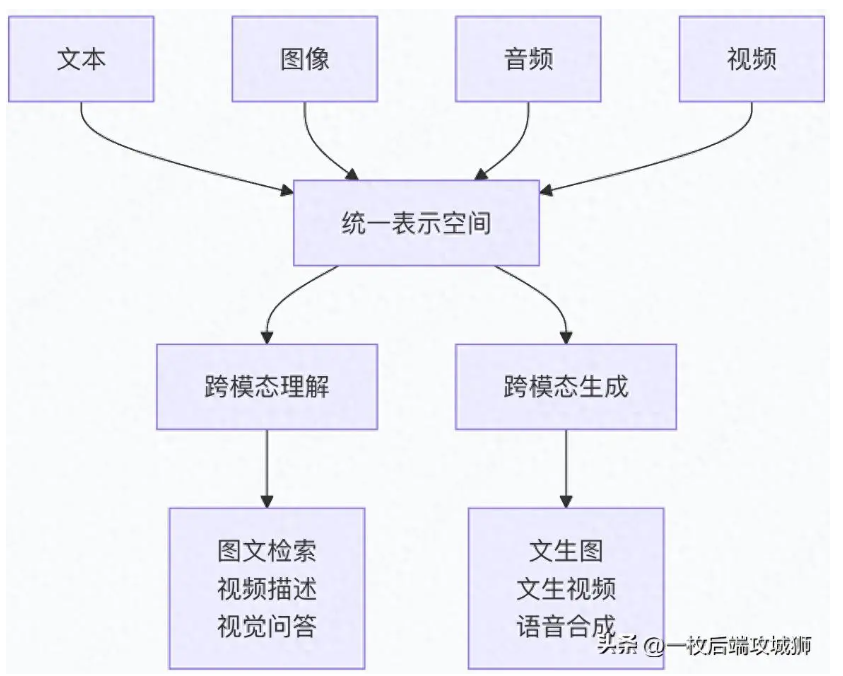
多模态大模型的定义
1)跨模态模型
跨模态指的是在不同模态之间进行信息转换或关联的过程。跨模态处理在人工智能中非常重要,因为它涉及到如何让机器理解和处理不同类型数据的问题。例如我们最常见的语音识别,就是一个听觉模态到文本模态的转换,还有最近很火的AIGC大模型文生图,就是文本模态到视觉模态的转换。跨模态的关键在于如何识别不同模态之间的语义差异,并准确地在它们之间进行信息映射。
模态定义: 在人工智能领域,模态(Modality)、跨模态(Cross-modality)和多模态(Multimodality)是描述数据类型和数据处理方式的重要概念。模态指的是信息的表现形式或感官通道。在日常交流中,我们使用多种模态来传递信息,例如语言(听觉模态)、文字(视觉模态)、肢体语言(视觉模态)和声音(听觉模态)。常见类型包括:
- 视觉模态:如图像、视频。
- 听觉模态:如音频、语音。
- 文本模态:如文字。
- 触觉模态:如触觉反馈或通过触觉感知的数据
跨模态处理:涉及在不同模态间进行信息转换或关联,例如语音识别(听觉到文本)或文生图(文本到视觉)。关键挑战是识别语义差异并准确映射信息。
跨模态模型具有多个关键特性:
- 多模态输入:跨模态模型能够同时接受和处理来自不同模态的输入数据,如文本、图像、声音等。
- 多模态输出:这些模型不仅可以处理多模态输入,还可以生成多模态的输出,例如从文本生成图像,或从语音生成文本。
- 模态转换:跨模态模型能够实现不同模态之间的转换,如将文本描述转换为相应的图像或视频。
- 多模态表示学习:模型能够学习不同模态数据之间的关联,形成更丰富的多模态表示,从而增强对数据的理解和处理能力。
典型模型示例:
- CLIP:由OpenAI提出,可理解并生成文本与图像的关联。CLIP是由OpenAI开发的,它将图像和文本映射到一个共享的嵌入空间,使得模型能够同时理解图像和文本。
- DALL·E:根据文本描述生成高质量图像。
- AudioLM:通过文本或音频描述生成自然声音。
- UNIMO:由华为Noah's Ark实验室开发的,它专注于将图像和文本整合在一起以提升自然语言理解和生成的性能。
应用领域:跨模态模型广泛用于图像文本匹配、智能检索、推荐系统等,通过融合多源信息提升理解能力。例如,在医疗领域,跨模态模型可以整合病人的医学影像数据和病历文本数据,为医生提供更全面的诊断依据。在自动驾驶领域,跨模态模型通过整合图像、声音和文本等多模态数据,可以帮助自动驾驶系统更好地感知和理解周围环境。此外,跨模态模型还在智能客服、教育、娱乐等领域得到了广泛应用。
2)单模态大模型
单模态大模型是指仅处理一种特定类型数据的大规模人工智能模型。它专注于理解和生成单一模态的信息,例如文本、图像或音频,但不能同时处理多种模态的混合输入。
核心特征:
- 单一数据类型:模型架构和训练目标都围绕一种模态设计,如纯文本或纯图像。
- 参数规模大:作为大模型,它拥有数十亿至数万亿级别的参数,基于海量数据训练,具备强大的学习和泛化能力。
- 任务专注:在特定领域表现优异,例如文本生成、图像分类或语音识别,但缺乏跨模态的关联理解能力。
常见类型与示例:
- 大语言模型(LLM):这是最常见的单模态大模型,仅处理文本数据。代表模型包括 ChatGPT、Claude、DeepSeek 和千问等,应用于对话系统、文本创作和翻译等任务。
