前言:
bev鸟瞰图模型 、 classification分类模型、 detection检测模型、disparity_pred深度估计模型、multitask多任务模型、online_map在线建图模型、opticalflow光流模型、segmentation分割模型、tracking追踪模型、traj_pred轨迹预测等
BEV鸟瞰图模型
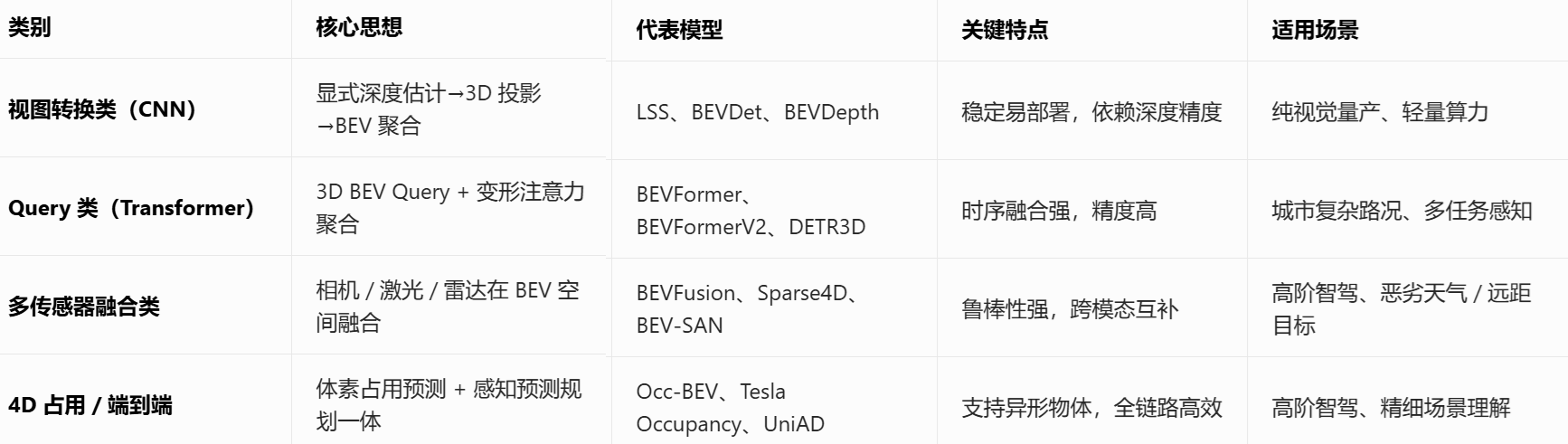
1. 视图转换类(CNN 基)
- LSS(Lift-Splat-Shoot) :BEV 感知开山之作。先从多视图图像预测深度分布,将 2D 特征 "提升" 为 3D 体素,再 "散开" 到 BEV 空间,最后通过卷积 "射击" 生成 BEV 特征。
- ✅ 优点:原理清晰、稳定、工程友好;
- ❌ 缺点:深度估计误差直接影响投影精度。
- BEVDet:基于 LSS 的检测专用框架,分 v1/v2/v3 系列,适配不同算力。
- ✅ 优点:部署成熟、支持多任务头;
- ❌ 缺点:时序融合弱于 Transformer 类。
- BEVDepth:改进 LSS 深度估计,显式建模深度不确定性,提升远距小目标表现。
- ✅ 优点:纯视觉下精度提升明显;
- ❌ 缺点:深度分支训练成本略高。
2. Query 类(Transformer 基)
- BEVFormer :标杆性 Query 模型。在 BEV 空间预设 Query,通过变形注意力(Deformable Attention)从多视图图像中稀疏采样聚合特征,天然支持时序融合。
- ✅ 优点:时序感知强、多任务统一、精度领先;
- ❌ 缺点:算力高于 CNN 类,部署需优化。
- BEVFormerV2:升级版,增强主干网络监督与数据增强,提升收敛速度与精度。
- ✅ 优点:适配大规模数据,支持多模态;
- ❌ 缺点:训练资源需求更高。
- DETR3D:将 3D 检测视为集合预测,直接从 BEV Query 生成 3D 框,端到端训练。
- ✅ 优点:无锚框设计,适合复杂场景;
- ❌ 缺点:收敛慢,算力消耗大。
3. 多传感器融合类
- BEVFusion :统一 BEV 空间,将相机与激光雷达特征对齐后融合。分特征级融合 (主流)与点云 - 图像级融合,支持动态权重分配。
- ✅ 优点:鲁棒性强,雨天 / 遮挡表现好;
- ❌ 缺点:激光雷达硬件成本高。
- Sparse4D:稀疏张量 + 原始数据前融合,端到端训练,提升融合效率。
- ✅ 优点:计算量低、实时性强;
- ❌ 缺点:工程实现复杂。
- BEV-SAN:空间自适应注意力融合,为 BEV 每个位置动态分配相机 / 激光权重。
- ✅ 优点:场景自适应强,解决固定权重泛化差问题;
- ❌ 缺点:推理略慢。
4. 4D 占用 / 端到端类
- Occ-BEV:BEV + 占用预测,输出 3D 体素占据网格,支持语义与实例分割。
- ✅ 优点:支持异形物体、长尾场景;
- ❌ 缺点:体素化计算量大。
- Tesla Occupancy Network:特斯拉量产方案,基于 BEV+Transformer 预测体素占用,替代传统 3D 检测。
- ✅ 优点:全链路高效、适配高阶智驾;
- ❌ 缺点:依赖车载大算力平台。
- UniAD:端到端模型,将感知、预测、规划统一为单网络。
- ✅ 优点:减少模块延迟,响应速度快;
- ❌ 缺点:训练与调试复杂。
选型建议(按场景)
- 纯视觉量产 :优先 LSS/BEVDet (稳定易部署);追求精度可选 BEVDepth 或 BEVFormer(轻量化版)。
- 城市复杂路况 :选 BEVFormer/BEVFormerV2 (时序融合强)或 BEVFusion(多模态鲁棒)。
- 高阶智驾(激光雷达) :选 BEVFusion (特征级融合)或 Sparse4D(稀疏高效)。
