集成学习
集成学习是机器学习中的一种思想,它通过多个模型的组合形成一个精度更高的模型,参与组合的模型称为 弱学习器(基学习器)。 训练时,使用训练集依次训练出这些弱学习器,对未知样本进行预测时,使用这些弱学习器联合进行预测。
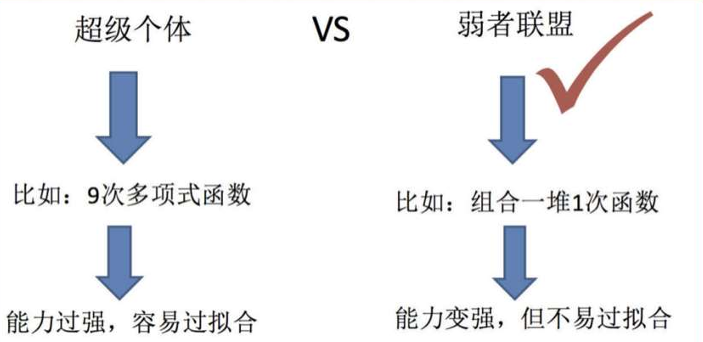
• Bagging:随机森林
• Boosting:Adaboost、GBDT、XGBoost、LightGBM
Bagging
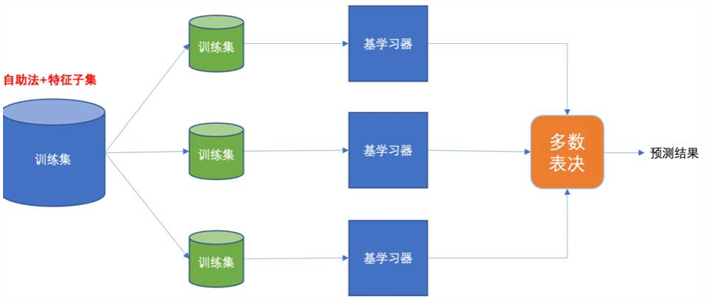
集成学习 -- Bagging思想
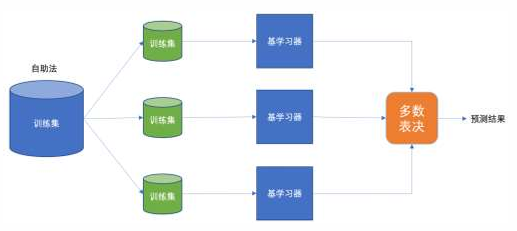
• 又称装袋算法或者自举汇聚法
• 有放回的抽样(bootstrap抽样)产生不同的训练集,从而训练不同的学习器
• 通过平权投票、多数表决的方式决定预测结果 在分类问题中,会使用多数投票统计结果 在回归问题中,会使用求均值统计结果
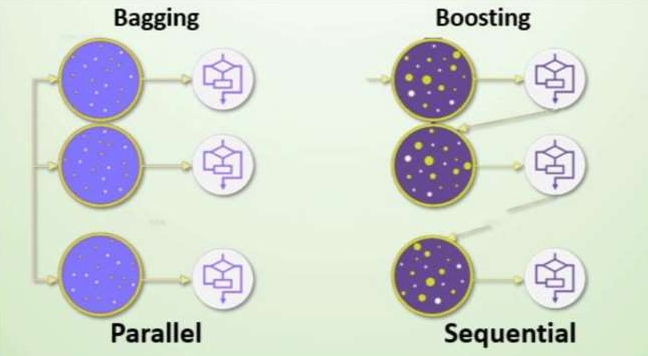
• 弱学习器可以并行训练
• 基本的弱学习器算法模型,如: Linear、Ridge、Lasso、Logistic、Softmax、ID3、C4.5、CART、SVM、KNN均可(严格意义上不属于bagging是另一种算法,集成学习(Ensemble Learning)中的"投票法(Voting)" 和 "堆叠法(Stacking)")。
Baggin的特征
• 同质性 :所有基学习器必须是同一种算法
• Bootstrap采样 :每个学习器在不同的Bootstrap样本集上训练
• 独立性:各学习器训练过程相互独立,可并行
Boosting
集成学习 -- Boosting思想
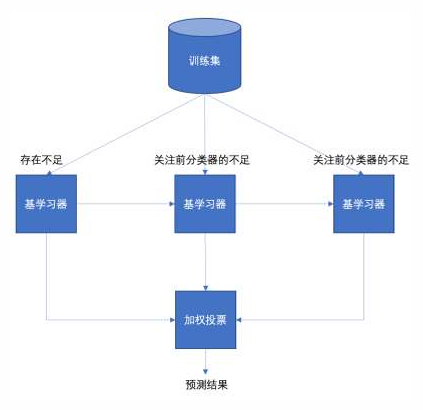
• 每一个训练器重点关注前一个训练器不足的地方进行训练
• 通过加权投票的方式,得出预测结果
• 串行的训练方式
•Boosting思想生活中的举例
• 随着学习的积累从弱到强
• 每新加入一个弱学习器,整体能力就会得到提升
• 代表算法:Adaboost,GBDT,XGBoost,LightGBM
Voting
集成学习 -- Voting思想
投票法 是最直观、最容易理解的集成方法,其核心思想是:"少数服从多数,专家集体决策"
想象一个医疗诊断场景:让内科医生、外科医生、影像科医生各自独立诊断同一个病人,然后通过投票决定最终诊断结果。
1. 硬投票(Hard Voting)
-
原理 :每个基学习器直接输出类别标签,最终预测为得票最多的类别
-
特点:简单直接,但可能损失概率信息
-
例:
三个分类器对某个样本的预测:
分类器1: "猫"
分类器2: "狗"
分类器3: "猫"硬投票结果:票数统计
猫: 2票, 狗: 1票 → 最终预测: "猫"
2. 软投票(Soft Voting)
-
原理 :每个基学习器输出类别概率,最终预测为平均概率最高的类别
-
特点:更精细,考虑了模型的不确定性
-
例:
三个分类器对某个样本的预测概率:
分类器1: [猫: 0.7, 狗: 0.3]
分类器2: [猫: 0.4, 狗: 0.6]
分类器3: [猫: 0.8, 狗: 0.2]软投票结果:平均概率
平均概率: [猫: (0.7+0.4+0.8)/3=0.633, 狗: (0.3+0.6+0.2)/3=0.367]
→ 最终预测: "猫"(平均概率更高)
Stacking
集成学习 -- Stacking思想
Stacking 是集成学习中最复杂、最强大的一种方法,它的核心思想是:"让模型学习如何组合其他模型"
想象一个总裁决策系统:多个专家(基学习器)各自提出建议,然后一位经验丰富的总裁(元学习器)学习如何综合这些建议做出最终决策。
1. 第一层:基学习器层
python
# 多种不同的基学习器并行工作
第一层 = [
"专家A(线性模型)", # 擅长捕捉线性关系
"专家B(树模型)", # 擅长捕捉非线性
"专家C(SVM)", # 擅长处理复杂边界
"专家D(神经网络)" # 擅长拟合复杂模式
]2. 第二层:元学习器层
python
# 元学习器学习如何组合专家意见
第二层 = "总裁(元模型)"
# 总裁的任务:
# 1. 收集所有专家的建议(预测结果)
# 2. 学习什么情况下该相信哪个专家
# 3. 基于学习到的规则做出最终决策四大集成方法全景对比
| 维度 | Bagging | Boosting | Voting | Stacking |
|---|---|---|---|---|
| 核心比喻 | 平行宇宙 | 错题本学习 | 专家委员会 | 总监+团队 |
| 算法要求 | 必须相同 | 通常相同(可不同) | 必须不同 | 必须不同 |
| 数据使用 | 不同(Bootstrap) | 相同,但权重不同 | 相同 | 相同(第一层) |
| 训练顺序 | 并行 | 串行(强依赖) | 并行 | 串行+并行(两层或多层) |
| 权重分配 | 平等投票 | 加权投票(α权重) | 平等/加权投票 | 元学习器自动学习权重 |
| 目标 | 降低方差 | 降低偏差 | 利用算法多样性 | 学习最佳组合策略 |
| 多样性来源 | 数据扰动 | 关注难样本 | 算法差异 | 算法差异+层级学习 |
| 典型代表 | 随机森林 | AdaBoost, GBDT | Hard/Soft Voting | 两层堆叠模型 |
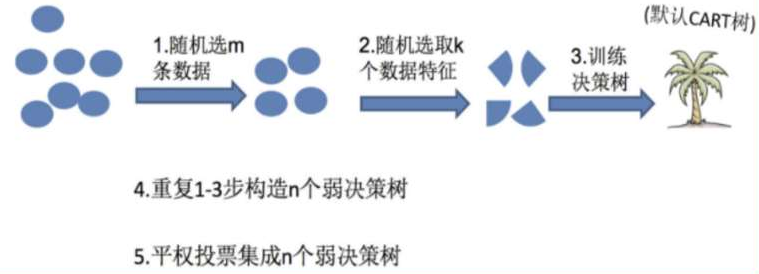
Bagging(随机森林算法)
随机森林是基于 Bagging 思想实现的一种集成学习算法,采用决策树模型作为每一个弱学习器。
训练:
(1)有放回的产生训练样本
(2)随机挑选 n 个特征(n 小于总特征数量)
预测:平权投票,多数表决输出预测结果
1:为什么要随机抽样训练集?
如果不进行随机抽样,每棵树的训练集都一样,那么最终训练出的树分类结果也是完全一样。
2:为什么要有放回地抽样?
