DeepSeek-R1 的发布犹如在人工智能领域投下一颗重磅炸弹,迅速成为技术社区热议的焦点。它不仅公开了模型权重和蒸馏版本,更重要的是公开了训练方法------一种能够复现类似 OpenAI o1 推理能力的完整方案。本文将带你一步步拆解 DeepSeek-R1 的训练奥秘,用最通俗的方式讲清楚这个里程碑式模型是如何炼成的。
大模型训练基础:从"鹦鹉学舌"到"思考者"
要理解 DeepSeek-R1 的特殊之处,我们先快速回顾一下现代大模型的通用训练流程。大多数大模型都采用"逐词元生成"的范式,即根据上文预测下一个词。但 DeepSeek-R1 在处理数学和推理问题时,能生成一种特殊的"思考词元"(thinking token),相当于让模型在回答之前先进行内部思考,花更多时间分析问题,如下图所示。

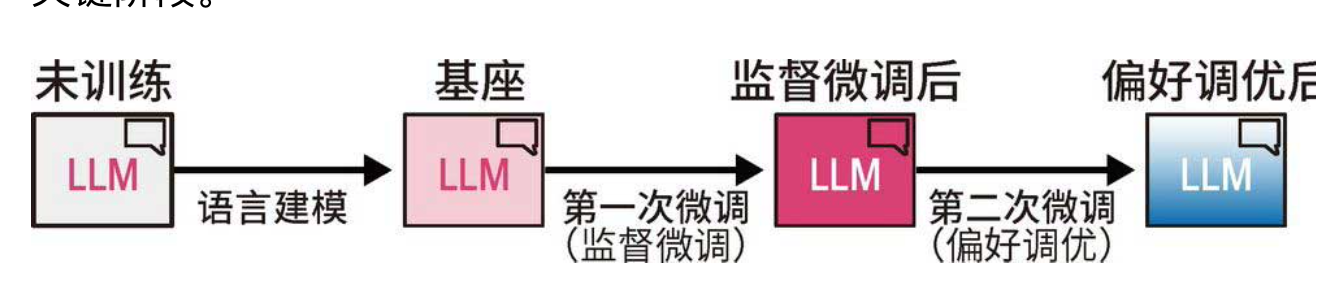
通常,构建一个高质量大模型需要经过三个关键阶段(下图):
-
语言建模阶段:在海量网络数据上训练模型预测下一个词,得到基础模型(Base Model)。
-
监督微调阶段:用人工标注的指令数据微调模型,使其学会遵循指令、回答问题,得到指令模型(SFT Model)。
-
偏好调优阶段:通过人类反馈(如 RLHF)进一步对齐模型行为,得到最终可用的聊天模型。
DeepSeek-R1 遵循这一通用框架,但其创新之处在于每个阶段的具体实现------尤其是如何获取高质量的推理数据,以及如何利用强化学习激发模型的推理潜能。
创新的训练方案:三步打造推理王者
DeepSeek-R1 的训练流程可以用下图概括,其中有三个关键创新点:

1. 60 万条长推理链数据从哪来?------临时推理模型的"数据工厂"
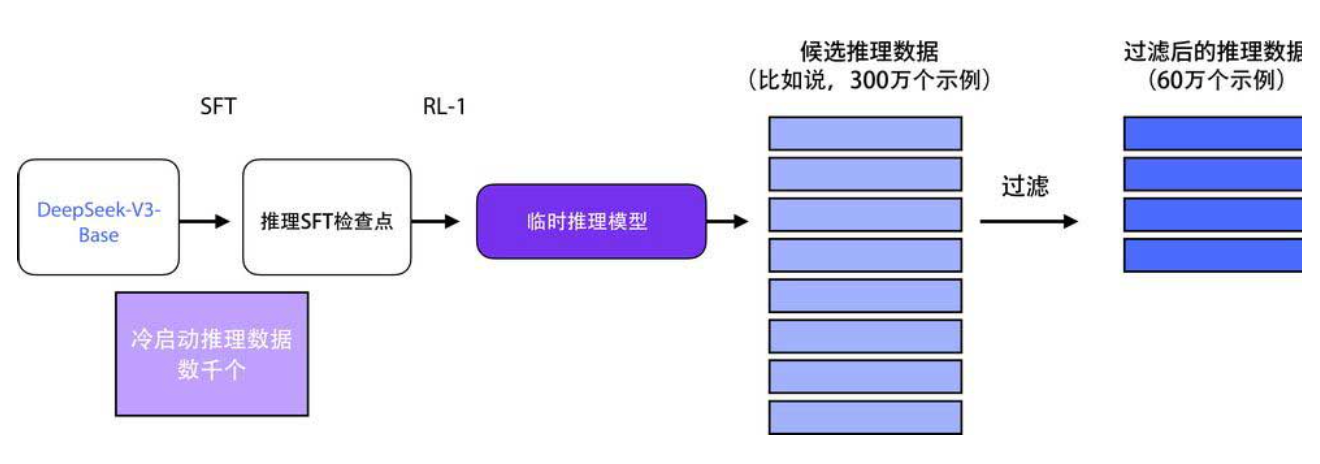
监督微调需要大量"长链思维"示例(即模型展示逐步推理过程的数据)。DeepSeek-R1 一共用了 60 万个这样的示例(下图)。如此规模的数据,如果全靠人工标注,成本高得难以想象。那么这些数据是怎么来的呢?