- 精细场景理解 :选 Occ-BEV/Tesla Occupancy(体素占用)。
- 成本敏感 :优先 LSS/BEVDet(纯视觉 CNN 类),搭配轻量化骨干与量化。
2025--2026 前沿方向
- 稀疏与高效:SparseBEV、Sparse4D(全稀疏架构,兼顾精度与实时性)。
- Mamba 替代 Transformer:MambaBEV(用 SSM 替代注意力,降低算力与内存)。
- 端到端一体化:UniAD、XNet 2.0(感知→预测→规划单网络)。
- 自监督 / 弱监督:SelfBEV、WeakBEV(降低标注成本,实车数据闭环)。
Classification分类模型
1、经典 CNN 分类模型
- LeNet最早的卷积分类网络,手写数字识别。
- AlexNet开启深度学习热潮,双 GPU、ReLU、Dropout。
- **VGGNet(VGG16 / VGG19)**结构简单、全 3×3 卷积,非常稳定,适合小数据集。
- **GoogLeNet / Inception(v1--v4)**多尺度卷积、1×1 降维,计算效率高。
- ResNet(18/34/50/101/152) 残差连接,解决深层训练难,最通用、最常用。
- ResNeXt分组卷积,精度更高,参量可控。
- DenseNet密集连接,特征复用,小模型效果好。
- MobileNet(v1/v2/v3) 深度可分离卷积,移动端 / 边缘端首选。
- ShuffleNet通道洗牌,超轻量模型。
- EfficientNet(B0--B7) 自动搜索最优宽度 / 深度 / 分辨率,精度极高。
- ConvNeXt纯 CNN 对标 Transformer,精度强、好训练。
2、Transformer 分类模型
- **ViT(Vision Transformer)**纯 Transformer 做分类,里程碑。
- Swin Transformer 分层窗口注意力,通用强、下游任务无敌。
- DeiT蒸馏版 ViT,训练更稳、更快。
- T2T-ViT渐进式 Token 化,小数据也能用。
- PVT / PVTv2金字塔 ViT,适合检测 / 分割。
- CrossViT多尺度分支交叉注意力。
3、轻量高效(适合部署 / 量化)
- MobileOne
- MobileViT
- EfficientNet-Lite
- RepVGG(重参数化,训练多分支,推理单路)
- MobileDense
- ShuffleNetV2
4、2025--2026 最新主流
- Mamba / VMamba(视觉状态空间模型,速度快)
- MetaFormer(PoolFormer、ConvFormer)
- EdgeNeXt
- MobileSAM 配套轻量分类头
5、最简单直接的选型建议
- 通用稳定:ResNet50
- 高精度:EfficientNetB4 / Swin-T
- 移动端 / 嵌入式:MobileNetV3 / MobileViT
- 科研 SOTA:ConvNeXt / Swin Transformer
- 超快推理:RepVGG / MobileOne
检测模型
1、两阶段检测(精度高,速度慢)
- Faster R-CNN两阶段标杆:RPN + 检测头
- Mask R-CNN检测 + 分割一起做
- Cascade R-CNN级联检测框,大幅提升 AP
- Libra R-CNN平衡特征,小目标更强
2、单阶段检测(速度快,工程首选)
Anchor-based
- SSD多尺度检测经典
- RetinaNet 解决正负样本不平衡,精度很高
- YOLOv3 / YOLOv4工业界曾经的王者
Anchor-free
- FCOS全卷积 anchor-free,稳定好用
