论文详解 | HDAM:破解 MAUP 的城市出行需求分析新方法,实现关键驱动精准识别
研究核心背景
随着全球化与城市化的快速推进,城市人口激增、交通出行方式多元化,加之环境可持续发展的需求,精准分析城市出行需求成为城市规划、交通管理和环境政策制定的核心基础,其不仅关乎居民个体出行的便利性,更直接影响交通资源优化配置、城市运行效率提升、环境污染治理和居民生活质量改善。但城市交通系统具有动态性与复杂性,出行行为和需求受社会经济、城市空间结构、建成环境等多因素交互影响,精准识别出行需求的关键驱动因素成为制定有效交通政策的关键。
而当前出行需求分析的核心痛点,在于空间分析中固有的可修改面单元问题(MAUP) ,这一问题直接导致出行需求研究结果的准确性、可靠性和可推广性大打折扣。MAUP主要体现为尺度效应 和分区效应:尺度效应下,分析单元过细则易出现数据稀疏问题,无法捕捉出行需求的空间关联特征;单元过粗则会过度聚合数据,掩盖区域内的空间异质性,丢失关键细节。分区效应下,即便在同一尺度下,网格原点偏移、行政边界不同等差异化的边界划分方式,也会得出差异显著的出行需求分析结果。
此外,现有出行需求相关研究仍存在诸多不足:多数研究以行政边界、固定尺度网格为分析单元,对替代分析单元如何影响结果、如何从根源缓解MAUP缺乏深入探讨;部分基于路网、地理探测器确定最优网格尺度的方法,仍受限于网格框架的地理语义缺失、尺度固定问题;且现有研究多采用全域综合建模方式,对MAUP影响下出行热点的形成机制、真正驱动因素关注不足,同时缺乏统一的尺度选择标准,模型的普适性和可迁移性较差。在此背景下,亟需一种数据驱动的新方法,从源头重构分析单元,弱化MAUP的影响,实现出行需求关键驱动因素的精准识别。
核心创新方法:HDAM
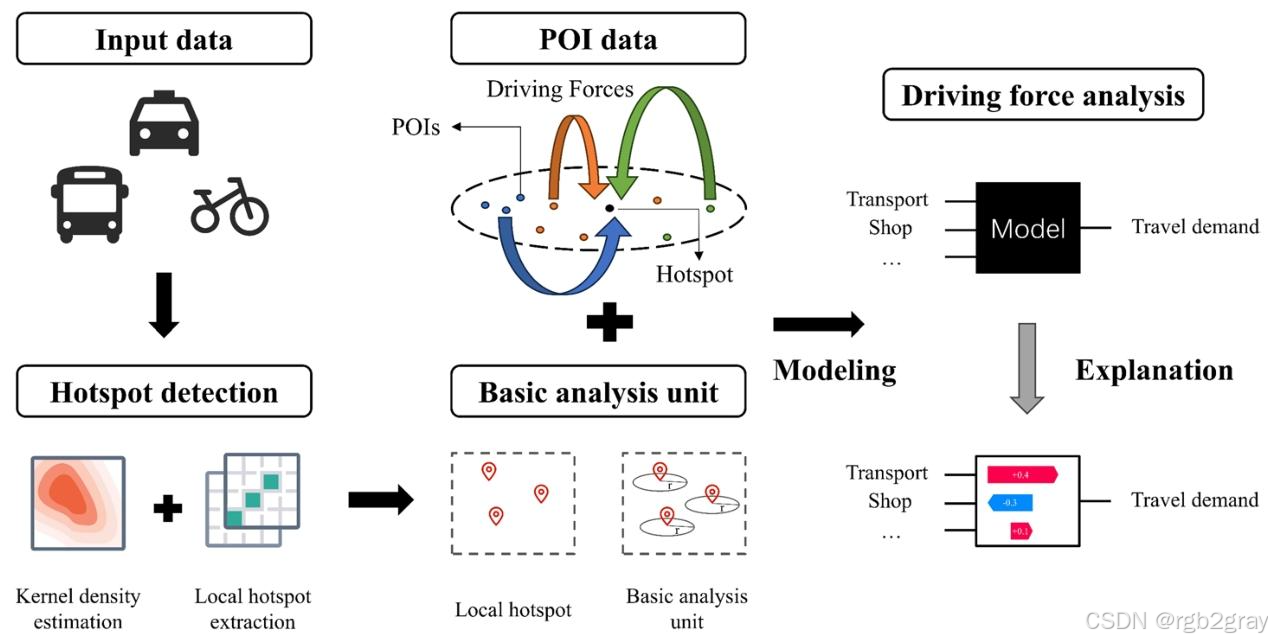
研究提出的基于热点检测的出行需求关键驱动分析方法(HDAM),以数据驱动为核心,摒弃传统全域分区的思路,从源头重构分析单元,结合热点检测、空间建模与可解释人工智能,构建了完整的出行需求分析框架,核心分为三步:
- 自适应出行热点检测 :针对城市多密度分布的出行数据,融合自适应核密度估计 与基于广度优先搜索(BFS)的局部热点提取算法实现精准热点识别。其中自适应核密度估计引入局部带宽调整系数,在出行密集区用小带宽捕捉精细特征,稀疏区用大带宽保证估计稳定性;局部热点提取算法通过峰值检测、密度连通区域扩展和唯一性验证,精准定位出行热点位置与强度,相比DBSCAN、HDBSCAN等经典密度聚类算法,该方法无噪声点、能识别更多热点且空间分布更集中。
- 构建热点导向的基础分析单元:以检测出的出行热点为中心,结合城市出行的步行距离特征,构建600m半径的缓冲带作为基础分析单元(哈尔滨实证中最优范围为500-700m),缓冲带的范围匹配出行热点的实际影响半径,解决了传统分析单元划分的主观性问题,同时对重叠的缓冲带进行多频次计数,精准评估POI对多个热点的贡献度。
- 融合XAI的驱动力分析 :整合城市13类POI数据(购物、餐饮、交通、教育文化等),采用OLS、决策树、随机森林、XGBoost等多种建模方法对比分析,选取表现最优的XGBoost模型建模,并引入SHAP值(沙普利加性解释) 这一可解释人工智能技术,量化各POI类型对出行需求的非线性贡献,破解了机器学习模型的"黑箱"问题,实现驱动因素的可解释性识别。
同时,研究在HDAM基础上提出分层建模方法,采用自然断点法将出行热点按强度分为低、中、高三级,分别探究不同强度层级下出行需求的关键驱动因素,进一步提升模型分析的精准度和针对性。
关键实证研究结果
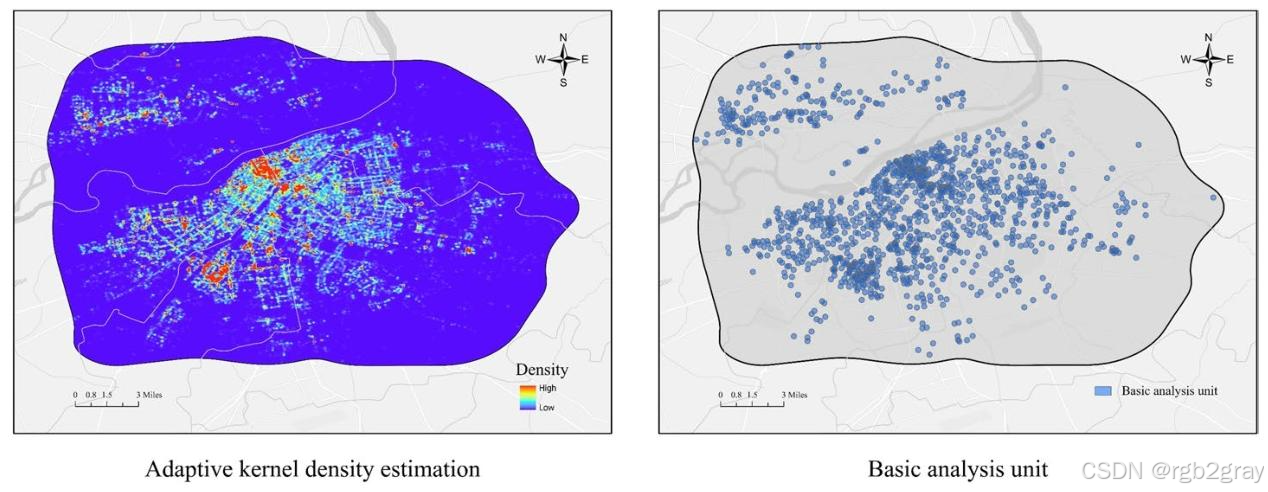
研究以哈尔滨绕城高速内的主城区为核心研究区,采用2024年4-5月的160余万条出租车订单数据和11.9万余条POI数据开展实证分析,同时以西安主城区为验证区完成跨城市普适性检验,核心结果如下:
- HDAM方法的有效性显著 :对比HDAM与交通分析区(TAZs)、Voronoi图、200m-2000m不同尺度网格等传统分区方法,HDAM在所有建模方法中均表现最优,其中XGBoost模型下 R 2 R^2 R2达0.79、RMSE为1257.9,远优于其他分区方法,有效捕捉了出行需求的空间异质性,弱化了MAUP的影响。
- 全域视角下的出行需求驱动特征 :哈尔滨出行热点的核心驱动因素为住宿服务和教育文化;交通服务、购物服务与出行需求呈显著正相关,生活服务、体育休闲、汽车服务呈负相关;多数POI类型存在明显的非线性特征,如教育文化设施存在"阈值效应"(数量超100个后边际效应递减),医疗、餐饮设施存在"集聚效应"(数量超150个才形成显著正向驱动),商业住宅、金融保险则存在"规模饱和效应"。而景区、企业对出行需求的驱动较弱,主要源于其数量少、分布在城市边缘,且与日常短途出行需求匹配度低。
- 分层视角下的驱动因素差异显著:低强度出行热点由住宿服务主导,反映该类区域的出行需求以满足基础居住、住宿需求为主;中、高强度热点则以购物服务为核心驱动,高强度热点中教育文化的驱动作用进一步凸显;交通服务的重要性在中等强度热点中显著下降,而生活服务在各强度层级中均保持稳定的驱动作用,体现了其作为基础配套的核心价值。
- 方法具有良好的跨城市普适性 :将HDAM应用于西安主城区,结合道路密度、土地利用混合熵、公交/地铁站点密度等变量建模,XGBoost模型下 R 2 R^2 R2达0.81,延续了在哈尔滨的优异表现,验证了HDAM在不同城市形态、社会经济特征和数据体系下的可迁移性和通用性。
研究的核心贡献与应用价值
- 方法论层面 :提出的HDAM方法以数据驱动重构分析单元,从源头有效弱化了MAUP对出行需求分析的影响,为空间分析领域解决该问题提供了新思路;同时构建的分层建模+XAI框架,既捕捉了出行热点的强度异质性,又实现了驱动因素的可解释性量化,提升了出行需求分析的精准度和科学性。
- 实践应用层面:为城市交通规划和管理提供了针对性的策略指导,如低强度出行区域需强化住宿、生活服务配套,中高强度区域应优化购物、教育文化设施的布局与管理,医疗、企业等设施需规划集聚布局以达到规模效应,才能有效驱动出行需求;同时HDAM可指导交通资源的精准配置,减少供需错配,助力城市交通的精细化治理。
- 技术拓展层面:HDAM框架可融合公交、共享单车、手机信令等多源出行数据,适配不同城市的分析需求,为城市出行热点的动态监测、出行需求的精准预测提供了技术支撑,推动城市交通系统向智能化、韧性化发展。
python
import numpy as np
import pandas as pd
import geopandas as gpd
from scipy.stats import gaussian_kde
from shapely.geometry import Point, Polygon
import matplotlib.pyplot as plt
# --------------------------
# 1. 数据预处理:加载出行数据(以出租车订单为例)
# --------------------------
def load_taxi_data(file_path):
"""
加载出租车订单数据,提取经纬度坐标
:param file_path: 数据文件路径(csv格式,包含lon, lat字段)
:return: 经纬度数组、GeoDataFrame
"""
df = pd.read_csv(file_path)
# 过滤异常值(经纬度范围示例:哈尔滨主城区)
df = df[(df['lon'] > 126.3) & (df['lon'] < 126.7) &
(df['lat'] > 45.7) & (df['lat'] < 46.0)]
coords = np.vstack([df['lon'], df['lat']])
