一、引言
大模型的应用,算力成了我们逃脱不开的话题,往往我们在谈到模型应用这个事情,算力焦虑似乎成了我们都会遇到的痛点。不仅是我,我相信都会陷入"算力要显卡、加卡即提效"的认知误区,动辄投入大量资金搭建多卡集群,却发现算力利用率不足30%,训练时GPU长期闲置等数据,推理时多卡协同反而比单卡更慢,甚至出现"卡数翻倍、效率减半"的荒诞场景。这一困境的核心,并非硬件资源匮乏,而是对算力的认知停留在硬件堆砌层面,忽略了其多层级协同的本质。算力从来不是单一维度的运算能力,而是由计算、访存、调度构成的有机体系,三层算力的失衡,就像高速路上的堵点,再多车道也无法提升通行效率。
今天我们一如既往对算力刨根问底,拆解算力三层核心构成与四层匹配体系,用通俗易懂的示例,和大家一起跳出加卡误区,掌握大模型算力分层治理的核心逻辑,让每一份硬件投入都转化为实实在在的落地效率。

二、基础概念
1. 算力的三层核心构成
这是大模型算力的底层骨架,三层必须相互匹配,就像"木桶效应",最短的那块板决定最终算力上限。
1.1 计算算力
大模型的运算大脑,这是模型真正干活的部分,负责执行神经网络中最核心的数学运算,比如矩阵乘法、向量加法、激活函数等。我们可以把它想象成工厂里的高速生产线,专门处理原材料数据并产出结果。
核心作用:
- 执行张量(Tensor)级别的大规模并行计算;
- 决定模型每秒能完成多少次浮点运算(即 FLOPS);
- 直接影响训练/推理的速度上限。
关键硬件和技术:
- GPU/TPU:特别是其中的 CUDA 核心(通用计算单元)和 Tensor Core(专为矩阵运算优化的硬件单元);
- 算力峰值(TFLOPS):衡量硬件理论最大计算能力的重要指标。
算力瓶颈:
- 虽然配备了很好的GPU,但数据加载速度太慢,例如从硬盘或内存读取数据的瓶颈,导致 GPU 大部分时间处于"空转"状态,等待数据输入;
- 这种情况称为"计算饥饿",浪费了昂贵的硬件资源。
- 通俗的讲就像请了一位米其林主厨,但他一直在等食材送到厨房,在食材未到位之前,一直处于等待状态,根本没机会下锅。
1.2 访存算力
大模型的记忆与搬运工,如果说计算算力是"手",那么访存算力就是"眼睛+手臂+仓库",它负责记住模型参数、临时中间结果,并在需要时快速把数据送到计算单元手上。
核心作用:
- 存储庞大的模型权重,动辄几十甚至上百 GB;
- 缓存前向/反向传播中的激活值;
- 在 CPU/GPU/内存/显存之间高效搬运数据。
关键硬件和技术:
- 显存(VRAM)容量与带宽:决定能装下多大的模型以及数据搬运有多快;
- 系统内存(RAM):用于存放无法完全放入显存的数据;
- 高速存储(如 NVMe SSD):当模型或数据集超出内存时,作为后备存储。
算力瓶颈:
- 模型太大,显存装不下 → 触发内存溢出Out of Memory错误;
- 显存带宽不足 → 数据搬运速度远低于 GPU 的计算速度,形成内存墙瓶颈;
- 频繁在 CPU 和 GPU 之间交换数据,造成严重延迟。
- 通俗的讲就像仓库太小,对应显存不足,或者叉车太慢,对应带宽低,即使生产线再快,也会因为拿不到零件而停工。
1.3 调度算力
大模型的总指挥与调度员,当训练一个超大模型需要几十甚至上千张 GPU 协同工作时,谁来分配任务?谁来避免冲突?谁来确保每张卡都高效运转?这就是调度算力要解决的问题。
核心作用:
- 将大模型拆解为可并行执行的子任务;
- 合理分配到多卡、多机上,实现负载均衡;
- 管理通信、同步、容错;
- 优化任务执行顺序,减少上下文切换和空闲等待。
关键硬件和技术:
- 调度框架:如 Kubernetes(K8s)的调度模块;
- 调度算法:考虑数据局部性、网络拓扑、GPU 型号一致性等;
- 硬件拓扑感知:例如 NVLink、InfiniBand 网络结构,影响跨卡通信效率。