如果不是有放回的抽样,那么每棵树的训练样本都是不同的,都是没有交集的,这样每棵树都是"有偏的",也就是说每棵树训练出来都是有很大的差异的;而随机森林最后分类取决于多棵树(弱分类器)的投票表决。
3:随机深林算法训练数据每次一定都有交集吗?
不一定有交集,但大概率会有部分交集,而且每棵树看到的样本不完全相同。
交集的存在是有益的:保证了树之间有一定相似性,集成才稳定
非完全交集是必要的:保证了树之间有足够差异,集成才有效
**综上:**弱学习器的训练样本既有交集也有差异数据,更容易发挥投票表决效果
案例一(泰坦尼克号案例)
随机深林
python
# 1.导入依赖包
from sklearn.ensemble import RandomForestClassifier
import pandas as pd
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.metrics import accuracy_score
from sklearn.tree import DecisionTreeClassifier
def dm01_random_forest_classifier():
# 2.获取数据集
titan = pd.read_csv('./data/titanic/train.csv')
# 3.数据处理,
# 3.1 确定特征值和目标值
print('---------------- x[x[\'Age\'].isna()].head(3) -----------')
x = titan[['Pclass', 'Age', 'Sex']].copy()
y = titan['Survived'].copy()
print(x[x['Age'].isna()].head(3))
# 3.2处理数据-处理缺失值
print('---------------- x[\'Age\'].fillna ---------------')
x['Age'].fillna(value=titan['Age'].mean(), inplace=True)
print(x.head(3))
# 3.3 one-hot编码
print('---------------- pd.get_dummies(x) ---------------')
x = pd.get_dummies(x)
print(x.head(3))
# 3.4 数据集划分
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=22, test_size=0.2)
# 4.模型训练
# 4.1 使用决策树进行模型训练和评估
dtc = DecisionTreeClassifier()
dtc.fit(x_train, y_train)
dtc_y_pred = dtc.predict(x_test)
accuracy = dtc.score(x_test, y_test)
print('单一决策树accuracy-->\n', accuracy)
# 4.2 随机森林进行模型训练和评估
rfc = RandomForestClassifier(max_depth=6, random_state=9)
rfc.fit(x_train, y_train)
rfc_y_pred = rfc.predict(x_test)
accuracy = rfc.score(x_test, y_test)
print('随机森林进accuracy-->\n', accuracy)
# 4.3 随机森林 交叉验证网格搜索 进行模型训练和评估
estimator = RandomForestClassifier()
param = {"n_estimators": [40, 50, 60, 70], "max_depth": [2, 4, 6, 8, 10], "random_state": [9]}
grid_search = GridSearchCV(estimator, param_grid=param, cv=2)
grid_search.fit(x_train, y_train)
accuracy = grid_search.score(x_test, y_test)
print("随机森林网格搜索accuracy:", accuracy)
print(grid_search.best_estimator_)
dm01_random_forest_classifier()执行结果
python
---------------- x[x['Age'].isna()].head(3) -----------
Pclass Age Sex
5 3 NaN male
17 2 NaN male
19 3 NaN female
---------------- x['Age'].fillna ---------------
Pclass Age Sex
0 3 22.0 male
1 1 38.0 female
2 3 26.0 female
---------------- pd.get_dummies(x) ---------------
Pclass Age Sex_female Sex_male
0 3 22.0 False True
1 1 38.0 True False
2 3 26.0 True False
单一决策树accuracy-->
0.7821229050279329
随机森林进accuracy-->
0.7541899441340782
随机森林网格搜索accuracy: 0.7821229050279329
RandomForestClassifier(max_depth=8, n_estimators=60, random_state=9)Voting
python
from sklearn.ensemble import RandomForestClassifier, VotingClassifier
