一、持久化
Redis的高性能是由于其将所有数据都存储在了内存中,为了使Redis在重启之后仍能保证数据不丢失,需要将数据从内存中同步到硬盘中,这一过程就是持久化。
Redis支持两种方式的持久化,一种是RDB方式,一种是AOF方式。可以单独使用其中一种或将二者结合使用。
1.AOF持久化
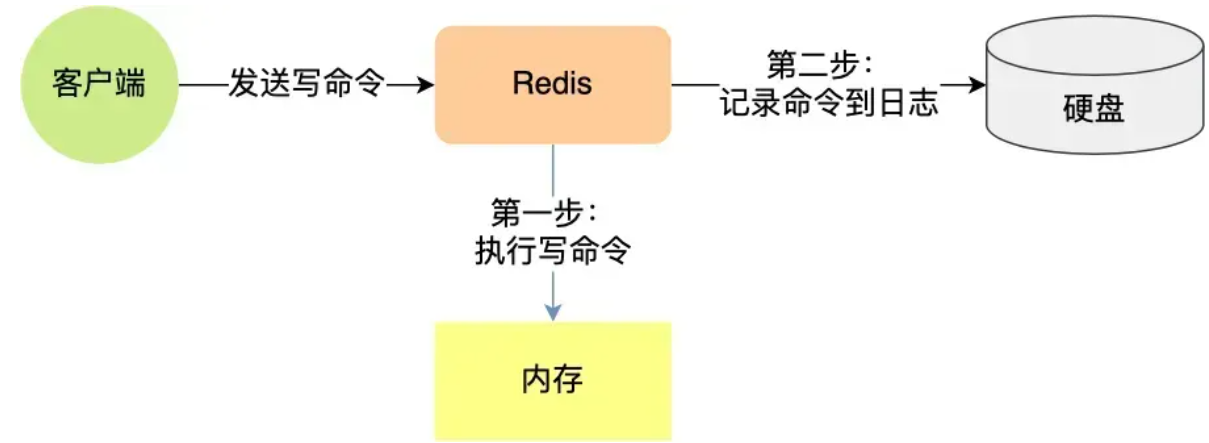
Redis 在执行完一条写操作命令后,就会把该命令以追加的方式写入到一个文件里,然后 Redis 重启时,会读取该文件记录的命令,然后逐一执行命令的方式来进行数据恢复。
可以通过appendonly参数开启:appendonly yes
开启AOF持久化后每执行一条会更改Redis中的数据的命令,Redis就会将该命令写入硬盘中的AOF文件。AOF文件的保存位置和RDB文件的位置相同,都是通过dir参数设置的,默认的文件名是appendonly.aof,可以通过appendfilename参数修改:appendfilename appendonly.aof。
2.RDB快照
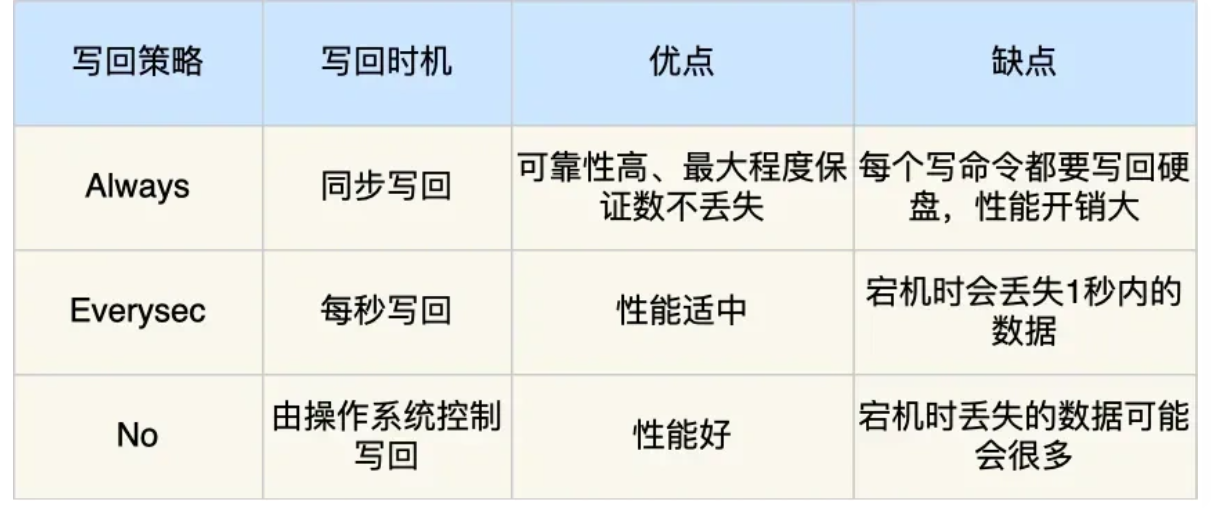
因为 AOF 日志记录的是操作命令, 不是实际的数据,所以用 AOF 方法做故障恢复时,需要全 量把日志都执行一遍,一旦 AOF 日志非常多,势必会造成 Redis 的恢复操作缓慢。为了解决这个问题,Redis 增加了 RDB 快照。
所谓的快照,就是记录某一个瞬间东西,比如当我们给风景拍照时,那一个瞬间的画面和信息 就记录到了一张照片。所以,RDB 快照就是记录某一个瞬间的内存数据,记录的是实际数据, 而 AOF 文件记录的是命令操作的日志,而不是实际的数据。因此在 Redis 恢复数据时, RDB 恢复数据的效率会比 AOF 高些,因为直接将 RDB 文件读入内存就可以,不需要像 AOF那样还需要额外执行操作命令的步骤才能恢复数据。
Redis 提供了两个命令来生成 RDB 文件,分别是 save 和 bqsave,他们的区别就在于是否在 「主线程」里执行:
- 执行了 save 命令,就会在主线程生成 RDB 文件,由于和执行操作命令在同一个线程,所以 如果写入 RDB 文件的时间太长,会阻塞主线程;
- 执行了 bqsave 命令,会创建一个子进程来生成 RDB 文件,这样可以避免主线程的阻塞。
在redis.conf中:
配置dir指定rdb快照文件的位置
配置dbfilenam指定rdb快照文件的名称
3.对比

二、主从复制
1.主redis配置:无需特殊配置
2.从redis配置
