随着本地大模型(LLM)在写作、问答、代码辅助等任务中越来越普及,将模型部署到本地成为很多开发者和内容创作者的需求。本文记录了我本地安装 Ollama 并部署 DeepSeek 模型的过程。
一、Ollama 与 DeepSeek 模型
Ollama:一款轻量、适配本地 LLM 的模型管理与推理工具,一键启动主流开源模型。
DeepSeek模型选择请根据自己的配置和需求选择合适的模型。"b" 是英文单词 "Billion"(十亿)的缩写,7b指的就是70亿个参数。
关于 Ollama 和 DeepSeek模型的更多介绍,我这里就不多赘述了。
二、安装 Ollama
推荐使用 Homebrew 安装 Ollama,因为这种方式易于管理、升级和卸载。
1. 安装 Homebrew
打开终端 (Terminal):
bash
brew --version如果显示版本号说明已安装;否则执行:
bash
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"2. 安装 Ollama
bash
brew install ollama安装完成后验证:
bash
ollama --version成功输出版本说明安装成功。

三、设置 Ollama 后台启动
为了方便后续调用和集成,建议将 Ollama 作为后台服务启动。
1) 启动 Ollama 服务
bash
brew services start ollama查看运行状态:
bash
brew services list默认 Ollama 服务监听地址是:
bash
http://localhost:11434四、下载 DeepSeek 模型
我这里选择的是8b模型。在终端执行:
bash
ollama run deepseek-r1:8b该命令将下载 DeepSeek-8B 模型并运行。
