一.Transformer
以一个比较简单的例子写一写transformer的代码,数据来源是《鲁迅全集》,简要展示一下:目的是续写后面的内容,或者说是生成类似风格的一段话吧(= -=) 效果也展示一下:最后会把整体代码贴上来
1.结果展示
原文内容:
样,而艺术本身有无限的价值等级存在,这是不得否认的。这是说,文艺之流,从最初的什么主义到现在的什么主义,所写着的内容,如何不同,而要有精刻熟练的才技,造成一篇优美无媲的文艺作品,终是一样。一条长江,上流和下流所呈现的形相,虽然不同,而长江还是一条长江。我们看它那下流的广大深缓,足以灌田亩,驶巨舶,便忘记了给它形成这广大深缓的来源,已觉糊涂到透顶。若再断章取义,说:此刻现在,我们所要的是长江的下流,因为可以利用,增加我们的财富,上流的长江可以不要,有着简直无用。这是完全以经济价值去评断长江本身整个的价值了。这
生成内容:却是真实的"实习惯的",所以也是这样的。这种文笔用所关于文艺文摊一张,则以见不过态度,就是连在中国有些人间告式的半旷新环宗爷活在挈论之前,也没有误等的。这时就是中国,安辱国还多看到起来,比凡都可怕的人类,甚而至于流出于也不出下台来,向文章上是甚而时也就用屋霉绯红色似的。众出现,这一受着作品文,因为有的在已经改变了"罢。幸而芬是接吻的文学史和文学的琐暇,既然也就是文学改革品的改作,对于写造出戏文。至少有的人受交病论》《关,出一篇之应该有些朽间,若在只有写下令人,动人想带,改,尤其是难催尔志两三种的少数了。然而首先就是两字,为难不许多印的,便明在上势所设法的一定之乐器。但那大作者却也多译者还见时有些总可笑的。至于路,又有些原因,毫无红法海,不可解,他们是姑且"社"的,就改成为我一切实际情形,破绽是得干了真是周围。
真实下文:种评断,出于着眼在经济价值的商人之口,不足为怪;出于着眼在艺术价值的文艺家之口,未免昏乱至于无可救药了。因为拿艺术价值去评断长江之上流,未始没有意义,或竟比之下流较为自然奇伟,也未可知。 真与美是构成一件成功的艺术品的两大要素。而构成这真与美至于最高等级,便是造成一件艺术品,使它含有最高级的艺术价值,那便非赖最高级的天才不可了。如果这个论断可以否认,那末我们为什么称颂荷马,但丁,沙士比亚和歌德呢?我们为什么不能创造和他们同等的文艺作品呢,我们也有观察现象的眼,有运用文思的脑,有握管伸纸的手?
2.数据处理
首先处理数据,数据保存在本地"鲁迅全集.txt",with open使用utf-8阅读文本数据
python
file_name = "鲁迅全集.txt"
with open(file_name, 'r', encoding='utf-8') as f:
text = f.read()然后需要对于鲁迅全集中的文本进行编码,以一句话为例子,即"以笔代戈,以文代盾",流程如下:(这里没有使用BPE算法,使用的是单字的分词)首先要对其中所有的单字标注id:这里构建一个集合,存储文本中存在的词的词表大小vocab_size,简历单字到id的映射:也即以:{0,笔:1,代:2,戈:3,文:4,盾:5}形式,也保留id到字的映射便于输出文本,代码如下:
python
#构建有序、不重复列表
chars = sorted(list(set(text)))
vocab_size = len(chars)
# print(chars)
# print(f"一共有{vocab_size}个不同的字符")
#字符和整数之间的投影映射
stoi = {ch:i for i,ch in enumerate(chars)} #字符到序号
itos = {i:ch for i,ch in enumerate(chars)} #序号到字符
# print(stoi)
# print(itos)
#编码和解码函数
encode = lambda str1: [stoi[c] for c in str1] #字符串转整数序列(列表)
