图像金字塔是什么?
是由一幅图像的多个不同分辨率的子图构成的图像集合。是通过一个图像不断的降低采样率产生的,最小的图像可能仅仅有一个像素点。图像金字塔的底部是待处理的高分辨率图像(原始图像),而顶部则为其低分辨率的近似图像。
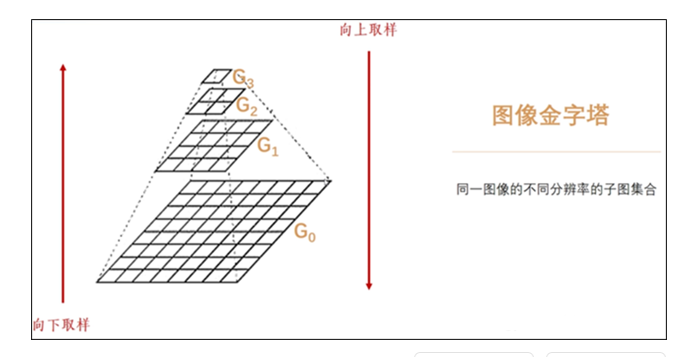
高斯金字塔和拉普拉斯金字塔是两种最常用的金字塔结构,二者相辅相成:高斯金字塔负责实现图像的尺度缩放,拉普拉斯金字塔负责记录缩放过程中的图像细节差异。
图像金字塔的作用
特征点提取(SIFT、HOG、ORB等)
模板匹配
光流跟踪
下采样和上采样
下采样
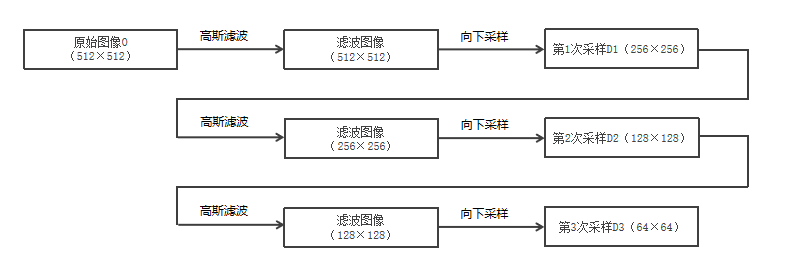
向金字塔顶部移动时,图像的尺寸和分辨率都不断地降低。通常情况下,每向上移动一级,图像的宽和高都降低为原来的1/2。
做法:1、高斯滤波
2、删除其偶数行和偶数列 OpenCV函数cv2.pyrDown()
上采样
通常将图像的宽度和高度都变为原来的2倍。这意味着,向上采样的结果图像的大小是原始图像的4倍。因此,要在结果图像中补充大量的像素点。对新生成的像素点进行赋值的行为,称为插值。
做法:1、插值
2、高斯滤波
注意:
通过以上分析可知,向上采样和向下采样是相反的两种操作。但是,由于向下采样会丢失像素值,所以这两种操作并不是可逆的。也就是说,对一幅图像先向上采样、再向下采样,是无法恢复其原始状态的;同样,对一幅图像先向下采样、再向上采样也无法恢复到原始状态
高斯金字塔
高斯金字塔是图像金字塔的基础,所有其他类型的图像金字塔几乎都依赖于高斯金字塔构建。它的核心操作是下采样 (也叫降采样),对应的反向操作是上采样(也叫升采样)。
拉普拉斯金字塔
为了在向上采样是能够恢复具有较高分辨率的原始图像,就要获取在采样过程中所丢失的信息,这些丢失的信息就构成了拉普拉斯金字塔。
拉普拉斯金字塔是有向下采样时丢失的信息构成。
案例
1.导入相关库并读取原始图像
python
import cv2
import numpy as np
读取原始图像
face = cv2.imread(r"C:\Users\LEGION\Desktop\OIP-C.webp", cv2.IMREAD_GRAYSCALE)
if face is None:
raise FileNotFoundError("未找到指定图像文件,请检查路径是否正确!")
