文章目录
- 1、reduce是什么?
- 2、原子操作
- 3.树形规约
-
- 3.1.优化1-交错寻址
- [3.2.优化2-解决Bank Conflict](#3.2.优化2-解决Bank Conflict)
- 3.3.优化3-改善线程空闲问题
- 3.4.优化4-展开最后一个warp
- [3.5.优化5-Warp Shuffle 指令](#3.5.优化5-Warp Shuffle 指令)
1、reduce是什么?
j简单来讲,reduce就是对一个数组求最大值、最小值、求和等过程。reduce又被称之为规约。通过reduce,我们可以获得一个比输入维度递减的输出。本文以求和为例来记录CUDA reduce相关过程。
对于一个一维数组求和,在cpu上执行非常简单,一个for循环就能解决。但在gpu上确是个老大难。需要精巧的树形结构设计:
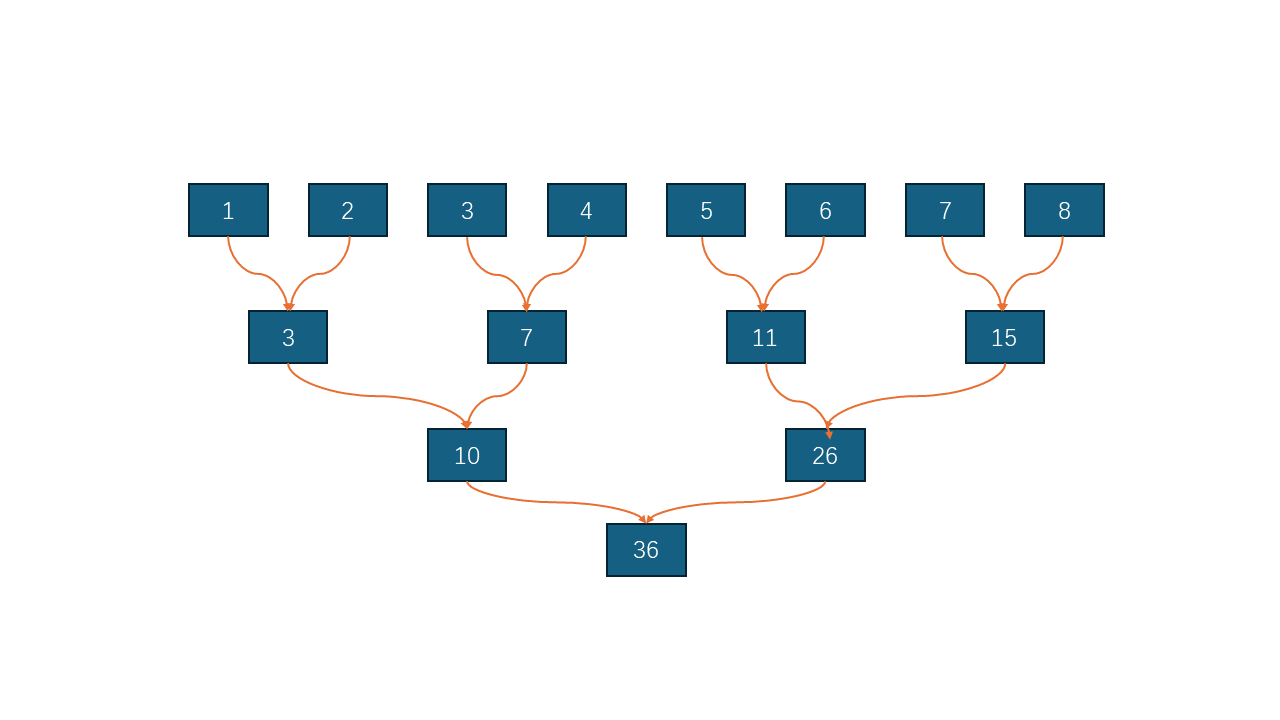
图片12、原子操作
cpp
#include <cuda.h>
#include <cuda_runtime.h>
#include <time.h>
#define N 32*1024*1024
#define BLOCK_SIZE 256
#include <cuda_runtime.h>
__global__ void reduce_v0(float *g_idata,float *g_odata, unsigned int n){
int i = blockIdx.x * blockDim.x + threadIdx.x;
if (i < n) {
// 所有线程都往同一个地址 g_odata[0] 加数据
atomicAdd(g_odata, g_idata[i]);
}
}
int main() {
float *input_host = (float*)malloc(N*sizeof(float));
float *input_device;
cudaMalloc((void **)&input_device, N*sizeof(float));
for (int i = 0; i < N; i++) input_host[i] = 2.0;
cudaMemcpy(input_device, input_host, N*sizeof(float), cudaMemcpyHostToDevice);
int32_t block_num = (N + BLOCK_SIZE - 1) / BLOCK_SIZE;
float *output_host = (float*)malloc((N / BLOCK_SIZE) * sizeof(float));
float *output_device;
cudaMalloc((void **)&output_device, (N / BLOCK_SIZE) * sizeof(float));
dim3 grid(N / BLOCK_SIZE, 1);
dim3 block(BLOCK_SIZE, 1);
reduce_v0<<<grid, block>>>(input_device, output_device,N);
cudaMemcpy(output_device, output_host, block_num * sizeof(float), cudaMemcpyDeviceToHost);
return 0;
}通过atomicAdd()进行原子性的相加,代码极其简洁,但代价巨大。原子操作导致并行退化成串行,成千上万的线程都在等待g_odata0。我们监控一下性能:
| 指标名称 | 单位 | 值 |
|---|---|---|
| DRAM Frequency | cycle/nsecond | 9.49 |
| SM Frequency | cycle/nsecond | 1.36 |
| Elapsed Cycles | cycle | 99572395 |
| Memory % | % | 1.38 |
| DRAM Throughput | % | 0.20 |
| Duration | msecond | 72.95 |
| L1/TEX Cache Throughput | % | 0.86 |
| L2 Cache Throughput | % | 1.38 |