gdf = gpd.GeoDataFrame(df, geometry=[Point(xy) for xy in zip(df['lon'], df['lat'])], crs='EPSG:4326')
return coords, gdf
# --------------------------
# 2. 自适应核密度估计(核心创新点)
# --------------------------
def adaptive_kde(coords, bandwidth_adjust=0.1):
"""
自适应核密度估计:根据局部数据密度调整带宽
:param coords: 经纬度坐标数组 (2, N)
:param bandwidth_adjust: 局部带宽调整系数
:return: kde模型、密度值数组
"""
# 基础KDE(全局带宽)
kde = gaussian_kde(coords)
global_bandwidth = kde.covariance_factor()
# 计算局部密度,用于调整带宽
densities = kde(coords)
# 归一化密度值(0-1)
norm_densities = (densities - densities.min()) / (densities.max() - densities.min())
# 自适应带宽:高密度区减小带宽,低密度区增大带宽
adaptive_bandwidths = global_bandwidth * (1 - bandwidth_adjust * norm_densities)
kde.set_bandwidth(adaptive_bandwidths.mean()) # 应用自适应带宽
# 生成网格并计算密度(用于可视化和热点提取)
lon_min, lon_max = coords[0].min(), coords[0].max()
lat_min, lat_max = coords[1].min(), coords[1].max()
lon_grid, lat_grid = np.meshgrid(np.linspace(lon_min, lon_max, 200),
np.linspace(lat_min, lat_max, 200))
grid_coords = np.vstack([lon_grid.ravel(), lat_grid.ravel()])
grid_densities = kde(grid_coords).reshape(lon_grid.shape)
return kde, grid_densities, lon_grid, lat_grid
# --------------------------
# 3. 基于BFS的热点提取(核心创新点)
# --------------------------
def extract_hotspots(grid_densities, lon_grid, lat_grid, threshold_percentile=95):
"""
基于广度优先搜索(BFS)提取出行热点
:param grid_densities: 网格密度值
:param lon_grid/lat_grid: 经纬度网格
:param threshold_percentile: 热点密度阈值(百分位数)
:return: 热点区域列表(每个热点为Polygon)
"""
# 确定密度阈值(取Top N%为热点)
density_threshold = np.percentile(grid_densities, threshold_percentile)
# 标记热点网格
hotspot_mask = grid_densities >= density_threshold
# BFS提取连通的热点区域
visited = np.zeros_like(hotspot_mask, dtype=bool)