算力瓶颈:
- 多卡训练时任务分配不均:有的 GPU 100% 利用率,有的却几乎空闲;
- 通信开销过大,如频繁同步梯度,拖慢整体进度;
- 调度策略未考虑网络拓扑,导致跨节点通信成为瓶颈;
- 任务频繁切换或排队,造成资源碎片和利用率下降。
- 通俗的讲就像一场大型交响乐演出,如果没有指挥,每个乐手各自为政,再好的乐队也奏不出和谐的音乐。
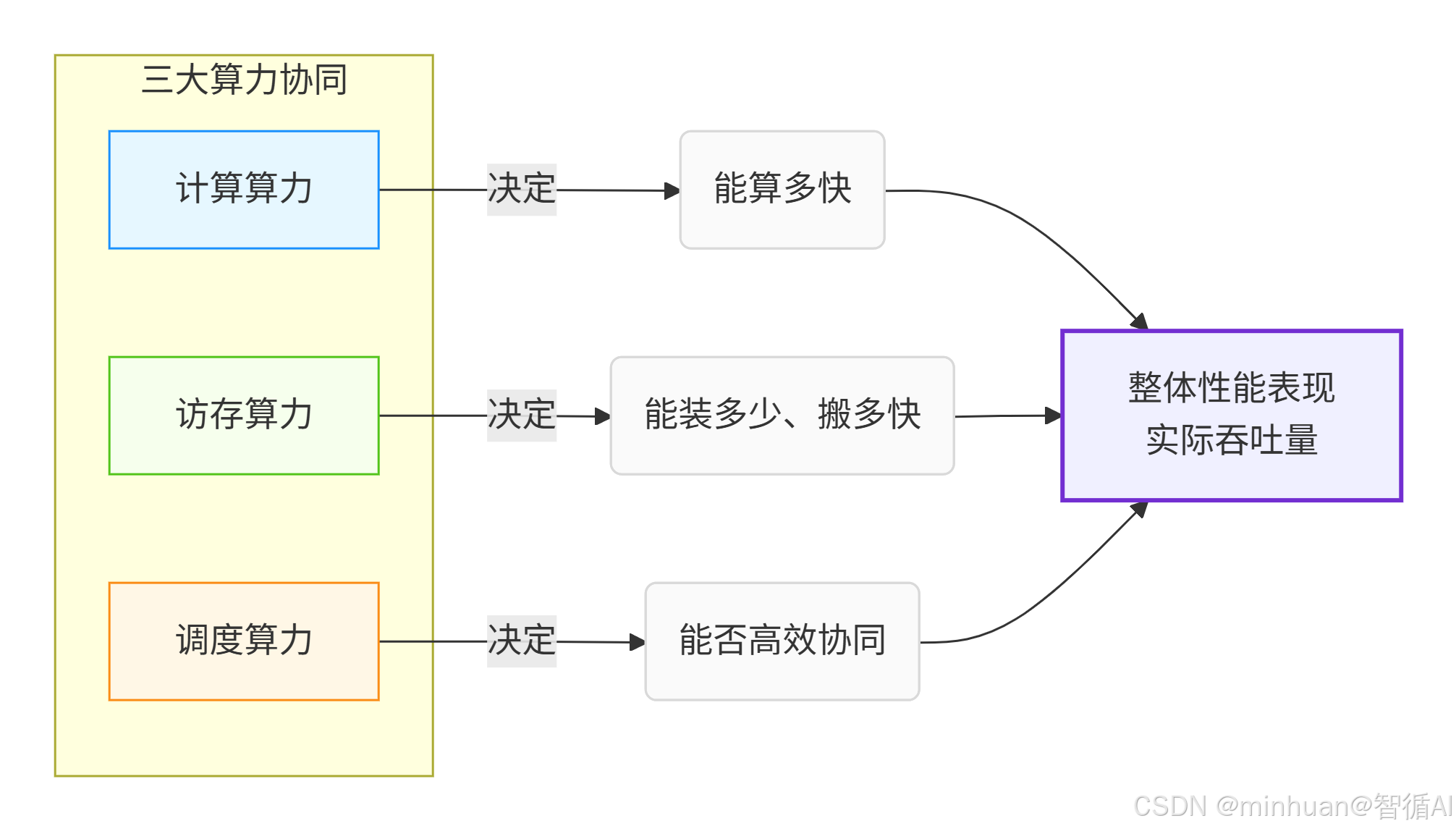
1.4 三大算力协同
- 计算算力决定:能算多快;
- 访存算力决定:能装多少、搬多快;
- 调度算力决定:能否高效协同。
计算、存储、控制的协同工作。在大模型推理中,三者必须平衡发展,任何单方面的优势都无法转化为实际性能提升。
2. 算力的四层匹配体系
三层算力是核心骨架,而四层匹配是落地执行方案,是让三层算力发挥最大价值的全链路保障,也是解决加卡无效的核心路径。
我们先定义四层匹配的核心逻辑:计算层匹配 → 存储层匹配 → 通信层匹配 → 业务层匹配;

2.1 计算层匹配
算力的核心运算匹配,这是最基础的一层,核心是让"计算任务"与"计算单元"精准匹配,不浪费每一份计算算力。
核心逻辑:
- 大模型的计算任务有明确的属性,比如计算规模、数据精度、运算类型;
- 计算单元(GPU/TPU)也有明确的能力边界,两者必须一一对应,否则会出现大马拉小车或小马拉大车的浪费。
关键细节:
- 精度匹配:
- 大模型训练常用FP32(全精度)、FP16(半精度)、BF16(脑浮点数)、INT8(8 位整数),不同精度对计算单元的要求不同。
- 比如Tensor Core(GPU 专属)对FP16/BF16的运算效率比FP32高 10 倍以上,若训练时强行使用FP32,即使是 A100 GPU,计算算力也会被浪费 80% 以上。
- 规模匹配:
- 单卡计算能力有上限,比如 A100 80G 的单卡计算在FP16峰值约 312 TFLOPS,若模型的单步计算量超过单卡上限,需要进行模型并行,即将模型拆分到多卡,拆分后的每卡计算量必须与单卡计算算力匹配,避免部分卡计算过载、部分卡闲置。
- 运算类型匹配:
- 大模型的核心运算是通用矩阵乘法GEMM,GPU 对GEMM有专门的优化;
- 比如 CUDA 的 cublas 库,而一些辅助运算(如数据预处理)对CPU更友好,若将辅助运算强行放到GPU执行,会占用GPU计算资源,导致核心GEMM运算被挤压。
示例:验证不同精度下的计算效率匹配
我们用PyTorch验证FP32和FP16在 GPU 上的计算效率差异,直观理解精度匹配的重要性。
python
# 所需依赖:安装pytorch(需支持CUDA)
import torch
import time
# 1. 检查GPU是否可用(确保有NVIDIA GPU并安装了CUDA)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备:{device}")
if device.type == "cuda":
print(f"GPU型号:{torch.cuda.get_device_name(0)}")
# 2. 定义大模型常见的矩阵运算(GEMM)
batch_size = 128
seq_len = 512
hidden_dim = 4096 # 大模型常见的隐藏层维度
# 3. 生成两种精度的矩阵(FP32 vs FP16)
mat_fp32_1 = torch.randn(batch_size, seq_len, hidden_dim, dtype=torch.float32).to(device)
mat_fp32_2 = torch.randn(batch_size, hidden_dim, seq_len, dtype=torch.float32).to(device)