- 图像生成模型:专注于图像的生成与理解,如 Stable Diffusion、Midjourney 和 DALL·E 3。
- 语音/音频模型:处理音频信号,如 Whisper(语音转文字)和 Mistral(音乐生成)。
与多模态大模型的区别:
- 单模态模型是多模态模型的基础,多模态模型在结构上通常包含单模态组件(如视觉编码器和语言模型),但增加了跨模态对齐与融合能力。
- 单模态模型的输入输出局限于一种模态(如"聊文字"),而多模态模型能处理混合输入(如"看图说话")。
简而言之,单模态大模型是"专精型"AI,而多模态大模型是"全能型"AI。
3)多模态模型
多模态指同时使用或分析多种模态的数据。例如,在一个多模态的情感分析任务中,系统可能会同时考虑文本内容(文本模态)、说话人的语气(听觉模态)和面部表情(视觉模态)。多模态数据处理提供了更丰富的信息,例如结合视觉(图像)、雷达和激光雷达数据来感知环境开发的自动驾驶算法,就是多模态技术的代表作。
多模态的基本原理
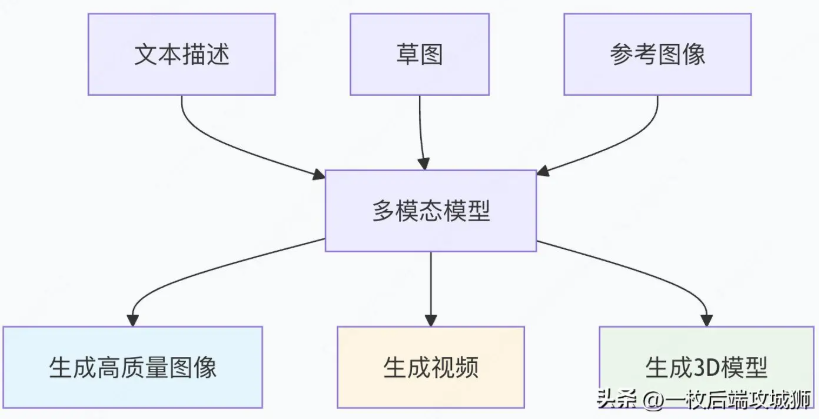
多模态模型架构的演进
"早期方法": {
"技术": "分别处理各模态,后期融合",
"例子": "分别提取图像和文本特征,然后拼接",
"缺点": "缺乏深层交互,理解有限"
},
"中期方法": {
"技术": "跨模态注意力机制",
"例子": "CLIP, ViLBERT",
"优点": "模态间交互,理解更深"
},
"现代方法": {
"技术": "统一编码器,任意模态输入输出",
"例子": "GPT-4V, DALL-E 3, Sora",
"优点": "无缝跨模态,端到端学习"
}跨模态生成能力
4)多模态语言大模型
多模态大模型是指能够同时处理和理解多种类型信息(如文本、图像、音频、视频等)的大型人工智能模型。它们打破了传统单一模态模型的局限,实现了跨模态的理解、推理和生成能力。
多模态语言大模型与多模态大模型是同一类人工智能模型的不同称呼,二者在核心概念和应用上高度重合,均指能够处理和融合多种类型数据(如文本、图像、音频、视频等)的大型模型。
多模态语言大模型:该术语强调模型以语言模型为基础,通过整合多模态输入(如视觉、听觉信息)来增强语言理解和生成能力,实现跨模态的推理与交互。例如,模型能根据图像内容生成描述性文本,或根据文字指令生成相应图像。
多模态大模型:作为更广泛的统称,指能够处理多种模态数据的大型模型,其训练和应用涵盖自然语言处理、计算机视觉、音频分析等领域,旨在提升对复杂信息的综合理解能力。
在实际使用中,这两个术语常被互换,均指向以大语言模型为基座、扩展多模态感知能力的先进AI系统。
有哪些多模态大模型
参考链接:https://developer.aliyun.com/article/1688802
多模态大模型是一种通过整合文本、图像、视频、音频等多类型数据进行联合训练的深度学习模型,核心技术包括跨模态编码器训练、语义对齐与特征融合。
1.开创性模型
-
CLIP - 连接文本和图像
CLIP模型配置和特点
clip_model_info = {
"开发者": "OpenAI",
"发布时间": "2021",
"核心创新": "对比学习连接文本和图像表示",