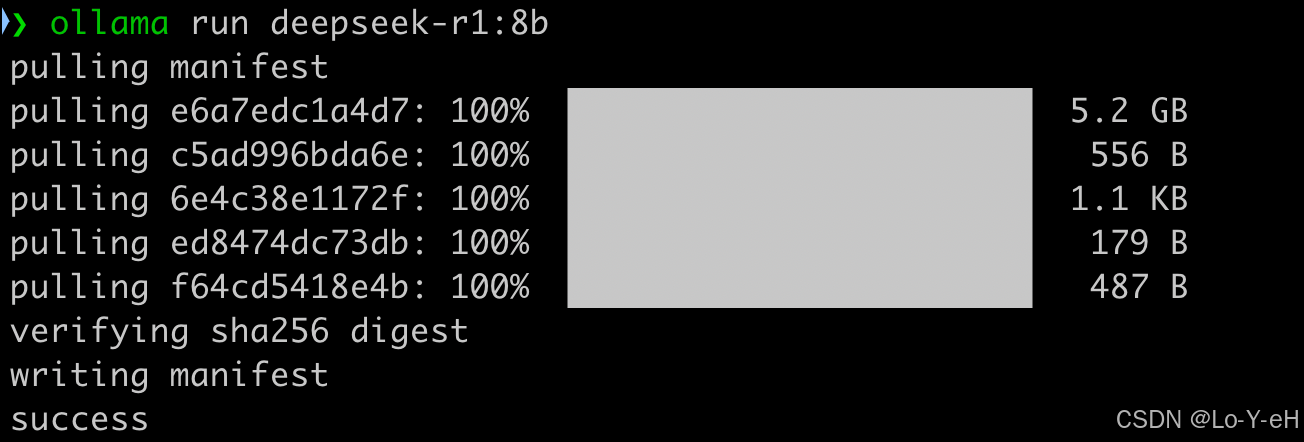
如果觉得模型响应慢,可以选择更轻量的 7B 模型。
bash
ollama run deepseek-r1:7b进入到模型交互界面

下载完成后可以执行:
bash
ollama list查看已下载的模型

五、命令行交互
在命令行界面进行对话:

测试一下代码编写:
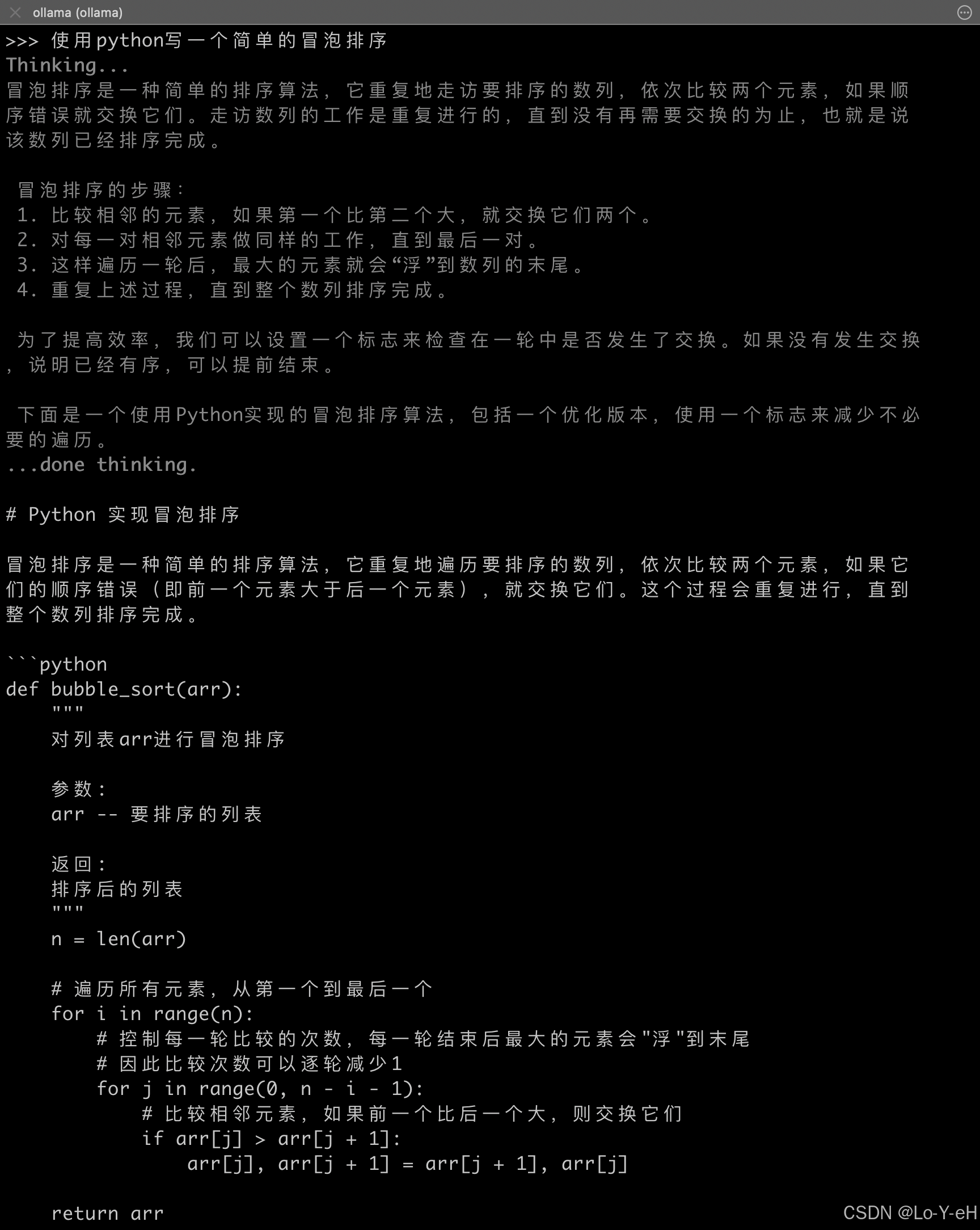
六、使用 Cherry Studio 交互
如果你更喜欢图形化交互,推荐使用 Cherry Studio 。Cherry Studio 本身不运行模型,它只是一个客户端。
真实结构是:
bash
Cherry Studio → Ollama(本地服务) → DeepSeek 模型只要 Cherry Studio 能连上 Ollama 的 11434 端口,就一定能用。