- CenterNet基于关键点,简单干净
3、YOLO 全家桶(最主流、最实用)
- YOLOv5(工程部署最多)
- YOLOv6(美团,速度精度均衡)
- YOLOv7
- YOLOv8(目前最通用、最易用)
- YOLOv9
- YOLOv10(极致速度)
- YOLOv11(最新 SOTA)
- YOLO-World(开放词汇检测)
4、Transformer 检测(SOTA 精度)
- DETR端到端检测,去掉 NMS
- Deformable DETR可变形注意力,速度快很多
- DINO目前 DETR 系列最强
- Swin Transformer + 检测头通用强基线
5、轻量化检测(边缘 / 嵌入式 / 量化)
- YOLOv8-n/s/m
- MobileNet-SSD
- MobileDets
- PP-YOLOE(百度飞桨轻量)
- YOLO-Pose(姿态 + 检测轻量)
6、3D / BEV 检测(自动驾驶)
- BEVDet
- BEVFormer
- DETR3D
- FCOS3D
- CenterPoint(激光雷达)
7、最简单直接选型(直接照抄)
- 通用项目、快速落地:YOLOv8 / YOLOv11
- 高精度、不计速度:Cascade R-CNN / DINO
- 边缘端、量化部署:YOLOv8-n/s / MobileDets
- 自动驾驶、BEV:BEVFormer / BEVDet
- 激光雷达 3D 检测:CenterPoint
分割模型:
按语义分割 / 实例分割 / 全景分割 / 轻量分割 / 3D/BEV 分割分。
1、语义分割(Semantic Segmentation)
给每个像素分类别(道路、人、车、天空等)
- FCN分割开山之作
- **U-Net / U-Net++**医学影像、小数据必备
- **DeepLabv3 / DeepLabv3+**空洞卷积 + ASPP,精度高、稳定
- PSPNet金字塔池化,场景理解强
- SegFormerTransformer 轻量化,又快又准
- SegNext精度超 SegFormer,更好训
- HRNet高分辨率保持,细节强
2、实例分割(Instance Segmentation)
把每个物体单独抠出来(每个人、每辆车)
- Mask R-CNN经典、通用、稳定
- SOLO / SOLOv2速度快,anchor-free
- CondInst动态卷积,实例分割轻量化
- **YOLACT / YOLACT++**实时实例分割
3、全景分割(Panoptic Segmentation)
语义 + 实例一起做(东西 + Stuff)
- Panoptic FPN
- Mask2Former一个模型搞定分割全任务,SOTA
- OneFormer通用大一统分割
4、实时 / 轻量分割(边缘、量化、移动端)
- BiSeNet / BiSeNetV2超实时,城市道路分割
- MobileSeg
- MobileOne-Seg
- PP-LiteSeg(百度飞桨)
- YOLOv8-seg工程最方便,开箱即用
5、自动驾驶 / BEV 分割
- BEVSeg
- BEVFormer + 分割头
- Occ-BEV(占用网格)
- SurroundOcc
- SimpleOccupancy
6、直接给你最强选型(照抄就行)
- 医学影像:U-Net++
- 通用语义分割:SegFormer / SegNext
- 工程快速落地:YOLOv8-seg
- 自动驾驶道路分割:BiSeNetV2 / DeepLabv3+
- 全景 / 多任务一体:Mask2Former
- 边缘端 + 量化:MobileSeg / BiSeNetV2
- BEV / 占用预测:BEVFormer / Occ-BEV
disparity /depth 预测
