一、双向循环链表详解
1.1 基本概念
双向循环链表是在双向链表的基础上,将首尾节点通过指针相连形成的环形结构。每个节点包含三个域:数据域、前驱指针(prev)和后继指针(next)。
1.2 主要操作与实现要点
创建与销毁
-
创建 :初始化头节点(或哨兵节点),使其
prev和next均指向自身。 -
销毁:遍历链表释放所有节点,注意避免内存泄漏。
插入操作
-
头插:在头节点后插入新节点,调整四个指针关系。
-
尾插:在尾节点后插入,由于循环结构,尾插可转换为在头节点前插入。
-
任意位置插入 :需定位插入位置的前后节点,谨慎调整
prev和next。
删除操作
- 定位待删除节点,修改其前驱节点的
next和后继节点的prev,最后释放节点内存。
遍历
-
可从任意节点出发,沿
next方向遍历,直到回到起始节点。 -
支持向前(
prev)和向后(next)两个方向的遍历。
1.3 与单向链表的对比
-
优势:
-
支持双向遍历,访问灵活性高。
-
删除指定节点时无需从头遍历寻找前驱。
-
-
劣势:
-
每个节点多一个指针,空间开销略大。
-
插入、删除时需维护更多指针关系。
-
1.4 应用场景
-
实现双向循环队列(Deque)。
-
操作系统中的进程调度块(如Linux内核链表)。
-
浏览器历史记录的前进与后退功能。
二、栈与队列的核心理解
2.1 栈(Stack)
基本特性
-
后进先出(LIFO)的线性结构。
-
操作仅允许在栈顶进行,包括入栈(Push)和出栈(Pop)。
栈的分类(基于增长方向与栈针指向)
| 类型 | 增长方向 | 栈针指向 | 特点 |
|---|---|---|---|
| 空增栈 | 向高地址增长 | 入栈位置 | 栈针指向下一个可写入位置 |
| 满增栈 | 向高地址增长 | 栈顶元素 | 栈针指向最后一个有效元素 |
| 空减栈 | 向低地址增长 | 入栈位置 | 同上,方向相反 |
| 满减栈 | 向低地址增长 | 栈顶元素 | 同上,方向相反 |