"训练数据": "4亿个图文对",
"能力": {
"零样本图像分类": "无需训练直接分类",
"图文检索": "跨模态搜索",
"图像生成引导": "为DALL-E提供基础"
},
"架构": {
"文本编码器": "Transformer",
"图像编码器": "ViT或CNN",
"损失函数": "对比损失"
}
} -
DALL-E系列 - 文本到图像生成
DALL-E模型配置和特点
dalle_evolution = {
"DALL-E 1": {
"发布时间": "2021年1月",
"核心能力": "从文本生成图像",
"技术特点": "离散VAE + Transformer",
"训练数据": "数亿图文对",
"生成质量": "256x256分辨率,概念组合能力强"
},
"DALL-E 2": {
"发布时间": "2022年4月",
"改进点": "更高的分辨率和真实性",
"新技术": "扩散模型 + CLIP引导",
"分辨率": "1024x1024",
"应用": "商业设计、艺术创作"
},
"DALL-E 3": {
"发布时间": "2023年",
"重大改进": "更好的提示跟随和细节",
"集成": "与ChatGPT深度集成",
"安全性": "更强的内容过滤"
}
}
2.通用多模态模型
-
GPT-4V - 多模态理解大师
gpt4v_capabilities = {
"模型全称": "GPT-4 with Vision",
"发布方": "OpenAI",
"核心能力": "理解和推理多模态内容",
"支持模态": ["文本", "图像", "文档", "图表"],
"典型应用": {
"视觉问答": "回答关于图像的问题",
"文档分析": "理解扫描文档和表格",
"代码生成": "根据图表生成代码",
"创意写作": "基于图像启发创作"
},
"技术特点": {
"架构": "基于GPT-4扩展视觉编码器",
"训练": "大规模多模态数据",
"安全性": "多层级内容审核"
}
} -
Gemini - 原生多模态设计
gemini_model_info = {
"开发方": "Google DeepMind",
"设计理念": "原生多模态,从底层支持多种模态",
"模型规模": ["Gemini Ultra", "Gemini Pro", "Gemini Nano"],
"模态支持": ["文本", "图像", "音频", "视频", "代码"],
"技术突破": {
"协同训练": "同时训练所有模态,而非后期融合",
"高效推理": "优化跨模态注意力机制",
"多尺度处理": "处理不同粒度的多模态信息"
},
"性能表现": {
"MMLU": "90.0% (超越人类专家)",
"图像理解": "在多个基准测试中领先",
"代码生成": "在HumanEval上达到顶级水平"
}
}
3.开源多模态模型
-
LLaVA - 开源多模态助手
llava_model_info = {
"全称": "Large Language and Vision Assistant",
"特点": "将预训练视觉编码器与LLM连接",
"训练数据": "GPT-4生成的视觉指令数据",
"版本演进": {