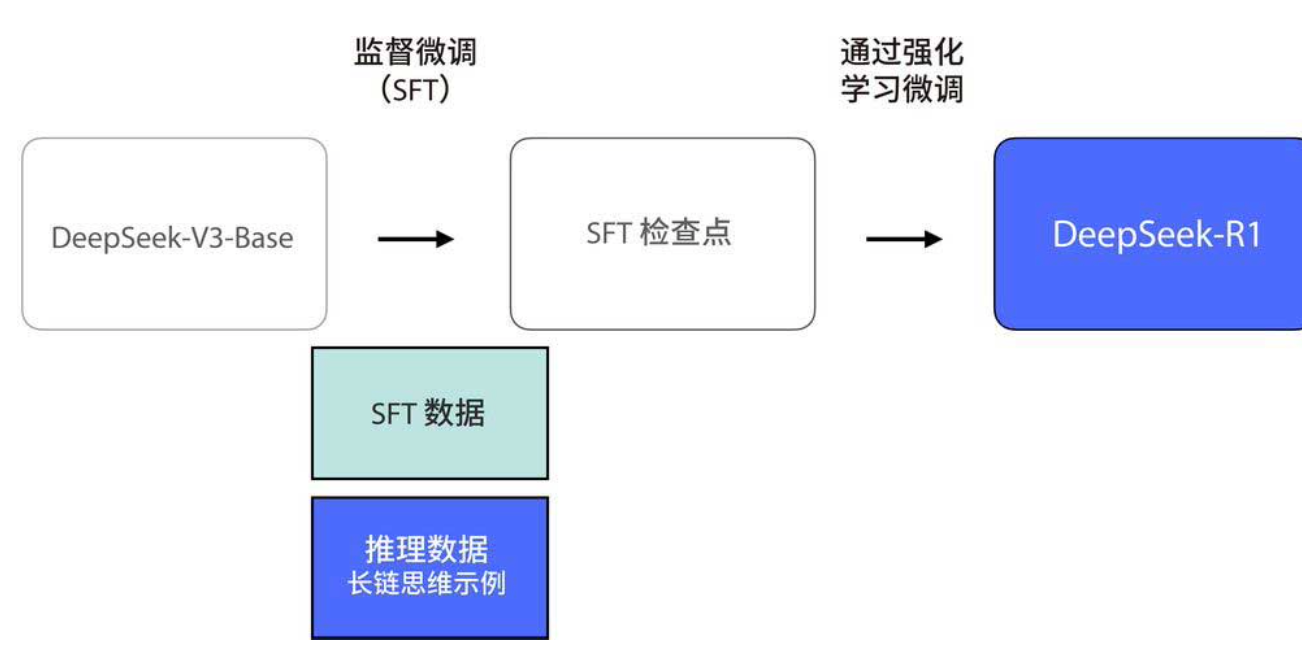
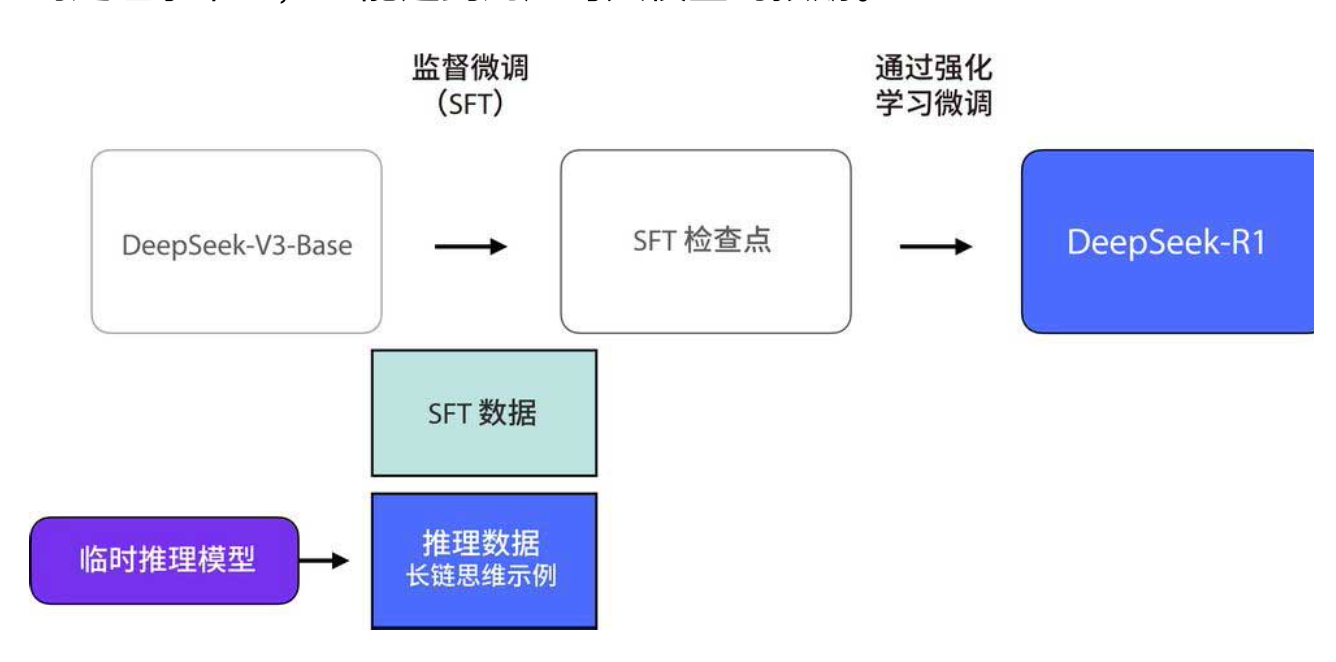
答案是用一个"临时推理模型"自动生成。这个临时模型本身并不完美,甚至只在推理任务上表现出色,在通用任务上表现平平(下图)。但它有一个关键能力:可以用极少的标注数据,通过大规模强化学习训练,成为推理专家。然后,研究者用这个临时模型生成 60 万条长链思维示例,再用这些数据去训练最终的 DeepSeek-R1 模型。这样一来,最终的模型既继承了强大的推理能力,又保留了通用对话能力。
2. 推理导向的强化学习:DeepSeek-R1-Zero 的诞生
