目录
[C 语言文件操作回顾](#C 语言文件操作回顾)
[系统调用:open 和 close](#系统调用:open 和 close)
[dup2 函数](#dup2 函数)
[文件名与 inode](#文件名与 inode)
前言
在学习 Linux 的文件之前,应该知道:
1、文件 = 内容 + 属性
2、文件分为打开的文件 和关闭的文件
3、打开的文件:文件是进程打开的,研究打开的文件,就是研究进程与文件的关系。文件被打开,必须先加载到内存(文件的属性一定先加载到内存)。一个进程可以打开多个文件,所以操作系统内部一定有很多打开的文件。操作系统采用"先描述,再组织"的方式管理文件。
4、关闭的文件:一般在磁盘中存储,关闭的文件非常多,我们最关心文件如何有秩序的被规制,如何快速的进行增删查改。
打开的文件
C 语言文件操作回顾
cpp
//打开文件
FILE * fopen ( const char * filename, const char * mode );
//关闭文件
int fclose ( FILE * stream );const char * filename:文件的绝对路径或相对路径,如果是绝对路径,就按照绝对路径找到文件,如果是相对路径,就在进程当前路径(cwd)下寻找。
w (只写方式)打开,会对文件进行清空,再从头写入,而不是从头覆盖。并且只要用 w 方式打开,就会对文件进行清空,不管有没有对文件进行写入。可以推断出用 >文件名 打开的文件,是用 w 方式打开的,用 >>文件名 打开的文件,是用 a 方式打开的。
把字符串写入文件时,\0 的问题:如果某个字符串以这种方式写入文件:
cpp
#include <stdio.h>
#include <string.h>
int main()
{
const char* str = "Hello Linux";
FILE* pf = fopen("log.txt",'w');
if(pf == NULL) perror("fopen");
fwrite(str,strlen(str) + 1,1,log.txt);
fclose("log.txt");
return 0;
}再用 vim 打开 log.txt,发现 Hello Linux 后有一个乱码,那就是 \0。那么字符串写入文件时,到底要不要带上 \0 呢,答案是不用,因为字符串以 \0 是 C 语言的规定,与文件没有关系。
访问文件的系统调用
在包含了 stdio.h 头文件之后,C 默认自动打开三个输入输出流,分别是stdin(对应键盘文件), stdout(对应显示器文件), stderr。键盘、显示器这些硬件在操作系统下都是文件,要访问硬件,也就是要访问这些硬件对应的文件,而硬件处于操作系统最底层,要访问硬件必须贯穿整个操作系统,用户必须使用操作系统提供的系统调用接口来合法的访问硬件,而像 fopen、fwrite、fread... 都是库函数,它们都封装了某些系统调用。不管是什么编程语言,只要在 Linux 下运行,它们的有关文件的库函数都一定封装了下面的系统调用:
系统调用:open 和 close
cpp
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
int open(const char *pathname, int flags);
int open(const char *pathname, int flags, mode_t mode);
#icnlude <unistd.h>
int close(int files);open:
pathname : 要打开或创建的目标文件
flags: 打开文件时,可以传入多个参数选项,用下面的一个或者多个常量进行"或"运算。O_RDONLY: 只读打开
O_WRONLY: 只写打开
O_RDWR : 读,写打开
O_CREAT : 若文件不存在,则创建它。需要使用mode选项,来指明新文件的访问权限
O_APPEND: 追加写
O_TRUNC:文件写入之前清空
mode:文件权限的八进制表示
返回值:
成功:新打开的文件描述符
失败:-1
close:
files:指定文件的描述符,关闭该文件。
使用位运算定制传参:
上面的 O_RDONLY、O_WRONLY、O_RDWR 其实都是定义的宏,这些宏的比特位只有一个 1,其余都是 0,通过将它们或在一起形成一个整数传参,在函数内部检查这个整数的对应比特位,可以启用任意组合的功能:
cpp
#include <stdio.h>
#define ONE (1<<0)
#define TWO (1<<1)
#define THREE (1<<2)
#define FOUR (1<<3)
void show(int flags)
{
if(flags&ONE) printf("Hello function1\n");
if(flags&TWO) printf("Hello function2\n");
if(flags&THREE) printf("Hello function3\n");
if(flags&FOUR) printf("Hello function4\n");
printf("\n");
}
int main()
{
show(ONE);
show(ONE|TWO);
show(ONE|TWO|THREE);
show(THREE|FOUR);
show(ONE|FOUR);
return 0;
}open 和 close 使用举例:
cpp
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
int main()
{
umask(0);
int fd = open("log.txt",O_WRONLY|O_CREAT,0666);
if(fd < 0)
{
perror("open");
return 1;
}
close(fd);
return 0;
}系统调用:write
cpp
#include <unistd.h>
ssize_t write(int fd, const void *buf, size_t count);fd:要写入的文件的文件描述符
buf:要写入数据的缓冲区指针
count:要写入的字节数
cpp
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include <string.h>
int main()
{
umask(0);
int fd = open("log.txt",O_WRONLY|O_CREAT,0666);