"LLaVA-1.5": "使用CLIP-ViT和Vicuna,在11个基准上达到SOTA",
"LLaVA-1.6": "改进的视觉编码器和训练配方"
},
"应用场景": [
"学术研究",
"低成本多模态应用",
"定制化开发基础"
]
} -
OpenFlamingo - 开源多模态对话
openflamingo_info = {
"基于": "CLIP视觉编码器 + LLaMA语言模型",
"特点": "支持交错的多模态输入(图像、文本交替)",
"能力": "视觉对话、推理、描述",
"训练": "大规模多模态网页数据",
"优势": "灵活的对话形式,强大的上下文学习"
}
4.视频生成模型
-
Sora - 文本到视频生成
sora_model_info = {
"开发方": "OpenAI",
"发布时间": "2024年2月",
"核心能力": "从文本生成高质量视频",
"视频参数": {
"长度": "最多60秒",
"分辨率": "1920x1080",
"连贯性": "保持物体在时间上的一致性"
},
"技术特点": {
"架构": "扩散Transformer",
"训练数据": "海量视频和图文数据",
"创新": "时空 patches 表示"
},
"应用前景": [
"影视制作",
"游戏开发",
"广告创意",
"教育内容"
]
} -
Runway、Pika等视频生成工具
video_generation_ecosystem = {
"Runway Gen-2": {
"类型": "商业视频生成平台",
"能力": "文本/图像到视频",
"特色": "运动控制、风格化"
},
"Pika Labs": {
"类型": "AI视频生成工具",
"优势": "用户友好,快速迭代",
"应用": "社交媒体内容创作"
},
"Stable Video Diffusion": {
"类型": "开源视频生成",
"基于": "Stable Diffusion",
"特点": "可定制性强"
}
}
多模态模型对比表格
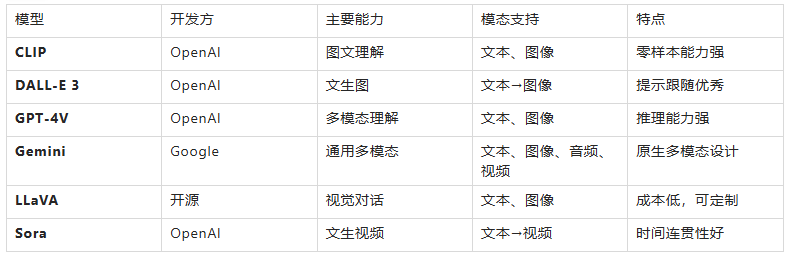
图文多模态模型
图文多模态模型是一种能够同时处理和理解文本与图像两种模态信息的人工智能模型。它使机器具备了类似人类的跨模态感知能力,可以理解图像内容并结合文字进行交互,例如回答关于图片的问题、根据文字描述生成图像或进行图文匹配等任务。
与只能处理单一文字信息的模型(如早期的ChatGPT)不同,图文多模态模型可以将视觉信息和语言信息关联起来,实现更自然、更丰富的交互方式。
这类模型的核心技术路径主要包括以下几种类型:
- 基于Transformer的架构:许多模型通过修改Transformer的注意力机制来融合图文特征。例如,ViLBERT引入了多模态共注意模块,LXMERT在跨注意力后加入全连接层并融合图文信息,VL-BERT将视觉区域特征与单词嵌入作为BERT的输入。
- 统一特征对齐:UNITER、ImageBERT等模型通过预训练任务(如掩码语言建模MLM、图文匹配ITM、区域特征回归MRFR等)学习图文在统一语义空间中的对齐表示,以提升跨模态理解能力。
- 轻量化与高效设计:ViLT模型将图像切分为块序列,与文本词序列通过可学习的模态类型嵌入进行区分,然后拼接输入Transformer,实现了高效的单流多模态编码。