深度估计模型,分双目视差(disparity) 、单目深度(depth) 、实时 / 轻量 / 可量化三类
1、双目视差 Disparity 模型(输出 disparity)
这类模型专门做双目匹配 → 视差图 ,最适合 disparity_pred。
- GC-Net早期经典 3D 卷积视差估计
- PSMNet 金字塔 + 空间池化,高精度标杆
- GA-Net引导聚合,精度更高
- GwcNet分组相关卷积,比 PSM 更快更准
- CFNet相关场滤波,实时性好
- RAF-Stereo迭代 refine,精度 SOTA
- StereoNet轻量双目,适合边缘部署
- AnyNet任意分辨率 / 实时双目
- MobileStereoNet移动端轻量化视差模型
2、单目深度估计模型(输出 depth map)
不做 disparity,直接输出深度值,但很多结构可改输出视差。
- Monodepth / Monodepth2自监督单目深度,最经典
- **DPT (Depth Prediction Transformer)**ViT + 深度预测,精度很高
- AdaBins分箱预测深度,SOTA
- DepthAnything 超强通用单目深度,工业实用
- Metric3D可输出米级绝对深度
- GLPN轻量 Transformer 深度模型
3、实时 / 轻量 / 可量化模型(适合 OpenExplorer 量化)
适合INT8 量化、BPU / 嵌入式部署:
- StereoNet
- MobileStereoNet
- AnyNet
- CFNet
- Lite-Mono
- MobileDepth
4、最优路线:
- 高精度:PSMNet / GwcNet / RAF-Stereo
- 工程 / 量化友好:StereoNet / MobileStereoNet
- 最简单快速:AnyNet
multitask多任务模型
1、通用多任务架构(Backbone + 多任务头)
最常见:一个主干,多个检测 / 分割 / 深度 / 分类头。
- Multi-task CNN(ResNet + 多分支)
- HRNet + Multi-head(高分辨率,适合分割 + 关键点)
- ResNet / ResNeXt + 多任务头
- Swin Transformer + Multi-task Heads
2、自动驾驶 / BEV 多任务(最常用)
- BEVFormer检测 + 分割 + 轨迹 + 占用 一网络搞定
- BEVDet3D 检测 + 语义分割
- BEVFusion多模态 + 多任务统一
- UniAD端到端:感知→预测→规划
- Occ-BEV3D 检测 + 占用网格 + 语义
- PETR / PETRv2BEV 多任务、时序融合
3、2D 视觉多任务(检测 + 分割 + 深度 + 关键点)
- Mask R-CNN检测 + 实例分割
- Panoptic FPN全景分割(语义 + 实例)
- YOLOv8/YOLOv11 multi-task检测 + 分割 + 姿态 + 分类
- OneFormer / Mask2Former大一统分割(语义 / 实例 / 全景)
- MTI-Net检测 + 深度 + 分割
- DPT-MultiTaskTransformer 多任务深度 + 分割
4、轻量多任务(适合量化、边缘、OpenExplorer)
- BiSeNet + 多任务头
- MobileNet + Multi-task
- MobileViT + 多分支
- PP-YOLOE + 多任务
- YOLO-Pose + Seg检测 + 姿态 + 分割
5、多任务训练范式(决定你怎么训)
- Hard Parameter Sharing主干共享,分支独立(最常用、最快)