修改从redis服务器上的redis.conf文件,添加slaveof 主redisip 主redis 端口
3.配置实例
(1)准备三个redis实例,一个主库,两个从库,主库是6379,从库是6380和6381端口
(2)从库的配置:在redis.conf里面都加上下面的配置
bash
slave 云服务器ip 6379(主库ip)(3)启动三个redis实例,注意需要在云服务器的安全组和防火墙加上6379端口
(4)进入从库的客户端,看一下有没有主库的相关信息
bash
./redis-cli -p 6380
127.0.0.1:6380> info replication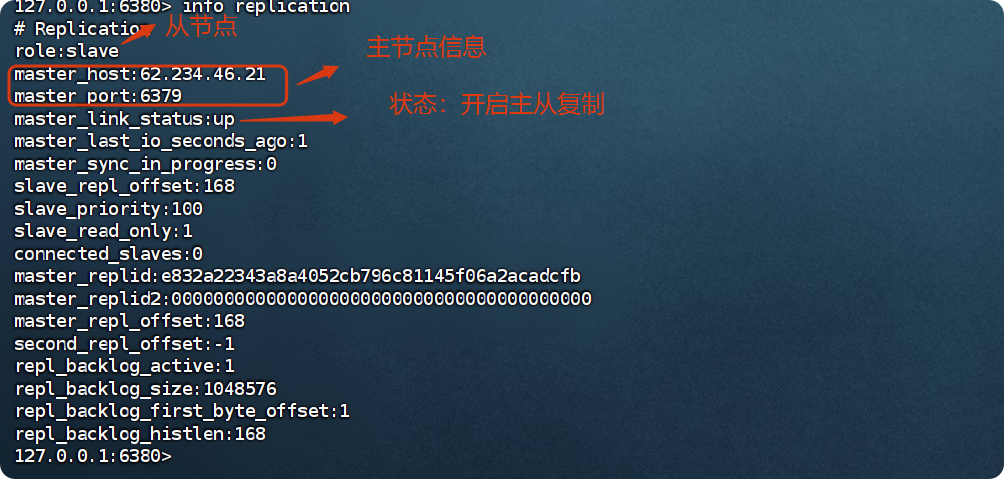
三、集群
我使用的是redis5.0.4版本
(一)创建六个redis节点
1.在usr/local目录下新建redis-cluster目录,用于存放集群节点
2.把redis目录下的bin目录下的所有文件复制到/usr/local/redis-cluster/redis01目录下,不用担心这里没有redis01目录,会自动创建的。操作命令如下(注意当前所在路径):
bash
cp -r redis/bin/ redis-cluster/redis013.删除redis01目录下的快照文件dump.rdb(如果有),修改redis.conf文件
下面的在配置文件里面都有,可以打开注释,进行修改
修改端口号为7001
bash
port 7001开启集群创建模式
bash
cluster-enabled yes开启后台启动
bash
daemonize yes修改集群配置文件:Redis 集群要求每个节点必须使用唯一的集群配置文件
bash
cluster-config-file nodes-7001.conf4.将redis-cluster/redis01文件复制5份到redis-cluster目录下(redis02-redis06),创建6个redis实例,模拟Redis集群的6个节点。然后将其余5个文件下的redis.conf里面的端口号分别修改为7002-7006,cluster-config-file也改成7002-7006
bash
#示例
cp -r redis01/ redis025.接着启动所有redis节点,由于一个一个启动太麻烦了,所以在这里在redis-cluster下面创建一个批量启动redis节点的脚本文件,命令为start-all.sh,文件内容如下:
bash
cd redis01
./redis-server redis.conf
cd ..