- 基于扩散模型的生成:在图文生成领域,扩散模型(Diffusion Model)已成为主流技术,能够根据文本提示生成高质量图像。
1)Vision Transformer
Vision Transformer(ViT)是一种基于Transformer架构的深度学习模型,专为计算机视觉任务设计,通过自注意力机制处理图像数据,实现全局特征建模,广泛应用于图像分类、目标检测等领域。
基本原理和工作机制
ViT的核心是将图像转换为序列化Token进行处理,具体流程如下:
- 图像分块(Patch Embedding):将输入图像分割为固定大小的块(如16×16像素),每个块展平为向量并线性映射为低维特征。
- 位置编码(Positional Encoding):为每个块添加位置编码,保留空间信息,使模型理解图像结构。
- Transformer编码器处理:
- 自注意力机制计算块间关系,动态加权全局依赖(如远距离物体关联)。
- 多层堆叠的Transformer Block(含前馈网络)逐步提取特征。
- 分类输出:通过特殊分类Token(CLS)聚合全局信息,经MLP Head输出预测结果(如类别概率)。
2)图像文本联合建模
图文联合建模的本质,不只是"拼接"。
多模态大模型听起来高深,其实它的基本逻辑并不复杂------关键在于"连接"。想象一下,你看到一张狗的照片,大脑会先由视觉皮层提取轮廓、颜色、动作等特征,再交由语言区域组织成句子:"这是一只金毛犬正在追球。"多模态模型模仿的就是这个过程。
典型架构如 BLIP-2 或 Qwen-VL,通常包含三个核心组件:
- 视觉编码器(如 CLIP ViT-L/14):负责把图像转为向量序列;
- 连接模块(Q-Former、MLP Adapter 等):将视觉特征投影到语言模型的语义空间;
- 大语言模型(LLM):接收图文混合输入,完成推理与生成。
真正决定性能的,往往是那个不起眼的"连接器"。比如 Q-Former 使用一组可学习的查询向量(learnable queries),从 ViT 输出的 patch embeddings 中"蒸馏"出最相关的信息,再注入 LLM 的上下文。这种方式比简单的线性映射更能保留细粒度语义,但也增加了训练难度。
3)大规模图文对齐模型(CLIP)
CLIP(Contrastive Language--Image Pre-training)是由OpenAI在2021年提出的一种多模态机器学习模型。它旨在通过大量的文本-图像对进行训练,从而学会理解图像内容,并能将这些内容与相应的自然语言描述相匹配。CLIP的核心思想是利用对比学习(contrastive learning),这是一种无监督或弱监督的学习方法,通过最小化正样本之间的距离同时最大化负样本之间的距离来学习表示。
CLIP的工作原理
-
数据集:CLIP使用了大规模的互联网抓取数据,包括图像和它们相关的文本描述。这些数据集通常非常庞大,包含数十亿的样本,这有助于模型学习到广泛的概念和关联。
-
模型结构:CLIP实际上由两个部分组成------一个用于处理图像的视觉编码器和一个用于处理文本的语言编码器。这两个编码器分别将输入的图像和文本转换成固定长度的向量表示,这些向量位于同一高维空间中,使得图像和文本可以在这个空间中直接比较。
-