| SM Active Cycles | cycle | 99527250.44 |
| Compute (SM) % | % | 0.42 |
好家伙,这效率比马里亚纳海沟还低,跑这几个数跑了72.95ms,我倒着跑都比这跑的快,显存利用率高达惊人的0.2%,还没我脸上的痘高,SM一整个在空转,都快赶上小彩旗了。用gpu去跑串行,好比用挖耳勺舀水喝,渴死你个大傻福。
3.树形规约
正统的解决方案是树形规约,可见如下代码:
cpp
#include <cuda.h>
#include <cuda_runtime.h>
#include <time.h>
#define N 32*1024*1024
#define BLOCK_SIZE 256
__global__ void reduce_v0(float *g_idata,float *g_odata){
__shared__ float sdata[BLOCK_SIZE];
unsigned int tid = threadIdx.x;
unsigned int i = blockIdx.x*blockDim.x + threadIdx.x;
sdata[tid] = g_idata[i];
__syncthreads();
// do reduction in shared mem
for(unsigned int s=1; s < blockDim.x; s *= 2) {
if (tid % (2*s) == 0) {
sdata[tid] += sdata[tid + s];
}
__syncthreads();
}
// write result for this block to global mem
if (tid == 0) g_odata[blockIdx.x] = sdata[0];
}
int main() {
float *input_host = (float*)malloc(N*sizeof(float));
float *input_device;
cudaMalloc((void **)&input_device, N*sizeof(float));
for (int i = 0; i < N; i++) input_host[i] = 2.0;
cudaMemcpy(input_device, input_host, N*sizeof(float), cudaMemcpyHostToDevice);
int32_t block_num = (N + BLOCK_SIZE - 1) / BLOCK_SIZE;
float *output_host = (float*)malloc((N / BLOCK_SIZE) * sizeof(float));
float *output_device;
cudaMalloc((void **)&output_device, (N / BLOCK_SIZE) * sizeof(float));
dim3 grid(N / BLOCK_SIZE, 1);
dim3 block(BLOCK_SIZE, 1);
reduce_v0<<<grid, block>>>(input_device, output_device);
cudaMemcpy(output_device, output_host, block_num * sizeof(float), cudaMemcpyDeviceToHost);
return 0;
}我们测一下这段代码的性能;
| 指标名称 | 单位 | 值 |
|---|---|---|
| DRAM Frequency | cycle/nsecond | 9.49 |
| SM Frequency | cycle/nsecond | 1.36 |
| Elapsed Cycles | cycle | 1139484 |
| Memory % | % | 62.69 |
| DRAM Throughput | % | 17.72 |
| Duration | usecond | 835.52 |
| L1/TEX Cache Throughput | % | 62.81 |
| L2 Cache Throughput | % | 7.84 |
| SM Active Cycles | cycle | 1137329.38 |
| Compute (SM) % | % | 69.49 |
性能大提升!
