目录
[一 进程概念和基本操作](#一 进程概念和基本操作)
[1 什么是进程](#1 什么是进程)
[2 为什么要有进程](#2 为什么要有进程)
[3 怎么办----重点](#3 怎么办----重点)
[4 描述进程---PCB](#4 描述进程---PCB)
[二 task_struct](#二 task_struct)
[三 查看进程](#三 查看进程)
[1 /proc](#1 /proc)
[2 PID](#2 PID)
[3 crtl+c](#3 crtl+c)
[4 当前路径](#4 当前路径)
[5 指令](#5 指令)
[ps ajx:显示所有进程信息](#ps ajx:显示所有进程信息)
[四 父进程和子进程](#四 父进程和子进程)
[kill-9 PID](#kill-9 PID)
[编辑 问题3](#编辑 问题3)
一 进程概念和基本操作
1 什么是进程
进程 = 内核数据结构(task_struct) + 自己的程序代码和数据
内核数据结构(struct task_struct):这是进程的 "学籍信息",包含了进程的 PID、优先级、内存地址、状态等元数据,是操作系统管理进程的核心。
程序的代码和数据:这是进程的 "本人",即被加载到内存中的可执行程序内容。
传统教材常说:"运行起来的程序就是进程" 或 "加载到内存的程序叫做进程"。但是这种说法只强调了 "代码和数据加载到内存",忽略了内核为管理进程而维护的数据结构,显得过于片面,不易理解。
2 为什么要有进程

从软件角度讲,把你的二进制可执行程序加载到内存的过程,就叫做创造进程
3 怎么办----重点
4 描述进程---PCB
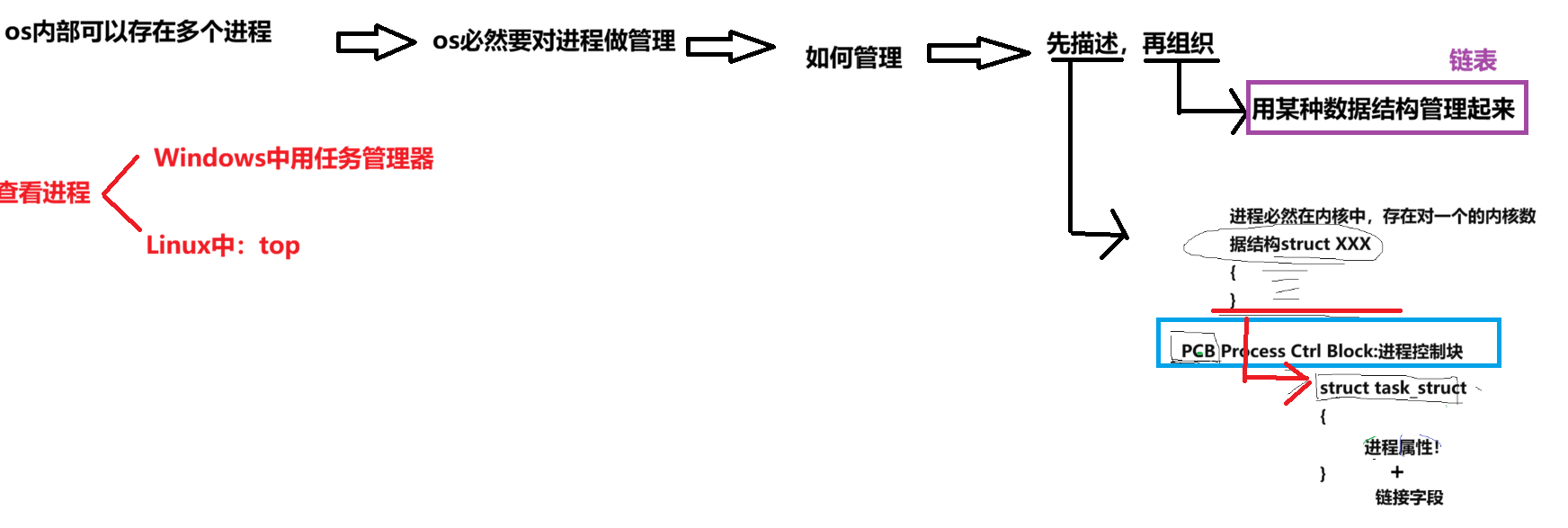