cv2.imshow('Original face', face)
cv2.waitKey(0)运行结果:

2.执行下采样(构建高斯金字塔)
python
face_down_1 = cv2.pyrDown(face) # 下采样1次(G1)
cv2.imshow('Down 1 (G1)', face_down_1)
cv2.waitKey(0)
face_down_2 = cv2.pyrDown(face_down_1) # 下采样2次(G2)
cv2.imshow('Down 2 (G2)', face_down_2)
cv2.waitKey(0)通过两次调用cv2.pyrDown()函数,实现了图像的两次下采样,构建了一个 3 层的高斯金字塔:原始图像face(记为 G0)、下采样 1 次得到的face_down_1(记为 G1)、下采样 2 次得到的face_down_2(记为 G2)。
运行结果:
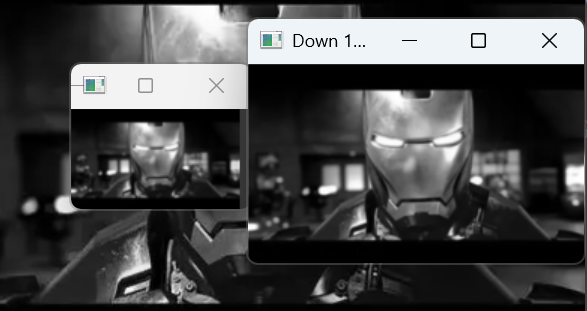
可以明显发现,执行下采样后,图片越来越小
每次调用 pyrDown,图像尺寸缩小为原来的 1/2,画面更模糊,但保留了主要的轮廓信息。
3.对下采样结果执行上采样(构建拉普拉斯金字塔)
python
face_down_1_up = cv2.pyrUp(face_down_1) # G1 上采样(恢复近似原始尺寸)
face_down_2_up = cv2.pyrUp(face_down_2) # G2 上采样(恢复近似 G1 尺寸)
cv2.imshow('Down 1 Up (G1 -> approx G0)', face_down_1_up)
cv2.imshow('Down 2 Up (G2 -> approx G1)', face_down_2_up)
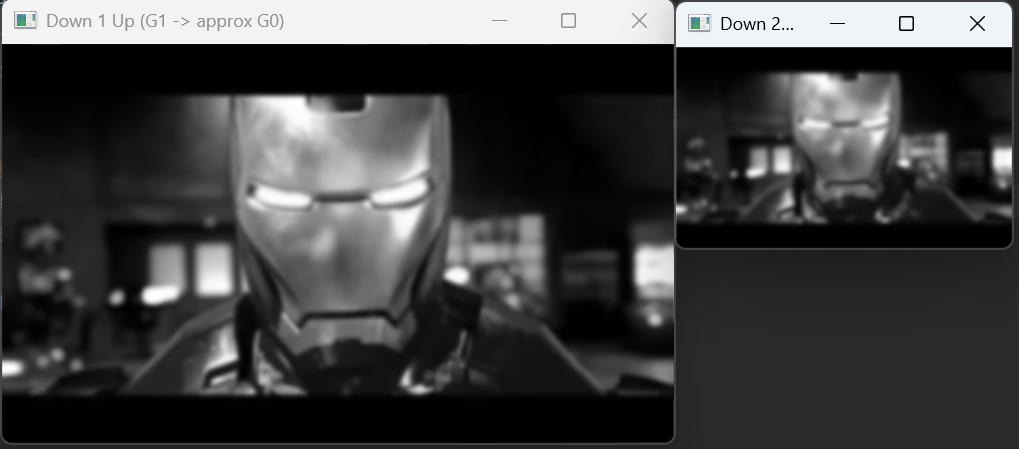
cv2.waitKey(0)G1 上采样(恢复近似原始尺寸)
G2 上采样(恢复近似 G1 尺寸)
运行结果:
注意:
先下采样再上采样,会发现图像比原始图更模糊,这是因为下采样时已经丢失了部分高频信息,而上采样无法恢复这些细节。如上文所说,是一个不可逆的过程。
4.智能裁剪(统一尺寸,替代硬编码裁剪,具备通用性)
裁剪规则:以尺寸较小的图像为基准,对齐左上角裁剪
处理 L0 = 原始图像 - G1上采样图像
python
h0, w0 = face.shape
h1, w1 = face_down_1_up.shape
target_h0 = min(h0, h1)
target_w0 = min(w0, w1)统一两张图像的尺寸
python
face_crop = face[:target_h0, :target_w0] # 裁剪原始图像
face_down_1_up_crop = face_down_1_up[:target_h0, :target_w0] # 裁剪上采样图像处理 L1 = G1 - G2上采样图像