代码理解起来很简单,代码使用了共享内存sdata,表明各个block块相对独立运算。 sdatatid = g_idatai;代表对每个block块中的sdata进行赋值。for循环实现了图片1中的逻辑,对于一个block中的某个线程来讲,每一次循环都会有部分线程参与运算,并且越来越少,直到最后结果保存在sdata0,是这个block块所负责的数据之和。所以有几个block,g_odata中就有几个值。
但上述的代码还存在几个问题:
1. 线程束分化(warp divergent)
线程束(warp)是gpu的基本执行单元,一个线程束包含32个线程,一个block块中包含若干个warp。而且同一个线程束内的所有线程必须执行相同的指令。所以说如果线程束内的线程在条件语句中走不同的分支,GPU 会串行执行所有不同的分支路径,导致性能大幅下降。
所以说if (tid % (2*s) == 0)这行代码,其实的执行顺序是(以s==1时举例),16个线程执行此分支(分支A),另外16的线程等待,分支执行结束后,执行分支A的16个线程等待,另外16的线程执行分支B.
2. 线程空闲浪费
每一轮迭代都有大量线程空闲,而且一轮比一轮多。
3.1.优化1-交错寻址
代码如下:
cpp
#include <cuda.h>
#include <cuda_runtime.h>
#include <time.h>
#define N 32*1024*1024
#define BLOCK_SIZE 256
__global__ void reduce_v0(float *g_idata,float *g_odata){
__shared__ float sdata[BLOCK_SIZE];
unsigned int tid = threadIdx.x;
unsigned int i = blockIdx.x*blockDim.x + threadIdx.x;
sdata[tid] = g_idata[i];
__syncthreads();
// do reduction in shared mem
for(unsigned int s=1; s < blockDim.x; s *= 2) {
int index = 2*s*tid;
if(index<blockDim.x){
sdata[index]+=sdata[index+s];
}
}
// write result for this block to global mem
if (tid == 0) g_odata[blockIdx.x] = sdata[0];
}
int main() {
float *input_host = (float*)malloc(N*sizeof(float));
float *input_device;
cudaMalloc((void **)&input_device, N*sizeof(float));
for (int i = 0; i < N; i++) input_host[i] = 2.0;
cudaMemcpy(input_device, input_host, N*sizeof(float), cudaMemcpyHostToDevice);
int32_t block_num = (N + BLOCK_SIZE - 1) / BLOCK_SIZE;
float *output_host = (float*)malloc((N / BLOCK_SIZE) * sizeof(float));
float *output_device;
cudaMalloc((void **)&output_device, (N / BLOCK_SIZE) * sizeof(float));
dim3 grid(N / BLOCK_SIZE, 1);
dim3 block(BLOCK_SIZE, 1);
reduce_v0<<<grid, block>>>(input_device, output_device);
cudaMemcpy(output_device, output_host, block_num * sizeof(float), cudaMemcpyDeviceToHost);
return 0;
}我们测一下这段代码的性能;
| 指标名称 | 单位 | 值 |
|---|---|---|
| DRAM Frequency | cycle/nsecond | 9.49 |
| SM Frequency | cycle/nsecond | 1.36 |
| Elapsed Cycles | cycle | 826206 |
| Memory % | % | 86.46 |
| DRAM Throughput | % | 24.45 |
| Duration | usecond | 606.02 |
| L1/TEX Cache Throughput | % | 86.70 |
| L2 Cache Throughput | % | 10.81 |
