
我首次接触 TabPFN 是通过 ICLR 2023 论文------TabPFN:一秒钟解决小型表格分类问题的 Transformer 。该论文介绍了 TabPFN,这是一个专为表格数据集构建的 开源 transformer 模型,这是尚未真正受益于深度学习的领域,其中梯度提升决策树模型仍然占主导地位。
当时,TabPFN 仅支持最多 1,000 个训练样本和 100 个纯数值特征,因此它在实际环境中的应用相当有限。然而,随着时间的推移,有一些增量改进,包括 TabPFN-2,它于 2025 年通过论文引入------使用表格基础模型(TabPFN-2)在小数据上准确预测。
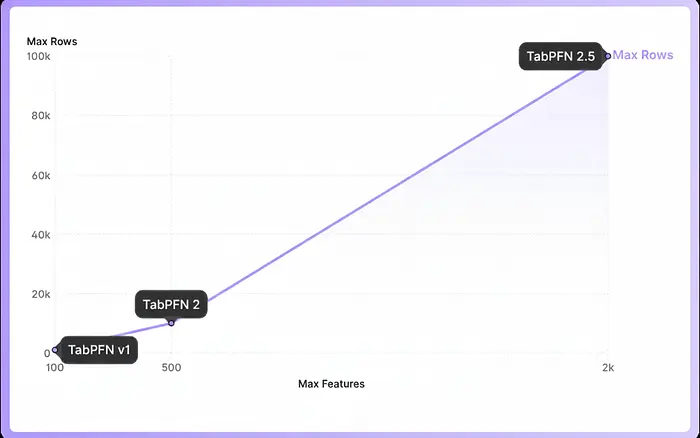
最近,TabPFN-2.5 发布,该版本可以处理接近 100,000 个数据点和大约 2,000 个特征,这使其相当适用于实际预测任务。我花了很多专业时间处理表格数据集,因此这自然引起了我的兴趣,促使我深入了解更多。在本文中,我提供了 TabPFN 的高级概述,并使用 Kaggle 竞赛进行了快速实施,以帮助您入门。
1、什么是 TabPFN?
TabPFN 代表 Tabular Prior-data Fitted Network(表格先验数据拟合网络) ,这是一个基于将模型拟合到 表格数据集的先验而不是单个数据集的思想的基础模型,因此得名。
在阅读技术报告时,我发现这些模型有很多有趣的部分。例如,TabPFN 可以以非常低的延迟提供强大的表格预测,通常可与调优的集成方法相媲美,而无需重复的训练循环。
从工作流程的角度来看,也没有学习曲线,因为它通过 scikit-learn 风格的接口自然地融入现有设置。它可以处理缺失值、异常值和混合特征类型,只需最少的预处理,我们将在本文后面的实施中介绍这一点。
2、表格数据基础模型的需求
在深入了解 TabPFN 如何工作之前,让我们首先尝试理解它试图解决的更广泛的问题。
对于表格数据上的传统机器学习,您通常为每个新数据集训练一个新模型。这通常涉及较长的训练周期,并且意味着先前训练的模型不能真正重复使用。
然而,如果我们查看文本和图像的基础模型,它们的想法根本不同。不是从头开始重新训练,而是在许多数据集上进行大量的预训练,然后在大多数情况下,结果模型可以应用于新数据集而无需重新训练。
在我看来,这是模型试图填补表格数据差距的地方,即减少为每个数据集从头开始训练新模型的需求,这看起来是一个有前途的研究领域。
3、TabPFN 训练和推理流程概述
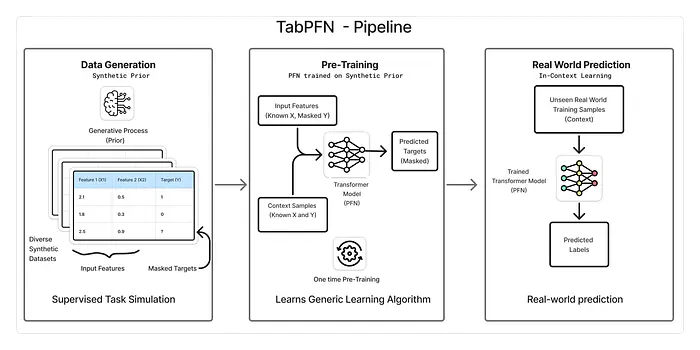
TabPFN 利用 上下文学习 将神经网络拟合到表格数据集的先验。这意味着,模型不是一次学习一个任务,而是学习表格问题通常如何呈现的一般外观,然后通过单个前向传递使用该知识对新数据集进行预测。以下是 TabPFN 的 Nature 论文的摘录:
TabPFN 利用上下文学习(ICL),这是导致大型语言模型惊人表现的相同机制,生成一个强大的完全学习的表格预测算法。虽然 ICL 最早是在大型语言模型中观察到的,但最近的工作表明,transformer 可以通过 ICL 学习简单算法,如逻辑回归。
流程可以分为三个主要步骤:
3.1 生成合成数据集
