目录
一、题目地址
原题直达:https://leetcode.cn/problems/find-all-anagrams-in-a-string/description/
二、题目描述
给定两个字符串
s和p,找到s中所有p的 异位词的子串,返回这些子串的起始索引。不考虑答案输出的顺序。
三、题目示例
示例 1:
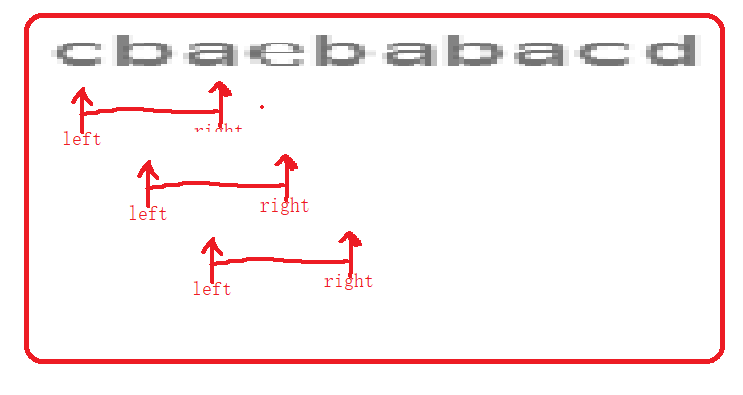
输入: s = "cbaebabacd", p = "abc"
输出: 0,6
解释:起始索引等于 0 的子串是 "cba", 它是 "abc" 的异位词。
起始索引等于 6 的子串是 "bac", 它是 "abc" 的异位词。
示例 2:
输入: s = "abab", p = "ab"
输出: 0,1,2
解释:起始索引等于 0 的子串是 "ab", 它是 "ab" 的异位词。
起始索引等于 1 的子串是 "ba", 它是 "ab" 的异位词。
起始索引等于 2 的子串是 "ab", 它是 "ab" 的异位词。
四、主体思路
暴力思路:
我们根据p字符串的长度,在s数组中依次找p.size()长度数组,与p数组进行对比,如果相等就返沪数组最嘴左边下标。
**判断两个数组是否相等:**可以定义两个unordered_map hash表,把字符存到hash表中,进行判断是否相等。
优化方案:
利用"定长滑动窗口"思想,定义right,left区间,滑动窗口内存放的时一块定长区间。r
right入窗口,判断两个hash是否相等,如果相等存储left,当长度大于p.size时left出窗口。
细节:出窗口时如果出的字母hash表中位0,直接删除这个数在hash的存储。

五、代码实现
cpp
class Solution {
public:
vector<int> findAnagrams(string s, string p) {
int n1=p.size();
unordered_map<int,int> hash1;
for(int i=0;i<n1;i++){
hash1[p[i]]++;
}
int n2=s.size();
unordered_map<int,int> hash2;
vector<int> v1;
int right=0;
int left=0;
while(right<n2){
hash2[s[right]]++;
if(right-left+1>n1){
//出窗口
hash2[s[left]]--;
if(hash2[s[left]]==0){
hash2.erase(s[left]);
}
left++;
}
if(hash1==hash2){
v1.push_back(left);
}
right++;
}
return v1;
}
};