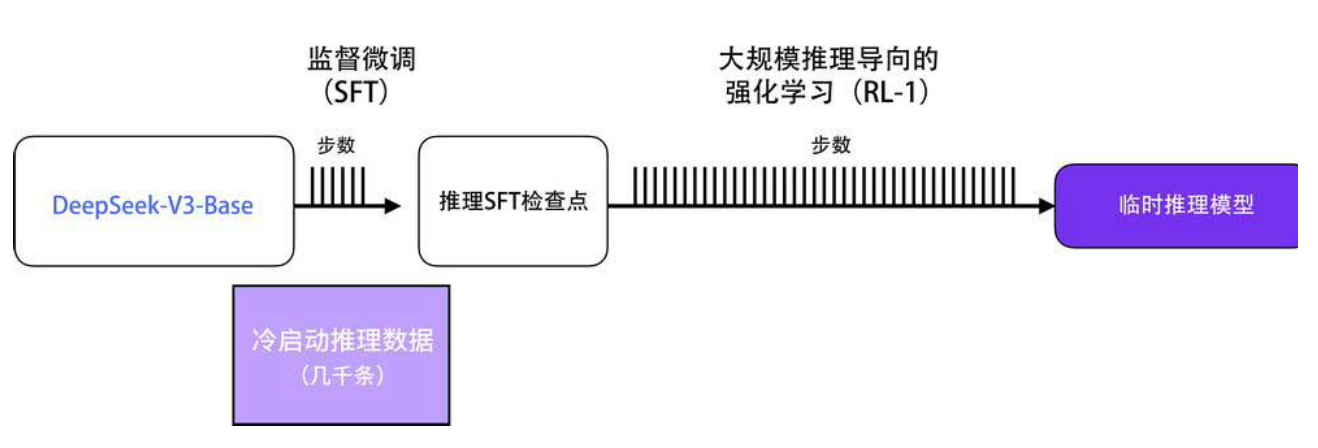
构建临时推理模型的关键是大规模推理导向的强化学习(下图)。整个过程分为两步:
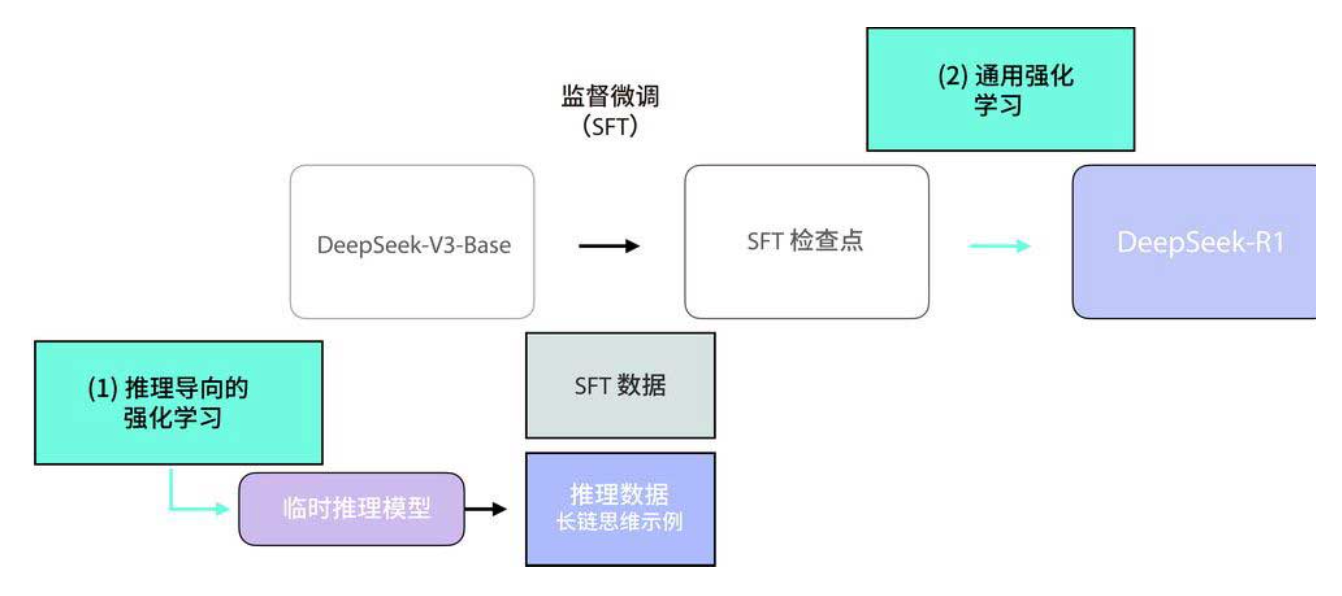
- 第一步:直接从基础模型(DeepSeek-V3-Base)出发,进行推理导向的强化学习,得到 DeepSeek-R1-Zero(下图)。

- 第二步:用这个 Zero 模型生成推理数据,再结合少量冷启动数据微调,得到临时推理模型。
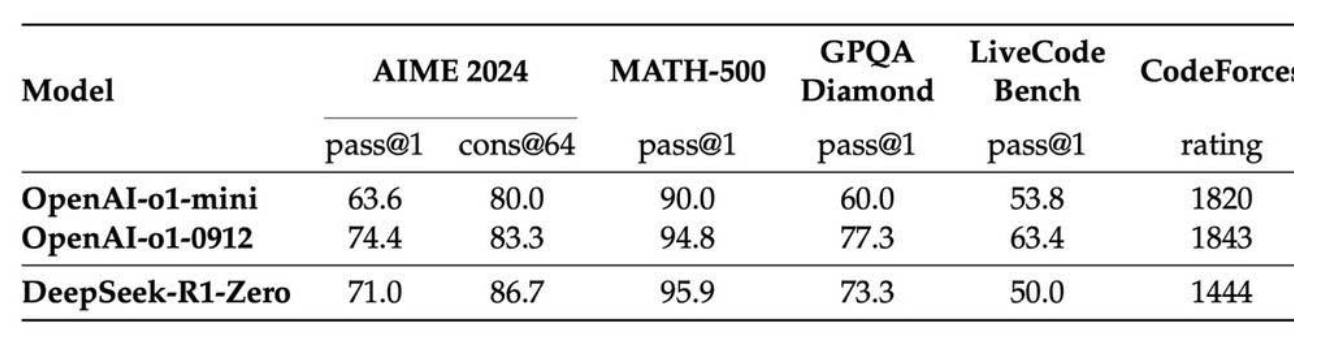
DeepSeek-R1-Zero 是一个非常特别的实验产物------它完全跳过了监督微调阶段,仅靠强化学习就在推理任务上达到了与 OpenAI o1 相当的水平(下图的表格)。