if(fd < 0)
{
perror("open");
return 1;
}
const char* message = "Hello write\n";
write(fd,message,strlen(message));
close(fd);
return 0;
}用上面的方式写入文件,写入时是从文件开始处写入,但是写入之前并不会对文件进行清空,需要在 open 函数的 flags 添加 O_TRUNC:
cpp
int fd = open("log.txt",O_WRONLY|O_CREAT|O_TRUNC,0666);如果想要以追加的方式写入,只需把 O_TRUNC 改成 O_APPEND。
系统调用:read
cpp
#include <unistd.h>
ssize_t read(int fd, void *buf, size_t count);fd:文件描述符
buf:存储读取数据的缓冲区指针
count:最多读取的字节数
cpp
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include <string.h>
int main()
{
char buffer[1024];
ssize_t s = read(0,buffer,sizeof(buffer));
if(s < 0) return 1;
buffer[s] = '\n';
printf("echo:%s\n",buffer);
return 0;
}通过上面的系统调用,可以很容易的模拟实现出 fopen 等 C 库函数:
cpp
FILE* pf = fopen("log.txt",'w');
// 内部调用
int fd = open("log.txt",O_WRONLY|O_CREAT|O_TRUNC,0666);操作系统是如何管理文件的
一个打开的文件,在操作系统内核都有一个描述它的信息的结构体,叫做 struct_file,所有文件的 struct_file 形成一个双向链表,便于进行增删查改。文件是进程打开的,所以进程与它打开的文件必须建立链接,在进程的 tesk_struct 的内部就有一个指向 struct_file 类型的指针 struct_file* file,该指针指向一个大结构体,叫做 file_struct,这个大结构体内部有一个 struct_file* 类型的指针数组。
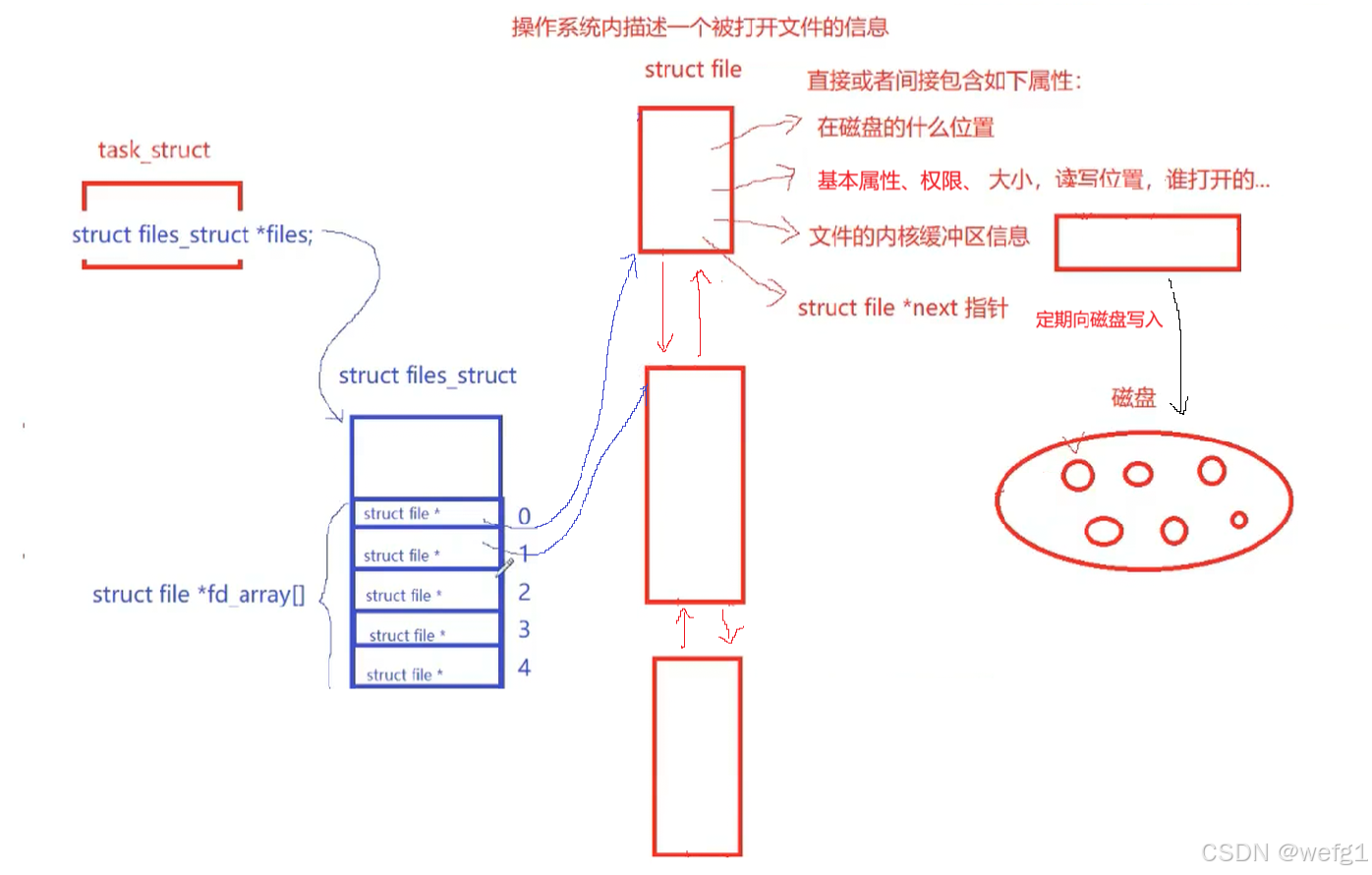
文件描述符
当进程打开一个文件时,进程会在 array 数组中找到一个未被使用的指针,把该指针指向 struct file 中的结构体。在 open 函数中,回返回这个下标,所以文件描述符本质就是一个指针数组的下标。
cpp
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include <string.h>
int main()
{
umask(0);
int fd = open("log.txt",O_WRONLY|O_CREAT,0666);
if(fd < 0)
{
perror("open");
return 1;
}
printf("fd:%d\n",fd);
close(fd);
return 0;
}输出:fd:3,问题来了:下标为 0,1,2 的文件是什么? 文件描述符 0、1、2 总是对应标准输入流、标准输出流、标准错误流,C 语言的 stdin、stdout、stderr 分别封装了这三个文件描述符,提供了访问它们的便捷方式。
FILE 是 C 语言封装的一个结构体,我们的推断出它里面一定封装了文件描述符。实际上,FILE 结构体的 _fileno 存储了文件描述符:
cpp
#include <stdio.h>
int main()
{
printf("stdin:%d\n",stdin->_fileno);
printf("stdout:%d\n",stdout->_fileno);
printf("stderr:%d\n",stderr->_fileno);
return 0;
}struct_file* 类型的指针数组的某两个指针可能指向同一个 struct_file,当使用 close()关闭该文件时,其内核数据结构不应该被销毁,这其中就使用了引用计数。
文件描述符的分配规则
cpp
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
int main()
{
close(0);
int fd = open("log.txt",O_CREAT|O_WRONLY|O_TRUNC,0666);
printf("fd:%d\n",fd);
const char* message = "Hello Linux\n";
int cnt = 5;
while(cnt--)
{
write(fd,message,sizeof(message));
}
return 0;
}输出:fd:0,如果把 close(0) 改为 close(1),没有任何输出,但是文件内容符合预期,如果 close(2),输出:fd:2,可以推断出文件描述符的分配规则:从数组下标为 0 的位置开始线性遍历,寻找一个位置为空的位置来作为新文件的描述符。
重定向
cpp
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <string.h>
int main()
{
close(1);
int fd = open("log.txt",O_CREAT|O_WRONLY|O_TRUNC,0666);
const char* message = "Hello Linux\n";
int cnt = 5;
while(cnt--)
{
write(1,message,strlen(message));
}
return 0;
}运行代码的现象:没有任何输出,查看 log.txt 的内容发现是应该打印的内容,即:本来应该打印到显示器的内容,现在却打印到了 log.txt,这个现象叫做输出重定向 ,(本来应该从键盘读取,现在从文件中读取,叫做输入重定向)造成上面现象的原因:关闭了描述符为 1 的文件(默认为显示器文件),现在打开了 log.txt,log.txt 文件的描述符被分配为1,write(1,message,strlen(message)); 其实是向 log.txt 打印。
stdout 和 stderr 的区别
stdout 和 stderr 都是往显示器打印,那它们的区别是什么呢?