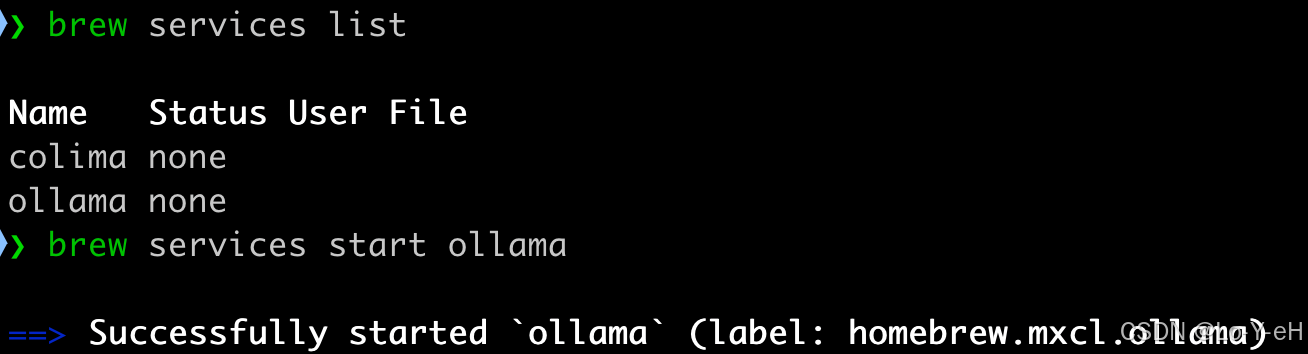
1. 确认 Ollama 正在运行
在终端执行:
bash
brew services list如果你看到类似:
ollama started说明已经是后台服务 ✅
如果没有,启动它:
bash
brew services start ollama比如我这里就没有启动,因为之前使用的是前台启动。
然后验证 Ollama 是否可访问
bash
curl http://localhost:11434
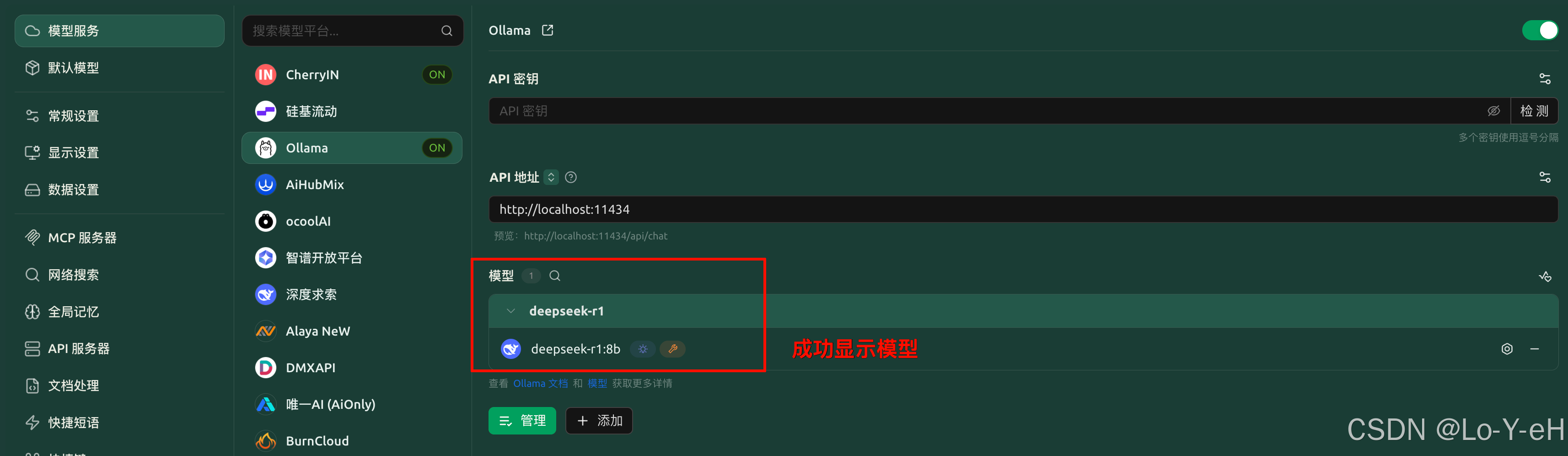
2. 配置 Cherry Studio
打开 Cherry Studio → 设置界面 → 模型服务 → ollama:可以看到url默认是 http://localhost:11434。
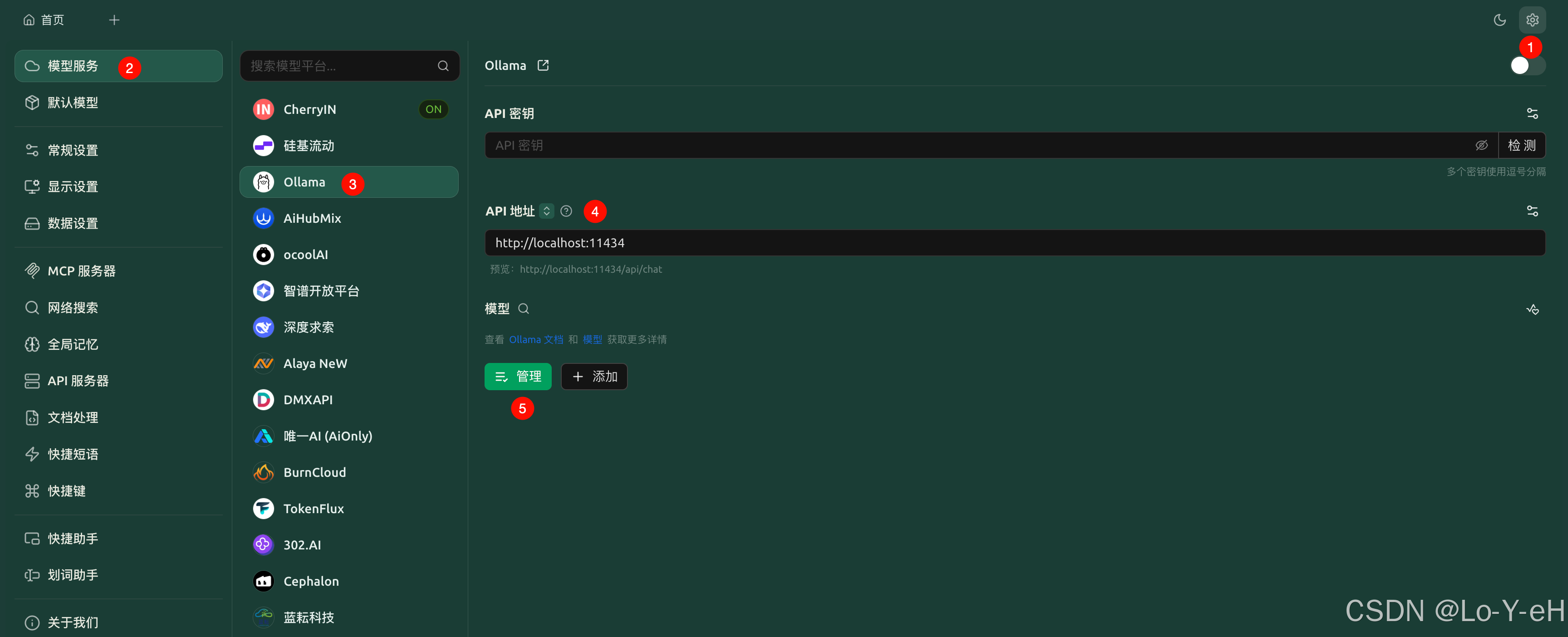
