
前言
在构建复杂的 AI 应用时,我们常常面临一个核心挑战:如何优雅地处理多步骤、动态决策、状态依赖的执行流程。传统的链式调用(如 LangChain 的 LCEL)虽然简洁高效,但在面对"需要根据中间结果动态决定下一步操作"或"多次循环检索-推理"等场景时,往往显得力不从心。而市面上一些低代码平台(如 DIFY)虽然提供了可视化编排,却在灵活性与控制粒度上存在明显短板------尤其在需要精细干预每一步逻辑、实时反馈或并行处理多个知识源时,其"黑盒"特性反而成了瓶颈。
正因如此,LangGraph 应运而生。作为 LangChain 生态中专为有状态、多参与者、循环迭代 工作流设计的图状编排框架,LangGraph 允许开发者以节点(Node)和边(Edge)的方式显式定义执行逻辑,天然支持循环、条件跳转与状态持久化。本文将以一个典型场景为例:用户提问后,系统先由 LLM 判断涉及哪些知识库,再对每个知识库动态执行向量检索(Top3)并生成中间响应(如"正在检索知识库 A..."),最后汇总所有结果生成最终答案。我们将分别用纯代码、RunnableLambda/RunnableBranch 以及 LangGraph 三种方式实现,并深入对比其可读性、扩展性与维护成本。你会发现:当流程不再是线性,而是需要"思考-行动-再思考"的闭环时,LangGraph 不仅更香,更是不可替代的主编排引擎。
通过一个实例子来看传统编码、流程式编码、LangGraph
主流基于知识库问答的Agentic Flow
我们的设计如下
1.用户提问
2.先用LLM把用户的回答对着当前系统看属于哪个知识库或者哪几个知识库以list返回出来
2.1 如果用户的提问不在知识库list中或者説不属于知识库范围,那么我们用llm拟一个回答告诉用户
2.2 如果用户的提问属于我们系统的知识库范围,那么接着走下去
3. 根据用户回答属于哪几个知识库,把用户的提问用BM25+HYDE折成3-5个关键词,循环这些关键词列表,外层知识库list一层循环内套用户提问折成的关键词列表循环
3.1 循环时由于我们不是"静RAG",而是主流的"交互播报式RAG",因此内部每一次循环内会进行向量检索,检索出top3,然后让llm进行中间回答类似ai ide开发工具那种:
- 我正在检索xxx
- 当前正在检索xxx
4. 当外层知识库列表这一层的循环完成后,再给到llm做一次总结性回答 这种设计是主流的设计也是目前最先进的动态规划的交互式RAG,如:cursor, qoder等AI IDE开发工具用的都是这种方式,我们称这种RAG为Agentic RAG。
根据设计做技术选型
为了让大家非常直观的比较传统编程、流程式编码以及用LangGraph,我们就只实现1,2,2.1, 2.2这几点。
传统编程式
传统编程式当然实现简单,代码写起来也很容易,下面是伪代码。
knowledge_repo_list=get_knowledges();
identify_result=get_identify(userInputPrompt, knowledge_repo_list)
if identify_result.size>0
走下一步
else
用llm拟一段话术告诉用户你当前的提问不在我的服务范围看起来不难,但总觉得有点不对劲
我们现在是用api在窜这个工作流,既然用了langchain,那么langchain里有什么更加好的办法来实现这么一个逻辑分支流程吗?或者説编码式实现这个只是一个笨办法?
传统编程式实现流程优缺点分析
现在的流程是:
- 获取知识库列表 → 2. LLM判断意图 → 3. 分支A : 匹配到知识库 / 分支B: 未匹配,再调用LLM生成友好回答
这是手工编排的流程,用Python代码显式控制每一步。
LangChain推荐的更优雅方案
使用 LangGraph(最推荐)
LangGraph 是 LangChain 专门用于构建多步骤、有状态、带分支的Agent工作流的框架。
你的场景非常适合用 LangGraph:
优势:
-
✅ 流程可视化(可以生成Mermaid图)
-
✅ 状态管理自动化
-
✅ 分支逻辑清晰
-
✅ 支持流式输出、循环、记忆等高级特性
-
✅ 易于调试和监控
优势:
-
✅ 比手工if-else优雅
-
✅ 可以和其他Runnable组合
-
❌ 但状态管理还是要自己处理
✅ 优点
-
逻辑清晰直观:代码一看就懂,适合快速开发
-
灵活性高:想加什么逻辑直接写Python代码
-
调试方便:可以随时print/log
❌ 缺点
-
不够声明式:流程隐藏在代码里,不直观
-
难以可视化:无法生成流程图
-
状态管理混乱:变量散落在各处
-
难以扩展:加新分支要改多处代码
-
不符合LangChain设计理念:没有利用Runnable的组合能力
短期
来説这种实现没问题,对于简单的2-3步流程,手工编排完全够用。
中期(功能稳定后)
一般用 RunnableBranch,保持LangChain风格,代码更优雅。
长期(复杂场景)
如果后续要加:
-
多轮对话
-
循环调用
-
人工介入
-
复杂分支(3个以上)
强烈建议迁移到 LangGraph,它就是为这种复杂场景设计的。
那么我们看看什么是RunnableBranch呢?
RunnableBranch实现
其实RunnableBranch是一种声明式编程,上面那一"陀"代码没有太多本质上的改变,只是它变得更声明,当然,对于:如果用户回答属于当前知识库范围那么。。。如果不属于那么。。。还是要写一对if else
我们来看RunnableBranch的核心实现
python
def _build_general_chat_chain():
"""构建通用聊天的 RunnableBranch Chain"""
log.info("[RunnableChain] 构建 RunnableBranch Chain...")
fetch_runnable = RunnableLambda(_step_fetch_knowledge_repos)
identify_runnable = RunnableLambda(_step_identify_intent)
branch = RunnableBranch(
(
# 条件1: matched_knowledge 存在且不为空列表
lambda x: x.get("matched_knowledge") is not None
and len(x.get("matched_knowledge", [])) > 0,
RunnableLambda(_step_handle_matched),
),
# 默认分支: 未匹配或出错
RunnableLambda(_step_handle_not_matched),
)
chain = fetch_runnable | identify_runnable | branch
log.info("[RunnableChain] RunnableBranch Chain 构建完成")
return chain看,这就是RunnableBranch,从代码来看有点流程的感觉了。
现在的流程是:
- 获取知识库列表 → 2. LLM判断意图 → 3. 分支A : 匹配到知识库 / 分支B: 未匹配,再调用LLM生成友好回答
不过这还是手工编排的流程,用Python代码显式控制每一步,只不过较声明式了。
不能只看到一种就决定设计需要多问还有没有更好的实现?