decode = lambda list1: ''.join([itos[i] for i in list1]) #整数序列转字符串
# print(encode(""鲁迅!""))
# print(decode([2, 611, 545, 617, 3]))下面对数据集进行处理,分开训练文本和测试文本,把文本转化为id,组织成一个一维张量,长度也即全文的长度,对其进行9:1的训练集和测试集分割,这里是朴素实现
python
#训练集和验证集划分
data = torch.tensor(encode(text), dtype=torch.long) #用整数表示字符
# print(data)
n = int(0.9*len(data)) #前90%做训练集,后10%做验证集
train_data = data[:n]
val_data = data[n:]
# print(f"训练集有{len(train_data)}个字符,验证集有{len(val_data)}个字符")
print(f"{file_name}已经读取完成")
#数据分批次
def get_batch(split):
data = train_data if split == 'train' else val_data
ix = torch.randint(len(data) - block_size, (batch_size,))
x = torch.stack([data[i:i+block_size] for i in ix])
y = torch.stack([data[i+1:i+block_size+1] for i in ix])
#对于每一个字而言(x),它的预测目标是下一个字(y)
x,y = x.to(device), y.to(device)常规可以使用DataLoader、Dataset类,结合train_test_split()函数进行测试集和验证集的分割,介绍一下:
Dataset和DataLoader是PyTorch 中用于数据加载的核心组件,train_test_split是 scikit-learn(sklearn)中用于数据集划分的工具
train_test_split:负责数据划分,将原始数据拆分成训练集和测试集(可选验证集),保证数据的独立性和实验的可复现性。Dataset(PyTorch):负责数据封装 ,定义数据的读取、预处理逻辑,每次返回单条样本(特征 + 标签),是数据加载的基础。DataLoader(PyTorch):负责批量加载 ,对Dataset封装的数据进行批量提取、打乱、多进程加速等,为模型训练提供批量数据,是连接Dataset和模型的桥梁。①
train_test_split将原始数据(特征矩阵
X、标签向量y)划分成训练集和**测试集,**分布均匀易于复现
pythonsklearn.model_selection.train_test_split(*arrays, test_size=None, train_size=None, random_state=None, shuffle=True, stratify=None)
*arrays:传入需要划分的数据集,通常是X(特征)和y(标签),要求所有传入数据的样本数一致。test_size:测试集占比(0~1)或样本数量(整数),比如0.2表示测试集占 20%。random_state:随机种子,固定种子后划分结果可复现。shuffle:划分前是否打乱数据,默认True,避免数据有序导致模型过拟合。stratify:按标签分布 分层划分,传入y(标签),适用于分类任务,保证训练集和测试集的标签比例与原始数据一致。这里我们对一段话进行预测,因此传入已经处理好的data,测试集设为10%,给定随机种子,不需要进行shuffle
②Dataset
Dataset是 PyTorch 提供的**抽象数据类,继承自torch.utils.data.Dataset抽象类:**它的核心职责是:
- 定义数据集的总样本数(
__len__方法)。返回数据集总长度,比如训练集有 750 个样本,就返回 750,DataLoader会通过这个方法确定批量加载的边界。- 定义根据索引
idx获取单条样本 (特征 + 标签)的逻辑(__getitem__方法)。idx是0 ~ len(dataset)-1的整数,DataLoader在加载数据时,会自动循环传入idx,获取单条样本后再拼接成批量数据。上面两个方法在自定义Dataset时必须重写,否则会报错
- 同时可以在内部完成数据预处理(比如归一化、类型转换、数据增强等),让数据直接满足模型输入要求。
给出一个常规的示例:
pythonimport torch from torch.utils.data import Dataset # 自定义Dataset类,封装训练/测试数据 class MyCustomDataset(Dataset): def __init__(self, features, labels, transform=None): """ 初始化方法:加载数据并保存预处理方式 :param features: 特征数据(numpy数组) :param labels: 标签数据(numpy数组) :param transform: 可选的额外数据预处理(比如TorchVision的图像增强) """ self.features = features self.labels = labels self.transform = transform def __len__(self): """ 返回数据集的总样本数,DataLoader会用这个方法判断数据是否加载完毕 """ return len(self.features) def __getitem__(self, idx): """ 核心方法:根据索引idx返回单条样本(特征+标签) :param idx: 样本索引(整数,由DataLoader自动传入) :return: 处理后的单条样本(特征tensor + 标签tensor) """ # 1. 