这在以前几乎不可想象,因为数据通常被认为是模型能力的瓶颈。为什么能做到?
自动验证:强化学习的"免费午餐"
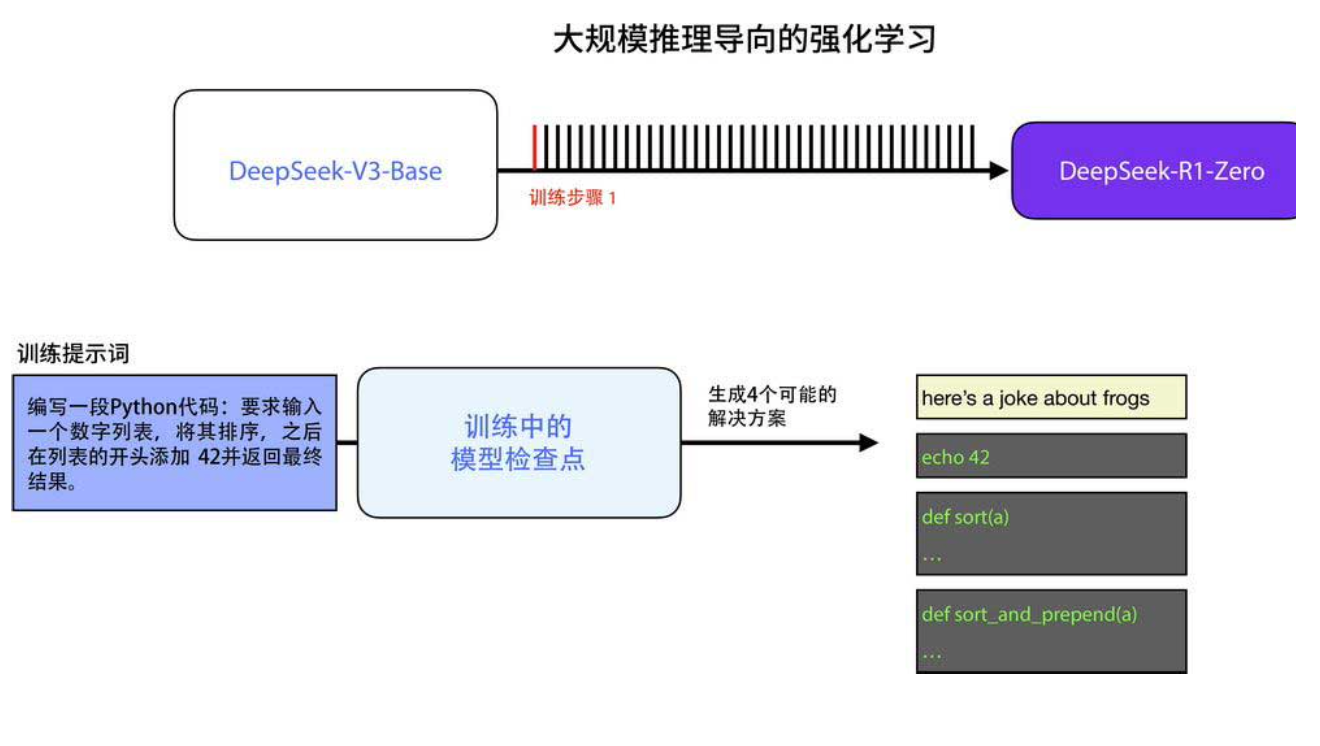
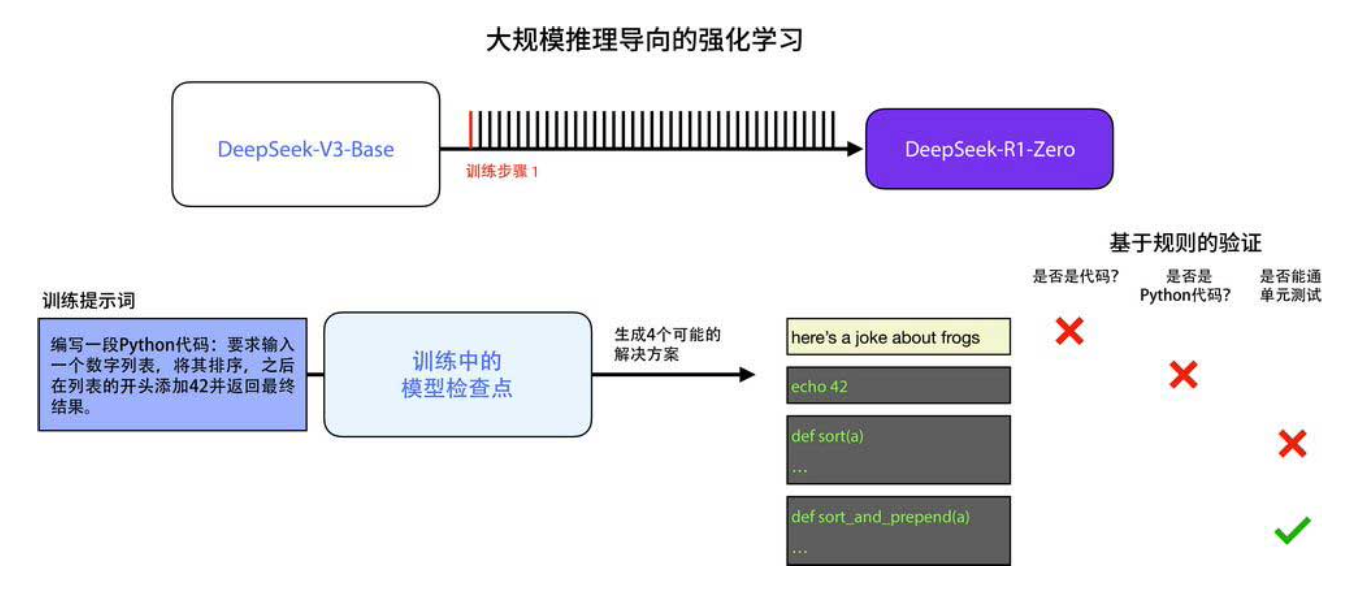
推理问题有一个天然优势:结果可以自动验证。例如,让模型写一段 Python 代码,我们可以用代码检查工具(linter)、执行代码、甚至让另一个模型写单元测试来验证代码的正确性(下图)。
这种自动验证信号可以直接作为强化学习的奖励(下图)。
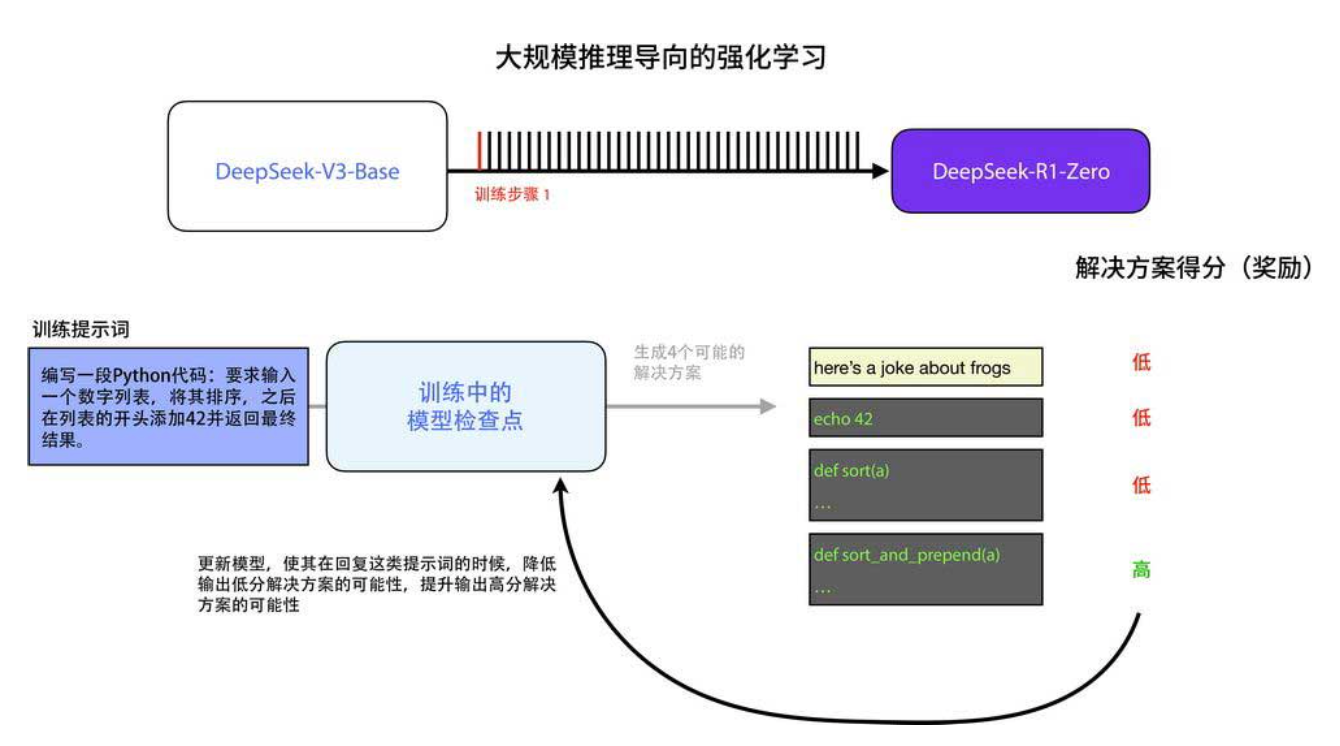
