📌 索引分类概览

🏗️ 按数据结构分类
1. B+Tree 索引(最常用)
-- MySQL默认使用B+Tree索引
CREATE INDEX idx_name ON users(name);特点:
-
平衡多路搜索树,适合范围查询和排序
-
所有数据存储在叶子节点,查询稳定
-
InnoDB、MyISAM 都支持
-
支持
=, >, >=, <, <=, BETWEEN, LIKE 'prefix%'
B+Tree结构示例:
[15|30]
/ | \
[10|15] [20|25|30] [35|40]
↓ ↓ ↓
叶子节点链表:10→15→20→25→30→35→402. 哈希索引
-- Memory引擎默认使用哈希索引
CREATE TABLE memory_table (
id INT,
INDEX idx_hash USING HASH (id)
) ENGINE=MEMORY;特点:
-
基于哈希表,O(1)时间复杂度
-
只支持等值查询(=, IN),不支持范围查询
-
Memory引擎支持,InnoDB有自适应哈希索引
-
冲突处理:链地址法
3. 全文索引
-- 创建全文索引
CREATE TABLE articles (
id INT PRIMARY KEY,
title VARCHAR(200),
content TEXT,
FULLTEXT(title, content)
) ENGINE=InnoDB;
-- 全文搜索
SELECT * FROM articles
WHERE MATCH(title, content) AGAINST('mysql 索引' IN NATURAL LANGUAGE MODE);特点:
-
用于文本内容的全文搜索
-
支持自然语言和布尔搜索模式
-
MyISAM和InnoDB(5.6+)都支持
-
使用倒排索引结构
4. R-Tree 空间索引
-- 空间数据索引
CREATE TABLE locations (
id INT PRIMARY KEY,
point POINT NOT NULL,
SPATIAL INDEX(point)
) ENGINE=MyISAM;
-- 空间查询
SELECT * FROM locations
WHERE MBRContains(GeomFromText('Polygon((0 0, 10 0, 10 10, 0 10, 0 0))'), point);特点:
-
用于地理空间数据(GIS)
-
支持点、线、多边形等几何类型
-
MyISAM支持,InnoDB(5.7+)也支持
💾 按物理存储分类
1. 聚簇索引(Clustered Index)
-- InnoDB的聚簇索引
CREATE TABLE users (
id INT PRIMARY KEY, -- 聚簇索引
name VARCHAR(50),
age INT
) ENGINE=InnoDB;特点:
-
索引和数据存储在一起(叶子节点存数据行)
-
一个表只能有一个聚簇索引
-
InnoDB中主键就是聚簇索引
-
查询速度快(减少一次I/O)
存储结构:
B+Tree叶子节点:[主键值 | 整行数据]2. 非聚簇索引(Secondary Index)
-- 非聚簇索引(二级索引)
CREATE INDEX idx_age ON users(age);特点:
-
索引和数据分开存储
-
叶子节点存储主键值 或行指针
-
需要回表查询获取完整数据
-
一个表可以有多个非聚簇索引
InnoDB二级索引结构:
叶子节点:[索引列值 | 主键值]
查找流程:索引 → 主键 → 数据行🎯 按逻辑功能分类
1. 主键索引(PRIMARY KEY)
-- 创建主键索引
CREATE TABLE students (
id INT PRIMARY KEY, -- 主键索引
name VARCHAR(50)
);
-- 或后续添加
ALTER TABLE students ADD PRIMARY KEY (id);特点:
-
唯一且非空
-
一个表只能有一个
-
InnoDB中作为聚簇索引
2. 唯一索引(UNIQUE)
-- 创建唯一索引
CREATE TABLE users (
email VARCHAR(100) UNIQUE, -- 唯一约束自动创建索引
phone VARCHAR(20),
UNIQUE INDEX idx_phone (phone) -- 显式创建唯一索引
);特点:
-
保证列值唯一,允许多个NULL
-
可用于外键约束
-
提高查询性能
3. 普通索引(INDEX)
-- 创建普通索引
CREATE INDEX idx_name ON employees(last_name);
CREATE INDEX idx_department ON employees(department_id, hire_date);特点:
-
最基本的索引类型
-
无唯一性约束
-
可单列或多列(复合索引)
4. 复合索引(多列索引)
-- 复合索引(最左前缀原则)
CREATE INDEX idx_name_age_city ON users(last_name, first_name, age, city);
-- 有效使用:
SELECT * FROM users WHERE last_name = 'Smith';
SELECT * FROM users WHERE last_name = 'Smith' AND first_name = 'John';
SELECT * FROM users WHERE last_name = 'Smith' AND age > 25;
-- 无效使用(跳过最左列):
SELECT * FROM users WHERE first_name = 'John'; -- 无法使用索引最左前缀原则:索引从最左边开始匹配