| SM Active Cycles | cycle | 823932.49 |
| Compute (SM) % | % | 86.46 |
比之前性能有所提升。通过修改判断条件,明显减少warp divergent的次数。当s=1时,0-3wrap正好处于index<blockDim.x条件内,4-7wrap正好处于条件外,无warp divergent产生。当s=2时0、1warp满足条件,其他不满足,无warp divergent产生,也就是说直到第四次迭代才会产生warp divergent,比之前迭代一次产生一次要强的多。
问题:
存在存储体冲突(Bank Conflict)
在一个block块中,共享内存被分为32个存储体(bank)如下图:
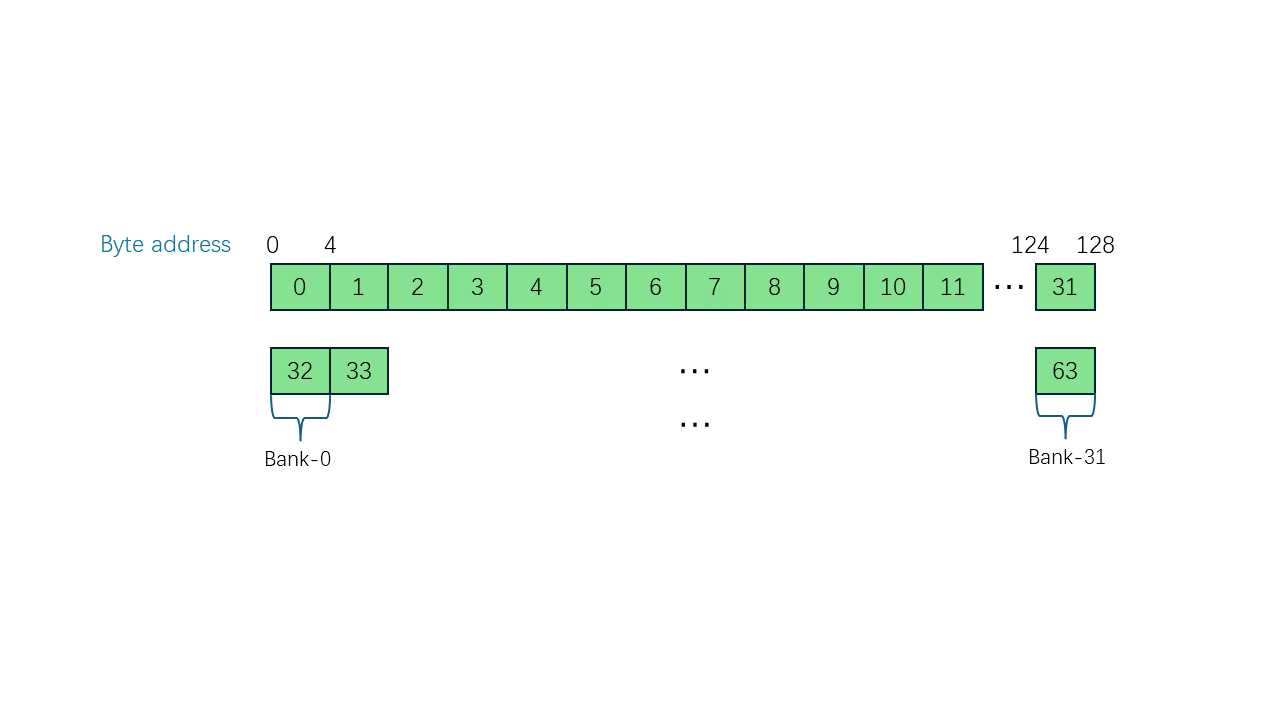
Bank Conflict表示在一个warp中,两个或者多个线程去访问同一个bank。
譬如在上述代码中,当s=1时,warp0中同时存在线程0与线程16对同一个bank的不同地址操作(访问地址0与地址32,同一bank)导致Bank Conflict;当s=1时,warp0同样存在线程0与线程线程8的Bank Conflict。
3.2.优化2-解决Bank Conflict
代码:
cpp
#include <cuda.h>
#include <cuda_runtime.h>
#include <time.h>
#define N 32*1024*1024
#define BLOCK_SIZE 256
__global__ void reduce_v0(float *g_idata,float *g_odata){
__shared__ float sdata[BLOCK_SIZE];
unsigned int tid = threadIdx.x;
unsigned int i = blockIdx.x*blockDim.x + threadIdx.x;
sdata[tid] = g_idata[i];
__syncthreads();
// do reduction in shared mem
for(unsigned int s=blockDim.x/2; s>0; s >>= 1) {
if (tid < s){
sdata[tid] += sdata[tid + s];
}
__syncthreads();
}
// write result for this block to global mem
if (tid == 0) g_odata[blockIdx.x] = sdata[0];
}
int main() {
float *input_host = (float*)malloc(N*sizeof(float));
float *input_device;
cudaMalloc((void **)&input_device, N*sizeof(float));
for (int i = 0; i < N; i++) input_host[i] = 2.0;
cudaMemcpy(input_device, input_host, N*sizeof(float), cudaMemcpyHostToDevice);
int32_t block_num = (N + BLOCK_SIZE - 1) / BLOCK_SIZE;
float *output_host = (float*)malloc((N / BLOCK_SIZE) * sizeof(float));
float *output_device;
cudaMalloc((void **)&output_device, (N / BLOCK_SIZE) * sizeof(float));
dim3 grid(N / BLOCK_SIZE, 1);
dim3 block(BLOCK_SIZE, 1);
reduce_v0<<<grid, block>>>(input_device, output_device);
cudaMemcpy(output_device, output_host, block_num * sizeof(float), cudaMemcpyDeviceToHost);
return 0;
}测试一下性能:
| 指标名称 | 单位 | 值 |
|---|---|---|
| DRAM Frequency | cycle/nsecond | 9.49 |
| SM Frequency | cycle/nsecond | 1.36 |
| Elapsed Cycles | cycle | 794072 |
| Memory % | % | 89.96 |
| DRAM Throughput | % | 25.43 |
| Duration | usecond | 582.37 |
| L1/TEX Cache Throughput | % | 90.22 |
| L2 Cache Throughput | % | 11.25 |