在训练中,对于同一个提示词,模型会生成多个候选答案,自动验证会给每个答案打分(比如是否正确、是否高效)。模型通过强化学习算法(如 PPO)不断调整参数,让输出高分答案的概率越来越大。下图展示了训练过程中 DeepSeek-R1-Zero 在 AIME 数学基准上的准确率持续提升,
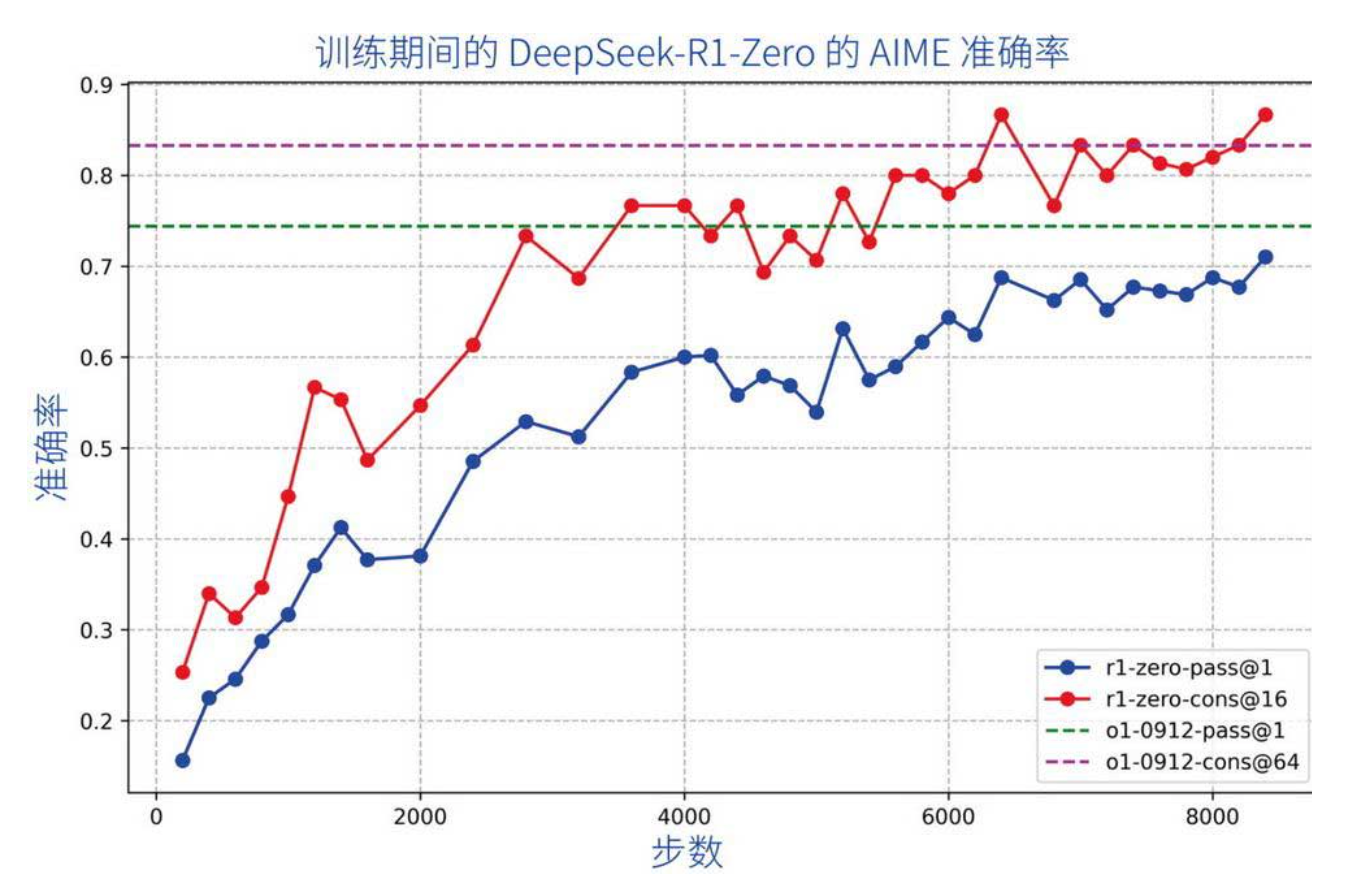
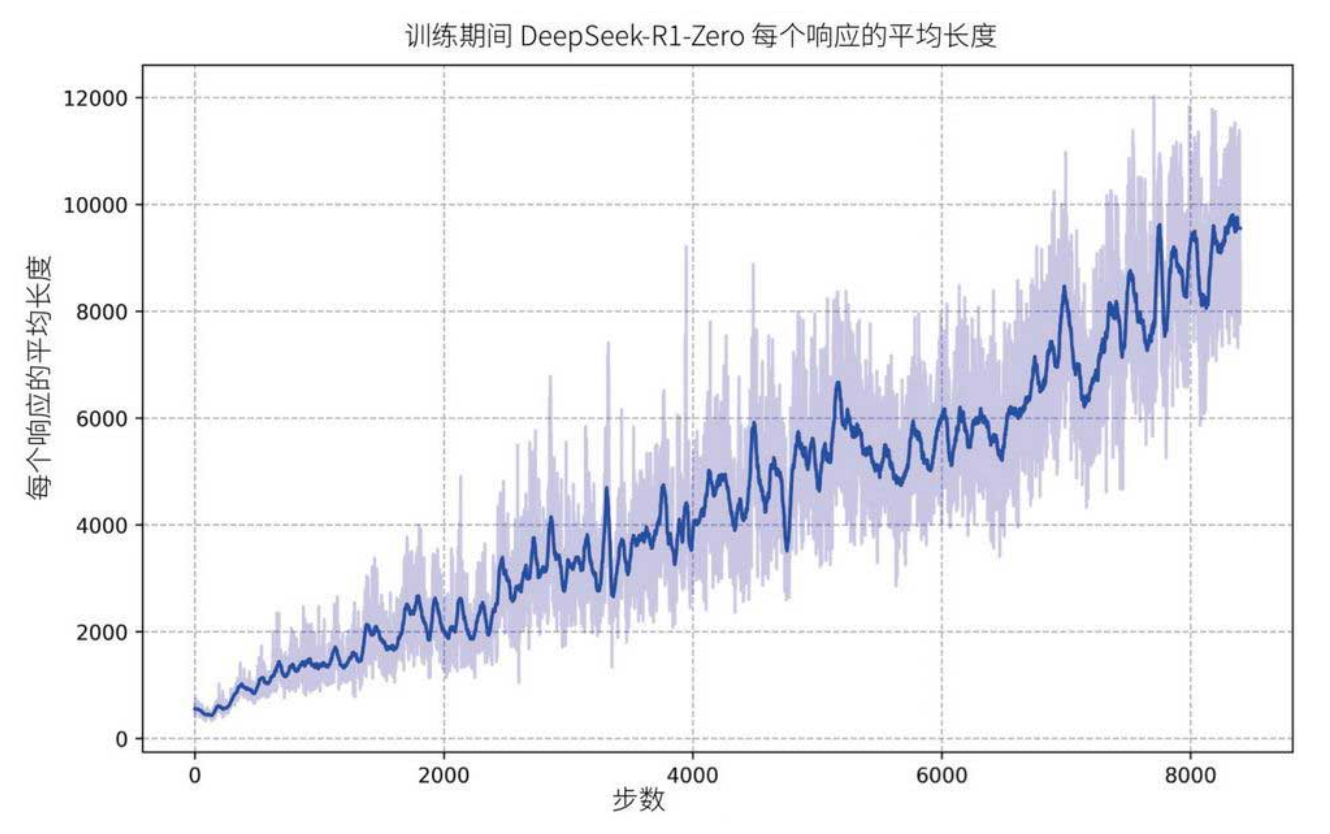
而下图则显示模型生成的内容长度也在增加------它学会了用更多"思考词元"处理复杂问题。
3. 冷启动与通用强化学习:从推理专家到全能助手