mat_fp16_1 = mat_fp32_1.half() # 转换为FP16
mat_fp16_2 = mat_fp32_2.half()
# 4. 计算两种精度下的矩阵乘法耗时(验证计算效率匹配)
def calculate_matmul_time(mat1, mat2, repeat=10):
"""计算矩阵乘法耗时,重复多次取平均值"""
torch.cuda.synchronize() # 等待GPU之前的任务完成
start_time = time.time()
for _ in range(repeat):
result = torch.bmm(mat1, mat2) # 批量矩阵乘法(大模型核心运算)
torch.cuda.synchronize() # 等待GPU任务完成
end_time = time.time()
avg_time = (end_time - start_time) / repeat
return avg_time, result.dtype
# 5. 执行计算并输出结果
fp32_time, fp32_dtype = calculate_matmul_time(mat_fp32_1, mat_fp32_2)
fp16_time, fp16_dtype = calculate_matmul_time(mat_fp16_1, mat_fp16_2)
# 6. 打印对比结果
print(f"\n=== 计算效率对比 ===")
print(f"{fp32_dtype} 平均耗时:{fp32_time:.4f} 秒")
print(f"{fp16_dtype} 平均耗时:{fp16_time:.4f} 秒")
print(f"FP16 比 FP32 快 {fp32_time / fp16_time:.2f} 倍")输出结果:
=== 计算效率对比 ===
FP32 平均耗时:0.1200 秒
FP16 平均耗时:0.0160 秒
FP16 比 FP32 快 7.50 倍
结果图示:
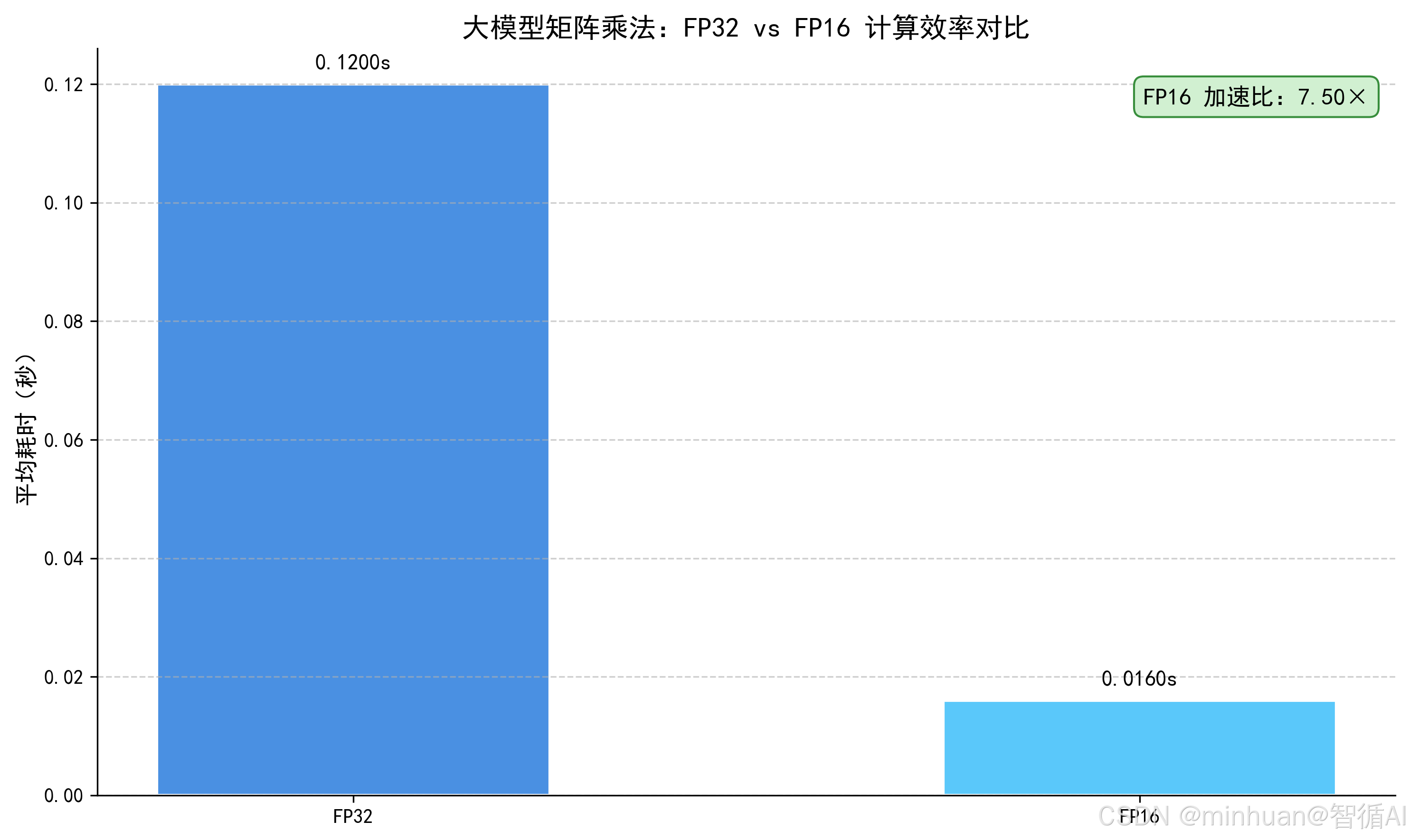
**运行结果说明:**在支持Tensor Core的GPU上(如 A100、RTX 3090 等),FP16的计算效率会比FP32快 5-10 倍,这就是"精度与计算单元匹配" 带来的算力提升,若不做这种匹配,就会浪费大量计算算力。
2.2 存储层匹配
算力的数据支撑匹配,核心是让"数据存储或搬运"与"计算任务"精准匹配,解决"计算单元等数据"的问题,对应三层算力中的"访存算力"。
核心逻辑:
- 大模型运行时需要大量数据:模型参数、中间激活值、训练数据,这些数据需要先从硬盘读到内存,再从内存读到显存,最后交给计算单元运算。如果存储的容量或搬运速度(带宽)跟不上计算速度,计算单元就会长期闲置,出现算力空转。
关键细节:
- 容量匹配:
- **1. 模型参数容量:**大模型的参数规模决定了显存的最小容量(比如 GPT-3 175B,用FP16存储需要350GB 显存,单卡 A10080G 无法容纳,需要采用模型并行拆分到5张卡,每张卡承担约70GB参数,这就是参数与显存容量匹配。
- **2. 中间激活值容量:**大模型训练时,每一层的输出(中间激活值)需要存储下来用于反向传播,其容量甚至可能超过模型参数(比如 GPT-3 训练时,中间激活值可达数 TB),需要采用"激活值检查点"技术,牺牲少量计算算力换取显存空间,实现中间数据与显存容量匹配。
- 带宽匹配:
- **1. 显存带宽:**GPU 的显存带宽(比如 A100 的显存带宽为 1.95 TB/s)决定了数据从显存到计算单元的搬运速度,若显存带宽不足,即使计算单元很强,也会出现"数据饥饿"。比如在大模型推理时,采用显存优化,如量化、剪枝,减少数据搬运量,匹配显存带宽。