import pandas as pd
from sklearn.model_selection import train_test_split, GridSearchCV, cross_val_score
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.tree import DecisionTreeClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.neighbors import KNeighborsClassifier
import numpy as np
import matplotlib as plt
import seaborn as sns
def voting():
titan = pd.read_csv('./data/titanic/train.csv')
x = titan[[
'Pclass',
'Age',
'Sex',
# 'SibSp',
# 'Parch',
# 'Fare'
]].copy()
y = titan['Survived'].copy()
x['Age'].fillna(value=x['Age'].mean(), inplace=True)
# 划分的Sex只保留一列,避免共线性
x = pd.get_dummies(x, columns=['Sex'], drop_first=True)
print(x)
# 数据集划分
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=22, test_size=0.2, stratify=y)
# 创建多种不同的分类器
estimators = [
('dt', DecisionTreeClassifier(
max_depth=5,
min_samples_split=10,
random_state=22
)),
('rf', RandomForestClassifier(
n_estimators=50,
max_depth=6,
min_samples_split=10,
random_state=22
)),
('svc', SVC(
C=1.0,
kernel='rbf',
probability=True, # 软投票需要概率
random_state=22
)),
('lr', LogisticRegression(
C=1.0,
max_iter=1000,
random_state=22
)),
('knn', KNeighborsClassifier(
n_neighbors=5
)),
('nb', GaussianNB())
]
# 打印每个模型的信息
for name, model in estimators:
print(f" {name}: {model.__class__.__name__}")
print()
# 方法一:硬投票
voting_hard = VotingClassifier(
estimators=estimators,
voting='hard'
)
# 训练模型
voting_hard.fit(x_train, y_train)
# 预测和评估
y_pred_hard = voting_hard.predict(x_test)
accuracy_hard = accuracy_score(y_test, y_pred_hard)
print(f"硬投票准确率: {accuracy_hard:.4f}")
print("分类报告:")
print(classification_report(y_test, y_pred_hard))
# 方法二:软投票
voting_soft = VotingClassifier(
estimators=estimators,
voting='soft'
)
# 训练模型
voting_soft.fit(x_train, y_train)
# 预测和评估
y_pred_soft = voting_soft.predict(x_test)
accuracy_soft = accuracy_score(y_test, y_pred_soft)
print(f"软投票准确率: {accuracy_soft:.4f}")
print("分类报告:")
print(classification_report(y_test, y_pred_soft))
# 单独评估每个基学习器
print("各基学习器单独性能:")
individual_accuracies = {}
for name, model in estimators:
# 克隆模型以避免数据影响
from sklearn.base import clone
model_clone = clone(model)
model_clone.fit(x_train, y_train)
y_pred = model_clone.predict(x_test)
acc = accuracy_score(y_test, y_pred)
individual_accuracies[name] = acc
print(f"{name}: {acc:.4f}")
print(f"\n硬投票提升: {accuracy_hard - np.mean(list(individual_accuracies.values())):.4f}")
print(f"软投票提升: {accuracy_soft - np.mean(list(individual_accuracies.values())):.4f}")
voting()执行结果
python
Pclass Age Sex_male
0 3 22.000000 True
1 1 38.000000 False
2 3 26.000000 False
3 1 35.000000 False
4 3 35.000000 True
.. ... ... ...