cpp
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <string.h>
int main()
{
fprintf(stdout,"hello normal message\n");
fprintf(stdout,"hello normal message\n");
fprintf(stdout,"hello normal message\n");
fprintf(stdout,"hello normal message\n");
fprintf(stdout,"hello normal message\n");
fprintf(stderr,"hello error message\n");
fprintf(stderr,"hello error message\n");
fprintf(stderr,"hello error message\n");
fprintf(stderr,"hello error message\n");
fprintf(stderr,"hello error message\n");
return 0;
}在命令行输入:
bash
[hxh@VM-16-12-centos 2026_1_26]$ ./test > log.txt
hello error message
hello error message
hello error message
hello error message
hello error message
[hxh@VM-16-12-centos 2026_1_26]$ cat log.txt
hello normal message
hello normal message
hello normal message
hello normal message
hello normal message发现输出重定向只重定向了 stdout,stderr 仍然是向屏幕打印,这就是区别。stderr 也可以向文件中打印:
cpp
int main()
{
fprintf(stderr,"hello error message\n");
fprintf(stderr,"hello error message\n");
fprintf(stderr,"hello error message\n");
fprintf(stderr,"hello error message\n");
fprintf(stderr,"hello error message\n");
return 0;
}
cpp
[hxh@VM-16-12-centos 2026_1_26]$ ./test 2>err.txt
[hxh@VM-16-12-centos 2026_1_26]$ cat err.txt
hello error message
hello error message
hello error message
hello error message
hello error message把 stdout 和 stderr 分别打印到不同文件:
bash
[hxh@VM-16-12-centos 2026_1_26]$ ./test 1>nor.txt 2>err.txt也可以打印到同一个文件:
bash
[hxh@VM-16-12-centos 2026_1_26]$ ./test 1>all.txt 2>&1dup2 函数
如果每次重定向之前,都要关闭原文件,再打开新文件,未免太麻烦,dup2 函数可以帮助我们快速重定向。
cpp
#include <unistd.h>
int dup2(int oldfd, int newfd);作用 :将
oldfd复制到newfd上。如果newfd已经打开,会先自动关闭它。oldfd 可以 close 也可以不 close(不应该是 newfd 复制到 oldfd 上吗?这个函数的参数设计不好)返回值:
成功:返回新的文件描述符(即
newfd)失败:返回 -1,并设置
errno
cpp
// 将标准输出重定向到文件
int fd = open("output.txt", O_WRONLY | O_CREAT, 0644);
dup2(fd, stdout.fileno); // 现在printf/write会写入output.txt
close(fd);
// 将标准输入重定向到文件
fd = open("input.txt", O_RDONLY);
dup2(fd, stdin.fileno); // 现在scanf/read会从input.txt读取
close(fd);如何理解"一切皆文件"