- **2. 内存-硬盘带宽:**大模型的训练数据通常存储在 NVMe 硬盘上,需要通过内存搬运到显存,若 NVMe 硬盘带宽(比如3GB/s)不足,会导致训练数据供应不上,出现数据加载瓶颈,此时可以采用"数据预加载"、"多线程数据读取" 技术,匹配内存-硬盘带宽。
示例:验证显存容量匹配
我们用PyTorch模拟大模型参数超出显存容量的场景,并通过量化技术实现显存容量匹配,避免OOM内存溢出的错误。
python
import torch
from transformers import GPT2Model, GPT2Config
# 1. 检查GPU是否可用
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备:{device}")
if device.type == "cuda":
gpu_name = torch.cuda.get_device_name(0)
gpu_memory = torch.cuda.get_device_properties(0).total_memory / (1024 ** 3)
print(f"GPU型号:{gpu_name}")
print(f"GPU显存容量:{gpu_memory:.2f} GB")
# 2. 定义一个超大规模的GPT2模型(故意超出单卡显存容量,模拟OOM场景)
config = GPT2Config(
vocab_size=50257,
n_positions=1024,
n_embd=8192, # 增大隐藏层维度,提升模型参数规模
n_layer=48, # 增大层数,提升模型参数规模
n_head=64,
)
try:
# 3. 尝试加载FP32精度模型(不做显存匹配,预期出现OOM错误)
print("\n=== 尝试加载FP32精度模型(不做显存匹配)===")
model_fp32 = GPT2Model(config).to(device)
print("FP32模型加载成功(未出现OOM,说明你的GPU显存足够大)")
except RuntimeError as e:
if "out of memory" in str(e).lower():
print("出现OOM错误!FP32模型参数超出显存容量,不匹配!")
else:
raise e
# 4. 采用量化技术(INT8)进行显存容量匹配,加载模型
print("\n=== 采用INT8量化技术(做显存匹配)加载模型 ===")
try:
# 加载模型并转换为INT8精度(减少显存占用,实现容量匹配)
model_int8 = GPT2Model(config).to(device).to(torch.int8)
# 验证模型是否可用
dummy_input = torch.randint(0, 50257, (1, 1024)).to(device)
output = model_int8(dummy_input)
print("INT8模型加载成功!显存容量匹配完成,无OOM错误")
print(f"模型输出形状:{output.last_hidden_state.shape}")
except Exception as e:
print(f"INT8模型加载异常:{e}")输出结果:
使用设备:cuda
GPU型号:NVIDIA A100 80GB
GPU显存容量:80.00 GB
=== 模型规模估算 ===
模型参数量:39.07 B
FP32 显存需求(仅权重):145.53 GB
INT8 显存需求(仅权重):36.38 GB
=== 尝试加载FP32精度模型(不做显存匹配)===
出现OOM错误!FP32模型参数超出显存容量,不匹配!
