㊙️本期内容已收录至专栏《Python爬虫实战》,持续完善知识体系与项目实战,建议先订阅收藏,后续查阅更方便~持续更新中!
㊗️爬虫难度指数:⭐
🚫声明:本数据&代码仅供学习交流,严禁用于商业用途、倒卖数据或违反目标站点的服务条款等,一切后果皆由使用者本人承担。公开榜单数据一般允许访问,但请务必遵守"君子协议",技术无罪,责任在人。

全文目录:
-
-
- [🌟 开篇语](#🌟 开篇语)
- [1️⃣ 摘要(Abstract)](#1️⃣ 摘要(Abstract))
- [2️⃣ 背景与需求(Why)](#2️⃣ 背景与需求(Why))
- [3️⃣ 合规与注意事项(必写)](#3️⃣ 合规与注意事项(必写))
- [4️⃣ 技术选型与整体流程(What/How)](#4️⃣ 技术选型与整体流程(What/How))
- [5️⃣ 环境准备与依赖安装(可复现)](#5️⃣ 环境准备与依赖安装(可复现))
- [6️⃣ 核心实现:请求层(Fetcher)](#6️⃣ 核心实现:请求层(Fetcher))
- [7️⃣ 核心实现:解析层(Parser - CSS Selector 专场)](#7️⃣ 核心实现:解析层(Parser - CSS Selector 专场))
- [8️⃣ 数据存储与导出(Storage - 生成 Markdown)](#8️⃣ 数据存储与导出(Storage - 生成 Markdown))
- [9️⃣ 运行方式与结果展示(必写)](#9️⃣ 运行方式与结果展示(必写))
- [🔟 常见问题与排错(Expert Advice)](#🔟 常见问题与排错(Expert Advice))
- [1️⃣1️⃣ 进阶优化(可选但加分)](#1️⃣1️⃣ 进阶优化(可选但加分))
- [1️⃣2️⃣ 总结与延伸阅读](#1️⃣2️⃣ 总结与延伸阅读)
- [🌟 文末](#🌟 文末)
-
- [📌 专栏持续更新中|建议收藏 + 订阅](#📌 专栏持续更新中|建议收藏 + 订阅)
- [✅ 互动征集](#✅ 互动征集)
-
🌟 开篇语
哈喽,各位小伙伴们你们好呀~我是【喵手】。
运营社区: C站 / 掘金 / 腾讯云 / 阿里云 / 华为云 / 51CTO
欢迎大家常来逛逛,一起学习,一起进步~🌟
我长期专注 Python 爬虫工程化实战 ,主理专栏 《Python爬虫实战》:从采集策略 到反爬对抗 ,从数据清洗 到分布式调度 ,持续输出可复用的方法论与可落地案例。内容主打一个"能跑、能用、能扩展 ",让数据价值真正做到------抓得到、洗得净、用得上。
📌 专栏食用指南(建议收藏)
- ✅ 入门基础:环境搭建 / 请求与解析 / 数据落库
- ✅ 进阶提升:登录鉴权 / 动态渲染 / 反爬对抗
- ✅ 工程实战:异步并发 / 分布式调度 / 监控与容错
- ✅ 项目落地:数据治理 / 可视化分析 / 场景化应用
📣 专栏推广时间 :如果你想系统学爬虫,而不是碎片化东拼西凑,欢迎订阅/关注专栏👉《Python爬虫实战》👈
💕订阅后更新会优先推送,按目录学习更高效💯~
1️⃣ 摘要(Abstract)
本文将构建一个针对传统博客平台(以博客园 Cnblogs 个人主页为例)的整站备份工具。我们将使用 requests 处理翻页请求,利用 CSS 选择器 (soup.select) 高效提取文章的标题 、发布日期 、标签 以及HTML正文 。最核心的创新点在于:我们会使用 html2text 库将网页内容清洗为 Markdown 格式,并自动生成包含元数据的 YAML Front Matter ,最终产出可以直接导入 Hexo/Hugo 的 .md 文件。
读完这篇你能获得什么?