进程信息被放在一个叫做进程控制块的数据结构中,可以理解为进程属性的集合。
・课本上称之为 PCB(process control block),Linux 操作系统下的 PCB 是:task_struct。
task_struct 是 PCB 的一种。
・在 Linux 中描述进程的结构体叫做 task_struct。
・task_struct 是 Linux 内核的一种数据结构类型,它会被装载到 RAM(内存)里并且包含着进程的信息。
二 task_struct
内容分类
标示符:描述本进程的唯一标示符,用来区别其他进程。
• 状态:任务状态,退出代码,退出信号等。
• 优先级:相对于其他进程的优先级。 • 程序计数器:程序中即将被执行的下一条指令的地址。
• 内存指针:包括程序代码和进程相关数据的指针,还有和其他进程共享的内存块的指针。
• 上下文数据:进程执行时处理器的寄存器中的数据。(休学例子,要加图 CPU、寄存器)
• I/O 状态信息:包括显示的 I/O 请求、分配给进程的 I/O 设备和被进程使用的文件列表。
• 记账信息:可能包括处理器时间总和,使用的时钟数总和,时间限制,记账号等。
• 其他信息
• 具体详细信息后续会介绍
组织进程
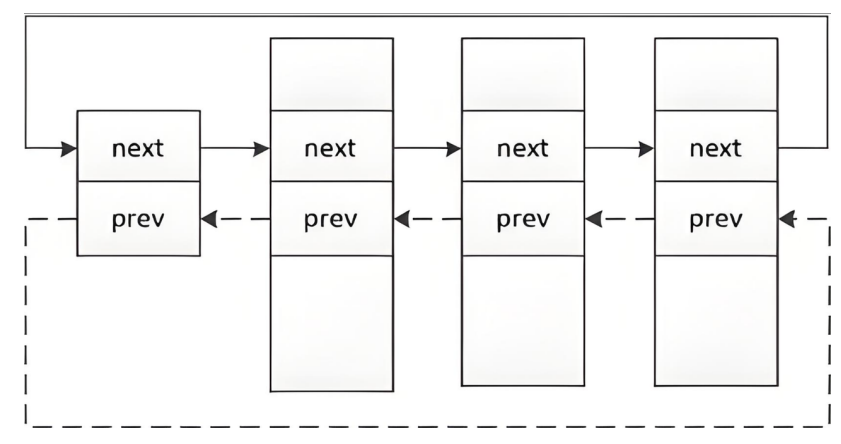
可以在内核源代码⾥找到它。所有运行在系统⾥的进程都以 task_struct 双链表的形式存在内核
⾥。
三 查看进程
我们可以用一个指令来查看进程:ps axj | grep ./[可执行程序]
查看进程的做法:
1 /proc
2 命令
1 /proc
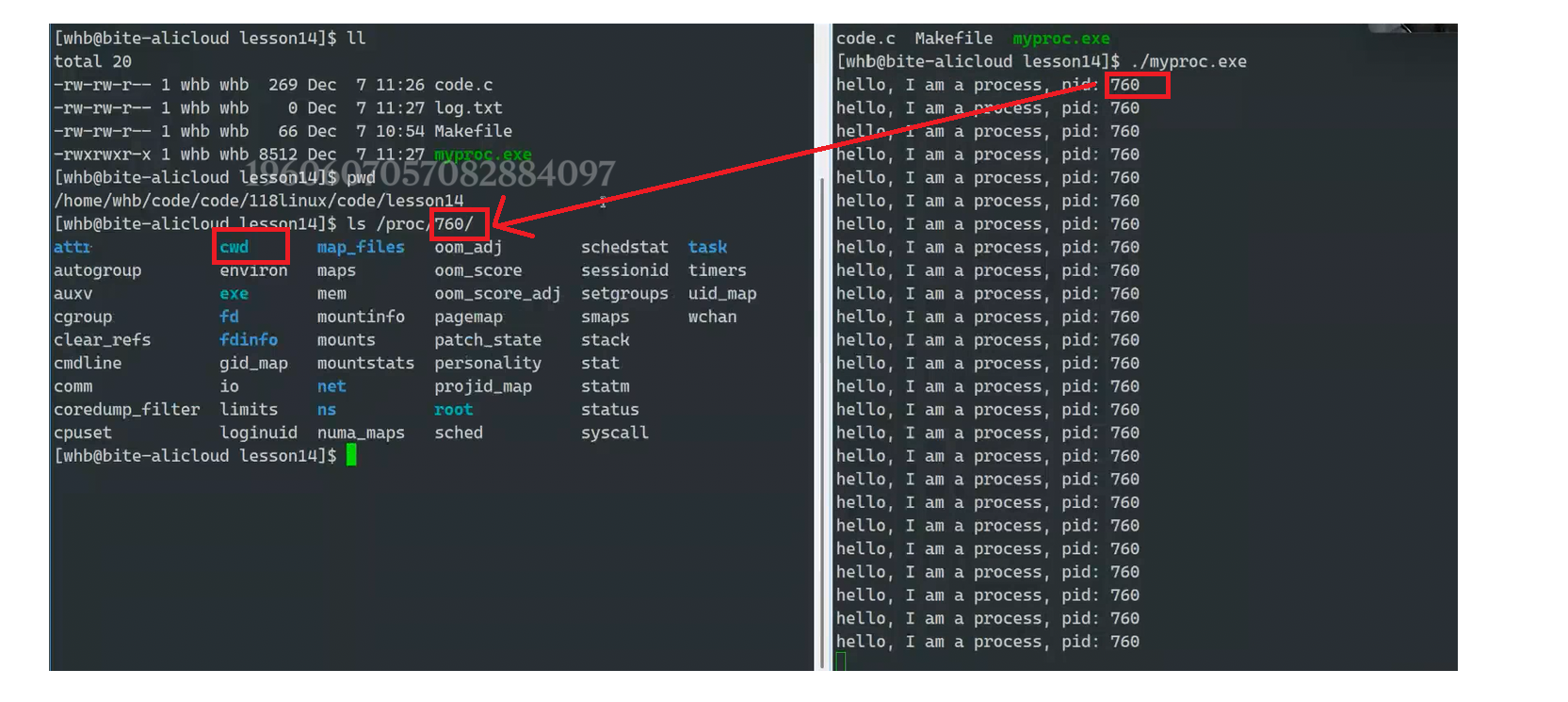
进程的信息可以通过 /proc 系统文件夹查看