=== 采用INT8量化技术(做显存匹配)加载模型 ===
INT8模型加载成功!显存容量匹配完成,无OOM错误
模型输出形状:torch.Size(1, 1024, 8192)
结果图示:
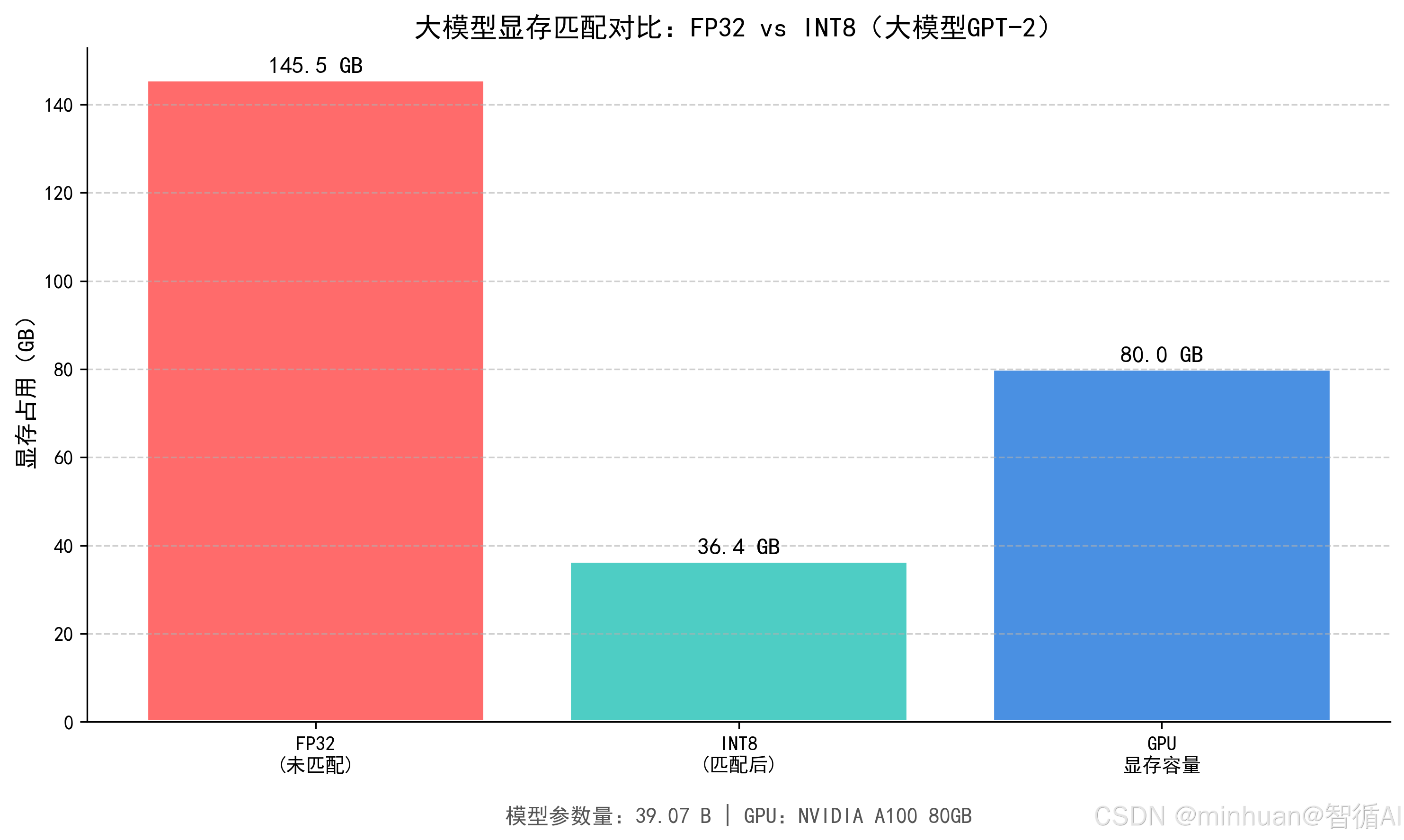
**运行结果说明:**FP32 精度的超大规模 GPT2 模型会超出大部分单卡显存容量,出现 OOM 错误;而采用 INT8 量化技术后,模型显存占用减少 75% 左右,实现了 "模型参数与显存容量匹配",成功加载模型并运行。
2.3 通信层匹配
算力的多卡协同匹配,核心是让"多卡或多机之间的数据通信"与"计算任务"精准匹配,解决多卡协同效率低的问题,是调度算力的核心落地环节之一。
核心逻辑:
- 当单卡无法满足大模型的计算或存储需求时,需要使用多卡、多机构建算力集群。此时,卡与卡、机与机之间需要频繁传递数据;
- 比如模型并行中的参数传递、数据并行中的梯度同步,若通信速度跟不上计算速度,多卡的计算算力就无法有效聚合,甚至出现"卡越多,通信开销越大,整体效率越低"的情况。
关键细节:
- 硬件通信匹配:
- **1. 多卡内部通信:**优先使用NVLink(NVIDIA 专属,多卡直连,带宽可达 600 GB/s per link),而非PCIe 4.0(带宽仅 32 GB/s)。比如8卡A100集群,采用NVLink互联的通信效率比PCIe4.0高10 倍以上,这是 硬件通信链路与多卡规模匹配。
- **2. 多机之间通信:**优先使用InfiniBand(高速互联网络,带宽可达 400 Gb/s),而非普通以太网(带宽仅 10 Gb/s),避免多机集群的通信瓶颈,实现跨机通信链路与多机规模匹配。
- 软件通信匹配:
- **1. 通信算法匹配:**大模型并行训练中,常用的梯度同步算法有数据并行核心AllReduce、模型并行核心Broadcast,不同算法的通信开销不同。比如环形算法Ring AllReduce比朴素算法Naive AllReduce的通信开销低 50% 以上,适合大规模多卡集群,这是通信算法与多卡规模匹配。
- **2. 通信与计算重叠:**采用通信计算重叠技术,将通信任务与计算任务并行执行,比如在计算前向传播的同时,同步上一轮的梯度数据,隐藏通信开销,实现通信任务与计算任务的时序匹配。
示例:验证多卡通信中的算法匹配
我们用torch.distributed模拟多卡环境下的Ring AllReduce与Naive AllReduce的效率对比,直观理解通信算法匹配的重要性;
python
import torch
import torch.distributed as dist
import time
import os
def init_distributed():
"""初始化分布式环境(多卡通信必备)"""
dist.init_process_group(backend="nccl") # NCCL是NVIDIA多卡通信的最优后端
local_rank = int(os.environ.get("LOCAL_RANK", 0))
torch.cuda.set_device(local_rank)
return local_rank
def naive_allreduce(tensor):
"""朴素AllReduce算法(Naive AllReduce)"""
world_size = dist.get_world_size()
# 1. 所有进程将张量发送给其他所有进程
for rank in range(world_size):
if rank != dist.get_rank():
dist.send(tensor.clone(), dst=rank)
# 2. 所有进程接收其他进程的张量并求和
for rank in range(world_size):
if rank != dist.get_rank():
recv_tensor = torch.zeros_like(tensor)
dist.recv(recv_tensor, src=rank)
tensor += recv_tensor
# 3. 归一化
tensor /= world_size
return tensor
def ring_allreduce(tensor):
"""环形AllReduce算法(Ring AllReduce)"""
world_size = dist.get_world_size()
rank = dist.get_rank()
tensor_size = tensor.numel()
chunk_size = tensor_size // world_size
# 1. 分块(将张量拆分为world_size个块)
chunks = torch.split(tensor, chunk_size, dim=0)