RunnableBranch不错,看着挺像工作流的,可是现在我们只是实现了一个框子,后面要实现更复杂的:
python
1.用户提问
2.先用LLM把用户的回答对着当前系统看属于哪个知识库或者哪几个知识库以list返回出来
2.1 如果用户的提问不在知识库list中或者説不属于知识库范围,那么我们用llm拟一个回答告诉用户
2.2 如果用户的提问属于我们系统的知识库范围,那么接着走下去
3. 根据用户回答属于哪几个知识库,把用户的提问用BM25+HYDE折成3-5个关键词,循环这些关键词列表,外层知识库list一层循环内套用户提问折成的关键词列表循环
3.1 循环时由于我们不是"静RAG",而是主流的"交互播报式RAG",因此内部每一次循环内会进行向量检索,检索出top3,然后让llm进行中间回答类似ai ide开发工具那种:
- 我正在检索xxx
- 当前正在检索xxx
4. 当外层知识库列表这一层的循环完成后,再给到llm做一次总结性回答 特别是流程里套流程,还有分片检索。。。
- 把未来的流程拆一下
1.1 当前只是"识别属于哪些知识库 → 不在范围就友好回复/在范围就返回列表"。
1.2 最终形态梳理:
-
第一步:识别
knowledgeList(目前已经有) -
第二步:循环每个命中的知识库:
-
向量检索 top3
-
LLM 做"中间回答 / 过程播报"(SSE:我正在检索第N个、当前查到X、准备总结...)
-
-
第三步:所有库循环结束后,再调用一次 LLM 做总总结(一个整合性的 final answer)
-
整体是一个「多轮、多节点、有循环、有中间状态」的动态 RAG 工作流。
- 从几个关键维度客观对比:Runnable vs LangGraph
2.1 流程复杂度 & 可读性
-
纯 RunnableBranch:
-
多层
RunnableLambda | RunnableBranch+ 手工 while/for 循环,很容易变成"嵌套洋葱":-
外层:知识库循环
-
内层:向量检索 → LLM → SSE 分段输出
-
代码里会充满多层状态 dict 的更新,阅读成本高。
-
-
优点:一切都在一个 Python 函数里,直觉上"就是 Python 代码"。
-
-
LangGraph:
-
可以显式画出节点:
identify_knowledge→for_each_knowledge (loop)→vector_search→llm_partial_answer→aggregate_summary
-
每个节点一个函数,结构自然是"流程图级别"的,可视化(Mermaid / Graphviz)也直接可用。
-
-
结论:只要引入"循环 + 中间播报 + 最终汇总",LangGraph 的优势会非常明显,Runnable 会很快变得难读。
2.2 循环 & 动态控制
-
RunnableBranch:
-
本身不带循环语义,你要自己写
for/while,在 state 里维护 index、累积结果等。 -
一旦要做"中途可中断"、"某个知识库失败是否跳过/重试"等逻辑,代码会变得非常命令式。
-
-
LangGraph:
-
原生支持循环、条件跳转、子图复用,可以设计类似:
-
for_each_knowledge子图:对单个知识库运行「检索→中间回答」; -
外层图把
knowledgeList展开成多次调用,或用"边+条件"控制。
-
-
-
结论 :涉及多次循环 + 动态决策时,LangGraph 更适合作为主编排。
2.3 状态管理(中间检索结果、累积上下文)
-
RunnableBranch:
-
你会用一个大的 dict state 携带:
- 当前 knowledgeId、当前检索结果列表、中间 LLM 回复、最终 summary 输入等。
-
全部靠你自己约定 key 名和更新顺序,没有类型/结构上的约束。
-
-
LangGraph:
-
用
TypedDict(你现在就有ChatState)明确:- 哪些字段是输入、哪些是中间、哪些是输出。
-
每个节点只关心它要读/写的那一部分,整体状态逻辑更清晰。
-
-
结论 :随着状态字段数量增加,LangGraph 的
StateGraph + TypedDict会明显比"生 dict + RunnableLambda"更安全。
2.4 SSE 流式输出 & 中间播报
-
两者都能做,差别在组织方式:
-
Runnable 方案:
-
router 层写一个
async def generate_stream(),在其中手写循环:- 调 Runnable → 拿结果 →
yieldSSE → 继续下一步 / 下一个知识库。
- 调 Runnable → 拿结果 →
-
LangChain Runnable 本身也可以
astream,但复杂逻辑时,你会混合"内部流式 + 外层 for + 外层 yield",容易乱。
-
-
LangGraph 方案:
-
工作流内部专注于"决策+状态",router 只关心:
- 让 LangGraph 跑一个 step/阶段 → 根据返回状态决定发哪些 SSE 片段。
-
更高级做法:用 LangGraph 的 "事件流 / 节点回调" 思路,把"在哪个节点打什么日志 / SSE"标准化。
-
-
结论 :SSE 实现本身两者都行,但 LangGraph 更有利于把"播报点"固定在节点边界,不至于散落在一堆 if/for 里。
2.5 调试 & 可视化
-
这个维度在复杂流程中很重要,即可视化调试(debug_mode、流程图):
-
RunnableBranch:
- 全靠日志和断点,"脑内画图"。
-
LangGraph:
- 直接
visualize_workflow()得到 Mermaid,流程走到哪一步、被哪个条件路由了,都能对齐日志。
- 直接
-
结论:后期流程一旦复杂,这一项对"理解 / 排查问题"的帮助会非常大。
2.6 实现成本 & 心智负担
-
短期成本:
-
我们已经有了 Runnable 版本 → 在现有基础上继续堆逻辑,开发门槛最低。
-
引入 LangGraph 作为主链路,需要你接受:StateGraph / 节点粒度 / 状态流的思维方式。
-
-
长期成本:
-
复杂逻辑用 Runnable 硬撑,后面 refactor 成 LangGraph 的成本会更高。
-
现在就用 LangGraph设计架构,后面加节点/分支比较自然。
-
3. 结合我们的最终目标,客观建议
3.1 要知道,我们的目标不是"一个简单判断分支的API",而是一个:
-
动态 RAG 多轮工作流:
-
多知识库循环
-
每轮向量检索 + 过程播报
-
全局总结。
-
3.2 在这种场景下:
-
把 LangGraph 作为主编排,
-
把 RunnableBranch 作为节点内部的子决策工具, 比"主线程用 RunnableBranch 顶住全流程,LangGraph 做附属调试"要合理得多。
3.3 更具体一点的推荐策略:
-
主链路:LangGraph(必选)
-
节点划分例如:
-
identify_knowledge(得到 knowledgeList) -
iterate_knowledge(单个知识库子图:向量检索 + partial answer) -
aggregate_summary(最终回答)
-
-
-
节点内部:仍然用 Runnable
- 比如
iterate_knowledge里,向量检索 → LLM 中间回答,可以用 RunnableChain/RunnableBranch 表达。
- 比如
-
对外接口仍然是 Runnable 形态
- 提供统一的
execute_general_chat(user_prompt, session_id),内部调用compiled_graph.ainvoke(...),符合"主链路是 LangGraph,但接口是 Runnable"的规范记忆。
- 提供统一的
一句话总结
后面要做的"多知识库循环 + 动态检索 + 中间播报 + 最终总结"这个复杂度,主执行链路用 LangGraph 更合适,Runnable 留在"节点内部 + 对外包装"层面; 如果现在还只是简单识别 + 一次回答,Runnable 足够,但一旦按我们设计的路线演进,迟早要迁到 LangGraph 做主编排。
因此我们决定使用LangGraph
LangGraph的实现
核心代码
python
def build_general_chat_graph() -> StateGraph:
"""
构建通用聊天的 LangGraph 工作流
流程图:
```
START
↓
fetch_repos (获取知识库)
↓
identify (识别意图)
↓
[路由判断]
├─ 匹配到知识库 → handle_matched → END
└─ 未匹配 → handle_not_matched → END
```
"""
log.info("[LangGraph] 开始构建工作流...")