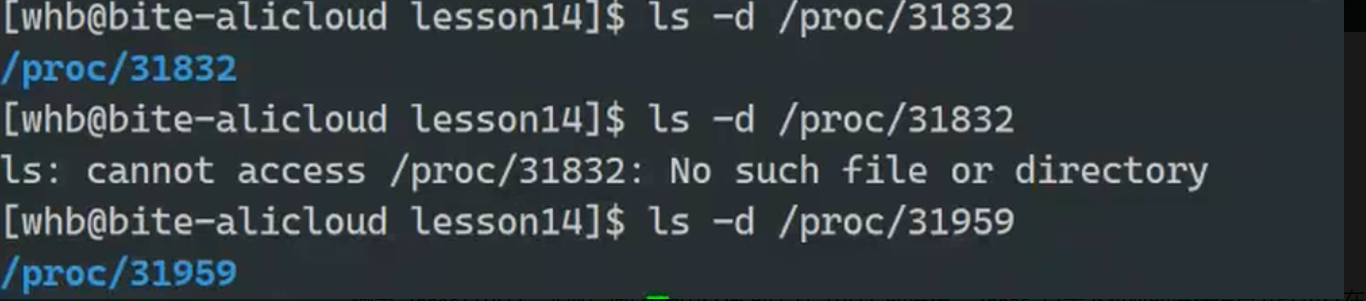
如:要获取PID为1的进程信息,你需要查看 /proc/1 这个文件夹。

ls /proc/PID
2 PID
PID 是 Process ID(进程标识符) 的缩写,是操作系统给每个正在运行的进程分配的一个唯一数字编号。
可以把 PID 理解成:进程的身份证号
PID可以被操作系统用作:
区分不同的进程
管理进程的运行(暂停、继续、终止等)
记录进程之间的关系(父进程、子进程)
例如:
终止一个进程:kill 1234(Unix/Linux)
查看进程信息:ps -ef | grep 1234
在 Windows 任务管理器中也能看到 PID
注意:PID不是固定的,它是动态分配和回收的
在系统的同一时间点,每个运行的进程都有一个唯一的 PID。
复用机制:当进程退出后,它的 PID 会被内核回收,并可以分配给新创建的进程。内核会从可用的 PID 池中按顺序分配,不会永久占用。
我们在上面图片左部分看到的数字就是PID
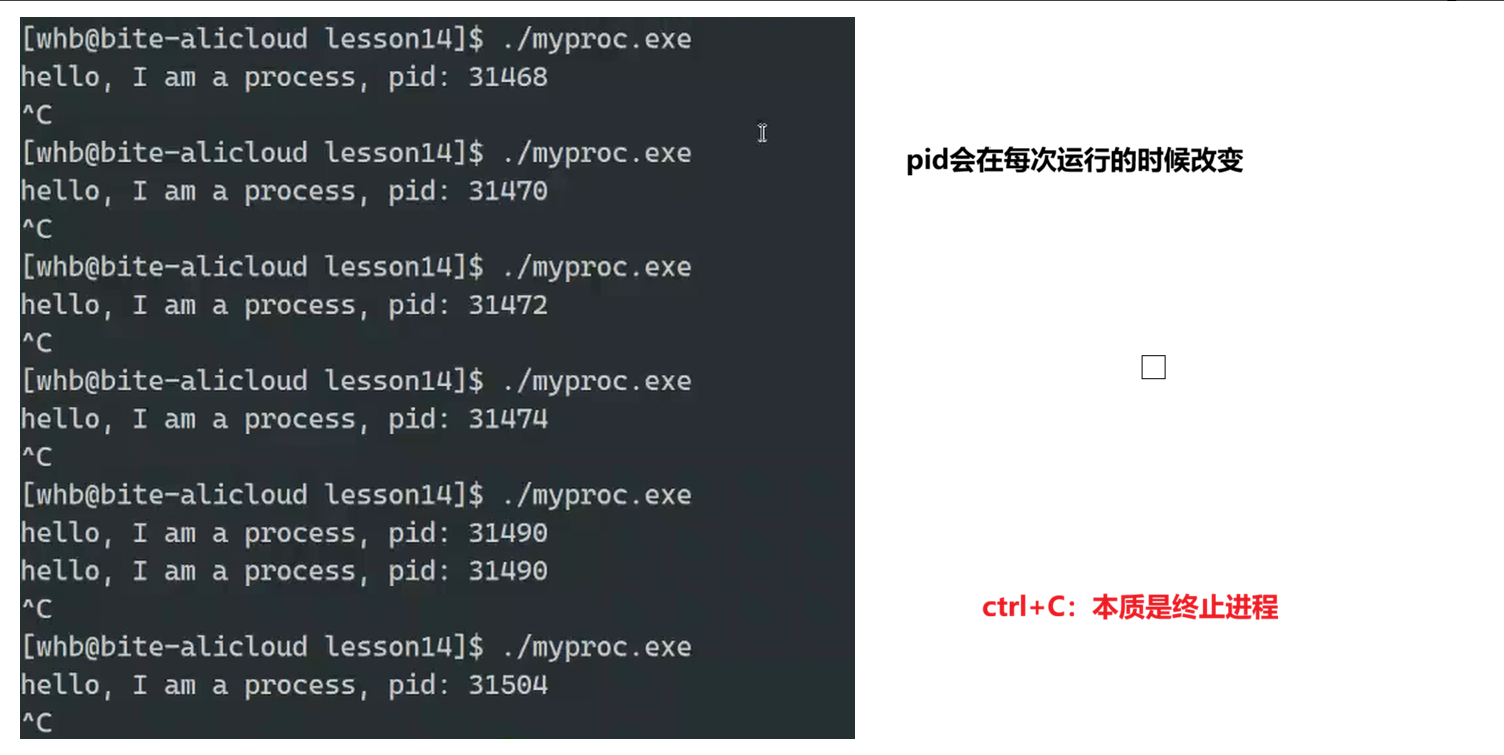
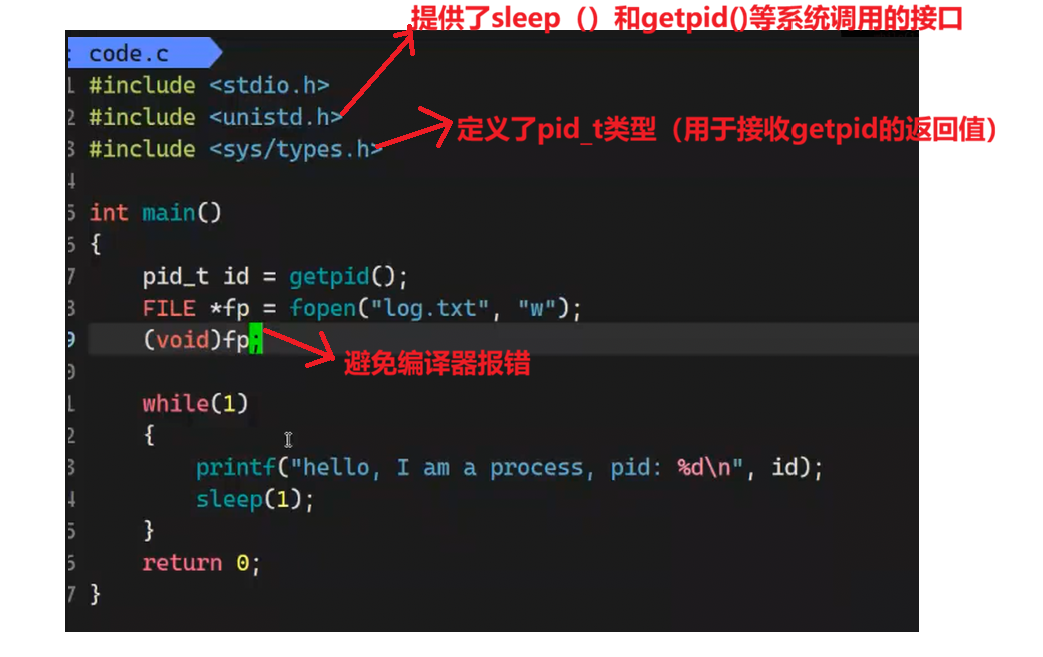
我们想要获取PID,可以用getpid()这个系统调用
3 crtl+c
在 Linux/Unix 终端中,它是发送 SIGINT(中断信号,信号编号 2)的快捷键,默认行为是终止当前前台运行的进程。
作用范围:仅对当前终端的前台进程 / 进程组生效,后台运行的进程不受影响
4 当前路径
cwd:current work dir(当前工作路径)
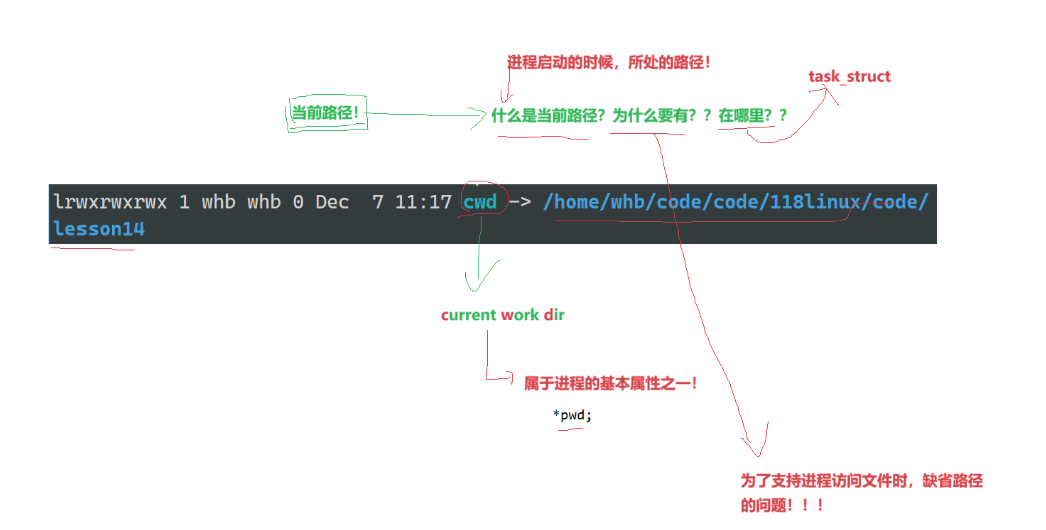
为什么要有当前路径?为了支持进程访问文件时缺省路径的问题。