| SM Active Cycles | cycle | 791791.11 |
| Compute (SM) % | % | 89.96 |
通过扩大间隔可以有效减少bank conflict的产生次数。改进之后有效果,但是效果不大,主要还是有太多线程空闲导致,怎么把空闲的线程用起来是优化的方向。
3.3.优化3-改善线程空闲问题
cpp
#include <cuda.h>
#include <cuda_runtime.h>
#include <time.h>
#define N 32*1024*1024
#define BLOCK_SIZE 256
__global__ void reduce_v0(float *g_idata,float *g_odata){
__shared__ float sdata[BLOCK_SIZE];
unsigned int tid = threadIdx.x;
unsigned int i = blockIdx.x*(blockDim.x*2) + threadIdx.x;
sdata[tid] = g_idata[i]+g_idata[i+blockDim.x];
__syncthreads();
// do reduction in shared mem
for(unsigned int s=blockDim.x/2; s>0; s >>= 1) {
if (tid < s){
sdata[tid] += sdata[tid + s];
}
__syncthreads();
}
// write result for this block to global mem
if (tid == 0) g_odata[blockIdx.x] = sdata[0];
}
int main() {
float *input_host = (float*)malloc(N*sizeof(float));
float *input_device;
cudaMalloc((void **)&input_device, N*sizeof(float));
for (int i = 0; i < N; i++) input_host[i] = 2.0;
cudaMemcpy(input_device, input_host, N*sizeof(float), cudaMemcpyHostToDevice);
int32_t block_num = (N + BLOCK_SIZE - 1) / BLOCK_SIZE;
float *output_host = (float*)malloc((N / BLOCK_SIZE) * sizeof(float));
float *output_device;
cudaMalloc((void **)&output_device, (N / BLOCK_SIZE) * sizeof(float));
dim3 grid((N/2) / BLOCK_SIZE, 1);
dim3 block(BLOCK_SIZE, 1);
reduce_v0<<<grid, block>>>(input_device, output_device);
cudaMemcpy(output_device, output_host, block_num * sizeof(float), cudaMemcpyDeviceToHost);
return 0;
}测试一下性能:
| 指标名称 | 单位 | 值 |
|---|---|---|
| DRAM Frequency | cycle/nsecond | 9.49 |
| SM Frequency | cycle/nsecond | 1.36 |
| Elapsed Cycles | cycle | 412381 |
| Memory % | % | 89.79 |
| DRAM Throughput | % | 48.90 |
| Duration | usecond | 302.66 |
| L1/TEX Cache Throughput | % | 90.33 |
| L2 Cache Throughput | % | 21.33 |
| SM Active Cycles | cycle | 409900.95 |
| Compute (SM) % | % | 89.79 |
| 通过减少block变相减少线程的浪费,邪修,但管用。但是s<=32时,此时的block中只有一个warp0在干活时,但线程还在进行同步操作。这一条语句造成了极大的指令浪费。 |
3.4.优化4-展开最后一个warp
cpp
#include <cuda.h>
#include <cuda_runtime.h>
#include <time.h>
#define N 32*1024*1024
#define BLOCK_SIZE 256
__device__ void warpReduce(volatile float* cache, unsigned int tid){
cache[tid]+=cache[tid+32];