- Soft Parameter Sharing各任务有独立 backbone,互相正则
- Attention-based FusionBEVFormer、Mask2Former 这种
- Multi-scale Feature FusionFPN、PAN 结构
6、最强落地选型(照抄)
- 自动驾驶 BEV 多任务:BEVFormer / BEVFusion
- 2D 检测 + 分割 + 姿态:YOLOv8 / YOLOv11 multi-task
- 高精度分割全家桶:Mask2Former / OneFormer
- 边缘 / 量化 / 低算力:MobileNet + 多任务头 / BiSeNet
- 端到端智驾:UniAD
**多个个任务一起做,**比如:
- 检测 + 分割
- 检测 + 深度视差(disparity)
- BEV 3D 检测 + 语义分割
opticalflow光流模型
1、深度学习光流模型(最常用)
1). 经典高精度
- FlowNet / FlowNet2光流深度学习开山,精度一般,速度慢。
- PWC-Net 金字塔 + 代价体积,轻量化、精度高、工业最常用。
- RAFT 迭代优化,目前精度天花板,非常稳。
- GMA基于 RAFT 加注意力,精度更高。
- GMFlow全局匹配 + Transformer,精度接近 RAFT,速度更快。
2). 实时 / 高速光流
- LiteFlowNet轻量 PWC-Net,速度快。
- FastFlowNet实时高精度,适合嵌入式。
- CSR-Flow上下文空间精炼,速度快。
- ROF实时光流,边缘部署友好。
3). 2025--2026 最新 SOTA
- GMFlow++
- MatchFlow
- UniMatch
- RAFT-Stereo(也能做光流)
2、传统光流算法(不用训练,直接跑)
- Lucas--Kanade(LK 光流)
- Horn--Schunck
- Farnebäck
- SIFT Flow
工程上一般只用来做对比 / 初始化,精度远不如深度学习。
3、适合 OpenExplorer 量化、嵌入式部署
最推荐 3 个:
- PWC-Net 结构干净、卷积为主、INT8 量化极其友好
- LiteFlowNet超轻量,速度快
- FastFlowNet实时性强,车规可用
RAFT/GMA 因为有循环 / 迭代,量化难度高,不太适合 BPU。
4、最简单直接选型
- 要精度最高 :RAFT / GMFlow
- 要工程落地 + 量化 :PWC-Net
- 要实时嵌入式 :LiteFlowNet / FastFlowNet
- 做自动驾驶 / BEV 时序 :PWC-Net 或 GMFlow
Track追踪模型
分单目标 / 多目标 / 2D / 3D / BEV 跟踪,直接给你能选的那种。
1、单目标追踪 SOT(Single Object Tracking)
给初始框,一直跟着它
- SiamFC孪生网络,早期经典
- **SiamRPN / SiamRPN++**精度高、速度快
- DaSiamRPN防遮挡更强
- Ocean / Ocean++
- TransTTransformer 跟踪
- StarkTransformer 高精度跟踪
2、多目标追踪 MOT(Multi-Object Tracking)
同时跟踪多人 / 多车,最常用在自动驾驶、安防
1). 传统关联(检测 + 卡尔曼 + 匈牙利)
- SORT
- DeepSORT(最经典、工业最常用)
- StrongSORT
2). 基于外观特征
- FastReID(行人 / 车辆重识别)
- OSNet(轻量 ReID)
3). 端到端 MOT(Joint Detect + Track)
- JDE
- FairMOT (工业首选,又快又稳)
- CenterTrack