获取单条数据(根据索引提取) single_feature = self.features[idx] single_label = self.labels[idx] # 2. 数据预处理:将numpy数组转换为PyTorch的Tensor(模型只能处理Tensor类型) single_feature = torch.tensor(single_feature, dtype=torch.float32) single_label = torch.tensor(single_label, dtype=torch.long) # 分类任务标签用long类型 # 3. 可选的额外预处理(比如图像增强) if self.transform: single_feature = self.transform(single_feature) # 4. 返回单条样本(特征+标签) return single_feature, single_label # 5. 实例化Dataset(分别封装训练集、测试集、验证集) train_dataset = MyCustomDataset(X_train, y_train) val_dataset = MyCustomDataset(X_val, y_val) test_dataset = MyCustomDataset(X_test, y_test) # 6. 测试Dataset的使用 # 查看总样本数 print(f"训练集Dataset总样本数:{len(train_dataset)}") # 获取第0条样本 sample_0_feature, sample_0_label = train_dataset[0] print(f"第0条样本特征形状:{sample_0_feature.shape},标签:{sample_0_label}")③DataLoader
DataLoader是 PyTorch 提供的数据加载器 ,不直接处理原始数据,是对我们设定的Dataset对象进行处理,将Dataset返回的单条样本拼接成批量数据。 批量加载时打乱数据 ,支持多进程数据加载,提升数据加载速度。自动处理数据拼接、剩余样本丢弃等细节
pythontorch.utils.data.DataLoader(dataset, batch_size=1, shuffle=False, num_workers=0, drop_last=False)
dataset:传入实例化后的Dataset对象。batch_size:批量大小,即每次返回多少条样本,比如32、64。shuffle:是否打乱批量数据。num_workers:数据加载的进程数,默认0,Windows 系统建议设为0(避免多进程报错),Linux/Mac 可设为4、8等(不超过 CPU 核心数)。drop_last:是否丢弃最后一批不足batch_size的样本,默认False,训练集可设为True。使用时需要实例化DataLoader,他是一个迭代器,可以直接通过for循环遍历并获取数据
pythonfrom torch.utils.data import DataLoader # 1. 实例化DataLoader(分别创建训练集、验证集、测试集的加载器) train_dataloader = DataLoader( train_dataset, batch_size=32, # 每次返回32条样本 shuffle=True, # 训练集打乱 num_workers=0, # Windows系统设为0 drop_last=True # 丢弃最后一批不足32条的样本 ) val_dataloader = DataLoader( val_dataset, batch_size=32, shuffle=False, # 验证集不打乱 num_workers=0, drop_last=False ) test_dataloader = DataLoader( test_dataset, batch_size=32, shuffle=False, # 测试集不打乱 num_workers=0, drop_last=False ) # 2. 测试DataLoader的使用(遍历获取批量数据) # DataLoader是一个迭代器,可以用for循环直接遍历 for batch_idx, (batch_features, batch_labels) in enumerate(train_dataloader): print(f"第{batch_idx+1}批数据") print(f"批量特征形状:{batch_features.shape}") # (batch_size, 特征数) → (32, 5) print(f"批量标签形状:{batch_labels.shape}") # (batch_size,) → (32,) # 仅查看前2批数据,避免输出过多 if batch_idx >= 1: break④常规使用流程
