目的
为避免一学就会、一用就废,这里做下笔记
说明
- 本文内容紧承前文-Transformer架构1-整体介绍、Transformer架构6-输出层,欲渐进,请循序
- 前面学完了Transformer架构1-6节,这里通过一个模型参数量计算的测试题,验证学习效果
问题
给出HuggingFace上模型Langboat/bloom-1b4-zh的结构信息如下:
BloomForCausalLM(
(transformer): BloomModel(
(word_embeddings): Embedding(46145, 2048)
(word_embeddings_layernorm): LayerNorm((2048,), eps=1e-05, elementwise_affine=True)
(h): ModuleList(
(0-23): 24 x BloomBlock(
(input_layernorm): LayerNorm((2048,), eps=1e-05, elementwise_affine=True)
(self_attention): BloomAttention(
(query_key_value): Linear(in_features=2048, out_features=6144, bias=True)
(dense): Linear(in_features=2048, out_features=2048, bias=True)
(attention_dropout): Dropout(p=0.0, inplace=False)
)
(post_attention_layernorm): LayerNorm((2048,), eps=1e-05, elementwise_affine=True)
(mlp): BloomMLP(
(dense_h_to_4h): Linear(in_features=2048, out_features=8192, bias=True)
(gelu_impl): BloomGelu()
(dense_4h_to_h): Linear(in_features=8192, out_features=2048, bias=True)
)
)
)
(ln_f): LayerNorm((2048,), eps=1e-05, elementwise_affine=True)
)
(lm_head): Linear(in_features=2048, out_features=46145, bias=False)
)上述模型结构信息,可以通过在jupyter中执行如下代码获得
python
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("Langboat/bloom-1b4-zh",low_cpu_mem_usage=True)
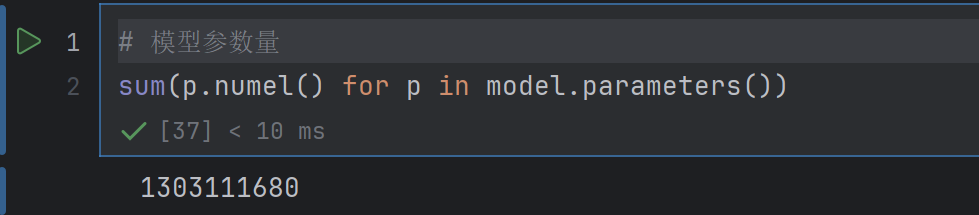
model解答
要计算 BloomForCausalLM 模型的参数量,可以根据模型结构中各层的参数数量进行累加。以下是详细的计算步骤:
1. Embedding 层 (word_embeddings)
- 形状为 (46145, 2048)
- 参数量 =
46145 × 2048 = 94,504,960
2. LayerNorm 层
- 每个
LayerNorm层有两个可学习参数:缩放因子(weight)和偏置项(bias) - 每个
LayerNorm的参数量 =2048 × 2 = 4096 - 总共有以下
LayerNorm层:word_embeddings_layernorm: 1 个input_layernorm(每层 Block): 24 个post_attention_layernorm(每层 Block): 24 个ln_f: 1 个
- 总参数量 =
(1 + 24 + 24 + 1) × 4096 = 50 × 4096 = 204,800归一化层(如Batch Norm, Layer Norm)中的缩放因子(Scale,通常记作 γ)和偏置项(Shift,通常记作 β),是赋予模型灵活性的关键可学习参数。它们的核心作用不是简单地"归一化",而是在归一化的基础上,让模型能自主决定是否恢复、以及恢复到何种原始数据特征。
3. Self-Attention 层
每个 BloomBlock 中的 self_attention 包含两个线性层:
(1) query_key_value 线性层
- 输入维度:
2048 - 输出维度:
6144 - 参数量 =
2048 × 6144 + 6144(权重 + 偏置)=12,582,912 + 6144 = 12,589,056 - 总共有 24 个 Block,因此总参数量 =
24 × 12,589,056 = 302,137,344
(2) dense 线性层
- 输入维度:
2048 - 输出维度:
2048 - 参数量 =
2048 × 2048 + 2048(权重 + 偏置)=4,194,304 + 2048 = 4,196,352 - 总共有 24 个 Block,因此总参数量 =
24 × 4,196,352 = 100,712,448
4. MLP 层(多层感知机/前馈网络)
每个 BloomBlock 中的 mlp 包含两个线性层:
(1) dense_h_to_4h 线性层
- 输入维度:
2048 - 输出维度:
8192 - 参数量 =
2048 × 8192 + 8192(权重 + 偏置)=16,777,216 + 8192 = 16,785,408 - 总共有 24 个 Block,因此总参数量 =
24 × 16,785,408 = 402,849,792
(2) dense_4h_to_h 线性层
- 输入维度:
8192 - 输出维度:
2048 - 参数量 =
8192 × 2048 + 2048(权重 + 偏置)=16,777,216 + 2048 = 16,779,264 - 总共有 24 个 Block,因此总参数量 =
24 × 16,779,264 = 402,702,336
5. LM Head 层
- 输入维度:
2048 - 输出维度:
46145 - 参数量 =
2048 × 46145(无偏置)=94,504,960
6. 总参数量汇总
将上述各项相加:
Embedding 层: 94,504,960
LayerNorm 层: 204,800
Self-Attention 层: 402,849,792
MLP 层: 805,552,128
LM Head 层: 94,504,960
-----------------------------------
总计: 1,303,111,6807. 结果验证(正确)