# 1. 创建状态图
workflow = StateGraph(ChatState)
# 2. 添加节点
workflow.add_node("fetch_repos", fetch_knowledge_repos_node)
workflow.add_node("identify", identify_intent_node)
workflow.add_node("handle_matched", handle_matched_node)
workflow.add_node("handle_not_matched", handle_not_matched_node)
# 3. 设置入口点
workflow.set_entry_point("fetch_repos")
# 4. 添加边(流程连接)
workflow.add_edge("fetch_repos", "identify")
# 5. 添加条件边(分支路由)
workflow.add_conditional_edges(
"identify", # 从 identify 节点出发
route_after_identify, # 使用路由函数决定走向
{
"handle_matched": "handle_matched",
"handle_not_matched": "handle_not_matched"
}
)
# 6. 添加结束边
workflow.add_edge("handle_matched", END)
workflow.add_edge("handle_not_matched", END)
# 7. 编译工作流
app = workflow.compile()
log.info("[LangGraph] 工作流构建完成")
return app全代码
python
"""
通用聊天核心逻辑
基于 LangGraph 作为主编排实现
"""
import json
from typing import Any, Dict, List, Optional, TypedDict, Literal
from langgraph.graph import StateGraph, END
from langchain_core.runnables import Runnable
from src.knowledgerepo.knowledgerepo_tool import get_all_knowledge_repos
from src.utils.prompt_setting_helper import get_prompt_setting
from src.utils.llm_tools import get_line_settings
from src.chat.general_chat_constants import (
MODEL_NAME_CHAT,
FUNCTION_NAME_USER_QUERY_IDENTIFY,
FUNCTION_NAME_USER_INPUT_NOT_VALID_ANSWER,
)
from src.chat.general_chat_prompt_helper import (
format_knowledge_repo_list_for_prompt,
build_prompt_template_for_query_identify,
build_prompt_template_for_not_valid_answer,
)
from src.chat.general_chat_llm_caller import call_llm_with_fallback
from src.utils.logger import log
# ==================== 原始粒度的三个核心能力(保留兼容接口) ====================
async def get_knowledge_repos_list() -> List[Dict[str, Any]]:
"""获取所有知识库列表(保留原有接口,供其他模块直接调用)"""
log.info("[GeneralChat] 开始获取知识库列表...")
knowledge_repos = await get_all_knowledge_repos()
log.info(f"[GeneralChat] 获取到 {len(knowledge_repos)} 个知识库:")
for idx, repo in enumerate(knowledge_repos, 1):
log.info(
f" {idx}. {repo.get('knowledgeBaseName', 'N/A')} "
f"(ID: {repo.get('_id', 'N/A')})"
)
return knowledge_repos
async def identify_user_query_intent(
user_prompt: str, knowledge_repos: List[Dict[str, Any]]
) -> Optional[List[Dict[str, Any]]]:
"""识别用户查询意图(保留原有接口)"""
log.info("[GeneralChat] 开始识别用户查询意图...")
# 1. 获取提示词配置
prompt_config = await get_prompt_setting(
model_name=MODEL_NAME_CHAT,
function_name=FUNCTION_NAME_USER_QUERY_IDENTIFY,
)
if not prompt_config:
log.error(
"[GeneralChat] 未找到提示词配置: "
f"model_name={MODEL_NAME_CHAT}, function_name={FUNCTION_NAME_USER_QUERY_IDENTIFY}"
)
return None
system_role_msg = prompt_config.get("systemRoleMsg", "")
user_role_msg = prompt_config.get("userRoleMsg", "")
log.info(
f"[GeneralChat] 获取到提示词配置,systemRoleMsg 前100字: "
f"{system_role_msg[:100]}..."
)
# 2. 格式化知识库列表
knowledge_repo_list_json = format_knowledge_repo_list_for_prompt(knowledge_repos)
# 打印格式化后的知识库列表(美化输出)
log.info(
f"\n[GeneralChat] 内置知识库列表(共 {len(knowledge_repos)} 个):\n"
f"{knowledge_repo_list_json}\n"
)
# 3. 构建提示词模板
prompt_template = build_prompt_template_for_query_identify(
system_role_msg=system_role_msg,
user_role_msg=user_role_msg,
knowledge_repo_list_json=knowledge_repo_list_json,
user_prompt=user_prompt,
)
log.info(f"[GeneralChat] 用户当前提示: {user_prompt}")
# 4. 获取主备线路配置
line_settings = await get_line_settings(streaming=False)
if not line_settings:
log.error("[GeneralChat] 未找到任何 LLM 线路设置 (streaming=False)")
return None
master_line = line_settings.get("master")
slaver_line = line_settings.get("slaver")
if not master_line or not slaver_line:
log.error("[GeneralChat] 主线路或备线路配置不完整")
return None
# 5. 调用 LLM 进行意图识别
try:
result = await call_llm_with_fallback(
prompt_template=prompt_template,
master_line=master_line,
slaver_line=slaver_line,
chain_name="UserQueryIdentify",
parse_json=True,
)
data = result.get("data", {})
knowledge_list = data.get("knowledgeList", [])
if knowledge_list:
log.info(
f"\n[GeneralChat] LLM 判断结果为:命中\n"
f"匹配到 {len(knowledge_list)} 个知识库:\n"
f"{json.dumps(knowledge_list, ensure_ascii=False, indent=2)}\n"
)
else:
log.info("[GeneralChat] LLM 判断结果为:未命中任何知识库")
return knowledge_list
except Exception as e:
log.error(f"[GeneralChat] 调用 LLM 识别用户意图失败: {e}")
log.exception(e)
return None
async def generate_not_valid_answer(user_prompt: str) -> Optional[str]:
"""当用户输入不在服务范围时,生成友好的回答(保留原有接口)"""
log.info("[GeneralChat] 开始生成友好回答(用户输入不在服务范围)...")