先划分,再封装,最后批量加载
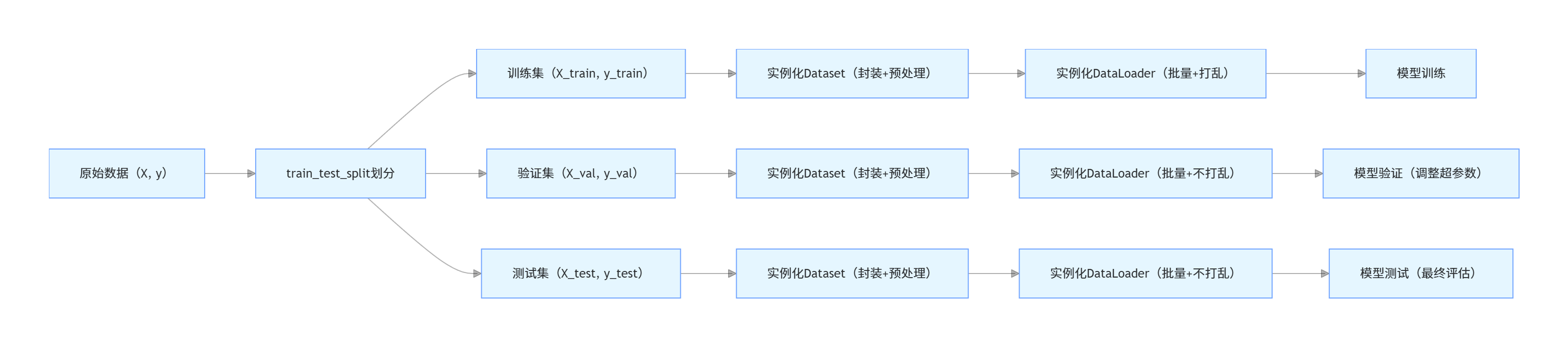
下面是使用DataLoader、Dataset和train_test_split进行数据集处理的代码:
把文本数据通过前面定义的encode函数转化为id序列,通过train_test_split函数划分训练集和验证集。重写Dataset函数,其中data也即要传进去的数据集,block_size也即一次要传入的字符长度。length方法用于获取数据集长度,由于每次预测之后,那么有效序列数量 = 1000 - 256 = 744个,需要为每个序列留出block_size个字符用于计算。每次计算时,获取X和y进行处理:
x = self.data[idx:idx+self.block_size]
y = self.data[idx+1:idx+self.block_size+1]
python原始文本: 深度学习很有趣 编码数据: tensor([0, 1, 2, 3, 4, 5, 6]) 数据长度: 7 数据集大小: 4 样本0: x='深度学', y='度学习' 样本1: x='度学习', y='学习很' 样本2: x='学习很', y='习很有' 样本3: x='很有趣', y='有趣'案例如上
python
# 训练集和验证集划分
data = torch.tensor(encode(text), dtype=torch.long) # 用整数表示字符
# 使用train_test_split划分索引
train_data, val_data = train_test_split(
data,
test_size=0.1, # 10%作为验证集
random_state=42, # 确保结果可重现
shuffle=False
)
class TextDataset(Dataset):
def __init__(self, data, block_size):
self.data = data
self.block_size = block_size
self.length = len(data) - block_size # 有效序列数量
def __len__(self):
return self.length
def __getitem__(self, idx):
# 确保索引在有效范围内
if idx < 0 or idx >= self.length:
raise IndexError("索引超出范围")
# 获取输入序列和目标序列
x = self.data[idx:idx+self.block_size]
y = self.data[idx+1:idx+self.block_size+1]
return x, y
# 创建训练集和验证集的Dataset实例
train_dataset = TextDataset(train_data, block_size)
val_dataset = TextDataset(val_data, block_size)
#在Windows上设置num_workers=0,避免多进程问题
num_workers = 0 # Windows系统上设置为0
# 创建DataLoader实例
train_loader = DataLoader(
train_dataset,
batch_size=batch_size,
shuffle=True,
num_workers=num_workers,
pin_memory=True,
drop_last=True
)
val_loader = DataLoader(
val_dataset,
batch_size=batch_size,
shuffle=False,
num_workers=num_workers,
pin_memory=True,
drop_last=True
)3.损失评估函数
定义了estimate_loss函数,用于在模型训练过程中监控训练效果、判断模型是否过拟合。在不更新模型参数的前提下,分别计算模型在训练集和验证集上的平均损失,反馈当前模型的效果
pytorch会自动计算梯度,使用@torch.no_grad()装饰器可以禁用自动梯度计算,因为当前正在评估,不需要更新参数。在评估前后需要进行模式的切换。在训练集和测试集中分别计算评估损失,创建一个长度为eval_iters的全零张量,用于存储eval_iters个批次的损失值。后续会用losses.mean()计算平均值。
其中的eval_iter是也即评估迭代批次,为了计算某一个数据集的平均损失,需要抽取的batch数量,这里也即64个样本。max_iters模型训练的最大参数更新次数,也是训练循环的终止条件
python
@torch.no_grad()
def estimate_loss(model):
out = {}
model.eval() #转换到评估模式
# 为训练集和验证集分别创建数据迭代器
for split in ['train', 'val']:
losses = torch.zeros(eval_iters)
# 根据split选择对应的DataLoader
data_loader = train_loader if split == 'train' else val_loader
# 创建数据迭代器
data_iter = iter(data_loader)
for k in range(eval_iters):
try:
# 直接使用DataLoader的迭代器获取数据
X, Y = next(data_iter)
except StopIteration:
# 如果数据遍历完,重新创建迭代器
data_iter = iter(data_loader)
X, Y = next(data_iter)
X, Y = X.to(device), Y.to(device)
logits, loss = model(X, Y)
losses[k] = loss.item()
out[split] = losses.mean()
model.train() #回到训练模式
return out4.Transformer具体模块
①单头自注意力
注意力的流程是:对于输入的嵌入向量,使用线性层将其映射到QKV矩阵空间。同时注册缓冲去,给定下三角掩码矩阵,这个矩阵是一个固定值,不随这参数进行更新。对于Head类,在初始化函数中初始化KQV和掩码矩阵,以及dropout单元
python
class Head(nn.Module):
def __init__(self, head_size):
super().__init__()
# 三个线性层:将嵌入向量映射到key、query、value空间(无偏置)
self.key = nn.Linear(n_embedding, head_size, bias=False)
self.query = nn.Linear(n_embedding, head_size, bias=False)
self.value = nn.Linear(n_embedding, head_size, bias=False)
# 注册缓冲区:下三角矩阵(掩码),不参与参数更新
self.register_buffer('tril', torch.tril(torch.ones(block_size, block_size)))
self.dropout = nn.Dropout(dropout) # Dropout正则化在forward中具体说明自注意力的流程。
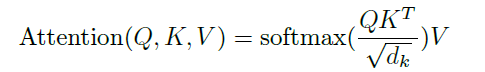
输入的嵌入向量,使用线性层将其映射到QKV矩阵空间后,使用q矩阵点乘转置的k矩阵,除以根号dk,经过softmax进行归一化后,再乘以v
python
def forward(self, x):
B,T,C = x.shape
k = self.key(x)
q = self.query(x)
wei = q @ k.transpose(-2,-1) * k.shape[-1]**-0.5
wei = wei.masked_fill(self.tril == 0, float('-inf'))
wei = F.softmax(wei, dim=-1)
wei = self.dropout(wei)
v = self.value(x)
out = wei @ v
return out②多头自注意力
定义自注意力的头数,[Head(head_size) for _ in range(number_heads)]:这是一个列表推导式 。它的作用是快速创建一个列表,这个列表里包含了 number_heads个 Head类的实例。也即创建了number_heads个头,每个头维度是head_sizes:
- 输入
x:(32, 10, 512)→ (B, T, C) - 单个
Head输出:(32, 10, 64)→ (B, T, hs) - 8 个
Head拼接后:(32, 10, 64*8)=(32, 10, 512)→ (B, T, hs*H) - 投影层输出(最终输出):
(32, 10, 512)→ (B, T, C)
python
class MultiHeadAttention(nn.Module):
def __init__(self, number_heads, head_size=head_size):
super().__init__()
self.heads = nn.ModuleList([Head(head_size) for _ in range(number_heads)])
self.proj = nn.Linear(head_size * number_heads, n_embedding)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
out = torch.cat([head(x) for head in self.heads], dim=-1)
out = self.dropout(self.proj(out))
return out③前馈神经网络
python
class FeedFoward(nn.Module):
def __init__(self, n_embedding):
super().__init__()
self.net = nn.Sequential(
nn.Linear(n_embedding, 4 * n_embedding),
nn.ReLU(),
nn.Linear(4 * n_embedding, n_embedding),
nn.Dropout(dropout),
)
def forward(self, x):
return self.net(x)④模型维护Block
由于要在一个模块上进行多次堆叠运算,将上述运算综合:
python
class Block(nn.Module):