886 2 27.000000 True
887 1 19.000000 False
888 3 29.699118 False
889 1 26.000000 True
890 3 32.000000 True
[891 rows x 3 columns]
dt: DecisionTreeClassifier
rf: RandomForestClassifier
svc: SVC
lr: LogisticRegression
knn: KNeighborsClassifier
nb: GaussianNB
硬投票准确率: 0.8436
分类报告:
precision recall f1-score support
0 0.84 0.93 0.88 110
1 0.86 0.71 0.78 69
accuracy 0.84 179
macro avg 0.85 0.82 0.83 179
weighted avg 0.85 0.84 0.84 179
软投票准确率: 0.8324
分类报告:
precision recall f1-score support
0 0.85 0.88 0.87 110
1 0.80 0.75 0.78 69
accuracy 0.83 179
macro avg 0.83 0.82 0.82 179
weighted avg 0.83 0.83 0.83 179
各基学习器单独性能:
dt: 0.8268
rf: 0.8492
svc: 0.6257
lr: 0.8324
knn: 0.7654
nb: 0.8156
硬投票提升: 0.0577
软投票提升: 0.0466Stacking
python
from sklearn.ensemble import RandomForestClassifier, VotingClassifier
import pandas as pd
from sklearn.model_selection import train_test_split, GridSearchCV, cross_val_score
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.tree import DecisionTreeClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.neighbors import KNeighborsClassifier
from sklearn.ensemble import GradientBoostingClassifier
from xgboost import XGBClassifier
from sklearn.ensemble import AdaBoostClassifier
from sklearn.ensemble import StackingClassifier
import numpy as np
import matplotlib as plt
import seaborn as sns
def dm01_stacking():
titan = pd.read_csv('./data/titanic/train.csv')
x = titan[[
'Pclass',
'Age',
'Sex',
# 'SibSp',
# 'Parch',
# 'Fare'
]].copy()
y = titan['Survived'].copy()
x['Age'].fillna(value=x['Age'].mean(), inplace=True)
x = pd.get_dummies(x, columns=['Sex'], drop_first=True)
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=22, test_size=0.2, stratify=y)
base_learners = [
('dt', DecisionTreeClassifier(
max_depth=4,
min_samples_split=10,
random_state=22
)),
('rf', RandomForestClassifier(
n_estimators=50,
max_depth=5,
min_samples_split=10,
random_state=22
)),
('svc', SVC(
C=0.5,
kernel='linear',
probability=True,
random_state=22
)),
('lr', LogisticRegression(
C=0.5,
max_iter=1000,
random_state=22
)),
('gbdt', GradientBoostingClassifier(
n_estimators=50,
max_depth=3,
learning_rate=0.1,
random_state=22
)),
('xgb', XGBClassifier(
n_estimators=50,
max_depth=3,
learning_rate=0.1,
eval_metric='logloss',
random_state=22
))
]
# 打印每个模型的信息
for name, model in base_learners:
print(f" {name}: {model.__class__.__name__}")
print()
# 定义元学习器(第二层)
print("定义元学习器(第二层):")
meta_learner = LogisticRegression(
C=1.0,
max_iter=1000,
random_state=22
)
print(f"元学习器: {meta_learner.__class__.__name__}")
print()
stacking = StackingClassifier(
estimators=base_learners,
final_estimator=meta_learner,
cv=5, # 使用5折交叉验证生成第一层特征
stack_method='auto', # 自动选择predict_proba
n_jobs=-1, # 使用所有CPU核心
passthrough=False # 不保留原始特征
)
# 训练Stacking模型
print("开始训练Stacking模型(可能需要一些时间)...")
stacking.fit(x_train, y_train)
print("训练完成!")
print()
# 7. 预测和评估
y_pred_stacking = stacking.predict(x_test)
accuracy_stacking = accuracy_score(y_test, y_pred_stacking)
print(f"Stacking准确率: {accuracy_stacking:.4f}")
print("分类报告:")
print(classification_report(y_test, y_pred_stacking))
# 单独评估每个基学习器
base_accuracies = {}
for name, model in base_learners:
# 克隆模型以避免数据影响
from sklearn.base import clone
model_clone = clone(model)
model_clone.fit(x_train, y_train)
y_pred = model_clone.predict(x_test)
acc = accuracy_score(y_test, y_pred)