尽管 DeepSeek-R1-Zero 推理能力惊人,但它存在严重缺陷:生成内容可读性差、语言混杂(中英文混用),难以直接使用。因此,研究者决定不直接用 Zero 作为最终模型,而是用它来构建更好的训练数据。
首先,他们收集了数千个高质量的"冷启动"推理示例(下图),包括:
-
用少样本提示引导模型生成带反思和验证的答案;
-
将 Zero 的输出整理成易读格式;
-
人工标注优化。
用这些冷启动数据对基础模型进行监督微调,得到一个初始的"临时推理模型"。然后,再用这个模型去生成 60 万条长链思维数据------这样既保证了数据质量,又实现了规模扩展(下图)。
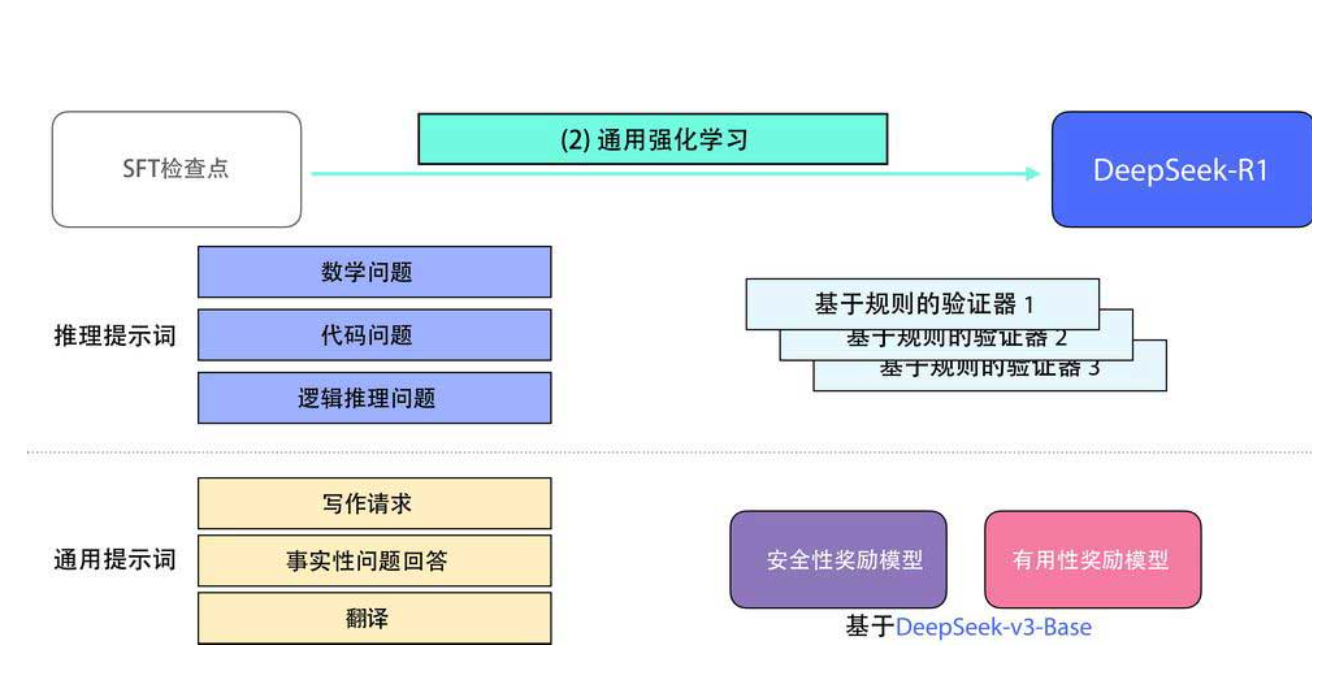