磁盘、屏幕、键盘等等外部设备,都会提供读或写方法(有的方法可能为空,比如一般不会向键盘写入,所以键盘的写方法为空),当一个文件被打开,一定是被进程打开,操作系统会创建保存文件信息的结构体,并给它分配一个 operation_func 结构体,里面定义了指向文件读或写的方法的指针,这两个指针会指向更底层的真正的读写方法。
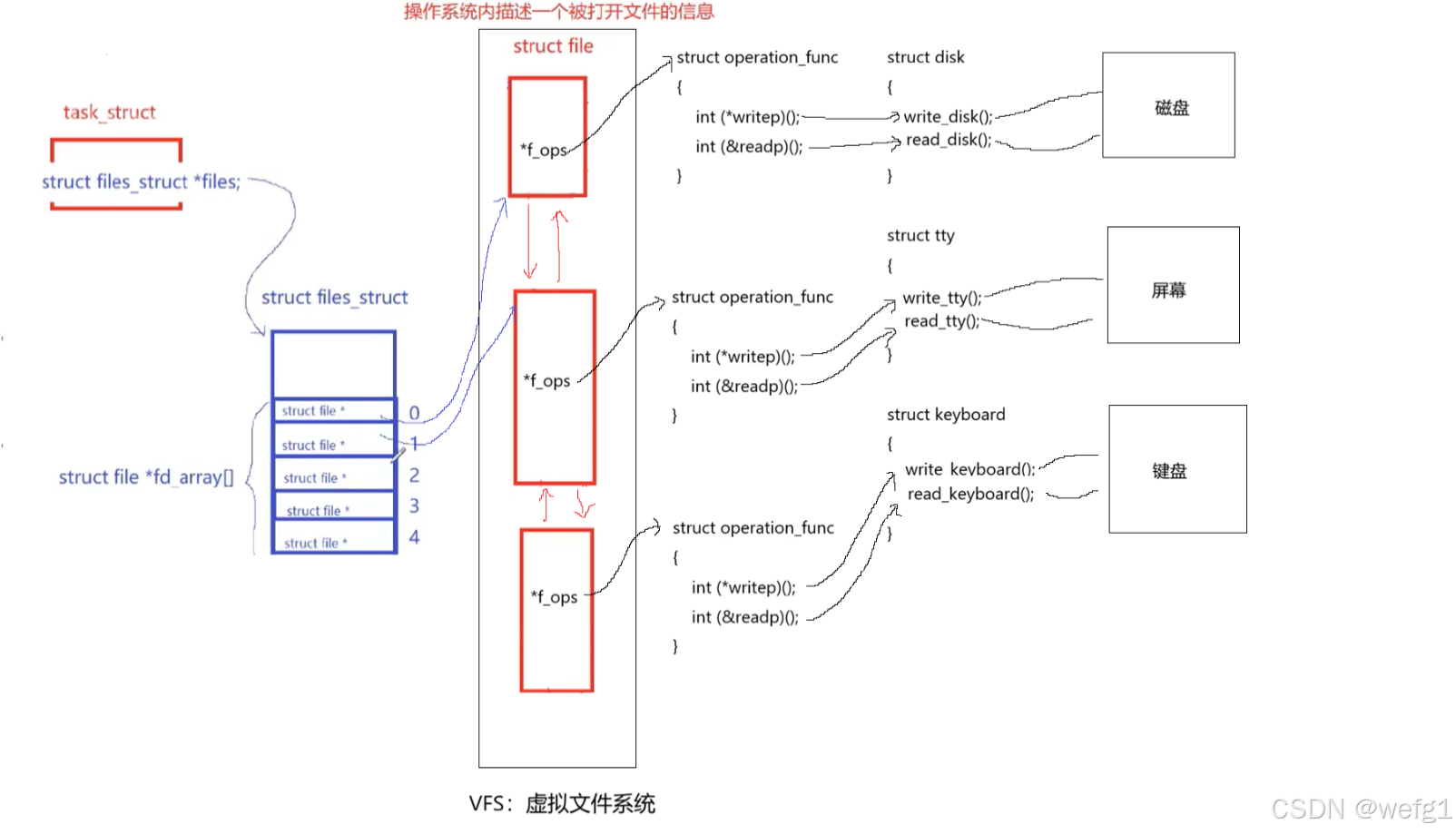
缓冲区
先观察现象:例子1:
cpp
#include <stdio.h>
#include <string.h>
#include <unistd.h>
int main()
{
const char* fstr = "Hello fwrite\n";
const char* str = "Hello write\n";
printf("Hello printf\n");
fprintf(stdout,"Hello fprintf\n");
fwrite(fstr,strlen(fstr),1,stdout);
write(1,str,strlen(str));
return 0;
}运行上面代码,显示屏打印:
bash
[hxh@VM-16-12-centos 2026_1_27]$ ./test
Hello printf
Hello fprintf
Hello fwrite
Hello write符合预期。重定向到文件里,再查看文件内容:
bash
[hxh@VM-16-12-centos 2026_1_27]$ ./test > log.txt
[hxh@VM-16-12-centos 2026_1_27]$ cat log.txt
Hello write
Hello printf
Hello fprintf
Hello fwrite也符合预期,现在稍微修改一下代码:例子2
cpp
#include <stdio.h>
#include <string.h>
#include <unistd.h>
int main()
{
const char* fstr = "Hello fwrite\n";
const char* str = "Hello write\n";
printf("Hello printf\n");
fprintf(stdout,"Hello fprintf\n");
fwrite(fstr,strlen(fstr),1,stdout);
write(1,str,strlen(str));
fork();// 在这里添加一个 fork 函数
return 0;
}运行上面代码,显示屏打印:
bash
[hxh@VM-16-12-centos 2026_1_27]$ ./test
Hello printf
Hello fprintf
Hello fwrite
Hello write符合预期。重定向到文件里,再查看文件内容:
bash
[hxh@VM-16-12-centos 2026_1_27]$ ./test > log.txt
[hxh@VM-16-12-centos 2026_1_27]$ cat log.txt
Hello write
Hello printf
Hello fprintf
Hello fwrite
Hello printf
Hello fprintf
Hello fwrite奇怪的现象出现了:C 库函数打印的内容打印了两次,而 write 系统调用只打印了一次,并且打印的顺序也不对。出现这种现象一定与 fork 函数有关。
再稍微修改一下代码:例子3
cpp
#include <stdio.h>
#include <string.h>
#include <unistd.h>
int main()
{
// 只用C库函数,且统一去掉\n
const char* fstr = "Hello fwrite";
printf("Hello printf");
fprintf(stdout,"Hello fprintf");
fwrite(fstr,strlen(fstr),1,stdout);
close(1);// 这里关掉stdout
return 0;
}
bash
[hxh@VM-16-12-centos 2026_1_27]$ ./test
[hxh@VM-16-12-centos 2026_1_27]$ ./test > log.txt
[hxh@VM-16-12-centos 2026_1_27]$ cat log.txt
[hxh@VM-16-12-centos 2026_1_27]$ 运行代码,什么也没有输出,重定向到文件,文件里也没有内容。再修改代码:例子4
cpp
#include <stdio.h>
#include <string.h>
#include <unistd.h>
int main()
{
// 只用系统调用,去掉\n
const char* str = "Hello fwrite";
write(1,str,strlen(str));