- TraDeS
- TransTrack
- ByteTrack (精度极高、现在最火)
- BotSort(比 ByteTrack 更强)
3、2D 检测 + 跟踪一体化(工程落地最强)
- YOLOv5 + DeepSORT
- YOLOv8 + ByteTrack / BotSort (目前最通用)
- YOLOv11 + Track
- YOLO-Track 系列
4、3D 追踪 / 自动驾驶 Tracking
- AB3D
- PTTA
- LTR
- SimpleTrack(3D 快速跟踪)
- CenterPoint + Track(激光雷达 3D 追踪)
5、BEV 跟踪(时序多目标追踪)
- BEV-Track
- BEVFormerTrack
- PETR-Track
- StreamPETR
- MOT-BEV
- MapTR + Track(在线建图 + 跟踪)
6、适合 OpenExplorer 量化、嵌入式部署
这些结构干净、无复杂循环、好转 ONNX、好量化 INT8:
- DeepSORT
- ByteTrack
- FairMOT
- YOLOv8/v11 Track
- FastReID、OSNet
7、 最强选型(照抄就行)
- 通用 2D 多目标:ByteTrack / BotSort
- 工程最快落地:YOLOv8 + ByteTrack
- 嵌入式 / 量化:DeepSORT + YOLOv8-n/s
- 自动驾驶 3D/BEV:BEVFormerTrack / PETR-Track
- 轻量 ReID:OSNet、FastReID
SLAM/VSLAM定位导航模型
1、经典开源 SLAM(最常用、资料最多)
1). 视觉 SLAM(VSLAM)
-
ORB-SLAM2 / ORB-SLAM3最经典、最稳、工程落地最多。
- 支持单目、双目、RGB-D
- ORB-SLAM3 支持视觉 + IMU 紧耦合
- 适合:扫地机、AGV、无人机、嵌入式开发板
-
SVO / SVO2半直接法,速度极快,弱纹理也能跑。
- 适合:高速无人机、嵌入式实时场景
-
DSO / LDSO直接法,精度高、对光照鲁棒。
- 适合:科研、高精度场景
-
VINS-Mono / VINS-Fusion视觉 + IMU 紧耦合,非常稳。
- 自动驾驶、机器人、无人机常用
-
RTAB-Map 闭环很强,适合大场景、长时间建图。
- 适合:服务机器人、室内大场景建图
2). 激光 SLAM(LiDAR SLAM)
-
LOAM / LeGO-LOAM激光经典框架,精度高、实时性强。
-
A-LOAMLOAM 的优化开源版,易编译、易跑通。
-
LIO-SAM / LIO-SAM-LITE 激光 + IMU 紧耦合,目前落地非常多。
- 自动驾驶、机器人、室外导航首选之一
-
FAST-LIO2超快、超稳、支持大场景。
- 工业机器人、自动驾驶、无人机都爱用
3). 多传感器融合 SLAM(现在主流)
- LVI-SAM:激光 + 视觉 + IMU 融合
- VINS-Fusion:视觉 + IMU + GPS / 激光
- ORB-SLAM3 + IMU + LiDAR:多模融合
2、深度学习 / 神经网络 SLAM
- DeepVO
- VO Transformer
- NeRF-SLAM(语义 + 重建)
- SLAM++ 这类精度高,但算力要求大,嵌入式一般不太跑。
3、极简选型建议
- 只有摄像头 → ORB-SLAM3 / VINS-Mono
- 摄像头 + IMU → ORB-SLAM3 / VINS-Fusion
- 激光雷达 → A-LOAM / FAST-LIO2
- 大场景、要稳、要闭环 → RTAB-Map
- 自动驾驶 / 机器人融合 → LIO-SAM / LVI-SAM