# 1. 获取提示词配置
prompt_config = await get_prompt_setting(
model_name=MODEL_NAME_CHAT,
function_name=FUNCTION_NAME_USER_INPUT_NOT_VALID_ANSWER,
)
if not prompt_config:
log.error(
"[GeneralChat] 未找到提示词配置: "
f"model_name={MODEL_NAME_CHAT}, function_name={FUNCTION_NAME_USER_INPUT_NOT_VALID_ANSWER}"
)
return None
system_role_msg = prompt_config.get("systemRoleMsg", "")
user_role_msg = prompt_config.get("userRoleMsg", "")
# 2. 构建提示词模板
prompt_template = build_prompt_template_for_not_valid_answer(
system_role_msg=system_role_msg,
user_role_msg=user_role_msg,
user_prompt=user_prompt,
)
# 3. 获取主备线路配置
line_settings = await get_line_settings(streaming=False)
if not line_settings:
log.error("[GeneralChat] 未找到任何 LLM 线路设置 (streaming=False)")
return None
master_line = line_settings.get("master")
slaver_line = line_settings.get("slaver")
if not master_line or not slaver_line:
log.error("[GeneralChat] 主线路或备线路配置不完整")
return None
# 4. 调用 LLM 生成友好回答
try:
result = await call_llm_with_fallback(
prompt_template=prompt_template,
master_line=master_line,
slaver_line=slaver_line,
chain_name="UserInputNotValidAnswer",
parse_json=True,
)
data = result.get("data", {})
answer = data.get("answer", "")
log.info(f"[GeneralChat] 生成的友好回答: {answer}")
return answer
except Exception as e:
log.error(f"[GeneralChat] 调用 LLM 生成友好回答失败: {e}")
log.exception(e)
return None
# ==================== LangGraph 状态定义 ====================
class ChatState(TypedDict):
"""聊天工作流状态"""
# 输入
user_prompt: str
session_id: Optional[str]
# 中间状态
knowledge_repos: List[Dict[str, Any]]
matched_knowledge: Optional[List[Dict[str, Any]]]
# 输出
result_type: Optional[str] # "knowledge_matched" | "friendly_answer" | "error"
result_data: Optional[Any]
error: Optional[str]
# ==================== LangGraph 节点函数 ====================
async def fetch_knowledge_repos_node(state: ChatState) -> Dict[str, Any]:
"""节点1: 获取知识库列表"""
log.info("[LangGraph] 节点1: 获取知识库列表...")
try:
knowledge_repos = await get_all_knowledge_repos()
log.info(f"[LangGraph] 获取到 {len(knowledge_repos)} 个知识库:")
for idx, repo in enumerate(knowledge_repos, 1):
log.info(
f" {idx}. {repo.get('knowledgeBaseName', 'N/A')} "
f"(ID: {repo.get('_id', 'N/A')})"
)
return {"knowledge_repos": knowledge_repos}
except Exception as e:
log.error(f"[LangGraph] 获取知识库列表失败: {e}")
log.exception(e)
return {
"knowledge_repos": [],
"error": f"获取知识库失败: {str(e)}"
}
async def identify_intent_node(state: ChatState) -> Dict[str, Any]:
"""节点2: 识别用户意图"""
log.info("[LangGraph] 节点2: 识别用户查询意图...")
user_prompt = state["user_prompt"]
knowledge_repos = state.get("knowledge_repos", [])
# 如果知识库列表为空,直接返回未命中
if not knowledge_repos:
log.warning("[LangGraph] 知识库列表为空,跳过意图识别")
return {"matched_knowledge": []}
try:
# 1. 获取提示词配置
prompt_config = await get_prompt_setting(
model_name=MODEL_NAME_CHAT,
function_name=FUNCTION_NAME_USER_QUERY_IDENTIFY,
)
if not prompt_config:
log.error("[LangGraph] 未找到提示词配置")
return {"matched_knowledge": None, "error": "未找到提示词配置"}
system_role_msg = prompt_config.get("systemRoleMsg", "")
user_role_msg = prompt_config.get("userRoleMsg", "")
# 2. 格式化知识库列表
knowledge_repo_list_json = format_knowledge_repo_list_for_prompt(knowledge_repos)
log.info(
f"\n[LangGraph] 内置知识库列表(共 {len(knowledge_repos)} 个):\n"
f"{knowledge_repo_list_json}\n"
)
# 3. 构建提示词模板
prompt_template = build_prompt_template_for_query_identify(
system_role_msg=system_role_msg,
user_role_msg=user_role_msg,
knowledge_repo_list_json=knowledge_repo_list_json,
user_prompt=user_prompt,
)
log.info(f"[LangGraph] 用户当前提示: {user_prompt}")
# 4. 获取主备线路配置
line_settings = await get_line_settings(streaming=False)
if not line_settings:
log.error("[LangGraph] 未找到 LLM 线路设置")
return {"matched_knowledge": None, "error": "未找到 LLM 线路设置"}
master_line = line_settings.get("master")
slaver_line = line_settings.get("slaver")
if not master_line or not slaver_line:
log.error("[LangGraph] 主线路或备线路配置不完整")
return {"matched_knowledge": None, "error": "线路配置不完整"}
# 5. 调用 LLM 进行意图识别
result = await call_llm_with_fallback(
prompt_template=prompt_template,
master_line=master_line,
slaver_line=slaver_line,
chain_name="UserQueryIdentify",
parse_json=True,
)
data = result.get("data", {})
knowledge_list = data.get("knowledgeList", [])
if knowledge_list:
log.info(
f"\n[LangGraph] LLM 判断结果为:命中\n"
f"匹配到 {len(knowledge_list)} 个知识库:\n"
f"{json.dumps(knowledge_list, ensure_ascii=False, indent=2)}\n"
)
else:
log.info("[LangGraph] LLM 判断结果为:未命中任何知识库")
return {"matched_knowledge": knowledge_list if knowledge_list else []}
except Exception as e:
log.error(f"[LangGraph] 调用 LLM 识别用户意图失败: {e}")
log.exception(e)
return {"matched_knowledge": None, "error": str(e)}
async def handle_matched_node(state: ChatState) -> Dict[str, Any]:
"""节点3A: 处理匹配到知识库的情况"""
log.info("[LangGraph] 节点3A: 用户输入匹配到知识库")
matched_knowledge = state.get("matched_knowledge") or []
return {
"result_type": "knowledge_matched",
"result_data": matched_knowledge,
}
async def handle_not_matched_node(state: ChatState) -> Dict[str, Any]:
"""节点3B: 处理未匹配知识库的情况,生成友好回答"""
log.info("[LangGraph] 节点3B: 用户输入不在服务范围,生成友好回答...")