close(1);// 这里关掉stdout
return 0;
}
bash
[hxh@VM-16-12-centos 2026_1_27]$ ./test
Hello fwrite[hxh@VM-16-12-centos 2026_1_27]$ ./test > log.txt
[hxh@VM-16-12-centos 2026_1_27]$ cat log.txt
Hello fwrite[hxh@VM-16-12-centos 2026_1_27]$ 运行代码,输出了内容,重定向到文件,文件有内容。
用户缓冲区和系统缓冲区
当使用 printf、fprintf、fwrite、fputc 等 C 标准库函数时,数据会先被写入用户空间的缓冲区 ,而非操作系统级别的缓冲区。这是因为 close(1) 在关闭文件描述符前会自动刷新缓冲区,而 close 作为系统调用,刷新的是系统级缓冲区。write 作为系统调用会直接将数据写入系统级缓冲区,因此在 close 操作时,通过 write 写入的数据会立即显示在终端上。所以在 C 标准库函数和 write 之间,一定存在 C 提供的用户空间的缓冲区,使用 C 标准库函数写入的数据,先被写入用户空间的缓冲区。用户缓冲区存在文件对应的 FILE 结构体内。
用户空间的缓冲区到系统级别的缓冲区的刷新规则
下面的刷新规则都是用户空间层面的缓冲策略,不是内核或系统级别缓冲区的直接规则。stdout的默认刷新规则是行缓冲 , 即遇到 \n 时,代表一行的结束,此时再刷新。目的是减少昂贵的系统调用(如
write)的次数,将多次小写操作合并为一次大写操作,极大提升效率。刷新策略除了"行缓冲",还有**"全缓冲"、"无缓冲"** 。标准错误 (stderr) 默认是无缓冲的:为了错误信息能及时显示,写入stderr的内容会立即调用write(),即使没有 \n。当stdout被重定向到文件或管道时,缓冲模式会变为全缓冲,即使有\n,如果缓冲区没满,数据也可能停留在用户缓冲区,不会立即进入内核/磁盘文件,可以用 fflush(strout) 强制将用户缓冲区刷新到内核,无论是否有\n或缓冲区是否满。在上面的例子2中,创建了子进程,例子2如果重定向到文件中,刷新策略变成全缓冲,子进程被创建时,浅拷贝了父进程的缓冲区,并且现在缓冲区都是 C 接口打印的内容(全缓冲),父子进程退出时,一共刷新了缓冲区两次。
为什么要有缓冲区
它是计算机架构中应对速度鸿沟和规模不匹配的核心协调器 。它通过用一部分内存空间换取时间和效率,将大量零碎、随机、高延迟的操作,转换为批量、顺序、低延迟的操作,从而极大地提升了整个系统的吞吐量、响应性和资源利用率。它是现代计算机能够高效运行的基石之一。
生活的类比:菜鸟驿站
没有缓冲区:每有一个包裹,快递员就开一辆车从你家直接送到收件人城市(非常低效,成本极高)。
有缓冲区:快递员把多个包裹收集到本地的快递点(缓冲区),攒够一车后,统一发往目的地城市的分拣中心(另一个缓冲区),最后进行派送。这大大提升了运输效率,降低了单件成本。
计算机系统中处处是数量级的速度差异:
CPU vs 内存 :CPU 纳秒级,内存百纳秒级 → 有 CPU 缓存,可以把内存看作是 CPU 与外设之间的一个巨大的缓冲区
内存 vs 硬盘/SSD :内存纳秒/微秒级,硬盘毫秒级(慢数万到百万倍)→ 有 页面缓存、磁盘缓冲区
进程 vs 外设 :进程运行极快,向屏幕打印、网络传输相对慢 → 有 I/O 缓冲区
对于 stdout 的缓冲区,还有支持格式化输入输出的作用,比如在用 printf("%d",1); 时,在用户缓冲区内把 %d 转化成 1,再写入内核缓冲区。 对于 read 和 write 这样的系统调用,它们只认字符,即:用 read 在键盘或文件读入的是字符串,至于怎么解析字符串,由上层定义,比如 read 读取到 "123"到系统缓冲区,把 "123" 看成整数还是字符串,由 scanf("%s",str) 或 scanf("%d",&var) 决定。
关闭的文件
在磁盘上存储文件,就要存储文件的内容和属性,文件的内容是以数据块形式存储的,文件的属性是以 inode 形式存储的,即:文件的内容和属性是分开存储的。
认识机械硬盘和固态硬盘
| 项目 | 机械硬盘 | 固态硬盘 | 对用户体验的影响 |
|---|---|---|---|
| 速度 | 慢。读写速度通常在80-200 MB/s。受限于转速(5400/7200 RPM)和寻道时间。 | 极快。SATA SSD可达500+ MB/s;NVMe SSD可达2000-12000+ MB/s。 | 最显著的区别。SSD让系统开机、软件启动、文件加载、游戏读图瞬间完成,整机响应"脱胎换骨"。 |
| 随机访问 | 非常慢。磁头需要物理移动到目标磁道和扇区,寻道时间长。 | 极快。电子访问,延迟极低(微秒级)。 | 这是系统感觉"卡顿"还是"流畅"的关键。SSD能同时快速处理大量零散文件请求。 |