cd redis02
./redis-server redis.conf
cd ..
cd redis03
./redis-server redis.conf
cd ..
cd redis04
./redis-server redis.conf
cd ..
cd redis05
./redis-server redis.conf
cd ..
cd redis06
./redis-server redis.conf
cd ..并且修改权限:
bash
chmod +x start-all.sh6.在redis-cluster下面运行命令执行start-all.sh脚本,启动6个redis节点
bash
./start-all.sh(二)搭建集群
1.如果你的redis版本在5之下,那么你就需要安装ruby,我的版本是5.0.4,所以不需要这个工具。
2.集群启动
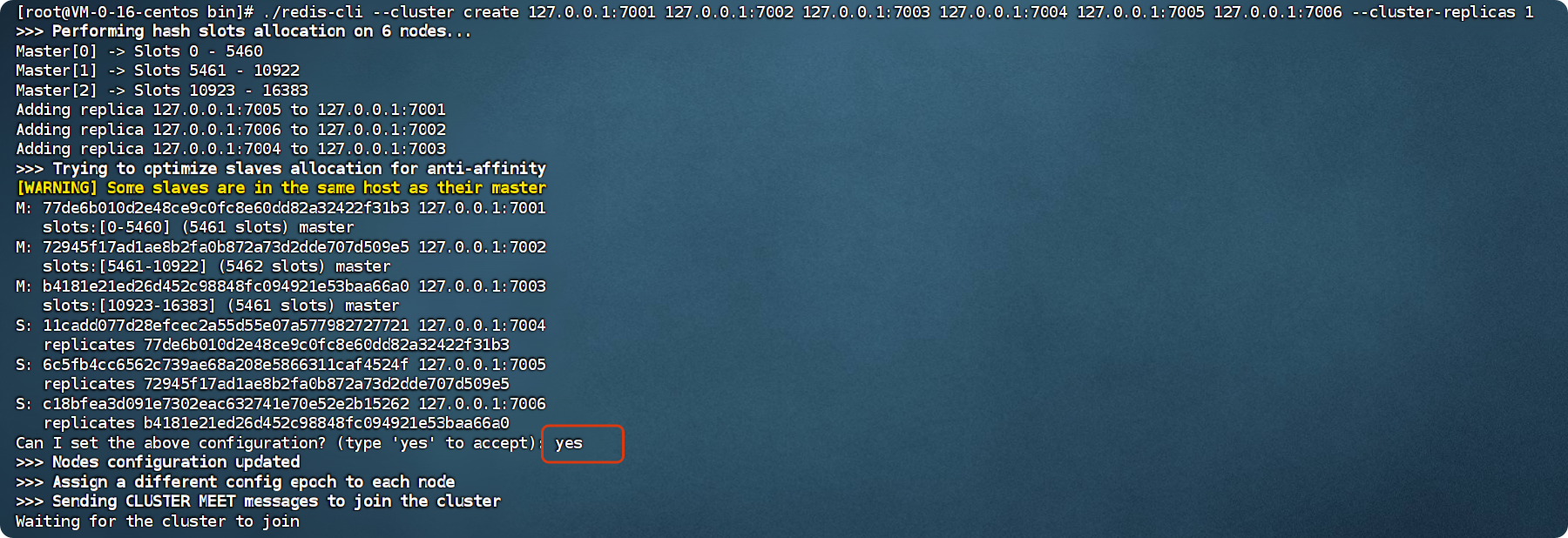
这里的replicas 1表示副本为1个,也就是现在是三主,每个主redis下有一个从redis
bash
redis-cli --cluster create 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005 127.0.0.1:7006 --cluster-replicas 1输入yes确认配置
4.测试集群
-c 表示集群模式 redis-cli表示client模式进入redis,-p表示端口号
也就是进入7001这个redis,使用cluster nodes看看有哪些其他节点信息。
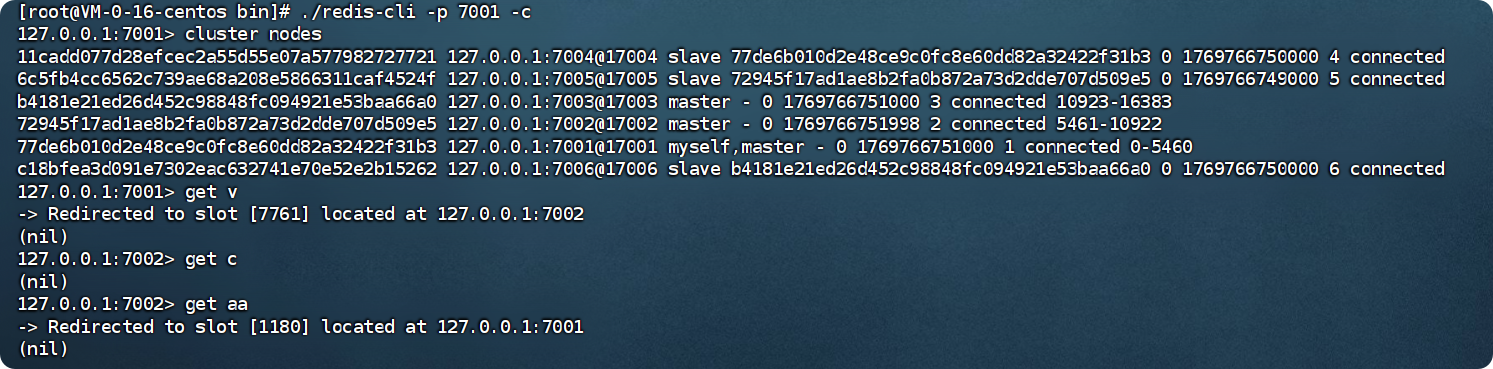
可以看到不同的key值被分配到了不同的机器上,也就是成功部署了redis cluster集群模式
四、使用springboot连接集群
一定要在安全组和防火墙都设置好端口:7001-7006
bash
sudo firewall-cmd --zone=public --add-port=7001-7006/tcp --permanent
firewall-cmd --reload1.pom添加redis starter
XML