user_prompt = state["user_prompt"]
try:
# 1. 获取提示词配置
prompt_config = await get_prompt_setting(
model_name=MODEL_NAME_CHAT,
function_name=FUNCTION_NAME_USER_INPUT_NOT_VALID_ANSWER,
)
if not prompt_config:
log.error("[LangGraph] 未找到提示词配置")
return {
"result_type": "error",
"result_data": None,
"error": "未找到提示词配置",
}
system_role_msg = prompt_config.get("systemRoleMsg", "")
user_role_msg = prompt_config.get("userRoleMsg", "")
# 2. 构建提示词模板
prompt_template = build_prompt_template_for_not_valid_answer(
system_role_msg=system_role_msg,
user_role_msg=user_role_msg,
user_prompt=user_prompt,
)
# 3. 获取主备线路配置
line_settings = await get_line_settings(streaming=False)
if not line_settings:
log.error("[LangGraph] 未找到 LLM 线路设置")
return {
"result_type": "error",
"result_data": None,
"error": "未找到 LLM 线路设置",
}
master_line = line_settings.get("master")
slaver_line = line_settings.get("slaver")
if not master_line or not slaver_line:
log.error("[LangGraph] 主线路或备线路配置不完整")
return {
"result_type": "error",
"result_data": None,
"error": "线路配置不完整",
}
# 4. 调用 LLM 生成友好回答
result = await call_llm_with_fallback(
prompt_template=prompt_template,
master_line=master_line,
slaver_line=slaver_line,
chain_name="UserInputNotValidAnswer",
parse_json=True,
)
data = result.get("data", {})
answer = data.get("answer", "")
log.info(f"[LangGraph] 生成的友好回答: {answer}")
return {
"result_type": "friendly_answer",
"result_data": answer,
}
except Exception as e:
log.error(f"[LangGraph] 调用 LLM 生成友好回答失败: {e}")
log.exception(e)
return {
"result_type": "error",
"result_data": None,
"error": str(e),
}
# ==================== LangGraph 路由函数 ====================
def route_after_identify(state: ChatState) -> Literal["handle_matched", "handle_not_matched"]:
"""路由函数:根据意图识别结果决定走哪个分支"""
matched_knowledge = state.get("matched_knowledge")
if matched_knowledge is None or len(matched_knowledge) == 0:
log.info("[LangGraph] 路由决策: 走未匹配分支")
return "handle_not_matched"
log.info("[LangGraph] 路由决策: 走匹配分支")
return "handle_matched"
# ==================== LangGraph 工作流构建 ====================
def build_general_chat_graph() -> StateGraph:
"""
构建通用聊天的 LangGraph 工作流
流程图:
```
START
↓
fetch_repos (获取知识库)
↓
identify (识别意图)
↓
[路由判断]
├─ 匹配到知识库 → handle_matched → END
└─ 未匹配 → handle_not_matched → END
```
"""
log.info("[LangGraph] 开始构建工作流...")
# 1. 创建状态图
workflow = StateGraph(ChatState)
# 2. 添加节点
workflow.add_node("fetch_repos", fetch_knowledge_repos_node)
workflow.add_node("identify", identify_intent_node)
workflow.add_node("handle_matched", handle_matched_node)
workflow.add_node("handle_not_matched", handle_not_matched_node)
# 3. 设置入口点
workflow.set_entry_point("fetch_repos")
# 4. 添加边(流程连接)
workflow.add_edge("fetch_repos", "identify")
# 5. 添加条件边(分支路由)
workflow.add_conditional_edges(
"identify", # 从 identify 节点出发
route_after_identify, # 使用路由函数决定走向
{
"handle_matched": "handle_matched",
"handle_not_matched": "handle_not_matched"
}
)
# 6. 添加结束边
workflow.add_edge("handle_matched", END)
workflow.add_edge("handle_not_matched", END)
# 7. 编译工作流
app = workflow.compile()
log.info("[LangGraph] 工作流构建完成")
return app
# ==================== 对外统一接口(Runnable 封装) ====================
async def execute_general_chat_chain(
user_prompt: str, session_id: Optional[str] = None
) -> Dict[str, Any]:
"""
执行通用聊天工作流(主入口)
对外统一的 Runnable 入口,内部使用 LangGraph 工作流
Args:
user_prompt: 用户输入
session_id: 会话ID(可选)
Returns:
执行结果字典:
- result_type: "knowledge_matched" | "friendly_answer" | "error"
- result_data: 对应的业务结果(知识库列表或友好回答文本)
- error: 错误信息(仅在 result_type == "error" 时有意义)
"""
log.info(
f"[LangGraph] 开始执行工作流, "