cache[tid]+=cache[tid+16];
cache[tid]+=cache[tid+8];
cache[tid]+=cache[tid+4];
cache[tid]+=cache[tid+2];
cache[tid]+=cache[tid+1];
}
__global__ void reduce_v0(float *g_idata,float *g_odata){
__shared__ float sdata[BLOCK_SIZE];
unsigned int tid = threadIdx.x;
unsigned int i = blockIdx.x*(blockDim.x*2) + threadIdx.x;
sdata[tid] = g_idata[i]+g_idata[i+blockDim.x];
__syncthreads();
// do reduction in shared mem
for(unsigned int s=blockDim.x/2; s>0; s >>= 1) {
if (tid < s){
sdata[tid] += sdata[tid + s];
}
__syncthreads();
}
if (tid < 32) warpReduce(sdata, tid);
// write result for this block to global mem
if (tid == 0) g_odata[blockIdx.x] = sdata[0];
}
int main() {
float *input_host = (float*)malloc(N*sizeof(float));
float *input_device;
cudaMalloc((void **)&input_device, N*sizeof(float));
for (int i = 0; i < N; i++) input_host[i] = 2.0;
cudaMemcpy(input_device, input_host, N*sizeof(float), cudaMemcpyHostToDevice);
int32_t block_num = (N + BLOCK_SIZE - 1) / BLOCK_SIZE;
float *output_host = (float*)malloc((N / BLOCK_SIZE) * sizeof(float));
float *output_device;
cudaMalloc((void **)&output_device, (N / BLOCK_SIZE) * sizeof(float));
dim3 grid((N/2) / BLOCK_SIZE, 1);
dim3 block(BLOCK_SIZE, 1);
reduce_v0<<<grid, block>>>(input_device, output_device);
cudaMemcpy(output_device, output_host, block_num * sizeof(float), cudaMemcpyDeviceToHost);
return 0;
}测试一下性能:
| 指标名称 | 单位 | 值 |
|---|---|---|
| DRAM Frequency | cycle/nsecond | 9.49 |
| SM Frequency | cycle/nsecond | 1.36 |
| Elapsed Cycles | cycle | 234901 |
| Memory % | % | 85.82 |
| DRAM Throughput | % | 85.86 |
| Duration | usecond | 175.01 |
| L1/TEX Cache Throughput | % | 70.43 |
| L2 Cache Throughput | % | 37.44 |
| SM Active Cycles | cycle | 232622.94 |
| Compute (SM) % | % | 69.78 |
| 管用。 |
3.5.优化5-Warp Shuffle 指令
cpp
#include <cuda.h>
#include <cuda_runtime.h>
#include <time.h>
#define N 32*1024*1024
#define BLOCK_SIZE 256
#define WARP_SIZE 32
template <unsigned int blockSize>
__device__ __forceinline__ float warpReduceSum(float sum) {
if (blockSize >= 32)sum += __shfl_down_sync(0xffffffff, sum, 16); // 0-16, 1-17, 2-18, etc.