| 抗震抗摔 | 差。工作时磁头距盘片仅纳米级,震动易导致划伤或坏道。 | 好。无机械部件,不怕震动,移动设备首选。 | SSD更适合笔记本电脑、移动设备,数据更安全。 |
| 功耗与噪音 | 较高。马达和磁头运动需要更多电能,并会产生噪音和热量。 | 很低。无运动部件,安静、发热小,续航更长。 | 笔记本用SSD可以更安静、更凉快、续航更长。 |
| 容量与价格 | 大容量、低单价。目前家用级可达22TB以上,单位容量成本远低于SSD。 | 容量较小、单价高。虽然价格持续下降,但同价格下容量远小于HDD。 | 核心选择依据。需要海量存储(如资料库、影音归档)时,HDD仍是性价比之王。 |
| 寿命与数据恢复 | 理论寿命长 ,但机械部件会磨损。数据恢复相对成熟可行。 | 有写入寿命 (TBW),但家用极难用尽。数据一旦损坏恢复极难。 | SSD需要更注意数据备份(但因其更抗震,实际意外损坏率可能更低)。 |
| 重量与尺寸 | 较重、较厚。标准3.5英寸和2.5英寸。 | 轻、薄。M.2规格的SSD仅如口香糖大小。 | 促进了超极本等轻薄设备的发展。 |
机械磁盘
机械磁盘的组成:
一、 部分物理/硬件组成

这是指你可以实际看到和触摸到的部件。一个密封的硬盘内部是一个无尘环境。
盘片
材质:通常由铝合金或玻璃制成,表面极其平整光滑。
涂层 :盘片两面都涂有由铁磁性材料(如钴合金)制成的磁性薄膜。数据就存储在这个薄膜上 ,通过磁化方向的不同来记录0和1。
数量:一个硬盘内可以有一到多张盘片,它们平行地安装在主轴上。
磁头
磁头:
每张盘片的上下两面各对应一个磁头,用于读写数据。
磁头在读写时并不接触盘面 ,而是"飞行"在盘片上方几纳米的空气垫上(这个距离比灰尘颗粒还小得多)。关机或休眠时,磁头会停靠在启停区(盘片外圈或内圈的一个特定区域,不存储数据),以免划伤盘面。
二、 逻辑/数据组织结构
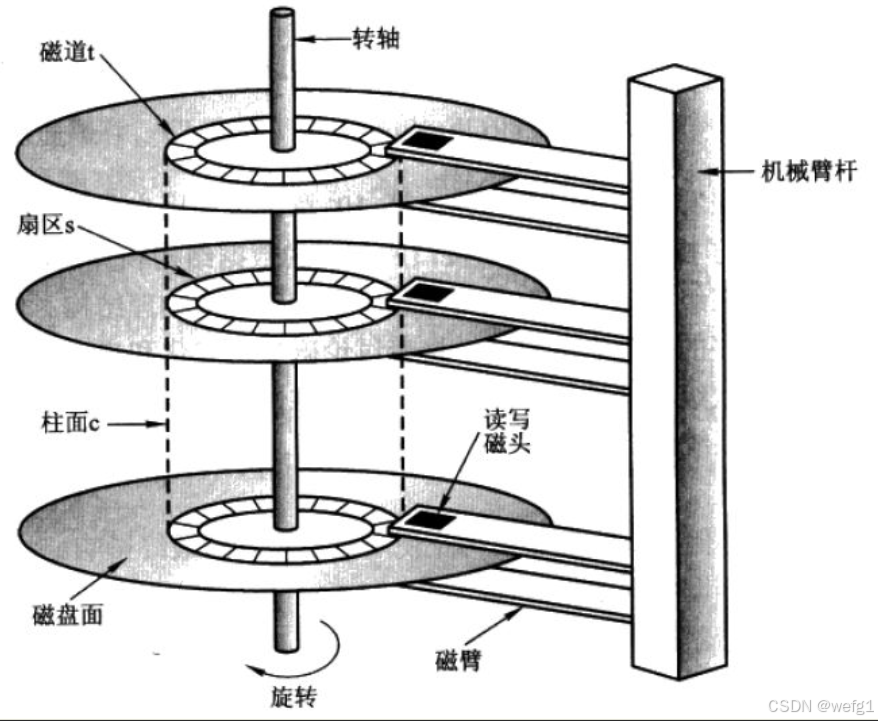
这是指数据在盘片磁性涂层上被组织和寻址的方式
磁道
- 盘片旋转时,磁头划出的一个圆形轨迹。一张盘片两面有成千上万个同心圆的磁道。
扇区
将每个磁道像切蛋糕一样等分成若干段弧段,每一段称为一个扇区。
这是硬盘最小的物理存储单元 ,传统大小是512字节 ,现代高级格式硬盘通常是4096字节(4KB)。
操作系统以扇区为单位进行读写。
柱面
所有盘片上半径相同的磁道在垂直方向上组成的"柱面"。
因为所有磁头同步移动,所以当磁头臂移动一次,所有磁头可以访问所有盘片上相同位置的磁道。数据常常按柱面组织,以减少磁头移动,提高效率。
磁盘进行数据寻址的过程很简单,就是确定使用哪个磁头(H eader)(确定盘面)、哪个磁道(确定柱面C ylinder)和扇面(S ector)也就是 CHS寻址方式。磁盘的运动越多,效率就越低,反之越高,所以软件设计者要有意识的把相关数据放在一起。
从物理结构到逻辑结构
磁盘在物理上是圆的,但在逻辑上认为它是线性的,就像把磁带的磁条全部扯出来拉直一样。假设一个磁盘有 6 个盘面,把这 6 个盘面想象成盘卷的磁条,把它们拉直并首尾拼接起来:
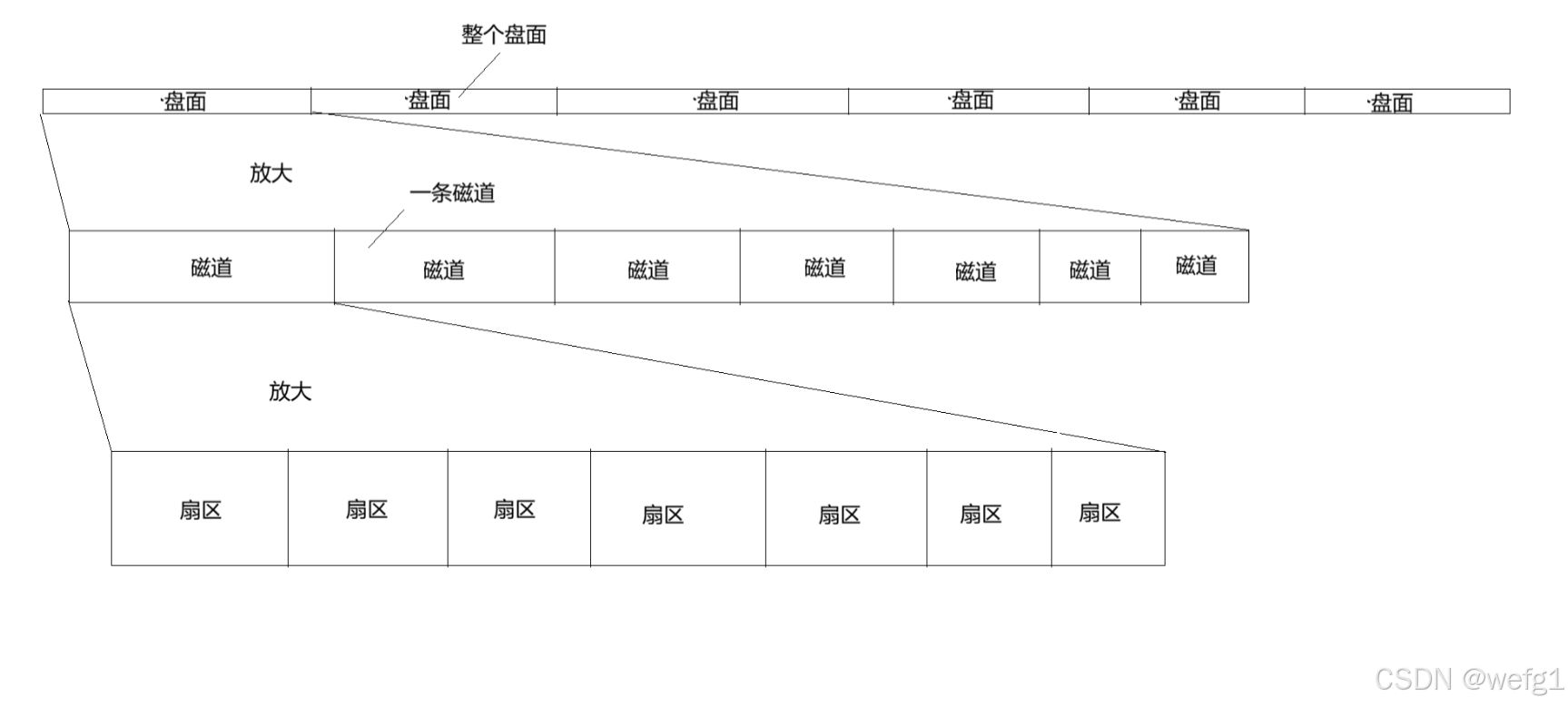
最终所有盘面都被划分为以扇区为基本单位的连续的数组。假设每个盘面有 2W 个扇区、50 条磁道,每个磁道有 400 个扇区,那么编号为 28888 的扇区(从 0 开始编号),在编号为 28888/20000 = 1 的盘面,在这个盘面的第 8888/400 = 22 号磁道上,是这条磁道的第 8888%400 = 88 个扇面,即逻辑扇区地址(LBA 地址) 28888 映射到物理 CHS 地址。物理 CHS 地址通过简单计算也可以得到逻辑地址。
文件系统
现在假设有一个容量为 800GB 的磁盘,直接管理所有不可行,可以把磁盘划分为任意大小的区域,比如划分为 200GB+100GB+150GB+150GB+200GB,类似于一个个省份,只要管理好了某个省份,就可以复制粘贴的管理好其他省份,整个磁盘就管理好了。直接管理一个省份也不可行,把省份继续划分,比如 200GB 划分为 20 个 10 GB(Block Group 块组),只要管理好任意一个 10 GB,就可以复制粘贴的管理好整个省份,就可以管理好整个磁盘。现在只要管理好这 10GB,可以管理好整个磁盘了,我们研究如何管理好这 10GB,把这 10GB 展开,就是文件系统:
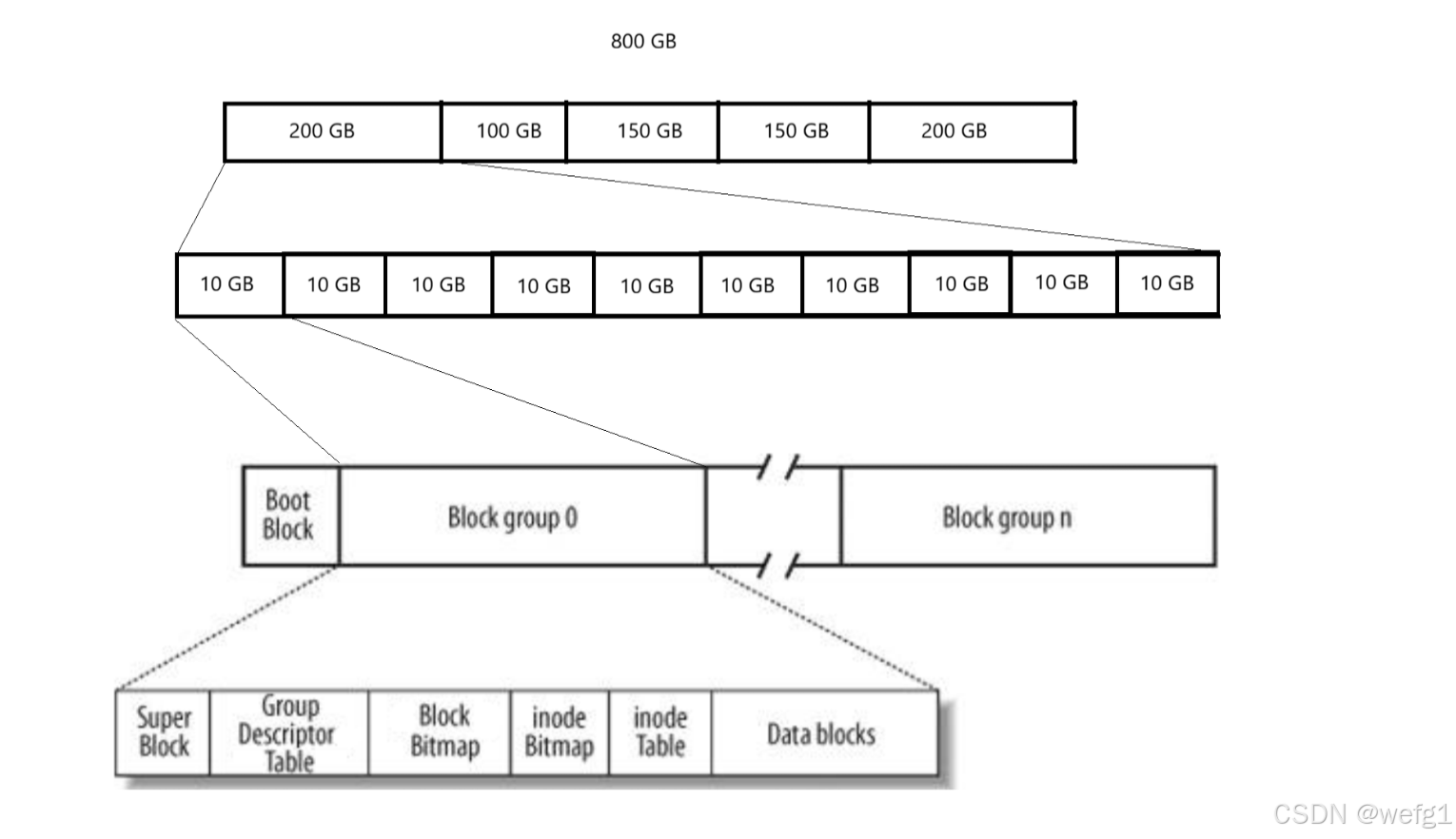
- Block Group:ext2 文件系统会根据分区的大小划分为数个 Block Group。而每个 Block Group 都有着相同的结构组成。