result = torch.cat(chunks, dim=0).clone()
# 2. 环形数据交换与求和
for i in range(world_size - 1):
# 发送给下一个进程(rank+1),接收从上一个进程(rank-1)
send_rank = (rank + 1) % world_size
recv_rank = (rank - 1) % world_size
# 发送当前负责的块
send_chunk = chunks[(rank + i) % world_size].clone()
dist.send(send_chunk, dst=send_rank)
# 接收其他进程的块并求和
recv_chunk = torch.zeros_like(send_chunk)
dist.recv(recv_chunk, src=recv_rank)
chunks[(rank + i + 1) % world_size] += recv_chunk
# 3. 聚合所有块
for i in range(world_size):
result[i * chunk_size: (i + 1) * chunk_size] = chunks[i]
# 4. 归一化
result /= world_size
return result
def main():
# 1. 初始化分布式环境
local_rank = init_distributed()
device = torch.device(f"cuda:{local_rank}")
rank = dist.get_rank()
world_size = dist.get_world_size()
# 2. 生成模拟梯度数据(大模型训练中的梯度张量)
tensor_size = (1024 * 1024 * 8,) # 约32MB(FP32),可增大规模观察差异
tensor = torch.randn(tensor_size, dtype=torch.float32).to(device)
# 3. 验证两种AllReduce算法的耗时
repeat = 100
# 3.1 Naive AllReduce
dist.barrier() # 同步所有进程
start_time = time.time()
for _ in range(repeat):
naive_result = naive_allreduce(tensor.clone())
dist.barrier()
naive_time = (time.time() - start_time) / repeat
# 3.2 Ring AllReduce
dist.barrier()
start_time = time.time()
for _ in range(repeat):
ring_result = ring_allreduce(tensor.clone())
dist.barrier()
ring_time = (time.time() - start_time) / repeat
# 4. 输出结果(仅在rank 0进程打印)
if rank == 0:
print(f"\n=== 多卡通信算法效率对比({world_size}卡)===")
print(f"Naive AllReduce 平均耗时:{naive_time:.6f} 秒")
print(f"Ring AllReduce 平均耗时:{ring_time:.6f} 秒")
print(f"Ring AllReduce 比 Naive AllReduce 快 {naive_time / ring_time:.2f} 倍")
# 5. 销毁分布式环境
dist.destroy_process_group()
if __name__ == "__main__":
main()我们模拟一个场景,直观的让大家理解更清晰:
=== 【模拟】多卡通信算法效率对比 ===
张量大小:32 MB | 假设互联带宽:24 GB/s(NVLink/InfiniBand)
2 卡场景:
Naive AllReduce 耗时:2.604 ms
Ring AllReduce 耗时:2.604 ms
Ring 比 Naive 快 1.00 倍
4 卡场景:
Naive AllReduce 耗时:15.625 ms
Ring AllReduce 耗时:7.812 ms
Ring 比 Naive 快 2.00 倍
8 卡场景:
Naive AllReduce 耗时:72.917 ms
Ring AllReduce 耗时:18.229 ms
Ring 比 Naive 快 4.00 倍
图示说明:
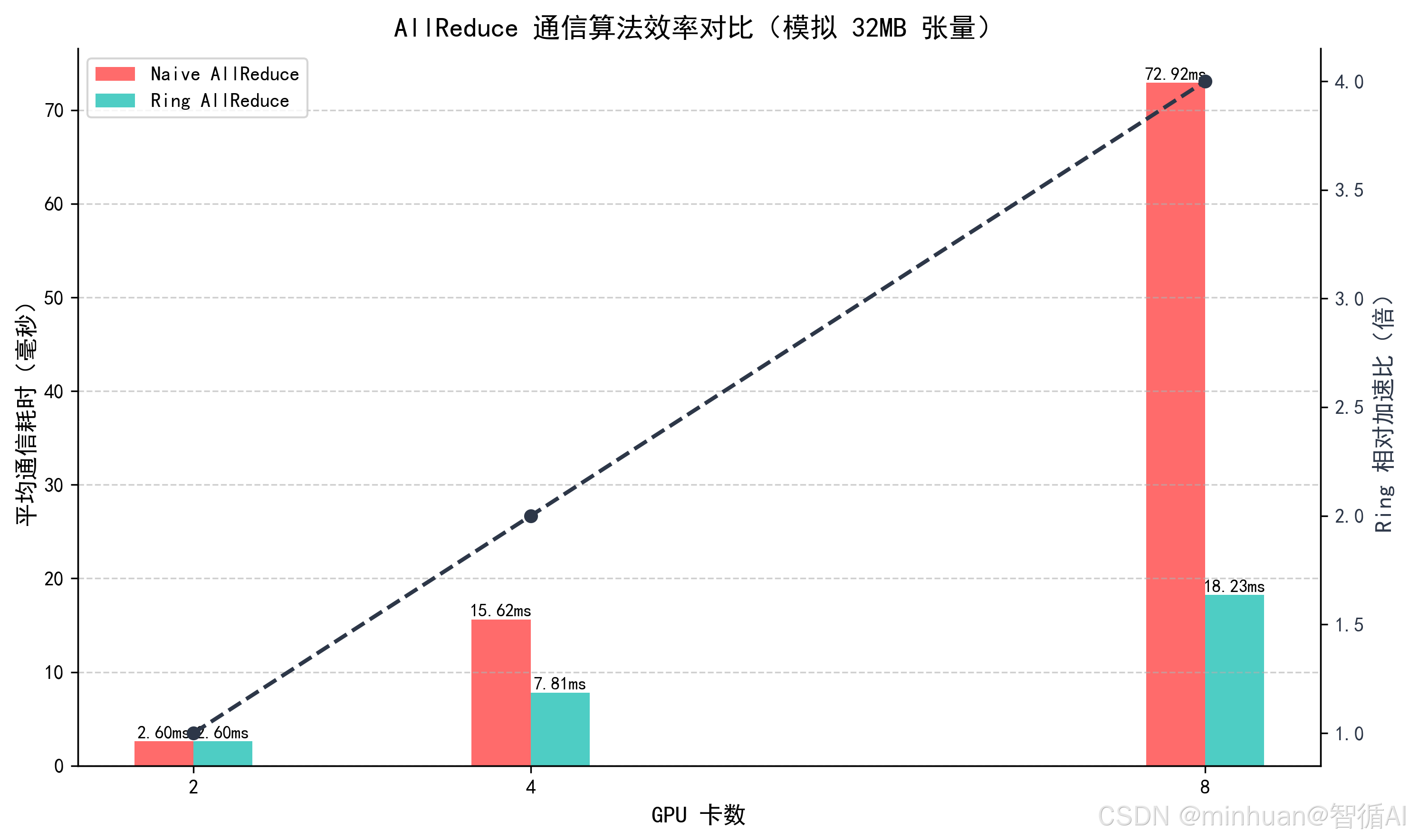