def __init__(self, n_embedding, n_head):
super().__init__()
head_size = n_embedding // n_head
self.sa = MultiHeadAttention(n_head, head_size)
self.ffwd = FeedFoward(n_embedding)
self.ln1 = nn.LayerNorm(n_embedding)
self.ln2 = nn.LayerNorm(n_embedding)
def forward(self, x):
x = x + self.sa(self.ln1(x))
x = x + self.ffwd(self.ln2(x))
return x⑤完整语言模型
完成上面的子模块,来编写完整的语言模型
模型的五大组件:
- 字符嵌入层:将每个字符的整数索引转换为
n_embedding维度的向量,是模型处理离散字符的基础。 - 位置嵌入层:Transformer 是并行计算的,没有时序信息(不像 RNN),必须手动加入位置信息,让模型知道每个字符在序列中的位置。这里直接用
nn.Embedding实现,将位置索引(0,1,2,...,block_size-1)转换为向量,与字符嵌入相加,融合两种信息。 - Transformer Blocks:模型的核心,串联 6 个
Block,提取序列的上下文语义信息。 - 最后的层归一化:提升模型训练稳定性,对
Blocks的输出进行归一化。 - 语言模型头:将
n_embedding维度的特征映射到vocab_size维度,输出每个字符的预测得分(logits),用于后续计算损失和生成文本。
python
class LanguagueModel(nn.Module):
def __init__(self):
super().__init__()
# 1. 字符嵌入层:将整数索引转换为嵌入向量
self.token_embedding_table = nn.Embedding(vocab_size, n_embedding)
# 2. 位置嵌入层:将字符的位置信息转换为嵌入向量
self.position_embedding_table = nn.Embedding(block_size, n_embedding)
# 3. Transformer Blocks:串联6个Block,构建深层模型
self.blocks = nn.Sequential(*[Block(n_embedding, number_heads) for _ in range(number_blocks)])
# 4. 最后的层归一化
self.ln_f = nn.LayerNorm(n_embedding)
# 5. 语言模型头:将嵌入向量映射到词汇表大小,输出每个字符的预测概率
self.lm_head = nn.Linear(n_embedding, vocab_size)
def forward(self, idx, target=None):
B,T = idx.shape # B:batch_size,T:sequence_length
# 1. 获取字符嵌入和位置嵌入
token_emb = self.token_embedding_table(idx) # (B, T, n_embedding)
position_embd = self.position_embedding_table(torch.arange(T, device=device)) # (T, n_embedding)
x = token_emb + position_embd # (B, T, n_embedding),融合字符信息和位置信息
# 2. 经过Transformer Blocks处理
x = self.blocks(x) # (B, T, n_embedding)
# 3. 最后的层归一化
x = self.ln_f(x) # (B, T, n_embedding)
# 4. 语言模型头,输出logits(未经过softmax的原始预测值)
logits = self.lm_head(x) # (B, T, vocab_size)
# 5. 计算损失(如果传入target)
loss = None
if target is not None:
B,T,C = logits.shape
# 展平数据:F.cross_entropy要求输入形状为(B*T, C),目标形状为(B*T)
logits = logits.view(B*T, C)
target = target.view(B*T)
loss = F.cross_entropy(logits, target) # 交叉熵损失(分类任务,预测每个字符的类别)
return logits, loss
def generate(self, token_seqence, max_new_tokens):
# 输入:token_seqence(初始序列,形状为(B, T)),输出:生成max_new_tokens个新字符
for _ in range(max_new_tokens):
# 截断序列:确保不超过block_size(位置嵌入层的最大长度)
token_input = token_seqence[:, -block_size:]
# 前向传播,获取logits(不计算损失)
logits, loss = self.forward(token_input)