f"user_prompt={user_prompt}, session_id={session_id}"
)
# 构建 LangGraph 工作流
app = build_general_chat_graph()
# 初始化状态
initial_state: ChatState = {
"user_prompt": user_prompt,
"session_id": session_id,
"knowledge_repos": [],
"matched_knowledge": None,
"result_type": None,
"result_data": None,
"error": None,
}
# 执行工作流
final_state = await app.ainvoke(initial_state)
log.info(
f"[LangGraph] 工作流执行完成, "
f"result_type={final_state.get('result_type')}"
)
# 返回结果(保持与原接口一致的格式)
return {
"result_type": final_state.get("result_type"),
"result_data": final_state.get("result_data"),
"error": final_state.get("error"),
}
# ==================== 可视化工具 ====================
def visualize_workflow() -> str:
"""
生成 LangGraph 工作流的 Mermaid 流程图代码(简洁版,不含样式)
Returns:
Mermaid 格式的流程图代码(标准格式,兼容所有渲染器)
"""
app = build_general_chat_graph()
# 获取原始 Mermaid 代码
raw_mermaid = app.get_graph().draw_mermaid()
# 清理并简化为标准 Mermaid 格式
lines = []
for line in raw_mermaid.split('\n'):
# 跳过样式定义和配置行
if line.strip().startswith('%%{init:'):
continue
if line.strip().startswith('classDef'):
continue
if ':::first' in line or ':::last' in line or ':::default' in line:
# 移除样式类标记
line = line.replace(':::first', '').replace(':::last', '').replace(':::default', '')
# 移除 HTML 标签(如 <p>)
line = line.replace('<p>', '').replace('</p>', '')
# 移除节点名称中的方括号包裹(保留箭头符号)
if '([' in line and '])' in line and '__start__' in line:
line = line.replace('([', '[').replace('])', ']')
if '([' in line and '])' in line and '__end__' in line:
line = line.replace('([', '[').replace('])', ']')
lines.append(line)
# 重新组合
cleaned_mermaid = '\n'.join(lines)
log.info("[LangGraph] 生成的简洁 Mermaid 流程图:")
log.info(f"\n{cleaned_mermaid}\n")
return cleaned_mermaid通过手工编程、RunnableBranch、LangGraph得到结论
LangGraph
❌ 不是图形界面
LangGraph 没有图形化拖拽界面(不像 n8n、Flowise 那种低代码平台)。
✅它是代码生成流程图
LangGraph 可以把你用代码定义的工作流自动转换成 Mermaid 流程图或 PNG 图片。
具体示例
python
# ==================== 可视化工具 ====================
def visualize_workflow() -> str:
"""
生成 LangGraph 工作流的 Mermaid 流程图代码(简洁版,不含样式)
Returns:
Mermaid 格式的流程图代码(标准格式,兼容所有渲染器)
"""
app = build_general_chat_graph()
# 获取原始 Mermaid 代码
raw_mermaid = app.get_graph().draw_mermaid()
# 清理并简化为标准 Mermaid 格式
lines = []
for line in raw_mermaid.split('\n'):
# 跳过样式定义和配置行
if line.strip().startswith('%%{init:'):
continue
if line.strip().startswith('classDef'):
continue
if ':::first' in line or ':::last' in line or ':::default' in line:
# 移除样式类标记
line = line.replace(':::first', '').replace(':::last', '').replace(':::default', '')
# 移除 HTML 标签(如 <p>)
line = line.replace('<p>', '').replace('</p>', '')
# 移除节点名称中的方括号包裹(保留箭头符号)
if '([' in line and '])' in line and '__start__' in line:
line = line.replace('([', '[').replace('])', ']')
if '([' in line and '])' in line and '__end__' in line:
line = line.replace('([', '[').replace('])', ']')
lines.append(line)
# 重新组合
cleaned_mermaid = '\n'.join(lines)
log.info("[LangGraph] 生成的简洁 Mermaid 流程图:")
log.info(f"\n{cleaned_mermaid}\n")
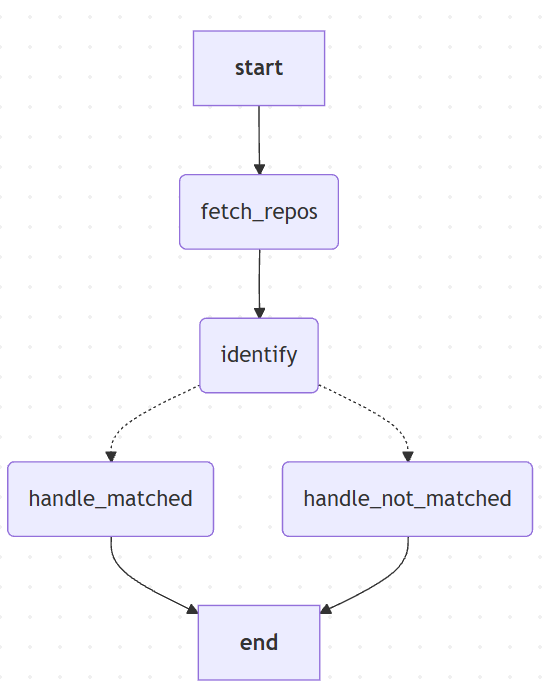
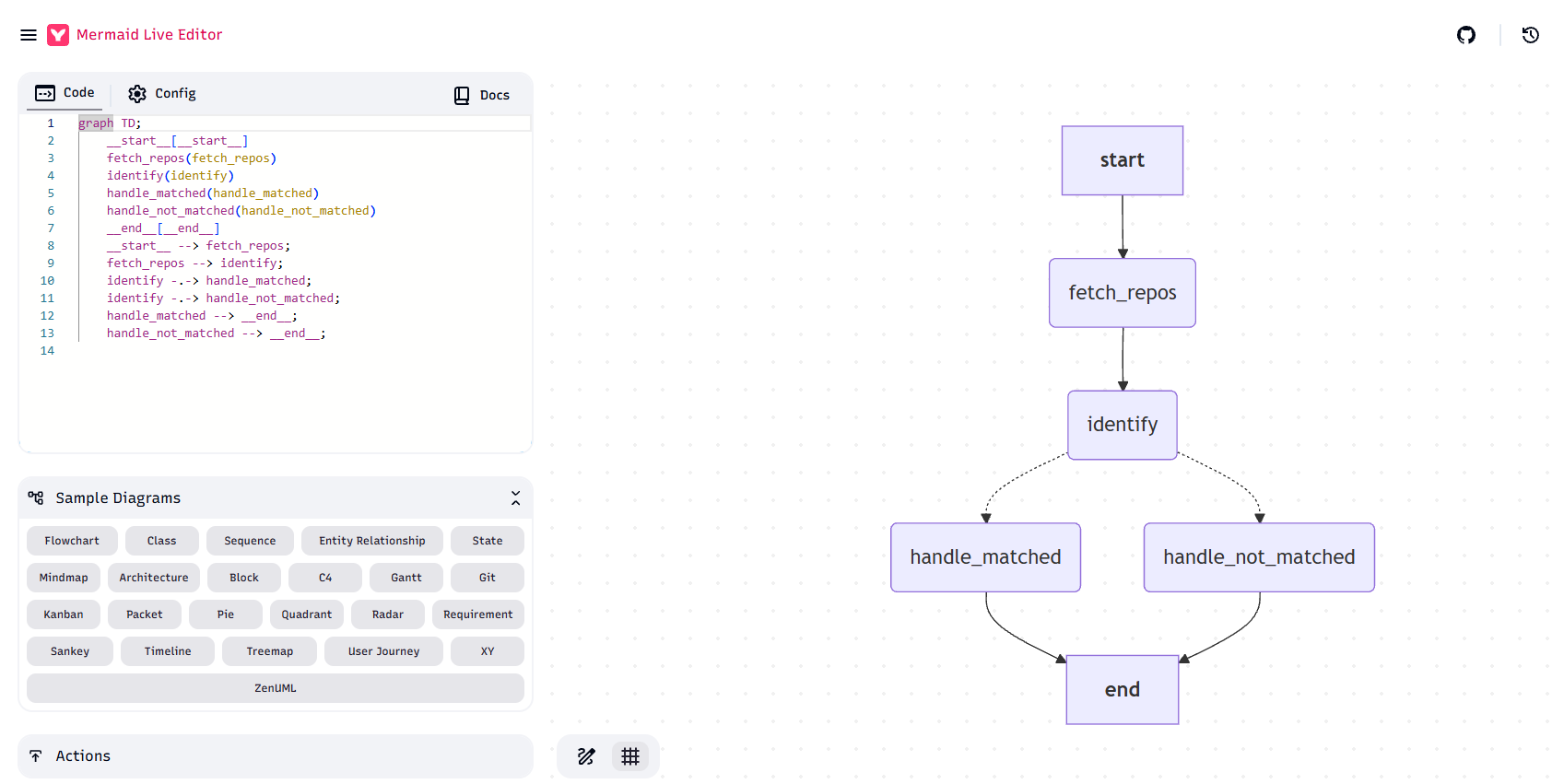
return cleaned_mermaid这块代码会生成:Mermaid 代码,把Mermaid代码放入:Mermaid在线免费生成图工具里后你应该会得到这样的一个图
你也可以把这个代码粘贴到支持 Mermaid 的地方(GitHub、Notion、Typora 等)就能看到图形。
对比手工代码
❌ 手工编排
python
router.pyknowledge_repos = await get_knowledge_repos_list()
knowledge_list = await identify_user_query_intent(user_prompt, knowledge_repos)
if not knowledge_list:
answer = await generate_not_valid_answer(user_prompt)
yield answer
else:
yield knowledge_list我们可以看到问题:流程隐藏在代码逻辑里,无法可视化。要理解流程必须读代码。
✅ LangGraph(可视化)
python
workflow = StateGraph(...)
workflow.add_node(...)
workflow.add_edge(...)