损失函数:CLIP使用了一个特殊的对比损失函数,该函数鼓励当图像和文本描述匹配时,它们的向量表示在高维空间中的距离更近;而不匹配的图像-文本对则距离更远。这种机制帮助模型学会了如何区分相关与不相关的图像-文本对。
方法
CLIP 由两个编码器组成:
- 图像编码器(Image Encoder):ResNet 或 Vision Transformer;
- 文本编码器(Text Encoder):CBOW 或 Transformer 结构。
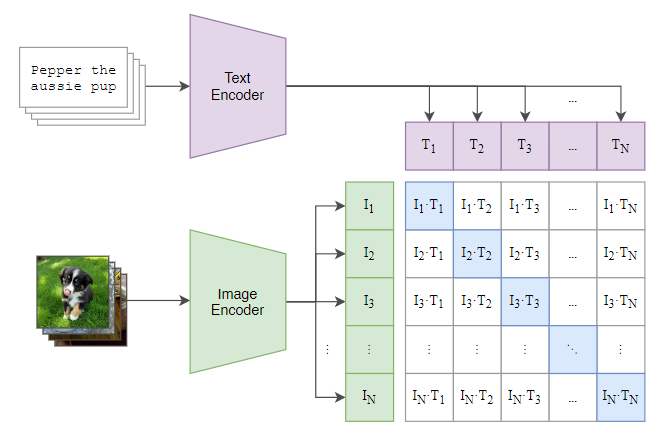
训练目标 :
在一个批次中,模型会看到 N 张图片与 N 段文字,它需要判断哪张图片与哪段文字配对。
通过计算每张图片与所有文字的相似度,可以得到一个 N×N 的相似度矩阵:理想情况下,对角线元素(i=j)最高,因为那是真正配对的图文。
模型通过对比学习(Contrastive Learning),让配对的图文嵌入在高维空间中靠近,不配对的远离,从而逼近理想情况。
4)多模态大语言模型
1)OpenAI GPT-4V
OpenAI GPT-4V(GPT-4 with Vision)是OpenAI于2023年9月正式发布的多模态语言模型,它是GPT-4的视觉增强版本,能够同时处理和理解文本与图像两种模态的信息。
核心功能与特点
- 图像理解能力:GPT-4V可以接收用户上传的图片,并结合文本提示(prompt)进行分析、回答问题或执行指令。其能力涵盖图像描述、OCR(光学字符识别)、图表解析、数学公式识别等。
- 多模态交互:作为OpenAI首个真正意义上的多模态大语言模型(MLLM),它标志着AI从纯文本交互迈向融合视觉与语言的新阶段,为智能助手、教育、医疗等领域开辟了新应用。
- API访问:该模型主要通过OpenAI API提供服务,允许开发者将其功能集成到自己的应用中。
2)Google Gemini
大模型Gemini是由谷歌DeepMind团队开发的多模态人工智能模型系列,旨在处理文本、图像、音频、视频和代码等多种类型的信息。
核心特点:
- 多模态原生设计:Gemini能够理解和融合不同形式的数据,例如分析图像内容、处理视频流或结合文本与代码进行推理。
- 长上下文处理:部分版本支持超长上下文窗口,例如Gemini 1.5 Pro可处理高达100万token的文本(约1500页文档),Gemini 2.5 Pro能分析长达3小时的视频内容。
- 复杂任务能力:在逻辑推理、编程辅助、数学问题解决等方面表现突出,例如Gemini Ultra在MMLU基准测试中达到人类专家水平。
关键能力:
- 复杂推理能力:可帮助理解复杂书面和视觉信息,发现海量数据中难以辨别的知识,能对数学和物理等复杂学科问题推理,可从数十万份文件中提取知识。
- 识别与理解能力:采用Transformer架构和高效Attention机制,可同时识别和理解文本、图像、音频等,Ultra版本无需OCR系统即可从图像中提取文本,能处理可变输入分辨率视频。
- 高级编码能力:可理解、解释和生成Python、Java、C++和Go等流行编程语言的高质量代码,能跨语言工作并推理复杂信息,可作为高级编码系统引擎。
- 安全能力:拥有全面安全性评估,包括偏差和病毒等,与外部专家合作压力测试确保内容安全,建立安全分类器识别和过滤有害内容。