TabPFN 将整个数据集视为馈送到网络的单个数据点(或标记)。这意味着它在训练期间需要暴露于非常大量的数据集。因此,训练 TabPFN 从 合成表格数据集开始。为什么是合成数据?与文本或图像不同,没有许多大型且多样化的真实世界表格数据集可用,这使得合成数据成为设置的关键部分。为了说明这一点,TabPFN 2 在 1.3 亿个数据集上进行了训练。
生成合成数据集的过程本身就很有趣。TabPFN 使用高度参数化的 结构因果模型创建具有多样化结构、特征关系、噪声水平和目标函数的表格数据集。通过从该模型采样,可以生成大型且多样化的数据集,每个数据集作为网络的训练信号。这鼓励模型学习许多类型的表格问题的一般模式,而不是过度拟合到任何单个数据集。
3.2 训练
下图取自 Nature 论文,清楚地说明了训练和推理过程。
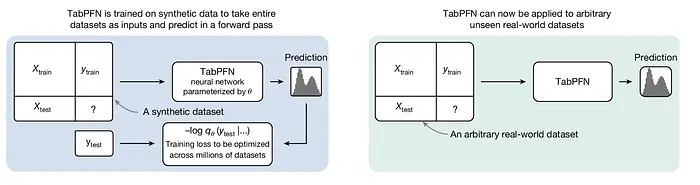
在训练期间,采样一个合成表格数据集并分为 X train 、Y train 、X test 和 Y test 。Y test 值被保留,其余部分传递给神经网络,该神经网络输出每个 Y test 数据点的概率分布,如左图所示。
然后根据这些预测分布评估保留的 Y test 值。然后计算 交叉熵损失并更新网络以最小化该损失。这完成了单个数据集的一个反向传播步骤,然后对数百万合成数据集重复此过程。
3.3 推理
在测试时,将训练好的 TabPFN 模型应用于真实数据集。这对应于右图,其中模型用于推理。如您所见,接口与训练期间保持相同。您提供 X train 、Y train 和 X test ,模型通过单个前向传递输出 Y test 的预测。
最重要的是,测试时不需要重新训练,TabPFN 执行实际上是 零样本推理,在不更新权重的情况下立即产生预测。
3.4 架构
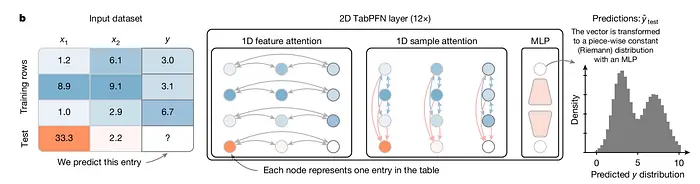
TabPFN 架构 | 来源:使用表格基础模型在小数据上准确预测(开放获取文章)
让我们也触及 论文 中提到的模型核心架构。在高级别上,TabPFN 调整 transformer 架构以更好地适应表格数据。不是将表格展平为长序列,模型将表中的每个值视为自己的单位。它使用两阶段注意力机制,首先学习特征在单行内如何相互关联,然后学习相同特征在不同行中的行为。
这种结构化注意力的方式至关重要,因为它匹配表格数据的实际组织方式。这也意味着模型不关心行或列的顺序,这意味着它可以处理比训练的表更大的表。
4、实施
现在让我们演练 TabPFN-2.5 的实施,并将其与原始 XGBoost 分类器进行比较,以提供熟悉的参考点。虽然模型权重可以从 Hugging Face 下载,但使用 Kaggle Notebooks 更直接,因为 模型 在那里 readily 可用,并且 GPU 支持开箱即用于更快的推理。无论哪种情况,在使用之前都需要接受模型条款。将 TabPFN 模型 添加到 Kaggle notebook 环境后,运行以下单元格以导入它。
# 导入模型
import os
os.environ["TABPFN_MODEL_CACHE_DIR"] = "/kaggle/input/tabpfn-2-5/pytorch/default/2"您可以在随附的 Kaggle notebook 这里 找到完整的代码。
4.1 安装
您可以通过两种方式访问 TabPFN,既可以作为 Python 包 在本地运行,也可以作为 API 客户端在云中运行模型:
# Python 包
pip install tabpfn
# 作为 API 客户端
pip install tabpfn-client4.2 数据集:Kaggle Playground 竞赛数据集
为了更好地了解 TabPFN 在实际环境中的表现,我在几个月前结束的 Kaggle Playground 竞赛中对其进行了测试。任务 使用降雨数据集进行二元预测 需要为测试集中的每个 id 预测降雨概率。评估使用 ROC-AUC 进行,这使得这很适合像 TabPFN 这样的基于概率的模型。训练数据如下所示:
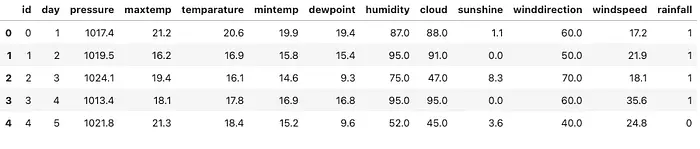
训练数据的前几行
4.3 训练 TabPFN 分类器
训练 TabPFN 分类器很简单,遵循熟悉的 scikit-learn 风格接口。虽然传统意义上没有特定任务训练,但启用 GPU 支持仍然很重要,否则推理可能会明显变慢。以下代码片段演练了准备数据、训练 TabPFN 分类器并使用 ROC-AUC 分数评估其性能。
# 导入必要的库
import pandas as pd, numpy as np
from tabpfn import TabPFNClassifier
from sklearn.model_selection import train_test_split
FEATURES = [c for c in train.columns if c not in ["rainfall",'id']]
X = train[FEATURES].copy()
y = train["rainfall"].copy()
# 将给定的训练数据分为训练和验证集
train_index, valid_index = train_test_split(
train.index,
test_size=0.2,
random_state=42
)
x_train = X.loc[train_index].copy()
y_train = y.loc[train_index].copy()
x_valid = X.loc[valid_index].copy()
y_valid = y.loc[valid_index].copy()
#训练 TabPFNClassifier
model_pfn = TabPFNClassifier(device=["cuda:0", "cuda:1"])
model_pfn.fit(x_train, y_train)
# 预测概率
probs_pfn = model_pfn.predict_proba(x_valid)
# 正类概率(class = 1)
pos_probs = probs_pfn[:, 1]
# 指标
print(f"ROC AUC: {roc_auc_score(y_valid, pos_probs):.4f}")
-------------------------------------------------
ROC AUC: 0.8722接下来让我们训练一个基本的 XGBoost 分类器
4.4 训练 XGBoost 分类器
model_xgb = XGBClassifier(
objective="binary:logistic",
tree_method="hist",
device="cuda",
enable_categorical=True,