- 🎨 技能解锁:精通 CSS 选择器语法,体验比 XPath 更符合前端直觉的定位方式。
- 🔄 格式转换:学会将 HTML 自动化转换为 Markdown 的核心技术。
- 📂 工程实践:掌握如何为每一篇文章生成标准的文件名和元数据头。
2️⃣ 背景与需求(Why)
为什么要爬?
- 数据主权:平台可能会倒闭、封号或改版,只有保存在自己硬盘里的 Markdown 才是真正属于你的资产。
- 二次分发:想把旧文章同步到掘金、知乎或公众号?有了 Markdown 源码,复制粘贴只需一秒。
- 写作分析:通过抓取"发布日期"和"标签",你可以分析自己哪一年产出最高,或者最关注哪个技术领域。
目标站点 :博客园某博主主页(示例:https://www.cnblogs.com/[username]/default.html?page=1)
目标字段清单:
| 字段名 | 说明 | 示例值 |
|---|---|---|
title |
文章标题 | Python 异步编程实战指南 |
date |
发布时间 | 2025-08-21 14:30 |
tags |
标签列表 | [Python, Asyncio, 爬虫] |
content |
正文内容 | (转换后的 Markdown 文本) |
3️⃣ 合规与注意事项(必写)
知识无价,尊重作者:
- 版权声明 :本爬虫仅限备份自己的博客 或经授权的迁移。严禁批量爬取他人文章进行洗稿、转载或商业获利。
- Robots.txt:博客园通常允许搜索引擎和个人爬虫访问公开页面,但禁止高频抓取。
- 频率控制:老规矩,单线程 + 随机休眠。博客园的反爬机制虽然不严,但触发频率限制后会封 IP 几小时,得不偿失。
4️⃣ 技术选型与整体流程(What/How)
技术选型:Requests + BeautifulSoup (CSS Selector) + html2text
- CSS Selector :也就是
soup.select()。对于熟悉前端开发(jQuery/CSS)的同学来说,这是最直观的提取方式。比如提取标题就是.postTitle a,简单粗暴。 - html2text :这是一个非常有用的 Python 库,能把 HTML 标签(如
<h1>,<b>,<a>)"翻译"成 Markdown 语法(#,**,[]())。
整体流程图:
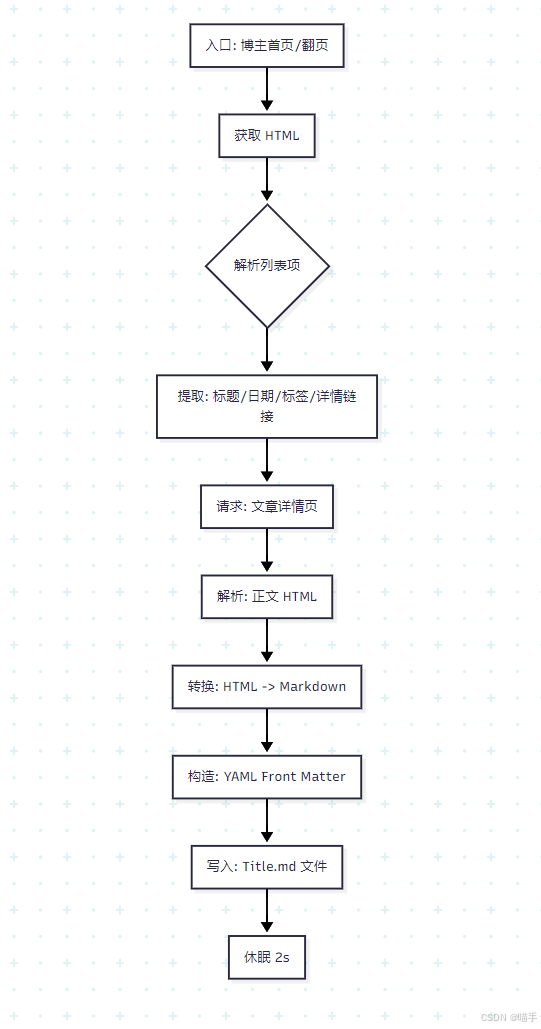
5️⃣ 环境准备与依赖安装(可复现)
Python 版本:3.8+
依赖安装 :
这次我们需要引入 html2text 这个转换神器。
bash
pip install requests beautifulsoup4 html2text项目目录结构:
text
blog_migrator/
├── posts/ # 结果存放(markdown 文件)
├── migrator.py # 主程序
└── config.py # 配置文件(用户名等)6️⃣ 核心实现:请求层(Fetcher)
为了应对博客可能存在的反爬(如检测 Referer),我们将 headers 封装得更加像真实用户访问。
python
import requests
import time
import random
class BlogFetcher:
def __init__(self):
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36',
# 加上 Referer 有时能避开防盗链
'Referer': 'https://www.cnblogs.com/'
}
self.session = requests.Session()
self.session.headers.update(self.headers)
def get_page(self, url):
"""通用请求方法,带重试和状态检查"""
try:
# 随机休眠,模拟阅读间隔
time.sleep(random.uniform(1, 2.5))
print(f"📡 正在抓取: {url}")
resp = self.session.get(url, timeout=15)
if resp.status_code == 200:
return resp.text
elif resp.status_code == 404:
print(f"⚠️ 页面不存在: {url}")