hotspots = []
rows, cols = hotspot_mask.shape
directions = [(-1,0), (1,0), (0,-1), (0,1), (-1,-1), (-1,1), (1,-1), (1,1)] # 8邻域
for i in range(rows):
for j in range(cols):
if hotspot_mask[i,j] and not visited[i,j]:
# BFS初始化
queue = [(i,j)]
visited[i,j] = True
hotspot_cells = [(i,j)]
while queue:
x, y = queue.pop(0)
for dx, dy in directions:
nx, ny = x+dx, y+dy
if 0<=nx<rows and 0<=ny<cols and hotspot_mask[nx,ny] and not visited[nx,ny]:
visited[nx,ny] = True
queue.append((nx, ny))
hotspot_cells.append((nx, ny))
# 将热点网格转换为地理多边形
cell_coords = [(lon_grid[cell], lat_grid[cell]) for cell in hotspot_cells]
if len(cell_coords) > 3: # 过滤过小的热点
hotspot_polygon = Polygon(cell_coords)
hotspots.append(hotspot_polygon)
return hotspots, density_threshold
# --------------------------
# 4. 主函数:完整流程运行
# --------------------------
if __name__ == "__main__":
# 1. 加载数据(替换为你的数据路径)
# 数据格式示例:csv包含lon(经度), lat(纬度)列
coords, gdf = load_taxi_data("taxi_orders.csv")
# 2. 自适应核密度估计
kde, grid_densities, lon_grid, lat_grid = adaptive_kde(coords)
# 3. 提取热点
hotspots, threshold = extract_hotspots(grid_densities, lon_grid, lat_grid)
# 4. 可视化结果
plt.figure(figsize=(12, 8))
# 绘制密度热力图
plt.contourf(lon_grid, lat_grid, grid_densities, cmap='Reds', alpha=0.7)
plt.colorbar(label='出行密度')
# 绘制热点区域
for hotspot in hotspots:
x, y = hotspot.exterior.xy
plt.plot(x, y, 'k-', linewidth=2)
# 绘制原始订单点(抽样显示,避免密集)
sample_points = gdf.sample(1000)
plt.scatter(sample_points['lon'], sample_points['lat'], c='black', s=1, alpha=0.3)
plt.title("HDAM方法:城市出行热点检测结果", fontsize=14)
plt.xlabel("经度")
plt.ylabel("纬度")
plt.tight_layout()
plt.show()
# 输出结果统计
print(f"检测到出行热点数量:{len(hotspots)}")
print(f"热点密度阈值({95}百分位):{threshold:.6f}")