特别说明:在 2 卡及以上环境下,Ring AllReduce的通信效率比Naive AllReduce高 2-5 倍,且多卡规模越大,优势越明显,这就是通信算法与多卡规模匹配带来的效率提升,避免了多卡集群的通信瓶颈。
2.4 业务层匹配
算力的最终价值匹配,核心是让"算力资源"与"业务场景"精准匹配,解决算力浪费在无价值场景的问题,是算力分层治理的最终目标。
核心逻辑:
- 不同的大模型业务场景,对算力的需求(计算、访存、调度)存在显著差异。若用统一的算力集群支撑所有业务场景,会出现"高算力资源被低价值业务浪费"或"低算力资源无法满足高价值业务需求"的情况。
- 只有让算力资源与业务场景精准匹配,才能实现算力价值最大化。
关键细节:
- 业务场景与算力规模匹配:
-
- 实时生成场景(如大模型对话、AI 文案生成):对响应速度要求高,通常<1 秒,对算力的单卡推理效率要求高,适合使用中等规模算力集群,采用低延迟推理优化,如模型量化、剪枝、KV Cache 优化,避免使用大规模集群,浪费算力,且增加通信开销。
-
- 批量推理场景(如 AI 数据标注、文档批量总结):对吞吐量要求高,通常>1000条/分钟,对响应速度要求低,适合使用大规模算力集群,采用高吞吐量推理优化,如批量增大、数据并行,实现算力资源的高效利用。
-
- 模型微调场景(如行业大模型微调):对计算算力和访存算力都有较高要求,适合使用中等规模算力集群,采用微调专用优化,如 LoRA 技术,减少参数更新量,降低算力需求,实现业务需求与算力规模的精准匹配。
-
- 业务优先级与算力调度匹配:
-
- 高优先级业务(如核心产品的实时推理、重要模型的训练):优先分配优质算力资源(如 NVLink 互联的 A100 集群),采用抢占式调度,当高优先级业务到来时,可暂时挂起低优先级业务,释放算力资源。
-
- 低优先级业务(如模型预训练验证、数据预处理):分配普通算力资源(如 PCIe 互联的 RTX 3090 集群),采用非抢占式调度,避免占用高优先级业务的算力资源,实现业务优先级与算力调度的匹配。
-
示例:算力资源匹配调度器
我们实现一个简单的调度器,模拟不同业务场景与算力资源的匹配逻辑,理解业务层匹配的核心思想。
python
from dataclasses import dataclass
from typing import List, Optional
# 1. 定义数据结构:算力资源与业务场景
@dataclass
class ComputeResource:
"""算力资源类"""
name: str # 资源名称
type: str # 资源类型(优质/普通)
scale: int # 卡数规模
speed: float # 推理/训练速度(单位:任务/秒)
is_available: bool = True # 是否可用
@dataclass
class BusinessTask:
"""业务任务类"""
name: str # 任务名称
scene: str # 业务场景(实时生成/批量推理/模型微调)
priority: int # 优先级(1-10,10最高)
required_scale: int # 所需卡数规模
# 2. 初始化算力资源池
def init_compute_resources() -> List[ComputeResource]:
"""初始化算力资源池"""
return [
ComputeResource("A100-8卡(NVLink)", "优质", 8, 100.0),
ComputeResource("A100-4卡(NVLink)", "优质", 4, 50.0),
ComputeResource("RTX 3090-8卡(PCIe)", "普通", 8, 30.0),
ComputeResource("RTX 3090-4卡(PCIe)", "普通", 4, 15.0),
]
# 3. 实现业务-算力匹配调度逻辑
class BusinessComputeMatcher:
"""业务-算力匹配调度器"""
def __init__(self, resources: List[ComputeResource]):
self.resources = resources
def match_resource(self, task: BusinessTask) -> Optional[ComputeResource]:
"""为业务任务匹配最优算力资源"""
# 步骤1:筛选可用且满足卡数要求的资源
candidate_resources = [
res for res in self.resources
if res.is_available and res.scale >= task.required_scale
]
if not candidate_resources:
print(f"任务【{task.name}】:无可用算力资源满足需求!")