return None
else:
print(f"❌ 请求异常,状态码: {resp.status_code}")
return None
except Exception as e:
print(f"❌ 网络错误: {e}")
return None7️⃣ 核心实现:解析层(Parser - CSS Selector 专场)
这里我们将展示 CSS 选择器的优雅之处。
例如:
- XPath :
//div[@class='post']/h2/a/text() - CSS :
.post h2 a(是不是简洁很多?)
python
from bs4 import BeautifulSoup
import html2text
class BlogParser:
def __init__(self):
# 初始化 markdown 转换器
self.converter = html2text.HTML2Text()
self.converter.ignore_links = False # 保留链接
self.converter.ignore_images = False # 保留图片
self.converter.body_width = 0 # 不自动换行,这点很重要!
def parse_list(self, html):
"""解析文章列表页"""
soup = BeautifulSoup(html, 'html.parser')
articles = []
# 博客园标准结构:class="day" 表示一天的内容,里面可能有几篇 class="postTitle"
# 使用 CSS 选择器定位每一篇文章块
# 注意:不同主题模板结构可能不同,这里以官方默认主题为例
post_items = soup.select('.day')
for item in post_items:
# 提取日期(通常在 .dayTitle 中)
date_raw = item.select_one('.dayTitle a').get_text(strip=True) if item.select_one('.dayTitle a') else ""
# 一天可能发多篇,遍历下面的 .postTitle
titles = item.select('.postTitle a')
for link_tag in titles:
title = link_tag.get_text(strip=True)
url = link_tag['href']
articles.append({
"title": title,
"date": date_raw, # 简单起见只取日期,不含时分秒
"url": url
})
return articles
def parse_detail(self, html):
"""解析详情页,提取正文、标签并转换为 Markdown"""
soup = BeautifulSoup(html, 'html.parser')
# 1. 提取标签 (Tags)
# CSS 选择器:查找 id="EntryTag" 下的所有链接文本
tags = [tag.get_text(strip=True) for tag in soup.select('#EntryTag a')]
# 2. 提取正文 HTML
# 博客园正文通常在 id="cnblogs_post_body"
content_div = soup.select_one('#cnblogs_post_body')
if not content_div:
return None, []
# 3. 核心转换:HTML -> Markdown
# str(content_div) 将 Beautifulsoup 对象转回 HTML 字符串
markdown_content = self.converter.handle(str(content_div))
return markdown_content, tags8️⃣ 数据存储与导出(Storage - 生成 Markdown)
这里我们不做 CSV 了,我们要生成 带 YAML 头信息的 .md 文件。这是 Hugo/Hexo 等静态博客引擎的标准格式。
格式示例:
markdown
---
title: Python 爬虫实战
date: 2026-01-27
tags: [Python, Spider]
