【论文】一种实用的VLA基础模型 ------
2601.A Pragmatic VLA Foundation Model
【项目主页】:https://technology.robbyant.com/lingbot-vla
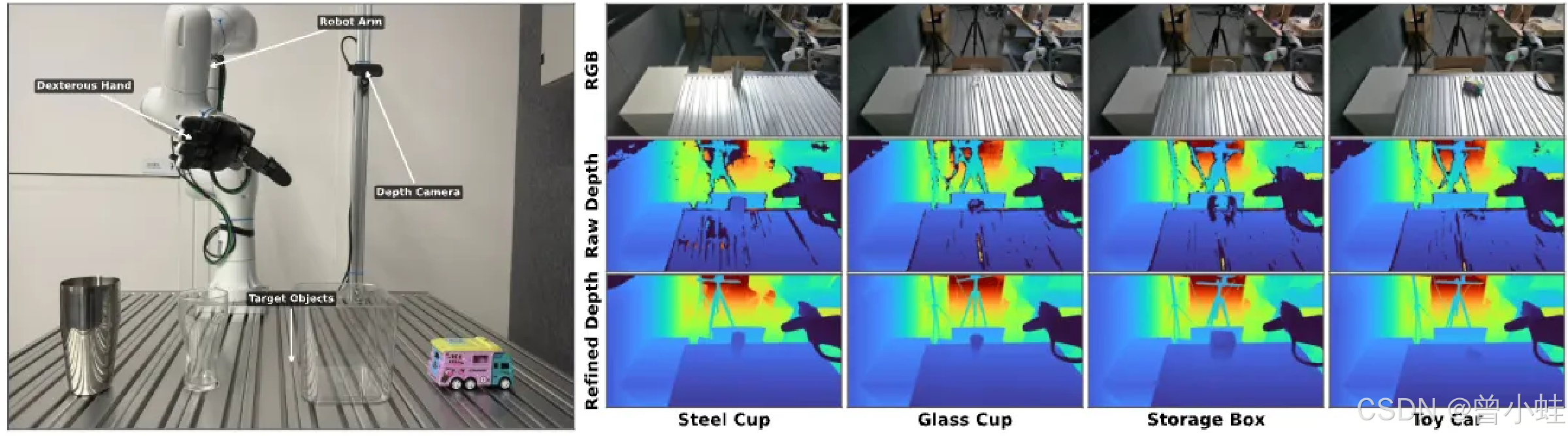
增强深度感知
rgb就好看不出透明杯;原始深度图也缺失; 修复后的,更明显
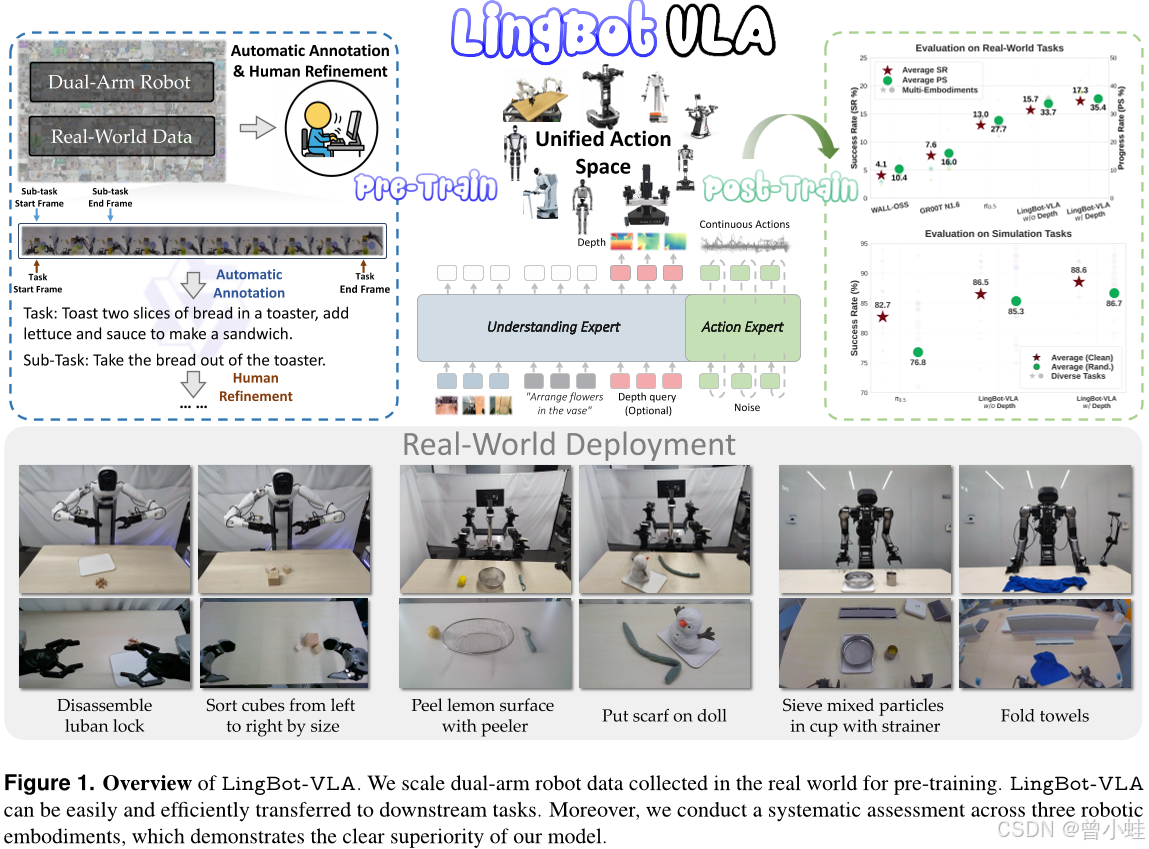
LingBotVLA简介
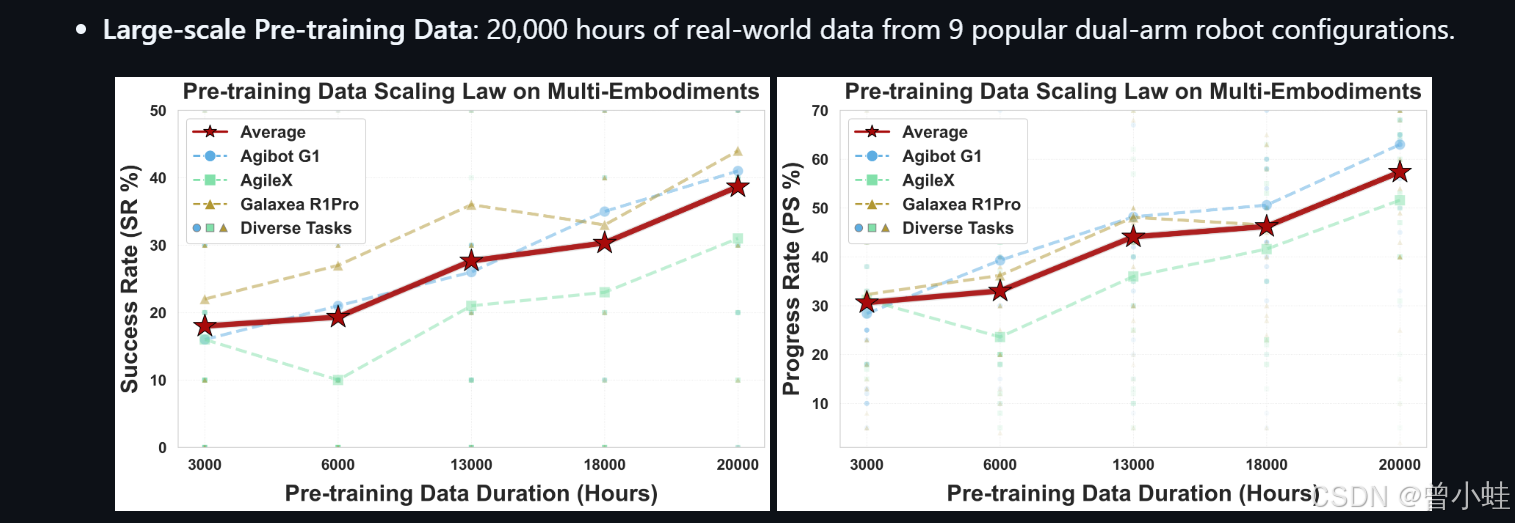
大规模预训练数据 (Large-scale Pre-training Data);我们基于9种热门双臂机器人配置,利用约2万小时的真实世界数据,开发了LingBot-VLA
数据来源于不同结构 的双臂机器人和多种场景(操纵、抓取、复合任务等),使模型学习到跨任务、跨形态的通用行为策略
数据收集
预训练数据集基于从9种流行的双臂机器人型号中收集的大规模远程操作数据构建,如图2所示。我们将在下文讨论这些型号:
·AgiBot G1。该装置配备两个7自由度机械臂,以及三个RGB-D摄像头。机器人数据通过基于虚拟现实的遥操作在此装置上采集。
· AgileX。该装置配备三台摄像头和两支6自由度机械臂。在数据采集过程中,采用同构机械臂实现机器人控制。
·Galaxea R1Lite。该配置配备两个6自由度机械臂,以及一台立体相机和两台腕部摄像头。
·Galaxea R1Pro。该配置使用了两个7自由度机械臂、一个立体相机和两个腕部摄像头。
·Realman Rs-02。该配置采用三台摄像头,具备16维的构型与动作空间:两个7自由度机械臂和两个并联夹爪。

验证了:"多机器人形态上的预训练数据规模定律"
scaling law