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>2.添加redistemplate
java
@Configuration
public class RedisConfig {
@Bean
public RedisTemplate<Object, Object> redisTemplate(RedisConnectionFactory redisConnectionFactory) {
Jackson2JsonRedisSerializer serializer=new Jackson2JsonRedisSerializer(Object.class);
RedisTemplate<Object, Object> template = new RedisTemplate<>();
template.setConnectionFactory(redisConnectionFactory);
template.setKeySerializer(serializer); //设置key序列化
template.setValueSerializer(serializer);//设置value序列化
return template; } }3.application.properties 文件添加redis集群
java
#刷新节点与槽位的映射关系
spring.redis.cluster.expire-seconds=120
#设置redis集群的节点信息,这个ip如果你的代码是在云服务器部署,
那你就写对应的云服务器的内网ip(保证几台云服务器都在同一个账号的同一个地域下面),
如果是代码在本地的话,就写公网ip,当然了我们是一个服务器开了多个redis实例,实际工作肯定是部署在多台服务器的
spring.redis.cluster.nodes=192.168.31.96:7001,192.168.31.96:7002,192.168.31.96:7003,192.168.31.96:7004,192.168.31.96:7005,192.168.31.96:7006
#设置命令的执行时间,如果超过这个时间,则报错
spring.redis.cluster.command-timeout=5000