app = workflow.compile()
# 随时可以生成流程图
print(app.get_graph().draw_mermaid())LangGraph在实际工作中怎么使用的流程
-
开发阶段:你用 Python 代码定义工作流
-
调试阶段:在 Jupyter Notebook 里查看流程图,确认逻辑正确
-
文档阶段:导出流程图放到文档/Wiki 里
-
维护阶段:新同事看流程图就能理解系统
总结
| 特性 | 手工编排 | LangGraph |
|---|---|---|
| 编写方式 | if-else + 函数调用 | 声明式图定义 |
| 流程可视化 | ❌ 无法自动生成 | ✅ 一行代码生成 |
| 理解成本 | 需要读代码 | 看图就懂 |
| 适合场景 | 简单流程(≤3步) | 复杂流程/多人协作 |
演示用LangGraph实现的工作流调用效果
python
{
"session_id": "111111",
"user_prompt": "你吃了吗"
}得到答案
python
data: {"status": "streaming", "content": "您好,我是一个AI助手,无法进食。
但我很乐意帮助您解答问题或提供帮助。有什么我可以帮您的吗?"}
data: {"status": "completed", "message": "回答完成"}再来
python
{
"session_id": "111111",
"user_prompt": "李白是中原人吗"
}得到答案
python
data: {"status": "knowledge_matched",
"knowledgeList": [{"id": "697b2059e1e0bd166ab8ae92", "knowledgeBaseName": "test3", "description": "test3", "systemRole": "李白的生平事迹相关介绍", "relatedQuestion": "李白是中原人吗"}]}
data: {"status": "completed", "message": "知识库匹配完成"}我们把上述的visualize_workflow通过本系列里的:langchain_start.py暴露成api
general_chat_router.py
python
"""
通用聊天 FastAPI 路由
"""
import json
from typing import Optional
from fastapi import APIRouter, HTTPException
from fastapi.responses import StreamingResponse
from pydantic import BaseModel
from src.chat.general_chat import execute_general_chat_chain, visualize_workflow
from src.utils.logger import log
# 创建子路由
router = APIRouter(prefix="/general_chat", tags=["General Chat"])
# --- 模型定义 ---
class GeneralChatRequest(BaseModel):
"""通用聊天请求模型"""
session_id: Optional[str] = None
user_prompt: Optional[str] = None
# --- 路由入口 ---
@router.post("")
async def general_chat(request: GeneralChatRequest):
"""
通用聊天接口(SSE 流式响应)
接口地址: POST http://localhost:8001/v1/chat/general_chat
Args:
request: 请求参数
- session_id: 会话 ID(可选)
- user_prompt: 用户输入(可选)
Returns:
SSE 流式响应
"""
async def generate_stream():
try:
log.info("[GeneralChatRouter] 收到通用聊天请求")
log.info(f"[GeneralChatRouter] session_id={request.session_id}")
log.info(f"[GeneralChatRouter] user_prompt={request.user_prompt}")
# 参数验证
if not request.user_prompt or not request.user_prompt.strip():
log.warning("[GeneralChatRouter] user_prompt 为空,返回错误")
yield f"data: {json.dumps({'status': 'error', 'error': '用户输入不能为空'}, ensure_ascii=False)}\n\n"
return
user_prompt = request.user_prompt.strip()
# 使用 LangGraph 工作流执行
from src.chat.general_chat import execute_general_chat_chain
log.info("[GeneralChatRouter] 使用 LangGraph 工作流执行...")
result = await execute_general_chat_chain(user_prompt, request.session_id)
result_type = result.get("result_type")
result_data = result.get("result_data")
error = result.get("error")
if error:
log.error(f"[GeneralChatRouter] 决策链执行失败: {error}")
yield f"data: {json.dumps({'status': 'error', 'error': error}, ensure_ascii=False)}\n\n"
return
if result_type == "knowledge_matched":
log.info(f"[GeneralChatRouter] 用户输入匹配到 {len(result_data or [])} 个知识库")
knowledge_list_json = json.dumps(result_data or [], ensure_ascii=False)
log.info(f"[GeneralChatRouter] 返回知识库列表:\n{knowledge_list_json}")
yield f"data: {json.dumps({'status': 'knowledge_matched', 'knowledgeList': result_data or []}, ensure_ascii=False)}\n\n"
yield f"data: {json.dumps({'status': 'completed', 'message': '知识库匹配完成'}, ensure_ascii=False)}\n\n"
elif result_type == "friendly_answer":
log.info(f"[GeneralChatRouter] 返回友好回答: {result_data}")
yield f"data: {json.dumps({'status': 'streaming', 'content': result_data}, ensure_ascii=False)}\n\n"
yield f"data: {json.dumps({'status': 'completed', 'message': '回答完成'}, ensure_ascii=False)}\n\n"
else:
log.error(f"[GeneralChatRouter] 未知的结果类型: {result_type}")
yield f"data: {json.dumps({'status': 'error', 'error': '未知结果类型'}, ensure_ascii=False)}\n\n"
return
except Exception as e:
log.error("[GeneralChatRouter] 处理请求时发生异常")
log.exception(e)
yield f"data: {json.dumps({'status': 'error', 'error': str(e)}, ensure_ascii=False)}\n\n"
return StreamingResponse(
generate_stream(),
media_type="text/event-stream",
headers={
"Cache-Control": "no-cache",
"Connection": "keep-alive",
"X-Accel-Buffering": "no"
}
)
@router.get("/visualize")
async def visualize_langgraph():
"""
可视化 LangGraph 工作流
接口地址: GET http://localhost:8001/v1/chat/general_chat/visualize
Returns:
Mermaid 格式的流程图代码(纯文本格式,可直接粘贴)
"""
from fastapi.responses import PlainTextResponse
try:
mermaid_code = visualize_workflow()
# 返回纯文本格式(带说明头部)
response_text = (
"# LangGraph 工作流可视化\n"
"# 复制下面的 Mermaid 代码,粘贴到 https://mermaid.live/ 查看流程图\n"
"# 或者在 GitHub/Notion Markdown 中使用 ```mermaid 包裹\n\n"
+ mermaid_code
)
return PlainTextResponse(response_text)
except Exception as e:
log.error(f"[GeneralChatRouter] 生成流程图失败: {e}")
log.exception(e)
return PlainTextResponse(f"# Error\n生成流程图失败: {str(e)}")在langchain_start.py里注册
langchain_start.py
python
import sys
from pathlib import Path
from contextlib import asynccontextmanager
# Add project root to path
project_root = Path(__file__).parent.parent
sys.path.insert(0, str(project_root))
from fastapi import FastAPI
from src.api.smartpen.router import router as smartpen_router
from src.api.demo.router import router as demo_router
from src.knowledgerepo.knowledge_repo_router import router as knowledgebase_router
from src.chat.general_chat_router import router as general_chat_router
from src.utils.logger import log
from src.core.mongo import get_mongo_client, close_mongo_connection
from src.core.redis_client import get_redis_client, close_redis_connection
@asynccontextmanager
async def lifespan(app: FastAPI):
"""
应用生命周期管理:启动和关闭时的资源初始化与清理
"""
# Startup
log.info("[Startup] Initializing application...")