if (blockSize >= 16)sum += __shfl_down_sync(0xffffffff, sum, 8);// 0-8, 1-9, 2-10, etc.
if (blockSize >= 8)sum += __shfl_down_sync(0xffffffff, sum, 4);// 0-4, 1-5, 2-6, etc.
if (blockSize >= 4)sum += __shfl_down_sync(0xffffffff, sum, 2);// 0-2, 1-3, 4-6, 5-7, etc.
if (blockSize >= 2)sum += __shfl_down_sync(0xffffffff, sum, 1);// 0-1, 2-3, 4-5, etc.
return sum;
}
template <unsigned int blockSize, int NUM_PER_THREAD>
__global__ void reduce_v0(float *g_idata,float *g_odata, unsigned int n){
float sum = 0;
// each thread loads one element from global to shared mem
unsigned int tid = threadIdx.x;
unsigned int i = blockIdx.x * (blockSize * NUM_PER_THREAD) + threadIdx.x;
#pragma unroll
for(int iter=0; iter<NUM_PER_THREAD; iter++){
sum += g_idata[i+iter*blockSize];
}
// Shared mem for partial sums (one per warp in the block)
static __shared__ float warpLevelSums[WARP_SIZE];
const int laneId = threadIdx.x % WARP_SIZE;
const int warpId = threadIdx.x / WARP_SIZE;
sum = warpReduceSum<blockSize>(sum);
if(laneId == 0 )warpLevelSums[warpId] = sum;
__syncthreads();
// read from shared memory only if that warp existed
sum = (threadIdx.x < blockDim.x / WARP_SIZE) ? warpLevelSums[laneId] : 0;
// Final reduce using first warp
if (warpId == 0) sum = warpReduceSum<blockSize/WARP_SIZE>(sum);
// write result for this block to global mem
if (tid == 0) g_odata[blockIdx.x] = sum;
}
int main() {
float *input_host = (float*)malloc(N*sizeof(float));
float *input_device;
cudaMalloc((void **)&input_device, N*sizeof(float));
for (int i = 0; i < N; i++) input_host[i] = 2.0;
cudaMemcpy(input_device, input_host, N*sizeof(float), cudaMemcpyHostToDevice);
int32_t block_num = (N + BLOCK_SIZE - 1) / BLOCK_SIZE;
float *output_host = (float*)malloc((N / BLOCK_SIZE) * sizeof(float));
float *output_device;
cudaMalloc((void **)&output_device, (N / BLOCK_SIZE) * sizeof(float));
dim3 grid((N/2) / BLOCK_SIZE, 1);
dim3 block(BLOCK_SIZE, 1);
reduce_v0<BLOCK_SIZE,2><<<grid, block>>>(input_device, output_device,N);
cudaMemcpy(output_device, output_host, block_num * sizeof(float), cudaMemcpyDeviceToHost);
return 0;
}测试一下性能:
| 指标名称 | 单位 | 值 |
|---|---|---|
| DRAM Frequency | cycle/nsecond | 9.49 |
| SM Frequency | cycle/nsecond | 1.36 |
| Elapsed Cycles | cycle | 211946 |
| Memory % | % | 95.13 |
| DRAM Throughput | % | 95.13 |
| Duration | usecond | 159.04 |
| L1/TEX Cache Throughput | % | 65.71 |
| L2 Cache Throughput | % | 41.47 |
| SM Active Cycles | cycle | 209443.11 |
| Compute (SM) % | % | 64.94 |
在 Kepler 架构之后,CUDA 引入了 Shuffle Instruction。它允许 同一个 Warp 内的线程直接交换寄存器数据,而无需经过 Shared Memory。不再以block块为个体,以每一个warp为个体。通过调整NUM_PER_THREAD和grid的值还可以让程序更快。
参考 :
【BBuf的CUDA笔记】三,reduce优化入门学习笔记
CUDA高性能计算系列08:原子操作与归约算法(Reduce)