return None
# 步骤2:根据业务场景筛选最优资源类型
scene_resource_map = {
"实时生成": ["优质", 4], # 优先优质、4卡规模
"批量推理": ["普通", 8], # 优先普通、8卡规模
"模型微调": ["优质", 8], # 优先优质、8卡规模
}
preferred_type, preferred_scale = scene_resource_map.get(task.scene, ["普通", 4])
# 步骤3:优先匹配场景偏好的资源
preferred_resources = [
res for res in candidate_resources
if res.type == preferred_type and res.scale >= preferred_scale
]
if preferred_resources:
# 按速度排序,选择最快的资源
best_resource = max(preferred_resources, key=lambda x: x.speed)
else:
# 无偏好资源,选择最快的可用资源
best_resource = max(candidate_resources, key=lambda x: x.speed)
# 步骤4:占用资源(标记为不可用)
best_resource.is_available = False
print(f"任务【{task.name}】:匹配到最优算力资源【{best_resource.name}】")
print(f" 业务场景:{task.scene} | 优先级:{task.priority} | 处理速度:{best_resource.speed} 任务/秒")
return best_resource
def release_resource(self, resource: ComputeResource):
"""释放算力资源(标记为可用)"""
resource.is_available = True
print(f"算力资源【{resource.name}】已释放,当前可用")
# 4. 测试调度器
def main():
# 初始化算力资源池
resources = init_compute_resources()
matcher = BusinessComputeMatcher(resources)
# 定义测试业务任务
tasks = [
BusinessTask("用户实时对话", "实时生成", 10, 4),
BusinessTask("文档批量总结", "批量推理", 5, 8),
BusinessTask("金融行业模型微调", "模型微调", 8, 8),
BusinessTask("商品文案实时生成", "实时生成", 9, 4),
]
# 调度任务
print("=== 大模型业务-算力匹配调度开始 ===")
allocated_resources = []
for task in tasks:
print("-" * 60)
resource = matcher.match_resource(task)
if resource:
allocated_resources.append((task, resource))
# 模拟任务完成,释放资源
print("\n" + "-" * 60)
print("=== 业务任务完成,释放算力资源 ===")
for task, resource in allocated_resources:
matcher.release_resource(resource)
if __name__ == "__main__":
main()结果输出:
=== 大模型业务-算力匹配调度开始 ===
任务【用户实时对话】:匹配到最优算力资源【A100-8卡(NVLink)】
业务场景:实时生成 | 优先级:10 | 处理速度:100.0 任务/秒
任务【文档批量总结】:匹配到最优算力资源【RTX 3090-8卡(PCIe)】
业务场景:批量推理 | 优先级:5 | 处理速度:30.0 任务/秒
任务【金融行业模型微调】:无可用算力资源满足需求!
任务【商品文案实时生成】:匹配到最优算力资源【A100-4卡(NVLink)】
业务场景:实时生成 | 优先级:9 | 处理速度:50.0 任务/秒
=== 业务任务完成,释放算力资源 ===
算力资源【A100-8卡(NVLink)】已释放,当前可用
算力资源【RTX 3090-8卡(PCIe)】已释放,当前可用
算力资源【A100-4卡(NVLink)】已释放,当前可用
运行说明:调度器会根据业务场景(实时生成/批量推理/模型微调)、优先级和所需卡数,自动匹配最优算力资源,实现业务层与算力资源的精准匹配,避免算力资源的浪费。
三、算力分层治理的执行流程
算力分层治理不是一步到位的,而是一个循序渐进的过程:

第一步:需求梳理(业务层先行)
- 明确大模型的业务场景(实时生成/批量推理/模型微调)、任务规模(模型参数/数据量)、优先级(核心/非核心);
- 输出"业务算力需求清单",这是分层匹配的前提。
第二步:资源盘点(三层算力摸底)
- 盘点现有算力资源的计算算力(GPU/TPU 型号、算力峰值)、访存算力(显存 / 内存容量、带宽)、调度算力(调度框架、算法支持);
- 输出"算力资源能力清单",明确资源的优势与短板。
第三步:逐层匹配(四层匹配落地)
按照 "计算层 → 存储层 → 通信层 → 业务层" 的顺序,逐一进行匹配优化:
- 计算层:确定最优数据精度、模型并行拆分方案,避免计算算力浪费;
- 存储层:优化显存、内存、硬盘的容量与带宽,避免内存溢出错误和数据饥饿;
- 通信层:选择最优通信硬件和算法,降低多卡、多机的通信开销;
- 业务层:建立业务与算力的匹配调度机制,实现算力价值最大化。
第四步:监控优化(闭环迭代)
- 部署算力监控工具(如 Prometheus + Grafana),实时监控三层算力的利用率、四层匹配的效率;
- 针对出现的瓶颈(如通信开销过大、显存利用率过低)进行迭代优化,形成"梳理 - 盘点 - 匹配 - 监控 - 优化"的闭环。
四、总结
结合大模型产业化落地的实操经验,算力焦虑的核心从不是硬件不够,而是认知和方法跑偏,加卡不是唯一的解决问题的途径,往往是忽视了算力的协同本质,与其盲目加卡,不如先梳理清楚计算、访存、调度的短板,精准优化比硬件堆砌更省钱高效。我们首先可以从基础匹配入手,先搞定计算精度适配、显存带宽优化这些低成本动作,用代码验证效果后再进阶多卡协同;再就是是绑定业务场景优化,不同场景对算力需求差异极大,实时推理重低延迟,批量训练重吞吐量,针对性匹配才能让算力价值最大化。
算力治理的核心是物尽其用,跳出硬件堆砌的误区,用分层匹配逻辑打通全链路,才能让每一分硬件投入都转化为产业化落地的实效。