当前路径就是进程启动时候所处的路径!
5 指令

大多数进程信息同样可以使用top和ps这些用户级工具来获取。
如果改变一个进程的当前工作路径,那么它在新建文件的时候,就一定会改变新建文件的位置
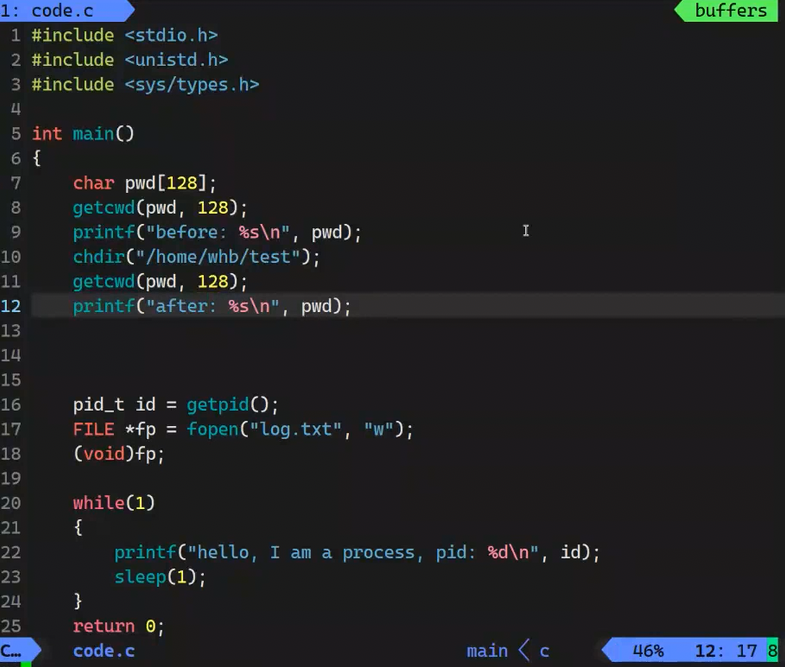
我们来写一段循环输出进程ID的代码
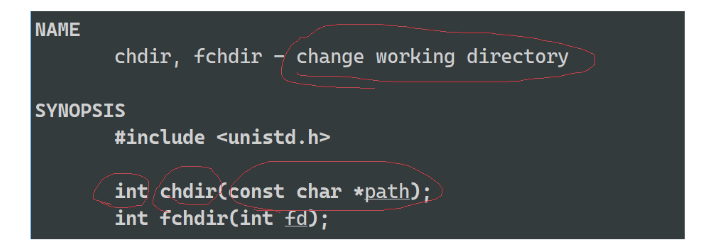
chdir:改变当前的工作路径
我们在上述代码中加上一句
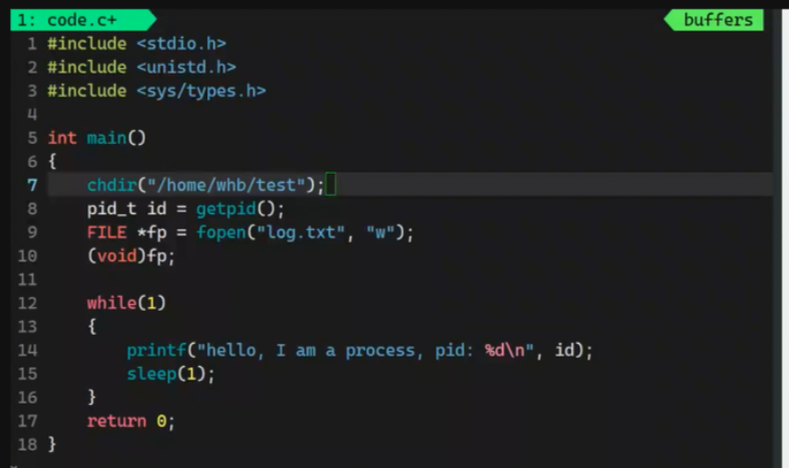
此时工作路径就被改变了,也证明了文件建在哪个路径取决于当前进程的工作路径(cwd)
getcwd:获取程序当前工作路径
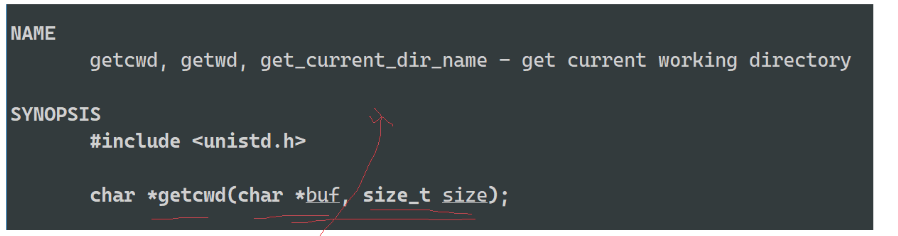
我们可以通过getcwd判断路径是否改变

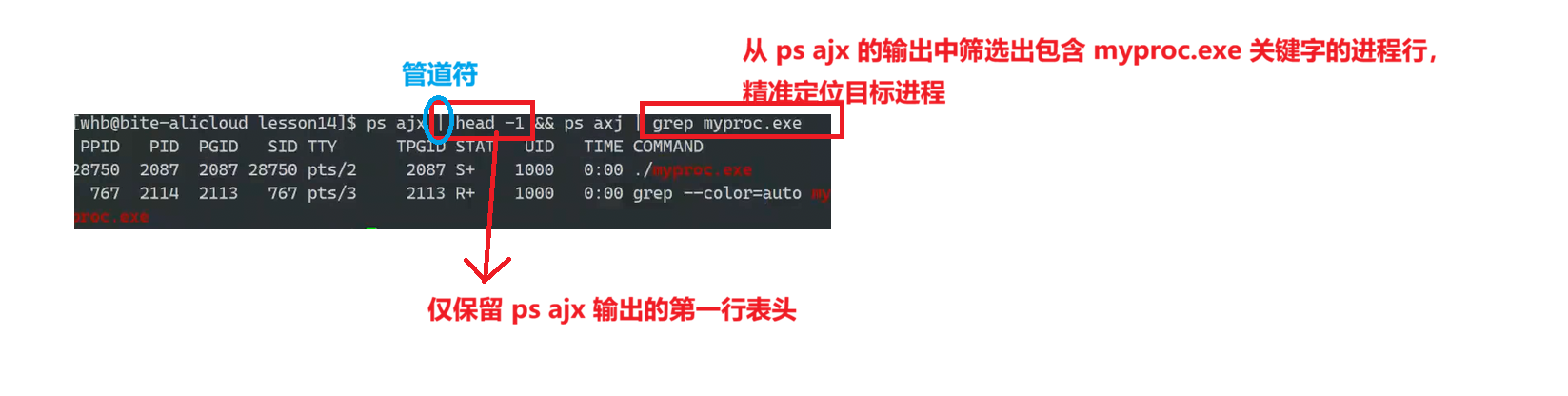
ps ajx:显示所有进程信息

里面每一个选项的详细介绍,我们到后面再讲解·
我可以利用这个系统调用,找到指定的进程:
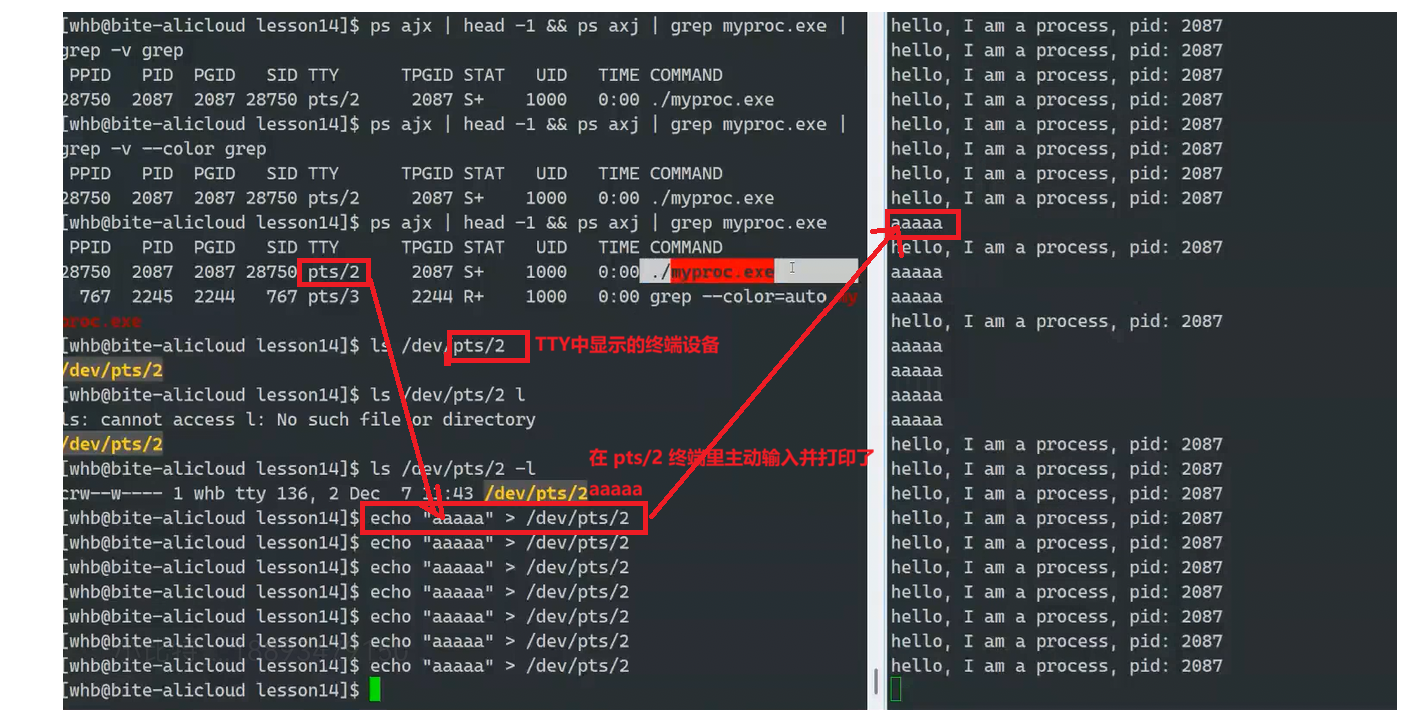
我们发现上面有一列信息的表头叫做TTY,TTY是用来表示该进程是在哪个窗口启动的
四 父进程和子进程
每个进程除了会记录自己的PID,还会记录自己父进程的PID
getppid():得到父进程的PID

我们来写一个程序看一下:
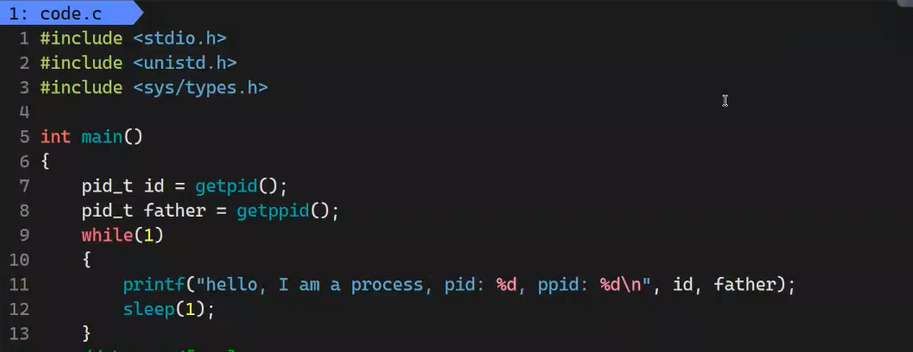
运行之后发现,父进程的PID不会改变
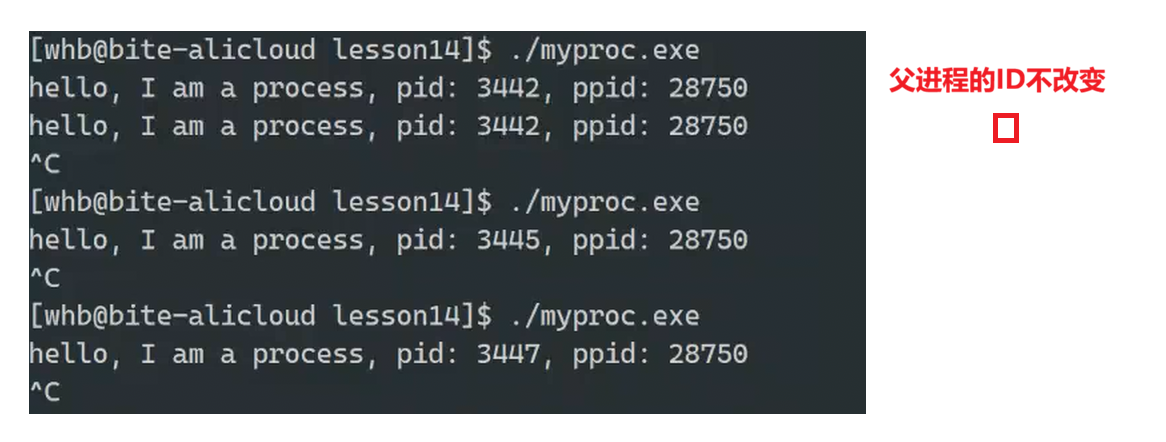
那么此时的这个父进程是谁?