random_state=42,
n_jobs=1
)
model_xgb.fit(x_train, y_train)
# 预测概率
probs_xgb = model_xgb.predict_proba(x_valid)
# 正类概率(class = 1)
pos_probs_xgb = probs_xgb[:, 1]
# 指标
print(f"ROC AUC: {roc_auc_score(y_valid, pos_probs_xgb):.4f}")
------------------------------------------------------------
ROC AUC: 0.8515如您所见,TabPFN 开箱即用地表现相当好。虽然 XGBoost 当然可以进一步调优,但我的意图是比较 基本的原始实现,而不是优化模型。它让我在公共排行榜上排名第 22 位。以下是前 3 名分数以供参考。
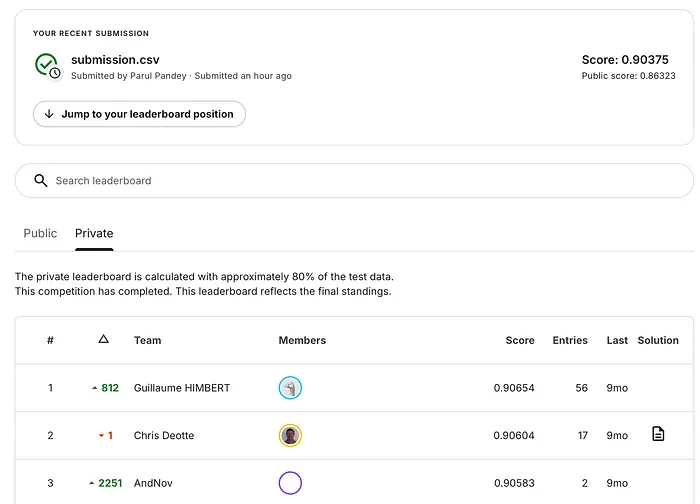
5、模型可解释性呢?
Transformer 模型本质上不可解释,因此为了理解预测,通常使用事后可解释性技术(如 SHAP(SHapley 加性解释))来分析单个预测和特征贡献。TabPFN 提供了一个专用的 可解释性扩展,它与 SHAP 集成,使得更容易检查和推理模型的预测。要访问该功能,您需要先安装扩展:
# 安装可解释性扩展:
pip install "tabpfn-extensions[interpretability]"
from tabpfn_extensions import interpretability
# 计算 SHAP 值
shap_values = interpretability.shap.get_shap_values(
estimator=model_pfn,
test_x=x_test[:50],
attribute_names=FEATURES,
algorithm="permutation",
)
# 创建可视化
fig = interpretability.shap.plot_shap(shap_values)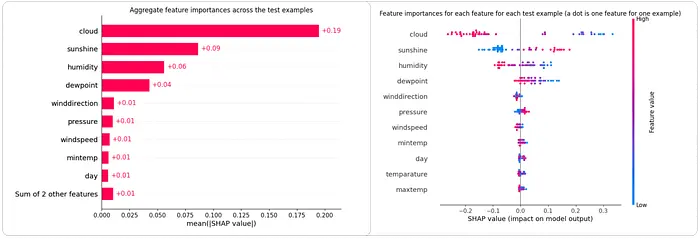
左:单个预测中每个特征的 SHAP 值 | 右:数据集中平均 SHAP 特征重要性。为了效率,在验证样本的子集上计算了 SHAP 值。
左图显示了整个数据集中的 平均 SHAP 特征重要性 ,提供了全局视图,了解哪些特征对模型最重要。右图是 SHAP 摘要(蜂群)图,通过显示每个特征在单个预测中的 SHAP 值,提供更细粒度的视图。
从上图可以看出,云层 、阳光 、湿度 和露点对模型预测的整体影响最大,而风向、压力和温度相关变量等特征的作用相对较小。
重要的是要注意,SHAP 解释了模型学习的关系,而不是物理因果关系。
6、结束语
TabPFN 比我在本文中涵盖的内容要多得多。我个人喜欢的是基本思想以及入门的容易程度。有很多方面我没有在这里涉及,例如 TabPFN 在时间序列预测、异常检测、生成合成表格数据和嵌入提取中的使用。
我特别感兴趣探索的另一个领域是微调,其中这些模型可以适应来自特定领域的数据。也就是说,本文是基于我的第一次实际体验的一个轻松介绍。我计划在未来的文章中更深入地探索这些额外的功能。目前,官方 文档 是深入了解的好地方。