python
h2, w2 = face_down_1.shape
h3, w3 = face_down_2_up.shape
target_h1 = min(h2, h3)
target_w1 = min(w2, w3)
face_down_1_crop = face_down_1[:target_h1, :target_w1]
face_down_2_up_crop = face_down_2_up[:target_h1, :target_w1]5.计算拉普拉斯金字塔
(转换为float32避免数值溢出,后续归一化回0-255)
python
L0 = np.float32(face_crop) - np.float32(face_down_1_up_crop)
L1 = np.float32(face_down_1_crop) - np.float32(face_down_2_up_crop)根据拉普拉斯金字塔的计算公式,分别计算了 L0 和 L1 两层拉普拉斯图像。在计算前,代码将图像转换为np.float32类型,这是因为灰度图像的默认类型是uint8(数值范围 0-255),减法运算可能会得到负数,uint8类型会直接将负数截断为 0,导致丢失细节信息。转换为np.float32类型后,可以保留负数数值,避免数值溢出和信息丢失。
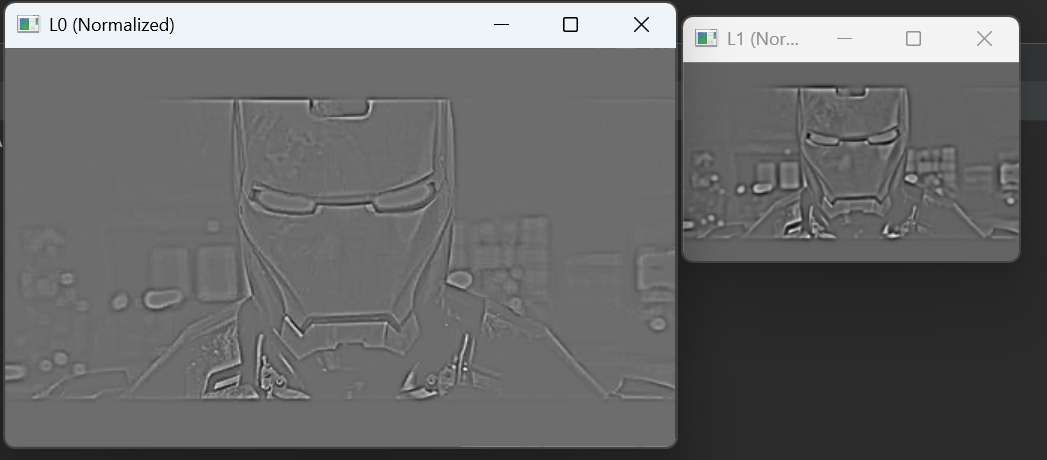
6. 归一化拉普拉斯图像
(便于显示,将数值范围映射到0-255)
python
L0_show = cv2.normalize(L0, None, 0, 255, cv2.NORM_MINMAX, cv2.CV_8U)
L1_show = cv2.normalize(L1, None, 0, 255, cv2.NORM_MINMAX, cv2.CV_8U)由于拉普拉斯图像的数值范围在正负之间波动,无法直接显示,所以要将其归一化。
运行结果:
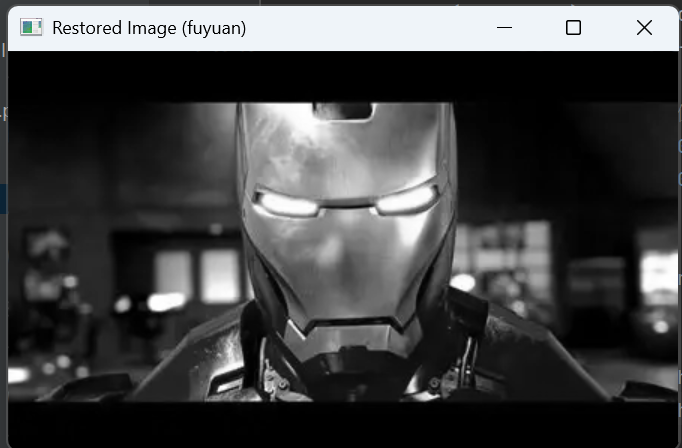
7.图像复原(转换回uint8类型)
python
fuyuan = np.uint8(np.clip(face_down_1_up_crop + L0, 0, 255)) # clip防止超出0-255范围利用拉普拉斯金字塔记录的细节信息,可以实现图像的近似复原
注意:也只是能实现图像的近似复原。
运行结果:
8.显示结果,释放窗口资源
python
cv2.imshow('L0 (Normalized)', L0_show)
cv2.imshow('L1 (Normalized)', L1_show)
cv2.waitKey(0)
cv2.imshow('Restored Image (fuyuan)', fuyuan)
cv2.waitKey(0)
# 9. 释放所有窗口资源(必须添加,避免内存泄露)
cv2.destroyAllWindows()