- 超级块(Super Block) :存放文件系统本身的结构信息。Super Block的信息被破坏,可以说整个文件系统结构就被破坏了。它规定对任意一个 Block group,展开后都要符合上图的结构,即 ext2 文件系统。它还记录了所有的 block group (200GB)的:bolck 和 inode 的总量,未使用的 block 和 inode 的数量,一个block 和 inode 的大小,每个 block group 有多大,每个组的 inode 数量,每个组的 block 数量,每个组的起始 inode 编号,文件系统的类型和名称。超级块并不是每个块组都有(那样的话更新超级块的成本过高),也不是只有一个块组有(要考虑鲁棒性),而是零星的几个块组有超级块。
- Group Descriptor Table(GDT) :块组描述符,描述块组属性信息,与超级块不同的是:它记录的是一个 block group 的 全局信息。记录的信息主要有:当前 block group 的 bolck 和 inode 的总量,未使用的 block 和 inode 的数量(如果没有 GDT,这些信息需要遍历块位图和 inode 位图,降低了效率),一个block 和 inode 的大小,下一个可以分配的 inode 编号,最近一次挂载的时间,最近一次写入数据的时间,最近一次检验磁盘的时间等其他文件系统的相关信息。
- 块位图(Block Bitmap):Block Bitmap 中的一个 bit 位记录着 Data Block 中哪个数据块已经被占用,哪个数据块没有被占用,比特位的位置与块号一一对应,
- inode位图(inode Bitmap):比特位的位置与 inode 编号一一对应,每个 bit 表示 inode table 的一个 inode 是否有效。
格式化:在使用磁盘的分区之前,都要先对该分区格式化,即初始化超级块、GDT、block 和 inode 位图。
要删除一个文件,只需要修改 Block Bitmap 和 inode Bitmap 的内容即可,如果想要恢复一个文件,只需要知道要恢复的文件的 inode,在 inode Bitmap 把对应 inode 置为有效,再根据对应的 inode 把 Block Bitmap 的块置为已占用。
- i节点表(inode Table): 这是一张表,存放了多个 inode,一个 inode 通常是 128 字节,有唯一的编号,用于存放文件属性如文件类型,文件大小,所有者,最近修改时间,占用了哪些块等。一般而言一个文件对应一个 inode。注意:inode 中并没有存储文件的名称。
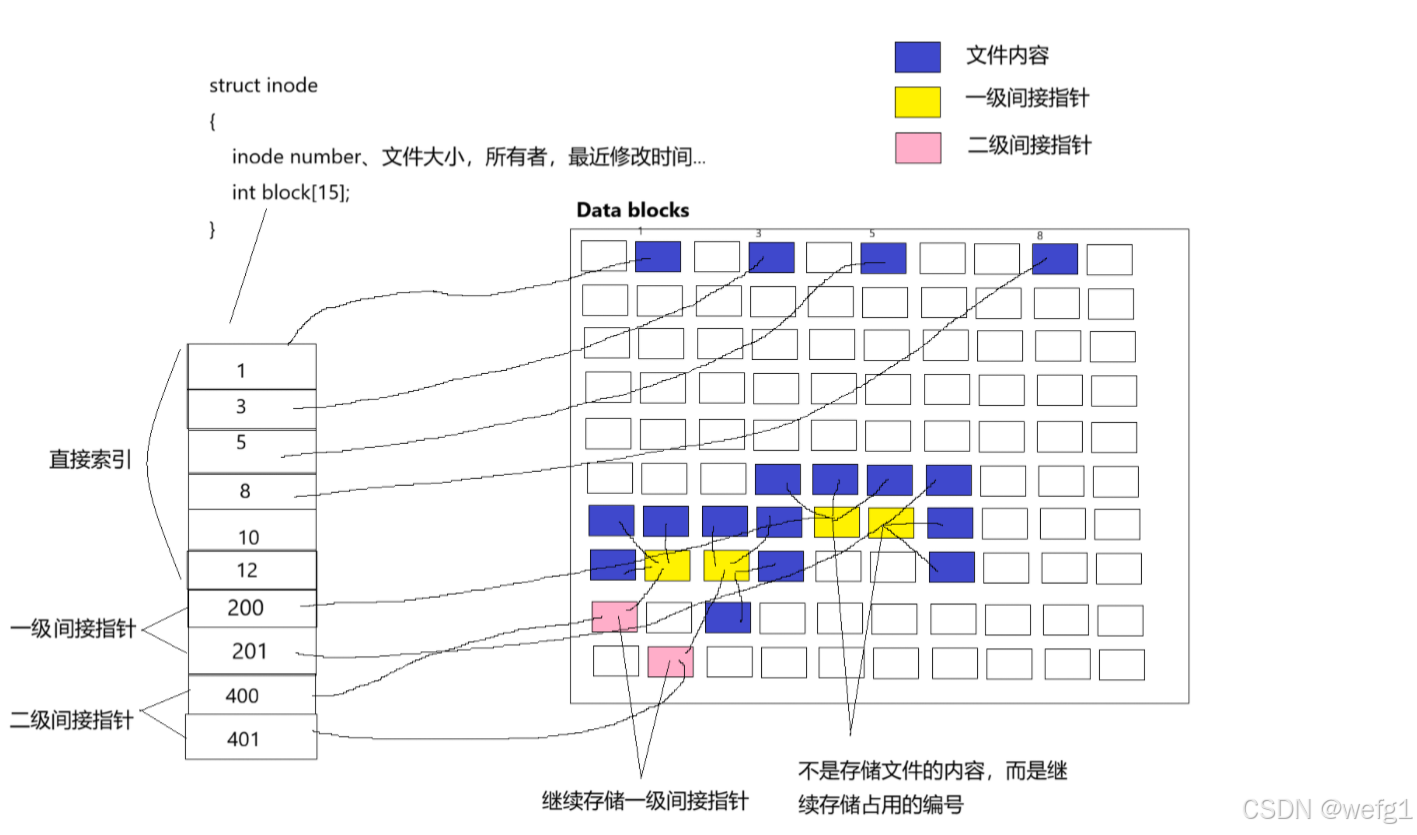
i节点表中存储文件占用了哪些块的数组:
Inode 中存储的是指向数据块的指针,但并非简单的"数组",而是一个精心设计的、多层级的间接指针系统。
- 数据区(Data blocks):存放文件内容,以块的形式呈现,常见大小是 4KB,mke2fs的 -b 选项可以设置块的大小是为1024、2048或4096字节。即使向一个文件只写入一个字符,也会分配一个块,而不是用多少分配多少。一个文件通常是最后一个块才有一点点空间浪费。
文件名与 inode
使用 stat 文件名 指令可以查看文件的更多信息。is -li 可以查看文件的 inode 编号。
我们平时在对文件进行增删查改时,用的都是文件名,而操作系统识别文件靠的是 inode,inode 是如何与文件名产生关联的?要回答这个问题,首先我们得理解目录:
bash
[hxh@VM-16-12-centos 2026_1_30]$ mkdir dir
[hxh@VM-16-12-centos 2026_1_30]$ ls -li
total 4
1048599 drwxrwxr-x 2 hxh hxh 4096 Jan 30 13:26 dir我们看到一个目录有自己的 inode,说明目录也是一个文件,有自己的属性和数据 。目录的数据中就存放了该目录下的文件的文件名和 inode 的映射关系,解释了 1、为什么同一目录下不能有相同的文件名 2、目录的权限问题:没有 w 权限,无法创建文件;没有 r 权限,无法查看文件;没有 x 权限,无法进入目录。现在解决了从目录中如何找到文件,还有一个问题没有解决,那就是如何找到目录。解决方法:操作系统找文件,必须是绝对路径,我们平时虽然没有使用绝对路径,但进程的环境变量、内核数据 cwd 已经帮我们记好绝对路径,绝对路径的起始是根目录,即:操作系统从根目录开始递归遍历找到当前目录。但这样未免效率低下,所以有 dentry 缓存:操作系统会记下我们访问过的目录,下次再访问时,就可以快速的找到
文件系统总结:Linux 下一切皆文件,所有文件被存储的最终表现形式是 inode (文件属性)和 data block(文件内容)。