base_accuracies[name] = acc
print(f"{name}: {acc:.4f}")
avg_base_accuracy = np.mean(list(base_accuracies.values()))
print(f"\n基学习器平均准确率: {avg_base_accuracy:.4f}")
print(f"Stacking提升: {accuracy_stacking - avg_base_accuracy:.4f}")
print()
dm01_stacking()执行结果
python
dt: DecisionTreeClassifier
rf: RandomForestClassifier
svc: SVC
lr: LogisticRegression
gbdt: GradientBoostingClassifier
xgb: XGBClassifier
定义元学习器(第二层):
元学习器: LogisticRegression
开始训练Stacking模型(可能需要一些时间)...
训练完成!
Stacking准确率: 0.8380
分类报告:
precision recall f1-score support
0 0.85 0.89 0.87 110
1 0.81 0.75 0.78 69
accuracy 0.84 179
macro avg 0.83 0.82 0.83 179
weighted avg 0.84 0.84 0.84 179
dt: 0.8268
rf: 0.8324
svc: 0.8101
lr: 0.8324
gbdt: 0.8324
xgb: 0.8380
基学习器平均准确率: 0.8287
Stacking提升: 0.0093Boosting(Adaboost算法)
Adaptive Boosting(自适应提升)基于 Boosting思想实现的一种集成学习算法,核心思想是通过逐步提高那些被前一步分类错误的样本的权重来训练一个强分类器。
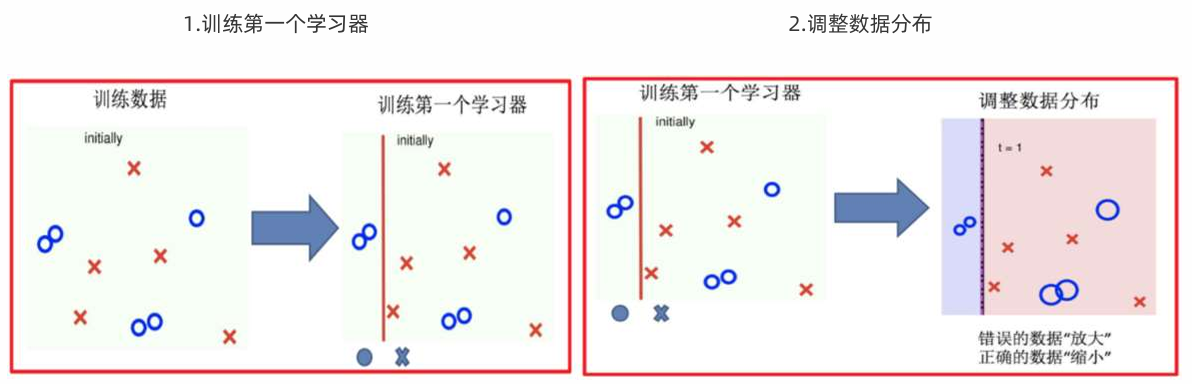
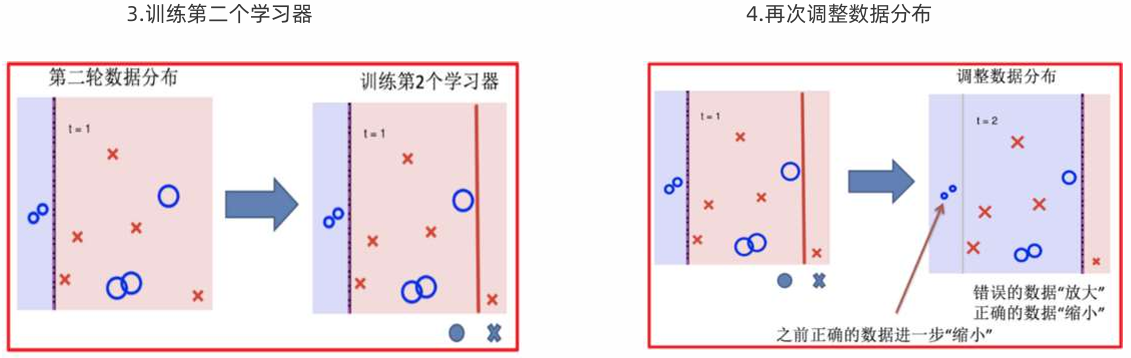
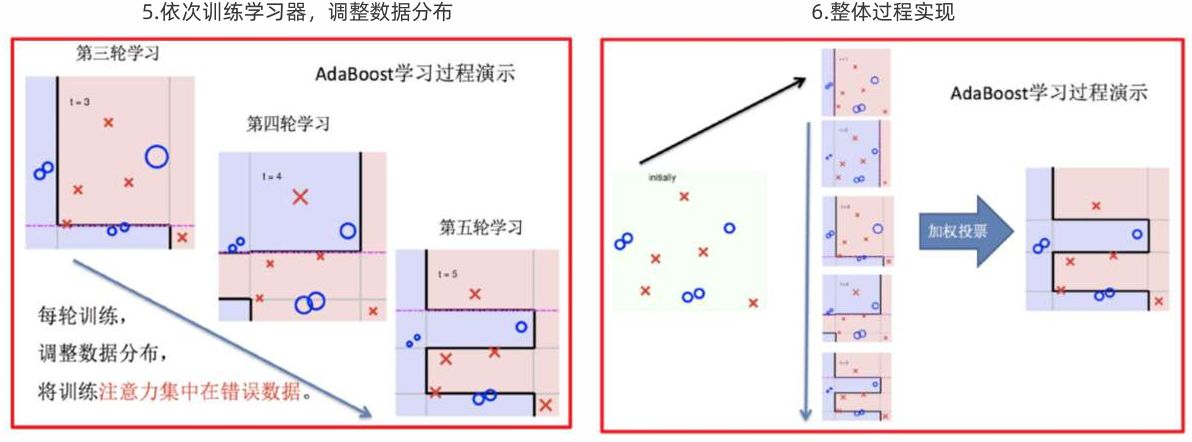
Adaboost算法推导
1 初始化训练数据权重相等,训练第 1 个学习器
如果有 100 个样本,则每个样本的初始化权重为:1/100
根据预测结果找一个错误率最小的分裂点,计算、更新:样本权重、模型权重
2 根据新权重的样本集 训练第 2 个学习器
根据预测结果找一个错误率最小的分裂点计算、更新:样本权重、模型权重
3 迭代训练在前一个学习器的基础上,根据新的样本权重训练当前学习器
直到训练出 m 个弱学习器
4 m个弱学习器集成预测公式: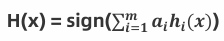
𝑎𝑖为模型的权重,输出结果大于 0 则归为正类,小于 0 则归为负类。
5 模型权重计算公式:

6 样本权重计算公式:

例:

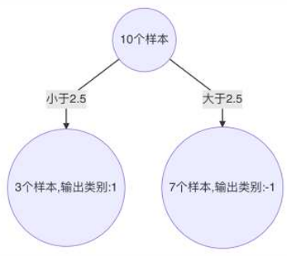
已知训练数据见下面表格,假设弱分类器由 x 产生,预测结果使该分类器在训练数据集上的分类 误差率最低,试用 Adaboost算法学习一个强分类器。
1.初始化工作:初始化10个样本的权重,每个样本的权重为:0.1

构建第一个基学习器:
1.寻找最优分裂点(正负样本判断以分类错误少的为准)
1.对特征值x进行排序,确定分裂点为: 0.5,1.5,2.5,3.5,4.5,5.5,6.5,7.5,8.5
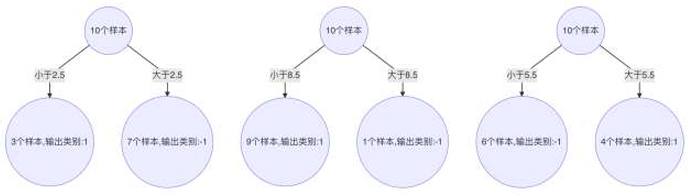
2.当以0.5为分裂点时,有5个样本分类错误(左1,右-1)
3.当以1.5为分裂点时,有4个样本分类错误(左1,右-1)
4.当以2.5为分裂点时,有3个样本分类错误(左1,右-1)
5.当以3.5为分裂点时,有4个样本分类错误(左1,右-1)
6.当以4.5为分裂点时,有5个样本分类错误(左1,右-1)
7.当以5.5为分裂点时,有4个样本分类错误(左-1,右1)
8.当以6.5为分裂点时,有5个样本分类错误(左1,右-1)
9.当以7.5为分裂点时,有4个样本分类错误(左1,右-1)
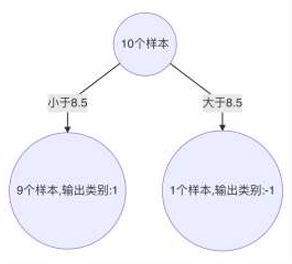
10.当以8.5为分裂点时,有3个样本分类错误(左1,右-1)
11.最终,选择以2.5作为分裂点,计算得出基学习器错误率为:3/10=0.3
2.计算模型权重:1/2 *np.1og((1-0.3)/0.3)=0.4236
3.更新样本权重:
1.分类正确样本为:1、2、3、4、5、6、10共7个,其计算公式为: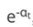 ,则正确样本权重变化系数为:
,则正确样本权重变化系数为: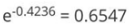
2.分类错误样本为:7、8、9共3个,其计算公式为: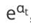 ,则错误样本权重变化系数为:
,则错误样本权重变化系数为: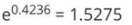
3.样本1,2,3,4,5,6,10 权重值为:0.1 * 0.6547 = 0.06547
4.样本7、8、9的样本权重值为: 0.1 * 1.5275= 0.15275
5.归一化Zt值为: 0.06547 * 7 + 0.15275 * 3 = 0.9165
6.样本1、2、3、4、5、6、10最终权重值为:0.06547 / 0.9165 = 0.07143
7.样本7、8、9的样本权重值为:0.15275 / 0.9165 = 0.1667

构建第二个基学习器:
1.寻找最优分裂点:
1.对特征值x进行排序,确定分裂点为: 0.5,1.5,2.5,3.5,4.5,5.5,6.5,7.5,8.5
2.当以0.5为分裂点时,有5 个样本分类错误,错误率为: 0.07143 * 2 + 0.16667 * 3 = 0.64287 (左1,右-1)
3.当以1.5为分裂点时,有4个样本分类错误,错误率为: 0.07143 * 1 + 0.16667 * 3 = 0.57144(左1,右-1)
4.当以2.5为分裂点时,有3个样本分类错误,错误率为: 0.16667 * 3 = 0.50001 (左1,右-1)
。。。。。。。。
5.当以8.5为分裂点时,有3个样本分类错误,错误率为: 0.07143 * 3 = 0.21429 (左1,右-1)
6.最终,选择以8.5作为分裂点,计算得出基学习器错误率为: 0.21429
2.计算模型权重:1/2 *np.1og((1-0.21429)/0.21429)=0.64963
3.分类正确的样本:1、2、3、7、8、9、10, 其计算公式为:,其权重调整系数为:0.5222
4.分类错误的样本:4、5、6, 其计算公式为: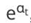 ,其权重调整系数为:1.9148
,其权重调整系数为:1.9148
5.分类正确样本权重值:
1.样本1,2,3,10为: 0.07143 * 0.5222 = 0.0373
2.样本7,8,9为:0.16667 * 0.5222 = 0.087
6.分类错误样本4,5,6权重值: 0.07143 * 1.9148 = 0.1368
7.归一化Z值为: 0.0373 * 4 + 0.087 * 3 + 0.1368 * 3 = 0.8206
8.最终权重:
1.样本1、2、3、10为: 0.0373 / 0.8206 = 0.0455
2.样本7、8、9为: 0.087 / 0.8206 = 0.1060
3.样本4、5、6为: 0.1368 / 0.8206 = 0.1667

构建第三个弱学习器
错误率: 0.1820,模型权重: 0.7514
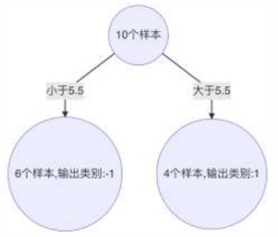
最终强学习器
3个弱学习器集成预测公式:
𝑎𝑖为模型的权重,输出结果大于 0 则归为正类,小于 0 则归为负类。
a1 = 0.4236 a2 = 0.64963 a3 = 0.7515 X = 3

0.4236*(-1) + 0.64963*(1) + 0.7514*(-1) = -0.52537 < 0 负类
案例二(葡萄酒分类)
需求 已知葡萄酒数据,根据数据进行葡萄酒分类
思路分析
1 读取数据
2 特征处理
2-1 Adaboost一般做二分类 去掉一类(1,2,3)
2-2 准备特征值和目标值
2-3 类别转化 (2,3)=>(0,1)
2-4 划分数据
3 实例化单决策树 实例化Adaboost-由500颗树组成
4 单决策树模型训练和评估
5 AdaBoost模型训练和评估
AdaBoost
python
# 1.导入依赖包
import pandas as pd
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import AdaBoostClassifier
from sklearn.metrics import accuracy_score
def dm01_adaboost():
# 2.读取数据
df_wine = pd.read_csv('./data/wine0501.csv')
print(df_wine.head())
# 3.特征处理
# 3.1 Adaboost一般做二分类 去掉一类(1,2,3)
df_wine = df_wine[df_wine['Class label'] != 1]
# 3.2 准备特征值和目标值 Alcohol酒精含量 Hue颜色
x = df_wine[['Alcohol', 'Hue']].values
y = df_wine['Class label']
# 3.3 类别转化y (2,3)=>(0,1)
y = LabelEncoder().fit_transform(y)
# 3.4 划分数据
X_train, X_test, y_train, y_test = train_test_split(x, y, random_state=22, test_size=0.2)
print(X_train.shape, X_test.shape, y_train.shape, y_test.shape)
# 4.实例化单决策树 实例化Adaboost-由500颗树组成
mytree = DecisionTreeClassifier(criterion='entropy', max_depth=1, random_state=0)
myada = AdaBoostClassifier(estimator=mytree, n_estimators=500, learning_rate=0.1, random_state=0)
# 5.单决策树模型训练和评估
mytree.fit(X_train, y_train)
myscore = mytree.score(X_test, y_test)
print('myscore -->', myscore)
# 6.AdaBoost模型训练和评估
myada.fit(X_train, y_train)
myscore = myada.score(X_test, y_test)
print('myscore-->', myscore)
dm01_adaboost()执行结果
python
Class label Alcohol Malic acid Ash Alcalinity of ash ... Proanthocyanins Color intensity Hue OD280/OD315 of diluted wines Proline
0 1 14.23 1.71 2.43 15.6 ... 2.29 5.64 1.04 3.92 1065
1 1 13.20 1.78 2.14 11.2 ... 1.28 4.38 1.05 3.40 1050
2 1 13.16 2.36 2.67 18.6 ... 2.81 5.68 1.03 3.17 1185
3 1 14.37 1.95 2.50 16.8 ... 2.18 7.80 0.86 3.45 1480
4 1 13.24 2.59 2.87 21.0 ... 1.82 4.32 1.04 2.93 735
[5 rows x 14 columns]
(95, 2) (24, 2) (95,) (24,)
myscore --> 0.7916666666666666
myscore--> 0.9166666666666666Voting
python
# 1.导入依赖包
import pandas as pd
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import AdaBoostClassifier
from sklearn.metrics import accuracy_score, classification_report
from sklearn.ensemble import RandomForestClassifier, VotingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.tree import DecisionTreeClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.neighbors import KNeighborsClassifier
import numpy as np
def dm01_voting():
# 2.读取数据
df_wine = pd.read_csv('./data/wine0501.csv')
print(df_wine.head())
# 3.特征处理
# 3.1 Adaboost一般做二分类 去掉一类(1,2,3)
df_wine = df_wine[df_wine['Class label'] != 1]
print(df_wine.head())
# 3.2 准备特征值和目标值 Alcohol酒精含量 Hue颜色
x = df_wine[['Alcohol', 'Hue']].values
y = df_wine['Class label']
# 3.3 类别转化y (2,3)=>(0,1)
y = LabelEncoder().fit_transform(y)
# 3.4 划分数据
X_train, X_test, y_train, y_test = train_test_split(x, y, random_state=22, test_size=0.2)
print(X_train.shape, X_test.shape, y_train.shape, y_test.shape)
# 创建多种不同的分类器
mytree = DecisionTreeClassifier(criterion='entropy', max_depth=1, random_state=0)
estimators = [
# ('dt',
# DecisionTreeClassifier(
# max_depth=5,
# min_samples_split=10,
# random_state=22
# )),
('rf', RandomForestClassifier(