并且在管理中可以看到我们本地的 deepseek-r1:8b 模型
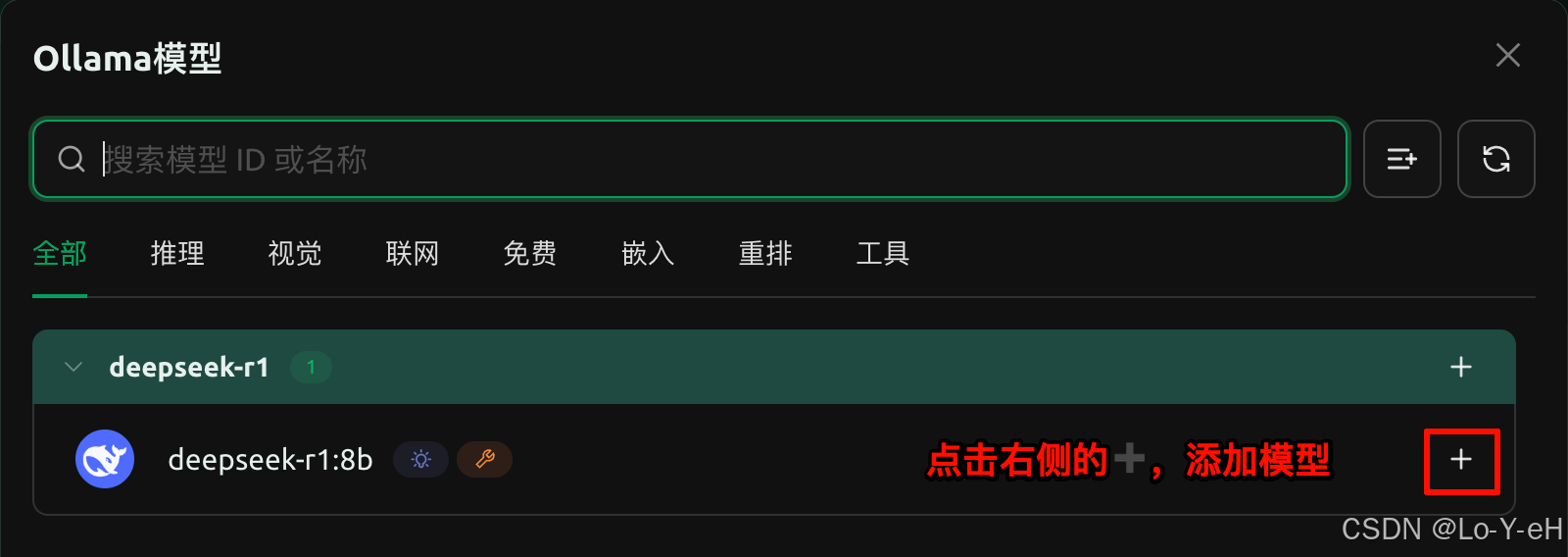
添加成功
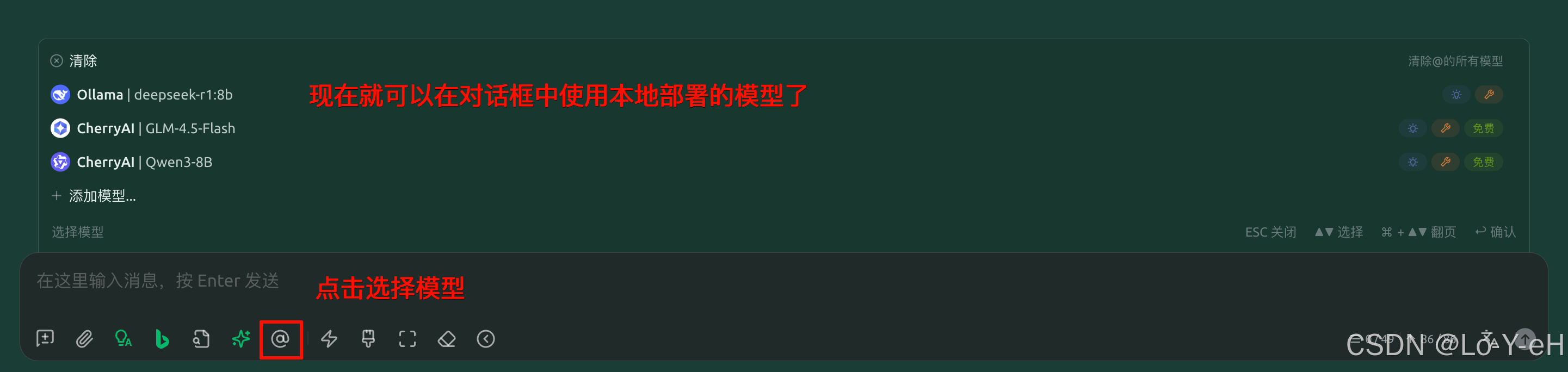
然后就可以在对话框处选择本地的模型了。
七、ollama常用命令
1、查看已下载模型:
bash
ollama list2、删除模型:
bash
ollama rm deepseek-r1:8b总结
通过本文你已经完成:
- 使用 Homebrew 安装 Ollama
- 配置并启动 Ollama 服务
- 下载并部署 DeepSeek-8B 模型
- 与 Cherry Studio 集成并通过 UI 调用
在本地部署模型不仅保护了隐私、提高了响应速度,还能摆脱对公网 API 的依赖,适合在本地的写作、问答和技术辅助任务。