实现方式
-
顺序栈:基于数组实现,需预先分配连续内存。
-
链式栈:基于链表实现,动态分配节点,无容量限制。
2.2 队列(Queue)
基本特性
-
先进先出(FIFO)的线性结构。
-
插入在队尾进行,删除在队头进行。
实现方式
-
顺序队列:使用数组,需处理"假溢出"问题,常通过循环队列优化。
-
链式队列:使用链表,动态伸缩,无需担心容量限制。
2.3 栈、队列与普通线性表的对比
| 特性 | 栈 | 队列 | 普通线性表 |
|---|---|---|---|
| 插入位置 | 仅栈顶 | 仅队尾 | 任意 |
| 删除位置 | 仅栈顶 | 仅队头 | 任意 |
| 访问方式 | LIFO | FIFO | 随机访问(如数组)或顺序访问 |
| 典型应用 | 函数调用、表达式求值 | 任务调度、缓冲区管理 | 通用数据存储 |
2.4 栈与队列的应用实例
-
栈:
-
函数调用栈(保存返回地址、局部变量)。
-
括号匹配、表达式求值(中缀转后缀)。
-
浏览器的"后退"功能。
-
-
队列:
-
CPU任务调度(如就绪队列)。
-
消息队列、打印任务缓冲。
-
广度优先搜索(BFS)算法。
-
今日练习
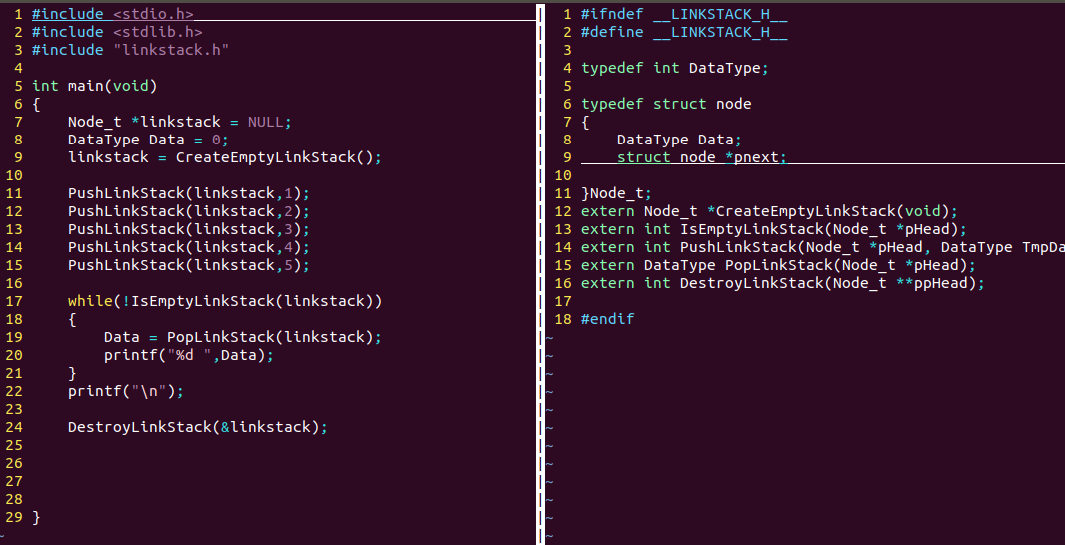
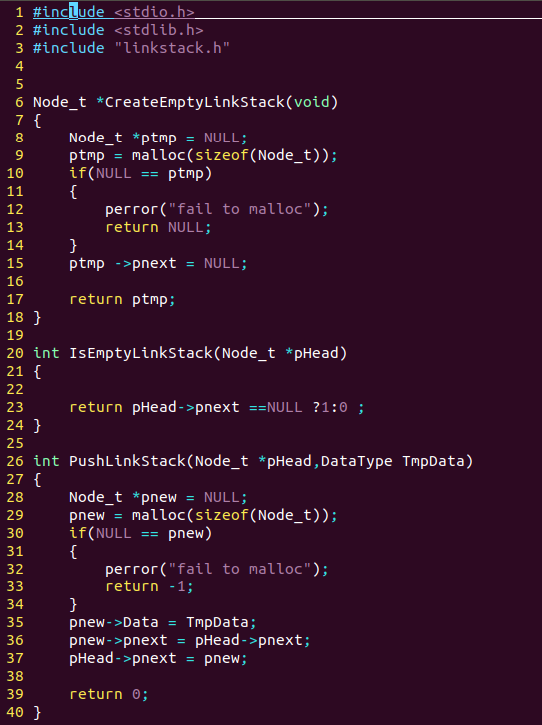
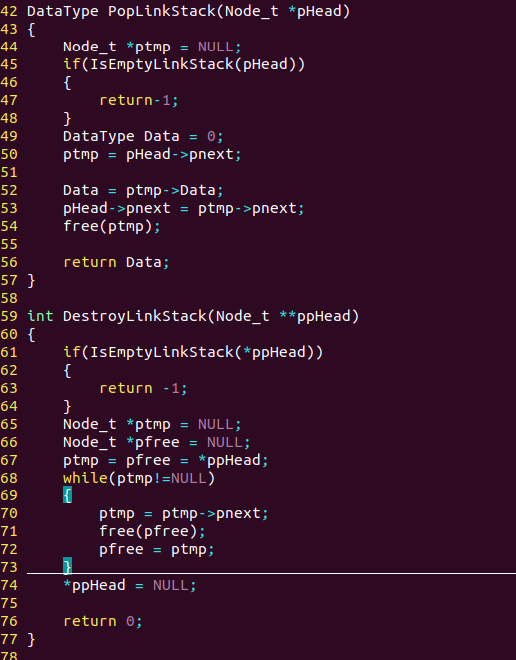
1.链式栈
Node_t *CreateEmptyLinkStack(void);
int IsEmptyLinkStack(Node_t *pHead);
int PushLinkStack(Node_t *pHead, DataType TmpData);
DataType PopLinkStack(Node_t *pHead);
int DestroyLinkStack(Node_t **ppHead);