本博客部分笔记来源参考 bilibili 炮哥带你学 https://www.bilibili.com/video/BV1WT421r72w?spm_id_from=333.788.player.switch\&vd_source=adac1e72946f55515de8ee1fb8b6571d\&p=3
背景
目标检测涉及两个步骤:
- 检测目标位置
- 对目标物体进行分类
主流算法涉及两种:
- 单阶段模型: YOLO 快
- 双阶段模型: faster RCNN
2015年Joseph Redmon首次提出You Only Look Once, 把目标检测看成一个回归问题,在一个神经网络中同时预测目标的位置和类别,2016年推出v2, 2018年推出v3。
Yolov1网络结构
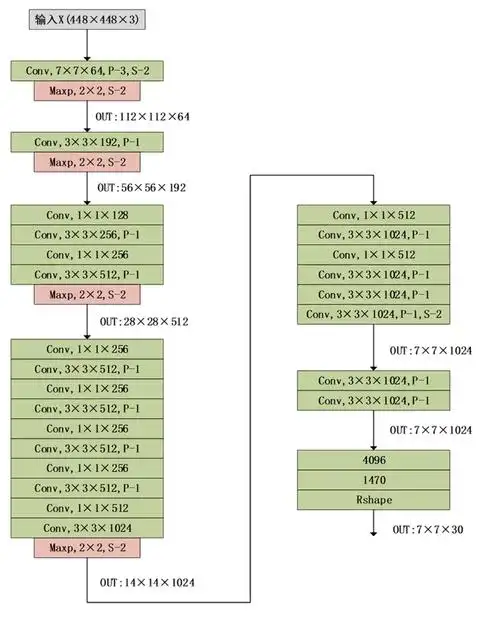
通过对网络结构的观察,不难发现,在输出层7x7x30前面,跟传统的CNN架构是及其相似的,去掉softmax替换成7x7x30的输出层,就变成了yolo。
类似的,我们可以将resnet等backbone放进来,接入一个7x7x30,改成目标检测模型。
一些细节:
-
在输出层前面有两个全连接层,实际上这一块有一部分弊端,参数量过大会导致过拟合,因此较多网络架构在输出时移除了全连接层,这也是v2优化的一个点。
-
卷积结构上依旧采取了主流做法,对size做逐步下采样,通道数逐步增加作为特征提取
-
除了最后一层用了线性激活函数,其他都是LeakyRelu。
-
Dropout和数据增强来防止过拟合。
Size 计算
H = (H+2P - K)/ S + 1
output_H = (448+2x3-7) / 2 + 1 = 447/2 + 1 = 224.5 = 224
7x7x30的输出
-
7x7可以理解成把图像划分成7x7个区域,30可以理解成每个区域有长度为30的向量输出(实际内容为2个区域(x,y,w,h,c),20个类别的概率值( p ))
-
对于每个grid cell:
1)预测B个边界框(v1是2个)
2)每个边界框包含5个元素:中心坐标x,y; 检测框的宽高:w, h; 框的置信度c。
3)类别概率
结果解析(x,y,w,h)
前面我们得到了7x7x30的结果,并且知道了7x7可以理解成将原图划分成49个小方格,并且每个小方格是得到全局信息的。 而在每个小方格的长度为30的向量中,里面有两个(x,y,w,h,c),以及20个类别的概率。
- 这里x,y的坐标代表的是每个小方格里物体中心位置的坐标。 逻辑与opencv一致,左上角为(0,0),注意每个小方格的左上角都是(0,0)。
- x,y的坐标是归一化后的坐标值,在0-1的范围内,所以需要反归一化才能得到坐标。
- w,h 是指bounding box 的宽和高,也是归一化到了0-1之间(相较于全图的size 448)
置信度
IOU
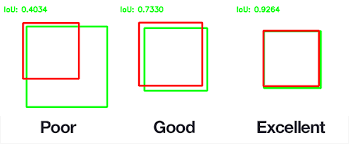
交并比(Intersection Over Union). IOU计算的是预测的边框和真实边框的交集和并集的比值。
IoU = 两个框"重叠得有多像"
IoU = 并集面积 / 交集面积
交集(Intersection):两个框重叠的那一块
并集(Union):两个框加起来的总面积(重叠部分只算一次)
| IoU 值 | 含义 |
|---|---|
| 1.0 | 完全重合 |
| 0.7+ | 非常好 |
| 0.5 | 勉强可接受(常见阈值) |
| < 0.5 | 定位不准 |
| 0 | 完全没对上 |
置信度c
- 代表当前box是否有对象的概率Pr(Object), 注意是有对象而不是某个类别的对象。 用来区分是背景还是有物体。
