpi=300, bbox_inches='tight')
# print(f"✅ 图表已保存至: {img_path}")
# plt.show()
# 准备数据摘要
summary_stats = {
'total_users': len(rfm_df),
'high_value_count': len(rfm_df[rfm_df['客户类型'].str.contains('重要')]),
'top_segment': rfm_df['客户类型'].value_counts().idxmax(),
'report_time': datetime.now().strftime("%Y-%m-%d %H:%M")
}
# HTML 模板 (使用 Jinja2 语法)
html_template = """
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<title>RFM 会员价值分析报告</title>
<style>
body { font-family: 'Microsoft YaHei', sans-serif; padding: 20px; background-color: #f4f4f9; }
.container { max-width: 1000px; margin: 0 auto; background: white; padding: 30px; box-shadow: 0 0 10px rgba(0,0,0,0.1); }
h1 { color: #2c3e50; text-align: center; }
.summary { display: flex; justify-content: space-around; margin-bottom: 30px; background: #ecf0f1; padding: 20px; border-radius: 8px; }
.stat-box { text-align: center; }
.stat-num { font-size: 24px; font-weight: bold; color: #e74c3c; }
table { width: 100%; border-collapse: collapse; margin-top: 20px; }
th, td { border: 1px solid #ddd; padding: 12px; text-align: left; }
th { background-color: #34495e; color: white; }
tr:nth-child(even) { background-color: #f2f2f2; }
.img-container { text-align: center; margin: 20px 0; }
img { max-width: 100%; height: auto; }
.strategy-tip { background: #fff3cd; border-left: 5px solid #ffc107; padding: 15px; margin-top: 20px; }
</style>
</head>
<body>
<div class="container">
<h1>📊 RFM 会员价值深度分析报告</h1>
<p style="text-align: center; color: #7f8c8d;">生成时间:{{ time }}</p>
<div class="summary">
<div class="stat-box"><div>总用户数</div><div class="stat-num">{{ total }}</div></div>
<div class="stat-box"><div>重要客户数</div><div class="stat-num">{{ high_val }}</div></div>
<div class="stat-box"><div>人数最多群体</div><div class="stat-num">{{ top_seg }}</div></div>
</div>
<div class="img-container">
<img src="rfm_analysis.png" alt="RFM Analysis Charts">
</div>
<h2>🎯 重点人群营销策略预览 (前 10 条)</h2>
<table>
<thead>
<tr>
<th>用户 ID</th>
<th>客户类型</th>
<th>R/F/M 得分</th>
<th>建议策略</th>
</tr>
</thead>
<tbody>
{{ table_rows }}
</tbody>
</table>
<div class="strategy-tip">
<strong>💡 分析师建议:</strong> 请重点关注"重要挽留客户",这部分用户历史贡献大但近期流失风险高,建议优先安排专人回访。
</div>
</div>
</body>
</html>
"""
# 构建表格行 HTML
table_rows_html = ""
# 选取几个典型的不同类型的用户展示
sample_df = rfm_df.sort_values('M_sum', ascending=False).head(10)
for idx, row in sample_df.iterrows():
rfm_str = f"R:{row['r_score']} F:{row['f_score']} M:{row['m_score']}"
table_rows_html += f"""
<tr>
<td>{idx}</td>
<td><strong>{row['客户类型']}</strong></td>
<td>{rfm_str}</td>
<td>{row['营销策略']}</td>
</tr>
"""
# 渲染模板
template = Template(html_template)
html_content = template.render(
time=summary_stats['report_time'],
total=summary_stats['total_users'],
high_val=summary_stats['high_value_count'],
top_seg=summary_stats['top_segment'],
table_rows=table_rows_html
)
# 保存 HTML
html_path = os.path.join(script_dir, "../Data/rfm_report.html")
with open(html_path, 'w', encoding='utf-8') as f:
f.write(html_content)
print(f"✅ HTML 分析报告已生成:{html_path}")
print("🎉 项目全部完成!请打开 HTML 文件查看最终成果。")