n_estimators=50,
max_depth=6,
min_samples_split=10,
random_state=22
)),
('lr', LogisticRegression(
C=1.0,
max_iter=1000,
random_state=22
)),
('knn', KNeighborsClassifier(
n_neighbors=5
)),
('nb', GaussianNB()),
('ada', AdaBoostClassifier(
estimator=mytree,
n_estimators=500,
learning_rate=0.1,
random_state=0
))
]
# 打印每个模型的信息
for name, model in estimators:
print(f" {name}: {model.__class__.__name__}")
print()
# 5.训练和评估
# 单决策树模型训练和评估
mytree.fit(X_train, y_train)
myscore = mytree.score(X_test, y_test)
print('myscore -->', myscore)
voting_hard = VotingClassifier(
estimators=estimators,
voting='soft'
)
voting_hard.fit(X_train, y_train)
# 6.AdaBoost模型训练和评估
y_pred_hard = voting_hard.predict(X_test)
accuracy_hard = accuracy_score(y_test, y_pred_hard)
print(f"投票准确率: {accuracy_hard:.4f}")
print("分类报告:")
print(classification_report(y_test, y_pred_hard))
# 单独评估每个基学习器
print("各基学习器单独性能:")
individual_accuracies = {}
for name, model in estimators:
# 克隆模型以避免数据影响
from sklearn.base import clone
model_clone = clone(model)
model_clone.fit(X_train, y_train)
y_pred = model_clone.predict(X_test)
acc = accuracy_score(y_test, y_pred)
individual_accuracies[name] = acc
print(f"{name}: {acc:.4f}")
print(f"\n软投票提升: {accuracy_hard - np.mean(list(individual_accuracies.values())):.4f}")
dm01_voting()运行结果
python
Class label Alcohol Malic acid Ash Alcalinity of ash ... Proanthocyanins Color intensity Hue OD280/OD315 of diluted wines Proline
0 1 14.23 1.71 2.43 15.6 ... 2.29 5.64 1.04 3.92 1065
1 1 13.20 1.78 2.14 11.2 ... 1.28 4.38 1.05 3.40 1050
2 1 13.16 2.36 2.67 18.6 ... 2.81 5.68 1.03 3.17 1185
3 1 14.37 1.95 2.50 16.8 ... 2.18 7.80 0.86 3.45 1480
4 1 13.24 2.59 2.87 21.0 ... 1.82 4.32 1.04 2.93 735
[5 rows x 14 columns]
Class label Alcohol Malic acid Ash Alcalinity of ash ... Proanthocyanins Color intensity Hue OD280/OD315 of diluted wines Proline
59 2 12.37 0.94 1.36 10.6 ... 0.42 1.95 1.05 1.82 520
60 2 12.33 1.10 2.28 16.0 ... 0.41 3.27 1.25 1.67 680
61 2 12.64 1.36 2.02 16.8 ... 0.62 5.75 0.98 1.59 450
62 2 13.67 1.25 1.92 18.0 ... 0.73 3.80 1.23 2.46 630
63 2 12.37 1.13 2.16 19.0 ... 1.87 4.45 1.22 2.87 420
[5 rows x 14 columns]
(95, 2) (24, 2) (95,) (24,)
rf: RandomForestClassifier
lr: LogisticRegression
knn: KNeighborsClassifier
nb: GaussianNB
ada: AdaBoostClassifier
myscore --> 0.7916666666666666
投票准确率: 1.0000
分类报告:
precision recall f1-score support
0 1.00 1.00 1.00 17
1 1.00 1.00 1.00 7
accuracy 1.00 24
macro avg 1.00 1.00 1.00 24
weighted avg 1.00 1.00 1.00 24
各基学习器单独性能:
rf: 0.9583
lr: 0.9167
knn: 0.9583
nb: 0.9583
ada: 0.9167
软投票提升: 0.0583Stacking
python
# 1.导入依赖包
from sklearn.ensemble import RandomForestClassifier, VotingClassifier
import pandas as pd
from sklearn.model_selection import train_test_split, GridSearchCV, cross_val_score
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.tree import DecisionTreeClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.neighbors import KNeighborsClassifier
from sklearn.ensemble import GradientBoostingClassifier
from xgboost import XGBClassifier
from sklearn.ensemble import AdaBoostClassifier
from sklearn.ensemble import StackingClassifier
import numpy as np
from sklearn.preprocessing import LabelEncoder
def dm01_adaboost():
# 2.读取数据
df_wine = pd.read_csv('./data/wine0501.csv')