- 也代表当box有物体的时候,它自己预测的box与真实box之间的IOU。
实际上,test的时候,我们也没有真实box传给模型,所以这里的置信度代表模型框出物体的自信程度。
C = P r ( O b j e c t ) ∗ I O U C = Pr(Object)*IOU C=Pr(Object)∗IOU
概率值
概率值就是softmax后面的值,20个类别的概率值和为1。
类别置信度
C c l s = P r ( C l a s s i ∣ O b j e c t ) P r ( O b j e c t ) ∗ I O U = C ∗ P r ( C l a s s i ) C_{cls} =Pr(Class_i|Object) Pr(Object)*IOU = C*Pr(Class_i) Ccls=Pr(Classi∣Object)Pr(Object)∗IOU=C∗Pr(Classi)
类别置信度,代表一种自信程度。框出的box内确实有物体,并且是该类别,包括整个物体(IOU)的自信程度。
NMS 非极大值抑制
每个小方格都会有2个框,所以大概率模型每个预测的目标有多个bounding box,我们需要筛选。
NMS 的作用:
同一个目标,只保留"最靠谱"的那个框,把其它高度重叠的框删掉。
NMS 是怎么做的?(核心 4 步)
1. 按类别分开处理
NMS 是"按类别"做的
比如:
所有 chicken 框一组
所有 basketball 框一组
不同类别之间 互不影响
类别置信度<0.5可以先过滤掉
2. 选置信度最高的框
在某一类(比如 chicken)里:
找到 类别置信度最高的那个框
记为 box_best
先保留它
这个框是"当前最可信的"
3. 算 IOU,删掉"太像"的框
把 box_best
和 剩下所有同类别的框 计算 IOU:
如果
I O U > 阈值(通常 0.5 ) IOU>阈值(通常 0.5) IOU>阈值(通常0.5)
说明:它们框的是同一个目标
结果:只保留 box_best
其它框 全部删掉
这一步就是"抑制(Suppression)"
4. 重复,直到没有框了
在剩下的框中
再选一个置信度最高的
重复上面的 IOU 判断
直到处理完所有框
损失函数
坐标损失+置信度损失+类别损失
- YOLOv1 把目标检测当成回归问题,一个 grid 只负责预测中心点落在该 grid 内的目标,其余 grid 即使框到了也不参与坐标学习
- 每个 grid 会预测 B 个框,但只有与 GT IOU 最大的那个框被指定为"负责框",只有它才计算坐标和有目标置信度损失
- 坐标损失对 (x,y,w,h) 使用 MSE,其中 (w,h) 取平方根是为了降低大框误差、提高小目标的相对权重
- 置信度在 YOLOv1 中被定义为 ( P ( object ) × I O U P(\text{object}) \times IOU P(object)×IOU),有目标时实际学习的是 IOU,本质是在回归定位质量
- 绝大多数预测框是背景,如果不加区分会淹没梯度,因此无目标置信度损失 单独设置权重 ( λ n o o b j \lambda_{noobj} λnoobj) 来压低影响
- 分类损失只在 grid 内确实存在目标时 计算,并且是对类别概率做 MSE,而不是交叉熵
- 整个 loss 是多项加权和,其中 ( λ c o o r d \lambda_{coord} λcoord) 用来强调定位的重要性,防止被分类和置信度项主导训练
- YOLOv1 的 loss 设计简单但耦合严重,定位、分类和置信度互相干扰,这是后续 YOLOv2+ 改进的核心动机