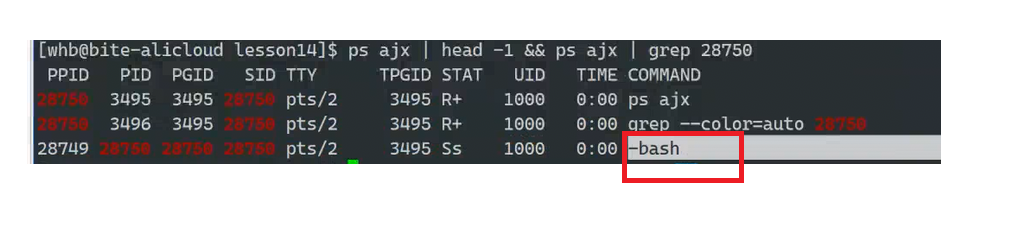
命令行启动的所有进程,父进程都是bash
bash是一个命令行解释器,它本身也是一个进程!
每一次登录,西铜都会自动提供bash,来进行命令行服务
我们运行bash之后发现,bash本身是一个代码内部具有死循环的软件
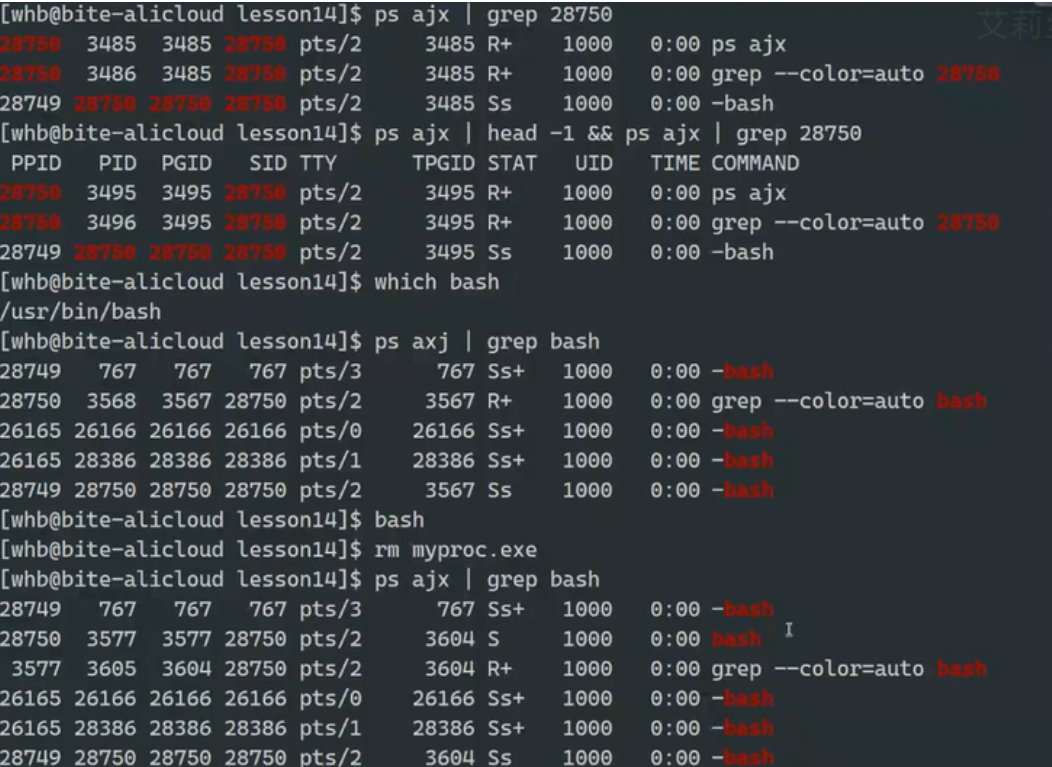
当我们用ps去看bash时,发现有些前面带'-',有些不带,为什么呢?
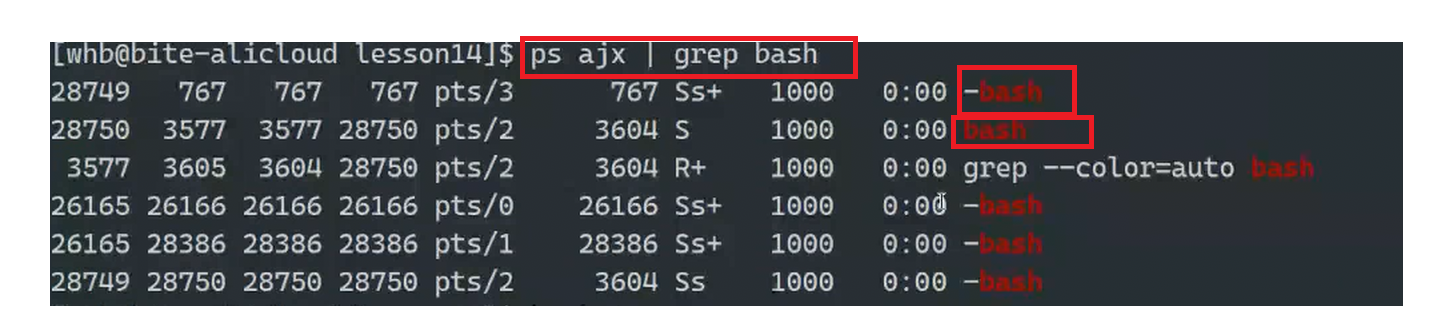
当你每一次远程登录Linux系统时,xshell都会分配一个新窗口,这种远程登录形成的bash,叫做-bash 而手动形成的bash前面没有-
kill-9 PID
杀掉一个进程
bash是如何创造子进程的?
我们先来引入一个新的系统调用:fork 创造一个子进程
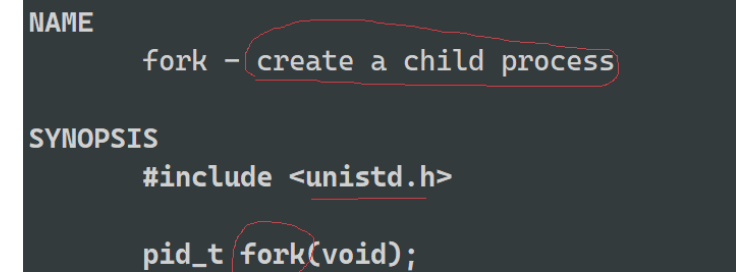
使用一下fork:
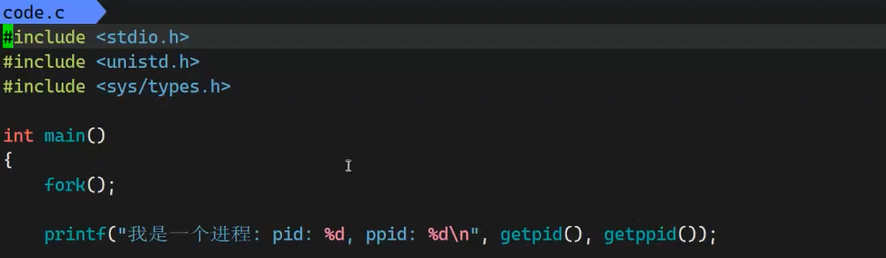
运行得到:

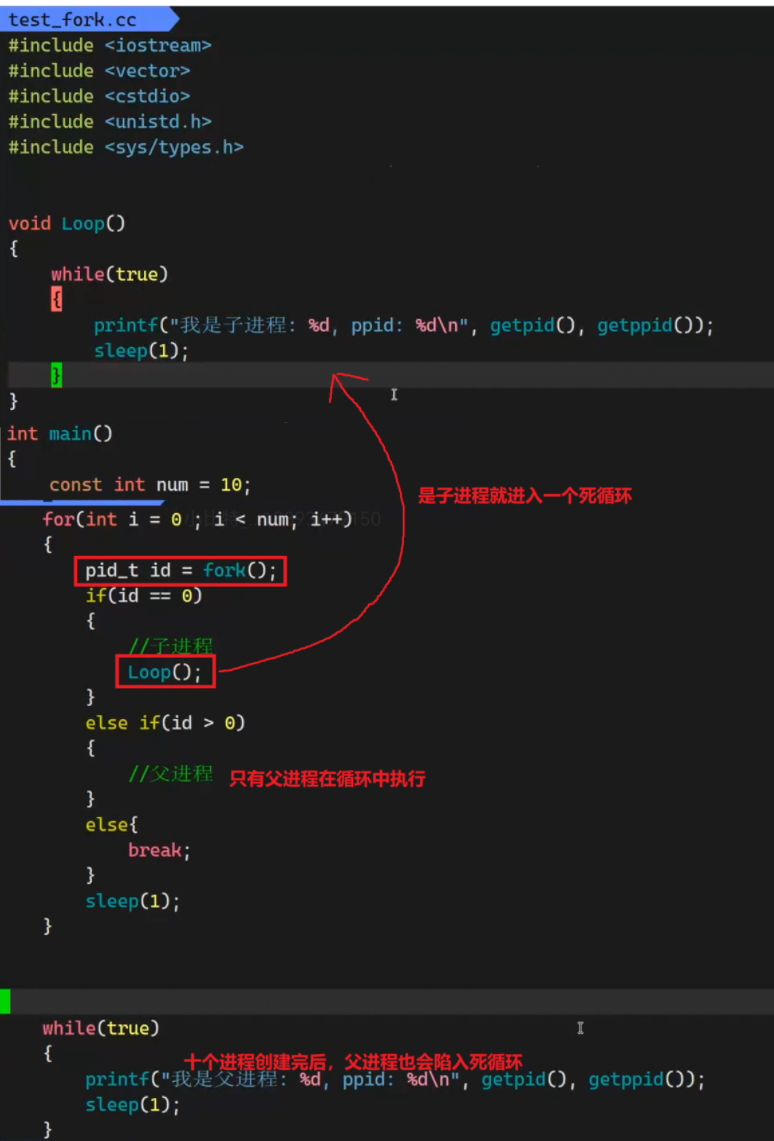
我们发现fork会分成父进程和子进程分别执行一遍 :
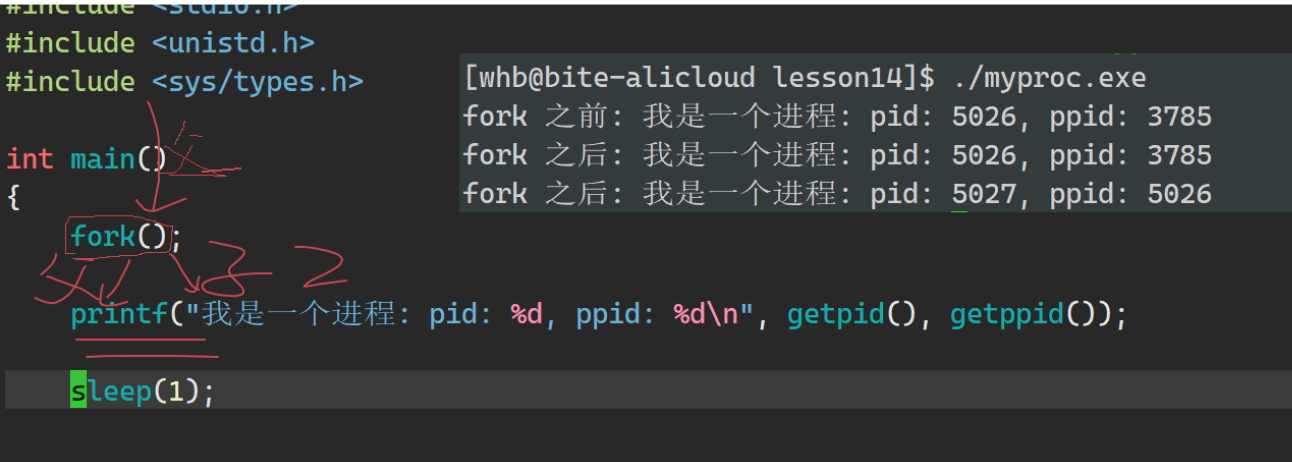
我们来看一下fork的返回值 是什么:

也就是说,如果成功的话,会把子进程的PID返回给父进程,返回0给子进程
我们来写一个程序测试一下:
运行之后发现:为什么父进程和子进程都运行了?fork怎么能既大于0,又等于0呢?
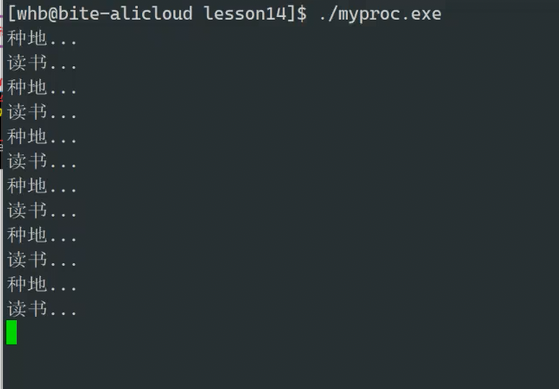
我们以前学习的代码,不可能两个死循环同时在跑,以前的代码都叫做单循环分支。但是我们现在有了父子两个进程,所有同时存在两个死循环