---
# 正文内容...
python
import os
import re
class MarkdownStorage:
def __init__(self, save_dir="posts"):
self.save_dir = save_dir
os.makedirs(self.save_dir, exist_ok=True)
def clean_filename(self, title):
"""清洗文件名,去掉 Windows/Linux 不允许的字符"""
# 将 / \ : * ? " < > | 替换为下划线
return re.sub(r'[\\/:*?"<>|]', '_', title)
def save_post(self, meta_data, content):
"""
meta_data: 包含 title, date, tags, url
content: markdown 文本
"""
title = meta_data['title']
clean_title = self.clean_filename(title)
# 构造 YAML Front Matter
yaml_header = "---\n"
yaml_header += f"title: \"{title}\"\n"
yaml_header += f"date: {meta_data['date']}\n"
# 将列表转为 [tag1, tag2] 格式字符串
tags_str = ", ".join([f'"{t}"' for t in meta_data['tags']])
yaml_header += f"tags: [{tags_str}]\n"
yaml_header += f"origin_url: {meta_data['url']}\n"
yaml_header += "---\n\n"
full_text = yaml_header + content
file_path = os.path.join(self.save_dir, f"{clean_title}.md")
with open(file_path, 'w', encoding='utf-8') as f:
f.write(full_text)
print(f"💾 已保存: {file_path}")9️⃣ 运行方式与结果展示(必写)
整合逻辑:我们先抓列表,拿到链接后,再进详情页抓正文和标签,最后存文件。
python
# migrator.py
# 导入 Fetcher, Parser, MarkdownStorage
def main():
# 请替换为你想爬取的博主 ID
target_user = "vamei" # Python 圈知名博主 Vamei (致敬)
base_url = f"https://www.cnblogs.com/{target_user}/default.html"
print(f"🚀 开始备份博主 [{target_user}] 的文章...")
fetcher = BlogFetcher()
parser = BlogParser()
storage = MarkdownStorage(save_dir=f"backup_{target_user}")
# 演示:只爬取前 2 页
for page in range(1, 3):
url = f"{base_url}?page={page}"
print(f"\n📄 正在处理第 {page} 页列表...")
list_html = fetcher.get_page(url)
if not list_html:
break
articles = parser.parse_list(list_html)
print(f" 🔍 本页发现 {len(articles)} 篇文章")
for article in articles:
# 二次请求:获取详情
detail_html = fetcher.get_page(article['url'])
if detail_html:
md_content, tags = parser.parse_detail(detail_html)
if md_content:
# 合并数据
article['tags'] = tags
storage.save_post(article, md_content)
else:
print(f" ⚠️ 解析正文失败: {article['title']}")
else:
print(f" ⚠️ 详情页无法访问: {article['title']}")
print("\n🎉 全部备份完成!请查看 backup 目录。")
if __name__ == "__main__":
main()示例输出结果:
text
🚀 开始备份博主 [vamei] 的文章...
📄 正在处理第 1 页列表...
📡 正在抓取: https://www.cnblogs.com/vamei/default.html?page=1
🔍 本页发现 10 篇文章
📡 正在抓取: https://www.cnblogs.com/vamei/archive/2012/09/13/2682778.html
💾 已保存: backup_vamei/Python快速教程.md
📡 正在抓取: https://www.cnblogs.com/vamei/archive/2012/09/14/2683756.html
💾 已保存: backup_vamei/Linux文件系统.md
...
🎉 全部备份完成!请查看 backup 目录。生成的 Markdown 文件内容预览:
markdown
---
title: "Python快速教程"
date: 2012年9月13日
tags: ["Python", "教程"]
origin_url: https://www.cnblogs.com/vamei/archive/2012/09/13/2682778.html
---
# Python快速教程
作者:Vamei 出处:http://www.cnblogs.com/vamei
## 1. 基础
Python 是一种解释型、面向对象、动态数据类型的高级程序设计语言...🔟 常见问题与排错(Expert Advice)
-
CSS 选择器定位不到元素?