L = λ coord ∑ i = 1 S 2 ∑ j = 1 B 1 i j obj ( x i − x \^ i ) 2 + ( y i − y \^ i ) 2 + λ coord ∑ i = 1 S 2 ∑ j = 1 B 1 i j obj ( w i − w \^ i ) 2 + ( h i − h \^ i ) 2 + ∑ i = 1 S 2 ∑ j = 1 B 1 i j obj ( C i − C ^ i ) 2 + λ noobj ∑ i = 1 S 2 ∑ j = 1 B 1 i j noobj ( C i − C ^ i ) 2 + ∑ i = 1 S 2 1 i obj ∑ c = 1 C ( p i ( c ) − p ^ i ( c ) ) 2 \begin{aligned} \mathcal{L} =&\;\lambda_{\text{coord}} \sum_{i=1}^{S^2} \sum_{j=1}^{B} \mathbb{1}{ij}^{\text{obj}} \Big (x_i-\\hat{x}_i)\^2 +(y_i-\\hat{y}_i)\^2 \\Big \\ &+\lambda{\text{coord}} \sum_{i=1}^{S^2} \sum_{j=1}^{B} \mathbb{1}{ij}^{\text{obj}} \Big (\\sqrt{w_i}-\\sqrt{\\hat{w}_i})\^2 +(\\sqrt{h_i}-\\sqrt{\\hat{h}_i})\^2 \\Big \\ &+ \sum{i=1}^{S^2} \sum_{j=1}^{B} \mathbb{1}{ij}^{\text{obj}} (C_i-\hat{C}i)^2 \\ &+ \lambda{\text{noobj}} \sum{i=1}^{S^2} \sum_{j=1}^{B} \mathbb{1}{ij}^{\text{noobj}} (C_i-\hat{C}i)^2 \\ &+ \sum{i=1}^{S^2} \mathbb{1}{i}^{\text{obj}} \sum_{c=1}^{C} (p_i(c)-\hat{p}_i(c))^2 \end{aligned} L=λcoordi=1∑S2j=1∑B1ijobj(xi−x\^i)2+(yi−y\^i)2+λcoordi=1∑S2j=1∑B1ijobj(wi −w\^i )2+(hi −h\^i )2+i=1∑S2j=1∑B1ijobj(Ci−C^i)2+λnoobji=1∑S2j=1∑B1ijnoobj(Ci−C^i)2+i=1∑S21iobjc=1∑C(pi(c)−p^i(c))2
坐标损失
x,y都是mse,对 w,h 开根号,是为了让"小框更敏感、大框更稳",避免大目标主导 loss。
举例来说,大框宽度从 200 变到 210 和小框从 20 变到 30,在像素上都是 10,但对小框是灾难、对大框影响很小
λ coord \lambda_{\text{coord}} λcoord 是5, λ noobj \lambda_{\text{noobj}} λnoobj是0.5,避免过度学习到没有目标的区域(大多数)
置信度损失
C i C_i Ci指的是预测和真实框的IOU
概率损失
只算有对象的
训练
v1的训练有两个阶段
- 在ImageNet上先预训练分类模型(224的输入)
- 网络输入改成448,去除全局平均池化并加入4个卷积层和2个全连接层,输出层改为7x7x30,继续finetuning(135轮).
优缺点
优点
- 快,不需要复杂组件
- 全图检测,不需要滑动窗口,预选区技术
缺点
- 准确率不够高(当然,后期够高了)
- 小物体表现差
- 可以检测的目标少 (最多7x7个结果)