我们用ps查看一下这两进程,发现这两个进程同时都在运行

所以,我们可以通过fork,让同一份代码,做不同的事情
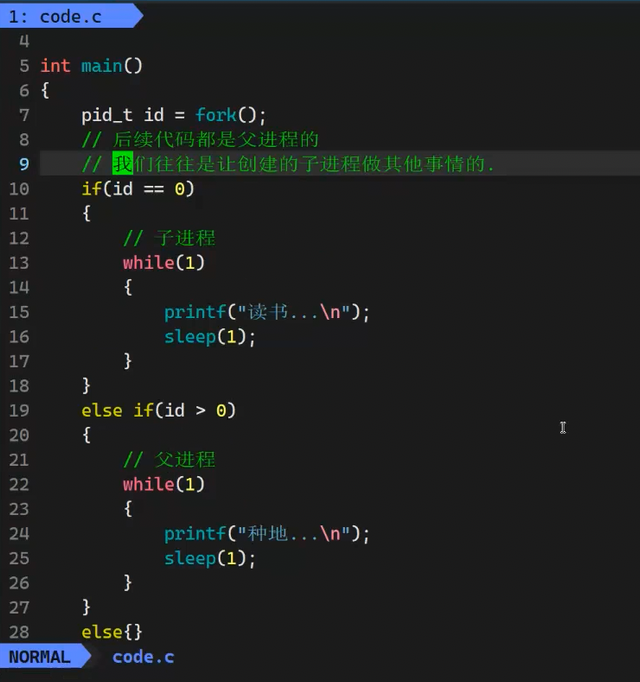
父进程是如何创建子进程的?
创建子进程:内存中就多了一个进程, 操作系统中多了PCB。子进程会以父进程为模板, 一般会把父进程的结构与变量,都拷贝一份给子进程。但是子进程中也有自己特有的部分:自己独立的PID,PPID等。所以拷贝到子进程中后,会对子进程中的个别属性作出修改
当用fork创建一个子进程时,没有把的数据和代码重新加载的过程。所以此时的拷贝,是浅拷贝 子进程也会指向伏见城的代码和数据,他们共享代码。 但是 子进程只能执行fork之后的代码
fork的三个问题

问题1
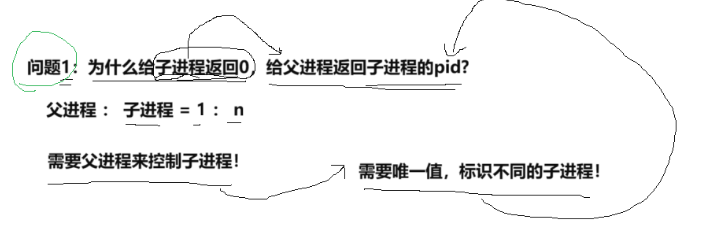 子进程只能有一个父进程
子进程只能有一个父进程
返回0:告诉子进程你已经被创建
返回PID:为了告诉父进程多了一个子进程,让它记住子进程的pid,让 父进程通过PID控制子进程
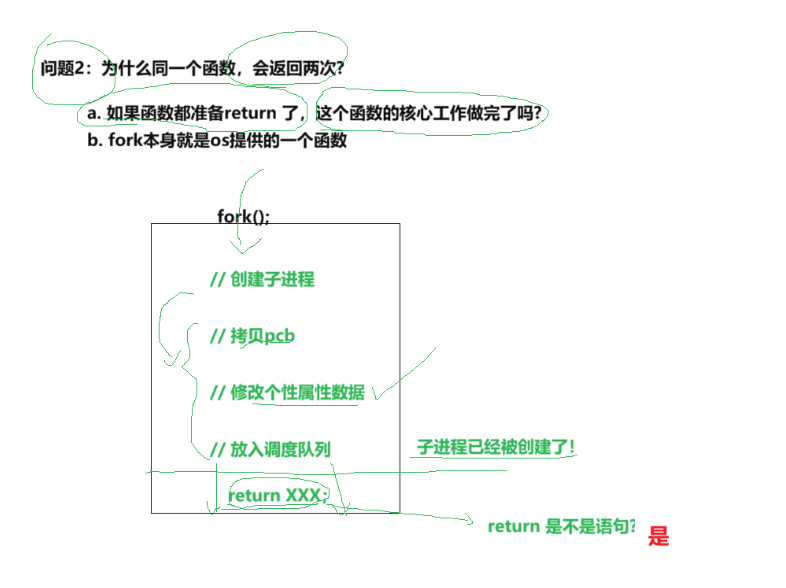
问题2
fork既是一个系统调用,也是一个函数。只要是函数,就有代码块,就有子过程
调用函数时,是需要进入函数内部。fork准备return时,子进程已经创建好了,此时fork内部有夫,子两个进程,也已经被操作系统管理起来了。
return是语句,此时父进程和子进程都需要return(return的代码被共享),各自return一次,返回两次
 问题3
问题3
对问题3的回答这里只做原理性说明,因为目前的知识没有办法解释完全,所以后面还会针对这部分讲解
进程具有很强的独立性---任何一个进程的奔溃都不会影响另一个进程
问题:代码共享时,数据是怎么处理的?