print(df_wine.head())
# 3.特征处理
# 3.1 Adaboost一般做二分类 去掉一类(1,2,3)
df_wine = df_wine[df_wine['Class label'] != 1]
# 3.2 准备特征值和目标值 Alcohol酒精含量 Hue颜色
# x = df_wine[['Alcohol', 'Hue']].values #转numpy
x = df_wine[['Alcohol', 'Hue']].copy()
y = df_wine['Class label'].copy()
# 3.3 类别转化y (2,3)=>(0,1)
y = LabelEncoder().fit_transform(y)
# 3.4 划分数据
X_train, X_test, y_train, y_test = train_test_split(x, y, random_state=22, test_size=0.2)
print(X_train.shape, X_test.shape, y_train.shape, y_test.shape)
# 4.实例化单决策树 实例化Adaboost-由500颗树组成
base_learners = [
('dt', DecisionTreeClassifier(
max_depth=4,
min_samples_split=10,
random_state=22
)),
('rf', RandomForestClassifier(
n_estimators=50,
max_depth=5,
min_samples_split=10,
random_state=22
)),
('svc', SVC(
C=0.5,
kernel='linear',
probability=True,
random_state=22
)),
('lr', LogisticRegression(
C=0.5,
max_iter=1000,
random_state=22
)),
('gbdt', GradientBoostingClassifier(
n_estimators=50,
max_depth=3,
learning_rate=0.1,
random_state=22
)),
('xgb', XGBClassifier(
n_estimators=50,
max_depth=3,
learning_rate=0.1,
eval_metric='logloss',
random_state=22
))
]
# 打印每个模型的信息
for name, model in base_learners:
print(f" {name}: {model.__class__.__name__}")
print()
# 定义元学习器(第二层)
print("定义元学习器(第二层):")
meta_learner = LogisticRegression(
C=1.0,
max_iter=1000,
random_state=22
)
print(f"元学习器: {meta_learner.__class__.__name__}")
print()
# 5.模型训练和评估
stacking = StackingClassifier(
estimators=base_learners,
final_estimator=meta_learner,
cv=5, # 使用5折交叉验证生成第一层特征
stack_method='auto', # 自动选择predict_proba
n_jobs=-1, # 使用所有CPU核心
passthrough=False # 不保留原始特征
)
print("开始训练Stacking模型(可能需要一些时间)...")
stacking.fit(X_train, y_train)
print("训练完成!")
print()
# 6.模型训练和评估
y_pred_stacking = stacking.predict(X_test)
accuracy_stacking = accuracy_score(y_test, y_pred_stacking)
print(f"Stacking准确率: {accuracy_stacking:.4f}")
print("分类报告:")
print(classification_report(y_test, y_pred_stacking))
# 单独评估每个基学习器
base_accuracies = {}
for name, model in base_learners:
# 克隆模型以避免数据影响
from sklearn.base import clone
model_clone = clone(model)
model_clone.fit(X_train, y_train)
y_pred = model_clone.predict(X_test)
acc = accuracy_score(y_test, y_pred)
base_accuracies[name] = acc
print(f"{name}: {acc:.4f}")
avg_base_accuracy = np.mean(list(base_accuracies.values()))
print(f"\n基学习器平均准确率: {avg_base_accuracy:.4f}")
print(f"Stacking提升: {accuracy_stacking - avg_base_accuracy:.4f}")
print()
dm01_adaboost()执行结果
python
Class label Alcohol Malic acid Ash Alcalinity of ash Magnesium ... Nonflavanoid phenols Proanthocyanins Color intensity Hue OD280/OD315 of diluted wines Proline
0 1 14.23 1.71 2.43 15.6 127 ... 0.28 2.29 5.64 1.04 3.92 1065
1 1 13.20 1.78 2.14 11.2 100 ... 0.26 1.28 4.38 1.05 3.40 1050
2 1 13.16 2.36 2.67 18.6 101 ... 0.30 2.81 5.68 1.03 3.17 1185
3 1 14.37 1.95 2.50 16.8 113 ... 0.24 2.18 7.80 0.86 3.45 1480
4 1 13.24 2.59 2.87 21.0 118 ... 0.39 1.82 4.32 1.04 2.93 735
[5 rows x 14 columns]
(95, 2) (24, 2) (95,) (24,)
rf: RandomForestClassifier
gbdt: GradientBoostingClassifier
xgb: XGBClassifier
定义元学习器(第二层):
元学习器: LogisticRegression
开始训练Stacking模型(可能需要一些时间)...
训练完成!
Stacking准确率: 0.9583
分类报告:
precision recall f1-score support
0 0.94 1.00 0.97 17
1 1.00 0.86 0.92 7
accuracy 0.96 24
macro avg 0.97 0.93 0.95 24
weighted avg 0.96 0.96 0.96 24
rf: 0.9583
gbdt: 0.9583
xgb: 0.9583
基学习器平均准确率: 0.9583
Stacking提升: 0.0000