软硬链接
建立软连接的方式
bash
ln -s 目标文件名 链接名建立硬连接的方式
bash
ln 目标文件名 链接名删除链接的方式
bash
unlink 链接名接下来尝试建立软链接,观察文件属性:
bash
[hxh@VM-16-12-centos 2026_1_30]$ touch file.txt
[hxh@VM-16-12-centos 2026_1_30]$ ln -s file.txt soft-link
[hxh@VM-16-12-centos 2026_1_30]$ ls -li
total 0
1048599 -rw-rw-r-- 1 hxh hxh 0 Jan 30 14:11 file.txt
1048600 lrwxrwxrwx 1 hxh hxh 8 Jan 30 14:11 soft-link -> file.txt软链接 soft-link 和 file.txt 的 inode 编号不同,说明 soft-link 是独立的文件,有自己的 inode,文件内容就是一个纯文本的路径字符串,可以使用 readlink 软链接名 查看软链接的内容。
bash
[hxh@VM-16-12-centos 2026_1_30]$ touch test.txt
[hxh@VM-16-12-centos 2026_1_30]$ ln test.txt hard-link
[hxh@VM-16-12-centos 2026_1_30]$ ls -li
total 0
1048599 -rw-rw-r-- 1 hxh hxh 0 Jan 30 14:11 file.txt
1048601 -rw-rw-r-- 2 hxh hxh 0 Jan 30 14:16 hard-link
1048600 lrwxrwxrwx 1 hxh hxh 8 Jan 30 14:11 soft-link -> file.txt
1048601 -rw-rw-r-- 2 hxh hxh 0 Jan 30 14:16 test.txt建立硬链接后,hard-link 和 test.txt 的文件权限后面有个数字 2,这个数字表示文件的硬链接数 。我们发现 hard-link 和 test.txt 的 inode 是一样的,说明 hard-link 不是独立的文件,它可以看作是给文件起别名。实际上,硬链接不创建 inode,而是创建名为目录项的结构体,该结构体中存储了硬链接的链接名和它指向的文件的 inode。
在文件的 inode 中,有一个用于引用计数的整型计数器,它记录了该文件有多少个硬链接指向它。如果有多个硬链接指向它,只有删除最后一个硬链接后,该文件才会被删除。软链接是独立的文件,删除一个文件的软链接不会影响计数器。软链接相当于快捷方式。软链接应用场景:需要快速打开某个文件,而不想根据绝对路径打开。硬链接应用场景:
bash
[hxh@VM-16-12-centos 2026_1_30]$ mkdir dir
[hxh@VM-16-12-centos 2026_1_30]$ ll
total 4
drwxrwxr-x 2 hxh hxh 4096 Jan 30 15:09 dir建立一个目录后,我们没有建立硬链接,但是 dir 目录的硬链接数却是 2,如果我们 cd dir:
bash
[hxh@VM-16-12-centos 2026_1_30]$ ls -li
total 4
1048599 drwxrwxr-x 2 hxh hxh 4096 Jan 30 15:09 dir
[hxh@VM-16-12-centos 2026_1_30]$ cd dir
[hxh@VM-16-12-centos dir]$ ls -lia
total 8
1048599 drwxrwxr-x 2 hxh hxh 4096 Jan 30 15:09 .
1048598 drwxrwxr-x 3 hxh hxh 4096 Jan 30 15:09 ..dir 目录内还有两个自动生成的目录:. 表示当前目录,它的 inode 与 dir 的 inode 一样,所以 . 是dir 目录的硬链接,也可以解释为什么 .. (表示上级目录)的硬链接数为什么是 3,因为上级目录也有 . 指向它。
Linux 系统允许对目录建立软链接,但不允许建立硬链接 。原因:防止目录环路 ,如果允许目录硬链接,就可能出现 A/B/C 中的 C 又链接回 A 的情况(C 是 A 的硬链接)这将导致遍历目录时陷入无限循环,许多文件系统检查工具都假定目录不会形成环路。. 和 .. 是操作系统开发者建立的,在逻辑上 .. 确实会形成环路问题,但是遍历文件多叉树结构时不会遍历 . 和 .. 。即使是 root 用户,也不允许对目录建立硬链接。正是有了 . 和 .. ,才有了相对路径的概念。