我们来写一段代码来检验这个问题:
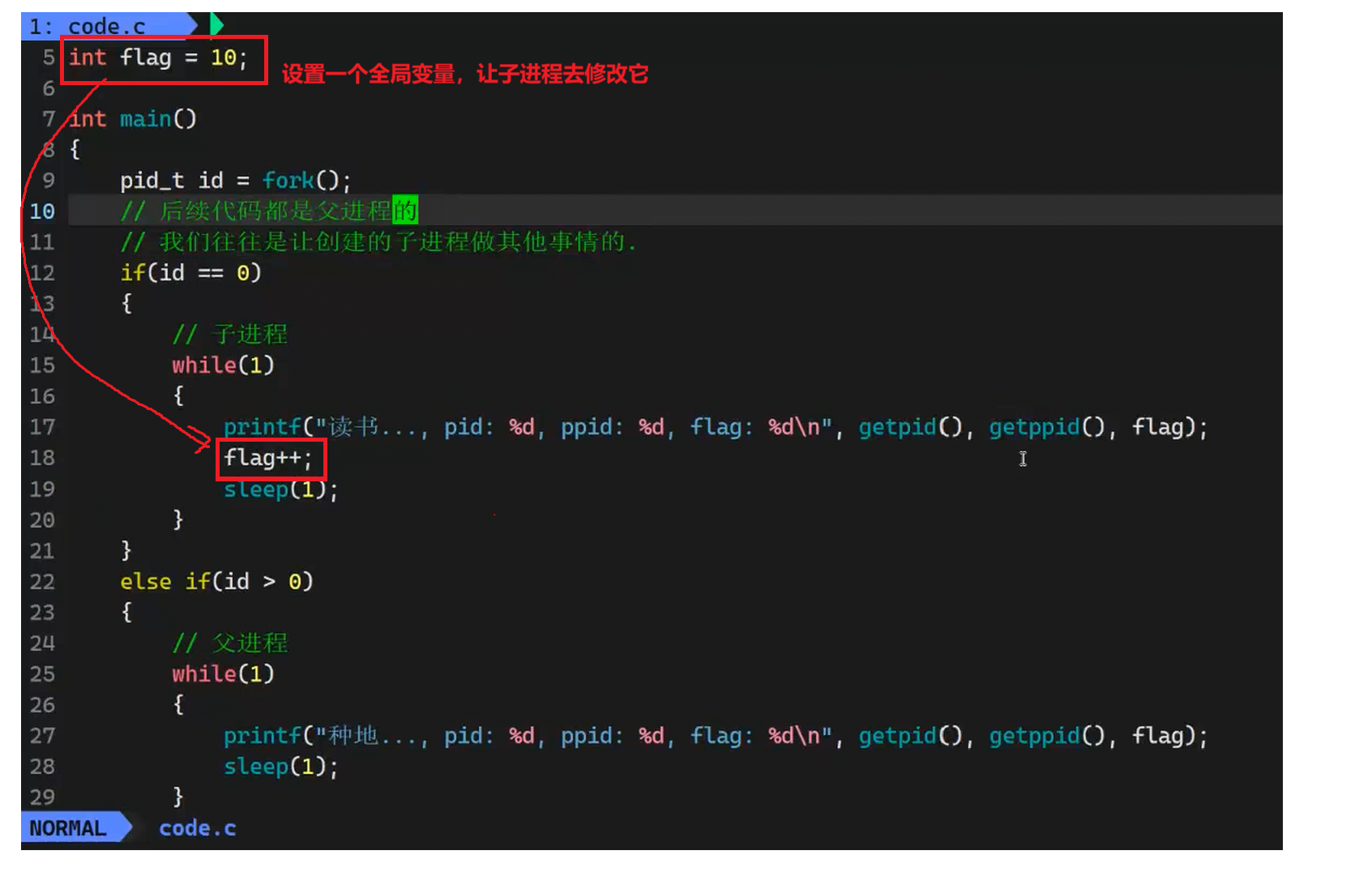
但是我们运行了之后发现:父进程的flag居然不受影响!!
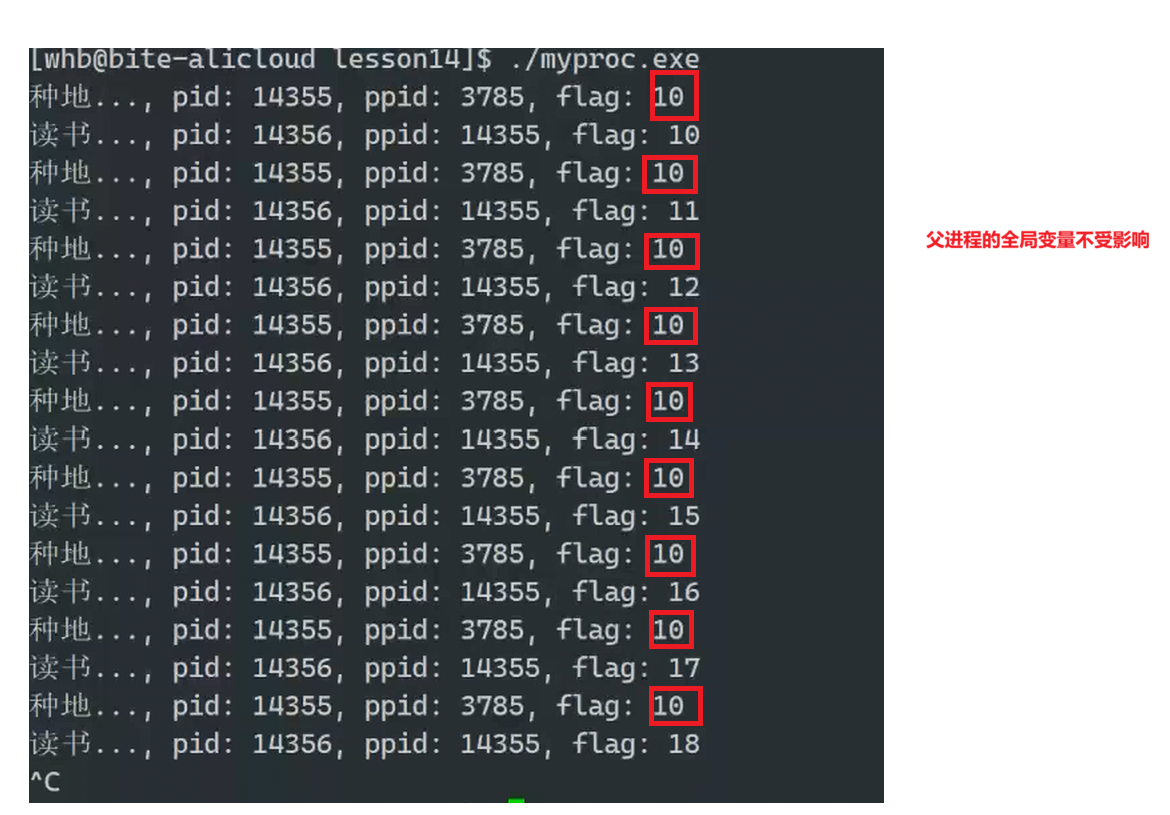
这说明父子进程的数据是分开的
但是,一个变量怎么能有两个值?