最后,进入通用强化学习阶段 (下图)。此时训练数据既有推理任务(数学、代码、逻辑),也有通用任务(写作、问答、翻译)。对于推理任务,仍然使用基于规则的验证器(如代码执行结果);对于通用任务,则引入有用性奖励模型 和安全性奖励模型(类似 Llama 的做法),确保模型既 helpful 又 harmless。
总结:DeepSeek-R1 的创新价值
DeepSeek-R1 的训练方案为我们揭示了一条可行的路径,让开源社区也能复现顶尖推理模型的能力。其核心创新可以归纳为:
-
数据合成的新范式:通过一个专门强化学习训练出的"临时推理模型"自动生成大规模长链思维数据,解决了推理数据稀缺和高成本的问题。
-
强化学习的巧妙应用:利用推理问题可自动验证的特点,在无监督微调的情况下直接通过强化学习激发出模型的深度推理能力(DeepSeek-R1-Zero),为后续数据生成打下基础。
-
冷启动与两阶段训练:先用少量高质量冷启动数据稳定模型,再通过大规模强化学习全面优化,最终得到既擅长推理又具备通用对话能力的实用模型。
对于整个机器学习社区,DeepSeek-R1 不仅贡献了一个强大的模型,更重要的是公开了训练过程中的反思和具体方法。这标志着开源模型在推理能力上已追上闭源前沿,也为未来更多领域的推理增强研究提供了可复现的蓝本。或许,这正是"AI 民主化"的又一大步。
本文参考:图解大模型:生成式AI原理与实战
书籍pdf免费下载地址:https://pan.baidu.com/s/1mTaUQ5czcfGpBM8KvJuS2g?pwd=un44