5. 前缀索引
-- 对文本列前N个字符创建索引
CREATE INDEX idx_email_prefix ON users(email(10));
-- 计算合适的前缀长度
SELECT
COUNT(DISTINCT LEFT(email, 10)) / COUNT(*) AS selectivity_10,
COUNT(DISTINCT LEFT(email, 15)) / COUNT(*) AS selectivity_15
FROM users;特点:
-
减少索引大小
-
适合长文本字段
-
选择性要足够高
🔧 特殊索引类型
1. 覆盖索引(Covering Index)
-- 创建覆盖索引
CREATE INDEX idx_covering ON orders(user_id, status, amount);
-- 查询使用覆盖索引
SELECT user_id, status, amount
FROM orders
WHERE user_id = 100 AND status = 'paid';
-- Extra: Using index(无需回表)2. 自适应哈希索引(Adaptive Hash Index)
-
InnoDB自动创建,无需手动管理
-
监控热数据,自动建立哈希索引
-
提升等值查询性能
-- 查看自适应哈希索引状态
SHOW ENGINE INNODB STATUS\G
-- 在Hash table statistics部分查看
3. 函数索引(MySQL 8.0+)
-- 基于表达式的索引
CREATE INDEX idx_lower_name ON users((LOWER(name)));
-- 使用函数索引查询
SELECT * FROM users WHERE LOWER(name) = 'john';4. 降序索引(MySQL 8.0+)
-- 创建降序索引
CREATE INDEX idx_desc ON orders(created_at DESC, amount ASC);
-- 优化ORDER BY ... DESC查询
SELECT * FROM orders ORDER BY created_at DESC, amount ASC;📊 各存储引擎支持的索引
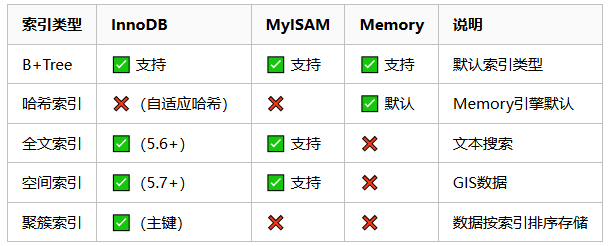
⚡ 索引选择策略
如何选择合适的索引类型
-- 1. 主键查询 → 聚簇索引(自动)
SELECT * FROM users WHERE id = 1;
-- 2. 等值查询(无范围) → 考虑哈希索引(Memory引擎)
SELECT * FROM session_data WHERE session_id = 'abc123';
-- 3. 范围查询/排序 → B+Tree索引
SELECT * FROM orders
WHERE order_date BETWEEN '2024-01-01' AND '2024-01-31'
ORDER BY amount DESC;
-- 4. 全文搜索 → 全文索引
SELECT * FROM articles
WHERE MATCH(content) AGAINST('数据库优化');
-- 5. 空间查询 → R-Tree索引
SELECT * FROM locations
WHERE ST_Distance(point, POINT(10, 20)) < 1000;索引创建最佳实践
-- 1. 选择性高的列建索引
CREATE INDEX idx_selective ON table(high_selectivity_column);
-- 2. 复合索引列顺序:高选择性在前,常用查询条件在前
CREATE INDEX idx_composite ON users(last_name, first_name, age);
-- 3. 避免过度索引(写性能下降)
-- 监控索引使用率
SELECT
object_schema,
object_name,
index_name,
rows_read,
rows_inserted
FROM performance_schema.table_io_waits_summary_by_index_usage
WHERE index_name IS NOT NULL;
-- 4. 使用不可见索引测试(MySQL 8.0+)
CREATE INDEX idx_test ON users(email) INVISIBLE;
ALTER TABLE users ALTER INDEX idx_test VISIBLE;📈 索引性能对比
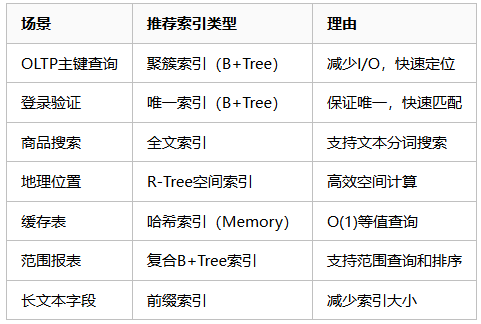
🔍 查看索引信息
-- 查看表索引
SHOW INDEX FROM users;
-- 查看索引大小
SELECT
TABLE_NAME,
INDEX_NAME,
ROUND(SUM(INDEX_LENGTH)/1024/1024, 2) AS 'Size(MB)'
FROM information_schema.TABLES
WHERE TABLE_SCHEMA = 'your_db'
GROUP BY TABLE_NAME, INDEX_NAME;
-- 分析索引使用情况
EXPLAIN SELECT * FROM users WHERE name = 'John';
-- 查看key_len、ref、rows、Extra等字段选择正确的索引类型可以显著提升查询性能。通常B+Tree索引是首选,特殊场景考虑其他索引类型。记得定期分析索引使用情况,避免无效索引影响性能。
文章转载自: ++佛祖让我来巡山++