我们分别在父进程和子进程中取地址,看一下是否是一个变量
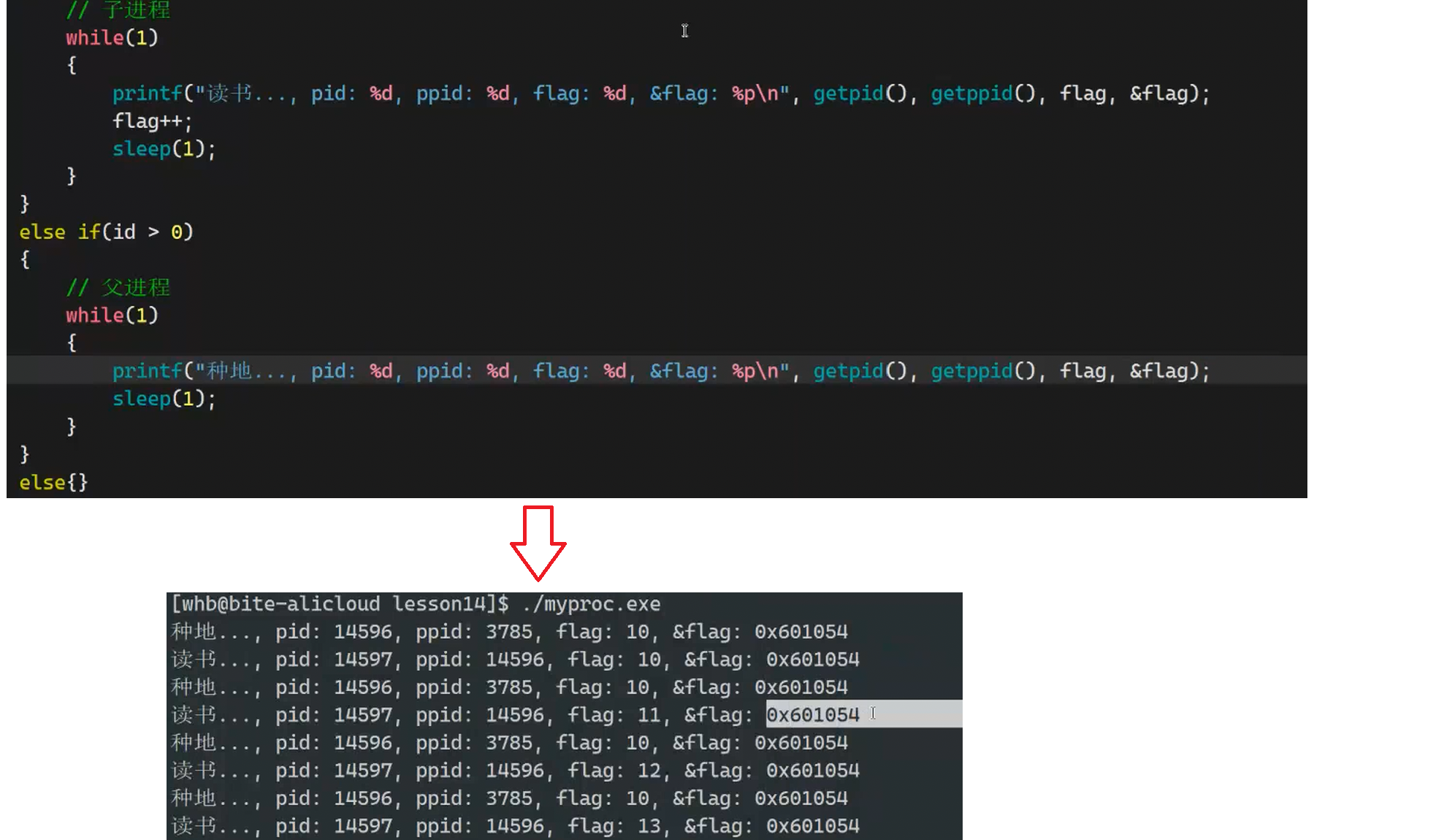
我们发现,地址是一样的,说明是一个变量。那这就说明,这个地址一定不是物理地址!!那是什么地址呢??
我们先引出概念**:这个地址是虚拟地址(具体会在后面的程序地址空间讲解)**
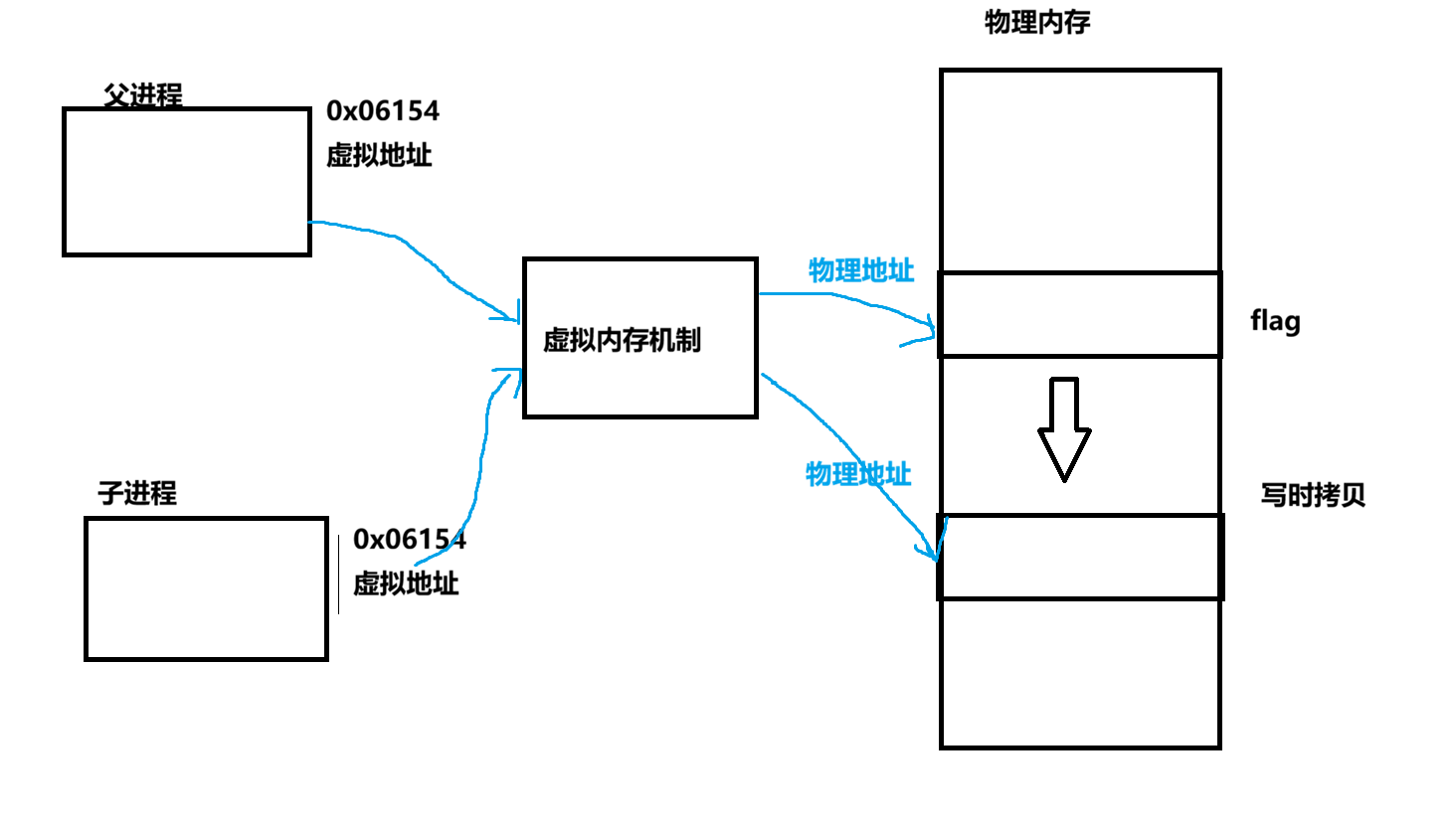
子进程继承父进程的虚拟内存空间,如果不修改数据,打印出来的地址一样。但是如果数据修改,系统会在物理内存中拷贝一个flag,这个拷贝就叫做写时拷贝。此时子进程会通过虚拟内存机制,映射到这个新的flag
这个过程是操作系统自己完成的,不需要手动完成


具体的我们后面讲解
如何利用fork建立多进程?
创建十个进程
注意:.cc后缀却表示c++