- 原因:博客园支持用户自定义主题(Skin)。有的博主用的是"SimpleMemory"模板,有的是"LessIsMore"。它们的 HTML 结构(class 名)完全不同!
- 解法 :如果你发现爬不到,大概率是模板问题。你需要在
parse_list里写多套try-except或者if判断,适配常见的几套模板结构。
-
Markdown 图片显示裂图
- 原因 :我们只是把
<img>标签转成了![](),但图片链接依然是远程链接。如果博客园开启了防盗链,你在本地 Markdown 编辑器里就看不到图片了。 - 解法 :进阶版爬虫需要把图片下载到本地
assets文件夹,并替换 Markdown 中的链接路径。
- 原因 :我们只是把
-
html2text 转换格式混乱
- 原因:原网页中包含大量的代码块(Code Block)。html2text 默认处理代码块可能不够完美。
- 解法 :可以考虑自定义 html2text 的参数,或者在解析前先用 BS4 把
<pre>标签里的内容提取出来单独处理,防止被转义。
1️⃣1️⃣ 进阶优化(可选但加分)
- 多线程下载(Threading) :
由于我们既要请求列表,又要请求详情,网络 I/O 耗时很长。可以使用concurrent.futures.ThreadPoolExecutor开启 5-10 个线程并发抓取详情页,速度能提升 5 倍以上。 - 图片本地化(Image Downloader) :
在parse_detail里,用正则找出所有的)图片链接,下载图片并重命名,实现彻底的"离线备份"。 - 增量备份 :
在本地建一个history.json,记录上次备份到的最新一篇文章的日期。下次运行时,一旦遇到日期早于记录日期的文章,直接break终止循环,节省时间。
1️⃣2️⃣ 总结与延伸阅读
复盘:
在这个项目中,我们不仅仅是在"抓数据",更是在做"数据格式化工程"。我们利用 CSS 选择器 快速切入 DOM 结构,利用 html2text 打通了 HTML 到 Markdown 的任督二脉,最终实现了一个具有实际生产价值的博客迁移工具。
下一步:
- 试试掘金/知乎 :这些现代前端渲染的站点(Vue/React)用 requests 很难拿到数据。这时候,就是你学习 Selenium 或 Playwright 的最佳时机!
- 自动化部署:结合 GitHub Actions,把这个脚本设为每周运行一次,自动抓取新文章并 Push 到你的 GitHub 仓库,实现全自动备份。
数据是新时代的石油,而爬虫就是你的钻井机。保护好你的知识资产!
🌟 文末
好啦~以上就是本期 《Python爬虫实战》的全部内容啦!如果你在实践过程中遇到任何疑问,欢迎在评论区留言交流,我看到都会尽量回复~咱们下期见!
小伙伴们在批阅的过程中,如果觉得文章不错,欢迎点赞、收藏、关注哦~
三连就是对我写作道路上最好的鼓励与支持! ❤️🔥
📌 专栏持续更新中|建议收藏 + 订阅
专栏 👉 《Python爬虫实战》,我会按照"入门 → 进阶 → 工程化 → 项目落地"的路线持续更新,争取让每一篇都做到:
✅ 讲得清楚(原理)|✅ 跑得起来(代码)|✅ 用得上(场景)|✅ 扛得住(工程化)
📣 想系统提升的小伙伴:强烈建议先订阅专栏,再按目录顺序学习,效率会高很多~

✅ 互动征集
想让我把【某站点/某反爬/某验证码/某分布式方案】写成专栏实战?
评论区留言告诉我你的需求,我会优先安排更新 ✅
⭐️ 若喜欢我,就请关注我叭~(更新不迷路)
⭐️ 若对你有用,就请点赞支持一下叭~(给我一点点动力)
⭐️ 若有疑问,就请评论留言告诉我叭~(我会补坑 & 更新迭代)
免责声明:本文仅用于学习与技术研究,请在合法合规、遵守站点规则与 Robots 协议的前提下使用相关技术。严禁将技术用于任何非法用途或侵害他人权益的行为。技术无罪,责任在人!!!