# MongoDB 健康检查
log.info("[Startup] Checking MongoDB connection...")
mongo_client = get_mongo_client()
try:
# 使用 ping 命令检查连接是否正常
result = await mongo_client.admin.command("ping")
log.info(f"[Startup] MongoDB ping result: {result}")
log.info("[Startup] MongoDB connection established successfully ✓")
except Exception as e:
log.error(f"[Startup] Failed to connect to MongoDB: {e}")
log.error("[Startup] Application will continue but MongoDB operations may fail")
# Redis 健康检查
log.info("[Startup] Checking Redis connection...")
redis_client = get_redis_client()
try:
# 使用 ping 命令检查连接是否正常
ping_result = redis_client.ping()
log.info(f"[Startup] Redis ping result: {ping_result}")
# 打印连接池信息(调试用)
pool_info = redis_client.connection_pool
log.info(
f"[Startup] Redis connection pool info: "
f"max_connections={pool_info.max_connections}, "
f"connection_kwargs={{host={pool_info.connection_kwargs.get('host')}, "
f"port={pool_info.connection_kwargs.get('port')}, "
f"db={pool_info.connection_kwargs.get('db')}}}"
)
log.info("[Startup] Redis connection established successfully ✓")
except Exception as e:
log.error(f"[Startup] Failed to connect to Redis: {e}")
log.error("[Startup] Application will continue but Redis operations may fail")
log.info("[Startup] Application startup complete ✓")
yield
# Shutdown
log.info("[Shutdown] Starting application shutdown...")
log.info("[Shutdown] Closing MongoDB connection...")
await close_mongo_connection()
log.info("[Shutdown] MongoDB connection closed ✓")
log.info("[Shutdown] Closing Redis connection...")
close_redis_connection()
log.info("[Shutdown] Redis connection closed ✓")
log.info("[Shutdown] Application shutdown complete ✓")
app = FastAPI(title="QuickChain LangChain Service", lifespan=lifespan)
# 挂载子路由
# 将 smartpen_router 挂载到 /v1/chat 下
# 最终路径将是: POST /v1/chat/smartpen-generate
app.include_router(smartpen_router, prefix="/v1/chat")
# 将 demo_router 挂载到 /v1/chat 下
# 最终路径将是: POST /v1/chat/demo/intension-identify
app.include_router(demo_router, prefix="/v1/chat")
# 将 knowledgebase_router 挂载到 /v1/chat 下
# 最终路径将是: POST /v1/chat/knowledgebase/label-identify
app.include_router(knowledgebase_router, prefix="/v1/chat")
# 将 general_chat_router 挂载到 /v1/chat 下
# 最终路径将是: POST /v1/chat/general_chat
app.include_router(general_chat_router, prefix="/v1/chat")
@app.get("/")
async def root():
return {"message": "QuickChain LangChain Service is running", "version": "1.0.0"}
@app.get("/health")
async def health():
return {"status": "healthy", "service": "langchain_service"}
if __name__ == "__main__":
import uvicorn
log.info("Starting QuickChain LangChain Service on port 8001...")
uvicorn.run(app, host="0.0.0.0", port=8001)接着我们这样访问:
python
curl --location --request GET 'http://localhost:8001/v1/chat/general_chat/visualize' \
--header 'Content-Type: application/json' \
--data-raw ''然后我们得到结果如下:
python
# LangGraph 工作流可视化
# 复制下面的 Mermaid 代码,粘贴到 https://mermaid.live/ 查看流程图
# 或者在 GitHub/Notion Markdown 中使用 ```mermaid 包裹
graph TD;
__start__[__start__]
fetch_repos(fetch_repos)
identify(identify)
handle_matched(handle_matched)
handle_not_matched(handle_not_matched)
__end__[__end__]
__start__ --> fetch_repos;
fetch_repos --> identify;
identify -.-> handle_matched;
identify -.-> handle_not_matched;
handle_matched --> __end__;
handle_not_matched --> __end__;从graph TD开始复制到最后放到在线Mermaid网址里去即可就可以得到一幅当前的流程图了。
写在最后
传统编码、RunnableBranch、LangGraph三者对比
综上所述,面对"动态知识库路由 + 多轮检索-推理"这类复杂流程,三种实现方式各有利弊:手工 if-else 编程 逻辑直观但代码冗长、难以维护,扩展性差;RunnableBranch / RunnableLambda 利用 LCEL 提升了声明式表达能力,适合简单分支,却无法自然表达循环与状态更新;而 LangGraph 通过图结构显式建模状态流转,天然支持循环、条件跳转与中间反馈,在复杂、动态、多步骤的 Agent 工作流中展现出强大优势------不仅代码清晰,还易于调试、监控和扩展。
| 方式 | 可读性 | 循环支持 | 状态管理 | 扩展性 | 适用场景 |
|---|---|---|---|---|---|
| 手工 if-else | 低 | 弱 | 手动 | 差 | 超简单线性逻辑 |
| RunnableBranch | 中 | ❌ | 无 | 一般 | 静态分支、无状态流程 |
| LangGraph | 高 | ✅ | 内置 | 强 | 动态决策、多轮 Agent |
LangGraph与Dify、n8n等低代码开发工具的比较
相比之下,DIFY 等低代码平台虽然降低了 AI 应用的入门门槛,但其流程编排多为静态、线性、黑盒化设计,难以支持"根据 LLM 输出动态决定检索哪些知识库"或"在循环中实时生成中间反馈"等高级交互逻辑。DIFY 的节点跳转依赖预设条件,无法在运行时动态构建执行路径,更缺乏对状态的细粒度控制。而 LangGraph 以代码为载体,赋予开发者完全的控制权------你可以自由定义节点行为、状态更新规则和跳转逻辑,轻松实现 DIFY 无法胜任的复杂 Agent 工作流。
| 能力维度 | LangGraph | DIFY(当前版本) |
|---|---|---|
| 编排方式 | 代码驱动,图结构显式定义(节点 + 边) | 可视化低代码拖拽,隐式流程 |
| 动态决策支持 | ✅ 支持运行时根据 LLM/状态动态决定下一步 | ❌ 仅支持预设条件分支,无法动态生成新路径 |
| 嵌套循环/迭代 | ✅ 原生支持循环、递归、多轮思考-行动闭环 | ❌ 不支持嵌套循环,只支持一层循环,流程为单向 DAG |
| 中间状态反馈 | ✅ 可在每一步输出中间结果(如"正在检索...") | ⚠️ 有限,通常仅支持最终输出 |
| 多知识库动态路由 | ✅ 可由 LLM 判断后动态遍历多个知识库 | ❌ 需预先绑定固定知识库,无法运行时动态扩展 |
当你的 AI 应用开始"思考",LangGraph 就是那个值得托付的主编排大脑。
简而言之:DIFY 适合快速搭建标准问答机器人,LangGraph 才是构建真正智能、可推理、会决策的 AI Agent 的利器。
附:项目中要用LangGraph的额外安装
它是完全开源免费的,LangChain官方专门用来应对复杂工作流的。
-
LangGraph 是独立的包,不包含在
langchain核心包中 -
需要
langchain-core >= 0.2.0 -
Python >= 3.9
你可以直接在你的requirement.txt里这样声明
python
# LangChain Core Dependencies (Python 3.13+)
# 核心框架
langchain==0.3.13
langchain-core==0.3.28
langchain-community==0.3.13
langgraph>=0.2.0 # Agent 工作流框架(支持可视化)