# 只保留最后一个位置的logits(预测下一个字符)
logits = logits[:, -1, :] # (B, vocab_size)
# softmax转换为概率分布
output_probability = F.softmax(logits, dim=-1)
# 随机采样:从概率分布中选取一个字符(比argmax更具多样性)
token_next = torch.multinomial(output_probability, num_samples=1) # (B, 1)
token_next = token_next.to(device)
# 拼接新字符到原序列,继续循环
token_seqence = torch.cat((token_seqence, token_next), dim=1) # (B, T+1)
# 只返回新增的tokens
new_tokens = token_seqence[:, -max_new_tokens:]
return new_tokens5.主函数
python
def main():
print(f"训练内容:{file_name}")
print(f"使用设备: {device}")
# 打印模型参数量(百万级)
print(sum(p.numel() for p in LanguagueModel().parameters())/1e6, 'M parameters')
# 初始化模型并迁移到设备
model = LanguagueModel()
model = model.to(device)
# 优化器:AdamW(带权重衰减的Adam,Transformer训练的常用优化器)
optimizer = torch.optim.AdamW(model.parameters(), lr=learning_rate)
# 训练循环
for i in range(max_iters):
# 定期评估损失,打印监控信息
if i % 50 == 0 or i == max_iters - 1:
losses = estimate_loss(model)
print(f"step {i}: train loss {losses['train']:.4f}, val loss {losses['val']:.4f}")
# 获取批量训练数据
xb, yb = get_batch('train')
# 前向传播计算损失
logits, loss = model(xb, yb)
# 梯度清零(避免梯度累积)
optimizer.zero_grad(set_to_none=True)
# 反向传播计算梯度
loss.backward()
# 优化器更新模型参数
optimizer.step()
# 定期打印单次batch的损失
if i % 20 == 0:
print(f"step {i}, loss {loss.item():.4f}")
print("训练结束,下面开始生成内容:")
# 文本生成参数
max_new_tokens = 200
# 随机选取验证集中的初始上下文
strat_idx = random.randint(0, len(val_data)-block_size-max_new_tokens) # 注意:拼写错误,应为start_idx
# 1. 上文内容(初始上下文)
context = torch.zeros((1,block_size), dtype=torch.long, device=device)
context[0,:] = val_data[strat_idx: strat_idx+block_size]
context_str = decode(context[0].tolist())
wrapped_context_str = textwrap.fill(context_str, width=50) # 格式化换行,美观输出
# 2. 真实下文
real_next_tokens = torch.zeros((1,max_new_tokens), dtype=torch.long, device=device)
real_next_tokens[0,:] = val_data[strat_idx+block_size : strat_idx+block_size+max_new_tokens]
real_next_str = decode(real_next_tokens[0].tolist())
wrapped_real_next_str = textwrap.fill(real_next_str, width=50)
# 3. 生成下文
generated_tokens = model.generate(context, max_new_tokens)
generated_str = decode(generated_tokens[0].tolist())
wrapped_generated_str = textwrap.fill(generated_str, width=50)
# 打印结果
print("上文内容:")
print(wrapped_context_str)
print("真实内容:")
print(wrapped_real_next_str)
print("生成内容:")
print(wrapped_generated_str)
# 确保在Windows上正确运行(主函数入口)
if __name__ == '__main__':
main()